Description
As noted in the previous assignment, you will parallelize your PageRank code in this assignment. Specifically, you will explore a couple of different partitioning schemes for your code and study their performance.
Partitioning and Load Balance
When we do partitioning for data parallelism, we need to distribute data evenly to the tasks in order to maximize the performance of the parallel execution (we assume that tasks do the same amount of computation for each data element; in general, you will want to partition evenly the actual workload of the tasks, not just the data). If one of the parallel tasks has more work to do than the others, that task has to run longer while the others are already done. Let's look at this Legion Prof trace of the tasks with some load imbalance:
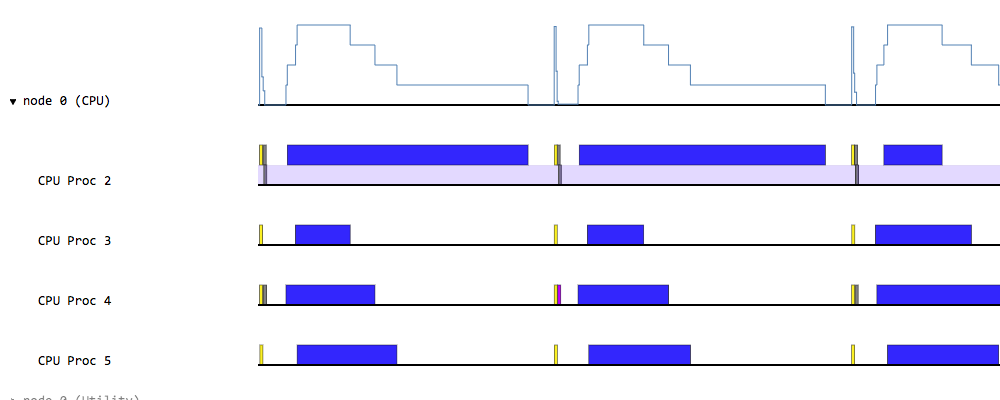
Even though the tasks start running in parallel at the beginning, most of them finish much earlier than the one that runs the longest and all but one processor are idle for most of the time. If we partitioned the data evenly, we could have used the processors more efficiently and the total execution time would have been shorter. Or, we could have used fewer processors and still achieved the same performance. On the other hand, the following trace shows better processor utilization than the previous one, which also makes the wall-clock time shorter:
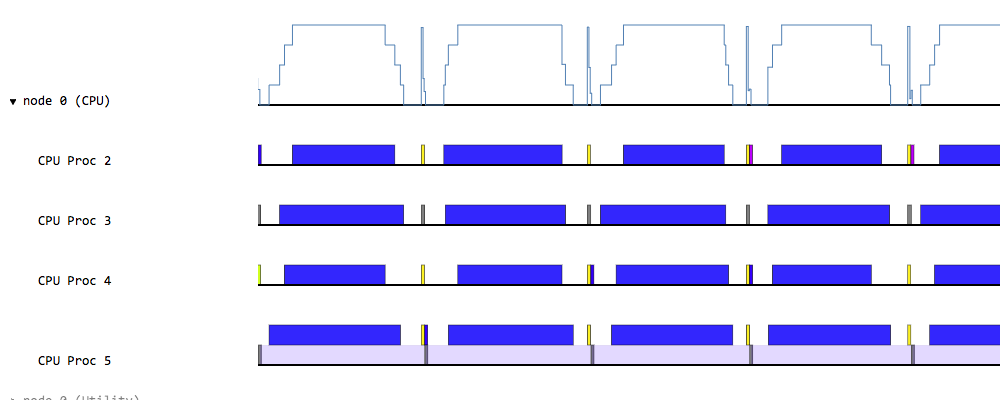
The load balancing issue was not a big concern in the edge detection assignment as there was only one region to consider and we simply used an equal partition of the image. In general, if the code uses only regions that are independent to each other, we can just create equal partitions for them. However, regions are often related, which makes us unable to partition them arbitrarily, but in a way that maintains the same relationship in their subregions (and also distributes their data as evenly as possible). PageRank is one such example; it uses two regions to keep the graph, one for the nodes and another for the edges, and each edge has two pointers to the region of nodes. In this case, we have to decide for which regions we create equal partitions and for which we derive dependent partitions. Each partitioning scheme can show different performance depending on both the input and the computation in tasks, so we need to explore several options in order to find the best one. In the next section, we are going to see a couple of partitioning schemes for PageRank.
Partitioning Schemes for PageRank
Since there are usually more edges than nodes in graphs, it is not surprising to first partition the set of edges equally and then build dependent partitions for nodes. We call this partitioning scheme edge partitioning. In general, edge partitioning is well suited to the tasks that loop through the edges.
For directed graphs, we often want to have two separate partitions for nodes, one for sources and another for targets, because the access patterns of their values are usually different. For example, the PageRank code will read the rank of a source node of the edge and update the target node. Of course, we can put source and target nodes together in one partition, but this might incur some inefficiencies in data movement because the runtime will create physical instances that are bigger than what we actually want.
The following table illustrates the edge partitioning scheme (nodes with multiple colors belong to multiple subregions, which means the partition is aliased):| Scheme | Independent Partition | Dependent Partitions | |
|---|---|---|---|
| Edge Partitioning |
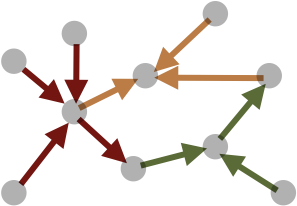
|

|

|
| Edge | Source Node | Target Node | |
You will notice that neither of the two node partitions covers all the nodes in the graph; they cannot be used in tasks that need to loop over the entire set of nodes. As a remedy to this, you can use a union of the two partitions, which is complete, or create another equal partition of the nodes.
The second option is node partitioning. As the name suggests, node partitioning consists of first partitioning the set of nodes equally and then deriving other partitions accordingly. Since we categorize the nodes into sources and targets, we can think of two node partitioning schemes, one based on the sources and another based on the targets. Here are the two schemes illustrated with some diagrams:
| Scheme | Independent Partition | Dependent Partitions | |
|---|---|---|---|
|
Node Partitioning by Source |

|
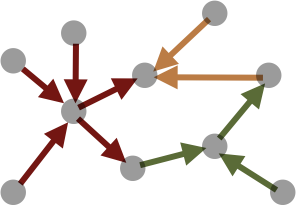
|

|
| Source Node | Edge | Target Node | |
|
Node Partitioning by Target |

|
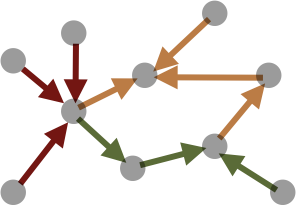
|

|
| Target Node | Edge | Source Node | |
These schemes are best suited to the tasks that iterate the region of nodes. However, they do not guarantee even data distribution among the subregions of edges, which can make the tasks on edges show sub-optimal parallel performance.
Of course, the partitioning schemes listed here are not the only ones you can choose. For example, you can divide edges into two groups, internal and crossing edges, instead of grouping nodes into source and target nodes. Furthermore, you can develop this scheme into a more sophisticated one with three groups of nodes, private, shared, and ghost nodes, as in the circuit simulation (the circuit simulation actually works on an undirected graph, so the scheme might need to be adapted somewhat). Even in the case you pick one of the three schemes above, you might still need to adapt them to your code, as we saw earlier with the edge partitioning scheme. Again, there is no panacea for all cases and you will end up implementing a couple of schemes to eventually reach to the best one for your code and inputs.
Your task in this assignment is to parallelize PageRank with two different partitioning schemes, compare the performance between them, and finally understand why one scheme is better than the other. You can pick any two schemes, but you will want to find the best one because you can get bonus credit if your code is faster than the TA's solution. For reference, the TA's solution takes approximately 4.65 seconds on average with the following command on GCP (a similar command will be used in grading):
regent ta_solution.rg -i /usr/local/share/ic-2004.dat -e 1e-5 -p 7 -ll:cpu 7 -ll:csize 20480 -fvectorize 0ic-2004.dat is a bigger graph file you can use for testing. PLEASE DO NOT MAKE A COPY OF THIS FILE. Since it is rather large, we would prefer not to have a copy for each student on the machine.
Note that your parallel versions should yield the same result as your serial version from the previous assignment.
How to run the code
The starter code (assignment4.tar.gz) is almost the same as in the previous assignment except that the code now supports one more flag: -p to set the number of parallel tasks:
Usage: regent pagerank.rg [OPTIONS]
OPTIONS
-h : Print the usage and exit.
-i {file} : Use {file} as input.
-o {file} : Save the ranks of pages to {file}.
-d {value} : Set the damping factor to {value}.
-e {value} : Set the error bound to {value}.
-c {value} : Set the maximum number of iterations to {value}.
-p {value} : Set the number of parallel tasks to {value}.
You can retrieve the number of parallel tasks from the parallelism field of the PageRankConfig object. You will need this value to create partitions.
What to submit
Send the following files to :
- Two source files
pagerank_scheme1.rgandpagerank_scheme2.rg, one for each partitioning scheme. - Write your answers for the following questions in file
answers.txt:- Describe the partitioning schemes that you implemented. For each partitioning scheme, characterize the input graphs to which it is ideally suited.
- Compare the performance between two partitioning schemes on 1, 2, 4, and 7 CPUs. You may try running on 2 nodes if you wish, but for this assignment you only need to report performance for 1 node. Use the graph
ic-2004.datfor input and set the error bound to1e-5. Discuss why one scheme showed better performance than the other. You should use Legion Prof to vet the performance of your implementations.
- (Bonus Point) Provide an input graph that makes the code that ran slower in the previous question perform better than the other. You also have to provide the exact commands that reproduce the performance difference.