Multi-Task Learning and Domain-Specific Models to Improve Robustness of QA System
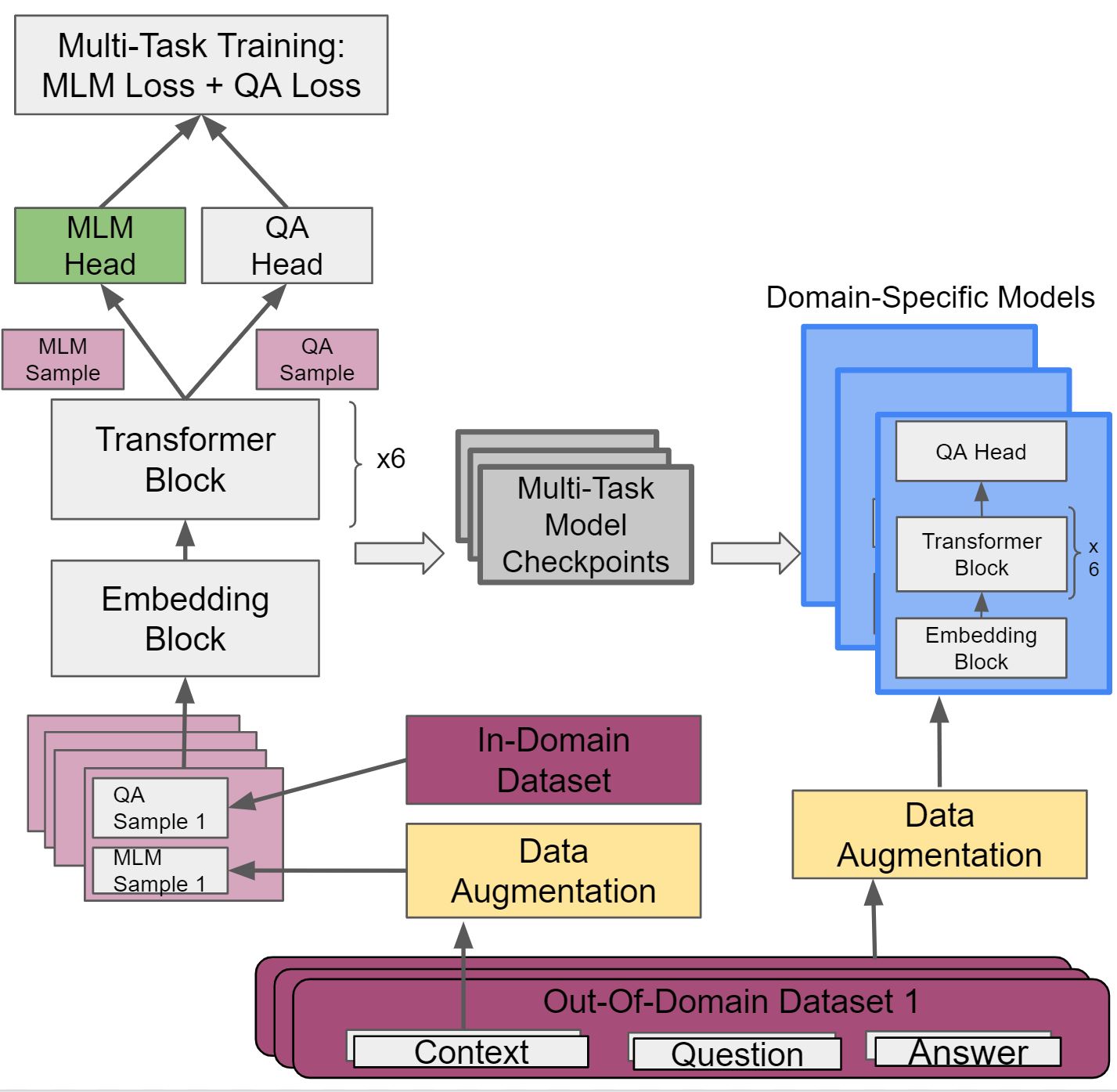
In CS224N course project, we develop a Robust Question Answering (QA) language model that works well on low resource out-of-domain (OOD) data from three domains. Our approach is to take the pre-trained DistilBERT model on high-resource in-domain dataset and then perform multi-task training. We implement multi-task training model that uses unlabeled text from OOD data for Masked Language Model Objective as well as labeled QA data from high-resource setting. The model jointly trains on unlabeled text and QA data to preserve the QA representation from high-resource data and adapt to low-resource OOD. We also explore data augmentation techniques such as synonym replacement, random word deletions and insertions, word swapping, and back-translation to expand our out-of-domain dataset. Finally, we use Domain-Specific Models to have separate models for different datasets and observe that we get the best result on different datasets using different strategies. As a result we achieved the score of 59.203 F1 and 42.362 EM on the test set, 54.41 F1 and 41.62 EM on the validation set.