Robust Question Answering Through Data Augmentation and TAPT
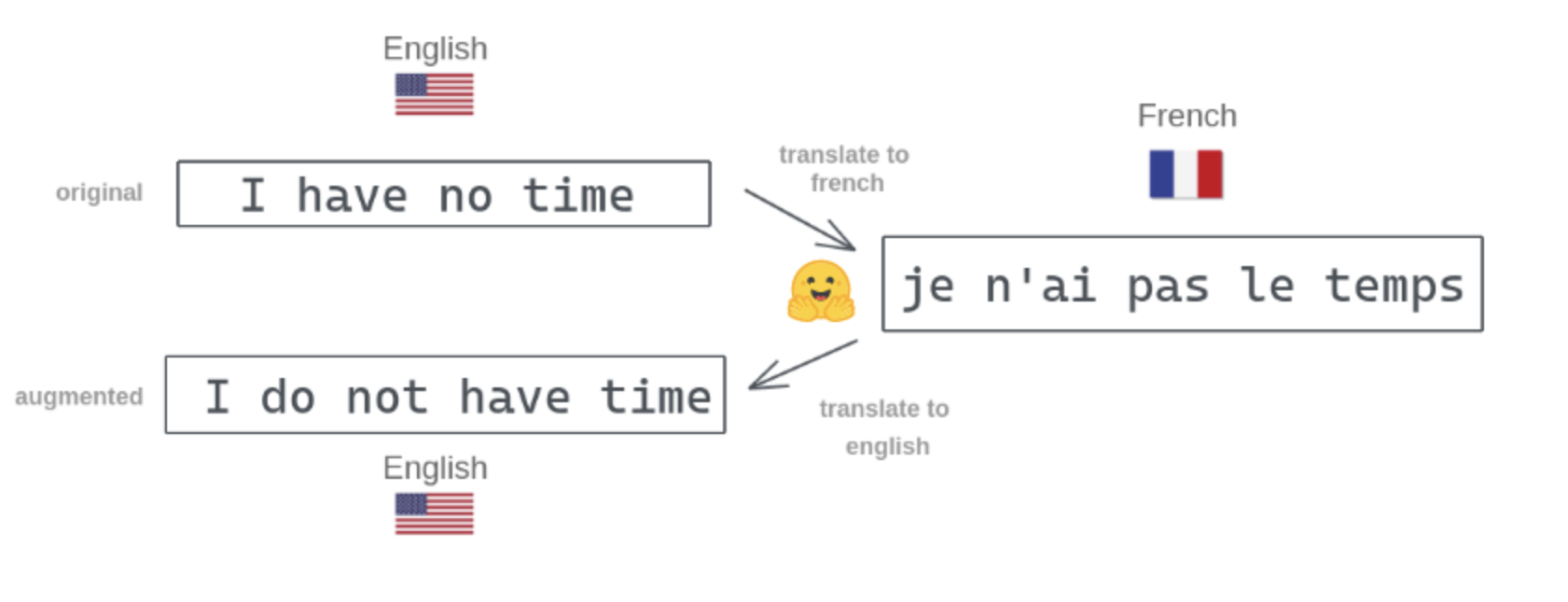
In this project, we aimed to improve on the given baseline model, which is a DistilBERT pretained transformer, as much as possible in order to make it more robust to out-of-domain data for the task of QA. In order to do this, we experimented with a variety of extensions to the baseline, among which are Task-Adaptive Pretraining and data augmentation. We found that data augmentation was able to improve the results of the baseline the best out of our various attempts. Our best model performed better than the baseline by 0.287 points for the F1 score and 0.941 points for the EM score on the test set.