QA System Using Feature Engineering and Self-Attention (IID SQuAD track)
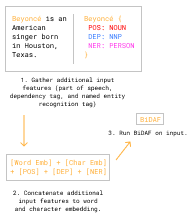
Machine reading comprehension is an exceedingly important task in NLP and is a desired feature in many of the latest consumer and research projects. Therefore, using this task as motivation, we set out to build a reading comprehension model that performed well on the SQuAD 2.0 question answering dataset. To do this, we built upon the existing BiDAF machine comprehension model given to us through the CS224n staff. Our contributions to this model are a character embedding layer on top of the existing word embedding layer, a self attention layer, and added features to the character and word embeddings which include Part of Speech tags (POS), named entity recognition (NER) tags, and dependency tags. As a result of implementing these layers we found that character embedding with additional input features performed the best with an F1 dev score of 64.38 and an EM dev score 61.29. On the test set we achieved F1 and EM scores 62.17 and 59.04 respectively.