Section 3 - Results
3.1 Lossless Encoding
3.1.1 Direct Application of BWT
According to [4], applying the BWT directly to image data is ineffective. We disproved this statement by performing the BWT followed by MTF encoding on several test images. As a proxy for an efficient encoder (e.g. Huffman or arithmetic), we calculated the zero-order entropy for the original image and for the transformed image. The results are presented in the table below. All values are in bits per pixel.
| Image | Original | MTF | BWT/MTF | JPEG-LS |
| peppers | 7.5925 | 6.9449 | 5.5727 | 4.513 |
| harbour | 6.7575 | 6.4984 | 6.2609 | 4.494 |
| boats | 7.0333 | 6.3996 | 5.6908 | 4.033 |
| bridge | 5.7056 | 5.1756 | 4.7974 | 5.500 |
| lena | 7.4451 | 6.6973 | 5.4819 | 4.237 |
Table 1. Zero-order entropy values for BWT-MTF transformed images
As can be seen, even this simple application of the BWT results in some compression - between 22% and 40% for this set of images. This is not entirely surprising. As Burrows and Wheeler stated in relation to text compression [1], if the context of a character is a good predictor for the character, then the BWT will tend to make the block more compressible. This is obviously true for image data as well as for text. A certain pixel value will tend to be found near certain other pixel values. It is this characteristic that is exploited by predictive encoders.
For comparison, we have included the performance of a state-of-the-art lossless encoder (JPEG-LS). Note that JPEG-LS is not a part either of the original JPEG standard nor of the new JPEG2000 standard and it outperforms the lossless modes of both of those standards [2].
Our relatively simple encoding scheme comes within 1-1.5 bits per pixel of JPEG-LS. Interestingly, JPEG-LS does not perform as well as the BWT/MTF encoding for the bridge image. We speculate that this is related to the distribution of gray tones in this picture. There are only half as many tones used in this image compared with the other images but they are distributed over the same range.
3.1.2 Predictive Encoding and BWT
[4] also suggests that a predictive encoder provides a suitable input to the BWT. It further states that the BWT works better for "decorrelated information such as text". We were very sceptical about the claims made in this paper since, as mentioned above, the ability of BWT to increase compressibility depends precisely on the correlation inherent in text. Since a predictive encoder is designed to decorrelate data, we believed that it would not be suitable for use with BWT.
Nevertheless, we tested the idea. For a predictive encoder, we chose to implement the non-linear predictive encoder that forms part of the JPEG-LS standard. This predictor is defined as follows:
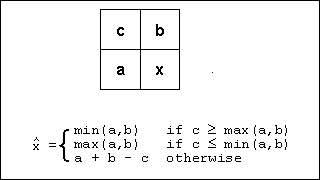
Fig.4 Non-linear Predictor Definition
If we calculate the zero-order entropy of our test image set after predictive encoding, we get (all values in bits per pixel):
| Image | Original | Predictor |
| peppers | 7.5925 | 4.9423 |
| harbour | 6.7575 | 4.9990 |
| boats | 7.0333 | 4.4081 |
| bridge | 5.7056 | 4.3171 |
| lena | 7.4451 | 4.5470 |
Table 2. Zero-order Entropy Values for Predictor Output
Next, we transformed the output of the predictive encoder using the BWT and MTF. The result was no discernable improvement in bit rate. As we expected, the decorrelated predictor output remains decorrelated after BWT.
This result is in direct contradiction with the above-mentioned paper [4] published in IEEE Transactions on Consumer Electronics. The authors claim that use of BWT preceded by a Gradient-Adjusted Predictor (GAP) can consistently outperform lossless JPEG (not the same as JPEG-LS). However the figures they supply show only a slight improvement. We suggest that this improvement could be due to the improved predictor (GAP) or to the fact that the authors used arithmetic encoding to produce their final compressed output. JPEG encoders normally use Huffman encoding which is slightly less efficient than arithmetic encoding.
3.2 Lossy Encoding
Most applications in image compression do not require lossless encoding but rather aim at extremely low data rates which make the occurrence of loss almost inevitable. The BWT, however, can not be applied before any lossy transform as any loss occurring in the transformed data makes it impossible for the inverse BWT to restore the original data. Therefore all loss must be introduced before applying the BWT. Discrete Cosine Transform (DCT) and Discrete Wavelet Transform (DWT) are two of the most frequently employed subband coding schemes today and shall be examined below (see diagram).
3.2.1 The DCT and BWT
The DCT is usually applied to 8x8 blocks of the image in order to reduce the computational complexity. After quantization, the DCT coefficients have to be scanned in order to form a linear input for the BWT. The DCT coefficients are scanned in a way that all coefficients at a certain position in their 8x8 blocks are grouped together. It turned out that the specific way of scanning these coefficients has negligible effect on the overall performance.
Using a run-length encoder before the BWT will not only reduce the computational complexity of the subsequent BWT but showed a significantly better performance for large quantization step sizes. A move-to-front encoder exploits the order introduced in the output of the BWT.
Our results as illustrated in Figure 6 prove that the performance of the BWT is significantly better for low rates. So far we have not able to reach the performance of the conventional DCT 8x8 encoder despite numerous refinements. We feel that the DCT is unsuitable for use with the BWT.
3.2.2 Wavelet Transform and DCT
As proposed by [5] the BWT can be used in conjunction with a Discrete Wavelet Transform. Figure 5 illustrates the test configuration that showed the best performance among the configurations examined.
After applying a Daubechies length 6 DWT of depth 6, the coefficients are quantized and scanned. As in the DCT case, a run-length encoder precedes the BWT. This takes advantage of long runs of zeros which are quite likely to occur in the case of high quantization step sizes. The results at low bit rates are quite encouraging. We are confident that further refinements (for example, in the quantizer and in the scanning sequence) will result in further significant performance gains.