Sesame Street Ensemble: A Mixture of DistiIBERT Experts
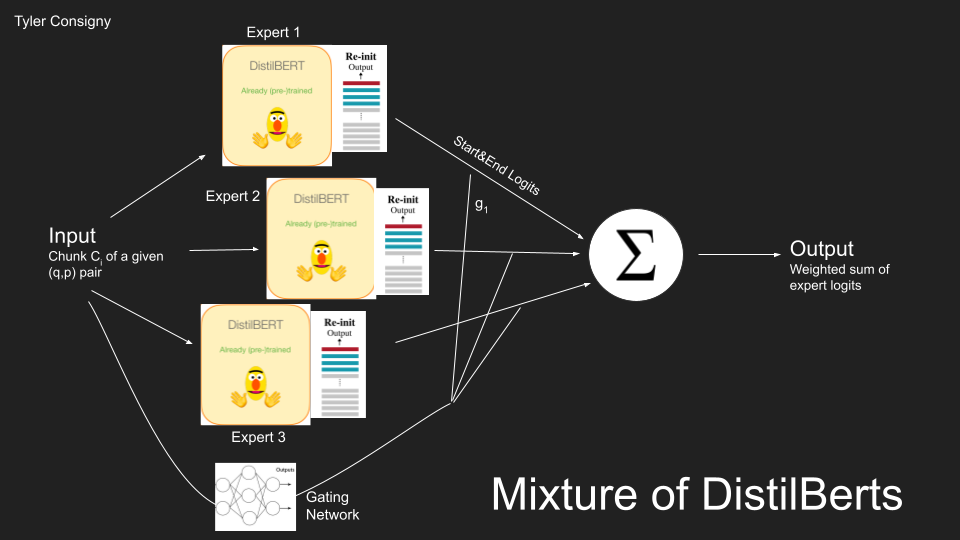
In this project, I attempt to finetune a pre-trained DistilBERT model to better handle an out of domain QA task. As there are only a few training examples from these outside domains, I had to utilize various techniques to create more robust performance: 1) implemented a mixture of local experts architecture and 2) finetuned a number of hyperparameters to perform best over this few shot learning task. Specifically, a separate DistilBERT model was finetuned on each of the in-domain datasets to act as an expert. The finetuning approaches focused on reinitializing a variable amount of final transformer blocks and training for a longer period. These two approaches were then synthesized to produce the final model. The results were negative. I speculate that this is because the domains covered by the experts were too distinct from that of the out-of-domain datasets. In future work, I would like to use data analysis to group similar training examples (across predefined datasets) to hopefully lead to more focused experts.