Investigating the effectiveness of Transformers and Performers on SQuAD 2.0
In this project, I explored aspects of the Transformer architecture in the context of question answering on SQuAD 2.0, the Stanford Question Answering Dataset. I split this exploration into several phases, which built upon each other.
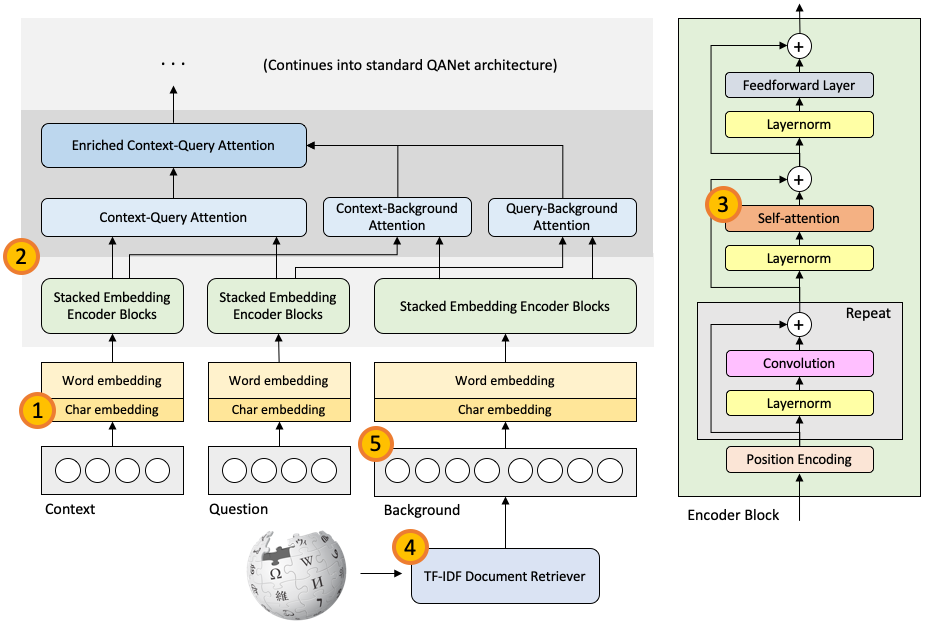
In Phase 1, I gained familiarity with the default baseline (based on BiDAF, a recurrent LSTM-based algorithm) by upgrading it to support character-level embeddings, in addition to the existing word-level embeddings. This resulted in a 2-point performance increase on all scoring metrics.
In Phase 2, I incrementally refactored the baseline from BiDAF into QANet, a question answering architecture which is similar in structure but uses convolution and Transformers instead of recurrent neural networks. After hyperparameter tuning, I found this improved performance by an additional 3.5 points on all scoring metrics.
In Phase 3, I replaced the Transformer with an architectural variant, the Performer, which aims to solve the issue of quadratic scaling in vanilla Transformers'runtime and memory usage by using kernel methods to approximate the self-attention calculation. I found that this was effective within QANet, enabling linear scaling from hundreds to tens of thousands of tokens, with minimal impact to performance.
In Phase 4, I prepared to make use of this scale to support open-domain question answering. I wrote a TF-IDF based document retriever, which returned the most similar Wikipedia page to the current context passage. I found this to be reasonably effective in locating similar passages.
Finally, in Phase 5, I fed this new input into QANet via a new, large Background input, which supplemented the existing Context and Question inputs. I upgraded QANet to support this by adding a Context-Background attention and a Query-Background attention layer to the current Context-Query attention layer. This appears to start training correctly, with training and validation loss both decreasing over time.