Self-attention and convolution for question answering on SQuAD 2.0: revisiting QANet
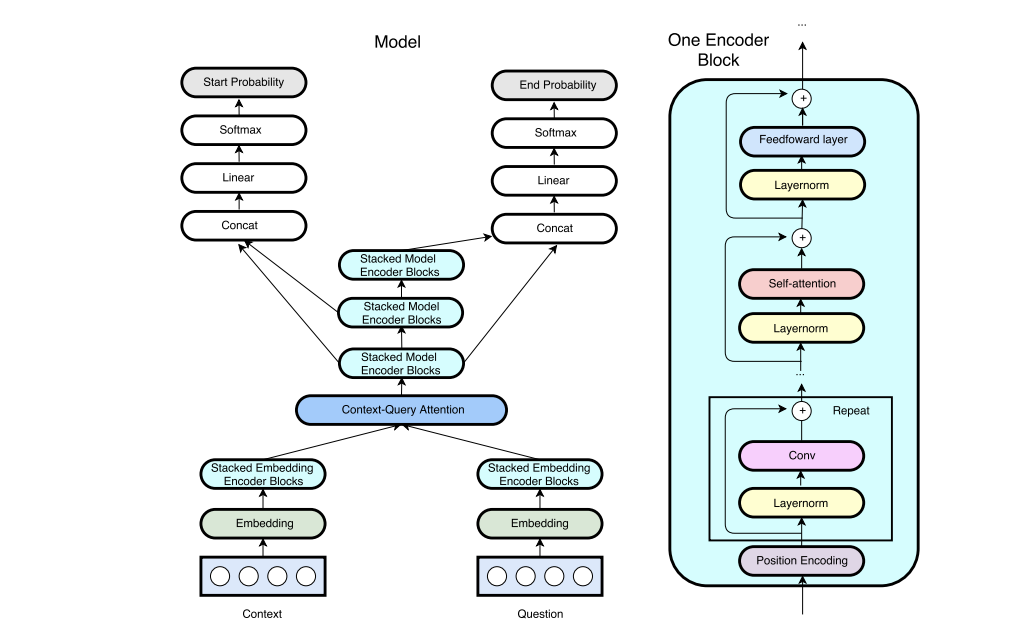
QANet was the first Question Answering model that combined self-attention and convolution, without any use of Recurrent Neural Networks. Convinced by the "Attention is all you need" motto (or, more accurately in this context, the "You don't need RNNs" motto), we were naturally interested in seeing how this applies to the specific task of Question Answering. In this project, we therefore tackle the Question Answering task on the SQuAD 2.0 dataset using different variations of the QANet architecture. We first re-implement the QANet model, and then explore different versions of the architecture, tweaking some parameters such as attention mechanisms and model size. We then propose 3 ensemble models with different inference methods: our best model, using a novel two-step answerability prediction based inference method, achieves 71.21 F1/ 68.14 EM on the development set, and 69.04 F1 / 65.87 EM on the test set.