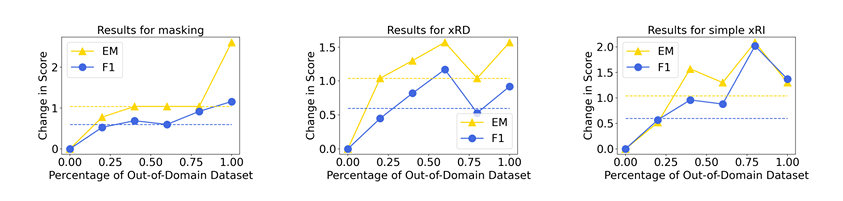
We present xEDA: extended easy data augmentation techniques for boosting the robustness of question answering systems to shifts in data domains. xEDA extends existing data augmentation techniques by drawing inspirations from techniques in computer vision. We evaluate its performance on out-of-domain question answering tasks and show that xEDA can improve performance and robustness to domain shifts when a small subset of the out-of-domain data is available at train time. xEDA consists of masking, extended random deletion, extended random insertion, and simple extended random insertion. We discovered that xEDA can help build a question answering system that is robust to shifts in domain distributions if few samples of out-of-domain datasets are available at train time. In particular, by applying xEDA to out-of-domain datasets during training, we were able to increase the performance of our question answering system by 6.1% in terms of F1 and by 14.9% in terms of EM when compared to the provided baseline on the dev set. Moreover, using 40% of the out-of-domain train datasets augmented via xEDA achieved the same performance as using 100% of the out-of-domain train datasets. Our analysis also suggests that an augmented data of smaller size may lead to better performance than non-augmented data of larger size in some cases. Given the simplicity and wide applicability of xEDA, we hope that this paper motivates researchers and practitioners to explore data augmentation techniques in complex NLP tasks.