


Next:Running
structure from theUp:Missing
data, null alleles...Previous:Sequence
data and YContents
Multimodality
The structure algorithm starts at a random place in parameter space,
and then converges towards a mode of the parameter space. (In this context,
a mode can be thought of, loosely speaking, as a clustering solution that
has high posterior probability.) For some data sets there may be multiple
modes8,
and the current implementation of structure does not normally cross
between them in runs of realistic length. This means that different runs
can produce substantially different answers, and longer runs will probably
not fix this. This is mainly an issue for very complex data sets, with
large values of 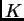 ,
, 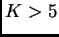 or
or 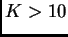 ,
say (but see the example of Data Set 2A in
Pritchard
et al. 2000a). You can examine the results for
,
say (but see the example of Data Set 2A in
Pritchard
et al. 2000a). You can examine the results for 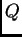 to get an idea of whether this seems to be happening. A careful analysis
of this type of situation was presented by
Pritchard
et al. 2000a, for a data set where the estimated
was around 19.
to get an idea of whether this seems to be happening. A careful analysis
of this type of situation was presented by
Pritchard
et al. 2000a, for a data set where the estimated
was around 19.
William Wen 2002-07-18