Towards a Robust Question Answering System through Domain-adaptive Pretraining and Data Augmentation
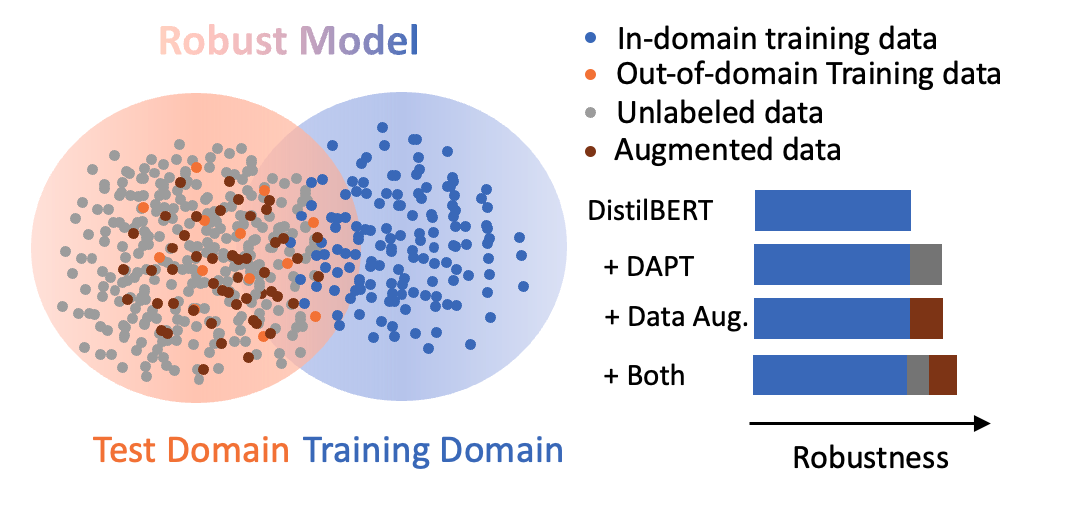
Large pretrained language models have shown great success over a bunch of tasks in the past few years. These large language models are trained on enormous corpus, and it now becomes a question whether they are robust to domain shift. We find in this paper that the domain of question answering (QA) problems has significant impact on the performance of these fine-tuned LMs and these fine-tuned QA models are still sensitive to domain shift during test time. This potentially causes problems in many real-word applications where broad or evolving domains are involved. So, how can we improve model robustness? In this paper, we offer two potential solutions. First, we propose to continue pretraining on the objective domains. This second-phase of pretraining helps model focus on information that is relevant to the problem. We find that domain-adaptive pretraining helps improve out-of-domain test performance. In some cases, we might have additional small amount of training data on the test domain. We propose to use data augmentation tricks to maximally utilize these data for domain adaptation purpose. We find that data augmentation tricks, including synonym replacement, random insertion and random deletion, can further improve the performance on out-of-domain test samples. Our work shows that the improvements in performance from domain-adaptive pretraining and data augmentation are additive. With both methods applied, our model achieves a test performance of 60.731 in F1 score and 42.248 in EM score. The experiments and methods discussed in this paper will contribute to a deeper understanding of LMs and efforts towards building a more robust QA system.