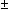 1 are also printed specially as 1.0
and -1.0. Infinite
bounds (1020
or larger) are printed as None.
1 are also printed specially as 1.0
and -1.0. Infinite
bounds (1020
or larger) are printed as None.PRINT file in accordance with the Solution keyword. Some header information appears first to identify the problem and the final state of the optimization procedure. A ROWS section and a COLUMNS section then follow, giving one line of information for each row and column. The format used is similar to certain commercial systems, though there is no industry standard.
An example of the printed solution is given in Examples. In general, numerical values are output with format f16.5. The maximum record length is 111 characters, including the first (carriage-control) character.
To reduce clutter, a dot ".''
is printed for any numerical value that is exactly zero. The
values 1 are also printed specially as 1.0
and -1.0. Infinite
bounds (1020
or larger) are printed as None.
Note : If two problems are the same except that one minimizes an objective f(x) and the other maximizes –f(x), their solutions will be the same but the signs of the dual variables pi and the reduced gradients dj will be reversed.
General linear constraints take the form l
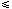 Ax u. The
ith constraint is therefore of
the form
Ax u. The
ith constraint is therefore of
the form
a aTx
b,
and the value of aTx
is called the row activity. Internally,
the linear constraints take the form Ax
- s = 0, where the slack variables
s should
satisfy the bounds lsu. For
the ith "row", it is
the slack variable si that
is directly available, and it is sometimes convenient to refer to its
state. Slacks
may be basic or nonbasic (but not superbasic).
Nonlinear constraints a Fi(x) + aTx b
are treated similarly, except that the row activity and degree
of infeasibility are computed directly from Fi(x) + aTx rather
than from si.
|
Label |
Description | ||||||||||||||||
|
Number |
The value n+i. This is the internal number used to refer to the ith slack in the iteration log. | ||||||||||||||||
|
Row |
The name of the ith row. | ||||||||||||||||
|
State |
The state of the ith row relative to the bounds a and b. The various states possible are as follows.
A key is sometimes printed before the State to give some additional information about the state of the slack variable.
Note : If Scale option > 0, the tests for assigning A, D, I, N are made on the scaled problem, since the keys are then more likely to be meaningful. | ||||||||||||||||
|
Activity |
The row value aTx (or Fi(x) + aTx for nonlinear rows). | ||||||||||||||||
|
Slack activity |
The amount by which the row differs from its nearest bound. (For free rows, it is taken to be minus the Activity.) | ||||||||||||||||
|
Lower limit |
a, the lower bound on the row. | ||||||||||||||||
|
Upper limit |
b, the upper bound on the row. | ||||||||||||||||
|
Dual activity |
The value of the dual variable pi, often called the shadow price (or simplex multiplier) for the ith constraint. The full vector p always satisfies BTp = gB, where B is the current basis matrix and gB contains the associated gradients for the current objective function. | ||||||||||||||||
|
I |
The constraint number, i. |
Here
we talk about the "column variables" xj, j
= 1:n. We
assume that a typical variable has bounds a
xj b.
|
Label |
Description | ||||||||||||||||||||
|
Number |
The column number, j. This is the internal number used to refer to xj in the iteration log. | ||||||||||||||||||||
|
Column |
The name of xj. | ||||||||||||||||||||
|
State |
The state of the ith row relative to the bounds a and b. The various states possible are as follows.
A key is sometimes printed before the State to give some additional information about the state of xj.
Note : If Scale option > 0, the tests for assigning A, D, I, N are made on the scaled problem, since the keys are then more likely to be meaningful. | ||||||||||||||||||||
|
Activity |
The value of the variable xj. | ||||||||||||||||||||
|
Obj Gradient |
gj, the jth component of the gradient of the (linear or nonlinear) objective function. (If any xj is infeasible, gj is the gradient of the sum of infeasibilities.) | ||||||||||||||||||||
|
Lower limit |
a, the lower bound on xj. | ||||||||||||||||||||
|
Upper limit |
b, the upper bound on xj. | ||||||||||||||||||||
|
Reduced gradnt |
The reduced gradient dj = gj –pTaj, where aj is the jth column of the constraint matrix (or the jth column of the Jacobian at the start of the final major iteration). | ||||||||||||||||||||
|
M+J |
The value m+j . |