Multi-Phase Adaptive Pretraining on DistilBERT for Compact Domain Adaptation
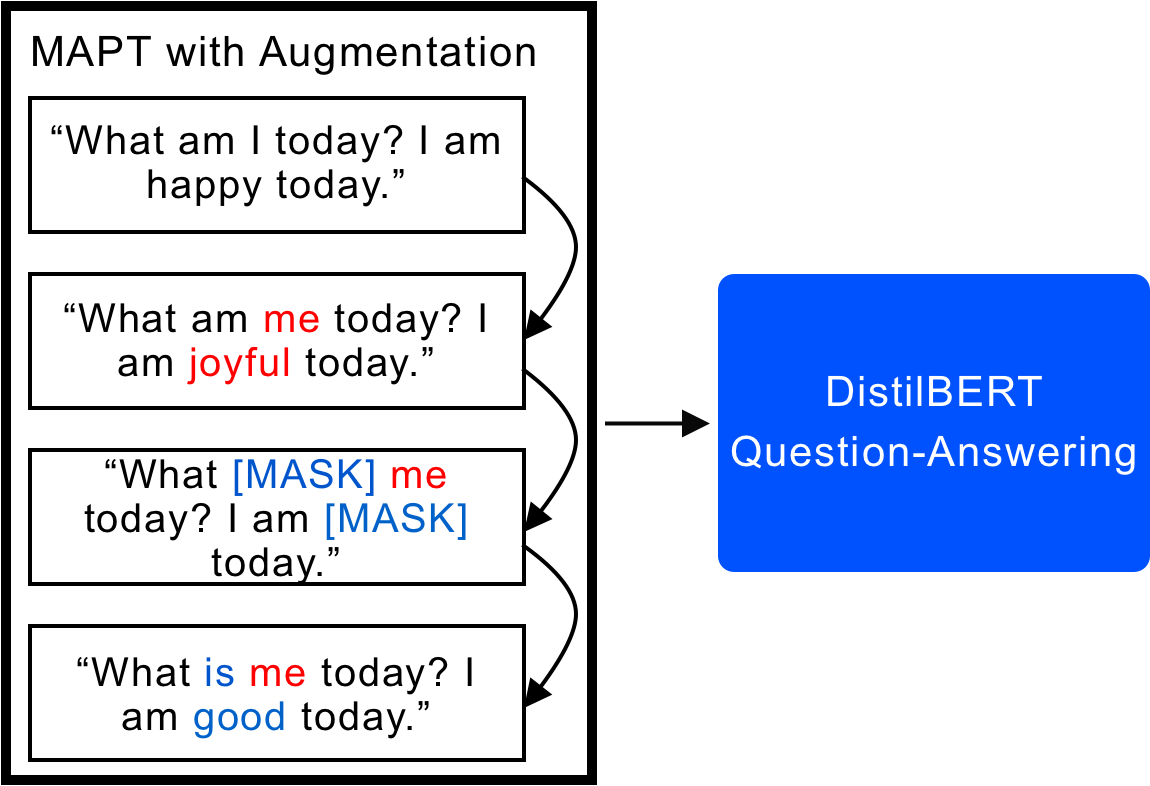
While modern natural language models such as transformers have made significant leaps in performance relative to their predecessors, the fact that they are so large usually means that they learn small correlations that do not improve the model's predictive power. As a result, such models fail to generalize to other data, thus hampering performance in real-world cases where data is not independently and identically distributed (IID). Luckily, the use of domain-adaptive pretraining (DAPT), which involves pretraining on unlabeled target domain data, and task-adaptive pretraining (TAPT), which entails pretraining on all of the unlabeled data of a given task, can dramatically improve performance on large models like RoBERTa when the original and target domain distributions have a small amount of overlap. Consistent with the Robust QA track of the default project, this report investigates and tests the hypothesis that TAPT in tandem with DAPT (also known as multi-phase adaptive pretraining, or MAPT) can improve performance on the target domain for smaller transformers like DistilBERT on the question answering task, especially in the presence of domain shift. The final results show that the use of TAPT can lead to a slight increase in Exact Match (EM) performance without DAPT. However, implementing DAPT, even with the use of word-substitution data augmentation, significantly degrades the performance of the model on the held-out target domain dataset.