Abstract
Recent works on accelerating Vision-Language Models achieve strong performance across a variety of vision-language
tasks despite highly compressing visual information. In this work, we examine the popular acceleration approach
of early pruning of visual tokens inside the language model. Surprisingly, we find that while strong performance
is maintained across many tasks, it exhibits drastically different behavior for a subset of vision-centric tasks
such as localization. Upon further investigation, we uncover a core issue with the acceleration approach where
most tokens towards the top of the image are pruned away. Yet, on many benchmarks aiming to evaluate vision-centric
capabilities, strong performance persists with the flawed pruning strategy, highlighting these benchmarks' limited
ability to assess fine-grained visual capabilities. Based on these findings, we propose

Figure 1. (a) Although FastV prunes most visual tokens from the upper portion of the image,
the approach still displays strong performance on a variety of evaluated vision-language tasks except for the
vision-centric task of localization. (b) Based on our findings, we propose
Revisiting Visual Token Pruning
The motivation of our study is to get a better understanding of the vision capabilities of accelerated VLMs given that they leverage highly compressed visual information, focusing specifically on FastV approach. When evaluating across a wide range of vision-language tasks, we present the following findings:
Early visual token pruning falters in vision-centric tasks. Pruning visual tokens after shallow LLM layers results in a jarring performance decline for localization benchmarks and a moderate decrease for TextVQA, whereas performance remains relatively unchanged for other evaluated tasks.
Figure 2. Contrasting the difference in performance dropoff on the challenging vision-centric localization task (Left) versus the other evaluated tasks (Middle) when pruning visual tokens after the shallow LLM layers. Whereas performance decrease is minimal for most tasks, localization exhibits roughly a linear decrease to zero as the ratio of pruned tokens increases. Right: Per-task performance breakdown across various setups of pruning ratios.
Interpreting poor vision-centric task performance. The pruning criteria when applied after shallow layers predominantly selects visual tokens from the bottom part of the image.
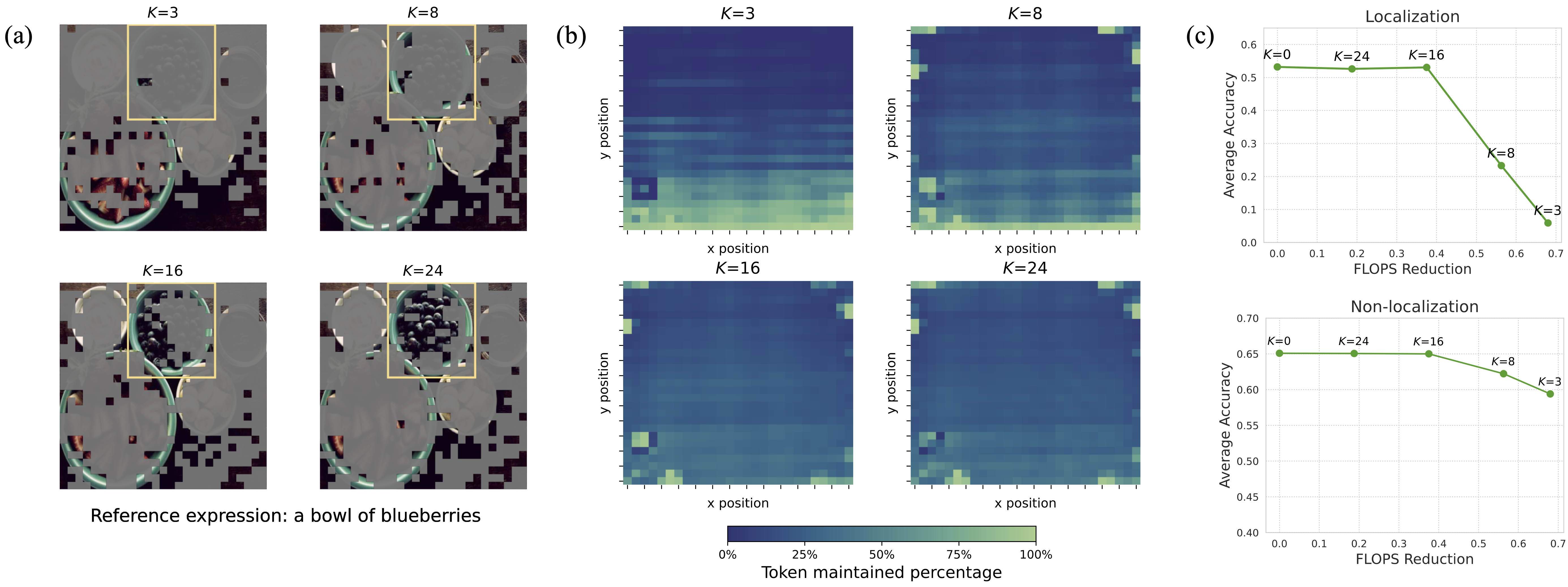
Figure 3. (a) Example demonstrating that when pruning in early layers, selected tokens are concentrated in the bottom of the image. (b) Heatmap illustrating that averaged across all benchmark examples, as the pruning layer increases, the selection of bottom visual tokens by the criteria is reduced. (c) Visualizing the effect of the pruning layer on performance for both localization and non-localization tasks.
Explaining VLM inference acceleration performance on other tasks. The majority of evaluated benchmarks do not require fine-grained visual grounding, as they can often be answered using only visual tokens located towards the bottom of the image.
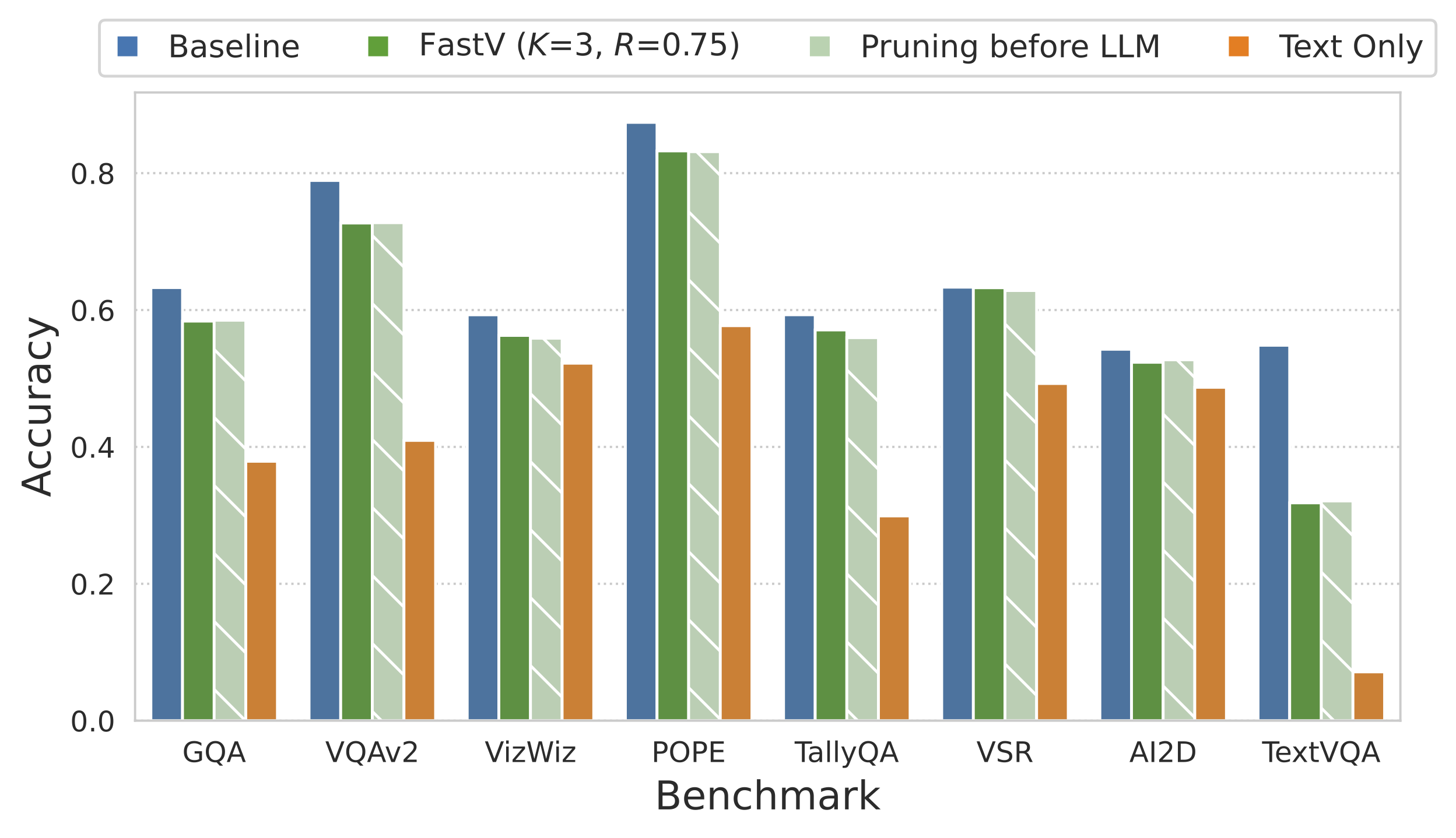
Figure 4. Allowing information transfer before pruning (shown in green) does not result in substantial performance improvement over the setup without visual information transfer (shown in light green), highlighting a limitation of many benchmarks.
Improving Visual Token Pruning
Based on our findings, we seek to enhance the studied VLM acceleration approach to better preserve fine-grained visual capabilities while still achieving computational efficiency. To this end, we propose alternative pruning criteria and demonstrate that our modifications enable effective pruning even when applied after early LLM layers. The criteria explored are:
- φoriginal: The attention score received from the last text token.
- φ-R: The attention score received from the last text token without applying RoPE to the attention mechanism, thereby removing the long-term decay effect.
- φKNN: Local visual embedding density from the vision backbone.
- φuniform:Uniformly sampling visual tokens.
- φ-R + φuniform: Ensemble utilizing φ-R with additional uniform sampled tokens.
| K | Criteria | FLOPS Red | OCID-Ref | RefCOCOg | RefCOCO+ | RefCOCO | Avg | Other Task Avg |
|---|---|---|---|---|---|---|---|---|
| 3 | Attention-based | |||||||
| φoriginal | 68% | 0.057 | 0.051 | 0.061 | 0.067 | 0.059 | 0.594 | |
| φ-R | 68% | 0.229 | 0.151 | 0.133 | 0.153 | 0.167 | 0.618 | |
| Non-attention-based | ||||||||
| φKNN | 66% | 0.151 | 0.249 | 0.260 | 0.296 | 0.239 | 0.606 | |
| φuniform | 66% | 0.206 | 0.286 | 0.297 | 0.333 | 0.280 | 0.618 | |
| Ensemble | ||||||||
| φ-R + φuniform | 61% | 0.291 | 0.272 | 0.247 | 0.277 | 0.272 | 0.633 | |
| 8 | Attention-based | |||||||
| φoriginal | 56% | 0.194 | 0.235 | 0.240 | 0.263 | 0.233 | 0.622 | |
| φ-R | 56% | 0.271 | 0.267 | 0.264 | 0.292 | 0.273 | 0.635 | |
| Non-attention-based | ||||||||
| φKNN | 55% | 0.154 | 0.244 | 0.252 | 0.294 | 0.236 | 0.607 | |
| φuniform | 55% | 0.246 | 0.310 | 0.309 | 0.348 | 0.303 | 0.618 | |
| Ensemble | ||||||||
| φ-R + φuniform | 50% | 0.320 | 0.359 | 0.354 | 0.388 | 0.356 | 0.644 | |
Table 1: Evaluating alternative criteria for token pruning after the early LLM layers.
From our results, we gain the following insights:
- Once removing the criteria tendency of selecting bottom image tokens, pruning after early LLM layers becomes substantially more effective.
- Even with the enhanced criteria for pruning after shallow LLM layers, pruning later still improves the criteria and downstream performance.
- Integrating uniform sampling into the attention-based pruning criteria enhances its effectiveness in early layers.
FEATHER
Guided by our insights, we now present our final approach
Figure 5. Comparing
Strikingly, we find that our approach achieves this performance improvement while only retaining 3.3% of visual tokens for the second half of LLM layers. See qualitative examples below.
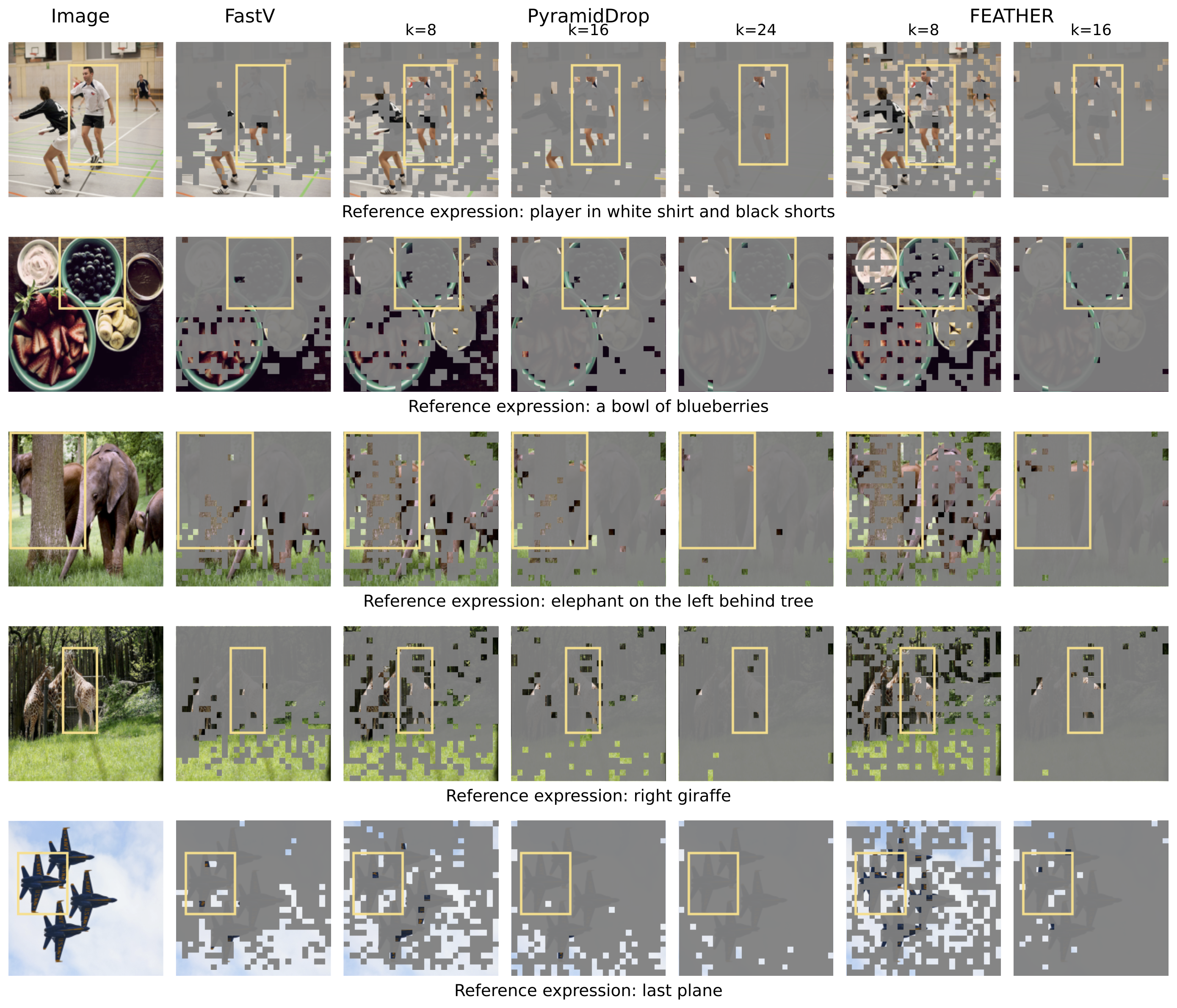
Figure 6. Visualizing the ability of
BibTeX
@inproceedings{endo2025feather,
author = {Endo, Mark and Wang, Xiaohan and Yeung-Levy, Serena},
title = {Feather the Throttle: Revisiting Visual Token Pruning for Vision-Language Model Acceleration},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year = {2025},
}