Probability-Mixing: Semi-Supervised Learning in Question-Answering with Data Augmentation
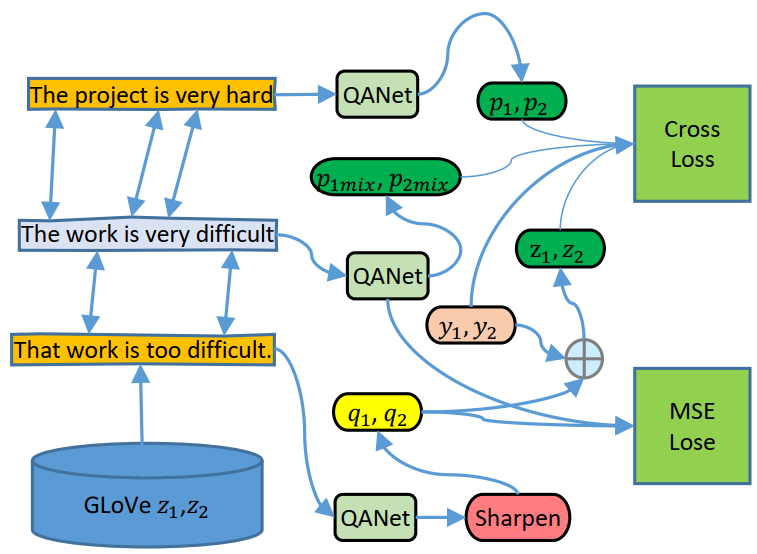
The probability-Mixing method proposed in this project consists label guessing and label interpolation. : We need to prepare three types of data for this semi-supervised problem: labeled data, mixed data, and unlabeled data. If we have labeled data "The project is too hard". We first use GLoVE to find similar words and replace them with something like "That work is super difficult", which is our unlabeled data. Then for each word, we randomly select either from word from both data and have "That work is too difficult". Then we can linearly interpolate the labels for the mixed data for both mean square loss and cross-entropy loss. In this project, our experiments demonstrate that sequential order information does not necessarily help query-context matching, and excessive sequential order information in BiDAF's RNN can lead to overfitting. To alleviate overfitting and add more variety to the training samples, we propose four data augmentation methods without introducing non-negligible label noise, which improves the F1 scores of BiDAF and the QANet with 8 heads by at least 2 points. We also propose the Probability-Mixing method to prevent the model from memorizing the context, which significantly improves its ability in query-context matching. This method reduces the FPR from 0.3 to 0.18 and increases F1(TP) by 4 points for the QANet model, making it a much better model in preventing the generation of misleading information for the question-answering system.