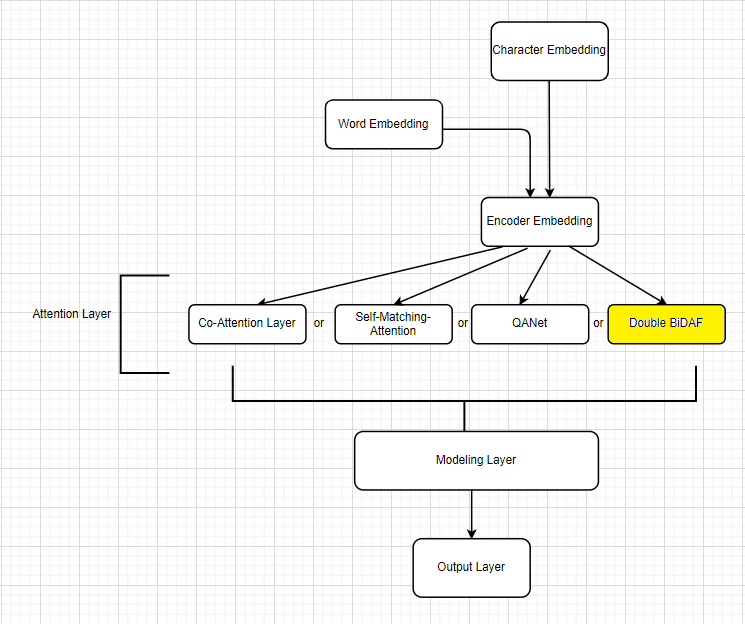
In order to improve our baseline model, we have experimented many approaches and methods. We have started by adding a "Character Embedding Layer", which allows us to condition on the internal morphology of words and better handle out-of-vocabulary words. Then we have focused on improving our attention layer by trying different approaches.
We developed a "Co-Attention Flow Layer", which involves a second-level attention computation, attending over representations that are themselves attention outputs. Furthermore, we added a "Self-Matching-Attention" from the R-Net consisting on extracting evidence from the whole passage according to the current passage word and question information. Besides, we experimented an idea from the "QANet" by adapting ideas from the Transformer and applying them to question answering, doing away with RNNs and replacing them entirely with self-attention and convolution. Then, we tried a new idea consisting on adding another BiDAF layer, this layer accounts not only for the interactions between the context and question and for the ones within the context. We wanted some-how to account also for the Context-to-Context interaction, this is will provide valuable information about the co-dependence between different words in the context.
To put this idea into practice we have added another BiDAF layer performing a self-attention process like the one between the context and the query. The input to this layer will be the representation we get from the first BiDAF attention layer and the words context representations we get from the first encoder. The output of this layer will successfully account not only for the interactions between the context and question and for the ones within the context. This is the model that provided the highest score. We have also being experimenting with additional gates and nonlinearities applied to the summary vector after the attention step. These gates and nonlinearities enable the model to focus on important parts of the attention vector for each word.
Our devised model "Double BiDAF" achieved the best score of 63.03 on the validation set. This is exceptional because we have only made a small change to the model architecture and it yielded such improvement.