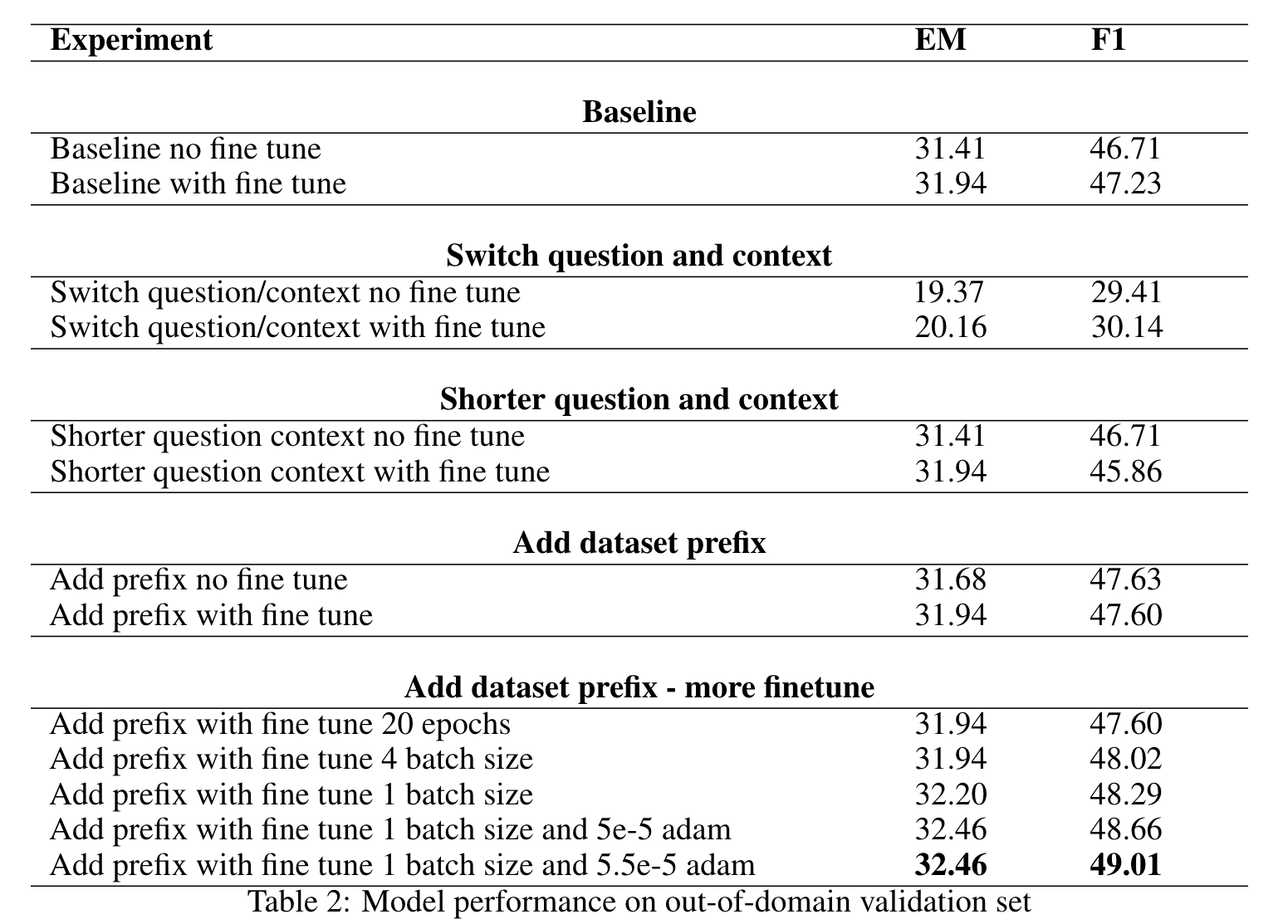
Robust QA on out of domain dataset over pretraining and fine tuning
We have seen tremendous progress on natural language understanding problems over the last few years. Meanwhile, we face issues that models learnt from a specific domain couldn't be easily generalized to a different domain. I explored different models to build robust question answering system that can be applied to out-of-domain datasets. Models explored are baseline with and without fine tuning, adding dataset prefix in question with and without fine tuning, switching question and context in question answering system with and without fine tuning, and shorter question and context in model input with and without fine tuning. Different fine tuning techniques like changing epochs, batch size and Adam optimization learning rate were explored to find the best model performance. The best model achieved 40.367 EM and 58.467 F1.