Quiz 3: Solutions
June 2nd, 2021
Below is a historgram of the results.
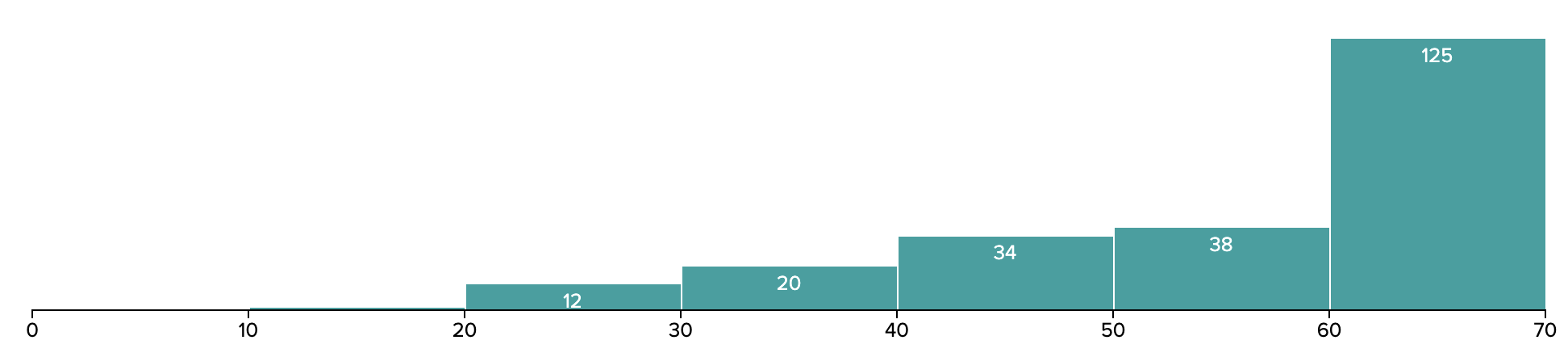 Key Statistics
Key Statistics
- Median: 62
- Mean: 57
- Maximum: 70
You can find your answers on Gradescope. Let Juliette know if you do not have access to Gradescope.
Regrade Requests We try to grade as consistently as possible, but we are human and we might make mistakes. If you feel like one of your problems was misgraded, please file a regrade request on Gradescope before Friday June 4th at 4:00pm. Note that this is the only way to have your regrade request considered; in particular, asking your section leader to take a quick look to see whether a problem was misgraded isn't a way of short circuiting this process. We want you to have the credit you deserve, but filing a formal request helps us make sure that your request goes to the right person.
1. One-liners (20 points)
Do not need to write a def for these questions. For each part, write a 1-line expression to compute the indicated value with: map() or sorted() or min() or max() or a comprehension. You do not need to call list() for these.
# a. Given a list of numbers. # Call map() to produce a result where each number is multiplied by 2. # (or equivalently write a comprehension) >>> nums = [3, 0, -2, 5] # yields [6, 0, -4, 10] # your expression:map(lambda x: x*2, nums)or equivalently[num*2 for num in nums]# b. Given a list of numbers. # Call map() to produce a result where each number is converted # to string form with a '!' added at its end. # (or equivalently write a comprehension) >>> nums = [3, 0, -2, 5] # yields ['3!', '0!', '-2!', '5!'] # your expression:map(lambda x: str(x)+'!', nums)or equivalently[str(num)+'!' for num in nums]# c. Given a list of city (name, population) tuples like this: # cities = [('palo alto', 51202), ('kensington', 12300), ...] # Call sorted() to produce a list of these tuples sorted in increasing # order by population # your expression:sorted(cities, key=lambda x: x[1])# d. Given a non-empty list of food (name, sour-score, sweet-score) tuples # like the following, scores are in the range 1 .. 10 # foods = [('banana', 1, 8), ('orange', 9, 6), ... ] # Call max() or min() to return the food tuple with the highest sweet-score. # your expression:max(foods, key=lambda food: food[2])
2. Dict (25 points)
Suppose we have a "foods" dict, where each key is a food, and its value is a len-2 tuple (tasty-score, healthy-score), where each score is in the range 1 .. 10, like this:
foods = {
'coffee': (3, 4),
'oatmeal': (6, 9),
'donut': (10, 1),
}
We have a "meals" dict where each key is a meal, and its value is a list of foods for that meal:
meals = {
'breakfast': ['coffee', 'oatmeal'],
'lunch': ['donut'],
'dinner': ['beets', 'donut']
}
Write code that, given the foods and meals dicts, creates and returns a new "healthy" dict which gathers the healthy scores for each planned meal. The healthy dict has the same keys as the meals dict, and the value for each key is a list of the healthy scores of that meal's foods. If a particular food is not present in the foods dict, assume it has a healthy score of 5, e.g. 'beets' in the example below.
# Input foods and meals dicts:
foods = {
'coffee': (3, 4),
'oatmeal': (6, 9),
'donut': (10, 1),
}
meals = {
'breakfast': ['coffee', 'oatmeal'],
'lunch': ['donut'],
'dinner': ['beets', 'donut']
}
Computed healthy dict:
{
'breakfast': [4, 9],
'lunch': [1],
'dinner': [5, 1]
}
def healthy_dict(foods, meals):
healthy = {}
for meal in meals.keys():
scores = []
for food in meals[meal]:
if food in foods:
tup = foods[food]
scores.append(tup[1])
else:
scores.append(5)
healthy[meal] = scores
return result
3. Dict-File (25 points)
Suppose we are working on a dumbed-down Tweet technology called Bleet. In a Bleet, all hashtags look like '#omg' - the hashtag is made of a '#' char and the 3 following chars. No logic or loop is needed to find the end of the hashtag; it's simply the 3 chars after the '#'. We have a text file, where each line is made of 2 or more bleets, separated by plus chars '+'.
hello #omgthere+hi and#idk as if#omg+#idkwhat
Each bleet, e.g. 'hello #omgthere', contains exactly 1 hashtag, and other than the hashtag, does not contain any '#' or '+' chars.
Process all the lines in the file, building and and returning a dict that has a key for each hashtag string without the leading '#', and its value is a list of all the bleets that include that hashtag.
{
'omg': ['hello #omgthere', 'as if#omg']
'idk': ['hi and#idk', '#idkwhat']
}
def read_posts(filename):
posts = {}
with open(filename) as f:
for line in f:
parts = line.split('+')
for bleet in parts:
hash = bleet.find('#')
tag = bleet[hash + 1:hash + 4]
if tag not in bleets:
bleets[tag] = []
bleets[tag].append(bleet)
return posts