[1] 0.001327097Pitfalls of data snooping
2024-04-01
Distribution of \(p\)-values
Distribution function here should be diagonal…
50% of our 95% confidence intervals will not cover 0 (truth)
[1] 0.5005834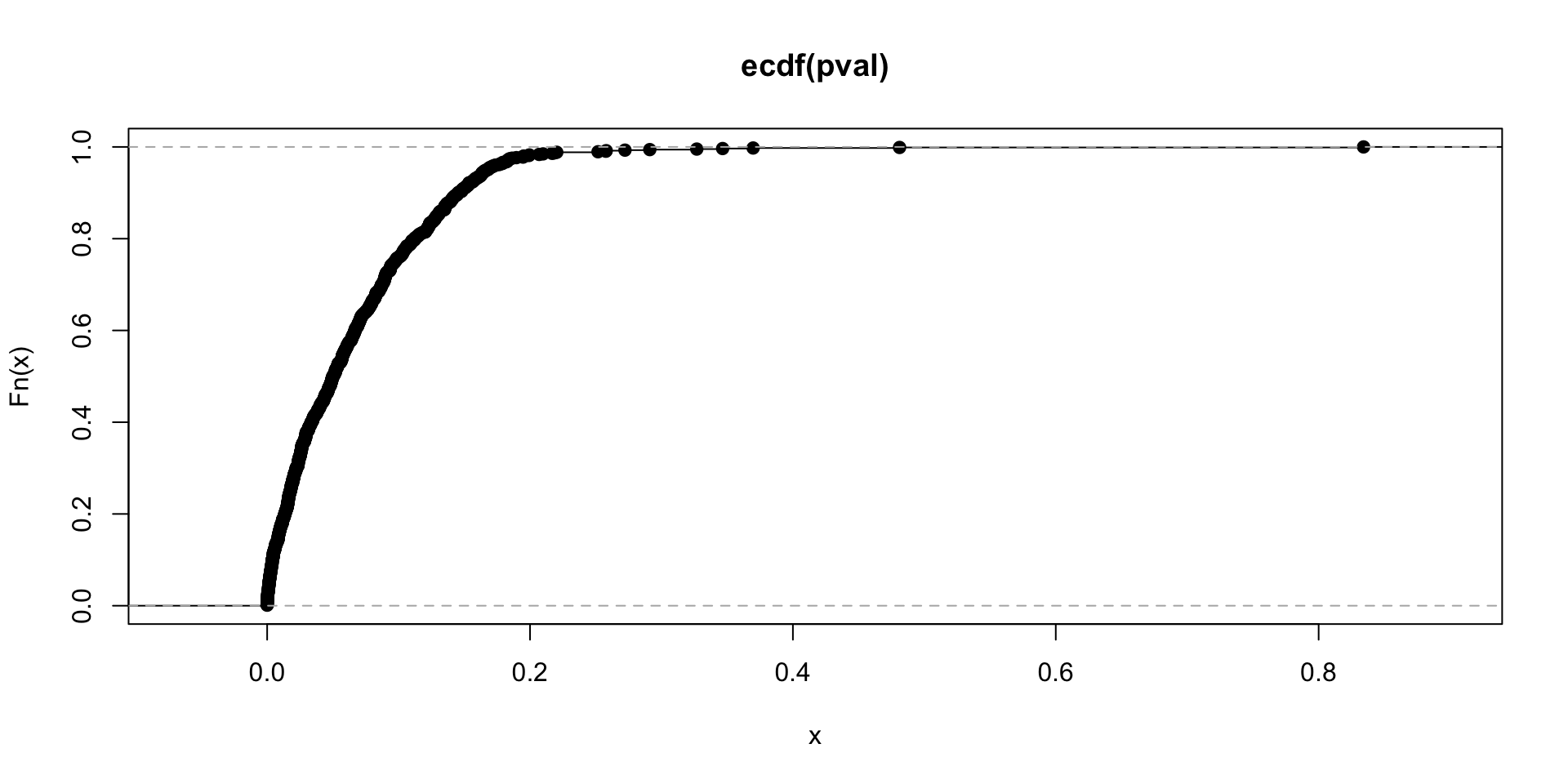
Data splitting \(p\)-values
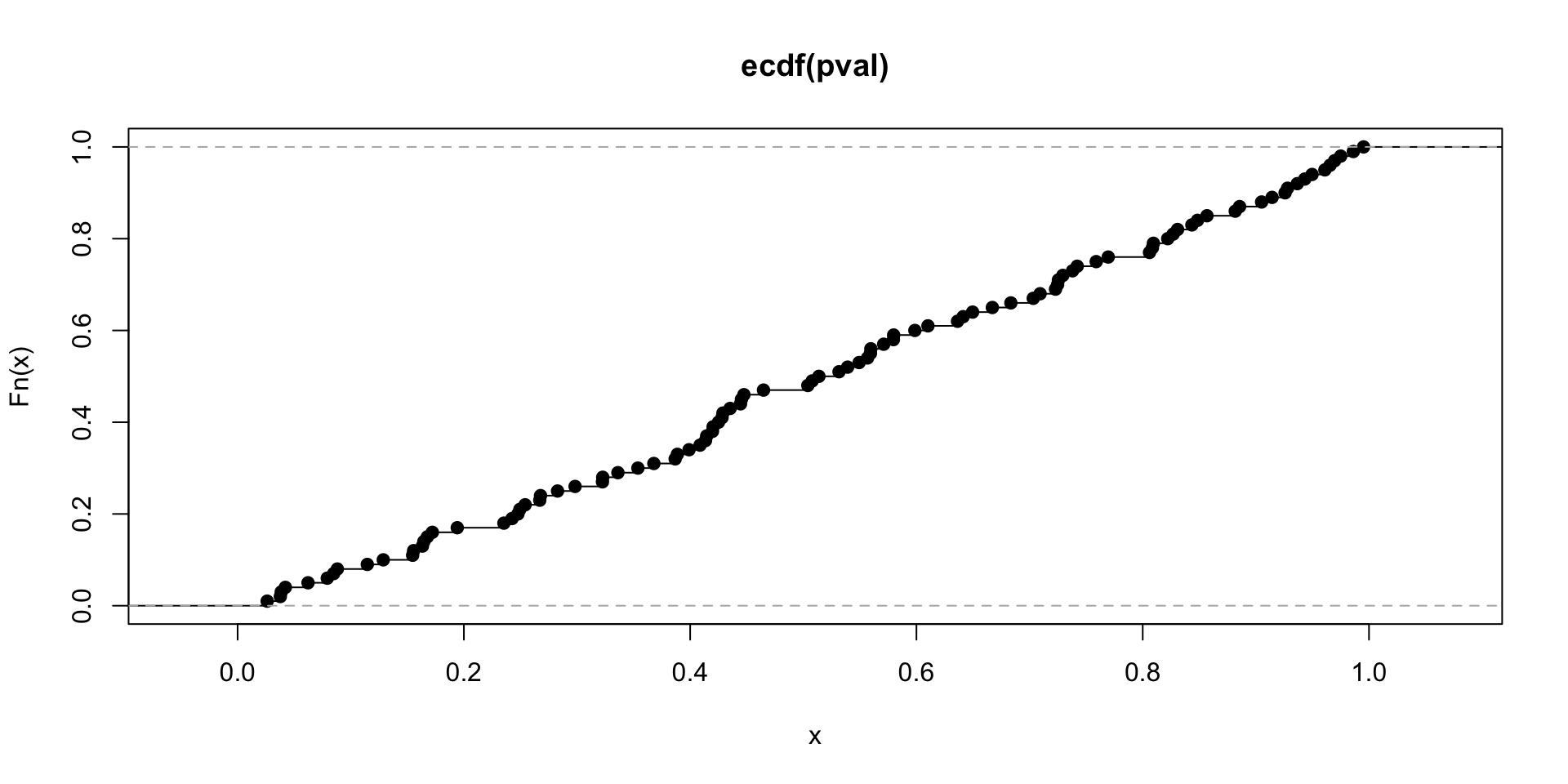
[1] 0.04
2024-04-01
Distribution function here should be diagonal…
50% of our 95% confidence intervals will not cover 0 (truth)
[1] 0.5005834
[1] 0.04