DA-Bert: Achieving Question-Answering Robustness via Data Augmentation
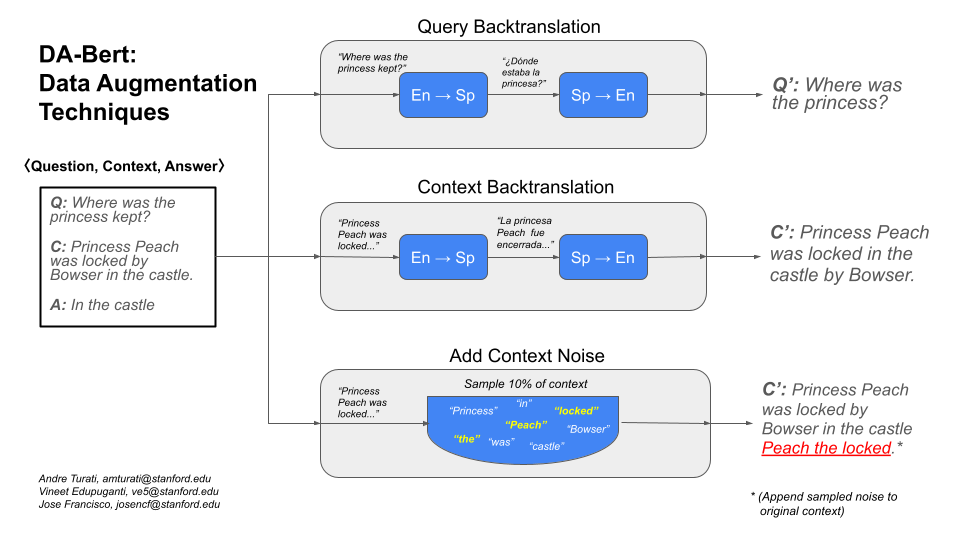
Pretrained models are the basis for modern NLP Question-Answering tasks; however, even state-of-the-art models are heavily influenced by the datasets they were trained on and don't generalize well to out-of-domain data. One avenue for improvement is augmenting the training dataset to include new patterns that may help the model generalize outside of its original dataset. In this paper, we explore improving model robustness in the question-answering task, where we have a query, a context (i.e. passage), and an answer span that selects a portion of the context. We utilize various data augmentation techniques including adding noise to our contexts and backtranslating (translating text to a pivot language and then back) both the queries and contexts. We find that leveraging the technique of backtranslation on the queries, both on in-domain and out-of-domain training datasets, greatly improves model robustness and gives a 3.7% increase in F1 scores over our baseline model without data augmentation. Further, within this approach of backtranslation, we explore the linguistic effect of particular pivot languages and find that using Spanish adds the greatest robustness to our model. We theorize that Spanish and potentially other Romance languages' linguistic similarity to English gives clearer and more helpful translations than other high-resource languages with different roots.