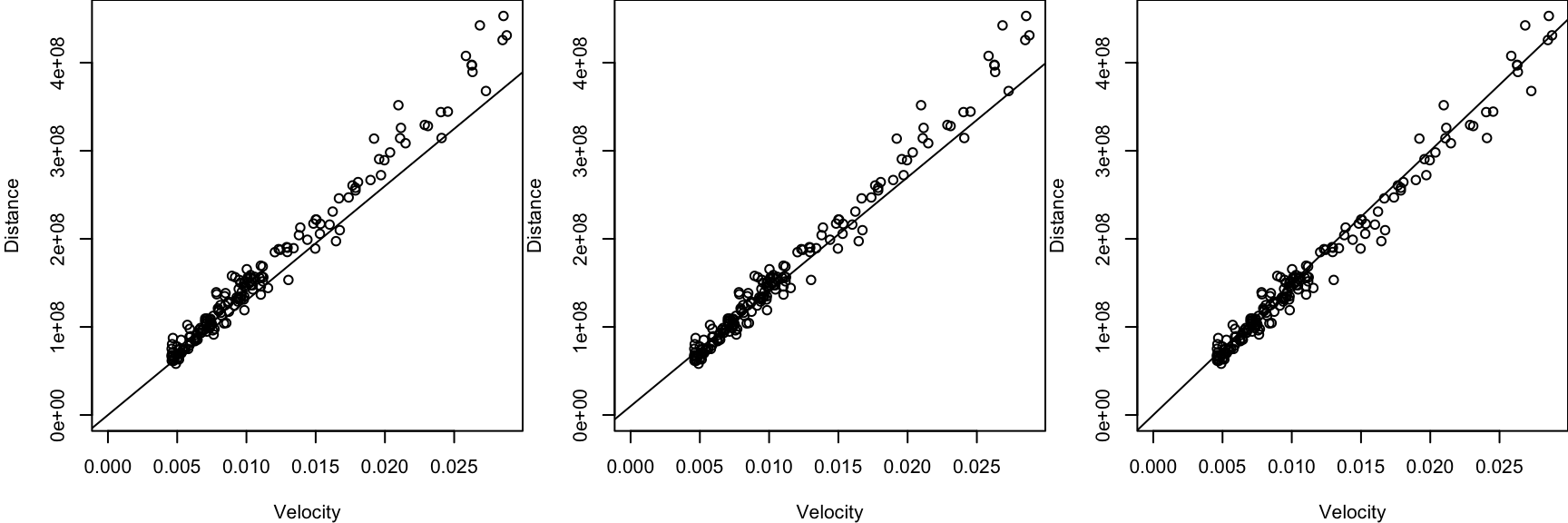
Least-Squares Line
Stats 203
Comparing Lines of Best Fit
All of us got different lines. How do we know which line is best?
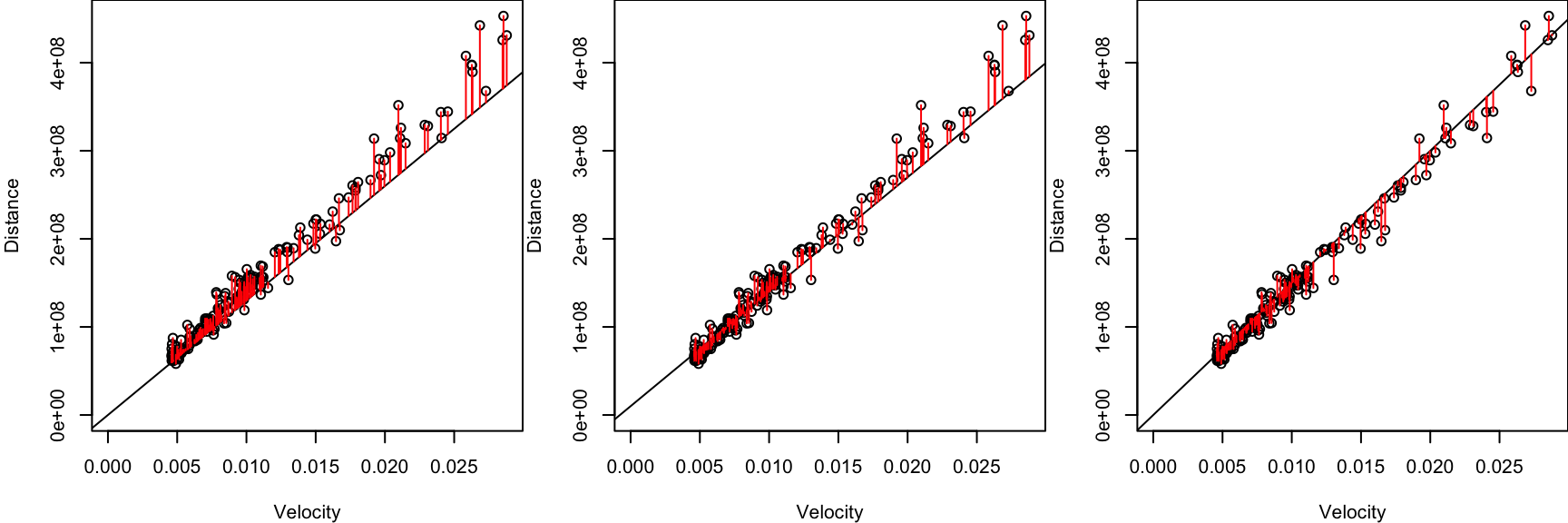
Calculate the sum of squared errors between the points and the line.
\[\text{SSE}(\alpha, \beta) = \sum_{i=1}^n (y_i - (\alpha + \beta x_i))^2\]
Interpreting the Least-Squares Line
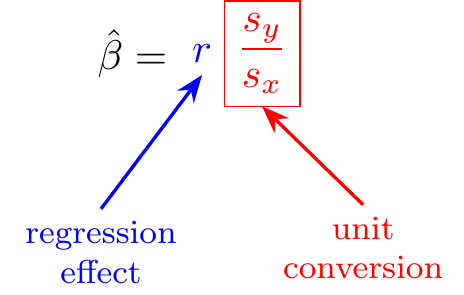
To understand this formula, let’s look at Galton’s study of heights of parents and offspring, which led him to coin the term “regression”.
Least-Squares Line and Projection
Remember that we choose \(\alpha\) and \(\beta\) to minimize
\[ \begin{align} \text{SSE}(\alpha, \beta) &= \sum_{i=1}^n (y_i - (\alpha + \beta x_i))^2 \end{align} \]
This is equivalent to choosing \(\hat{\bf y}\) to minimize
\[ \begin{align} || {\bf y} - &\hat{\bf y} ||^2 \\ \text{subject to } &\hat {\bf y} \in \text{span}({\bf 1}, {\bf x}) \end{align} \]
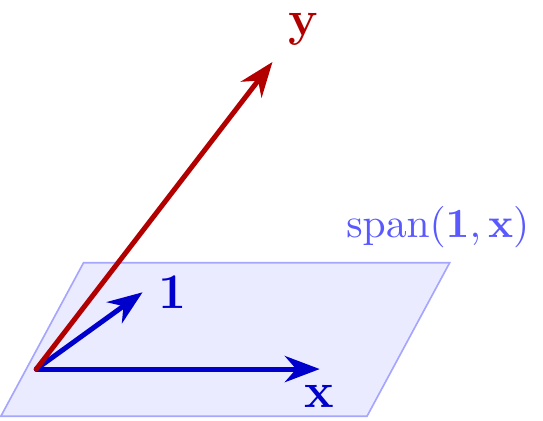
Visualization for \(n = 3\)
Least-Squares Line and Projection
Remember that we choose \(\alpha\) and \(\beta\) to minimize
\[ \begin{align} \text{SSE}(\alpha, \beta) &= \sum_{i=1}^n (y_i - (\alpha + \beta x_i))^2 \end{align} \]
This is equivalent to choosing \(\hat{\bf y}\) to minimize
\[ \begin{align} || {\bf y} - &\hat{\bf y} ||^2 \\ \text{subject to } &\hat {\bf y} \in \text{span}({\bf 1}, {\bf x}) \end{align} \]
which is \(P_{\text{span}({\bf 1}, {\bf x})}{\bf y}\), the projection of \({\bf y}\) onto the span.
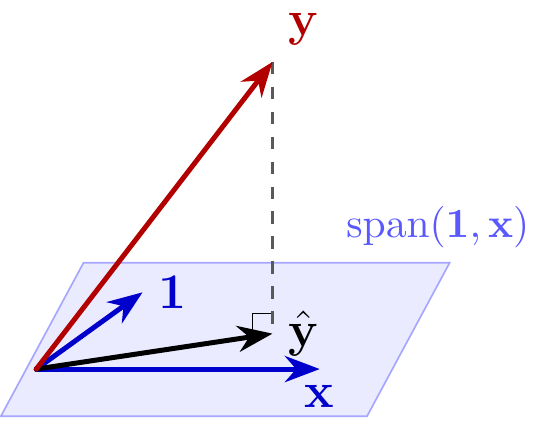
Visualization for \(n = 3\)
Applications of Linear Algebra
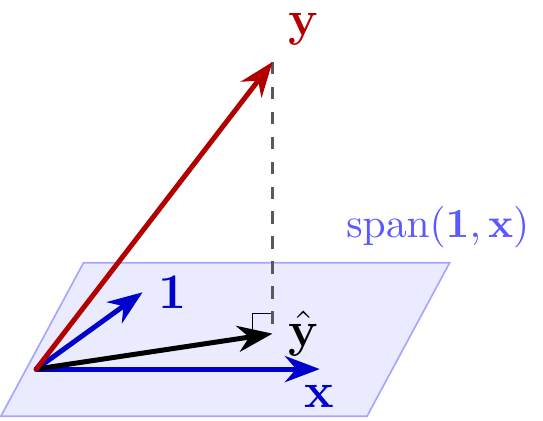
We see that \({\bf y} - \hat{\bf y}\) is orthogonal to both \({\bf 1}\) and \({\bf x}\), so
- \(0 = {\bf 1} \cdot ({\bf y} - \hat{\bf y}) = \sum_{i=1}^n (y_i - (\alpha + \beta x_i))\)
- \(0 = {\bf x} \cdot ({\bf y} - \hat{\bf y}) = \sum_{i=1}^n x_i (y_i - (\alpha + \beta x_i)),\)
which are the equations that we solve for \(\alpha\) and \(\beta\) (no derivatives required)!
By the Pythagorean Theorem, we see that
- \(||\hat{\bf y}||^2 + ||{\bf y} - \hat{\bf y}||^2 = ||{\bf y}||^2\)
- or equivalently \[ \sum_{i=1}^n \hat y_i^2 + \sum_{i=1}^n (y_i - \hat y_i)^2 = \sum_{i=1}^n y_i^2. \]
This identity is not easy to prove by algebra!