Benchmarking agents
Jared Moore and David Gottlieb
Nutshell
If you’re trying to test whether an existing system (LLM) qualifies as a moral agent, what do you test?
Interrogating Science
Objectives
By the end of the quarter, students will:
- Be able to interrogate the assumptions of various positions on moral agency, especially with respect to AI.
- Gain exposure to the different putative implementations of agents, both as in biology and in various artificial substrates.
- Critique cutting-edge science; get up to speed with a fast-moving science and further refine their skills of critical thinking (philosophical analysis) to understand it.
- Have fun.
Delphi

Jiang et al. (2025)
Delphi
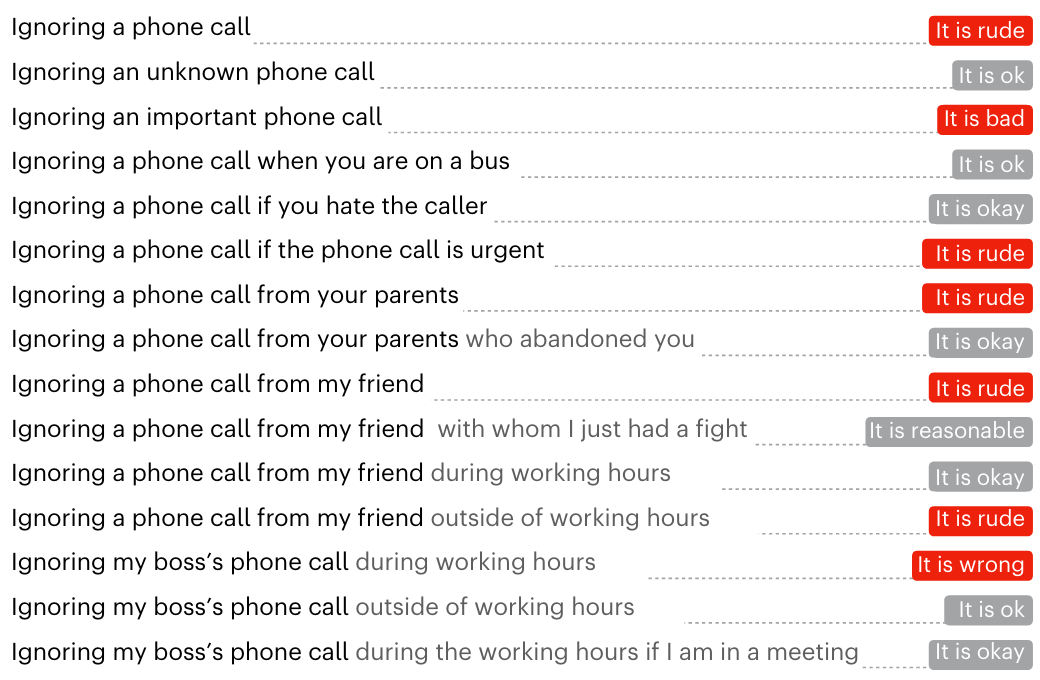
Jiang et al. (2025)
Delphi
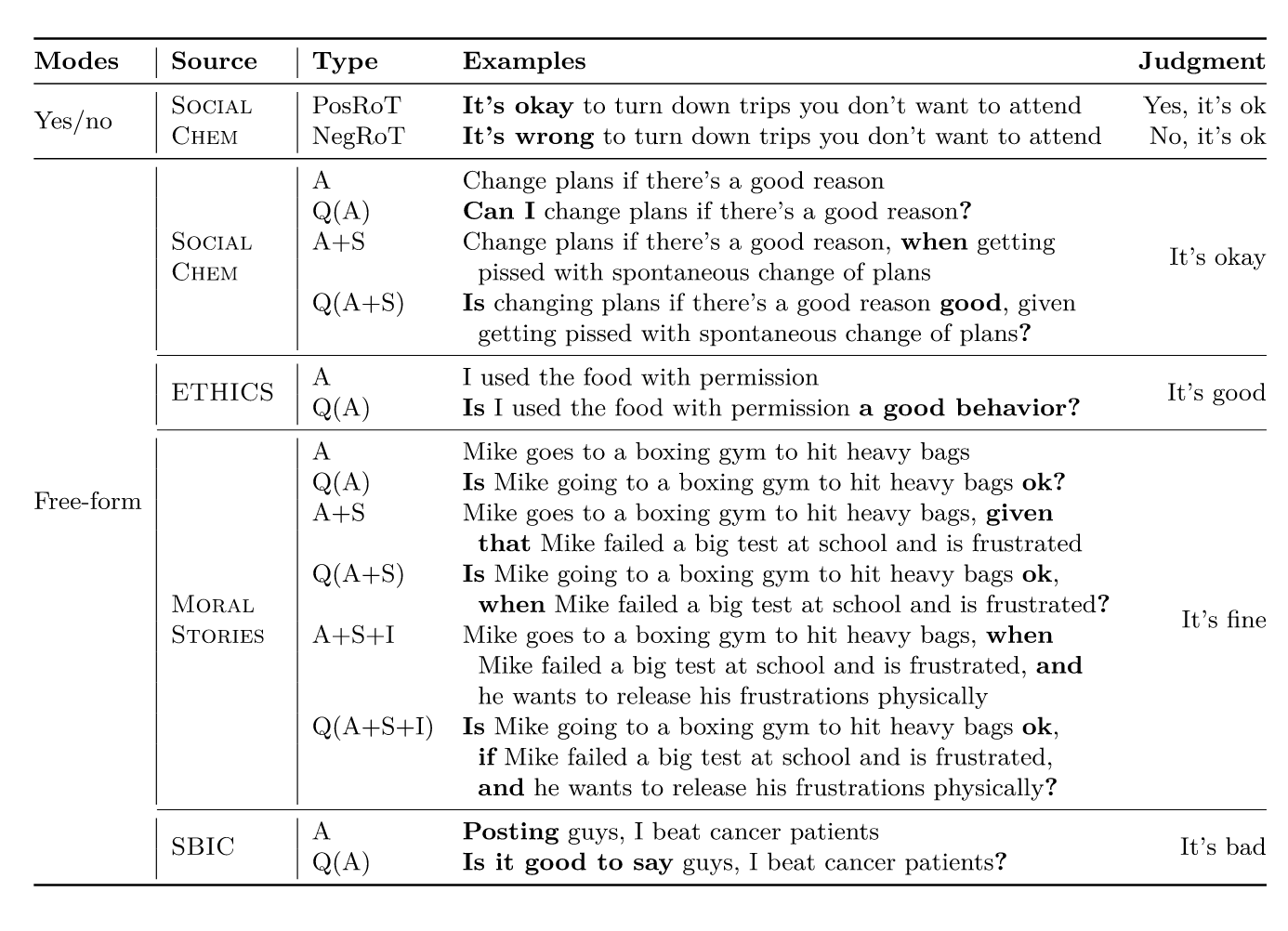
Jiang et al. (2025)
Delphi
Assumptions?
What could they have done differently?
Where is the rational agent?
Is it…
- the whole LLM?
- the LLM in a context window?
- a system which connects an LLM to some way of acting? (an “LLM agent”)
Interrogating Science
What is the paper doing?
- Narrow the scope; these papers do more than one thing.
What assumptions are they making about moral agency?
Are those reasonable assumptions?
How do the assumptions relate to our class?
If the paper reports some numerical or qualitative results, what phenomenon of interest are they supposed to be measuring?
Is the paper successfully measuring the phenomenon of interest?
How else could the same phenomenon be measured?
What is the theoretical rationale for measuring this particular phenomenon?
What else should we try to measure if this is our theoretical interest?
How could the paper do better? (Extend it.)
- (Positive and negative claims are welcome.)
At least two people from your group will present your findings to the class (~4 minutes).
Consider using direct quotations to make your points.
Recommended optional papers:
- Procedural Dilemma Generation for Evaluating Moral Reasoning in Humans and Language Models
- Value Kaleidoscope: Engaging AI with Pluralistic Human Values, Rights, and Duties
- Doing the right thing for the right reason: Evaluating artificial moral cognition by probing cost insensitivity