Abstract concepts
Humans possess the remarkable ability to flexibly acquire and
apply abstract concepts when interpreting the concrete world
around us. Consider the concept "maze": our mental model can
interpret mazes constructed with conventional materials (e.g.,
drawn lines) or unconventional ones (e.g., icing), and reason
about mazes across a wide range of configurations and
environments (e.g., in a cardboard box or on a knitted square).
Our goal is to build systems that can make such flexible and
broad generalizations as humans do. This necessitates a
reconsideration of a fundamental question:
what makes a maze look like a maze? A maze is not defined
by concrete visual features such as the specific material of
walls or particular perpendicular intersections, but by lifted
rules over symbols—a plausible model for a maze includes its
layout, the walls, and the designated entry and exit.
Current VLMs often struggle to reason about visual abstractions
at a human level, frequently defaulting to literal
interpretations of images, such as a collection of object
categories. Here, we propose Deep Schema Grounding (DSG), a
framework for models to interpret visual abstractions. At the
core of DSG are schemas—a dependency graph description of
abstract concepts. Schemas characterize common patterns that
humans use to interpret the visual world, generalize efficiently
from limited data, and reason across multiple levels of
abstraction for flexible adaptation. A schema for "helping"
allows us to understand relations between characters in a finger
puppet scene, while a schema for "tic-tac-toe" allows us to play
the game even when the grid is composed of hula hoops instead of
drawn lines. A schema for "maze" makes a maze look like a maze.

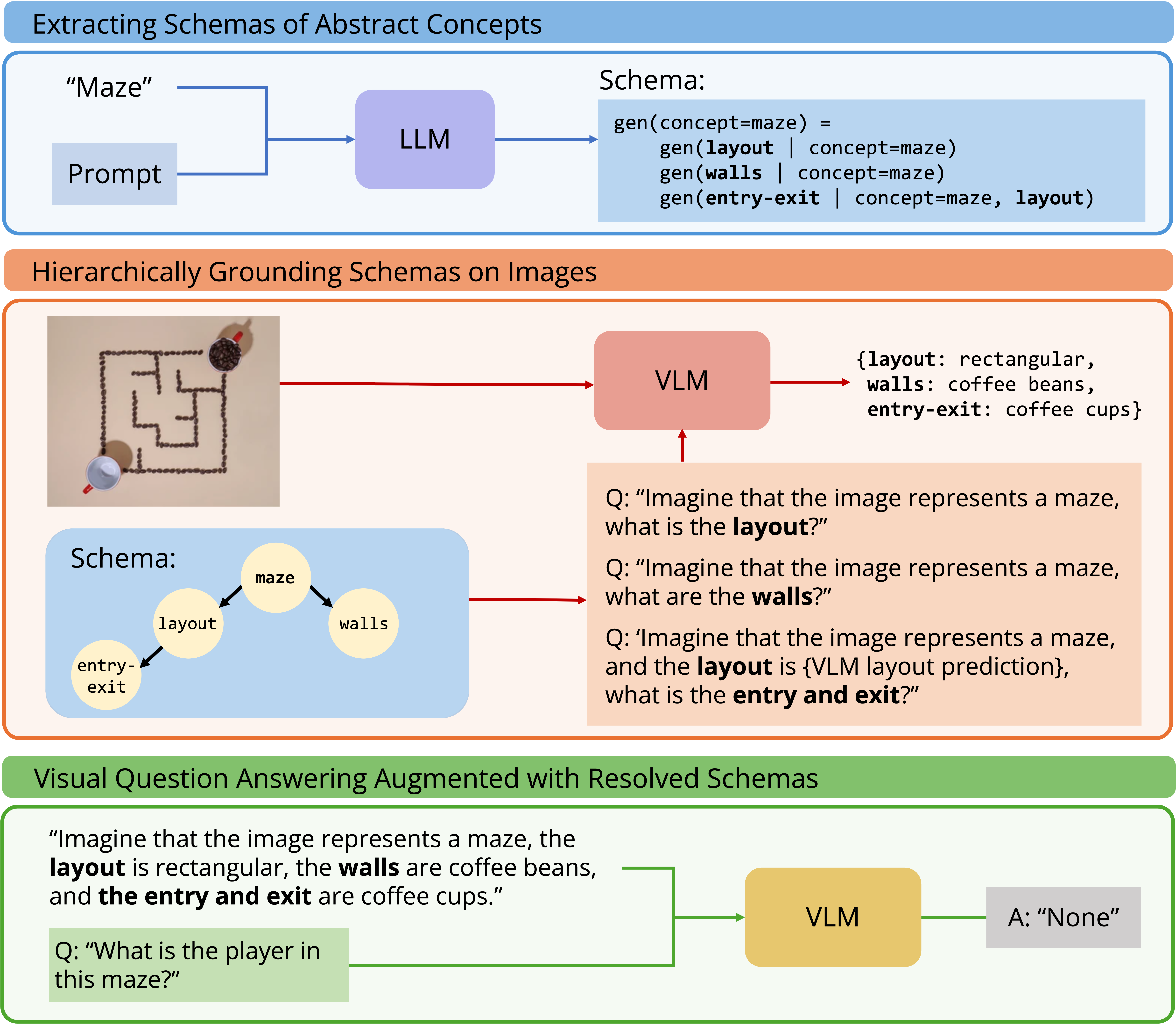
Deep Schema Grounding
Deep Schema Grounding (DSG) explicitly uses schemas generated
by and grounded by large pretrained models to reason about
visual abstractions. Concretely, we model schemas as programs
encoding directed acyclic graphs (DAGs), which decompose an
abstract concept into a set of more concrete visual concepts
as subcomponents. The full framework is composed of three
steps.
1. First, we extract schema definitions of abstract concepts
from a LLM.
2. Next, DSG hierarchically queries a VLM, first grounding
concrete symbols in the DAG (i.e., symbols that do not depend
on the interpretation of other symbols), then using those
symbols as conditions to ground more abstract symbols.
3. Finally, we use the resolved schema, including the
grounding of all its components, as an additional context into
a vision-language model to improve visual reasoning.
Our method is a general framework for abstract concepts that
does not depend on specific models; the LLMs and VLMs used are
interchangeable.