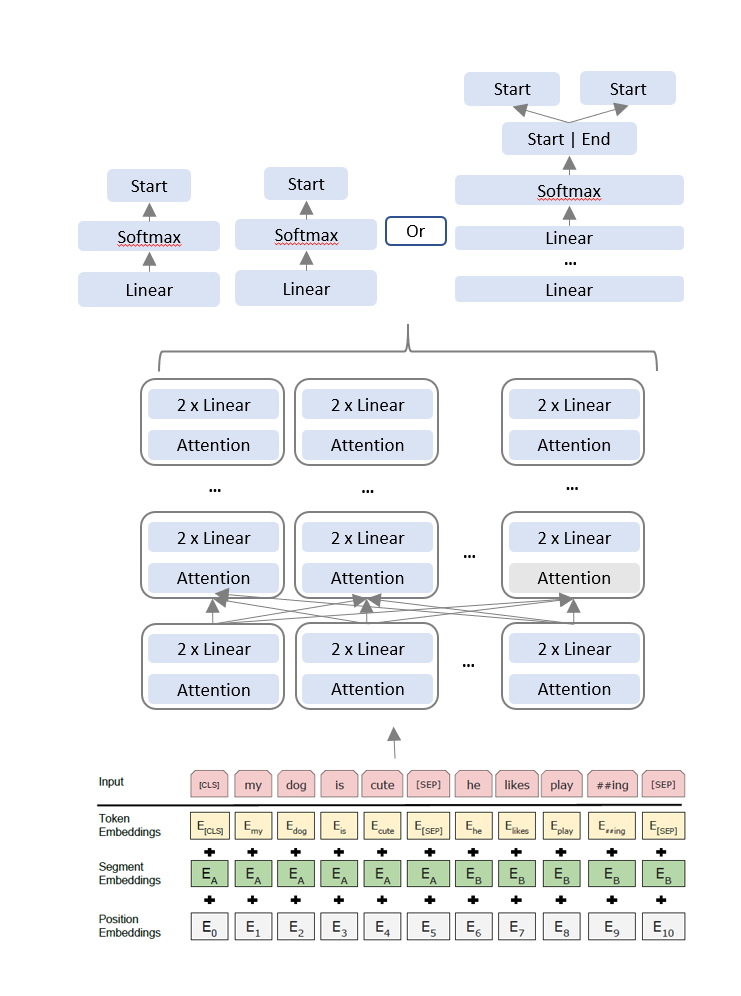
Exploration of Attention and Transformers for Question and Answering
The project was intended to be an exploration of convBERT model without pretraining,
but after training a base BERT model (encoder only Transformer) and
achieving very low performance, the objective shifted towards trying to understanding
transformers and attention for Question Answering. Experiments on both
hyperparameters and network architecture was done on the BERT model, with
conclusion that this model will either overfit, or not converge. A hypothesis is
suggested that without large corpus pretraining, simple self attention on a concatenated
context and question has big difficiencies vs explicit cross attention to learn
SQuAD. QAnet model was also trained for purposes of comparisons and analysis.