Improving the Robustness of QA Systems through Data Augmentation and Mixture of Experts
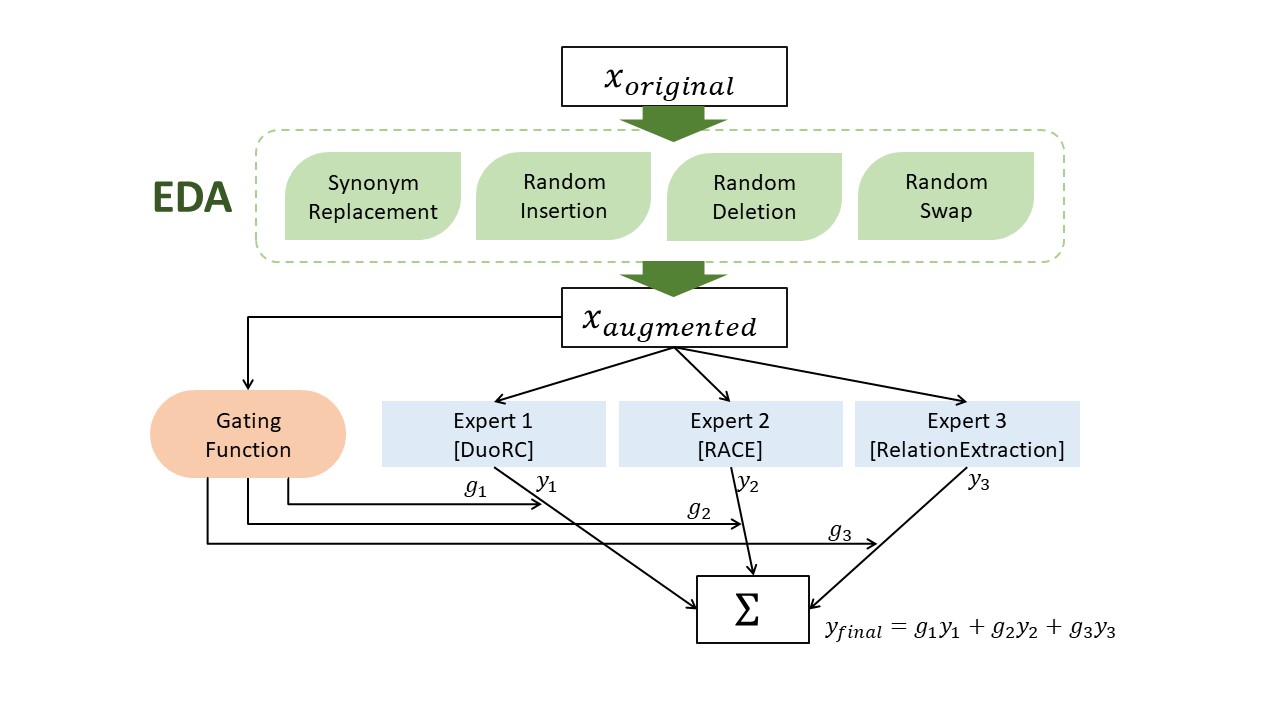
Despite the stunning achievements of question answering (QA) systems in recent years, existing neural models tend to fail when they generalize beyond the in-domain distributions. This project seeks to improve the robustness of these QA systems to unseen domains through a combination of Easy Data Augmentation (EDA) and Mixture of Experts (MoE) techniques. As baseline, we finetuned a pre-trained DistilBERT model with Natural Questions, NewsQA and SQuAD datasets using the default configurations and evaluated the model performance on the out-of-domain datasets, including RelationExtraction, DuoRC, and RACE. After obtaining our second baseline by including a small number of training examples from our out-of-domain datasets, we ran two rounds of hyperparameters tuning through random search. Based on the best performing set of hyperparameters, we then augmented our out-of-domain datasets using the EDA techniques and analyzed the effects of each technique through a series of experiments. Finally, we implemented an MoE model with three experts and a two-layer bi-directional LSTM followed by a linear layer as the gating function. Both the data augmentation technique and the mixture-of-expert approach demonstrated capability to improve the robustness of DistilBERT-based QA systems, and a combination of the two methods brings even further improvement. The combined approach increased the F1 and EM scores on the dev set by 15.03% and 14.87%, respectively, compared to the baseline, and achieved an F1 score of 62.062 and an EM score of 42.317 on the test leaderboard.