Attention-aware attention (A^3): combining coattention and self-attention for question answering
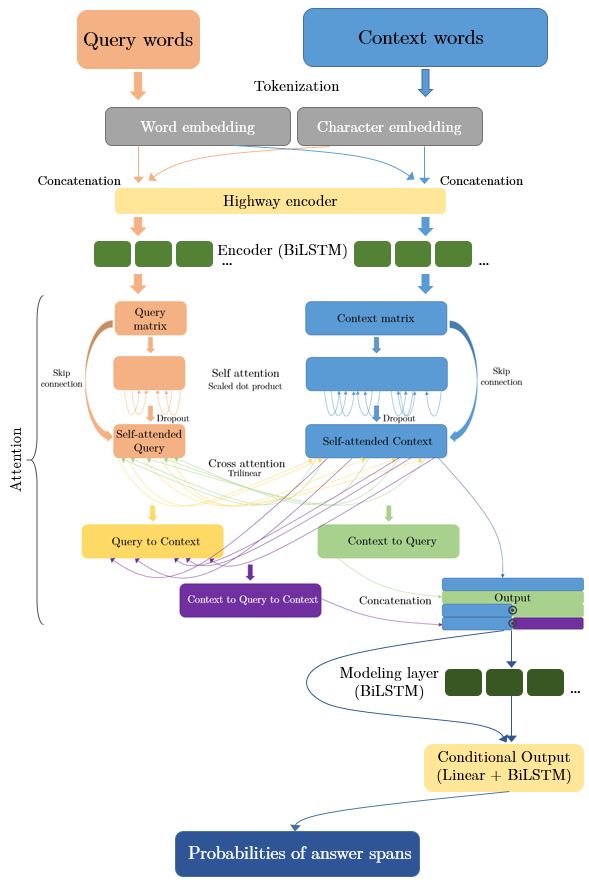
Attention has been one of the biggest recent breakthrough in NLP, paving the way for the improvement of state-of-art models in many tasks. In question answering, it has been successfully applied under many forms, especially with recurrent models (encoder-decoder fashion). Co-attention and multihead self-attention have been two interesting attention variations, but a larger study trying to combine them has never been conducted to the best of our knowledge. Hence, the purpose of this paper is to experiment different attention-based architecture types for question answering, as variations from one of the first successful recurrent encoder-decoder models for this task: BiDAF. We implement a variation of the attention layer, starting with a multi-head self-attention mechanism, on both the query and the context tokens separately, as provided by the encoder layer. Then, these contextualized tokens, added to the input tokens through a skip connection, are passed to a trilinear cross-attention and used to compute two matrices: a context to query matrix and a context to query to context matrix. These two matrices are concatenated with the self-attended context tokens into an output matrix. In addition, we provide our model a character embedding, which proves to have an important positive impact on the performance, as well as a conditional output layer. We test the performance of our model on the Stanford Question Answering Dataset 2.0 and achieved a performance of EM = 62.730 and F1 = 66.283 on the dev set, and EM = 60.490 and F1 = 64.081 on the test set. This provides +7.26 EM score and +6.95 F1 score compared to our coattention baseline, and +4.72 EM score and +4.97 F1 score compared to our BiDAF baseline.