Meta Learning with Data Augmentation for Robust Out-of-domain Question Answering
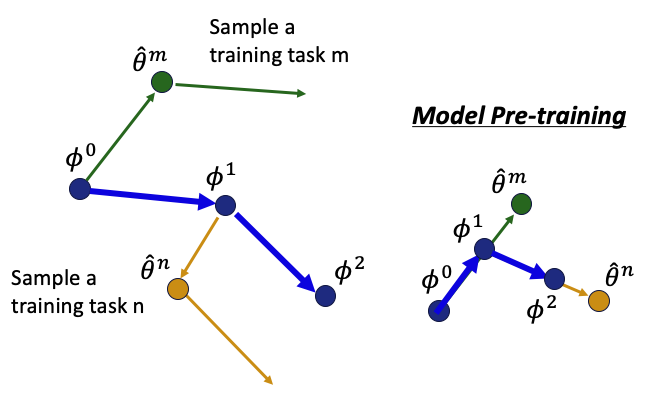
Natural language understanding problems has gain much popularity over the yearsand current models often has poor generalizability on the out-of-domain tasks. This robust question answering (QA) project aims to remedy this situation by using Reptile, a variant of meta learning algorithms. In this project, the primary goal is to implement Reptile algorithm for question answering tasks to achieve a better performance than the baseline model on the out-of-domain datasets. After the Reptile implementation is validated, the secondary goal of this project is to explore how various hyper parameters affect the final performance. After we believe that the Reptile is optimally tuned, we worked on the data provided for this project. First, we merged in-domain validation dataset to the training data, then we added data augmentation to further tap into the potential of the out-of-domain training data. Training results of Reptile outperforms vanilla BERT model and Reptile with data augmentation increases the score even further. The best F1 score is 59.985 and best EM score is 42.225. If we compare the performance on out-of-domain validation dataset, scores are more than 12% and 22% higher than the baseline score respectively.