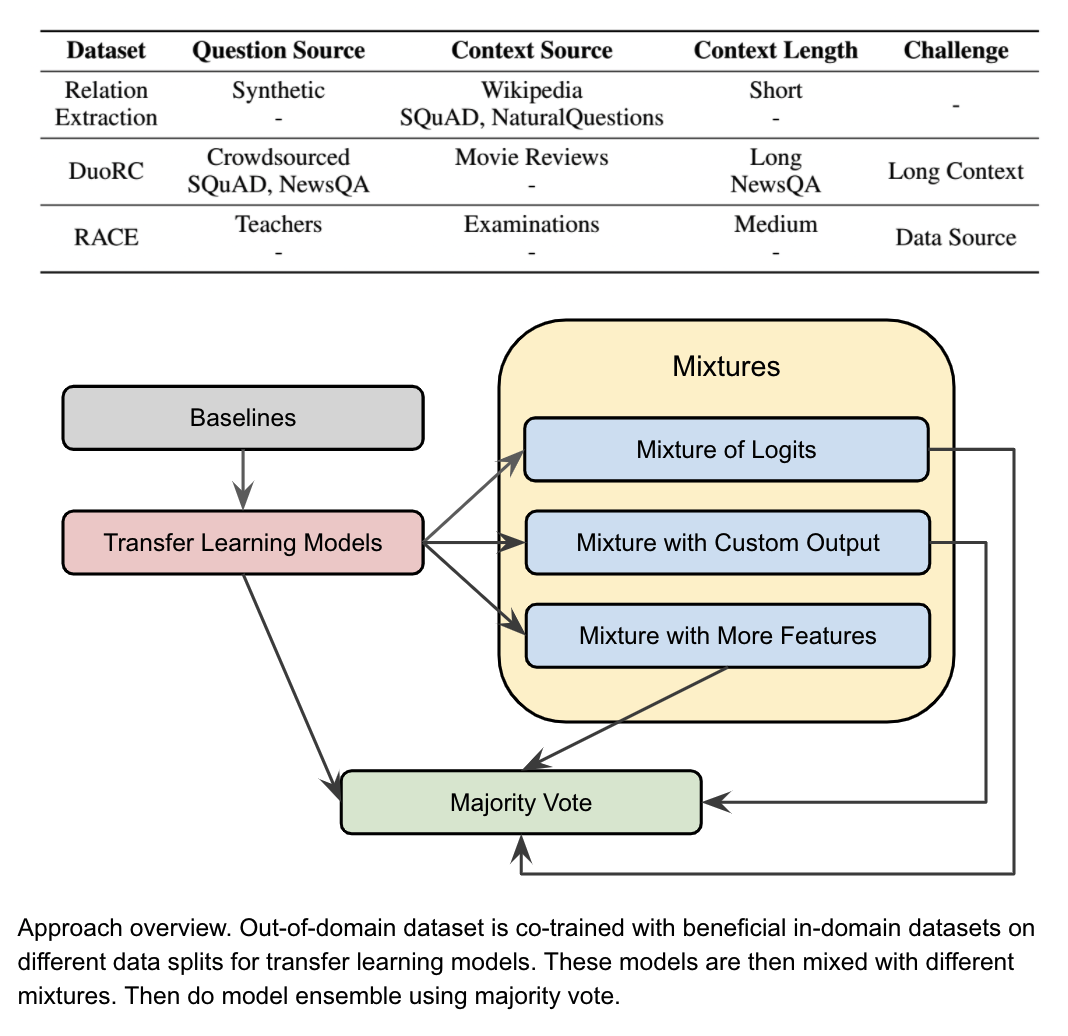
The robustness to domain shifts is very important for NLP, as in real world, test data are rarely IID with training data. This NLP task is to explore a Question Answering system that is robust to unseen domains with few training samples. In this task, three out-of-domain datasets show very different characteristics and they are trained with different in-domain datasets which are more beneficial for their challenges. Multiple transfer learning models are mixed in different ways: mixture of logits, mixture with custom output, and mixture with more features. Three majority vote strategies were taken to ensemble the models.