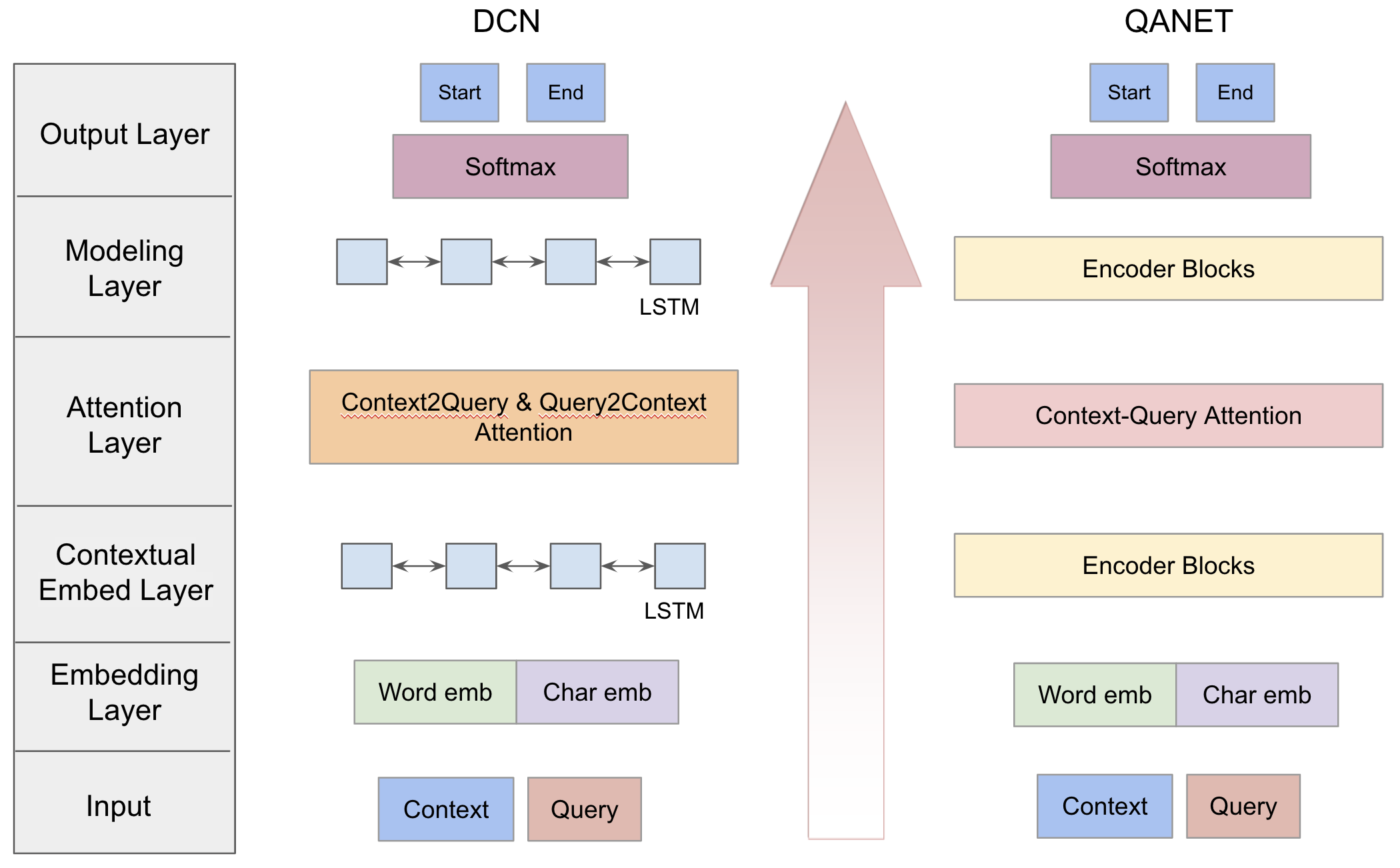
Coattention, Dynamic Pointing Decoders & QANet for Question Answering
The task of question answering (QA) requires language comprehension and modeling the complex interaction between the context and the query. Recurrent models achieved good results using RNNs to process sequential inputs and attention components to cope with long term interactions. However, recurrent QA models have two main weaknesses. First, due to the single-pass nature of the decoder step, models have issues recovering from incorrect local maxima. Second, due to the sequential nature of RNNs these models are often too slow for both training and inference. To address the first problems, we implemented a model based on Dynamic Coattention Network (DCN) that incorporates a dynamic decoder that iteratively predicts the answer span. To improve the model efficiency, we also implemented a transformer based recurrency-free model (QANet), which consists of a stack of encoder blocks including self-attention and convolutional layers. On the Stanford Question Answering Dataset (SQuAD 2.0), our best QANet based model achieves 68.76 F1 score and 65.081 Exact Match(EM) on dev set and 66.00 F1 and 62.67 EM on the test set. A high level model comparison of DCN and QANet is illustrated in the image.