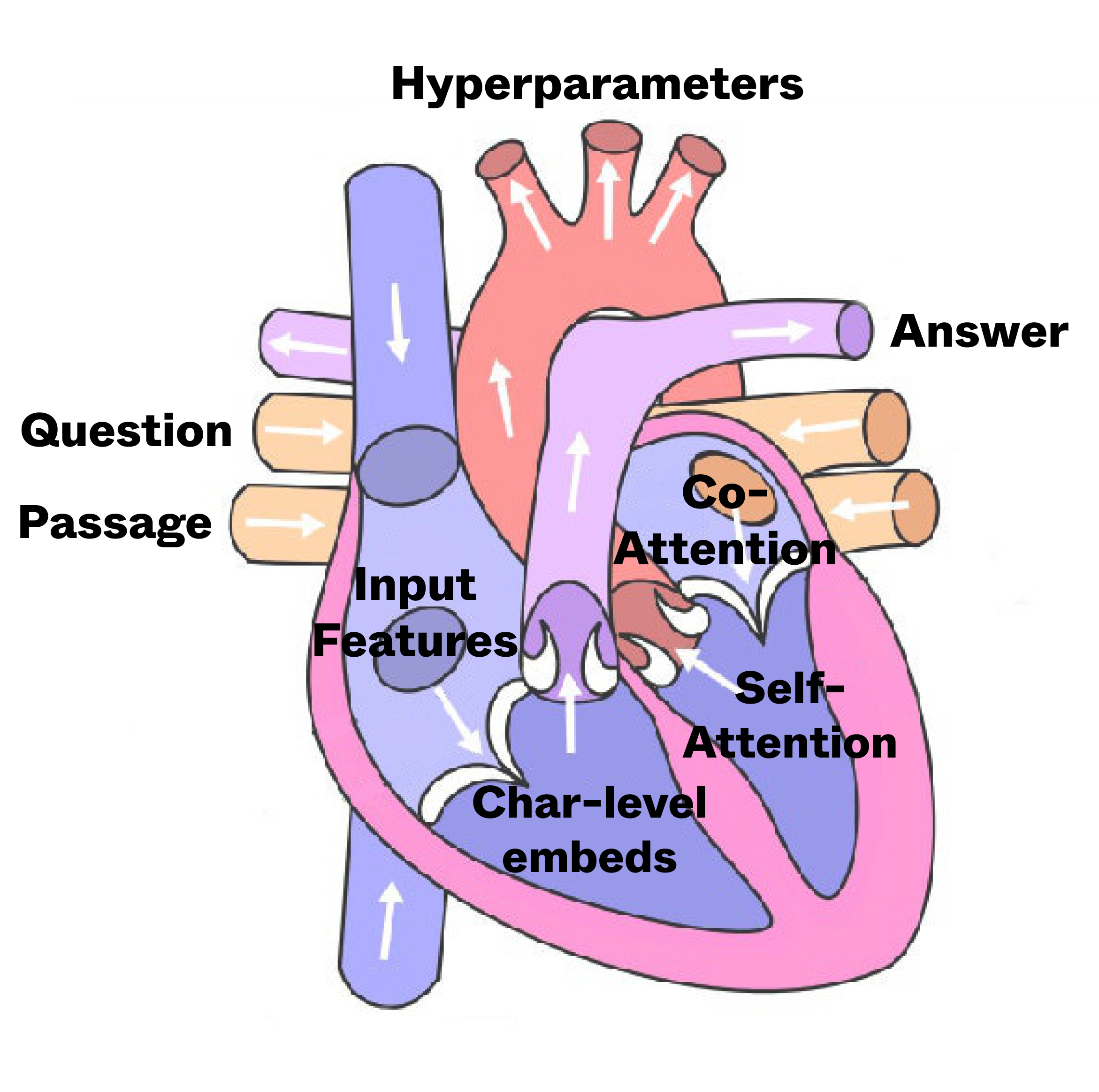
Embedding and Attending: Two Hearts that Beat as One
Neural attention mechanisms have proven to be effective at leveraging relevant tokens of the input data to more accurately predict output words. Moreover, incorporating additional embedding information significantly boosts performance and provides greater granularity of tokens at the character and word level. For these reasons, we focused on implementing various models that concern primarily the embedding layer and attention layers. In our project, we implemented three different attention mechanisms (co-attention from Dynamic Coattention Networks, key-query-value self-attention, and R-Net self-attention) in the domain of the Question-Answering (QA) paradigm. Our goal was to produce a model that is highly performant compared to the baseline BiDAF model on the Stanford Questioning Answering Dataset (SQuAD 2.0). We combined these attention mechanisms with character-level embeddings to provide more local contextual information, and finally enhanced these embeddings by including additional input features (part-of-speech and lemmatized forms of words). Lastly, we conducted a series of hyperparameter tuning experiments to determine the ideal hyperparameters that result in the greatest F1/EM scores. Augmenting the baseline with these techniques produced a significant improvement compared to the baseline. Our most performant model obtained an F1 score of 65.27 and EM score of 61.77 (an increase of 5.6% and 5.5%, respectively).