QaN I have Your Attention? Exploring Attention in Question-Answering Model Architectures
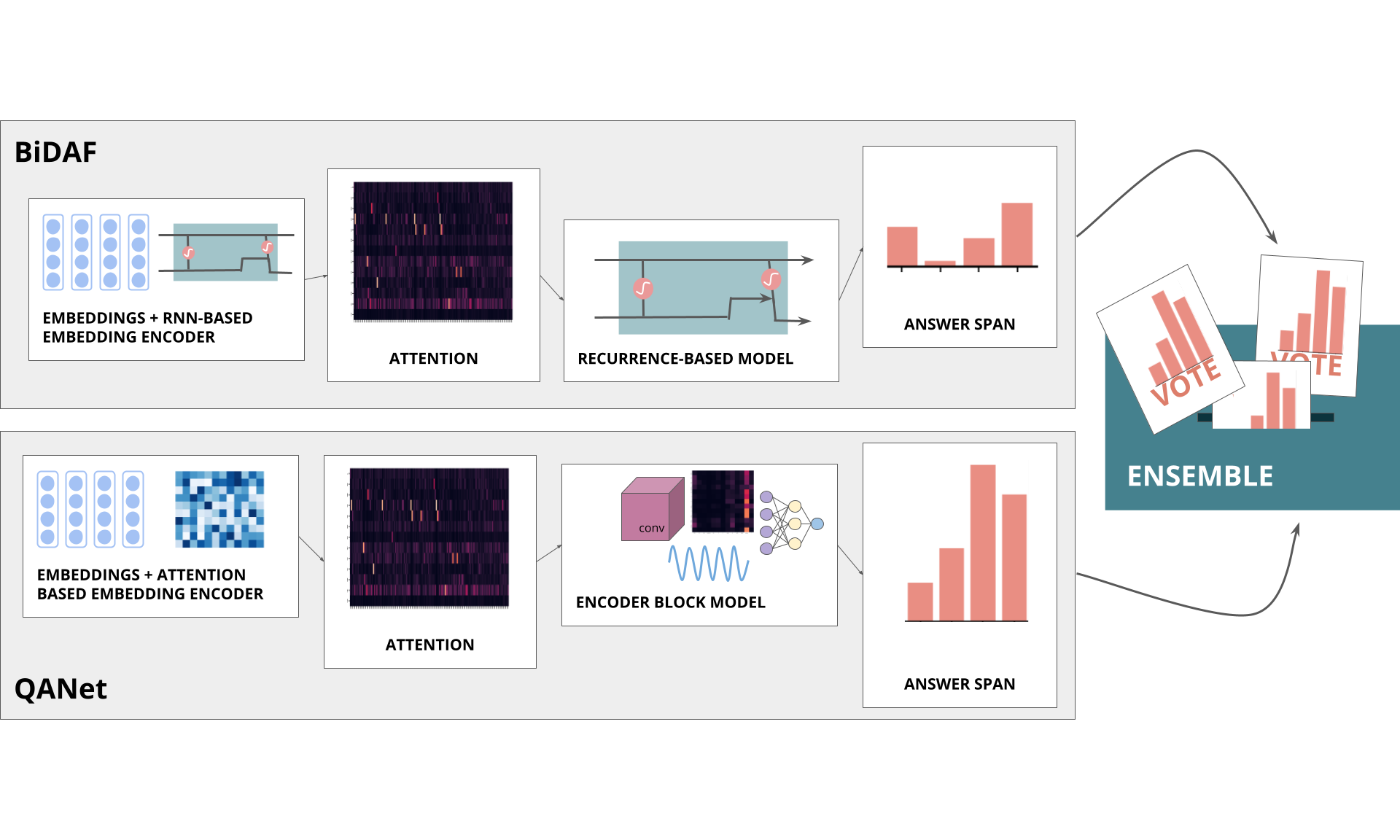
In this project, we build non-pre-trained models for the question-answering task on the Stanford Question Answering (SQuAD) 2.0 dataset, exploring on the effect of attention on the result. We explore the performance of deep learning model architectures that utilize attention: BiDAF (context-query attention), Dynamic Co-Attention (second-level attention) and QANet (self-attention). We explored the baseline BiDAF model, and improved it through character embeddings and co-attention, as well as re-implemented QANet. We ensembled results, and obtained highest performance of F1 67.96, EM 64.41 for single model dev, F1 70.66, EM 67.87 for ensemble dev, and F1 68.39, EM 65.44 for ensemble test. We performed analysis on the single model and ensembles to better understand the model mechanisms and performance.