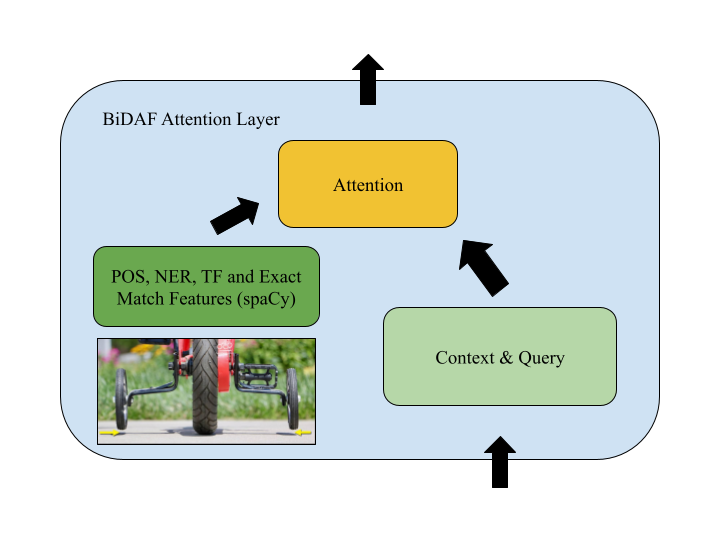
The DrQA document reader showed that adding per-token features (e.g. part-of speech and named entity recognition tags) to a question answering model significantly improves performance on the SQuAD benchmark. I add six features to a baseline BiDAF model and explore the benefit of applying attention to not only LSTM hidden state, but also these per-token features. I verify the benefit of applying self-attention to these features and find that the augmented model significantly improves upon the baseline in terms of metrics and train time. My best model achieves a test score of (62.06 EM, 64.89 F1) compared to a baseline of (59.33, 62.09), reaching an optimal model in half the training steps.