



Next: Isolation by distance data
Up: Estimation of (the number
Previous: Mild departures from the
Contents
There are a couple of informal pointers which might be helpful in
selecting 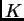 . The first is that it's often the situation that
. The first is that it's often the situation that
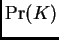 is very small for less than the appropiate value
(effectively zero), and then more-or-less plateaus for larger , as
in the example of Data Set 2A shown above. In this sort of situation
where several values of give similar estimates of log
is very small for less than the appropiate value
(effectively zero), and then more-or-less plateaus for larger , as
in the example of Data Set 2A shown above. In this sort of situation
where several values of give similar estimates of log
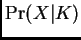 ,
it seems that the smallest of these is often ``correct''.
It is a bit difficult to provide a firm rule for what we mean by a
``more-or-less plateaus''. For small data sets, this might mean that
the values of log
are within 5-10, but our colleague Daniel
Falush writes that ``in very big datasets, the difference between
,
it seems that the smallest of these is often ``correct''.
It is a bit difficult to provide a firm rule for what we mean by a
``more-or-less plateaus''. For small data sets, this might mean that
the values of log
are within 5-10, but our colleague Daniel
Falush writes that ``in very big datasets, the difference between
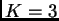 and
and 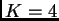 may be 50, but if the difference between and
may be 50, but if the difference between and
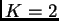 is 5,000, then I would definitely choose .''
I think that a sensible way to think about this is in terms of model
choice. That is, we may not always be able to know the TRUE value of
, but we should aim for the smallest value of that captures the
major structure in the data.
The second pointer is that if there really are separate populations,
there is typically a lot of information about the value of
is 5,000, then I would definitely choose .''
I think that a sensible way to think about this is in terms of model
choice. That is, we may not always be able to know the TRUE value of
, but we should aim for the smallest value of that captures the
major structure in the data.
The second pointer is that if there really are separate populations,
there is typically a lot of information about the value of 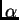 ,
and once the Markov chain converges, will normally settle
down to be relatively constant (usually with a range of perhaps 0.2 or
less in examples I have looked at). However, if there isn't any real
structure, will usually vary greatly during the course of the
run.
A corrollary of this is that when there is no population structure, you
will typically see that the proportion of the sample assigned to each
population is roughly symmetric (
,
and once the Markov chain converges, will normally settle
down to be relatively constant (usually with a range of perhaps 0.2 or
less in examples I have looked at). However, if there isn't any real
structure, will usually vary greatly during the course of the
run.
A corrollary of this is that when there is no population structure, you
will typically see that the proportion of the sample assigned to each
population is roughly symmetric (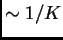 in each population), and
most individuals will be fairly admixed. If some individuals are strongly
assigned to one population or another, and if the proportions assigned
to each group are asymmetric, then this is a strong indication that you
have real population structure.
Suppose that you have a situation with two clear populations, but you
are trying to decide whether one of these is further subdivided (ie,
the value of
in each population), and
most individuals will be fairly admixed. If some individuals are strongly
assigned to one population or another, and if the proportions assigned
to each group are asymmetric, then this is a strong indication that you
have real population structure.
Suppose that you have a situation with two clear populations, but you
are trying to decide whether one of these is further subdivided (ie,
the value of
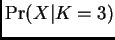 is similar to, or perhaps a little larger than
is similar to, or perhaps a little larger than
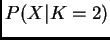 ). Then one thing you could try is to run structure using
only the individuals in the population that you suspect might be
subdivided, and see whether there is a strong signal as described above.
In summary, you should be skeptical about population structure
inferred on the basis of small differences in
if (1) there is
no clear biological interpretation for the assignments, and (2) the
assignments are roughly symmetric to all populations and no
individuals are strongly assigned.
). Then one thing you could try is to run structure using
only the individuals in the population that you suspect might be
subdivided, and see whether there is a strong signal as described above.
In summary, you should be skeptical about population structure
inferred on the basis of small differences in
if (1) there is
no clear biological interpretation for the assignments, and (2) the
assignments are roughly symmetric to all populations and no
individuals are strongly assigned.
Next: Isolation by distance data
Up: Estimation of (the number
Previous: Mild departures from the
Contents
William Wen
2002-07-18