
Introduction to Computer Speech and Language Processing
Autumn 2004, Dan Jurafsky
|
LINGUIST 138/238 - SYMBSYS 138
Introduction to Computer Speech and Language Processing Autumn 2004, Dan Jurafsky |
IP notice: These lecture notes include direct quotes from many web sites, especially including Alan Black's, but also and many others. Thus any text on any of these lecture notes should be viewed as being stolen from other people, all credit and rights go to them.
| Introduction to TTS |
| Articulatory Phonetics |
| The ARPAbet |
| The History of Speech Synthesis |
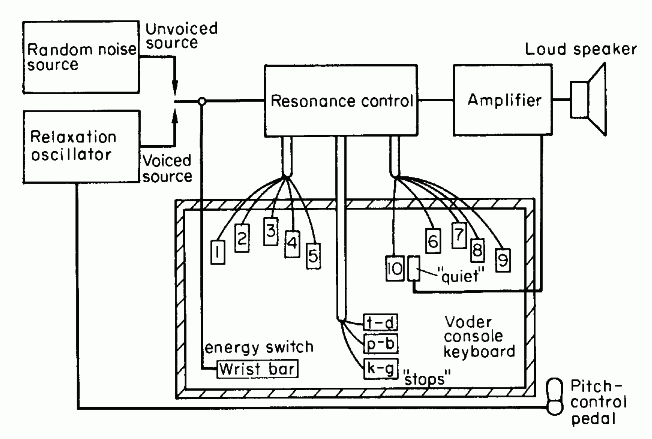



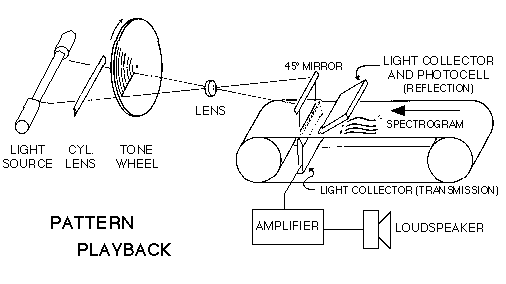
| Speech Synthesis Architectures |
| Overview of Festival |
festival --tts news.txt echo "Hello world" | festival --tts
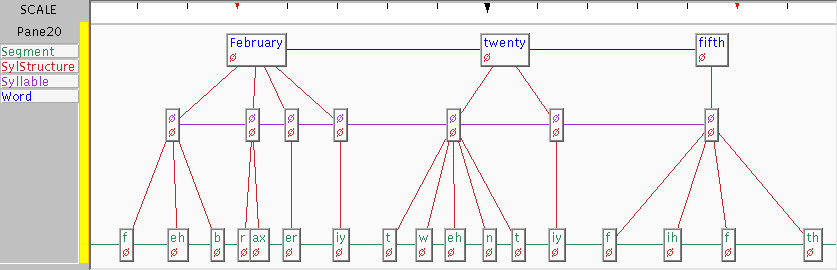
We started on Feb 25.
We started on february twenty fifth .
| Feb | 25 | | february | twenty | fifth | | 1 | 0 | 0 | 0 | 1 | 0 | 1 | | f | eh | b | r | ax | er | iy | t | w | eh | n | t | iy | f | ih | f | th |
Thus giving layers for tokens, words, syllables and phones.
Problems:
| Lexicons and Lexical Entries in Festival |
Lookup words with
(lex.lookup WORD PART-OF-SPEECH)or
(lex.lookup WORD)
e.g.
(lex.lookup 'reagan)
(lex.lookup 'object 'v)
(lex.lookup 'object 'n)
(lex.add.entry
'("reagan" n (((r ey) 1) ((g ax n) 0))))
Format is (WORD POS (SYL0 SYL1 ...)))
Syllable is ((PHONE0 PHONE 1...) STRESS)
(lex.lookup 'cepstra)
("cepstra" n (((k eh p) 1) ((s t r aa) 0)))
To find out what the phoneme set is and possible formats, it is often useful
to lookup similar words. Use the lex.lookup function
| Text Normalization |
Alan Black: Festival's currently-used decision tree for determining end of utterance is:
((n.whitespace matches ".*\n.*\n[ \n]*") ;; A significant break in the text
((1))
((punc in ("?" ":" "!"))
((1))
((punc is ".")
;; This is to distinguish abbreviations vs periods
;; These are heuristics
((name matches "\\(.*\\..*\\|[A-Z][A-Za-z]?[A-Za-z]?\\|etc\\)")
((n.whitespace is " ")
((0)) ;; if abbrev signal space is enough for break
((n.name matches "[A-Z].*")
((1))
((0))))
((n.whitespace is " ") ;; if it doesn't look like an abbreviation
((n.name matches "[A-Z].*") ;; single space and non-cap is no break
((1))
((0)))
((1))))
((0)))))
Thus the above difficult cases try to deal with the case where a token is terminated by a period but could be an abbreviation. An abbreviation is recognized as containing a dot or capitalized with one or two letters or three capital letters. When an abbreviation is detected there must be more than one space and the next word must be capitalized to signal a break. If the word doesn't appear to be an abbreviation, then any long break or capitalized following word will signal a break.
This will fail for such examples as
Pronunciation of numbers often depends on its type.
An example rule for dealing with such phrases as "$1.2 million" would be
(define (token_to_words utt token name)
(cond
((and (string-matches name "\\$[0-9,]+\\(\\.[0-9]+\\)?")
(string-matches (utt.streamitem.feat utt token "n.name")
".*illion.?"))
(append
(builtin_english_token_to_words utt token (string-after name "$"))
(list
(utt.streamitem.feat utt token "n.name"))))
((and (string-matches (utt.streamitem.feat utt token "p.name")
"\\$[0-9,]+\\(\\.[0-9]+\\)?")
(string-matches name ".*illion.?"))
(list "dollars"))
(t
(builtin_english_token_to_words utt token name))))
| Text Type | % NSW |
| novels> | 1.5% |
| press wire> | 4.9% |
| e-mail> | 10.7% |
| recipes> | 13.7% |
| classified> | 27.9% |
| Major type | minor type | % |
| numeric | number | 26% |
| year | 7% | |
| ordinal | 3% | |
| alphabetic | as word | 30% |
| as letters | 12% | |
| as abbrev | 2% |
EXPN
LSEQ
ASWD
MSPL
NUM
NORD
NTEL
NDIG
NIDE
NADDR
NZIP
NTIME
NDATE
NYER
MONEY
BMONY
PRCT
SLNT
PUNC
FNSP
URL
NONE
| Lexicons and Letter-to-Sound Rules |
A AH0 A'S EY1 Z A(2) EY1 A. EY1 A.'S EY1 Z A.S EY1 Z A42128 EY1 F AO1 R T UW1 W AH1 N T UW1 EY1 T AAA T R IH2 P AH0 L EY1 AABERG AA1 B ER0 G AACHEN AA1 K AH0 N AAKER AA1 K ER0 AALSETH AA1 L S EH0 TH AAMODT AA1 M AH0 T AANCOR AA1 N K AO2 R AARDEMA AA0 R D EH1 M AH0 AARDVARK AA1 R D V AA2 R K AARON EH1 R AH0 N AARON'S EH1 R AH0 N Z AARONS EH1 R AH0 N Z AARONSON EH1 R AH0 N S AH0 N AARONSON'S EH1 R AH0 N S AH0 N Z AARONSON'S(2) AA1 R AH0 N S AH0 N Z AARONSON(2) AA1 R AH0 N S AH0 N AARTI AA1 R T IY2 AASE AA1 S AASEN AA1 S AH0 N AB AE1 B AB(2) EY1 B IY1 ABABA AH0 B AA1 B AH0 ABABA(2) AA1 B AH0 B AH0 ABACHA AE1 B AH0 K AH0 ABACK AH0 B AE1 K ABACO AE1 B AH0 K OW2 ABACUS AE1 B AH0 K AH0 S ABAD AH0 B AA1 D ABADAKA AH0 B AE1 D AH0 K AH0 ABADI AH0 B AE1 D IY0 ABADIE AH0 B AE1 D IY0 ABAIR AH0 B EH1 R ABALKIN AH0 B AA1 L K AH0 N ABALONE AE2 B AH0 L OW1 N IY0 ABALOS AA0 B AA1 L OW0 Z ABANDON AH0 B AE1 N D AH0 N
( LEFTCONTEXT [ ITEMS ] RIGHTCONTEXT = NEWITEMS )
For example
( # [ c h ] C = k ) ( # [ c h ] = ch )
The # denotes beginning of word and the C is defined to
denote all consonants. The above two rules which are applied in order,
meaning that a word like christmas will be pronounced with a
k which a word starting with ch but not followed by a
consonant will be pronounced ch (e.g. choice.)
There are typically less phones that letters in the pronunciation of many langauges. Thus there is not a one to one mapping of letter t phones in a typical lexical pronunciation. In order for a machine learner technique to build reasonable prediction models we must first align the letter to phones, inserting epsilon where there is no mapping. For example
Letters: c h e c k e d Phones: ch _ eh _ k _ t
We provide two methods for this, one fully automatic and one requiring hand seeding. In the full automatic case first scatter eplisons in all possible ways to cause the letter and phoens to align. The we collect stats for the P(Letter|Phone) and select the best to generate a new set of stats. This iterated a number of times until it settles (typically 5 or 6 times). This is an example of the EM (expectation maximisation algorithm).
The alternative method that may (or may not) give better results is to
hand specify which letters can be rendered as which phones. This is
fairly easy to do. For example, letter c goes to phones k
ch s sh, letter w goes to w v f, etc. Typically all
letter can at some time go to eplison, consonants go to some small
number of phones and letter vowels got to some larer number of phone
vowels. Once the table mapping is created, similary to the epsilon
scatter above, we find all valid alignments and find the probabilities
of letter given phone. Then we score all the alignments and take the
best.
Typically (in both cases) the alignments are good but some set are very bad. This very bad alignment set, which can be detected automatically due to their low alignment score, are exactly the words whose pronunciations don't match their letters. For example
| dept @tab d ih p aa r t m ah n t |
| lieutenant @tab l eh f t eh n ax n t |
| CMU @tab s iy eh m y uw |
Other such examples are foreign words. As these words are in some sense non-standard these can validly be removed from the set of examples we use to build the phone prediction models.
CART trees are build for each letter in the alphabet (twenty six plus any accented characters in the language), using a context of three letters before an three letters after. Thus we collect features sets like
# # # c h e c --> ch c h e c k e d --> _
Using this technique we get the following results.
| Lexicon | Letters Correct | Words Correct |
| OALD (UK English) | 95.80% | 74.56% |
| CMUDICT (US English) | 91.99% | 57.80% |
| BRULEX (French) | 99.00% | 93.03% |
| DE-CELEX (German) | 98.79% | 89.38% |
After testing various models we found that the best models for the held out test set from the lexicon we not the the best set for genuinely unknown words. BAsically the lexicon optimised models were over trained for that test set, so we relaxed the stop criteria for the CART trees and got a better result on the 1,775 unknown words. The best results give 70.65% word correct. In this test we judged correct to be what a human listener judges asa correct. Sometimes even though the prediction is wrong with respect to the lexical entry in a test set the result is actually acceptable as a pronunciation.
This also highlights how a test set may be good to begin with after some time and a number of passes and corrections to ones training algorithm any test set will be become tainted and you need a new test set. It is normal to have a development test which is used during development of an algorithm then keep out a real test set that only get used once the algorithm is developed. Of course as development happens in cycles the real test set will effectively become the development set and hence you'll need another new test set.
| Use of part-of-speech tagging in TTS |
use 319 increase 230 close 215 record 195 house 150 contract 143 lead 131 live 130 lives 105 protest 94 survey 91 project 90 separate 87 present 80 read 72 subject 68 rebel 48 finance 46 estimate 46
| Main errors left in Festival (from Alan Black lecture notes:) |