Motor Control with Improving Performance
Applying Reinforcement Learning
Kevin Chavez
EE 152: Green Electronics
Autumn 2013 - 2014
Summary
This project sought to improve upon the widely-used PI control paradigm for motor control. In particular, it develops and applies a reinforcement learning algorithm to the problem of brushless motor control. The performance of this alternative controller--after training to convergence--was then to be compared to that of a ‘tuned’ PI controller. However, there were some mathematical subtleties in one of the final stages, the value function approximation, which led to to divergent behavior of the learning algorithm. This is still under investigation. Some sources that may prove useful in resolving this problem are Convergent Fitted Value Iteration with Linear Function Approximation.
Work Completed
Each of the various phases of the project are listed and described in the sections below.
Designing the Reinforcement Learning Algorithm
To fully define the reinforcement learning algorithm, the following items needed to be formulated: the state space S, the action space A, a way of initializing and determining the state transition probabilities ![]() , a reward function R, and a discount factor γ. All together, this provides a way of estimating an MDP associated with the motor system, which allows the controller to then determine an estimate of the optimal control policy. A desirable controller definition will allow the reinforcement learning algorithm to capture and make use of the properties of the actual system (unlike the parameters of a PI controller), thus they were defined as follows:
, a reward function R, and a discount factor γ. All together, this provides a way of estimating an MDP associated with the motor system, which allows the controller to then determine an estimate of the optimal control policy. A desirable controller definition will allow the reinforcement learning algorithm to capture and make use of the properties of the actual system (unlike the parameters of a PI controller), thus they were defined as follows:
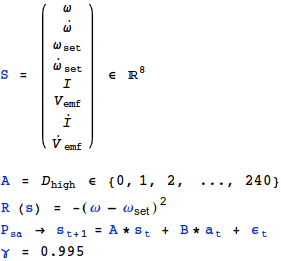
The true state space is continuous, but the controller’s observations of the state are discretized and limited by the ADC. Thus it would be reasonable to work with a discrete state MDP if the dimensionality were reduced to the order of 4. However, by incorporating the back emf and motor current in the definition of the state space, we can capture learn some of the elements of the theoretical dynamic model as expressed below. Therefore the compromise is to include the additional state variables and work in with a continuous state MDP.
The action space is the set of all possible duty factor levels that can be set by the controller. This is certainly discrete and for this microcontroller is in the range of 0 to 240.
The reward function is designed to have a maximum of zero if the controller is perfectly tracking the setpoint. Further, by using the squared error, this controller will tend to avoid large errors more strongly than small errors.
The model for state transition probabilities assumes a linear system. The discount factor γ is chosen and adjusted empirically. Intuitively, a lower γ will attribute more importance to the immediate errors than to errors in the future.
Creating Simulation Environment
In order to validate the reinforcement learning algorithm, it was necessary to develop a rather realistic simulation of a brushless motor system and include noise in transmission lines reflected in noisy measurements. The simulator was created in Matlab, at the level of individual components of the motor equivalent circuit.
The equivalent circuit used for the simulator is the same one developed in the article, Electrical equivalent circuit based modeling and analysis of direct current motors by Ali Bekir Yildiz.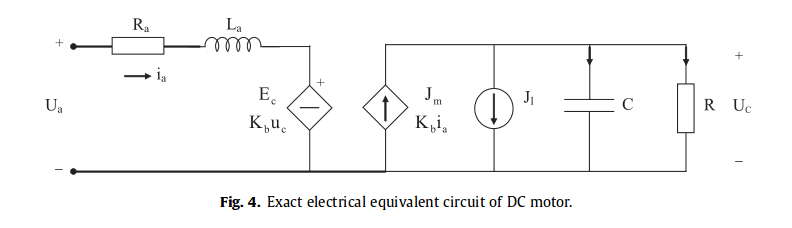
The dynamical system governing this circuit is given by: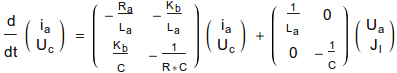
Note here that the inputs to the system are both the input voltage ![]() and the current due to the load torque
and the current due to the load torque ![]() . The state variables are the motor current
. The state variables are the motor current ![]() and the back emf
and the back emf ![]() . To add variability to the simulator, resembling the physical world, a noise term,
. To add variability to the simulator, resembling the physical world, a noise term, ![]() --which is assumed to be gaussian distributed with zero mean--is added to the new state at each step of the simulation.
--which is assumed to be gaussian distributed with zero mean--is added to the new state at each step of the simulation.
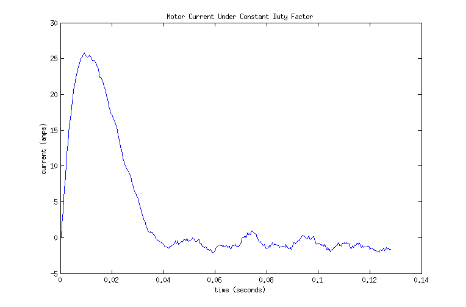
Figures 1 and 2 show a simulation of the motor going from a stand still to steady state velocity when a constant duty factor is applied. 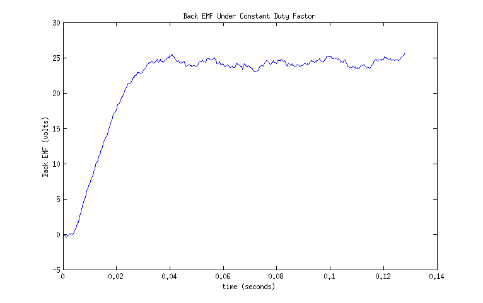
Download Simulator source code
Implementing the Learning Algorithm
The reinforcement learning algorithm with the MDP as described above was implemented in Matlab. The Matlab implementation is better suited for analysis of theoretical performance. While a C implementation was meant to be a proof of concept, demonstrating that it would be possible to run the learning algorithm in real-time within an embedded system while also running the controller, there were other more important issues to address that took priority.
Download Matlab source code
Lessons Learned
There was much to learn in the process of designing, and implementing this alternative control strategy.
For one, I learned to appreciate the simplicity of PID control and it’s general usefulness. The complexity of this new controller is much, much greater than that of the original PI controller. The additional benefit, if any, would serve for systems with more complex dynamics.
I learned more about converting electromechanical models into equivalent electrical models, using the case of the DC motor. Moreover, I was able to practice this process and follow along with the derivation given by Yildiz.
One of the greatest joys that I derived from this project was being able to integrate material from different courses. In working through the design of a reinforcement learning algorithm for DC motors, I learned how to realize some of ideas from the field of machine learning to green electronic applications. I recognize that DC motor control is not a particularly difficult control problem, and that PID controllers work just fine for this application. However, the after going through this process for this application, I feel much more capable of applying a similar procedure to more complex control problems in green electronics.
Key Results
The full control system looks like this: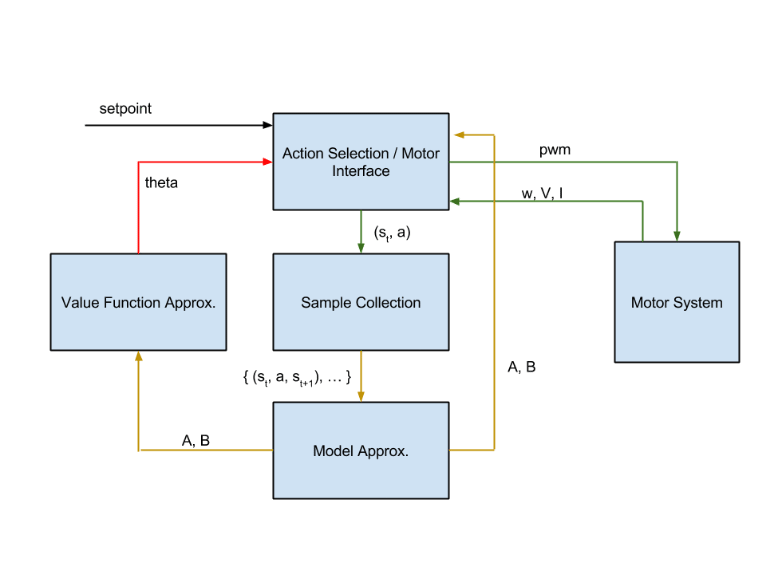
The full modules are in the Matlab code link above. Here is a short description of each of their functionalities:
Action Selection / Motor Interface (see test_update_model.m)
Using the parameters θ gleaned from the value function approximator and the matrices A and B, this module selects the action that maximizes the expected reward over time. That is, it finds the PWM level,
a = ![]()
![]() φ(A*s+B*a)
φ(A*s+B*a)
Model Approximation (see update_model.m)
Upon receiving a batch of samples, this module computes the matrices A and B that minimize![]()
Since ![]() is assumed to be given by
is assumed to be given by ![]() , this minimization yields the best estimate of that form.
, this minimization yields the best estimate of that form.
Value Function Approximation (see value_iteration.m)
Given a model of the system, this module approximates the expected value of the reward function if starting in a particular state and following an optimal policy (as defined by the value function). Because the value function is continuous-valued, the function is approximated by a linear combination of a set of nonlinear features (see feature_map.m). In particular it takes on the form ![]() φ(s). Also because it is continuous-valued, I used fitted value iteration, which usually converges in practice. However, I ran into problems with convergence which prevented later training stages and spent a lot of time trying to correct for it.
φ(s). Also because it is continuous-valued, I used fitted value iteration, which usually converges in practice. However, I ran into problems with convergence which prevented later training stages and spent a lot of time trying to correct for it.
Here we have the response to a step in setpoint, in the early stages of training.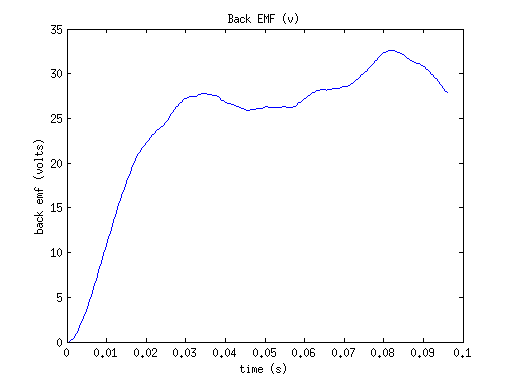
Deliverables
Learning algorithm as described in the corresponding section above.
A simulation environment for testing the proposed control strategy. This is described in the section Creating Simulation Environment. The full source code is available at the link in that section.
Next Steps
Some of the questions that I had hoped to address that are still remaining...
How does the reinforcement learning controller perform as judged by the following metrics:
- RMSE over step response
- Overshoot, rise time, decay ratio, settling time for a setpoint step
- RMSE over low frequency sinusoidal setpoint
Learning curve for the RL controller. Let each trial consist of a single setpoint change, and run until settling or some time limit. Then plot the RMSE as a function of trial number. Compare to RMSE of tuned PI controller (learning curve will be a straight line, i.e. it doesn’t learn).
After convergence, increase load torque by a factor of 2 (rather drastic change). Again, measure RMSE of PI controller to a step response. Plot re-learning curve of RL controller. How many trials to match performance of PI controller? How many trials to convergence?
This project consisted of the design and simulation stage of a control strategy for DC motor control. (Although, the approach can be used for other green electronic applications as well, and in fact, may be better suited for more complex control problems). The next step would be validation on a physical system. This would require developing some additional code to record measurements from the microcontroller’s ADC and write them to file for analysis. There are additional constraints to a physical system that were not taken into account for this first pass development. For example, there is a limit on the amount of current that can be driven back through the power stage. This can be taken into account by adding a term to the reward function that detracts from it if the current goes below some negative boundary.
Another potential step would be to look at other control problems in green electronics and use the framework/pipeline developed for this project to apply a similar reinforcement learning based control strategy for those problems.