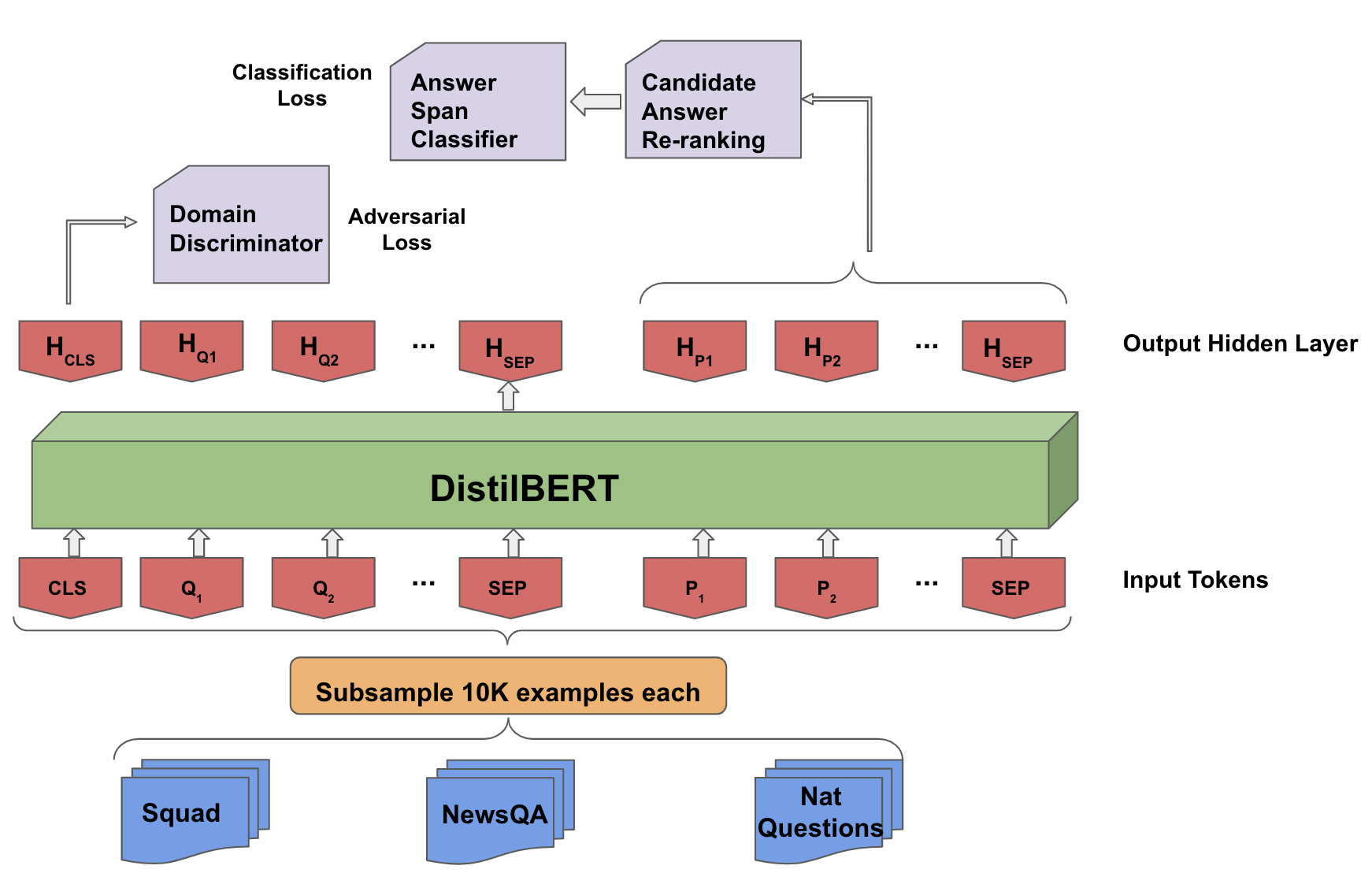
In the NLP task of question-answering, state-of-the-art models perform extraordinarily well, at human performance levels. However, these models tend to learn domain specific features from the training data, and consequently perform poorly on other domain test data. In order to mend this issue, we adopt the adversarial training approach to learn domain invariant features in existing QA models. In this approach, the QA model tries to learn hidden features that the discriminator, which tries to classify the domain of the question-answer embedding from the hidden features, unsure of its prediction, thereby learning domain-invariant features. The intuition is that if the QA model can confuse the discriminator, then the features it has learned are not easily attributable to a specific domain. The QA model's loss depends on its own errors in answer prediction (the QA loss) as well as how well the discriminator predicts domain (the adversarial loss). We study modifications this model, in particular the impact of weights on the adversarial loss on the model's performance. We also study other techniques such as data augmentation and answer re-ranking in order to make our model more robust. Our work is limited in that we only train models on a subset of the training data available to us due to the cost of training time. However, we can conclude that changing the weight of the adversarial model results in marginal changes in performance. Furthermore, although the adversarial model exhibits improvements over our baseline, data augmentation proves to be a more effective technique in making the model robust on our of domain data given the subsampled training data.