Robust Question Answering via In-domain Adversarial Training and Out-domain Data Augmentation
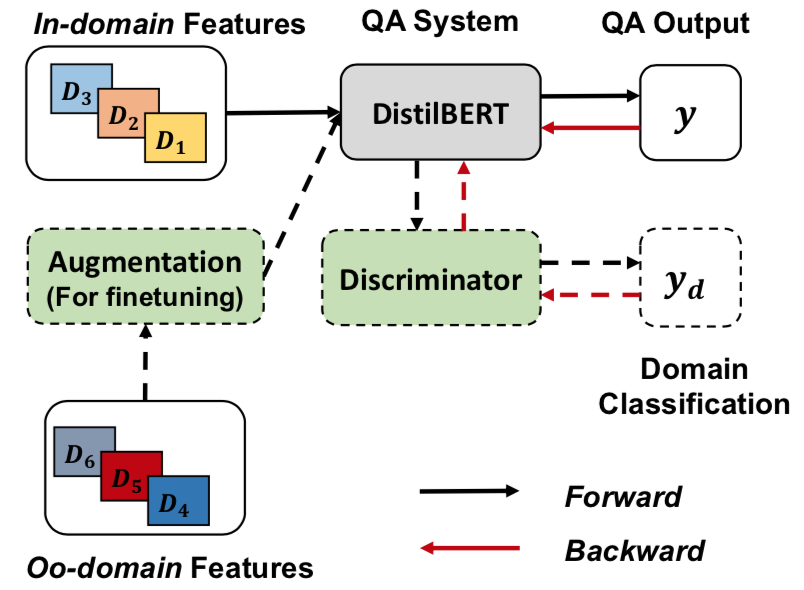
How can a Question Answering model trained on Wikipedia solve examination questions correctly? The cross-domain Question Answering is challenging since QA models are usually not robust to generalize well on out-of-domain datasets. We would like to explore the effectiveness of domain-related information on QA model robustness. We leverage potential domain information, both domain-specific and domain-invariant, from the text data. During training on the in-domain training set, we explore the adversarial training by experimenting on three adversarial functions. We add a domain classifier to distinguish different domains. Meanwhile, the QA model fools the domain discriminator to learn domain-invariant feature representations from the in-domain training set. In addition to the domain-invariant learning from the in-domain training, we also propose a data augmentation method that can retain high-level domain information by using named entity recognition and synonyms replacement. Out -of-domain datasets are insufficient and we want to utilize them most. This augmentation method is applied on the oo-domain training set and we suppose that it will let the model learn domain specific information from the out-of-domain datasets. To give better insights on our adversarial training and augmentation methods, we conducted several experiments and provide our analysis in this report.