



Next: Missing data, null alleles...
Up: Estimation of (the number
Previous: Informal pointers for choosing
Contents
Isolation by distance refers to the idea that individuals may be
spatially distributed across some region, with slow dispersal. In
this situation, allele frequencies vary gradually across the region.
The underlying structure model is not well suited to data from
this kind of scenario.
In practice, the inferred value of 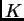 , and the corresponding allele
frequencies in each group can be rather arbitrary. Most individuals
will have mixed membership in multiple groups. That is, the algorithm
will attempt to model the allele frequencies across the region using
weighted averages of distinct components. In such situations,
interpreting the results may be challenging.
However, the admixture model will work well for 1-dimensional
isolation by distance, and also for hybrid zones.
, and the corresponding allele
frequencies in each group can be rather arbitrary. Most individuals
will have mixed membership in multiple groups. That is, the algorithm
will attempt to model the allele frequencies across the region using
weighted averages of distinct components. In such situations,
interpreting the results may be challenging.
However, the admixture model will work well for 1-dimensional
isolation by distance, and also for hybrid zones.
William Wen
2002-07-18