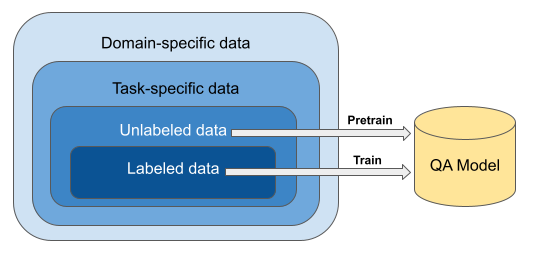
It is often hard to find a lot of labeled data to train a QA (question answering) model.
One possible approach to overcome this challenge is to use TAPT (task-adaptive
pretraining) in which the model is pretrained further using the unlabeled data from
the task itself. We implement the TAPT technique to make a QA model perform
robustly on a task with low-resource training data by first pertaining on the larger unlabeled data set. We then fine tune the model with a smaller labeled dataset. The results are mixed. Although a preliminary model that is pretrained on just the out-of-domain train data performed better than the baseline, additional pretraining using more out-of-domain data performed worse than expected.