Domain-Adversarial Training For Robust Question-Answering
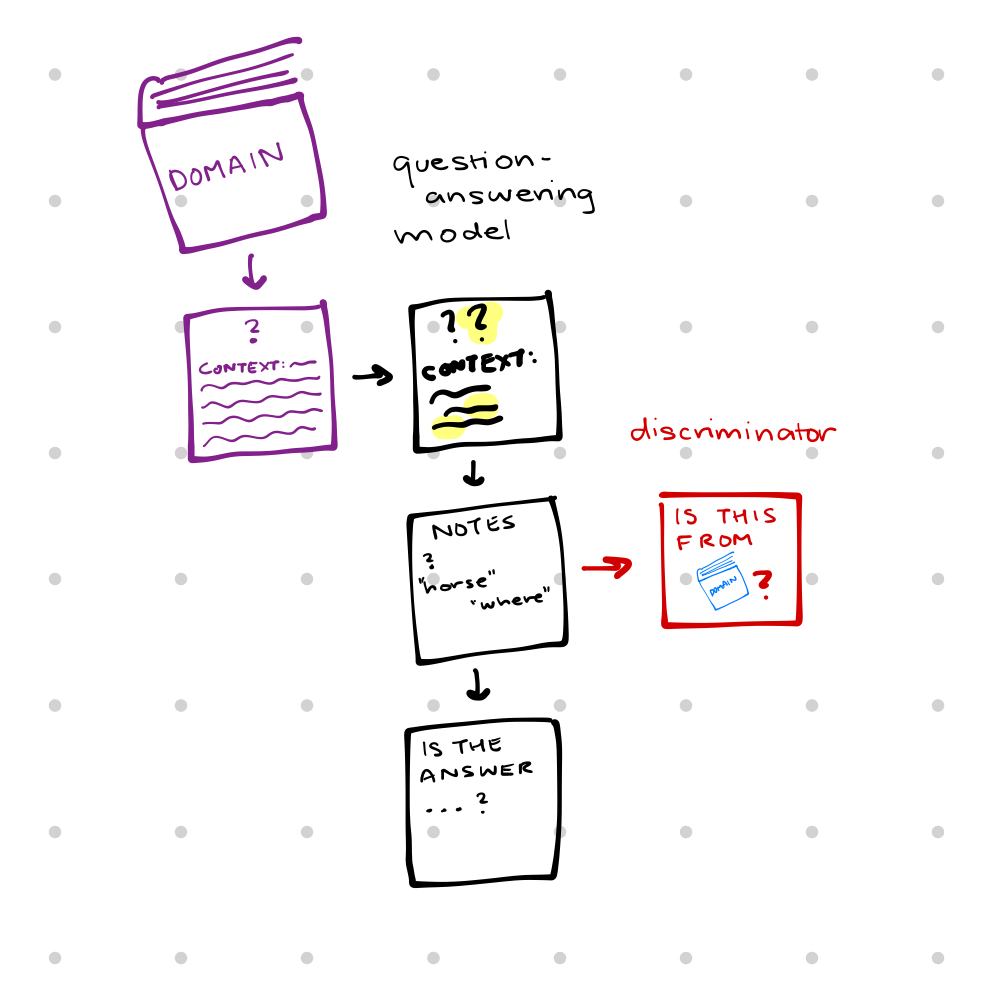
In this project, we created a domain-adversarial model to improve upon the baseline DistilBERT model on the task of robustly answering reading comprehension questions across domains. The way the adversarial model works is by creating a discriminator, which is trained to decide based on the last layer of our question-answering model which domain the question came from. Then, our question answering model is trying to not only answer questions correctly but also to trick the discriminator as much as possible, which forces it to prioritize features of the question and context which are not domain-specific in this final hidden layer. Our model got an EM score of 41.353 and F1 score of 59.803 on the test set.