Mixture of Experts and Back-Translation to improve QA robustness
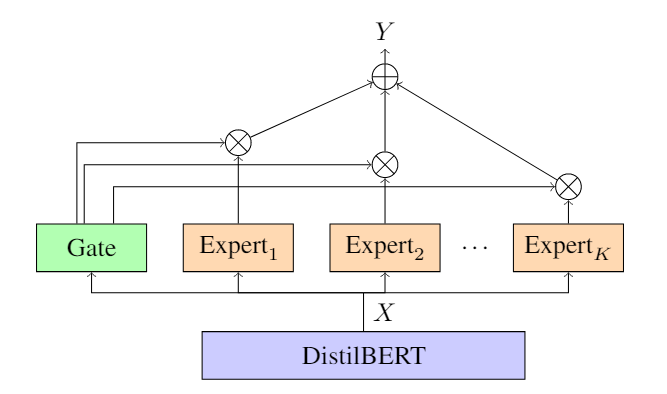
This work improves the generalization of a DistilBERT-based Question Answering (QA) model with the addition of a Mixture of Experts (MoE) layer as well as through data augmentation via back-translation. QA models generally struggle to perform in contexts that differ from those present in the model's training data. As a step towards addressing this limitation, our MoE implementation effectively learns domain-invariant features without explicitly training each expert on individual subdomains. We also apply top-k sampling back-translation and introduce a new technique to more effectively retrieve the answer span from the back-translated context. We find that the addition of the MoE layer yields an improvement of 3.19 in F1 score on an out-of-domain validation set, with back-translation granting a further 1.75 in F1 score. This represents a net improvement of 10.1% over the DistilBERT baseline.