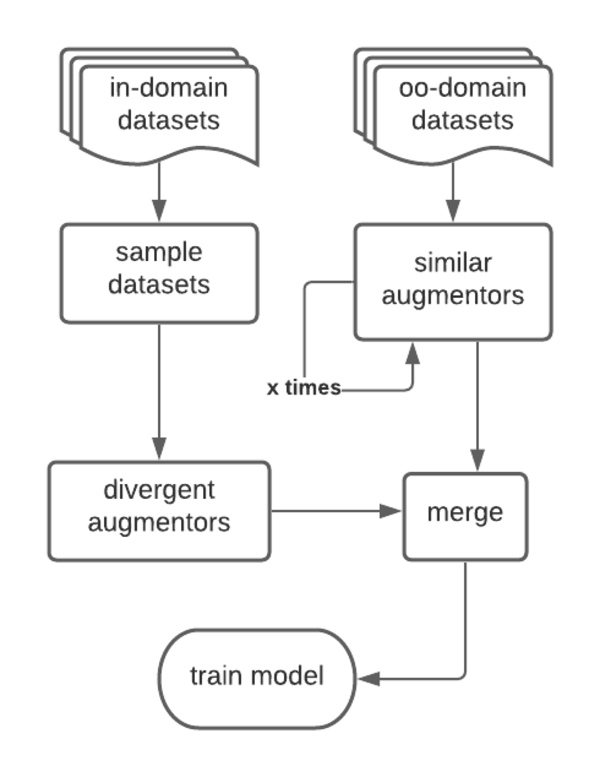
In this project, we identify the trade-off between different data augmentation strategies for Robust QA System. For in-domain datasets, we need to sample the datasets first to avoid overfitting and then use more advanced data augmentation techniques, such as back-translation and abstract summary augmentation, to generate more diverge datasets in order to help the model learn the unseen data. For out-of-domain datasets, we need to use data augmentation technique that could generate similar datasets, such as spelling augmentation and synonym augmentation. Also, we need to iterate the data augmentation for multiple times in order to increase the proportion of out-of-domain datasets. The iteration number needs to be carefully designed because it may also slightly affect the final performance of the Robust QA System.