More Explorations with Adversarial Training in Building Robust QA System
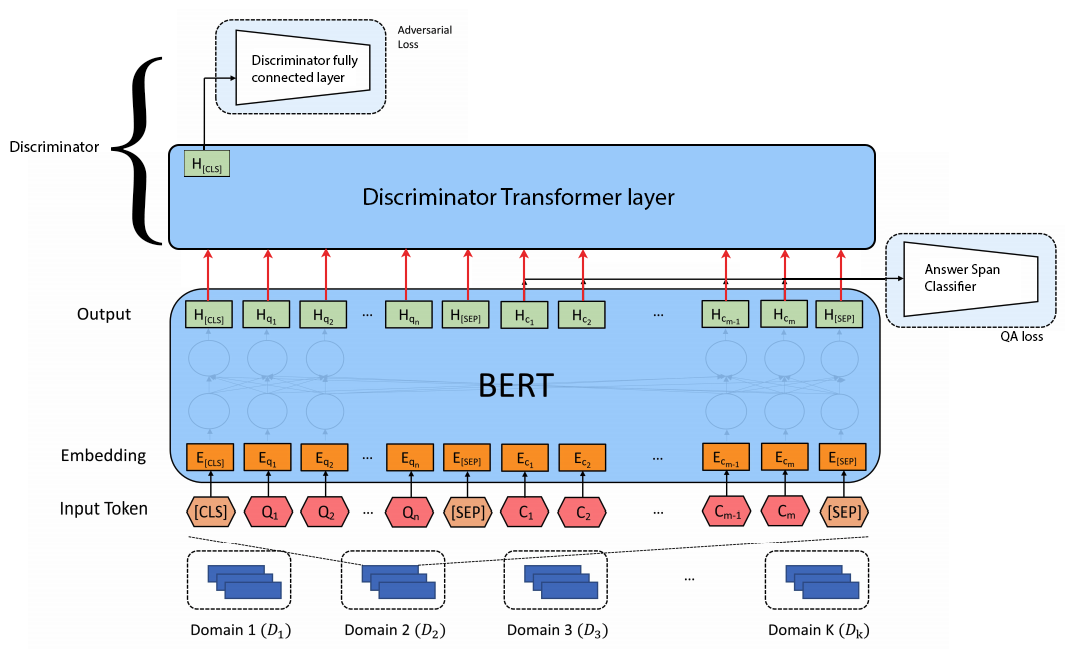
In real world Question Answering (QA) applications, a model is usually required to generalize to unseen domains. It was found that an Adversarial Training framework where a conventional QA model trained to deceive a domain predicting discriminator can help learn domain-invariant features that generalize better. In this work we explored more discriminator architectures. We showed that by using a single layer Transformer encoder as the discriminator and taking the whole last layer hidden states from the QA model, the system performs better than the originally proposed simple Multilayer Perceptron (MLP) discriminator taking only the hidden state at the [CLS] token of the BERT QA model.