In recent years, The massive pre-trained Language models have dominated the State-of-the-Art leaderboard across many NLP tasks including the Question Answering task on SQuAD 2.0. In this project, we travel back to a successful traditional approach known as Bi-Directional Attention Flow (BiDAF) which uses a sequence-to-sequence network. We identify the shortcomings of this model and implement a multi-stage hierarchical end-to-end network that solves the shortcomings of BiDAF.
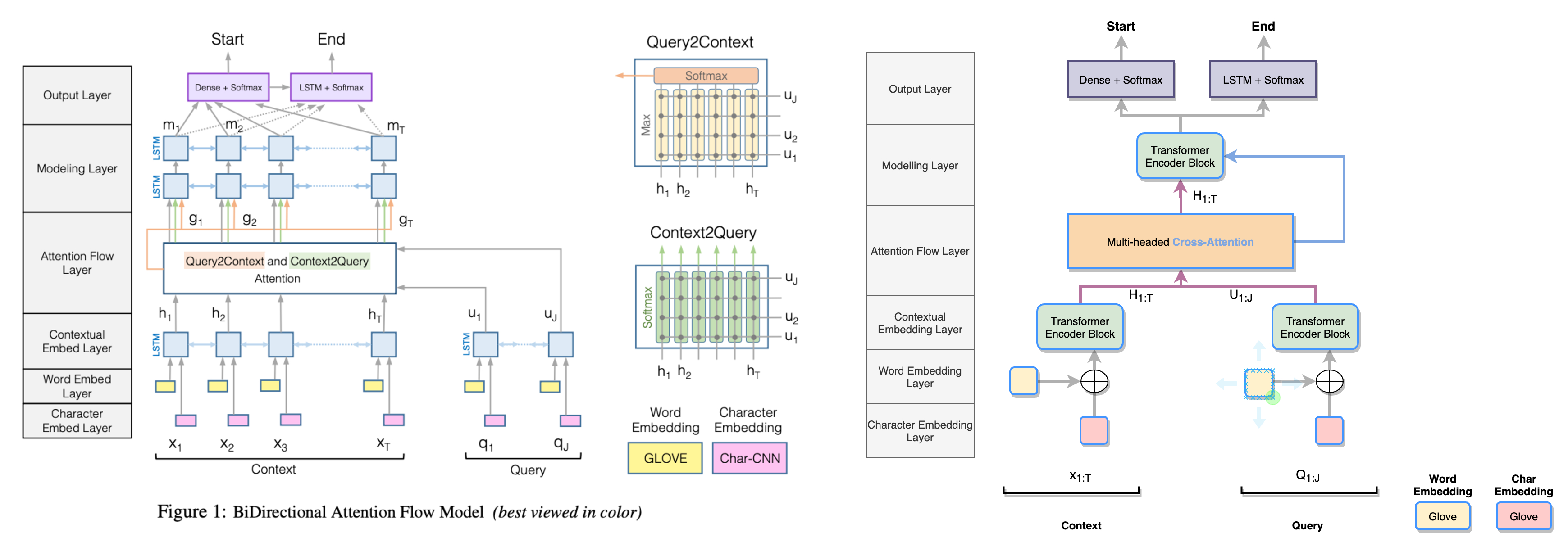
More specifically, the original model uses a sequence-to-sequence network like RNN to encode information of query/context into a vector. Even though RNNs' are known to be quite effective, they have few huge bottlenecks, namely, non-parallelizability of the network due to its seq-to-seq/time-step based computation, lack of transfer learning support, and vulnerability to vanishing/exploding gradient. We handle these shortcomings of RNN by replacing them with transformer encoders.
Additionally, we implement few recent techniques to improve the vanilla encoder network, namely, Spatial Positional Encoding instead of traditional Absolute Positional Encoding, ScaleNorm instead of traditional LayerNorm, Feedforward Network with Gated Linear Unit instead of traditional Feedforward Network with RELU.
Looking outside RNN, we replace the query-to-context and context-to-query Attention flow with Cross-Attention using a Multi-headed Attention mechanism. We show that multi-headed Cross-Attention works better than the traditional Attention Flow layer.
Finally, we introduce pre-trained character embedding vectors that were extrapolated from the existing Glove pre-trained word embeddings. We also show that this improves the baseline BiDAF model by a considerable amount.
Lastly, we show the results of our final model on the validation set and compare its performance with the baseline BiDAF model. Evidently, we can observe that our model is performing better than the original BiDAF in terms of latency, and accuracy. Our Model is also highly extensible since we use encoders and multi-head attention and they don't suffer from traditional seq-to-seq bottlenecks and are available to the use of transfer learning.