Research Discussions
The following log contains entries starting several months prior to the first day of class, involving colleagues at Brown, Google and Stanford, invited speakers, collaborators, and technical consultants. Each entry contains a mix of technical notes, references and short tutorials on background topics that students may find useful during the course. Entries after the start of class include notes on class discussions, technical supplements and additional references. The entries are listed in reverse chronological order with a bibliography and footnotes at the end.
Class Discussions
Welcome to the 2019 class discussion list. Preparatory notes posted prior to the first day of classes are available here. Introductory lecture material for the first day of classes is available here, a sample of final project suggestions here and last year's calendar of invited talks here. Since the class content for this year builds on that of last year, you may find it useful to search the material from the 2018 class discussions available here. Several of the invited talks from 2018 are revisited this year and, in some cases, are supplemented with new reference material provided by the list moderator.
August 9, 2019
%%% Fri Aug 9 04:18:57 PDT 2019
Here is a reading list focusing on the most up-to-date research relating to McClelland's Complementary Learning Systems Theory first introduced in the mid 90s, amended several times over the last twenty years, but remains remarkably close to its initial formulation. If you only have time to read only one paper, I recommend the first article listed below [221], as it is particularly well written, organized in a convenient tutorial format, reasonably comprehensive given the size of the related literature and particularly relevant to solving several key problems in training deep neural networks. The folder named Reference Papers includes PDF for many of the papers listed below:
I. Complementary Learning Systems Theory:
Kumaran et al [221] —
What Learning Systems do Intelligent Agents Need? Complementary Learning Systems Theory UpdatedSchapiro et al [332] —
Complementary learning systems within the hippocampus: A neural network modelling approach to reconciling episodic memory with statistical learningKumaran and Maguire [222] —
The Human Hippocampus: Cognitive Maps or Relational Memory?Kumaran and McClellandPR-12 [223] (REMERGE) — Generalization Through the Recurrent Interaction of Episodic Memories: A Model of the Hippocampal System
Kirkpatrick et al [215] —
Overcoming catastrophic forgetting in neural networks
II. Foundational and Related Earlier Papers:
McClelland et al [258] —
Why There Are Complementary Learning Systems in the Hippocampus and Neocortex: Insights From the Successes and Failures of Connectionist Models of Learning and MemoryMcClelland and Goddard [257] —
Considerations arising from a complementary learning systems perspective on hippocampus and neocortexO'Reilly et al [289] —
Complementary Learning SystemsHuang et al [193] (LEABRA) —
Assembling Old Tricks for New Tasks: A Neural Model of Instructional Learning and Control
August 5, 2019
%%% Mon Aug 5 03:25:36 PDT 2019
Papers on the Neural Correlates of Mathematical Thinking
Mathematical and Analytical Reasoning:
Amalric and Dehaene [12] see Fig 2
Menon [259] — see description of hippocampal role
Iuculano et al [203] — comprehensive overview
Imagination and Hypothetical Reasoning:
Hassabis and Maguire [175]— see Fig 1, Fig 3 and Fig 5
Abstraction and Hierarchical Reasoning:
Koechlin and Jubault [217]
Badre and D'Esposito [24] — see Fig 6
Badre [26] — see Fig 1 and Fig 2
Badre and Frank [25] — see [132] for computational model
The relevant figures from the above papers are available here (PDF).
Miscellaneous Loose Ends:
Robert Nesse [279] has written a very interesting book on the evolutionary basis for many psychological disorders. See this recent book review in the Wall Street Journal for a representive sample of its reception. His earlier work with George Williams [280] established him as one of the founders of the field of evolutionary medicine. Robert Sapolsky, Michael Gazzaniga and Carl Zimmer are among those extolling his contributions to neuropathology and clinical psychiatry. Richard Dawkins' interview with Nesse in 2013 focuses on evolutionary medicine, but the examples that Nesse uses in responding to Dawkins illustrate the principle guiding both books.
"An evolutionary perspective on dire mental diseases encourages new perspectives that shift attention away from the easy assumption that because they are influenced by genes, they are caused by defective genes. It calls attention to new traits, fitness landscapes, and control systems that may result in vulnerability. What such traits might be is a very good question. They are unlikely to be things as obvious as creativity or intelligence. Instead, they may be things such as rates of neuron growth in early development, rates of neuron pruning in adolescents, and rates of transmission in neural networks. On a higher level, attributing meaning to tiny gestures by others may be increasingly useful up to some peak beyond which it crashes into sustained paranoia. I am all too aware that these are mayor speculations and that the actual systems are likely to be complex in ways that make them hard to grasp. Nonetheless, investigating how selection shapes traits that maximize fitness but leave some individuals vulnerable offers opportunities to look for causes that are not underneath the streetlamps of population genetics and neuroscience." — From: Randolph M. Nesse. Good Reasons for Bad Feelings: Insights from the Frontier of Evolutionary Psychiatry. Page 261. 2019.
Substitute "genetic pathways" for "effectively operated neurotic chains" in the following quote from Norbert Wiener, and you'll have an approximate version of the above: "The superiority of the human brain to others ... is a reason why mental disorders are certainly most conspicuous and probably most common in man ... the longest chain of effectively operated neurotic chains, is likely to perform in a complicated type of behavior efficiently very close to the edge of an overload, [and] will give way in a serious and catastrophic way ... very possibly amounting to insanity." — Norbert Wiener. Cybernetics, or Control and Communication in the Animal and the Machine. Technology Press. 1948. Page 151.
July 21, 2019
%%% Sun Jul 21 04:43:14 PDT 2019
I've been struggling to deal with the problem of naïve physics as it relates to (a) the state-space representation for reinforcement learning and action selection, (b) hierarchical and compositional modeling and sample complexity, and (c) the role of analogy in transfer learning across multiple domains / environments. The naïve physics problem broke the back of logic-based approaches to building AI systems. In his ACM Turing Award lecture, Geoff Hinton explains why this failure happened in the context of the debate over symbolic and connectionist models and machine learning. I'll tell you some interesting anecdotes on Monday if you're interested.
The other loose end that I'm trying to tie up concerns catastrophic forgetting, memory consolidation and the problem of continuous training in which some parts of the network are being modified by gradient descent, some by Hebbian learning, others by targeted replay exploiting episodic memory and still others by some form of adaptive fast weights. I grouped these problems into two categories or general challenges that I refer to as grounded thinking (related to embodied cognition and modeling physical systems) and lifelong learning (related to transfer interference and catastrophic forgetting) where the former is an apt phrase for what I have in mind and the latter is borrowed from Thrun [366].
This is not the same as the symbol grounding problem which is the problem of how words (symbols) get their meanings. In particular, the notion of grounding is not tied to symbols, linguistics or formal logic. It owes more to Charles Sanders Peirce's theory of signs, than it does to Frege, Kripke or modern day logicians including Jerry Fodor, John McCarthy and Zenon Pylyshyn. Here are my recent thoughts concerning the importance of embodiment in the context of grounded thinking — see July 17; an example of how Barbara Tversky thinks about the importance of gestures; — see July 18; and several examples of biological learning strategies that operate in specialized subnetworks on different timescales — see July 19.
Miscellaneous Loose Ends: Please don't interpret my enthusiasm for the ideas in Tversky's book as a wholsale endorsement of her entire theory. The same goes for the popular writing of Andy Clark, Christine Kenneally or any of the other popular accounts that I've mentioned in these notes. None of these books are intended as scholarly works; they serve as outreach and education for the general public, and allow the writer to explore ideas in a more speculative and accessible format than would be possible in a peer-reviewed journal. They also provide a source of inspiration that can be invaluable to researchers in machine learning and AI, as long as they don't get carried away.
I've contemplated the idea that natural language could serve as the language of thought [128], perhaps even supplanting other means of internal neural communication1. Tversky's book provided a new perspective allowing me to better appreciate the importance of the body — or any suitably-capable cognitive apparatus serving as a tightly-coupled interface between an agent and its environment / underlying dynamical system — in enabling cognition and grounding language. Natural language complements our innate means of communicating with one another and sharing knowledge and is indispensable from a cultural and technological standpoint.
July 19, 2019
%%% Fri Jul 19 04:44:06 PDT 2019
This entry considers several neural network training methods that address the problem of catastrophic forgetting and lifelong learning. Yoon et al [405] present a neural-network architecture for lifelong learning that addresses the several key challenges2 They compare their architecture — that that they call Dynamically Expandable Networks (DEN) — with Elastic Weight Consolidation Kirkpatricket al [215] and Progressive Networks Rusu et al [322]. In contrasting their approach with the other two, they note that "since we retrain the network at each task t such that each new task utilizes and changes only the relevant part of the previous trained network, while still allowing to expand the network capacity when necessary. In this way, each task t will use a different subnetwork from the previous tasks, while still sharing a considerable part of the subnetwork with them." While only the Kirkpatricket al paper makes any claims regarding biologically plausibility, this trio of papers is worth taking a look at.
Another way that the brain appears to support learning new memories on top of existing ones is through neurogenesis: see Bergman et al 2015 Adult Neurogenesis in Humans and Kempermann et al 2015 Neurogenesis in the Adult Hippocampus. The dentate gyrus is one of the few circuits in humans that is generally agreed to support neurogenesis3. As you may recall from Randy O'Reilly's talk in class, the dentate gyrus is believed to support some form of pattern separation [347]. As another example of how neuroscience can contribute the development of AI systems, Brad Aimone and his colleagues at Sandia National Labs explored adding new neurons to deep learning networks during training, inspired by how neurogenesis in the dentate gyrus of the hippocampus helps learn new memories while retaining previous memories intact. His simulation studies described in a 2009 Neuron paper [1] and summarized in a recent podcast [00:22:46], suggest a somewhat more complicated role for the dentate gyrus that involves both pattern separation and time-dependent pattern integration4.
You have probably heard that sleep plays a critical role in learning new skills. Matthew Walker is a sleep researcher at UC Berkeley and his lab is responsible for a number of important results relating to sleep and learning. In a recent talk at Google moderated by Matt Brittin, Walker said the following:
So, in the studies with rats, what we've done is had them run around a maze with electrodes in their brains and you can pick up this kind of electrical signature of learning as it is running around the maze, and let's say that you just make each one of those brain cells have a tone to it and so as the rat is running around a maze, you just hear this set of brain cell firing as the rat's brain is encoding the maze [bup, bup, bup, bup, bump, bup, bup, bup, bup, bump, ...] and then, what was fascinating in these studies, is that when you let the rats sleep, what you heard was the same sequence of tones replayed [bup, bup, bup, bup, bump, ...], it wasn't at that speed. It was 20 times more quickly [Walker repeats the same sequence of tones, up, bup, bup, bup, bump, ..., but much more quickly] and so what we see is that the brain is actually essentially replaying those memories almost as though what it's doing, firstly is scoring the memory trace or etching the memory trace more powerfully into the brain so that when you wake up the next day you can better remember the things that you learned before and we know that sleep is wonderful for doing that.That actually happens during deep non-rapid eye movement sleep what happens during REM sleep is something more interesting there the brain almost becomes chaotic and random, and that what we think is happening during REM sleep is that during deep sleep you take the information you've learned and you save it — you hold onto it, then it's during REM sleep that we say, based on the information that we've learned today, how does it interrelate with everything that we've previously learned, how do we figure out which connections we should build and which we should let go of and it seems as though dream sleep is a form of informational alchemy, that you start at the site — it's almost like memory pinball — you begin bouncing around the attic of all of your memories and saying should this be a connection, should this connection, ..., but REM sleep is almost like a Google search gone wrong that it's during REM sleep that you input your search term and it immediately takes you to page 20 which is about some bizarre thing that you think, hang on a second, is there really such a strange tangential link? It's during dream sleep that we test out the most bizarre, strange, associative connections, and that's the reason that you wake up the next morning, often having divine solutions to previously impenetrable problems. That's what dream sleep seems to be about as well. — see the video on YouTube at [00:35:00]
You've probably heard some version of this before. There's more detail in Walker's recent book [384] and on the website for his lab at UC Berkeley. I've included this here along with several relevant papers from Walkers Lab [305, 385, 351, 383], not for what it tells us about sleep in particular, but rather what it tells us about learning and memory consolidation, and perhaps carries with it some insights into catastrophic forgetting and training networks in which different subnetworks are trained at different rates or using different learning methods and local objective functions.
Miscellaneous Loose Ends: You can find an extended excerpt from Barbara Tversky's book [375] in the footnote here5. The excerpt features a number of studies that look at whether subjects rely on gestures in solving problems involving structural and dynamical reasoning and whether their problem solving performance benefits from the use gestures.
July 17, 2019
%%% Wed Jul 17 04:03:56 PDT 2019
This entry attempts to shed light on several issues relating to the programmer's apprentice and related applications, beginning with the idea of embodiment as an essential interface with the agent's environment. I skimmed Barbara Tversky's book [375] over the weekend — thanks to Gene Lewis for the suggestion — and listened to Michael Shermer interview Tversky on this podcast. The interview was too high level to be useful to me and the audio quality made it difficult to hear what she was saying, but I found her perspective as well as the examples and the studies she described in the book worth attention. Yesterday I started reading it more carefully during lunch as I wanted see how her theory relates to other work on embodied cognition starting with Kenneth Craik [78], Varela, Thompson and Rosch [377] and more recently Andy Clark [72] — all of which are more philosophical but interesting nonetheless.
The book covers a lot of ground, explaining as it does how the movement of our bodies influences almost every aspect of experience from our most grounded (physical) activities to the most abstract (metaphysical) flights of fancy. Her main thesis is that human thought is embodied cognition. Language takes a backseat despite its impact on human culture. Tversky is right about the role of gestures and signaling in humans and many other animals. The work of Lieberman [241, 239] and more recently Terrence Deacon [84] underscores this connection, emphasizing that language is evolutionarily pretty late — estimates vary wildly anywhere from 50,000 years ago to as early as the first appearance of the human genus more than 2 million years ago — leaving little time for natural selection to make dramatic changes. Andy Clark — whom Tversky quotes in the prologue of her chapter — has a particularly insightful take on this that I mentioned in the class discussion notes.
I recommend that you read, listen to or watch Andy Clark's Edge Talk on "Perception As Controlled Hallucination: Predictive Processing and the Nature of Conscious Experience". If you only have a few minutes, listen to the segment from 00:12:00 to 00:20:00 or read the first part of the conversation. The audio samples — begin listening at: 13:00 in the video — provide a compelling example of how prediction, priors and controlled hallucination conspire to construct our reality and guide experience.
If you've read the books I just mentioned you might think there is nothing new in Tversky's book. To get something out of it you have to deal with the fact that it is aimed at a general audience and there is a lot of relevant previous work that Tversky relies on to make her points. She writes well and she skilfully weaves the thread of her ideas into a larger narrative that integrates what she borrows from previous work, explains what she rejects or reinterprets and highlights what she brings new to the table. I understand why she didn't use mathematics to explain many of the basic concepts, but metaphor can be a clumsy tool for characterizing some of the phenomena she discussed. For the most part, you can interpret her prose as being consistent with the mathematics of neural networks. Any pattern of activation in the brain can be thought of as a thought vector, the set of all such vectors constitutes a Hilbert space and the transformations she alludes to later in the book are called either projections or transformations depending on what branch of mathematics you're coming from.
Everything inside the brain is abstract. Nothing about the real world has its exact counterpart in the brain including the features encoded in primary sensory cortex. Activations of networks in the multi-modal association areas are examples of composites that represent complex entities, trajectories within the corresponding vector spaces represent system dynamics, collocations in space-time represent relationships and together these correspond to the sort of phenomena that can be modeled using variants of interaction networks [32, 31, 409] and graph networks [402, 326, 7, 205]. It is interesting to look carefully at the DeepMind implementation of graph nets and the work of Wang et al [390] in analyzing the dynamics of running programs for program repair — see the examples shown in Figure 5, for their use of GRUs as components in a larger architecture [69].
Reading Tversky's book with an open mind is the worth effort. It sparked connections to my earlier thinking about relational reasoning and analogy as they relate to hierarchical and compositional modeling, as well as revisiting recent work in code synthesis as it relates to the programmer's apprentice as an agent embedded in the "code world" which I'll expand on in a minute. I particularly liked Tversky's treatment of the role of attention in how our behavior is coupled with movement and the exploration and exploitation of our environment — see Hudson and Manning [196] for an interesting take on this. Tversky notes that gestures include pointing which is the most basic form of reference, followed by iconic images and finally symbols all of which emerged prior to language.
There is no official book of gestures; there is no need, since gestures are a natural extension of our bodies — the design of which we share with our fellow humans along with our experience of the natural work in which we evolved. Tversky makes the case that mirror neurons are an important evolutionary development facilitating transfer learning and the rapid spread of knowledge and culture. Her treatment of perspectives is worth reading — Geoff Hinton in his ACM Turing Award lecture made the case that computer vision has failed to leverage frames of reference as the basis for learning relationships between objects that we perceive in our environment. There is much else in Tversky's book to warrant reading it cover to cover, but the goal here is not to slavishly emulate how humans think, but rather to gain insight into how AI systems intended to serve as experts in specialized domain might be architecturally organized so as to facilitate reasoning in their area of expertise. If you are interested in how the hippocampus represents abstract thinking, take look at this footnote6.
Having read Tversky, it is a useful exercise to think of the apprentice as an embodied agent with a body that corresponds to an IDE (Integrated Development Environment) and an environment that corresponds to a conventional computer, a small network of workstations or a large network of linked servers. In the following, we consider the simple case of a single computer. There is an important sense in which a computer provides a rich environment to learn in and — like our physical environment — is governed by a few fundamental principles whose emerging properties the agent can discover by exploration.
Programs represented as source code listings are static objects that have a great deal of inherent structure and latent dynamics. Think of source code listings as the DNA specifying algorithmic genotypes, the compiler as the reproductive machinery responsible for producing phenotypes (bodies) corresponding to running programs, the computer hardware as the environment in which running programs live and its peripherals - I/O devices - the means by which programs perceive, alter and are altered by the greater world beyond the confines of their (process thread instances) manifestations. An alternative analogy is to think of malware instances as the parasitic phenotype, computers as hosts and the internet as the world in which the hosts live — my imagination immediately seized upon Westworld but I was able to fend off the tempting meme.
Running programs are dynamic objects that manifest their behavior primarily though changes to memory including RAM, caches, ALU registers, call stacks, process-scheduling queues and input-output devices, just to name a few of the ways that running code can alter the state of its physical environment. The apprentice is just a program that lives in an environment that includes other running programs, that can write and run its own programs, observe their behavior as well as its own, and intervene to modify their own behavior to suit their purposes. The apprentice's "guild master" programmer is just another stream of data — actually multiple streams corresponding to different sensory modalities including voice and video, and its observations and interventions are analogous to the physical sensory and motor activities of a human moving through its environment.
Despite the fact that writing and running programs seems so much more difficult than playing Atari games — or Starcraft for that matter, "code world" has a lot of advantages in comparison with the simulated worlds of OpenAI Gym and DeepMind Open Source Environments. The set of rich environments is as diverse as there are different applications, different languages, different abstractions, different levels of complexity as in Karel and DrScheme. The distance between environments can be relatively small as in the case of different dialects of Lisp and variants for writing regular expressions. Or it could be large depending on the application, e.g., interactive graphics in C++ versus formatting scripts written in bash.
As an exercise, think about how our understanding of the dynamics of the world around us might emerge, as a child goes through the early stages of development, from helpless infant to curious toddler and on into later childhood. Think about how the infant brain is gradually assembled, neurons and synapses are over-produced and then pruned in late childhood and early adolescence. How all of this happens against the backdrop of the child learning about the environment, becoming familiar with its own body, creating the diverse maps that represent and facilitate our situational awareness, and how the dynamics of the body interact with the dynamics of the environment in which it lives.
What would the earliest maps look like? They probably would be quite primitive early on and yet the foundations must have been laid relatively early, exploiting pathways whereby sensory information enters the brain in order to construct the basic groundwork upon which to lay down the traces for a more nuanced representation that can accommodate fast growth of the growing child. Besides a naÏve physics representation of the physical environment in which action is played out, might there also be the beginning of the simplest mental models corresponding to its primary caregivers. Apparently a sense of self emerges rather late within the early developmental window that characterizes the first 3 to 4 years [277, 274, 174, 83].
Keep in mind that the brain is still very much a work in progress in this early stage. As an analogy, I imagine a child playing in a sand pile in the midst of a construction site where a building is being erected around the child and construction workers are scurrying about carrying tools and building materials. The world is being gradually revealed to a brain that is constantly preparing itself to take into account yet more complex aspects of the environment in which it behaves. How would it go about doing this? What neural structures and cognitive biases are available to bootstrap this process? What affordances does the brain, body and environment have to offer to make the job easier or even simple?
Now think about the extent to which the apprentice will have to construct a complicated edifice encapsulating what amounts to a huge amount of information even when restricted to the task of writing programs. For example, consider the seemingly simple case of the assistant predicting the consequence of evaluating an assignment, e.g., X = X + Y x 3 or a relatively simple conditional statement, if P then A else B. How many years of education were required to gain enough knowledge to perform this relatively simple task and how might we accelerate arriving in this enlightened state? Perhaps not with the same level of skill as an engineer, but more along the lines of a child pecking away at calculator.
The task of learning how to perform operations that were difficult for us in grade school might be facilitated by the assistant performing the equivalent of a baby grasping, waving its arms and rocking back and forth in its crib. Remember the toys often attached to baby cribs that look something like an abacus with brightly colored wooden beads that slide back and forth on metal rods? It's important that the beads are different colors and make a satisfying clicking noise when they collide with one another. The colors and sound attract the infant while the different ways one can arrange the beads engage the toddler. Perhaps such exploratory play lays the groundwork for learning simple math operations.
Now might be a good opportunity to review the material on hierarchical and compositional modeling here and perhaps skim the Wikipedia pages about J.J. Gibson, Jean Piaget, and Lev Vygotsky and then read the "Neural Programmer-Interpreters" paper by Scott Reed and Nando de Freitas [311] and "Learning Aware Models" by Amos et al [13]7.
Miscellaneous Loose Ends: I've placed a copy of my bibliography references in BibTex format here for your use as a convenient reference. There are over 5,000 references most with abstracts and primarily concerning topics in neuroscience, machine learning and computer science. I use it primarily as a memory palace for technical books and papers that have proved useful and are likely to remain relevant to my research.
July 12, 2019
%%% Fri Jul 12 05:56:38 PDT 2019
Some of you met with me on July 2nd to discuss the possibility of writing an arXiv paper loosely based around the content of this year's course. The plan we discussed involved organizing the paper around a list of major challenges standing in the way of developing sophisticated AI systems like the programmer's apprentice. A running theme of the paper would be how neuroscience has led the way to important algorithmic and architectural innovations. An amended version of the slides I went over in our discussion is available here. The amendment was to add a slide at the end on how insights from fMRI studies have inspired hierarchical and compositional models to support action selection across multiple domains.
At the end of the meeting I asked for volunteers willing to take the lead on one of the six challenges, and said that whether or not the paper happens depends on whether there are enough of students willing to put substantial effort into contributing to such a paper. I know you are busy this summer and so this may not be a good time for you to make such a commitment, but it's not as though you'll have a lot of free time once classes start. In any case, the response to my request for contributing authors yielded no takers. For the July 2nd meeting, I selected those whose projects and interests were most closely aligned with the paper as I envisioned it, reasoning that, if there were no serious volunteers from that subset, then the paper wouldn't get done by the end of August.
So rather than burden you with more work this summer, I've decided to write the first draft of the paper by myself. This will probably take me the rest of the Summer, but I can guarantee it would take substantially longer if there were more contributing authors even if those authors were really committed to helping out. See Brooks's Law from The Mythical Man-Month if you want to understand my rationale. Depending how it goes, we can revisit including additional authors in the Fall. As an added benefit for prospective co-authors, using the first draft as an extended outline, it will be much easier for you to figure out whether and how you might contribute to a second draft. In the meantime, enjoy the rest of the summer.
July 11, 2019
%%% Thu Jul 11 02:11:54 PDT 2019
After the lecture that I gave last week concerning some of the major challenges to progress in building systems like the programmer's apprentice, I realized that, while it addressed the problem of how to organize procedural (subroutine) memory in a manner that is both hierarchical and compositional, it did not make a compelling proposal for generating a rich enough state representation to precisely identify the different contexts in which to deploy particular subroutines. What was needed was a state space representation rich enough to capture the essential characteristics of situations in terms of factors that directly speak to the dynamics of acting in difference contexts.
For example, altering a piece of code designed for one purpose to serve another requires that you understand the consequences of the changes you might need to make in order to evaluate different alterations. Specifically, the state representation needs to be rich enough to identify the dynamics governing the state in which you're acting. The dynamics of Tetris is different from the dynamics of Pac Man. Both of these games have many variants with different layouts and characters but essentially the same rules and physics engines. Experienced players can easily determine whether a game is a variant of one or the other of these classic games and apply their general knowledge to the specific instance at hand.
Making such distinctions requires that an agent ignore the superficial features of the game at hand and focus on what counts, namely how do the relevant pieces of the game move and what control does the player have in terms of intervening in the action so as to earn points. In some variants, the physics might depend on the color or size of an object, in which case those characteristics are relevant to understanding the underlying dynamics and the player's ability to influence the state of the game. Some players are familiar with dozens if not hundreds of games many of which exhibit Tetris-like dynamics in some parts of the game, Pac-Man-like dynamics in other parts and perhaps a combination of the two in still other parts. The term analogy is often used to describe the relationships between such games.
In the two weeks since the first lecture, I've been following in the intellectual footsteps of Hamrick, Battaglia, Botvinick, Hassabis and others trying to gain some purchase on what's missing from the model I'm proposing. This slide — laid out in the same style as those in the first lecture — includes a theoretical claim that addresses the missing pieces alluded to earlier, pointers to studies pertaining to the relevant neural correlates and references to recent work on learning relational models suggesting how we might go about developing systems that support the necessary functionality. In the coming weeks, I will flesh out a neural-network architecture design that implements this functionality, and develop an outline for the promised white paper summarizing the complete architecture.
July 9, 2019
%%% Tue Jul 9 04:55:38 PDT 2019
In developing hierarchical and compositional models to support action selection across multiple domains, general method to differentiate between different contexts for acting that primarily depend on activity in the parietal and temporal cortex corresponding to the association areas that produce abstract representations incorporating sensory data across all modalities. The problem is that such representations — at least in the case for standard type of network architectures, e.g., stacked convolutional neural networks with recurrent connections and attentional layers, used for vision or speech — do little to separate out the features of different environments that are most relevant to action selection8.
In our discussions in class, Jessica Hamrick and Peter Battaglia emphasized the importance of rich relational models that capture the distinctive entities, relationships between entities and co-variances among those relationships that characterize different environments and assist in prediction and action selection [170, 32, 171, 326, 409, 327, 392, 33, 31, 236]. These models — encompassing the ontological, relational and dynamical properties particular to specific environments — appear to be exactly the sort of representations one needs in order to differentiate contexts for the purpose of selecting specialized strategies (subroutines) for reasoning and acting.
There are a number of theories hypothesizing that analogy is pervasive in human reasoning and may even constitute the core of human understanding — Douglas Hofstadter's theories being the mostly widely cited9. For our purposes, an analogy is just a compelling model mapping from one domain to another — one that aligns entities, relations and dynamics in such a way as to facilitate borrowing strategies from one domain in order to apply them in another. We are constantly creating, refining and evaluating such models based on how well they help us make predictions and plan for the future. Over time we construct a rich repertoire of models that we can draw upon in different circumstances10.
It would interesting to see if we can tease apart the functionality as described above in terms of a basic capability tied more closely to direct sensing of the environment and a more sophisticated level of reasoning that operates on top of this basic capability allowing for more abstract thinking. In particular, I'm interested in the neural-network architecture question of how imagination-based planning and relational modeling as implemented in graph-nets-like component networks might fit in a larger architecture that aspires to solving problems in a wide variety of domains. Such a division of labor between a basic — common across a wide range of species — and a more sophisticated capability — found in humans but perhaps not other animals — makes sense from an architectural and possibly evolutionary perspective, if not from a strictly-observed anatomical criterion.
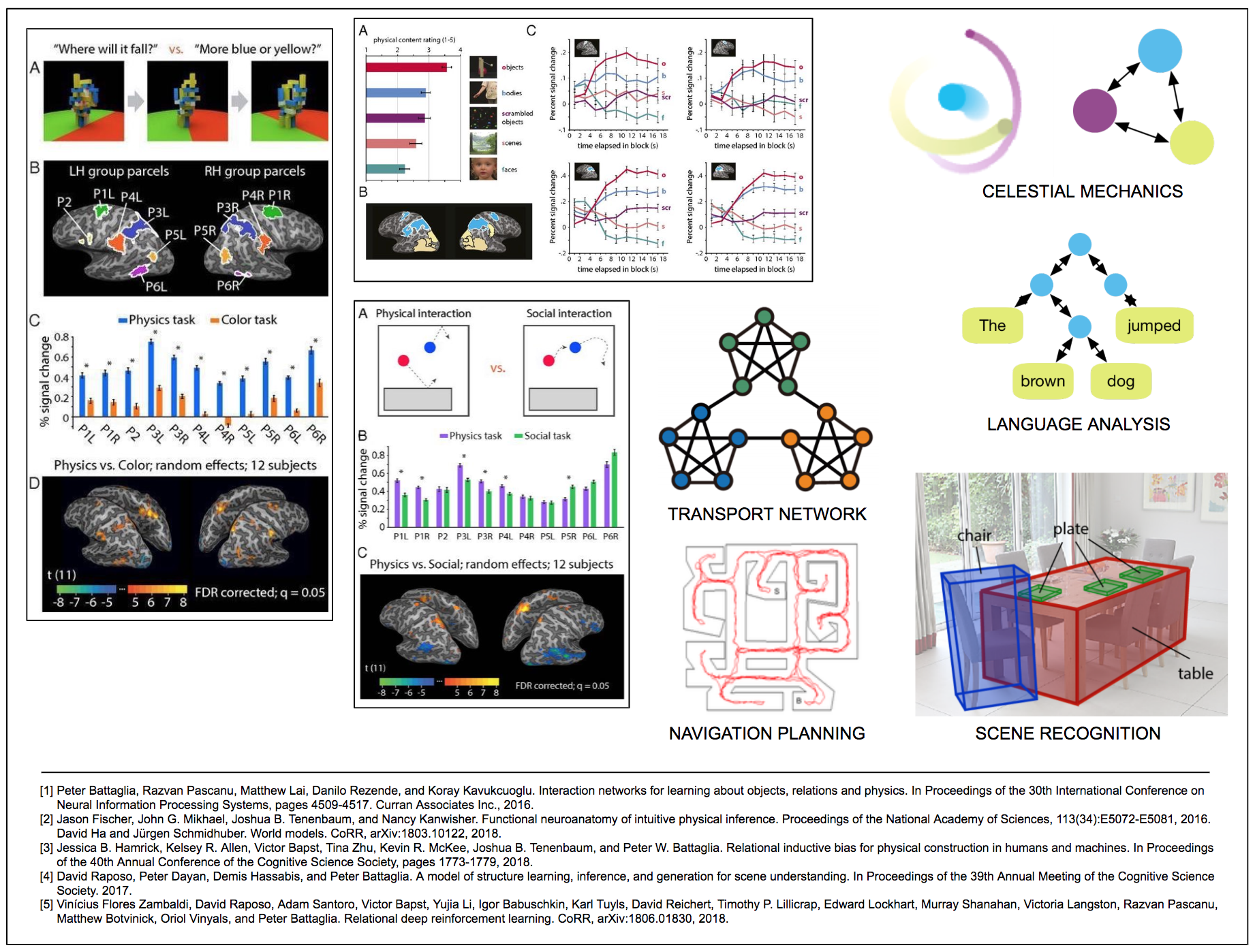 |
Several studies offer speculation along similar lines [308, 309, 78]. Recent fMRI studies from the labs of Nancy Kanwisher and David Dilks attempt to localize activation related to the use of such models [212, 126]. Their results indicating activity in the parietal and frontal cortices when subjects are watching or predicting the unfolding of physical events agrees with the hypothesis that learning and deploying such models has its basis in the sensory cortex and abstract association areas in particular; that this basic capability is likely conserved across mammals and perhaps birds, cetaceans and cephalopods as well; and that this activity is unconscious and effortless. Whereas many of the more sophisticated applications of this basic core are situated in the frontal cortex; are less well distributed across the animal kingdom; and some are found only in human primates.
Still, it could be the case that such intuitive physical inference — what is often referred to as naïve physics reasoning in the AI literature — is carried out by strictly the same domain-general cortical regions that contribute to a wide variety of tasks, termed the multiple demand (MD) network11. Responses in the MD areas generally scale with task difficulty, and this network is thought to provide a flexible problem-solving framework that contributes to general intelligence. To test whether the physics-responsive areas identified in the first three experiments are the same as the MD network — see the attached slide, the authors separately localized the MD network in the same twelve subjects who participated in the first two experiments, thereby providing support for there being two separate networks [126].
July 3, 2019
%%% Wed Jul 3 02:43:15 PDT 2019
Here are my slides from yesterday complete with post hoc presenter notes that I dictated this morning. The transcription is likely include errors and omissions so please don't disseminate. The full lecture and discussion was two hours and so my notes constitute a substantially abbreviated version of the talk. As promised, I've supplied related content for the challenges discussed in class.
Each challenge is paired with a link to an earlier entry in the class discussion list providing an introduction to one facet of the related issues. In most cases, the entry selected is one among many to be found in the class notes. You might also find it useful to search in the introductory material, e.g., the section on accelerating language learning. Here's the annotated list of technical challenges:
Item 1: catastrophic forgetting — June 27, 2019 Thinking Beyond Hippocampal Place Cells
Item 2: sample complexity — May 31, 2019 Complex Environments Varied and Numerous
Item 3: hierarchical and compositional — June 25, 2019 Hierarchy, Abstraction, Compositionality
Item 4: relational and analogical reasoning — July 9, 2019 Relational Models, Planning Contexts
Item 5: modeling other minds — July 29, 2019 Inner Speech, Language as Thinking
Item 6: language and communication — June 17, 2019 Why No Dedicated Language Areas
June 29, 2019
%%% Sat Jun 29 03:08:45 PDT 2019
Here's the current plan for the course summary document — this plan is provisional and we'll be discussing the content and focus of the proposed paper at length in our meeting tomorrow. We will meet tomorrow = Tuesday, July 2 from 2-4 PM in Gates 358. The room is larger (seats 26) than I thought we would find on such short notice and so if there is someone else on your team who is in town and free during that period, feel free to invite them. Please each of you invite no more than one person, if we decide to go forward I will arrange for suitable room, invite everyone who handed in a project and schedule the next meeting with more advance notice.
This class was larger than in the past with a total of 35 students taking the class for credit and receiving a final grade. I don't expect everyone who took the course this year to participate in writing the final summary document. However, I will proceed for the time being as if everyone in the class is committed to contributing and plan accordingly.
The provisional plan is to update the content in this year's introductory notes to account for what we learned and also speak to the remaining challenges that stand in the way of implementing a fully-functional programmer's apprentice.
For each of the original challenges plus any additional ones we decide to include, the plan is to integrate brief mention of each challenge in the primary text and then write a more detailed analysis in an appendix. This strategy is similar to the one we used in writing the summary paper for the 2013 class.
I will send out a calendar invitation containing a Hangout link. If someone is familiar with Zoom and would like to help out that would be most appreciated, since I will preoccupied with getting my notes and slides together for the discussion. If you invite someone, you can share the hangout link.
Miscellaneous Loose Ends If time permits and one of you is willing to invest some effort in doing some of the background research, I would like to say something about natural language processing and narrow-domain dialogue management in the class summary paper. While we didn't talk about it in class, I had several interesting conversations with students last quarter. Here are few observations that we might unpack in the proposed arXiv paper. Each entry includes a footnote that lists one or more issues / perspectives that may be useful to include in a corresponding appendix, but I am open to considering other options.
It is useful to think of language as natural selection's way of enabling human beings to share thoughts12.
Inner speech is self-directed dialogue for learning how to speak, rehearse and evaluate what to say14.
Generating and understanding speech is a probabilistic process of action selection and interpretation15.
Language is hierarchical, compositional and, importantly, the direct product of goal-directed planning16.
Acquiring linguistic facility requires both physical grounding and developmentally-staged learning17.
Here are a few ideas to think about in developing a technology to bootstrap the programmer's apprentice;
synthetic data — create ablation training examples by strategically modifying working software;
motor mimicry — create an invertible IDE in analogy with the role of mirror neurons in primates;
scripted base — employ a scripting language like python and hierarchical network to generate data;
developmental — recapitulate child development by building language facility from the bottom up;
curriculum — leverage multiple objective functions and combine intrinsic and extrinsic rewards;
I highly recommend that you read, listen to or watch Andy Clark's Edge Talk on "Perception As Controlled Hallucination: Predictive Processing and the Nature of Conscious Experience". If you only have a few minutes, listen to the segment from 00:12:00 to 00:20:00 or read the first part of the conversation18. The audio samples — begin listening at: 13:00 in the video provide a compelling example of how prediction, priors and controlled hallucination conspire to construct our reality and guide experience.
June 27, 2019
%%% Thu Jun 27 03:14:09 PDT 2019
In class discussions, we talked about place and grid cells in the hippocampus, opining that the hippocampus is much more general than this usage implies. Dmitriy Aronov a postdoc working in David Tank's lab at Princeton conducted some interesting experiments using rats in a virtual environment and obtained recordings of hippocampal cells similar to those from rats running mazes in a physical environment. Continuing his collaboration with Tank after moving to Columbia University, Aranov trained rats to traverse an auditory rather than a physical space. The animals used a joystick to move through a sort of sound maze — a defined sequence of frequencies. When the rat moved the joystick, the frequency increased and kept increasing for as long as the animal deflected the joystick:
 |
The researchers discovered a set of cells that act very much like place cells [17]. Instead of firing when the animal is in a specific location, these 'sound cells' fire when the animal hears a specific tone. "[i]t has the classic pattern of the hippocampal place cell," Aronov says. This Simons Institute article cites related work by Beth Buffalo and her collaborators at the University of Washington and Eva Pastalkova, now at the Howard Hughes Medical Institute's Janelia Research Campus. Their findings show that the same neural circuitry can map space during visual or physical exploration, which hints at the representational flexibility of entorhinal circuits — Tank and Aronov mention that their sound experiments were inspired in part by Buffalo's research [320].
Most studies of navigation in the hippocampus and entorhinal cortex focus on specific types of cells — grid cells, place cells, head-direction cells and others. However, these cells make up only a small fraction of the neuron population in those brain regions. Lisa Giocomo, a neuroscientist at Stanford University, is developing new ways to study the role of the remaining cells. Giocomo points out that this type of unbiased approach will be important for gaining a complete view of the function of the entorhinal circuit. "It is hard to fully understand what role the entorhinal cortex is playing in behavior if we don't even know what over half of the neurons are encoding," she says. "This approach allows us to reveal what the majority of neurons are encoding without requiring predefined assumptions for what tuning should look like." SOURCE
This is just a sample of current papers that are redefining and broadening the concepts of place and grid cells. It would be interesting to explore what these new perspectives suggest in terms of building neural network models of the hippocampal-entorhinal-cortex complex. In a recent paper in Current Biology [42], Andrej Bicanski and Neil Burgess propose that "grid cells support visual recognition memory, by encoding translation vectors between salient stimulus features. They provide an explicit neural mechanism for the role of directed saccades in hypothesis-driven, constructive perception and recognition, and of the hippocampal formation in relational visual memory." A concensus is building that operates on a relatively general and functionally diverse set of abstract patterns, covering a wide range of behavioral and cognitive requirements. SOURCE
On a related note, a group of researchers at DeepMind have developed a theory of hippocampal function that recasts navigation as part of the more general problem of computing plans that maximise future reward. In a recent paper [350] in Nature, the authors write that "[o]ur insights were derived from reinforcement learning, the subdiscipline of AI research that focuses on systems that learn by trial and error. The key computational idea we drew on is that to estimate future reward, an agent must first estimate how much immediate reward it expects to receive in each state, and then weight this expected reward by how often it expects to visit that state in the future. By summing up this weighted reward across all possible states, the agent obtains an estimate of future reward [...] we argue that entorhinal grid cells encode a low-dimensionality basis set for the predictive representation, useful for suppressing noise in predictions and extracting multiscale structure for hierarchical planning." SOURCE
June 25, 2019
%%% Tue Jun 25 02:51:29 PDT 2019
I've continued to develop ideas on how to support hierarchy and compositionality within a reinforcement-learning framework. I've found several papers suggesting that something like my context-based approach to representing abstract subroutines coupled with the method of augmenting the neural state vector / current pattern of activations in working memory is on the right track. The evidence is in the form of fMRI studies that show patterns of activity in the PFC consistent with such a theory, and biologically-plausible implementations of the approach that demonstrate how such a strategy improves on flat, indecomposable approaches.
The basic idea is simple to understand. The PFC employs neural circuits that alter and enhance working memory to create an augmented context that encodes information about the current state of ongoing planning. This context serves as the input to action-selection circuits of the basal ganglia and thalamus. Relevant circuits in the PFC implement a meta-controller that learns to construct this augmented context and supports abstract actions whose primary consequences correspond these working-memory enhancements. Absent in the papers I've read is an account of how the brain avoids catastrophic forgetting [150], nor is there any discussion of the depth or degree of integration of the hypothesized biological solution.
The proposal outlined earlier, deals with catastrophic forgetting and supports arbitrary depth by taking advantage of the properties of a dynamic external memory implemented as a differentiable neural computer [154]. It was not meant as a biologically plausible model, rather as a hybrid, biologically inspired but practically designed to circumvent the computational limitations of human brains. The earlier proposal also provides a link between biologically-plausible action selection and conventional-computing program emulation albeit with the benefits and limitations of differentiable models.
What follows is a bibliographical reference catalog including papers most relevant to the above discussion. For evidence relating to the existence and neural correlates of the suggested model of how the human brain handles hierarchy and compositionality in planning and action selection see Badre and Frank [25] and earlier work by Koechlin et al [218], Badre [26], Badre and D'Esposito [24] and Dehaene and Changeux [92]. For work specifically on hierarchical reinforcement from a cognitive neuroscience perspective see Botvinick [56] and Botvinick and Barto [54].
For biologically-plausible simulations of how this sort of hierarchical inference might be implemented and demonstrating it improving on behavior generated by a flat / unaugmented models, see Reynolds and O'Reilly [313]19, Frank and Badre [132] and Rasmussen et al [310]. For early influential attempts to develop hierarchical reinforcement learning see Kaelbling [210] — macro-operators for Watkin's Q-learning algorithm, Sutton et al [358] — temporal abstractions using options, Hauskrecht et al [176]20 — temporal abstraction using macro-actions, and Dietterich [109] — the MAXQ value function decomposition. For more recent approaches see Sahni et al [325] — skill networks, Rosenbaum et al [319] — routing networks and Silver et al [340] — policy networks.
For your convenience, I've uploaded PDF documents for all of the papers cited above to my Stanford class website. You can find them here — if challenged for access, type student for user and urwelcome for password. It should be easy to map from the bibliography below to the file names corresponding to the cited papers.
References:
June 17, 2019
%%% Sat Jun 15 04:39:30 PDT 2019
I've been reading your final project reports for a few days now. Highlighting various paragraphs and adding my comments in the margins, and what I notice is that there are two kinds of commentary I tend to make. One has to do with problems you've encountered in training, often in the form of perplexing cases in which an algorithm that you're confident should be an improvement on the state-of-the-art turns out not to be nearly as good as the competing algorithm — that is it appears to be given the experiments you were able to run in the relatively short time allowed for completing your class project. The second has to do with the complexity of the networks that you're using and the reasons you have for selecting particular technologies like variational auto encoders, generative adversarial networks, convolutional networks and different flavors of Long-Short-Term Memory, Gated Recurrent Unit Neural Networks, or whatever happens to be the neural network architecture du jour.
On the one hand, these are the sort of comments you routinely hear in conversations with Google software engineers concerning what architectures work and what ones are difficult to train and what sort of alchemy one has to invoke in trying to eke out a little more performance from a given architecture. On the other hand, this makes it blatantly clear that we don't have the tools that engineers need in order to solve these common problems with any confidence of a successful outcome. There are wizards among us who can iterate quickly, generate synthetic data to expand existing data sets and experiment with different types of models — often dozens of variants in hundreds of different combinations, all run in parallel — and then absorb all this knowledge and apply it to the problem at hand. They are however as rare as hen's teeth and even these adepts routinely fail on the harder problems, especially those involving novel data sets or new architectures.
When I read your tales of woe, I can commiserate with you, but I can't tell you how to avoid such problems in the future, and I can't suggest any particular tools that would help you solve the specific problems you describe in your project reports. I started to collect a list of the major issues standing between us and developing human level AI, or for that matter less ambitious technologies capable of mastering even a few of the everyday skills we humans take for granted. In thinking about how we might summarize what we've learned this quarter, it occurs to me that in terms of a useful paper that we might collaborate on together, perhaps the most valuable thing we could do is draw upon what we've learned concerning how to leverage ideas from cognitive neuroscience and explain in some detail why effectively exploiting those ideas is nontrivial — expanding on the list below — and suggesting some possible avenues for how we might correct this.
Here is a preliminary list of major technical issues standing in the way of progress:
Item 1: catastrophic forgetting — clearly we need to be able to learn across multiple time scales, constantly switching between different types of problems, simultaneously exercising different skills and requiring different approaches to learning in different parts of large neural network architectures, especially those with lots of recurrent connections. For example, in some theoretical models of episodic memory in the hippocampal-entorhinal complex, there are least three different types of learning occurring all at once in multiple nested recurrent loops. Imagine continuous training in which some parts of the network are being modified by gradient descent, some by Hebbian learning, others by targeted replay exploiting episodic memory and still others by some form of adaptive fast weights. [See Mattar & Daw and Hinton & Plaut]
Item 2: sample complexity — also related to environmental (Kolmogorov) complexity and the problem of transfer learning — the ability to learn new skills and apply them in novel situations seems so natural to us that we will have to make an effort to appreciate just how hard these challenges are likely to be as we tackle increasingly more complicated applications. Many of the skills we have been contemplating for the programmer's apprentice are likely to require some form of curriculum learning or applying what we know about developmental psychology in order to efficiently learn those skills simultaneously in the midst of everyday activities, e.g., "What does this case statement do?", "How do I set a break point in the debugger?", or "Can I substitute an integer for a float in this expression?" [See Kulkarni]
Developmental psychologists believe that most animals learn what they need to by applying strategies that are baked into their genome allowing them to quickly acquire critical survival skills. Instincts that guide and shape rapid learning may also serve to restrict what an animal can learn. It seems likely our built-in instincts are substantially less powerful but also less restrictive. Instead we rely on an extended developmental period in which we essentially learn how to learn, a skill that separates us from most other animals. The challenge is to design artificial systems that learn how to learn by exposure to the right sort of feedback and a diverse set environments in which to experiment. [See Zador]
Item 3: hierarchical and compositional modeling — these two characteristics are common in combinatorial / symbolic architectures. Connectionist models are inherently hierarchical and convolutional models are the epitome of compositional architectures. So far, however, developing hierarchies of composable subroutines that exhibit the sort of compactness and modularity we find in conventional (symbolic) computing libraries has eluded us. While there has been a recent trend to consider ways in which connectionist models might handle graphs and trees, it may be that the way human brains handle hierarchical structure is very different from the tree structured models that dominate our current ways of thinking about the problem.
Item 4: relational and analogical reasoning — while an important focus for earlier work in cognitive modeling and linguistic inference, e.g., Douglas Hofstadter's Gödel, Escher and Bach and the work of Dedre Genter and Keith Holyoak comes to mind, it is only recently that the rising tide of deep learning has begun to look at this seriously. As a means of facilitating transfer learning between superficially different domains these methods provide a powerful way to adapt and reuse hard-won procedural and declarative knowledge. Here again we may find ourselves somewhat misled by the specific emphases in some of the older work in cognitive science. Perhaps this is a case where identifying and analyzing the neural correlates of analogical reasoning might yield substantial dividends.
Item 5: reasoning about other minds — conventionally referred to as theory of mind modeling, this area of study is I believe muddied by a misguided belief that this sort of reasoning is intrinsically deep and conceptually hard to get a handle on. Contrary to this view, researchers like Michael Graziano and Matt Botvinick focus on what they consider to be a core antecedent to such reasoning in our ability to construct and apply models of our own bodies, essentially determining the boundaries of the semipermeable, mental, physical and social membranes that separate "us from them" and dealing with the ambiguity that results when the boundaries between organisms are mutable and depend upon context.
From these body centric models and relating to what is often referred to as embodied cognition, it is easier to imagine the emergence of a sense of "self" and its separation from "other". If you don't get too caught up in trying to encompass what it means to have a mind, it is relatively straightforward to think about why having some fundamental sense of self would arise as a natural consequence of evolution, as would an inclination to group together with closely related kin to improve our chances of reproductive success. Maintaining social and personal boundaries is important for survival despite the accompanying socially-divisive and deeply-seated distinction between "us" and "them".
From a personal sense of self and the realization that we are able to reason about other things and other animals including humans, it is not a huge step to infer — or at least accommodate from a purely pragmatic perspective — that other inanimate objects around us might also be able to reason about their environment and protective of their persistent selves. Again making this explicit as a theory of mind is less fraught with difficulty than the philosophical conundrums that occupy those of a more academic leaning. Here again Graziano, Botvinick, Rabinowitz and others with a more practical bent seem to have no trouble grasping this. The practical problem of how one integrates such thinking in a general strategy for planning and problem solving and a better understanding of how one might learn such models or build upon some instinctual or developmental seed of inspiration is an open and fascinating technical and engineering challenge. [See Rabinowitz]
Item 6: language and communication — despite decades of academic study in the fields of computational linguistics, natural language processing and developmental psychology, we appear to be at a loss for developing theories that can be used to formulate robust, practical language learning. Delving into the background literature is not for the faint of heart, and the acrimonious debates that played out within and between the various communities with a stake in this endeavor are difficult to undestand for those of us who weren't raised in the one of the major factions that characterize these disciplines.
You could of course go back to Chomsky, Jackendoff, Lieberman, Fodor, Pinker, Pylyshyn, Savage-Rumbaugh, etc., but I believe there is a more fundamental level that starts with primitive signaling and builds in easy-to-learn stages to the subtle instrument of human social interaction that is the basis for culture and civilization as we know it. I'm an advocate of starting out with basic signaling and semiotic primitives and following the developmental arc apparent in the interaction between parents and their children and depends, not on the child possessing an instinct for learning language, but rather on the child's parents possessing an instinct for teaching their children how to learn. [See Deacon]
Editor: That was long and discursive, but I expect you're used to that by now. If I was sure about what I was trying to convey, I would have simply written the paper, but I'm not sure and I am reasonably confident that no one else has cause to believe they have the definitive answers either. Hence my reaching out to you, inviting you to participate and puzzle out some of the issues listed above. Not solve the problems so much as articulate them clearly and motivate them convincingly. If this sounds like something you'd like to contribute to, I'll create a forum where we can discuss this with the goal of writing a white paper for arXiv.
References:
%%% Mon Jun 17 05:41:24 PDT 2019
Here is a trick question. What do the neural circuits in Wernicke's area do? Broca's area? Basal ganglia? What if circuits in your reptile ancestor's brain did X and millions of years later homologous circuits in your brain were demonstrated to do Y? What if basal ganglia in Homo sapiens "ran substantially faster and utilized more parallel connections" than basal ganglia in Homo erectus?
Daniel Everett [121] in Chapter 6 of How Language Began: The Story of Humanity’s Greatest Invention makes the case that —
Neither the brain nor the vocal apparatus evolved exclusively for language. They have, however, undergone a great deal of microevolution to better support human language. It is often claimed that there are language specific areas of the brain such as Wernicke’s area or Broca’s area. There are not. On the other hand, in spite of the lack of dedicated language regions in the brain, several researchers have shown the importance of the subcortical region known as the basal ganglia to language. The basal ganglia are a group of brain tissues that appear to function as a unit and are associated with a variety of general functions such as voluntary motor control, procedural learning (routines or habits), eye movements and emotional function. This area is strongly connected to the cortex and thalamus, along with other brain areas. These areas are implicated in speech and throughout language. Philip Lieberman refers to the disparate parts of the brain that produce language as the functional language system [19]. From Chapter 6 How the Brain makes Language Possible [121].
To a large extent, Everett's thesis is borrowed from Philip Lieberman who has spent a good deal of his professional life gathering evidence to support these claims. Lieberman's paper On the Nature and Evolution of the Neural Bases of Human Language [20] is well worth reading if you haven't the time to read one of his longer treatises such as Human language and our reptilian brain: The subcortical bases for speech, syntax and thought [19] or Toward an Evolutionary Biology of Language [239]. If you haven't even the time to read [20], you can read or skim the following notes, to understand the basic ideas.
%%% Sun Jun 16 06:23:47 PDT 2019
One thing you learn from reading evolutionary neurobiologists is that — possibly without exception — no part of the brain does just one thing. By that they don't mean that a given part of the brain might have once done X and now does Y, but rather that if it ever did X and now does Y that it most certainly still does X. This is especially relevant in understanding the origins of language since it is such a late addition to our repertoire of cognitive capabilities. In particular, the identification of Wernicke's area and Broca's areas as language areas — a notion that persists to this day despite an overwhelming amount of evidence to the contrary — is misleading; the real question for us is what role do these two areas play in the human brain that natural selection exploited this role in the evolution of language.
I've been reading Philip Lieberman [241, 240, 239, 19] and Daniel Everett [121] focusing on their accounts of how language evolved in human beings, and the first thing you learn from them is that while a fully capable language of the sort we now have involves relatively complex syntax, much of it relies upon features that were present in our — and some other animal's — use of signs, signals and referential behavior. For example, consider the way in which the various components of phrases — whether spoken or signed — are combined in ways that avoid ambiguity and encourage specific interpretations, and similarly in the composition of two or more phrases in generating more complicated interlocutory constructions.
I was particularly taken by a comment made by Daniel Everett in which he described the function of the basal ganglia as primarily having to do with the selection and deployment of both individual actions and routinely repeated sequences of activity corresponding to what we've been calling subroutines or simply routines, including activity of a purely cognitive sort. Everett suggests that it is useful to think about such activity is consisting of simply thoughts, and that the role of the basal ganglia is essentially to transform one thought into another — just as one action leads to another depending upon the particular context in which they occur. I should say — and Everett gives credit where credit is due — that Everett is channeling Lieberman here, but Everett also provides a good deal of original commentary and insight based on his decades of fieldwork as an anthropologist and linguist.
From this viewpoint, the basal ganglia is just machinery for transforming thoughts and the thoughts are no more than patterns of neural activity in the brain. This way of thinking is particularly agreeable to those of us who think of the weight matrices that specify how one layer of a neural network depends on another are transformations from one vector space to another, but it is also useful as a thought experiment in thinking about how language evolved. It seems a bit contrived to think of our experience of the moment as a point or vector in high-dimensional Hilbert space. Surely this physical space that surrounds us is more complicated than a single point. Indeed a single point in isolation conveys little information. However, a point embedded in a space populated by millions of such vectors conveys a good deal of information assuming that the points and the relationships between them as encoded in the transformations that relate one point to another are grounded in — that is to say they can be reliably mapped onto — the physical environment experience through our senses.
Relevant to our earlier comments about Wernicke's area and Broca's area, given that damage to the former often results in deficits relating to the understanding of language and damage to the latter often results in deficits relating to the generation of language, what might that tell us about the general function of these two areas. Considering that neither area is anatomically or cytoarchitecturally coherent, to avoid confusion in the sequel we refer to them generically as regions. Everett and Lieberman take a step backward and ask the question how are these regions wired together and to what other parts of the brain such as the basal ganglia and the reward centers that comprise the cortico-basal ganglia-thalamo-cortical (CBGTC) loop.
Lieberman and McCarthy2013 [241] write that "[t]he neural bases of human language are not domain-specific — in other words, they are not devoted to language alone. Mutations on the FOXP2 transcriptional gene shared by humans, Neanderthals, and at least one other archaic species enhanced synaptic plasticity in cortical–basal ganglia circuits that are implicated in motor behavior, cognitive flexibility, language, and associative learning. A selective sweep occurred about 200,000 years ago on a unique human version of this gene. Other transcriptional genes appear to be implicated in enhancing cortical–basal ganglia and other neural circuits.
The basal ganglia are implicated in motor control, aspects of cognition, attention and several other aspects of human behavior. Therefore, in conjunction with the evolved form of the FOXP2 which allows for better control of the vocal apparatus and mental processing of the kind used in modern human's language, the evolution of connections between the basal ganglia in the larger human cerebral cortex are essential to support human speech (or sign language). The FOXP2 gene, though it is not a gene for language, has important consequences for human cognition and control of the muscles used in speech.
This gene seems to have evolved in humans since the time of Homo erectus. [...] FOXP2 also elongates neurons and makes cognition faster and more effective. [...] Such a FOXP2 difference could have resulted in a lack of parallel processing of language by Homo erectus, another reason they would have thought more slowly. [...] FOXP2 in modern humans also increases in length and synaptic plasticity of the basal ganglia, aiding motor learning and performance of complex tasks." See Pages 117-118 in [121].
Everett writes that another reason that the basal ganglia are important is that their role in language illustrates the importance of the theory of micro-genetics. This theory claims that human thinking engages the entire brain, beginning with the oldest parts of the brain first or as put in a recent study: "The implication of micro genetic theory is that cognitive processes such as language comprehension remain integrally linked to more elementary brain functions, such as motivation and emotion [...] linguistic and nonlinguistic functions should be tightly integrated, particularly as they reflect common pathways of processing [372]." See Pages 135-136 in [121].
Christine Kenneally [213] channeling Lieberman writes "[i]t is clear from this evidence, according to Lieberman, that the basal ganglia are crucial in regulating speech and language, making the motor system one of the starting points for our ability not only to coordinate the larynx and lips in talking, but to use abstract syntax to create meaningful and more complicated expressions. [...] One of the important functions of the basal ganglia is their ability to interrupt certain motor or thought sequences and switch to a different motor or thought sequence. Climbers on Everest become increasingly inflexible in their thinking as they ascend the mountain — stories about bad decision-making in adverse circumstances abound. Accordingly, Lieberman's climbers showed basic trouble with their thinking. [...]
Basal ganglia motor control is something we have in common with many, many animals. Millions of years ago, an animal that had basal ganglia and a motor system existed, and this creature is the ancestor of many different species alive today, including us when we deploy syntax, Lieberman argued, we are using the neural bases for a system that evolved a long time ago for reasons other than stringing words together. [...] Chimpanzees, obviously, have basal ganglia. Birds have basal ganglia. So do rats. When rats carry out genetically programmed sequences of grooming steps, they are using the basal ganglia. If their basal ganglia are damaged, then their separate grooming moves are left intact, but their ability to execute a sequence of them is disrupted." In backhanded homage to Chomsky, Lieberman calls their grooming pattern UGG for universal grooming grammar.
Recognizing these changes helps us to recognize that human language and speech are part of the continuum seen in several other species. It is not that there is any special gene for language or an unbridgeable gap that appeared suddenly to provide humans with language and speech. Rather, what the evolutionary record shows is that the language gap was formed over millions of years by baby steps. Homo erectus is evidence that apes could talk if they had brains large enough. Humans are those apes. See Pages 193-194 in [121].
Miscellaneous Loose Ends: Note Tony Zador's paper [26] on how animals rely on highly structured brain connectivity to learn rapidly: "Here we argue that much of an animal's behavioral repertoire is not the result of clever learning algorithms — supervised or unsupervised — but arises instead from behavior programs already present at birth. These programs arise through evolution, are encoded in the genome, and emerge as a consequence of wiring up the brain. Specifically, animals are born with highly structured brain connectivity, which enables them learn very rapidly. Recognizing the importance of the highly structured connectivity suggests a path toward building ANNs capable of rapid learning." Check out this interview with Zador about 01:18:00 into the podcast. You might also find Nathaniel Daw's interview and lecture on rational planning using prioritized experience replay as it relates sharp wave ripples and hippocampal replay.
If you missed it here is a link to my earlier compilation of papers on hierarchical and compositional models relating to multi-policy reinforcement learning. Related is the work of Ramachandran and Le [307] and Rosenbaum et al [19] on routing networks — Consider a model with a single large network or supernetwork with numerous subnetworks that implement experts and a second smaller network or router that learns to route examples through the supernetwork. Given that the router is characterized as a neural network, it must be trained. Rosenbaum et al [19] use reinforcement learning to train the router and Ramachandran and Le [307] use the noisy top-k gating technique of Shazeer et al [336] that enables the learning of the router directly by gradient descent.
That's all for CS379C this year. I wordsmithed the list of technical challenges that I circulated earlier and made it the penultimate entry in this class discussion. If you want to share it or circulate the ideas more broadly, please use this link to do so. I'm just about finished going through the final project reports for the second time and all the remaining grades will be posted by noon on Tuesday — the registrar's deadline for all students — at the very latest.
June 11, 2019
%%% Tue Jun 11 04:48:44 PDT 2019
Since all of you were working hard on completing your final projects, I decided to cash out my current thinking about action selection and compositional modeling. In previous entries we've considered several aspects of the problem — some we've addressed, some we've ignored and still others we've briefly explored and then put on the back burner. This entry attempts to combine several of the ideas we've talked about in a single architecture, tracing sensory input to motor output with an emphasis on the role of the neural state vector in selecting what to do next and how libraries of subroutines provide a means for exploiting compositionality and leveraging hierarchical planning. I wrote and then destroyed a few thousand words before giving up on prose and set about trying to visualize what I have in mind. The result is summarized in Figure 78. If nothing else, I am better prepared to empathize with your struggles to take the ideas you explored in your project proposals and convert them into working code, experimental results and useful insights.
| |
| Figure 78: Composite network highlighting the three primary subnetworks. Starting from the far right: perception, showing unrolled LSTM networks (H) for encoding sequences including dialogue and comments as text, programs as abstract syntax trees, plus, not shown here, specifications, IDE output, shared screen images and execution traces utilizing appropriate standard neural network components, and additional multi-modal layers corresponding to the abstract association areas in the parietal and temporal lobes that comprise semantic memory and the global workspace (G). In the middle are shown the attentional networks (F) roughly corresponding to the circuits in the prefrontal cortex responsible for identifying and actively maintaining (E) those circuits in the GWS deemed most relevant to the current situation; these patterns of activity serve to summarize the current neural state vector (D) and provide the input required for action selection. On the far right, the meta-controller (C) — roughly corresponding to the areas in frontal cortex that participate in the hyperdirect pathway — that takes as input the neural state vector and produces as output a context used by the read-write controller (B) to retrieve a subroutine from the (DNC) program memory appropriate to execute next and guides the execution of the currently running subroutine. The final component is partly inspired by circuits related the thalamus and basal ganglia that are responsible for the final step in action selection, namely applying the value function for the currently running subroutine to select the next action to perform whether that implies executing a primitive action or performing some inference step that indirectly alters the neural state vector or the local context for the currently running subroutine. The corresponding neural network (A) takes as input an augmented state vector (ASV) that includes local state information relevant to the currently running subroutine, that, in addition to providing short-term memory for the intermediate results of computations performed in the subroutine, also provides short-term memory on the call stack allowing subroutines to be interrupted when calling another subroutine and then continue from where it left off when called. | |
|
|

Miscellaneous Loose Ends: If you're interested in tradeoffs involving model-based and model-free reinforcement learning, check out Podcast #37 of Brain Inspired at around 00:40:00 into the interview with Nathaniel Daw from Princeton talking about his work on planning and hippocampal replay — see his 2018 paper in Nature Neuroscience (PDF)— and its relationship with sharp wave ripples and other topics that Loren Frank talked about in his presentation in class. The paper and discussion are likely to be interesting to both biological and machine learning experts.
June 9, 2019
%%% Sun Jun 9 02:23:28 PDT 2019
In the previous entry in this log, we focused on the problem of representing the problem at hand in such a way that the next thing to do is obvious — even if the next best thing to do is throw up your hands in despair. The abstract representations corresponding to activity throughout the brain and the association areas in the parietal and temporal lobes in particular encode the state of our minds. That encoding might reflect the chaotic state of an agitated mind unable to focus or the organized state of a mind razor-focused on solving a specific problem. One of hardest things that children have to learn is how to cultivate and sustain such states.
As a simplification, imagine the programmer's apprentice in a loop in which the apprentice first focuses on a problem to solve — it could be a problem of what to say next, or the problem of figuring out what steps to take next in debugging a piece of software, and then, having decided what to work on next, it goes about figuring out what concrete step to take, e.g., which could be to enter the debugger, set some breakpoints and run the code to see what happens. In any case, the choice of what to focus on is made automatically by an attentional mechanism with access to patterns of activity throughout what Dehaene et al call the global workspace [99, 103, 101].
This attentional mechanism employs a suitable prior [38] to identify from among a set of currently active neural circuits and then actively maintain these circuits for a short time — on the order of a few tenths of a second — thereby allowing other circuits in the frontal cortex to perform computations related to action selection [104, 97]. The current collection of actively maintained circuits comprise a pattern of activation that together serve as a proxy for the current neural state vector in much the same way that the hippocampal-entorhinal-cortex complex encodes episodic memory.
To assist in making decisions regarding what to do next we assume that the meta-controller learns to discriminate between different problem spaces and arrange for the appropriate objective function to guide the assistant in choosing what to work on next. For example, the problem space corresponding to working on programming problems would combine inputs from the assistant's conversations with the programmer, the current state of the integrated development environment including the current code listing that the programmer and assistant are focusing on, and the status of any flags that have been set and related output from any of tools available in the IDE.
All of the input related to these sources is combined in one large state vector and embedded in a vector space with an associated metric that emphasizes those dimensions most relevant in determining what steps to take next in pursuing whatever goal the assistant has set for itself or been assigned by the programmer. We also assume a network that maps points in problem space vector field to the set of contexts that define procedures at different levels of abstraction. As the programmer takes concrete steps to examine or make alterations of the software being developed, the relevant point in the problem space will shift as will the contexts that suggest what to do next.
It's as though the programmer surveys activity throughout its encoding of the problem space, including its interactions with the programmer, memories of past similar patterns of activity, and all the little details and irrelevant side issues that it has learned to ignore or push to the background until some other bit of information makes them relevant and brings them to the fore. There is no magic. One neural network with reciprocal connections throughout the cortex selects a subset of currently active circuits in working memory and then using another neural network sends a compressed summary of this activity to the meta controller responsible for selecting what next to do
It is clear from our earlier discussion concerning transfer learning and the complexity of learning environments, that a single source of extrinsic reward will not suffice to efficiently learn about programming. It may require multiple objective functions applicable to different stages in development, carefully crafted curricula that serve to advance learning using performance measures that signal competence in a given area necessary to graduate to the next level and a combination of extrinsic and intrinsic rewards to guide learning even in the case of unpredictable and widely separated rewards.
In addition, the neural state vector may — undoubtedly will — prove inadequate as a basis for fully exploring the problem space. Here we will have to rely on predictive machinery to expand the latent space in order to account for the partial observability of the underlying stochastic process [393]. As for evidence of the shortcomings of our current state representation, once again we will have to use analogy and relational models to leverage what we know other about other parts of the state space, and expend effort exploring our environment, essentially playing the role of scientist in performing experiments to reveal what we need to be aware of in order to thrive.
June 7, 2019
%%% Fri Jun 7 03:56:10 PDT 2019
In this entry, we discuss the concept of a conscious thought as a pattern of cortical activity, its implementation as an artificial neural network and its role in the design of agents that pursue goals, generate plans and create complex artifacts such as computer programs. Stanislas Dehaene [95] does a wonderful job explaining the role of attention and conscious awareness in how we construct thoughts and focus on specific content in the process of deriving additional thoughts and producing behavior, and so, if you are not familiar with his recent work on consciousness, I encourage you to read this footnote21. In an effort to make these ideas more concrete, I've expanded on an example drawn from my experience that I think you will find useful in understanding some of the lessons we can learn through introspection — despite oft repeated misgivings about relying on intuition.
The remainder of this entry addresses the problem of how to select what to do next. From reading Stanislas Dehaene you should have some idea of how a conscious state arises several times a second in the form of the stable activation of a subset of the active workspace neurons. The particular subset of neurons can change from one moment to the next but it remains stable for long enough that it plays an essential role in decision making. The actions that arise as a consequence of these fleeting states alter the set of active workspace neurons, thereby changing what we attend to and, by so doing, produce new conscious states in a constantly repeating cycle.
When you try to reconstruct what you think about from moment to moment it quickly becomes apparent that unless we are concentrating on a particular task our thoughts tend to be somewhat scattered, caught up in the minutia of daily life and the many things we have to attend to in order to get along with our lives, all of this against a constant chatter of nagging thoughts about what we want or don't want, who we like or don't like, etc. These thoughts can be so intrusive as to render us incapable of working productively on anything that requires our focused attention and persistent concentration — a state that Dehaene describes as pandemonium.
It feels like a great effort to focus your attention on a single task and ignore distractions. Even when we succeed for a moment, it is common for our attention to wander and our minds to fall back into the pattern of allowing the distractions to render us incapable of sustained focus. With practice we acquire the habits of mind that enable concentrated mental effort, and, to the extent possible, an ability to sustain that concentration over periods long enough to accomplish worthy goals. However, it is a rare individual who can sustain such concentration or maintain focus when attempting challenges at the limit their ability.
| |
| Figure 77: A method of painting that involves imposing structure to force the artist to see the world from a different perspective. Graphic A depicts a prepared canvas with a 5 × 7 grid superimposed. Graphic B shows a photograph of a water color by Albrecht Dürer as it would appear if divided into 35 panels. In applying the method described in the text, the artist would work on one panel at a time looking only at the portion of the photograph corresponding to the selected panel. Graphic C depicts the partially completed painting, illustrating that the panels are selected for rendering at the discretion of the painter — as are, though not depicted here, all of the other characteristics of each individual panel. The resulting painting appears as a montage held together by whatever artistic or stylistic constraints the artist has chosen to impose on his creation. | |
|
|

My wife is a landscape artist whose paintings often combine natural scenes with self-imposed structure that forces both artist and viewer to think about space, continuity and our apprehension of the natural world in novel ways. In one series, she starts with a photograph, overlays a grid dividing the photograph into square panels and paints one panel at a time in whatever order makes the most artistic sense to her at the time, using whatever style and palette seems appropriate. The process involves strategic planning in deciding on the subject matter and grid design, along with many tactical decisions as the painting gradually emerges.
What panel to paint next? Should it adjoin other painted panels? Should the transition between this panel and the one immediately to its left be abrupt and discontinuous or gradual and seemingly natural? What brush to use? Load a palette knife with pigment in the style of van Gogh or use a narrow brush to apply color thinned with medium as if painting a Dürer watercolor. The seemingly smooth, convincingly coherent running commentary we produce when self-consciously attending to our thoughts is an illusion. Following Cèzanne's injunction that "We must not paint what we think we see, but what we see" is easier said than done.
Most of the time it takes constant effort to bring together and then maintain just the right collection of relevant thoughts to make the connections necessary to address whatever part of the problem becomes important to resolve in making progress toward your goals. More often than not, progress requires finding some new element to add to the mix or adjusting your attitude with respect to some aspect that resists your effort to accommodate or bring to bear on the problem at hand. There is a myriad of adjustments we make in attempting to reimagine the problem so possible solutions become apparent or the path forward more obvious.
In the best case, we continue adapting the space from which solutions will emerge and resist being derailed by our misgivings and insecurities, but that too requires effort. None of it is particularly deep but all of it is fraught with the instability of our best efforts to remain focused and emotionally unencumbered. Our thoughts seem as if as spun out in long threads of concentrated effort when in fact they are punctate sequences of our responding to the constantly changing set of active workspace neurons. It is the narrative account we provide to explain our reasoning that evokes this sense of continuous, sustained rationality.
Miscellaneous loose ends: Two of the most useful characteristics of computational and representational models are that they are compositional and hierarchical. A model is said to be compositional if it is possible to combine multiple components of the model in different configurations to solve a wide variety problems. A compositional model is (strictly) hierarchical insofar as the components of the model can be arranged in an hierarchy such that, at every level except the bottommost, the components are more general than and composed of the components in the subordinate level. These models are desirable whether they be concerned with activities, objects, goals, plans, objects, programs, etc22.
June 5, 2019
%%% Wed Jun 5 03:59:07 PDT 2019
Each subroutine / procedure is associated with a context corresponding to a pattern of activity in semantic memory / association areas in parietal and temporal cortex, emphasizing those aspects of the state vector that determine the applicability of the corresponding subroutine / procedure. The context essentially defines the preconditions for invoking the procedure; while not immediately relevant to our discussion here, the context as precondition for a given subroutine is paired with a second pattern of activity that defines the postconditions for the procedure which can be used as a training signal / termination criterion.
We will continue to employ terminology from computer science when appropriate anticipating our audience to the extent that is possible and thereby avoiding inventing new terminology — at the very least, the reader can use online resources to disambiguate our use of the terminology to gain additional insight. As a case in point, in order to handle interruptions in the execution of a subroutine as in the case of one subroutine calling a second subroutine or itself recursively, we need some means of temporarily retaining state information relevant to the interrupted subroutine so we can resume its execution when the called subroutine terminate.
Indeed, we need to be able to handle multiple interrupts as one subroutine calls another, that can in turn call yet another and so on. In a conventional computer, this eventuality is handled by the program call stack which serves as a short-term memory for nested procedure invocations. The context for a subroutine defines how it is called and what it needs to be aware of, but as a subroutine is run it also needs to keep track of local changes, for example in remembering intermediate results of its computations, and these too have to be stored in short-term memory and kept separate from other subroutine invocations.
This sort of bookkeeping is handled by stack and frame pointers. To deal with maintaining local state information when a subroutine is interrupted and allow for including any directives required by the neural equivalent of the Unix process scheduler, we extend the current state vector by appending a fixed-length vector called a frame to current state vector, and use a LIFO stack implemented as DNC to keep track of recursive subroutine calls. In a conventional computer the stack and frame pointers correspond to arbitrary offsets in the memory allocated for the call stack and hence are implemented as memory addresses, i.e., pointers in the C++ sense of the word. In our case, we use the extended state vector to keep track of all local state, and so the frame pointer is the top location of the LIFO and the stack pointer is essentially the input layer for the subroutine network
Roughly speaking, when a procedure is invoked, a stack frame is pushed onto the call stack to serve as short-term memory for the this particular invocation of the procedure. This frame serves as a short-term-memory record of the procedure state that can be used to restore state when another procedure is called, creates its own a frame to record local state and eventually returns control to the original procedure that uses its stack frame to restore the state as it was prior to invoking the called procedure. In this way, we can make as many nested procedure calls as we like, limited only by how much short memory we have to keep track of the local state information.
In the following we refer to the component labeled in PREFRONTAL CORTEX in Figures 74 and 76 as the meta controller (MC) that will, among other duties, determine what subroutines are to be run, oversee their runtime behavior and manage the call stack in support of nested procedure calls. With regard to the last, the MC uses two additional controllers shown in earlier figures as a single controller for a DNC partitioned into long-term memory for storing subroutines and short-term memory for storing stack frames.
We separate the single controller shown in the earlier figures into two separate controllers, one for each block of the partition, and refer to them in following as the program memory controller (PMC) and the call-stack controller (CSC). The key-value pairs for PMC controlled memory block consist of a context and weight matrix. The key-value pairs for the CSC controlled memory block consist of a context and stack frame recording the local state of an interrupted subroutine where the context is only used to restore the weights of interrupted subroutine and DNC memory is used as a simple LIFO stack. The MC controls the subordinate memory controllers by performing three basic operations:
PUSH — use the CSC to push the context for the current running subroutine and its current stack frame on the LIFO stack, and then use the PMC and a supplied new context as a key to extract the associated weight matrix from the program memory to replace the weight matrix of the interrupted subroutine;
POP — use the CSC to pop the call stack and obtain a key and stack frame, then use the PMC and the recovered key to restore the weight matrix of the suspended subroutine, append the stack frame to the current state vector and write the augmented state vector to the input layer of the subroutine network;
CONT — this operation doesn't require using either the CSC or the PMC controller; the MC does look at the stack frame from the previous state, computes a new stack frame, appends it to the current state vector and writes the resulting augmented state vector to the input layer of the subroutine network;
May 31, 2019
%%% Fri May 31 04:36:02 PDT 2019
The following graphic appeared in the first lecture of the course this year. On the left (A) is a cartoon drawing of the hippocampal complex including the dentate gyrus (DG) and portions of entorhinal cortex (EHC). On the right (B) is a block diagram featuring some of the major functional components that comprise the underlying circuitry and hinting at various aspects of their function such as the role of the reciprocal connections between the EHC and CA1 completing a loop critical in training the system to accurately reconstruct the original stimulus, the recurrent connections in CA1 presumed responsible for pattern completion in retrieval, and the recurrent connections between the EHC and the cortex that are implicated in the imperfect reconsolidation of memory leading to unreliability of eyewitness testimony [244, 243] and hypothesized to enable creative reimagining of the past as a means of anticipating the future [175, 174]:
 |
Unsolicited Career Advice: Are you thinking about spending the next five to ten years of your life training to become a scientist? I know that some of you taking the class this year are interested in such a career path since we've talked about what it might be like to pursue careers in science and related technology in the midst of the current economic, social and political climate. Here are some of my thoughts [...]23
Figure 73 illustrates the important role that reciprocal connections and semantic memory play in support of episodic memory. One observation repeatedly encountered in the suggested readings and presentations in class is that it is not enough to just train networks with backpropagation using labeled data (supervised) or auto-associative methods (semi-supervised). Learning useful abstractions in semantic memory requires that they be grounded in our apprehension of the physical world — or more generally in multiple environmental models that account for the dynamics and relational structure found in different domains. Such experience and the coherence and relevance it brings to our understanding of the physical world that we inhabit, not only grounds the language that we use to communicate and share knowledge with other human beings, but it also provides the foundation for everything else we learn and makes it possible for us to rapidly adapt to new domains by transferring the skills we learn in one environment to our understanding of and interaction with new environments.
| |
| Figure 73: A version of this figure showed up early in class as an architectural sketch illustrating the importance and pervasiveness of reciprocal connections in our current understanding of human cognition. There are three primary systems illustrated here including an attentional network — top center — with connections to circuits throughout the cortex but especially the association areas in the parietal and temporal lobes that combine multiple sensory moralities to form the abstractions that play a central role in higher cognition. These association areas are often referred to collectively as semantic memory. Also included here is a cartoon network showing the multiple levels of perceptual processing — bottom left — that produce these abstract representations and that we discuss in the main text. By way of emphasis, the simple model of episodic memory roughly based on the hippocampus and entorhinal cortex is illustrated — mid height far left — with its extensive reciprocal connections especially to areas of semantic memory. | |
|
|
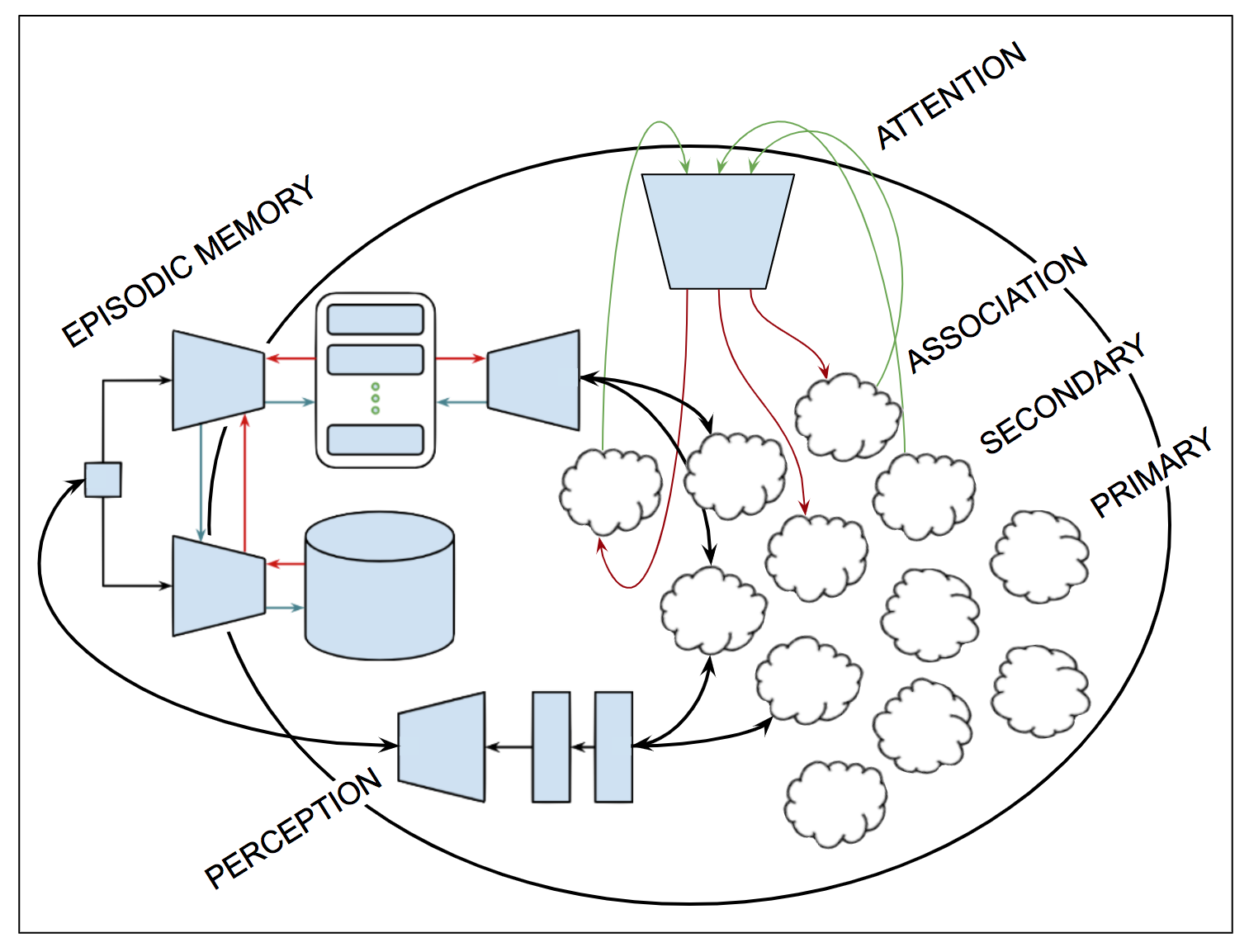
One of the important lessons we picked up from several speakers is that the sample complexity of reinforcement learning as it relates to the (Kolmogorov) complexity of the environments that we inhabit and, in particular, our ability to transfer learning between multiple environments, is generally prohibitive if the difference in complexity between environments is high and the learning agent is not able to exploit similarities between environments. Apart from the asymptotics, if an agent is to exhibit accelerated learning by exploiting the observable relationships between environments it has to be exposed to a suitably diverse collection of environments early in life. If this learning can be done in a staged manner then the agent can quickly acquire the tools necessary to learn new models underscoring the benefits of developmental learning. The importance of rich models of the world that enable us to compress semantic information into useful abstractions is also key to our ability to attend to those aspects of the world that most impact our well being. Here are a few results on the sample complexity of reinforcement learning as it relates to the underlying problem of optimally solving Markov Decision Processes [20, 230, 248].
The following graphic also appeared in the first lecture of the course this year. The graphic on the left (A) shows a cartoon drawing of the basal ganglia (BG) along with some of the neural circuits that it connects with, including the thalamus that serves as an interface with the cerebral cortex relaying information between the cortex and circuits in the basal ganglia, and the amygdala and related parts of the limbic system that provide important emotional and motivational signals. The circuits shown here are the basis for action selection. On the right (B) is a block diagram showing some of major functional components that comprise the underling neural circuitry illustrating a loop that enables an iterative process involving inhibitory and excitatory shaping of neural activity in the cortex via two pathways — the so-called direct and indirect paths — and that converges to a single, selected action. In subsequent talks by Randy O'Reilly and Matt Botvinick, we would learn that the basal ganglia provide only part of the story as it relates to action selection and cognitive control in the primate brain:
 |
In the following, we describe how context-based hierarchical reinforcement learning handles problems relating to variable binding, problem decomposition, procedural abstraction and the creation and application of context-subroutine pairs, how both the context and the subroutine are allowed to adapt over time as a consequence of their deployment, and how the neural network analogues of the basal ganglia and prefrontal cortex work together to adapt context-subroutine pairs by altering the contents of short-term memory24.
Plans are formulated, modified to suit circumstances and carried out guided by patterns of activity throughout both cortical and subcortical circuits that represent the agent's current situational awareness, including state information relating to ongoing planning and execution activities. These patterns of activity correspond to the abstract composite representations that account for and integrate the separate products of perception, proprioception and kinesthetic awareness. They make it possible to pick up a fork from the dinner table or scratch an itch anywhere on your body without consciously making an effort to infer anything — these representations are maintained so you don't have to think hard to perform simple tasks.
There is, however, a lot going on inside your brain that does require explicit attention, including the initiation and maintenance of patterns of neural activity that correspond to abstract representations of objects and processes that play out in the physical world we inhabit25. Both the basal ganglia and the relevant circuits in the frontal cortex have extensive reciprocal connections across most regions of the cortex as well as subcortical nuclei and the brainstem. They both utilize and modulate activity in these regions as the means by which they initiate and control external behavior in the form of muscle movements and manipulate internal state vectors to create the informational contexts that drive both planning and execution of external behavior.
%%% Sat Jun 1 02:58:16 PDT 2019
We begin by explaining our technical use of the term context as it relates to our model of hierarchical reinforcement learning (HRL). HRL is essentially a reinforcement learning (RL) approach to learning and deploying hierarchical task networks26. Specifically, we have to explain how neural network analogues of the basal ganglia (BG) and relevant circuits in the prefrontal cortex (PFC) carry out action selection and planning using the neural mechanisms described above. Moreover, the planning part has to provide the sort of flexibility afforded by a hierarchy of abstract encapsulated expertise in the form of subroutines analogous to the use of this term in computer programming27.
At a high level, a context organizes the information necessary to perform a subroutine so that it can be manipulated by circuits in the frontal cortex employed in planning. Contexts are specific to operations performed by the frontal cortex. In contrast, the mammalian basal ganglia focus on a simpler problem, namely working in coordination with the cerebellar cortex and other subcortical circuits responsible for motivation to modulate cortical activity via excitation and inhibition through its several nuclei so as to select the next — generally primitive — action to take [52].
In the traditional view, RL constructs a policy that maps states to actions — in some cases, indirectly through the intermediary of a value or reward function that maps states to expected rewards. The BG can be thought of as implementing such a policy, and the PFC as adapting that policy. Our approach to HRL involves the use of a composite policy comprised of a core-competency policy that is common across all contexts and a subroutine implemented as a policy that is specific to that subroutine and that is adapted by the PFC to suit the current circumstances. Such adapted contexts can be thought of as altering cortical landscape in which the basal ganglia normally operate.
The PFC plays the role of a meta-controller that learns to decompose the space of actions into the neural-network equivalent of a hierarchical task network, thereby speeding up the process of learning new skills by learning simple policies that can be utilized in many contexts, abstracting out common procedural knowledge so that expertise is consolidated where possible and ensuring that knowledge gained through experience is efficiently made available across all relevant tasks.
The meta controller that (very roughly) models circuits in the frontal cortex responsible for executive control, essentially plays the role of the program counter and related routing and control logic in the arithmetic and logic unit that fetches and decodes program instructions, loads operands into registers, handles branching, etc. However, in our case, the instructions, operands and registers are not perfectly aligned in byte-sized chunks, neatly organized in consecutive locations in a (robustly) non-volatile random access memory in accord with the protocol followed by the compiler, or otherwise precisely orchestrated to comply with conventional computing hardware design principles.
The PFC fetches the analogous input required by a subroutine using its reciprocal connections to circuits throughout the cortex in order to map patterns of activity to a canonical form that we refer to as the subroutine's context and that is expected by the policy implementing the subroutine. In this manner, the policy can always depend on its input encoded in the context to unambiguously exhibit a fixed structure it can exploit to pass variable bindings or any additional directives required to return information to the calling subroutine or supply information to any subroutines called in the process of executing the subroutine policy28 .
I am probably pushing the conventional-computing analogy more than is strictly necessary for this discussion. All we require is that the PFC — in analogy to the role of the ALU in a conventional microprocessor — treat each subroutine as a combination of context and policy and that it consistently map the relevant cortical activations to the context thereby uniquely identifying the corresponding subroutine, in much the same way that the formal parameter names and type declarations of a procedure written in a conventional programming language define a unique signature determining its use29.
The PFC / meta controller envisioned here would allow a subroutine to select an action corresponding to a subroutine implemented as a policy to call another subroutine and then return control to the original subroutine when it completes, having possibly enriched the environment of the (original) calling subroutine by some binding set by the subordinate (called) subroutine. However, for most purposes it probably makes the most sense for every subroutine invocation to be treated as a tail call30, and return values, if any, to be communicated to the PFC by the calling procedure modifying state in the call stack31.
| |
| Figure 74: The above diagram shows a simplified version of the architecture described in Figure 72 minus the subroutine policy induction component. The four components comprising the architecture are labeled A-D and identified as follows: A is an NTM partitioned into program memory for storing subroutine parameters and a call stack that keeps track of the contexts for all of the subroutines currently in play, and B is the read-write-head controller for the NTM in which each location corresponds to a key-value pair with a context as the key and the context-adapted weight-matrix (wt) of a neural-network implementing a subroutine as the value. C is the (high-level) meta-controller that determines the current context (ct) from the state (st) and employs this information to coordinate the execution of multiple subroutines, locally altering contexts on the call stack in order to orchestrate the behavior of multiple subroutine calls. Contexts on the call stack essentially serve as closures encoding local state in the form of controller directives and shielding parameter bindings in the case of multiple calls to the same subroutine or different subroutines utilizing the same parameter encodings. D is a composite policy consisting of a (mid-level) network layer corresponding to a context-adapted subroutine selected by the meta-controller and a (low-level) network layer common to all subroutines that selects primitive actions (at) based on the current state and the output of the context-adapted subroutine. | |
|
|
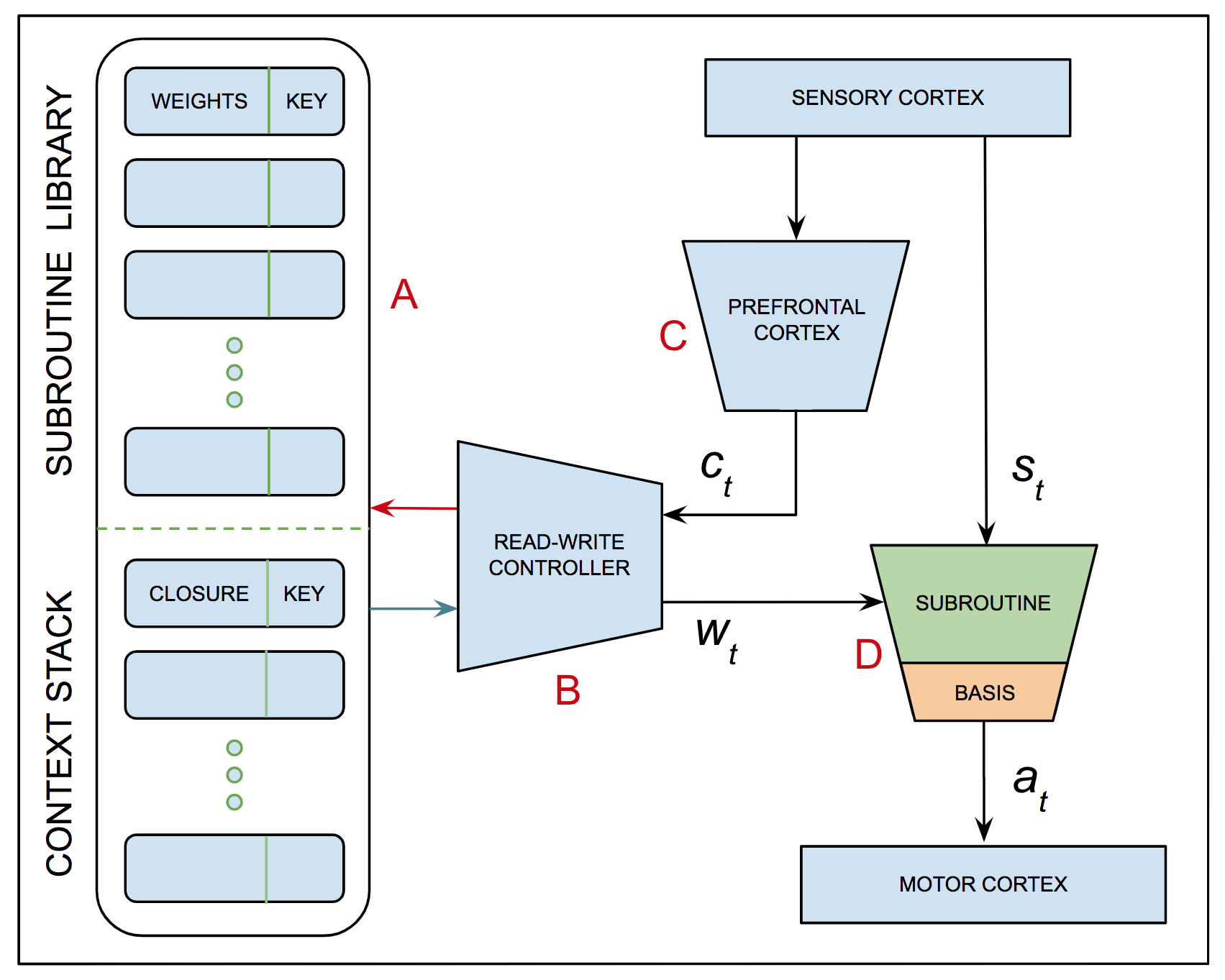
Figure 74 is a simplified version of an earlier diagram shown in Figure 72. The diagram in Figure 74 does not include the machinery responsible learning new subroutines highlighted in the earlier architecture and is intended here as a visual aid in explaining the basic idea of how a set of subroutines represented as policies can implement a powerful instantiation of hierarchical reinforcement learning.
%%% Mon Jun 3 02:58:16 PDT 2019
We begin by explaining the main components corresponding to the labeled rectangles and trapezoids shown in the figure, starting with the rectangle labeled as the sensory cortex. In the following we use the term sensory cortex to refer to the source of activity arising from perception and accessible to conscious attention. In particular the association areas in the parietal and temporal lobe that encode abstractions combining multiple sensory modalities including high-level visual, spatial and proprioceptive awareness. What we refer to as the sensory cortex is sometimes called semantic memory by cognitive scientists studying consciousness and metacognition.
The trapezoid (C) labeled as the prefrontal cortex (PFC) is intended as a catchall to encompass circuits in the frontal cortex responsible for high-level decision-making and executive control. These circuits have extensive reciprocal connections to most areas of the neocortex as well as the cerebellar cortex and diverse subcortical nuclei responsible for emotional and motivational valence. The reciprocal connections allow the prefrontal cortex to both access and sustain activity as a means of short-term memory essential for problem solving and complex decision-making.
The rectangle labeled motor cortex is also a catchall term intended to encompass neural circuitry responsible for controlling muscles throughout the body. If the sensory cortex is the source of all direct and derived sensory experience including both direct sensory stimuli and the complex abstract representations that arise in higher-level association areas, then the term motor cortex is intended to encompass the control interfaces for all of our means of interacting with the physical environment including walking, running, speaking, rolling your eyes in consternation and drinking a glass of water.
The trapezoid (B) labeled read-write controller is responsible for managing short-term memory (A) implemented as a differential neural computer (DNC) to facilitate planning and decision-making. We say that the DNC is partitioned into two blocks, labeled SUBROUTINE LIBRARY and CONTEXT STACK in Figure 74 for reasons that will soon become apparent — they could have been labeled PROGRAM MEMORY and CALL STACK if we wanted strengthen the analogy with conventional computer architecture33.
Given a context corresponding to a pattern of activity in the sensory cortex, the controller searches a collection of subroutines that implement policies mapping states to actions that are appropriate in a given context. Subroutines are stored as key-value pairs in the subroutine library where the keys are contexts and the values are policy-network weights. The controller also maintains a stack of subroutines that are either currently running or have called another subroutine and are awaiting its return. The controller performs the operations of a neural network equivalent control unit in the ALU of a conventional digital computer34.
The remaining component (D), illustrated as a green trapezoid stacked on top of a smaller orange trapezoid, performs a composite function combining functionality responsible for low-level action selection generally attributed to the basal ganglia and an intermediate-level meta-cognition for more complicated planning and execution often attributed to circuits in the prefrontal cortex. They have been separated out and stacked one on top of the other to emphasize their composite functionality while at the same time illustrating their structurally enforced cognitive precedence.
Each of the two subcomponents corresponds to a multilayer neural network with the bottom layer of the top network directly feeding into the top layer of the bottom network. The default, shallow-reasoning mode for the composite is that the top network is the identity matrix and so the input to the bottom layer is just the current state vector st. You can think of the bottom layer as implementing primitive action sequences in a manner that is, at the very least, safe and provides a reliable low-level interface for the motor system broadly construed. There are obvious parallels with industrial robotics and early child development.
The top subcomponent (D) shaded green corresponds to a neural network that has been trained to solve a particular class of problems. We will refer to these specialized networks as subroutines and assume for now that we have an extensive library of such subroutines each of which is exactly the same architecture and hence the weights of one subroutine can easily be substituted for those of another. It is the job of the PFC component to infer a context that the read-write controller will use as a key, read a subroutine from the subroutine library as a weight matrix wt, and then modify the top network in component D accordingly.
For the time being, we will continue to ignore the problem of how subroutines are initially trained and subsequently adapted to perform specialized tasks, and turn our attention to the problem of how the PFC selects a context and associated subroutine and how it manages to handle the case of one subroutine invoking another that performs some specialized task and then returns control to the calling subroutine along with any information gathered that has particular relevance to the calling subroutine. Suffice it to say that subroutines are created to solve problems that present themselves as contexts that no existing subroutine adequately resolves.
We are assuming that the PFC has reciprocal connections with circuits throughout the cortex and selected subcortical circuits. Elsewhere we have discussed a simple model of conscious attention that selects and highlights a subset of these circuits that exhibit activity relevant to the agent's current focus of attention. For simplicity, we will assume that the PFC component shown in Figure 74 subsumes this attentional mechanism and that, in the context of the current discussion, this PFC component uses its reciprocal connections to create a canonical summary of the current state of the system emphasizing activity relevant to planning what to do next. We refer to this summary as the current focal context for planning and execution. When compressed such contexts serve as keys that are used to identify subroutines stored in the SUBROUTINE LIBRARY block of the partitioned DNC that are relevant to ongoing planning activity.
| |
| Figure 75: The basal ganglia form anatomically and functionally segregated neuronal circuits with thalamic nuclei and frontal cortical areas. A The motor circuit involves the motor and supplementary motor cortices, the posterolateral part of the putamen, the posterolateral GPe and GPi, the dorsolateral STN, and the ventrolateral thalamus. B The associative loop and C the limbic loop connect the prefrontal and cingulate cortices with distinct regions within the basal ganglia and thalamus. In the STN, a functional gradient is found, with a motor representation in the dorsolateral aspect of the nucleus, cognitive–associative functions in the intermediate zone, and limbic functions in the ventromedial region. Via a 'hyperdirect' pathway, the STN receives direct projections from the motor, prefrontal and anterior cingulate cortices that can detect and integrate response conflicts.11,104 This pathway is a powerful contact to influence basal ganglia outflow. Abbreviations: GPi, internal globus pallidus; GPe, external globus pallidus; STN, subthalamic nucleus. Adapted from Obeso et al [283]. | |
|
|

The circuit diagram illustrating action selection in the basal ganglia shown earlier does not account for the influence of the prefrontal cortex in cognitive control. It appears there is an additional path called the hyperdirect pathway so named because it receives input directly from the frontal cortex and sends excitatory projections directly to the basal ganglia output, bypassing the striatum altogether. This may seem like a relatively small change but it substantially alters our understanding of action selection and hence what we can expect from upstream cognitive capabilities that rely on this basic enabling functionality for executive control and complex problem solving.
Figure 75 illustrates the revised neural architecture highlighting the hyperdirect pathway, and Wang et al [387] present a new theory of reward-based learning, in which the dopamine system trains another part of the brain, the prefrontal cortex, to operate as its own free-standing learning system. This new perspective accommodates the findings that motivated the standard model, but also deals gracefully with a wider range of observations and suggests that this expanded theory implements a form of "learning-to-learn" that can be realized by a form of meta-learning.
| |
| Figure 76: The model shown here builds on the model presented in Figure 74 by providing somewhat more detail concerning how subroutines are integrated into the proposed model in the part of the network under the direct control of the the circuits corresponding to the basal ganglia. The exchangeable weights that implement the different subroutines are shown sandwiched between striatum and thalamus playing the role of the globus pallidus, substantia nigra and related circuits of the basal ganglia. The adaptive basis network from Figure 74 common to all subroutines is not shown here to reduce clutter. The connections highlighted in red complement those rendered in black in Figure 74 and suggest recurrent reciprocal connections motivated by our understanding of how the prefrontal cortex and hyperdirect pathway moderate activity in the basal ganglia as illustrated in Figure 75. The highlighted connections shown in red represent multiple ways we might accomplish the intervention, with the assumption that only a subset of these connections would be necessary for any particular solution to integrating prefrontal meta-control into the network architecture. | |
|
|

Miscellaneous Loose Ends: The highly-adaptive self-assembling and self-healing characteristics of biological systems are extensive throughout the animal kingdom, and, in some cases, capable of restoring an entire limb or damaged organ. Even the earliest stages of our primary visual cortex retain the capacity for experience-dependent change, or cortical plasticity, throughout life:
Plasticity is invoked for encoding information during perceptual learning, by internally representing the regularities of the visual environment, which is useful for facilitating intermediate-level vision-contour integration and surface segmentation. The same mechanisms have adaptive value for functional recovery after CNS damage, such as that associated with stroke or neurodegenerative disease. A common feature to plasticity in primary visual cortex (V1) is an association field that links contour elements across the visual field. The circuitry underlying the association field includes a plexus of long-range horizontal connections formed by cortical pyramidal cells. These connections undergo rapid and exuberant sprouting and pruning in response to removal of sensory input, which can account for the topographic reorganization following retinal lesions. Similar alterations in cortical circuitry may be involved in perceptual learning, and the changes observed in V1 may be representative of how learned information is encoded throughout the cerebral cortex. Excerpt from Gilbert and Li [147].
Artificial neural networks do not undergo similarly dramatic changes in their connectivity — though at some point we may find reason to allow for such adaptation in support of developmental changes that play out over the early stages of learning allowing us to exert more control over the final network architecture. Connection weights do, of course, change in response to propagating gradients during end-to-end training, and, in principle, the representational locus of key concepts could drift over time.
That said we can hedge our bets in laying down the reciprocal connections between the association areas responsible for encoding useful abstractions that compose multiple sensory modalities and the attentional and executive control networks that exploit those abstractions, by densely connecting the corresponding networks and letting gradient descent do the rest — perhaps even performing some form of subsequent pruning. That was a long-winded way of saying we are going to ignore these disturbing prospects until we have evidence to support our taking them more seriously.
It is important to keep in mind that computations in the brain, as in connectionist models of the brain, are distributed in circuits throughout the brain. The inputs and outputs of these computations as well as the machinery responsible for performing the computations are said to reside in place in the sense that, if you want to perform a given computation, the input, as it were, must be encoded in one ensemble of neurons that are part of the circuit that will perform the computation, and, following the computation, the output will be encoded in another ensemble of neurons that are also part of this circuit and could include neurons from or be identical to the ensemble used to encode the input.
Steeped as we are in the terminology of traditional computing hardware based on the von Neumann architecture, it feels rather awkward trying to express what it means to compute something using the terminology of parallel distributed processing as it is manifest in connectionist models. One important point to keep in mind is that in a connectionist model of computation, if we want to perform the same computation to multiple data then it is often convenient to simply replicate the relevant neural circuitry. Similarly, if we want to perform even slightly different computations on the same data, the time space trade-off often dictates that we replicate the relevant circuitry. In combinatorial optimization problems, where there are large number of alternatives to consider, often the best approach in a connectionist model is to represent the set of possibilities — see for example, Villarrubia et al [379] and Smith et al [344].
May 23, 2019
%%% Thu May 23 05:25:57 PDT 2019
I'm intrigued by the idea of interpolating between policies as described in Pashevich et al [296]. I've read dozens of HRL papers over the last couple of weeks and I'm probably just confusing the authors' approach with one or more of the other papers I've read lately, but it seems that in their model, actions would be determined by a winner-take-all selection process, not just over a single Q-function, but the maximum of the maxima of the Q-functions of all the subroutines indexed in the modulatory bit-vector signal. An alternative is to use some sort of a mixture model — a simple linear mixture of discrete actions probably doesn't make sense, but a weighted average might work in the case of a continuous action space.
I need to read their paper more carefully to figure out how new policies are initially generated to satisfy some unmet need (created), combined to extend their functionality (generalized), separated to narrow their functionality (specialized) and otherwise modified over time in response to their observed performance. I suppose that the fact the modulatory signal is a bit vector, i.e., each bit a binary decision to include a policy or not, means that each sub policy is realized as a strict subset of the set of all policies and the selected action is determined by the maximum value of their respective value functions35.
In the case of the context-based model described here in the the class discussion notes, contexts are learned and associated with the corresponding (mid-level) policy implementing a subroutine. However, since the subroutine parameters are stored in a differentiable neural computer with the keys corresponding to contexts and values corresponding to subroutines, when you retrieve an item the controller computes a softmax of the key-context dot products, that it uses to construct a weighted average of the values.
A natural question is what would be the weighted average of a collection of weight matrices — where we are assuming that all the subroutine weight parameters have exactly the same form / network topology — and does that even make sense. Alternatively we could just compute the outputs of all the weight matrices and combine their weighted average as the input to the low-level network layer. In any case, it might make sense to use the key-context dot products to apportion credit in such a way as to sharpen contextual selection and thereby better separate — better specialize — subroutines to focus action selection.
See Topalidou et al [368] — especially the computational model shown in Figure 3 — and Aron et al [16] for discussions concerning the interaction — one of the two papers characterizes this as competition — between the basal ganglia and circuits throughout the cortex but especially the prefrontal and anterior cingulate cortex36 (ACC) via the reciprocal direct and hyperdirect pathways governing, respectively, motor and cognitive function. While we already have a lot to explain regarding interactions between the cortical and subcortical areas mentioned above, it is worth flagging the point that we have overlooked the role of the cerebellum in both motor and cognitive function, noting that it too coordinates its activity with the basal ganglia and diverse cortical areas and is key in the execution of what we might reasonably think of as compiled subroutines that depend primarily on feed-forward computations37.
May 21, 2019
%%% Tues May 21 05:34:31 PDT 2019
I did a search for papers on multiple-policy and multiple-reward-function reinforcement learning methods applied to transfer learning and hierarchical and multi-agent planning. Among the potentially relevant papers, Alvarez et al [11], Dusparic and Cahill [115] and Glatt and Costa [148] had interesting ideas that might be useful in developing networks that support hierarchical reinforcement learning, but were were not directly related to our uses cases. The papers listed below, however, are more directly applicable to the programmer's apprentice application — specifically, dialogue management for continuous conversation involving multiple tasks and topics, and automated code synthesis and program repair involving multi-procedure programs. I also recommend Ribas-Fernandes et al [24] and Frank and Badre [9] on the neural basis of hierarchical reinforcement learning.
If you read only one paper, I recommend Bakker and Schmidhuber [28] for its approach to letting high-level policies identify subgoals that precede the overall high-level goal, while simultaneously pursuing low-level policies that learn to reach subgoals set by the higher-level policies. Low-level policies also learn which subgoals they are capable of reaching, and in this way they learn to specialize. As a primer, you might find it useful to take a look at this post on The ∇ Gradient weblog written by Yannis Flet-Berliac [127] and entitled "On the Promise of Hierarchical Reinforcement Learning". I've listed a sample of papers in this space along with short descriptions and excerpts from the abstracts in case you are thinking about final class projects involving hierarchical RL. There is a lot of work on this topic and the technology is improving, but don't expect easy-to-apply off-the-shelf solutions.
Fernandez and Veloso [123] — Probabilistic Policy Reuse in a Reinforcement Learning Agent
Our method relies on using the past policies as a probabilistic bias where the learning agent faces three choices: the exploitation of the ongoing learned policy, the exploration of random unexplored actions, and the exploitation of past policies. We introduce the algorithm and its major components: an exploration strategy to include the new reuse bias, and a similarity function to estimate the similarity of past policies with respect to a new one.
Andreas et al [15] — Modular Multitask Reinforcement Learning With Policy Sketches
Policy sketches annotate each task with a sequence of named subtasks. Our approach associates every subtask with its own modular subpolicy, and jointly optimizes over full task-specific policies by tying parameters across shared subpolicies. This optimization is accomplished via a simple decoupled actor–critic training objective that facilitates learning common behaviors from dissimilar reward functions.
Narasimhan et al [272] — Grounding Language for Transfer in Deep Reinforcement Learning
We demonstrate that textual descriptions of environments provide a compact intermediate channel to facilitate effective policy transfer by learning to ground the meaning of text to the dynamics of the environment such as transitions and rewards. Their method employs Value Iteration Networks [362] (VIN) and a bag-of-words LSTM document model to exploit text descriptions that facilitate policy generalization across tasks.
Sahni et al [20] — Learning to Compose Skills
We present a differentiable framework capable of learning a wide variety of compositions of simple policies that we call skills. By recursively composing skills with themselves, we can create hierarchies that display complex behavior. Skill networks are trained to generate skill-state embeddings that are provided as inputs to a trainable composition function, which in turn outputs a policy for the overall task.
Moffaert and Nowè [265] — Multi-Objective Reinforcement Learning using Sets of Pareto Dominating Policies
Multi-objective reinforcement learning (MORL) is a generalization of standard reinforcement learning where the scalar reward signal is extended to multiple feedback signals, in essence, one for each objective. This algorithm is a multi-policy algorithm that learns a set of Pareto dominating policies in a single run.
Bakker and Schmidhuber [28] — Hierarchical Reinforcement Learning Based on Subgoal Discovery and Subpolicy Specialization
We introduce a new method for hierarchical reinforcement learning. High-level policies automatically discover subgoals; low-level policies learn to specialize on different subgoals. Subgoals are represented as desired abstract observations which cluster raw input data. High-level value functions cover the state space at a coarse level; low-level value functions cover only parts of the state space at a fine-grained level.
Pashevich et al [296] — Modulated Policy Hierarchies
We introduce modulated policy hierarchies (MPH), that learn end-to-end to solve tasks from sparse rewards. We consider different modulation signals [82] and exploration for hierarchical controllers, and find that communicating via bit-vectors is more efficient than selecting one out of multiple skills, as it enables mixing between them. MPH uses its different time scales for temporally extended intrinsic motivation at each level of the hierarchy.
Kulkarni et al [18] — Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
We present hierarchical-DQN (h-DQN), a framework to integrate hierarchical action-value functions, operating at different temporal scales, with goal-driven intrinsically motivated deep reinforcement learning. A top-level q-value function learns a policy over intrinsic goals, while a lower-level function learns a policy over atomic actions to satisfy the given goals. h-DQN allows for flexible goal specifications, such as functions over entities and relations.
References:
May 19, 2019
%%% Sun May 19 04:27:46 PDT 2019
There are definitely a lot of moving parts in the proposed model for differentiable procedural abstraction described in the previous entry. Complete realizations of this model will likely end up being big, complicated, hard-to-train networks. We are exploring various class projects that take baby steps. Some of these involve experimenting with extensions of the value iteration network [19] and universal planning network [349] models from Pieter Abbeel's group as possibilities for the planning module. Other possible incremental steps involve using multiple objective functions [251], training subnetworks in isolation and clamping some weights while adapting others [39], and employing some variant of curriculum learning to guide training [249, 35, 40].
We are also brainstorming about how we might divide the model shown in Figure 72 into two completely separate networks and experiment with each part separately to get some idea of how hard it might be to train such a model. For example, how hard would it be to adapt a version of the Sprechmann et al [348] memory-based parameter adaptation architecture to address the right-hand side of the graphic shown in Figure 72 in order to enable a simple model of context switching between two existing, partially trained policies.
Another incremental step that might work for a project involves implementing a version of the left-hand side of the graphic in the Figure 72 — the DNC partitioned for program memory and call-stack memory plus the controller — to experiment with a differentiable program emulator for a subset of lisp. Practically speaking, we've been talking about dividing the suggested multi-partition DNC into two separate DNC components — one for programs and the other for the call stack — and then start out by learning how to emulate simple math functions before contemplating extensions to handle recursion as a stretch goal.
May 16, 2019
%%% Thu May 16 3:44:32 PDT 2019
Figure 72 describes the current version of the neural-network architecture for implementing hierarchically-organized procedural abstraction. It is intended to be largely-self contained and, as such, it is necessarily abstract. A good deal of additional background is provided in the earlier entries of this document, but this is by no means the last word and your feedback will be much appreciated.
| |
| Figure 72: The above diagram shows another version of the architecture described in Figure 70. The illustration is intended as a visual aid for an expanded explanation of our proposal for supporting hierarchically-organized procedural abstractions in a differentiable model. The five main components comprising the architecture are labeled A-E and identified as follows: The component labeled A is an NTM partitioned into program memory for storing subroutine parameters and a call stack that keeps track of the contexts for all of the subroutines currently in play, and B is the read-write-head controller for the NTM in which each location corresponds to a key-value pair with a context as the key and the context-adapted weight-matrix (wt) of a neural-network implementing a subroutine as the value. Component labeled C is the (high-level) meta-controller [172, 295] that determines the current context (ct) from the state (st) and call history (ht) and employs this information to coordinate the execution of multiple subroutines. D is a composite policy consisting of a (mid-level) network layer corresponding to a context-adapted subroutine selected by the meta-controller and a (low-level) network layer common to all subroutines that selects primitive actions (at) based on the current state and the output of the context-adapted subroutine. This approach relies on a variant of memory-based parameter adaptation that stores examples in episodic memory and then uses a context-based lookup to directly modify the weights of the networks that instantiate subroutines [348, 223]. Component E shown in the inset is the placeholder for a planning module that the meta-controller deploys to train subroutines as discussed earlier in these notes [349, 19]. On the basis of observing the performance of a subroutine in its associated context, the meta-controller can invoke the planning module to adapt the subroutine weights to better account for recent relevant examples stored in episodic memory. Not shown here are the circuits involved in episodic memory nor those responsible for attending to the neural activity resulting from observations of external conditions that shape the context and thereby influence the behavior resulting from the execution of preprogrammed procedural abstractions (subroutines). The left half of the graphic shown in Figure 67 supplies a summary of how one might implement this functionality, but is not required to understand the proposal sketched here. | |
|
|
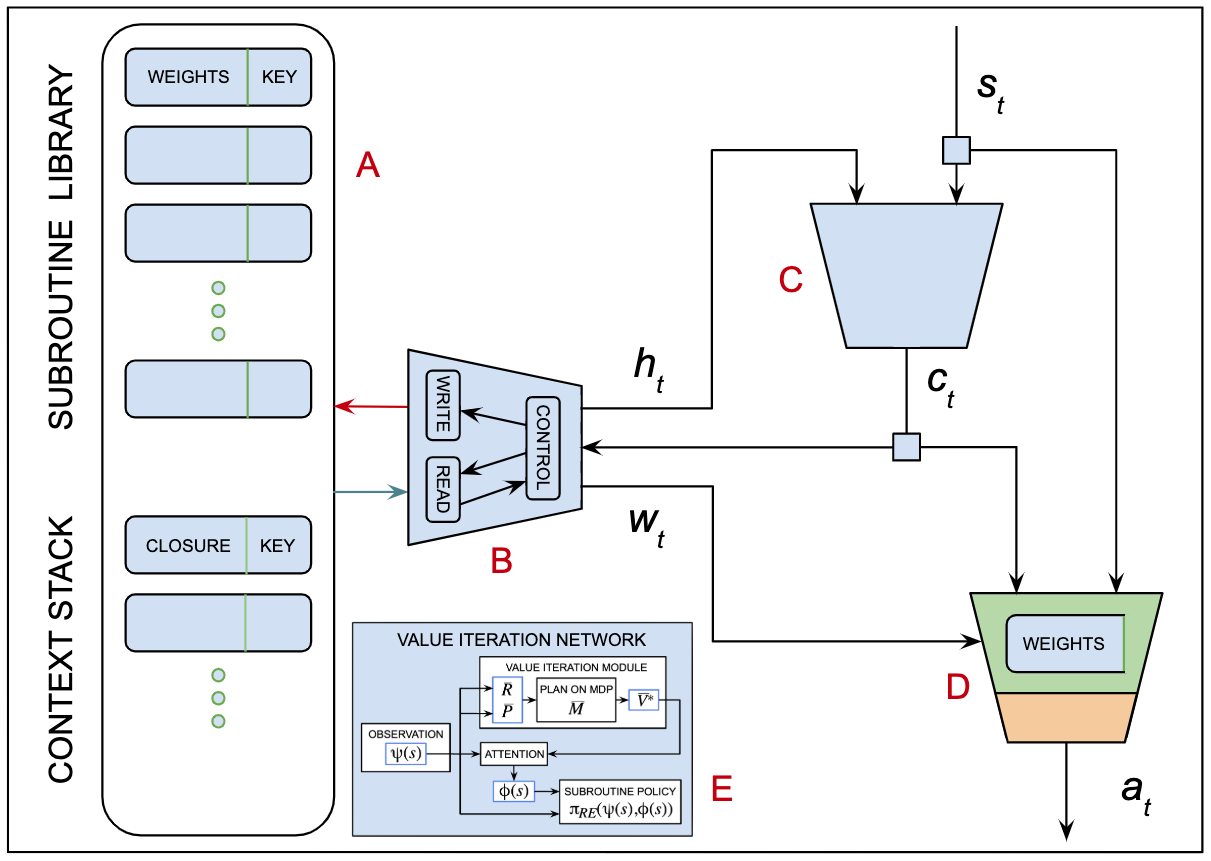
What problems does this solve for us?
It provides subroutines as the basis for procedural abstraction.
One can have an indefinite number of subroutines depending on the size of program memory. New subroutines can be created as needed, they can be adjusted to accommodate changes in the contexts in which they apply. They compete for resources (program memory) and their parameters garbage collected and recycled if they outlive their usefulness. Though one can have an indefinite number of subroutines each one has a limited number of parameters depending the layout of program memory that it can adapt to perform a particular computational task.
It introduces contexts as a basis for hierarchical organization.
You can think of contexts as containers for subroutines. They provide the basis for organizing procedural knowledge to facilitate its targeted deployment. Pragmatically, contexts correspond to patterns of neural activity in sensory and motor cortex in addition to subcortical areas associated with motivation. In the vocabulary of hierarchical planning contexts correspond to the preconditions for abstract plans that achieve specific goals. Algorithmically they serve as keys in a differentiable key-value memory used for storing programs.
It supports composition and consolidation of procedural knowledge.
Contexts can be divided into more specialized contexts or combined into more general ones. In principle, a context need not invoke any concrete activity but instead alter the current set of activations so as to produce an alternative abstract context in which other contexts that actually do invoke subroutines can perform actions. The abstract contexts serve much the same purpose as do objects in object oriented programming, that is to encapsulate procedural and semantic knowledge, support modularity, enable reuse and protect from degradation due to catastrophic_interference.
In addition to static precedural knowledge implicit in weight vectors, a subroutine, when envoked, is dynamically allocated space on the call stack to store local state information including the neural analog of bindings for formal-parameters supplied by the calling subroutine and local variables required for computations performed by the invoked subroutine. Each entry in the call stack is essentially a closure used to maintain state when a subroutine is invoked or is preempted by another subroutine running concurrently or the same subroutine applied recursively.
The mutable parameters stored on the call stack can be modified as a consequence of actions taken by the currently executing subroutine, whereas the parameters that define subroutine networks are only adjustable during training via back propagation. There may be advantages to allowing leakage across context boundaries on the stack mediated by an attention mechanism. It is anticipated that training and execution can be interleaved or performed concurrently where the former consists of replaying sequences of prior state-action histories recorded in episodic memory and carried out at an accelerated rate relative to other adaptations.
Miscellaneous Loose Ends: Here are three seminal papers along with bibliographic references, summary footnotes and online technical tutorials that are probably worth your time to learn about: (a) Variational Autoencoders38 (VAE) Doersch [111] — see Jaan Altosaar's VAE Tutorial, (b) Deep Recurrent Attentive Writer39 (DRAW) Gregor et al [161] — see Kevin Frans' DRAW Tutorial, and (c) Generative Adversarial Networks40 (GAN) Goodfellow et al [151] — see Ian Goodfellow's GAN Tutorial.
May 14, 2019
%%% Tue May 14 4:52:21 PDT 2019
Zambaldi et al [409] focus on the observation that relational computations needn't necessarily be biased by entities' spatial proximity. They develop a framework for relational reinforcement learning that emphasizes non-local computations by using a shared function and iterative message-passing computation akin to that used graph neural networks [32]:
We show that an agent which computes pairwise interactions between entities, independent of their spatial proximity, using a shared function, will be better suited for learning important relationships than an agent that only computes local interactions, such as in translation invariant convolutions. Moreover, an iterative computation may be better able to capture higher-order interactions between entities. Excerpt from Zambaldi et al [409].
| |
| Figure 71: Here is the Box-World agent architecture showing the multi-head dot-product attention (MHDPA) or self-attention operation [378] that computes interactions between entities41. E is a matrix that compiles the entities produced by the visual front-end. The function fθ is a multilayer perceptron applied in parallel to each row of the output of an MHDPA step, A, and producing updated entities, Ẽ. The MHDPA step projects each entity's state vector, ei, into query, key, and value vector representations: qi, ki, vi, respectively, whose activities are normalized [22], used to compute a measure of salience for each entity, and, finally produce a weighted mixture of the value vectors, {vi}. We refer to one application of this process as an attention block. A single block performs non-local pairwise relational computations, analogous to relation networks [327] and non-local neural networks [389]. Multiple blocks with shared (recurrent) or unshared (deep) parameters can be composed to more easily approximate higher-order relations, analogous to message passing on graphs. | |
|
|

The authors describe an approach that introduces a relational inductive bias [32, 171] and an architecture related to graph neural networks [402, 32, 326] that uses multiple stages of a multi-head attentional module that performs iterative message passing to discover higher-order relationships between entities — instances of the attentional module identify non-local interactions and multiple stages of message passing reveal higher-order relationships. Figure 71 borrows from Figure 2 in [409] illustrating the basic idea much better than I can succinctly explain it in words.
We don't want to get too carried away with the performance of the RRL agent on the Box-World problem reported in Zambaldi et al [409]. There is a reason that the methods of choice for relational learning include powerful tools for dealing with uncertainty and combinatorial reasoning like inductive logic programming [113]. In the case of the Box-World environment, efficiently solving even the early levels of the game requires discovering that the color of keys and boxes is relevant and that to obtain the contents of a box you need to find a key that is the same color as the box you want to open. If you don't know the right questions to ask or the right places to look, then you are likely to be faced with a time-consuming combinatorial search.
Box-World is a perceptually-simple but combinatorially-complex environment that requires abstract relational reasoning and planning. It consists of a 12 × 12 pixel room with keys and boxes randomly scattered. The room also contains an agent, represented by a single dark gray pixel, which can move in four directions: up, down, left, right. Keys are represented by a single colored pixel. The agent can pick up a loose key — one not adjacent to any other colored pixel — by walking over it. Boxes are represented by two adjacent colored pixels — the pixel on the right represents the box's lock and its color indicates which key can be used to open that lock; the pixel on the left indicates the content of the box which is inaccessible while the box is locked.To collect the content of a box the agent must first collect the key that opens the box (the one that matches the lock's color) and walk over the lock, which makes the lock disappear. At this point the content of the box becomes accessible and can be picked up by the agent. Most boxes contain keys that, if made accessible, can be used to open other boxes. One of the boxes contains a gem, represented by a single white pixel. The goal of the agent is to collect the gem by unlocking the box that contains it and picking it up by walking over it. Keys that an agent has in possession are depicted in the input observation as a pixel in the top-left corner. Excerpt from Zambaldi et al [409].
Programmers routinely solve similar problems in debugging or refactoring a fragment of unfamiliar code. Infants are generally curious and often alarmingly fearless explorers to the dismay of their watchful parents. They notice when something unusual happens and investigate any novel stimuli or possible toy, often conducting experiments by putting the object of their attention in their mouth. By the time they are toddlers, they already have an extensive repertoire of specialized techniques and are well on their way to compiling a comprehensive library of general strategies. Such behavior manifests at such an early stage in development that some believe there exists an innate inductive bias that promotes inquisitiveness and encourages exploratory activity [364, 152]. Kulkarni et al [12] note the absence of such skill in existing reinforcement-learning agents and suggest a possible solution in terms of a hierarchical model for reinforcement learning:
Learning goal-directed behavior in environments with sparse feedback is a major challenge for reinforcement learning algorithms. One of the key difficulties is insufficient exploration, resulting in an agent being unable to learn robust policies. Intrinsically motivated agents can explore new behavior for their own sake rather than to directly solve external goals. Such intrinsic behaviors could eventually help the agent solve tasks posed by the environment. We present hierarchical DQN (h-DQN), a framework to integrate hierarchical action-value functions, operating at different temporal scales, with goal-driven intrinsically motivated deep reinforcement learning. A top-level q-value function learns a policy over intrinsic goals, while a lower-level function learns a policy over atomic actions to satisfy the given goals. h-DQN allows for flexible goal specifications, such as functions over entities and relations. This provides an efficient space for exploration in complicated environments. Excerpt from Kulkarni et al [12].
May 12, 2019
%%% Sun May 12 2:56:13 PDT 2019
Lessons learned from discussing final project ideas and reading the final project proposals and related papers:
challenge — synopsis of challenges relating to action selection and executive function;
planning — subroutine learning by differentiable planning within a goal-directed policy;
contexts — relational modeling as the basis for learning when to deploy subroutines;
framework — architectural sketch for leveraging hierarchy and procedural abstraction;
May 11, 2019
%%% Sat May 11 3:43:09 PDT 2019
My primary objective for this weekend has been to finish reviewing all of the final project proposals, provide feedback and schedule any follow-up meetings for next week. My secondary objective is to consolidate what I have learned over the last two weeks about action selection and planning as it pertains to the generation of a library of subroutines that solve a collection of abstract goals relevant to automated program synthesis.
The latter is a special case of lifelong learning in which the challenge is to refine or generate new action plans as required to address new challenges or improve performance with regard to recurring challenges and deal with the problems associated with catastrophic forgetting that require focusing on specific challenges on an as-needed basis and inevitably neglecting the refinement of solutions to existing challenges that recur intermittently in the midst of dealing with the problems at hand.
In the last few entries in this discussion log, we reviewed a number of potentially useful technologies for the programmer's assistant that support automated planning, specifically related to hierarchical inference, action selection and procedural abstraction. In particular, we reviewed work leveraging reinforcement learning to implement automated planning from Pieter Abbeel's group here and here, and, in this entry, we discuss work by Google Brain and DeepMind on learning dynamics to support model-based planning et al [169]. We begin however with brief discussion of relational learning in the context of planning.
In using vanilla reinforcement learning to solve blocks world problems, having learned to put A on top of B given the goal on(A,B), the RL agent has to start all over to learn to put C on top of D and yet these two goals are related to one another — or at least in the blocks world they are related: on(A,B) ⇔ stack(C,D). Here is a corresponding simple programming example that assumes the programmer intended add two numbers X and Y and that the unbound W is a typo in the (def fun (X Y) (+ W Y)) — allowing the following transformation: (def fun (X Y) (+ W Y)) ⇒ (def fun (X Y) (+ X Y)). The challenge is to accurately determine the contexts in which such a transformation is warranted.
Driessens [113] surveys the general area of relational reinforcement learning (RRL) and reviews different approaches including the potential benefits of inductive logic programming which is routinely applied in concept learning but only more recently in RRL. As one might expect, relational databases are concerned with entities and their relationships; an entity that is not related to any other entity is not likely to be of much interest. Dzeroski et al [117] provide an example of RRL applied to blocks world planning combining conventional machine learning techniques with Q-learning [23]:
[W]e present an approach to relational reinforcement learning and apply it to simple planning tasks in the blocks world. The planning task involves learning a policy to select actions. Learning is necessary as the planning agent does not know the effects of its actions. Relational reinforcement learning employs the Q-learning method [Watkins & Dayan, 1992; Kaelbling et al., 1996; Mitchell, 1997] where the Q-function is learned using a relational regression tree algorithm — see [De Raedt & Blockeel, 1997; Kramer, 1996]. A state is represented relationally as a set of ground facts. A relational regression tree in this context takes as input a relational description of a state, a goal and an action, and produces the corresponding Q-value. Excerpt from Dzeroski et al [117].
The following includes excerpts from a recent posting on the Google AI Blog describing PlaNet, a deep neural-network architecture for automated planning using model-based reinforcement learning. If you are unfamiliar with the terminology used in the following description, you might look at the video presentations and lecture notes for David Silver's Introduction to Reinforcement Learning course at University College London.
Model-free approaches to reinforcement learning attempt to directly predict good actions from sensory observations. Model-based reinforcement learning attempts to have agents learn how the world behaves in general. Instead of directly mapping observations to actions, this allows an agent to explicitly plan ahead to more carefully select actions by "imagining" their long-term outcomes. To leverage planning in unknown environments — such as controlling a robot given only pixels as input, the agent must learn the rules or dynamics from experience. PlaNet learns a dynamics model given image inputs and efficiently plans with it to gather new experience.In contrast to previous methods that plan over images, we rely on a compact sequence of hidden or latent states. This is called a latent dynamics model: instead of directly predicting from one image to the next image, we predict the latent state forward. The image and reward at each step is then generated from the corresponding latent state. By compressing the images in this way, the agent can automatically learn more abstract representations, such as positions and velocities of objects, making it easier to predict forward without having to generate images along the way. (SOURCE)
 |
Learned Latent Dynamics Model: In a latent dynamics model, the information of the input images is integrated into the hidden states (green) using the encoder network (grey trapezoids). The hidden state is then projected forward in time to predict future images (blue trapezoids) and rewards (blue rectangle). (SOURCE)
 |
Planning in Latent Space: For planning, we encode past images (gray trapezoid) into the current hidden state (green). From there, we efficiently predict future rewards for multiple action sequences. Note how the expensive image decoder (blue trapezoid) from the previous figure is gone. We then execute the first action of the best sequence found (red box). The authors note that compared to their preceding work on world models, PlaNet works without a policy network — it chooses actions purely by planning, so it benefits from model improvements on the spot. (SOURCE)
Miscellaneous Loose ends: Jerry Meng, John Mern, Elizabeth Tran and Julia White are working on a final project that involves the application of normalizing flows and variational autoencoders. Normalizing flows are used to transform a simple distribution (like a mixture of Gaussians) into a more complex distribution by applying a sequence of invertible transformation functions; the resulting densities can used in a variety of applications involving variational inference et al [314]. If you're interested in learning more you might check Eric Jang's Normalizing Flows Tutorial: Part 1: Distributions and Determinants and Part 2: Modern Normalizing Flows.
May 9, 2019
%%% Thu May 9 3:41:22 PDT 2019
Here is a synopsis of my current thinking as regards what I see as the most glaring problem with current approaches to planning as it relates to the challenges posed by the programmer's apprentice problem:
General Problem: Current approaches to action selection and executive control don't support abstraction, hierarchy or task diversity.Specific Issue #1: A single, all-encompassing value-function approach is inadequate for tackling domains that involve solving general problems, require a range of flexible solution strategies, routinely fail and have to recover gracefully, and interleave tasks that share resources or that have competing preconditions.
Proposed Solution: Integrate a planning capability to generate new or refine existing subroutines and a meta-controller to maintain a stack of subroutine calls, switch between subroutines, abort failed or no-longer-necessary subroutines, recognize and recover from failure and adapt or replan as required by current conditions.
Specific Issue #2: Action selection doesn't adapt to handle new situations and even minor deviations from familiar situations require retraining.
Proposed Solution: Exploit episodic memory to quickly learn new strategies from existing memories and apply them in dealing with novel situations — requires some form of imagination-based synthesis and the ability to apply analogical thinking to generate candidates for abstract analytical consideration and concrete testing.
Specific Issue #3: Action selection often depends on the relationships between entities — relationships that need not be spatially proximal and are often higher order involving multiple entities. Some of these relationships are causal and can be used to guide intervention while others are coincidental and need to be recognized as such.
Proposed Solution: Use a recurrent attentional network to identify task-relevant entities and their associated relationships in the stream of sensory data, generate of apply interaction networks to learn models of the underlying dynamics and employ some form of chunking to consolidate and generalize the related activity.
Miscellaneous Loose Ends: Several of us were talking after class on Thursday and the conversation turned to a discussion of how much early development influences visual processing later in life. I was trying to remember a condition that if not properly handled during early development would leave the child permanently impaired. The developmental characteristic is called ocular dominance and it concerns the tendency to prefer visual input from one eye to the other. I've provided a short synopsis and description of related conditions in this footnote42. Occasionally I entertain the idea of writing another book. Having written four books during my academic career and not really enjoyed writing even one of them, I have somehow managed to avoid making the same mistake for the last twenty years since writing Talking With Computers. I have, however, started many book projects during the intervening years, encouraged by my students, colleagues or publishers. Generally, it is enough to write the first few paragraphs in order to disabuse myself of the conceit that embarking on a multi-year writing project would be a good idea43 .
May 8, 2019
%%% Wed May 8 5:07:46 PDT 2019
Miscellaneous Loose Ends: Google Brain and DeepMind have teamed up to develop Deep PlaNet, a deep planning network for reinforcement learning [169]. PlaNet is touted to be a deep neural network that learns a model from images alone, e.g., sequences of images generated by a simulation environment such as OpenAI Gym or DeepMind Unity, and then uses that model to create plans by using imagination-based simulation. The developers have released the source code to encourage more wide-spread use. In the experimental results presented in the paper, PlaNet significantly outperforms the incumbent preferred A3C (asynchronous advantage actor-critic) model. I haven't read the paper carefully yet, but I thought some of you might find the ideas in the paper applicable to your final projects. Presumably it has a policy that learns to generate a plan to achieve a goal where the plan is itself a policy. Whereas typically we are given the current state and use a policy to infer the best action to take in that state, I'm assuming that the planning policy starts with a desired goal state and attempts to infer the best action to reach the goal or at least make progress toward reaching the goal.
May 7, 2019
%%% Tue May 7 5:38:10 PDT 2019
I think of episodic memory as a vast untapped reservoir of procedural knowledge which can be annotated, adapted and eventually compiled into reusable subroutines that can then be called in various contexts analogous to the sort of conventional procedural abstractions that are provided in modern programming languages. Alternatively or additionally, one could alter the current context so as to start, interrupt or abort a given subroutine, thereby enabling even greater flexibility and fine-grained control. The basic utility of macros, methods, procedures, shell-scripts and subroutines as a means of consolidating function is so obvious to programmers that we take it for granted.
I've been putting off thinking about this topic as it relates to the programmer's apprentice — both the design of the apprentice neural-network architecture and the particular problems that the apprentice is intended to assist in solving, primarily because there are so many other apprentice-related challenges to contend with in exploring this space. However, related issues have come up so often in the context of our recent final project discussions that I can't avoid it any longer — even though I have no particular inspiration to guide me. And so I ask you to bear with me in the next few installments as I step off the deep end and thrash about for a while in trying to find some purchase.
Much of the current work on hierarchical reinforcement learning is based directly or indirectly on a widely cited paper by Tom Dietterich [9] that introduced a general framework building on earlier work by Satinder Singh [342], Peter Dayan and Geoff Hinton [82], Leslie Kaelbling [15] and some of my theoretical work with students and colleagues [90, 14] on state-space decomposition applied to modeling planning problems involving uncertainty as discrete-time, finite-state stochastic automata, i.e., Markov decision processes. The abstract of Dietterich's paper clearly states the basic premise:
This paper presents a new approach to hierarchical reinforcement learning based on decomposing the target Markov decision process (MDP) into a hierarchy of smaller MDPs and decomposing the value function of the target MDP into an additive combination of the value functions of the smaller MDPs. The decomposition, known as the MAXQ decomposition, has both a procedural semantics—as a subroutine hierarchy—and a declarative semantics—as a representation of the value function of a hierarchical policy. [...] It is based on the assumption that the programmer can identify useful subgoals and define subtasks that achieve these subgoals. By defining such subgoals, the programmer constrains the set of policies that need to be considered during reinforcement learning. The MAXQ value function decomposition can represent the value function of any policy that is consistent with the given hierarchy. The decomposition also creates opportunities to exploit state abstractions, so that individual MDPs within the hierarchy can ignore large parts of the state space. Excerpt from Dietterich [9].
In more recent work Tamar et al [19, 163] and others in Pieter Abbeel's group at Berkeley have developed specific neural network architectures for reinforcement learning that support hierarchical planning:
We introduce the value iteration network (VIN): a fully differentiable neural network with a "planning module" embedded within. VINs can learn to plan, and are suitable for predicting outcomes that involve planning-based reasoning, such as policies for reinforcement learning. Key to our approach is a novel differentiable approximation of the value-iteration algorithm, which can be represented as a convolutional neural network, and trained end-to-end using standard backpropagation. This excerpt and the following graphic are adapted from [19].
 |
In subsequent work, Srinivas et al [349] demonstrated a rather elegant neural network architecture (Figure 68) that supports differentiable planning within a goal-directed policy:
We introduce the universal planning networks (UPN) for learning abstract representations that are effective for specifying goals, planning, and generalization. UPNs embed differentiable planning within a goal-directed policy. This planning computation unrolls a forward model in a latent space and infers an optimal action plan through gradient descent trajectory optimization. The plan-by-gradient-descent process and its underlying representations are learned end-to-end to directly optimize a supervised imitation learning objective. This excerpt and the following graphic are adapted from [349]:
| |
| Figure 68: Given an initial observation ot and a goal observation og, the gradient descent planner (GDP) uses gradient descent to optimize a plan to reach the goal observation with a sequence of actions in a latent space represented by fφ. This planning process forms one large computation graph, chaining together the sub-graphs of each iteration of planning. The learning signal is derived from the (outer) imitation loss and the gradient is back-propagated through the entire planning computation graph. The blue lines represent the flow of gradients for planning, while the red lines depict the meta-optimization learning signal and the components of the architecture affected by it. Note that the gradient descent planner iteratively plans across np updates, as indicated by the ith loop. Models are trained on synthetically-generated expert demonstration data so as to produce actions that match the expert demonstrations. There are two loops, one nested inside the other, each one having its own loss function. 𝓛(i)plan is an instance of the Huber loss function for well-behaved inner-loop gradients and 𝓛imitate is an outer-loop L2 norm on the imitation error. The above graphic and following commentary are adapted from [349]. | |
|
|

I recommend reading the two papers mentioned above or jumping directly here for a more recent entry in the class discussion list that discusses hierarchical planning. The remainder of this entry consists primarily of my thoughts as they relate to topics in cognitive science and developmental psychology. Figure 70 is an early sketch that I will return to in (chronologically) subsequent entries as time permits.
| |
| Figure 69: The three panels shown above represent three ideas — illustrated here as neural-network components — that we might leverage in designing an hierarchical reinforcement learning system that utilizes contexts as a means of learning subroutines. Panel A shows a meta-control architecture for imagination-based program emulation based on ideas from Hamrick [170], Weber et al [394] and Pascanu et al [295], Panel B shows a partitioned program-plus-call-stack memory for representing differentiable programs [87], and Panel C is adapted from [348] and intended for local parameter adaptation for contextualized procedural abstractions. | |
|
|

Here (Figure 69) we leverage ideas on relational deep reinforcement learning and self attention [409], exploiting past experience in the form of episodic memory [303], context-based local adaptation of examples stored in memory [348] and draw inspiration from research in cognitive neuroscience on how sensory context activates abstract rule sets to enable transfer learning in novel contexts [73]:
Often the world is structured such that distinct sensory contexts signify the same abstract rule set. Learning from feedback thus informs us not only about the value of stimulus-action associations but also about which rule set applies. Hierarchical clustering models suggest that learners discover structure in the environment, clustering distinct sensory events into a single latent rule set. Such structure enables a learner to transfer any newly acquired information to other contexts linked to the same rule set, and facilitates re-use of learned knowledge in novel contexts. [...] These results further our understanding of how humans learn and generalize flexibly by building abstract, behaviorally relevant representations of the complex, high-dimensional sensory environment. Excerpt from Collins and Frank et al [73].
The way in which we employ the word context here is also related to the notion of option as introduced in Sutton et al [22] to describe closed-loop policies for taking action over some period of time:
Learning, planning, and representing knowledge at multiple levels of temporal abstraction are key, longstanding challenges for AI. In this paper we consider how these challenges can be addressed within the mathematical framework of reinforcement learning and Markov decision processes (MDPs). We extend the usual notion of action in this framework to include options — closed-loop policies for taking action over a period of time. Examples of options include picking up an object, going to lunch, and traveling to a distant city, as well as primitive actions such as muscle twitches and joint torques. Overall, we show that options enable temporally abstract knowledge and action to be included in the reinforcement learning framework in a natural and general way. In particular, we show that options may be used interchangeably with primitive actions in planning methods such as dynamic programming and in learning methods such as Q-learning. Formally, a set of options defined over an MDP constitutes a semi-Markov decision process (SMDP), and the theory of SMDPs provides the foundation for the theory of options. However, the most interesting issues concern the interplay between the underlying MDP and the SMDP and are thus beyond SMDP theory. We present results for three such cases: (1) we show that the results of planning with options can be used during execution to interrupt options and thereby perform even better than planned, (2) we introduce new intra-option methods that are able to learn about an option from fragments of its execution, and (3) we propose a notion of subgoal that can be used to improve the options themselves. All of these results have precursors in the existing literature; the contribution of this paper is to establish them in a simpler and more general setting with fewer changes to the existing reinforcement learning framework. In particular, we show that these results can be obtained without committing to (or ruling out) any particular approach to state abstraction, hierarchy, function approximation, or the macro-utility problem. Excerpt from Sutton et al [22].
| |
| Figure 70: This figure is almost as summarily unsatisfying as it is expansively misleading. Be that as it may, I've left it as a sketch to be fleshed out with more detail in one or more (chronologically) subsequent entries in this log. The diagram shows: A an NTM partitioned into program memory for storing subroutine parameters and a call stack that keeps track of the contexts for all of the subroutines currently in play; B the read-write-head controller for the NTM in which each location corresponds to a key-value pair with a context as the key and the (learned) parameters of a subroutine as the value; C the meta-controller RL that determines the current context from the state and call history; and D a composite policy that combines a fixed low-level policy (roughly analogous to the neural circuits that modulate the direct and indirect pathways of the basal-ganglia-striatum system) that generates primitive actions given the current state and the output of the context-adapted (roughly analogous to the hyper-direct frontal-cortex pathway) subroutine (mid-level) controller [229]. Note that the model shown here makes no attempt to explain how we might learn the context-adapted subroutines, but the subsequent entries here and here provide more recent speculations. | |
|
|

Contexts are derived from the current state or predicted from a combination of the currently open contexts and the recency weighted sum of earlier states. The same machinery is responsible for recognizing when to change context in which case a related meta-controller carries out the change and updates existing open contexts in accord with the dependencies recorded in the call stack. The hierarchy of contexts implicit in the order in which contexts are created — including the parent context — is not rigidly adhered to and dependencies between open contexts are treated as semi-permeable, allowing for some possibility of identifying and recovering information from any open context.
A context corresponds to an abstraction in that it packages generic procedural declarations, allowing them to be specifically crafted for the current circumstances and thereby invoked to perform specialized computations that are adapted to achieve context-specific outcomes. Collins and Frank [73] make the same point by describing a context as signifying a set of different situations all of which can be handled by employing the same abstract rule set.
The notion of a closure in functional programming is relevant here for the way in which the current scheme deals with information encoded in a given context and how it deviates from the strict concept of closure in functional programming. Implicit variable bindings that arise in the process of invoking a context are generally not available outside of that context. Explicit variable bindings that arise in, say, inferring the referent of a pronoun in an earlier sentence in the midst of reading a document or carrying on a conversation, can generally be thought of as global variables unless the binding is overridden, e.g., by using the same pronoun to refer to a new entity. Obviously this becomes tricky and hence we don't assume the machinery described here as being able to make such subtle determinations.
Out of the womb we have no learned repertoire of actions. The wiring of the cortex is in a state of early development and there are few connections that might yield any interesting activity. However, the developing infant rapidly achieves some degree of primitive sensory-motor control and is instinctively able to move its limbs within the first few months. Simple sensory motor activities initially occur spontaneously, but then are reinforced by a combination of extrinsic and intrinsic rewards44.
Over time these simple activities are strung together to produce more complicated and sophisticated activity. Already the primary sensory areas in the cortex are learning to parse the world in ways that allow the infant to explore its environment especially as it relates to the pleasures of food and warmth and physical contact. The basic reinforcement learning circuits — minus any contribution from the underdeveloped prefrontal cortex — are in play very early in development and there is an innate tendency to experiment and string together simple actions relying on feedback to achieve simple goals.
As the child develops, so too its capacity to encode memories and the ability to replay recorded activities as a basis for simple skill learning. Encoded memories reflect the nascent status of the basic sensory motor activations designed to capture both stimulus and response along with emotional valence. As the relevant cortical structures begin to mature creating richer representations of the extant features that reflect this more abstract understanding of the world, so to the recorded activity becomes more abstract and subsequently able to generalize from specific experience45.
Even the earliest episodic memories include both the sensory context in which activities are carried out and the commands that produce physical changes in the environment. The developing child is able to integrate similar activities that produce analogically similar outcomes such that the activities and outcomes are related by some commonality among their respective abstract recorded memories. This is the conceptual basis for relational reinforcement learning46.
Some memories evolve into generalized behaviors that share the same skeleton but differ in the details of their inputs and outputs. One can invoke these skeletal behaviors by adapting them on the fly using some form of constructive reimagining, but this requires some effort and so instead are attached to structures that serve as containers coupled with bespoke circuits trained to produce the same outcome as constructive reimagining but without the effort and time required of such reconstruction. We refer to these adaptive circuits as subroutines since they can be utilized in multiple contexts and further generalized as they provide value in new contexts. They package utility and focus reuse.
Subroutines are keyed to special contexts that group together situations in which they provide value so that further refinements and generalization can be stored in a single location to facilitate their widespread use and utility. Subroutines can be nested when their corresponding contexts are sufficiently aligned with one another, thereby generating a hierarchy of abstractions that allows for a good deal of versatility and lends itself to dealing with not just concrete instances of generalized activity, but the abstractions themselves as they arise in everyday conversation and diverse technical and intellectual pursuits.
April 28, 2019
%%% Sun Apr 28 15:38:10 PDT 2019
Miscellaneous Loose Ends: I appear to have caught a cold. At first I thought my sneezing and runny nose were due to all the pollen in the air. However, by Friday evening it was pretty obvious that it was a cold or something so like a cold that it didn't make any difference. Despite the cold symptoms, I felt antsy but couldn't focus long enough to do any useful work. Then I made the mistake of listening to a podcast about consciousness during which some philosopher went on and on about qualia, and I got so aggravated that I started writing a piece about how we experience our bodies and the next thing you know I'm hurtling down the rabbit hole. The resulting missive doesn't deserve a prominent place in the class notes, but if you're interested in how nociceptors and our faculties of interoception, exteroception and proprioception conspire to create our sensation of pain, you might check out the footnote at the end of this sentence47.
April 21, 2019
%%% Sun Apr 21 3:27:11 PDT 2019
One of the technical issues I've been thinking about concerns the conversations we've been having with Adam Marblestone, Loren Frank and Michael Frank, representing the three key disciplines we are trying to bring together in this course: namely, cognitively inspired neural architectures — featuring Adam, Greg Wayne, Jessica Hamrick and their colleagues at DeepMind, translating insights from cellular and molecular neuroscience — starring Loren and several other scientists whom we’ve enlisted, and systems and cognitive neuroscience — with Michael building on our relationships with Randy O'Reilly's at University of Colorado at Boulder and Matt Botvinick at DeepMind.
In particular, one aspect that I hadn't anticipated is playing out now as we start to design and evaluate more comprehensive composite architectures. The issue relates to the trade-off between employing bespoke architectural features supporting, for example, persistent storage and easily addressable locations in working memory and the related variable-binding problem, and the alternative of providing more general architectural components and relying upon unsupervised and reinforcement learning along with novel curricular training strategies to adjust the weights in the general-purpose component networks located strategically within the architecture specifically for this sort of adaptation.
I am predisposed to the latter, while Adam and Greg seem more inclined to the former. Their intuition is that without a strong structural bias it will be difficult to learn how to adapt these general-purpose networks. My argument is that our track record in building this sort of structurally biased systems is rather discouraging — the canonical example being nearly a decade of trying to exploit the conceit that we knew enough to design a Gabor filter basis for the initial layers of a convolutional stack for machine vision. As an additional argument, since we are capable of mathematical thinking we assume that natural selection has provided the necessary architectural components upon which to build such a facility, whereas it is entirely possible that natural selection was driven by very different ethological incentives that had little or nothing to do with symbolic manipulation and hence the fact that children have so much trouble learning such skills.
April 20, 2019
%%% Sat Apr 20 3:45:33 PDT 2019
I'm counting on Adam, Loren and Michael to provide the class us with a perspective on the hippocampus and basal ganglia and their possible function in cognitive architectures of the sort we are attempting to understand in this class. The expectation is that we can learn something from each of recent advances in (i) artificial neural networks, (ii) cellular and molecular neuroscience and (iii) systems and cognitive neuroscience62. We hope to apply what we learn toward developing computational models that might serve as a bridge or common language for characterizing the computational properties of such systems. Practically speaking, this implies that the resulting architectures, while they exhibit novel behavior, are composed of familiar components and employ conventional methods of training, without need of arbitrary hacks to assemble the components into working models. This is an exercise designed to explore possibilities, not an hypothesis we are willing to die for, as Karl Popper would say.
Adam led off with an analysis of two important challenges to successfully integrating some form of symbolic reasoning within a (primarily) connectionist architecture. Earlier Randall O'Reilly underscored the advantages of such hybrid architectures, and, in his talk Adam discussed his work with Greg Wayne at DeepMind and Ken Hayworth at HHMI Janelia Research Campus on stable, addressable locations in working memory and the related variable-binding problem. Next Tuesday, we will review Greg Wayne's talk from last year on memory, prediction and learning in decision problems characterized as partially observable Markov processes (POMDP) that Adam referred to in his presentation.
In preparation for Loren and Michael's participation, I will suggest some questions that we might tackle in class and then describe a straw-man architecture to help ground the discussion of modeling with artificial neural networks. For Loren63, what do we know from directly observing neural activity in mouse models during repeated trials of maze learning? For Michael, what further have we learned from fMRI studies of human subjects solving memory related problems and postmortem studies of patients with lesions in relevant cortical and subcortical regions? For all of us, what is the state-of-the-art in developing computational models of mouse navigational-related cognition and human cognitive capabilities involving both the hippocampal-entorhinal-cortex complex and the cortico-thalamocortical plus basal-ganglia circuits ostensibly responsible for executive-control and variable-binding in human symbolic reasoning?
Finally, relating to the previous item and relevant to the practical application of these ideas in building AI systems that employ existing ANN architectural components, how might we design systems that, while they are inspired by biological neural networks, deviate from these biological architectures by employing second-generation components like neural Turing machines and novel training strategies to coerce these component networks to mimic our reimagining of how advanced cognitive strategies and symbolic reasoning in particular can be efficiently implemented?
This last strategy is related to Terrence Deacon’s argument for the co-evolution of language and neural circuits that can be trained by developmentally staged exposure to ambient language processing. Essentially, natural selection need only engineer the basic circuitry such that it is within the capacity of a young child to coerce this general circuitry to serve the needs of language processing, where the language itself is shaped by selection pressures imposed by adults who both rely on language to survive and benefit from learning new ways in which language can assist survival while at the same time ensuring that it can easily be passed on to the next generation via some combination of unsupervised and reinforcement-based learning.
| |
| Figure 67: This diagram shows a cognitive architecture assembled entirely from conventional, off-the-shelf neural network components including multi-layer convolutional networks for uni-modal primary sensory and multi-modal association areas, an attentional network configured with an objective function based on a version of Yoshua Bengio's consciousness prior [38], two differentiable neural computer networks, one capable of storing a relatively small number of key-value pairs and a second of storing a much larger set of pairs, to model, respectively, working memory and episodic memory. | |
|
|

As an example, consider the architecture shown in 67 featuring a stack of standard neural network components including both attentional circuits and differentiable neural computing elements, i.e., stock Neural Turing Machines with configurable controllers. In architecture shown, there is no (explicit) provision made for many of the critical cognitive capabilities attributed to the circuitry of the prefrontal cortex, cortico-thalamic-basal-ganglia or hippocampus-entorhinal-perirhinal-and-parahippocampal systems. The conceit is that various hidden layers, for example, in the boxes shown with dashed borders, are supplied specifically to encourage these capabilities by teaching the system how to control the machinery of the supplied memory and routing systems strategically placed to serve such roles. Given what we know about how difficult it is for children to learn basic mathematical skills involving symbolic reasoning, this learning may require some form of curriculum-based, staged developmental cultivation64.
April 19, 2019
%%% Fri Apr 19 5:02:46 PDT 2019
Slide 11 in Adam's slides relating to Solari and Stoner [345] (HTML) is the start of his description of Hayworth and Marblestone [177] "How thalamic relays might orchestrate supervised deep training and symbolic computation in the brain". While Adam and Ken provide a coherent account of how thalamic latches and working memory buffers might arise naturally in human brains. The following is an excerpt from an email message to Adam concerning the part of his presentation at 00:34:20 into the recorded video of his talk:
I enjoyed the description of the model that you and Ken developed and especially your theoretical explanation of how cortico-thalamic-basal-ganglia circuitry might have evolved thalamic latches to support working memory buffers. It reminded me of Terrence Deacon's The Symbolic Species: The Co-evolution of Language and the Brain [5] in which he takes Chomsky to task by first making the case that syntax and semantics together are needed to bootstrap language, observing that the foundation of symbolic processing as it relates to meaning comes down to the semiotic theory of Charles Sanders Peirce with its focus on three basic types of sign — icons, indices and symbols, and noting that learning a gramar building on such a foundation is rather simple and therefore there is no need for an innate universal grammar.
He then explains how language and symbolic processing co-evolved drawing on Jeffrey Elman's recurrent neural network model — the so called simple recurrent networks (SRN) of Elman and Jordan to explain (a) the need for recurrent connections in processing combinatorial symbolic representations and (b) how the problem of local minima can be solved using an early form of curriculum learning that involves learning layer by layer and strategically clamping weights to shape the energy landscape as the network's symbolic manipulation circuity gradually becomes more and more capable. He spends an entire section describing how language and the brain's symbol processing ability co-evolved with the former an emergent phenomenon arising out of human social intercourse and providing the essential scaffolding on which to erect civilization.
It's a wonderful treatise and convincing argument. I've included two excerpts in the footnote at the end of this sentence to give you a flavor of his argument65. The book is out of print, but there's a PDF here and if you open it in the Chrome browser — rather than Apple Preview — then it is easy to search and select text since Google knows how to do search in documents with uncommon fonts, kerning and other typesetting intricacies — whereas Apple either doesn't know how or doesn't care enough to get it right. Deacon's latest book Incomplete Nature: How Mind Emerged from Matter [85] is even more ambitious and complex — possibly completely off base but interesting nonetheless — and you can check out my short summary here if you are tempted.
April 17, 2019
%%% Wed Apr 17 04:17:31 PDT 2019
Relating to some conversations right after class on Tuesday, understanding how the hippocampus works in memory retrieval and subsequent reconsolidation is key to developing powerful episodic memory systems that support imaginative recall (what researchers at DeepMind call imagination-based planning and optimization) and various means of organizing episodic memory to support replay for training reinforcement-learning models and subroutine construction (what psychologists and cognitive neuroscientists going back to Tulving call chunking [8]).
One of the big mysteries has to do with the reciprocal nature of hippocampal-cortical interaction and the patterns of connectivity between hippocampus and the perirhinal and parahippocampal cortex and between these regions and association areas in the parietal and temporal cortex. Patch-clamp electrophysiology and macroscale tractography provide tantalizing hints but better detail and coverage would substantially accelerate our understanding.
See the attached introduction to the special issue of Hippocampus on hippocampal-cortical interactions for a nice survey of the state of the art in 2000 and the recent articles citing [231] from PubMed more up-to-date research. If as suggested in [231] the feedback efferent projections from the perirhinal and parahippocampal cortices to the neocortex largely reciprocate the afferent projections from the neocortex to these areas, this would simplify designing an architecture recapitulating hippocampal function. The Maguire et al [246] paper points out some of the diagnostic implications66.
Miscellaneous Loose Ends: On a related note, I once thought that lucid dreaming — a technique I have toyed with at various times — helped me to focus attention and leverage the benefits of lying quietly in bed just prior to sleep, in order to solve problems that have eluded me during the day. Now, having read Nick Chater's The Mind is Flat [67], I have to entertain the possibility that ideas I attributed to lucid dreaming might have an alternative explanation. Specifically, lucid dreaming assumes that prior to going to sleep you settle your mind and focus your attention on the problem that has been vexing you during the day. In this preparatory stage, the point is not to try to solve the problem, but rather frame it as clearly as possible and then allow your prepared mind the opportunity to solve the problem while you are sleeping and not otherwise distracted.
Scientists from a broad range of disciplines have reported some success in applying this technique model to solving problems [384]. An alternative explanation might go something like the following: in framing the problem and settling your mind in preparation for sleep, you've already accomplished something that was difficult to do while waking, given the distractions in your workplace. That alone could have made a significant difference in whether or not you arrived at a solution. In addition, sleep specialist often refer to the idea of placing the problems of the day on the shelf so as not to disturb your sleep, parking them, as it were, at some remote from your sleeping mind. These preparatory steps — parking your worries of the day and settling your mind — are conducive to getting a better night sleep, and so could make it all the more plausible that you would come up with a solution upon waking or in that half-awake state just prior to arousal and waking fully. Of course, Chater only characterizes the unconscious variants of thought as being shallow, mere vestiges of fully conscious thought. And so, it is also consistent with Chater's theory and the practice of lucid dreaming, that we indulge in some form of problem-solving during sleep perhaps akin to hypnagogic hallucinations or some form of metacognition.
April 15, 2019
%%% Mon Apr 15 03:40:11 PDT 2019
Thanks again to Brian and Michael for their presentation last week. Tomorrow, Elizabeth, Jing, Olina, Orien, Riley and Vidya will be leading the discussion of Randall O'Reilly's presentation from last year. There are three primary topics covered in Randy's talk:
The distinction between symbolic computing characterized as slow, essentially-serial and combinatorial on the one hand, and connectionist computing characterized as fast, highly-parallel, distributed and context-sensitive on the other. Randy's talk begins with this topic and the "limited systematicity" paper [292] provides the necessary detail. This may seem esoteric but, in fact, it is central to both the applied development of AI and our understanding of merits and limitations of biological computation. We will return to this issue in our discussions with Adam Marblestone, Loren Frank and Michael Frank, all three of which will be participating in classes. Adam Marblestone who will be joining us on Thursday and is currently working with Greg Wayne at DeepMind has written extensively about related issues [250, 252, 253].
The role of the hippocampal-entorhinal-cortex complex system (HPC-EHC) that underlies episodic memory and imaginative recall. In the first two lectures, I described how one might map the neural correlates of this fundamental cognitive function onto a relatively simple artificial neural network utilizing Differentiable Neural Computing / Neural Turing Machine as the basis for associative encoding of experience and subsequent recall. Loren Frank — participating on Thursday, April 25 —is an expert on the associated biological networks and Michael Frank contributed substantially to the Leabra System and corresponding computational models of long-term memory and executive control.
The role of the basal-ganglia, thalamus and prefrontal cortex (BF-PFC) in action selection and executive control as well as the interaction between the BF-EHC and HPC-EHC systems. Michael Frank — participating Tuesday, April 20 — has made several important contributions to our understanding of this system and Randy's overview does a great job presenting the relevant concepts. As a visual supplement you might look at the series of short videos created by Matthew Harvey with help from Felix May and available on the Brain Explained YouTube channel.
Upcoming presentations / talks listed on the class calendar include:
Randall O'Reilly, University of Colorado, Boulder, Tuesday, April 16 [HTML] — discussion led by Elizabeth, Jing, Riley, Orien, Olina and Vidya;
Adam Marblestone, Google DeepMind, Thursday, April 18 [HTML] — Adam will be presenting in class;
Greg Wayne, Google DeepMind, Tuesday, April 23 [HTML] — discussion led by Albert, Ben, Julia, Lucas, Manon and Stephen;
Loren Frank, University of California, San Francisco, Thursday, April 25 [HTML] — Loren will be presenting in class;
Michael Frank, Brown University, Tuesday, April 30 [HTML] — Michael will be presenting in class.
April 11, 2019
%%% Thu Apr 11 10:07:33 PDT 2019
Some of my recent correspondence included ideas, commentary and recommendations that I normally would have cleaned up and included in the class discussion log had I the time — and so I'll take the expedient of including relevant excerpts that were partly inspired by conversations in class or in email exchanges with students.
%%% Thu Apr 11 3:46:31 PDT 2019
We've been discussing class projects that involve agent architectures that employ variations on the network illustrated in Figure 66 and composed of the following subnetworks:
Semantic Memory — refers to circuits corresponding to multi-modal association areas primarily in the posterior that encode abstract representations grounded in various sensory — including somatasensory and auditory language-related input [8, 7];
Episodic Memory — implemented using DNC networks inspired by the hippocampal complex including frontal and entorhinal cortex — the connection to pattern separation and pattern completion in the hippocampus was mentioned in the Nature paper [2];
Conscious Attention — a narrow characterization of conscious awareness involving circuits in the frontal cortex that use reinforcement learning to learn to survey activity in semantic memory and attend to exactly one thing at time thereby serializing conscious thought [102, 370, 95];
| |
| Figure 66: Here is a simple schematic illustrating the primary reciprocal connections linking the three subnetworks described in the text. Information enters via the peripheral nervous system as sensory data that serves to ground the agent in the physics of its body and accessible environment. The data — including the obvious sensory systems plus the somatasensory and subcortical nuclei comprising the limbic system — is processed by the same highly-parallel machinery that underlies all forms of perception, progressing through multiple layers of abstraction and increasing integration of sensory modalities until activating highly-abstract patterns in semantic memory. These patterns are surveyed and selectivelyand serially activated enabling the hippocampal-entorhinal complex to probe episodic memory and recover related patterns from prior experience to compare with and possibly (imaginatively) enrich current experience. | |
|
|

The full architecture also includes an action selection component modeled derived from the work of Matt Botvinick and Randy O'Reilly described in their respective presentations from last year here and here, but for now we're primarily interested in a simpler agent that just observes, selectively commits patterns of activity in semantic-memory to episodic memory and learns to predict simple dynamic phenomena the agent is biased to be interested in. We were interested in your comments concerning strategies for training imagination-augmented agents from your recorded talk in class last year. How hard would it be to train such a system given the recurrent patterns of activity between the three major subnetworks as illustrated in the attached? The attentional system would be trained by reinforcement learning using an objective based on Yoshua Bengio's "consciousness" prior [38]. The primary and secondary sensory components would use some sort of semi-supervised learning based on samples collected from the target environment. The DNC as shown is divided into a write-only long-term memory and a short-term memory for the active maintenance of patterns of activity in semantic memory highlighted by conscious attention and could be replaced with a variant of Geoff Hinton's fast weights [25, 21].
To: Adam, Michael, Loren and Jessica
%%% Fri Apr 12 11:52:53 PDT 2019
I'm not nearly as fussy as Adam and Greg. In my work with Rishabh on automated code synthesis, I developed a neural-network representation of procedures that allows one to embed a collection of procedures that can call one another and (recursively) themselves in a Neural Turing Machine [153] (NTM) / Differentiable Neural Computer [2] (DNC) in order represent structured programs. To complement this framework and provide tools for automatic programming, I described how one might build a program emulator — essentially an interactive read-eval-print interpreter — that would enable an ANN to analyze and execute such programs. The computations performed by the NN emulator only approximately simulate the actual program, but the distributed (connectionist) representations of the intermediate and final results of emulating the NTM representation of a program could be very useful for code synthesis if combined with the sort of imagination-based planning and optimization discussed in several recent DeepMind papers [295, 172].
Since my rough-and-ready model of the hippocampal-entorhinal-cortex (HPC-EHC) complex is essentially an NTM with a specialized controller that supports a differentiable version of C pointers, it naturally occured to me to think of the key-value pairs as a neural-network model of place- and / or grid-cells that could be used to follow paths though computational space, i.e., execution traces, in order to analyze, alter and debug programs. And, as long as I'm spinning speculative tales, serve as the conceptual basis for storing, applying and adapting everyday plans in episodic memory, with the basal-ganglia-prefrontal-cortex (BG-PFC) executive-controller serving as the component responsible for figuring out when to initiate, terminate / abort, adapt or repair programs / subroutines. It might be interesting to the neuroscience community if were able to demonstrate such a model observing traces of executing programs, encoding traces as episodic memory in an NTM model of the HPC-EHC complex, and subsequently using the BG-PFC controller to imaginatively adapt old traces to work in new circumstances.
%%% Sat Apr 13 03:54:23 PDT 2019
Here's a note I sent David Chalmers after we exchanged email following his presentation at Google on April 2. You can watch the video or read the paper [64] — the questions from the audience and Chalmer's responses were my favorite part, and below is my effort to summarize my thoughts in less than a thousand words — it weighs in around 750:
I don't want to sound too cavalier in my dismissal of the nuances regarding consciousness that philosophers seem concerned about. I've always liked Dan Dennett's understanding of free will worth having [Dennett, 2015] and so it was natural for me to read his books about consciousness, but I got tired of the seemingly endless wrangling over the details and the tendency to draw in the opinion of every philosopher since Socrates in order to buttress or defend their theories — the problem is that the nuggets of wisdom are buried in (putatively) didactic prose. A couple of years ago I ran across your adviser's "I Am a Strange Loop" [Hofstadter, 2007], and instantly felt enlightened — I ended up never reading the book but the inspiration I got from the title alone seemed profound at the time and remains so for me. I read and for the most part agreed with Dehaene and Graziano, but they did little to increase my understanding of the larger, evolutionary puzzle of consciousness.Then I read about research relating to the so-called dual-streams hypothesis as applies to language processing and it clicked for me that there was another (reciprocal) pathway completing the language-production-and-understanding loop, and that this bidirectional path was essential to understanding how being conscious might feel — or at least how people report it to feel. And then finally, I read — or mainly skimmed — Nick Chater's "The Mind is Flat" [Chater, 2018], and his account of human subconscious thinking made the rest seem plausible. If you haven't read Chater's book, the main idea is that all of our subconscious thinking is the result of interpreting sensory input — broadly construed, using the same neural circuitry we employ in perception. Everything that enters the brain through the peripheral nervous system is fodder for constructing abstract representations grounded in the physics of our bodies and the environment in which we live.
These abstract representations form what systems neuroscientists refer to as semantic memory and they are constructed by highly-parallel neural processing all of which succumbs to the same sort of perceptual / conceptual errors we make in thinking that when we look at or listen to a complex scene or polyphonic recording, we are simultaneously attending to all the details, when in fact the brain fools us into thinking this by a combination of imaginatively filling in the details and literally bringing into focus the details only when we alter our focus of attention to emphasize these details. Hence it feels to us as though we are both deep — in terms of our interpretations of what we perceive — and comprehensive — in that we take in the entire sensory experience in one fell swoop, whereas in reality our apprehension and analysis are shallow and piecemeal.
The dual-streams hypothesis suggests that the basic circuitry of the primate visual system with its ventral and dorsal streams constructing complementary representations of visual scenes through many layers of primary, secondary and association areas, is recapitulated in the auditory sensory cortex with one important detail of particular importance in this discussion, namely that these two streams form a loop such that two important brain regions — Broca's and Wernicke's areas — are reciprocally connected by fast, myelinated tracts that facilitate unsupervised learning and, importantly, inner speech [Fernyhough, 2015; Hickok and Poeppel, 2007]. The obvious implication being that when we talk to ourselves we not only hear ourselves but what we say modifies what we think, and just as in other areas of perception even as we change our focus of attention and serialize our thoughts and vocal expression we create a narrative that in some very real sense becomes the story of our lives.
Moreover, since our thoughts are primarily the result of exploiting patterns of activity highlighted by conscious attention in order to recall from our past experience episodes that might help in shaping our future experience, this recursive storytelling — what Hofstadter calls a "strange loop" — produces a narrative that includes a play-by-play account that personalizes everything we see, hear, feel and indeed what we think. Moreover, this personalization is pervasive since, to the mind hidden away in — or, as I like to say. "haunting" — the dark recesses of our brains, the distinction between and origins of perceptual events are largely inaccessible, and, according to many accounts, engineered by natural selection so that we don't notice and become alarmed of just how shallow and incomplete our understanding and apprehension of the world actually is.
April 7, 2019
%%% Sun Apr 7 04:24:06 PDT 2019
Prepare for class on Tuesday (April 9) by reading one or more of the three assigned papers and viewing at least the first part of Oriol Vinyals' talk here. You don't learn complex concepts by osmosis. You have to read the material for an initial exposure and then review it in order to consolidate your understanding — class on Tuesday will help with the review and Oriol and your fellow students will be able to answer your questions. You're studying machines that learn and so you have no excuse for not following what we know about how humans learn. I won't apologize for pointing out what should be obvious, but I promise I won't do it again.
We need volunteers for the next few speakers / presentations. Note that I'm giving you a chance to volunteer since you made it crystal clear that you would prefer this to my making random assignments. Jessica Hamrick will be joining us on Thursday (April 11). Jessica's recommended papers, presentation and video are all available on her calendar page here. I've listed Jessica's four suggested papers below along with BibTeX references and links to PDF provided on the calendar page; if you're interested in volunteering, send me email ASAP with a list, e.g., 1.C, 2.E, 1.D, sorted by preference, starting with your most preferred:
Analogues of mental simulation and imagination in deep learning [170] — 1.A
Metacontrol for adaptive imagination-based optimization [32] — 1.B
Relational inductive biases, deep learning, and graph networks [172] — 1.C
Relational inductive bias for physical construction in humans and machines [171] — 1.D
Next Tuesday (April 16) we will go over Randall O'Reilly's 2018 presentation in the same way we'll go over Oriol's presentation this coming week. Note that both Oriol and Randy have agreed to answer questions via email and help out presenters. Randy's presentation is directly relevant to our understanding of fundamental computational tradeoffs in biological intelligence. He covers (a) the hippocampus (episodic memory), (b) the basal ganglia (action selection) and (c) the key issue of how brains integrate parallel, contextual, distributed (connectionist) representations with largely-serial, systematic, combinatorial (symbolic) representations. Below are the papers I will be assigning — you can find BibTeX, PDF, slides and video here:
Making Working Memory Work: A Model of Learning in the Prefrontal Cortex and Basal Ganglia [16] — 2.A
Six principles for biologically based computational models of cortical cognition [286] — 2.B
Towards an executive without a homunculus: models of prefrontal cortex/basal ganglia system [178] — 2.C
Biologically Based Computational Models of High-Level Cognition [288] — 2.D
How Limited Systematicity Emerges: A Computational Cognitive Neuroscience Approach [292] — 2.E
Finally, next Thursday (April 18) Adam Marblestone will be joining us on VC from London where he is currently working with Greg Wayne at DeepMind. Adam is a polymath and incredibly prolific and diverse in his interest as you can see from this description. He majored in quantum physics at Harvard, did his PhD with George Church on DNA origami and molecular labeling using in situ hybridization, has done a lot of research with Ed Boyden and is still affiliated with Ed's lab, worked for a while at Bryan Johnson's Kernel startup and now is at DeepMind. We've got something special planned for April 18th that I'll tell you about as soon as we get things a little more organized.
April 5, 2019
%%% Fri Apr 5 2:44:05 PDT 2019
Note to Tyler, Julia, Jerry, John, Meg and Paul regarding the papers for Tuesday's class discussion featuring Oriol Vinyals' 2018 presentation. Thanks again for agreeing to do this on relatively short notice. Here's a table of names and email addresses in case you want to coordinate — which is probably a good idea just so everyone is on the same page on Tuesday:
|
The slides and videos are in the course archives here and your paper assignments are listed below along with links to the assigned papers:
Learning model-based planning from scratch [295] [John, Tyler]
Imagination-Augmented Agents for Deep Reinforcement Learning [394] [Julia, Meg]
Learning to Search with Monte Carlo Tree Search (MCTS) networks [164] [Jerry, Paul]
Here's what I expect on Tuesday: Shreya will cue up the videos and slides and have the overhead projector and audio working. Each of you will summarize your assigned paper in the order that they appear in Oriol's presentation. I don't expect you to create any new slides unless you want to, but I hope you will make good use of Oriol's slides and video. Shreya will cue up and advance the slides as you request. If you show parts of one of the four video segments with Oriol speaking, that's fine ... indeed having Oriol speak for himself is encouraged ... it simplifies your life and allows you interject commentary, pose questions and generally add value to the presentation from your careful reading.
Don't expect the students to have watched the videos or read the papers. I'm a realist; class participation is the bane of seminar courses, hence the approach I'm trying out this year with you three teams of two being the first guinea pigs. You don't have to and really shouldn't try to present every detail in your paper. Summarize the highlights with enough coverage that you would want if you were listening rather than presenting. If you want to show an excerpt of one of the videos, write down which of the four videos and an offset HH:MM:SS so that Shreya can cue it up without a lot searching for the right space.
Since there are two of you assigned to each paper, I expect you to figure out a presentation strategy that you feel comfortable with and try it out — split it up and present as a tag team or divide the labor however you see fit. We'll all learn from the experience and subsequent presentations will benefit and can either follow your lead or come up with an alternative. Since I don't expect you to go crazy and practice — much less polish — your presentations, it can be as casual and experimental as you like. Thanks again and if you have any questions for us, please don't hesitate to reach out.
April 4, 2019
%%% Thu Apr 4 03:57:54 PDT 2019
We'll talk about the following listing in class this afternoon in the context of creating a method of encouraging class participation that is fair, flexible, not punitive, and, if approached in the right spirit, will turn out to be pleasingly educational. This is a reboot following up on several conversations after class on Tuesday regarding an earlier proposal mentioned briefly in the first class of the quarter on Tuesday. For those of you reading this who didn't attend class today, I'll follow up with details of what conspired when I get a chance tomorrow.
There's nothing magical about consciousness [100, 95, 98] Stanislas Dehaene VIDEO
What's consciousness and how can we build it [155, 159, 199] Michael Graziano VIDEO
There is no "hard problem" of consciousness [106] Daniel Dennett see Felipe de Brigard — one of Dennett's students at — 01:03:15 into VIDEO
Theory of Mind Reasoning is Easy and Hard [23] Neil Rabinowitz VIDEO
Strange loops and what it's like to be you [189] Douglas Hofstadher VIDEO
False memories and counterfactual reasoning [293, 83] Felipe de Brigard VIDEO
Thinking Shallow or Deep and Fast or Slow [67, 211] Nick Chater VIDEO
Meta-Control of Reinforcement Learning Matt Botvinick Slides and video in the class archives VIDEO
Prefrontal cortex as a meta-reinforcement learning system [388]
Episodic control as a meta-reinforcement learning system [317]
Computational Models of High-Level Cognition Randal O'Reilly Slides and video in the class archives VIDEO
The Leabra Cognitive Architecture: How to Play 20 Principles with Nature and Win! [291]
Complementary Learning Systems [289]
Making Working Memory Work: Model of Learning in the Prefrontal Cortex and Basal Ganglia [16]
Towards an Executive Without a Homunculus: Models of the Prefrontal Cortex and Basal Ganglia [178]
Prediction, Planning and Partial Obervability [393] Greg Wayne Slides and video in the class archives VIDEO
Predictron: End-To-End Learning and Planning [341] David Silver Slides and video available on Vimeo VIDEO
Imagination, Model-based and Model-free learning Oriol Vinyals Slides and video in the class archives VIDEO
Learning model-based planning from scratch [295]
Imagination-Augmented Agents for Deep Reinforcement Learning [394]
Learning to Search with Monte Carlo Tree Search (MCTS) networks [164]
Miscellaneous Loose Ends: I have at least two faults as a lecturer and public speaker: First, I try to pack too much into too short a time. Second, I don't repeat myself often enough, even though I know both from experience and my understanding of the research on learning that repetition, replay, rephrasing and having students repeat what they just heard is key to learning — note that I just did it.
My lecture on Tuesday was a good example though I admit that I did make an attempt to repeat some of the key ideas, unfortunately I couldn't help but change the examples as a consequence of my misguided intuition that nobody likes to hear the same example twice. In addition I didn't really motivate why I introduced the quote by Max Planck — as if it needed clarification [...] you can add "wry sense of humor" to my faults.
Apart from those pedagogical failings, neither did I realize how much people don't want to believe the point I was trying to make. I understand that it is hard coming to grips with the fact that knowledge is not static. Over time some propositions we believe to be fact turn out to be false, and some propositions we adamantly believe to be false turn out to be among the fundamental truths that govern the universe — until they are overturned by even more fundamental truths.
There was another point that I meant to make but forgot in trying to cram too much information into little time and that is Planck's funereal prediction continues to be true and, moreover, the consequences of its impact are exacerbated by the fact that we continue to increase our average lifespan. If I had had the time, I would've added another list of scientists alongside the neuroscientists and computer scientists that I listed, and that would be biologists and geneticists — if I had had the time I would gone off on other tangents.
One of my favorite examples concerns one of my least favorite scientists Carl von Linné — also known as Linnaeus — who in the 10th edition of his magnum opus taxonomy about biological diversity included "wild children" as a separate subspecies of humanity characterized by mental and physical disabilities. Johann Friedrich Blumenbach ultimately set the record straight and went on to further annoy various of his contemporaries by writing that "man is a domesticated animal ... born and appointed by nature the most completely domesticated animal" — puzzle that out if you can67.
And as if the taxonomy of the natural world was not fraught with additional controversy in its long history, you only have to read David Quammen's "The Tangled Tree: A Radical New History of Life" account of the discovery of how the discovery of a new "third kingdom" of life changed our understanding of evolution — by identifying the widespread evidence of horizontal gene transfer — and the lives of the scientists — including Carl Woese and Lynn Margolis — who fought against entrenched interests to bring this discovery to the attention of the scientific community and convince their peers of this unsettling truth — did it again, as if Stanford students have time to read potboiler histories of science that chronicle heroic human endeavors that changed our fundamental understanding of life.
April 3, 2019
%%% Wed Apr 3 4:49:10 PDT 2019
A Personalized History of Artificial Intelligence
I've been working in the field of artificial intelligence for nearly 40 years. I was a graduate student during the Halcyon days of the early 80s when IJCAI, the premier international conference on AI, was held in Los Angeles with nearly 5,000 attendees. That year the convention center floor space for vendors was packed with small companies looking to attract customers to demo their AI systems. Larger companies rented lavish hotel suites and booked fancy yachts complete with catered dining to lure talented graduate students. Pretty heady times for young graduate students unaware their field of study was so popular — and apparently lucrative.
When I co-chaired IJCAI 1999 in Stockholm, the attendance was less than 2,000 and we had trouble filling the conference hotel. I watched as the field became enamored of so-called expert systems, started believing their own hype and entered a period of decline generally referred to as the AI Winter that spanned the late 80s and early 90s. During that time the field splintered into specialized subfields and dispersed to favor more focused conferences and academic journals.
Throughout my career I've contributed to research in several core areas of AI including automated planning, computer vision, robotics, machine learning and probabilistic graphical models. I've also published papers in journals that focus on control theory, computational neuroscience, decision support systems operations research and stochastic optimal control, but I was unusual in having such eclectic taste. The 80s represent a time during which it was unwise to deviate much from the mainstream. There was less tolerance for embracing other disciplines and graduate students were discouraged from deviating too far from the mainstream. AI was trying to define itself.
I grew up in the 60s, dropped out of Marquette University within a few weeks of registering as a freshman and ended up hitchhiking around the country, living in communes and participating in many of the political and countercultural activities of that era. After a few years of homesteading in rural Virginia while trying to make a living building houses and refurbishing industrial machine tools, I got interested in computers and enrolled Virginia Polytechnic Institute in 1968. I majored in mathematics but also took classes in computer science and worked with a CS professor writing code for a Prolog-based automated robot planning system. That was my first exposure to AI.
Prior to enrolling in Virginia Tech, I had read a lot and developed some of my own naïve theories about building artificially intelligent systems. I sent Marvin Minsky at MIT a short paper describing my ideas and he was kind enough to send me a supportive letter and suggested that I read the work of Nikolaas Tinbergen who together with Karl von Frisch and Konrad Lorenz founded the field ethology68, and jointly were awarded the 1973 Nobel Prize in Physiology or Medicine for their work on animal behavior as an evolutionarily adaptive trait. After graduating from Virginia Tech, I was admitted to the graduate program in computer science at Yale University where I ended up working with Drew McDermott, one of Gerald Sussman's graduate students who was Minsky's student, making Marvin my academic great grandfather.
When I started graduate work at Yale, the field of AI was in thrall of first-order predicate logic. John McCarthy and his colleagues at Stanford University had wrested the intellectual focus of AI from MIT and CMU and symbolic reasoning was king. This was important to my career for a couple of reasons. It would occasion my making several trips to the West Coast and spending a summer at SRI69 in Menlo Park California next door to Stanford and right in the center of Silicon Valley. Graduate students from all over the world participated in an SRI-sponsored effort they codenamed Common Sense Summer to represent all of commonsense reasoning in first-order logic. I was absolved of having to work on the project so I could complete my Ph.D. thesis in time to join the faculty of Brown University starting in January of 1986.
In hindsight, first-order logic was not a good tool for modeling naïve reasoning about everyday physics. Some of that work has continued but it is no longer central to the main thrust of current research in artificial intelligence with its focus on neural networks. Part of the motivation for exploring first-order logic was to formalize and make rigorous the sort of symbolic processing that was emblematic of the work of Allen Newell and Herbert Simon at Carnegie Mellon and Terry Winograd Stanford. I admired Minsky's broad range of interests and was fascinated with his early work at Princeton in developing an analog artificial neural network in hardware70, but Minsky was to have a devastating impact on artificial neural network research.
Concerned with what they saw as a lack of rigor and focus, Minsky and Seymour Papert, Minsky's colleague at MIT, were successful in convincing many researchers that work on neural networks was misguided and that they should instead focus their efforts on the new field of artificial intelligence that Minsky, McCarthy and Claude Shannon had helped to launch at the Dartmouth Summer Research Project on Artificial Intelligence held in 195671. While many heeded the warnings of Minsky and Papert, an assemblage of researchers primarily located at Carnegie Mellon calling themselves the PDP group and led by the psychologists David Rumelhart and Jay McClelland along with computer scientists, physicists and cognitive scientists including Geoffrey Hinton, Ronald Williams and Terry Sejnowski made important contributions to our understanding of artificial neural networks. PDP stands for parallel distributed processing and it is the predominant approach to what is now known as connectionism72 emphasizing the parallel nature of neural processing and the distributed nature of neural representations.
In late 80s, Jerry Fodor and Zenon Pylyshyn, cognitive scientists at Rutgers University, made the claim that, while both connectionist distributed-processing and traditional symbolic-processing models postulate representational mental states, only the latter is committed to symbol-level representational states that have combinatorial syntactic and semantic structure. They saw the existing evidence for this claim as making a strong case that the architecture of the brain is not connectionist at the cognitive level [8]. Since then there has been a good deal of work showing that the context sensitivity of connectionist architectures — objects and activities are defined by the context in which they appear, and the systematicity of symbolic architectures — the ability to process the form or structure of something independent of its specific contents, are complementary from a functional perspective and separately realized in the brain from a anatomical perspective [292].
Simply put, these two complementary information processing systems enable us to recognize that a pony is a horse even though we've never seen such a small equine and parse a sentence in our native tongue even if we don't understand the meaning of most of the words. Context sensitivity allows us to deal with concepts and analogies that lack clear boundaries or allow for some degree ambiguity. Systematicity makes it possible for us to do mathematics and design complex machines. In subsequent chapters we explore cognitive architectures modeled after the human brain that exhibit these characteristics in their ability to employ language to communicate and collaborate, formulate and carry out complex plans, recall past experience from episodic memory and adapt that experience to present circumstances and perform at a superhuman level such tasks as writing computer programs and proving mathematical theorems. We'll also investigate the possible advantages of machines that are consciously aware, that create and maintain a sense of self, that can reason about their own mental state as well as the mental states of others — characteristics considered by many as uniquely human.
April 2, 2019
%%% Tue Apr 2 2:43:58 PDT 2019
Course Organization
The class is organized along two dimensions: cognitive architecture — how to design and implement systems that operate in complex environments, using episodic memory to adapt past experience in the process of planning for and predicting future events, and embodied cognition — disembodied minds are the stuff of science fiction, but minds integrated with powerful physical and cognitive enhancements that facilitate interacting with complex environments are the future.
Tom Dean will take primary responsibility for the discussions and invited talks related to topics in cognitive architecture, emphasizing the design of artificial neural networks implementing memory, perception and attention models. Rishabh Singh will handle the discussions and talks related to embodied cognition, with an emphasis on synthesizing, repairing and refactoring source code, and designing digital assistants that, among other skills, supports interactive code completion.
Conceptual Roadmap
Primary References and Related Talks and Presentations:
Concept: Conscious Attention
Resources: Nick Chater [67], Stanislas Dehaene [95], Michael Graziano [155]
Lectures: Stanislas Dehaene, Michael Graziano, Felipe de Brigard*
Concept: Episodic Memory
Resources: Dere et al [107], Frank et al [133], O'Keefe and Nadel [5]
Lectures: Randall O'Reilly+, Loren Frank*, Michael Frank*, Greg Wayne+
Concept: Action Selection
Resources: Frank et al [133], Ito [202], O'Reilly and Munakata [287]
Lectures: Matt Botvinick+, Jessica Hamrick*, Peter Battaglia*, Adam Marblestone*
Concept: Code Synthesis
Resources: Gulwani et al [166]
Lectures: Vijayaraghavan Murali*, Miltos Allamanis*, Tejas Kulkarni*
[*] Participate in discussions
[+] Welcome class questions
Note: I've put several reference books73 on reserve in the Engineering library. BibTeX references, including many abstracts, for all the papers cited in the class materials as of this writing are available for reference here. Two supplementary readings for the first week of classes are available on the course website: Stanford students can access the prologue to Nick Chater's The Mind is Flat and a chapter from Helen Thomson's Unthinkable about a woman whose ability to navigate in everyday life is severely compromised — in the process of telling this woman's fascinating personal story, Thomson does an excellent job of describing how the hippocampus, entorhinal cortex and retrosplenial cortex support navigation and landmark recognition using a collection of specialized neurons, including place cells, grid cells, border cells and head-direction cells.
April 1, 2019
%%% Mon Apr 1 4:32:56 PDT 2019
The grading breakdown for the class is as follows: 30% for class participation, 20% for project proposals and 50% for final projects. Project proposals are due around midterm and final projects by the end of the exam period. There will be plenty of opportunity for feedback on proposals and advising and brainstorming on projects. We'll spend most of the class on Thursday, April 4 discussing example projects, including the length and content of proposals, the scope of projects, working in teams and what you'll have to turn in for grading.
In the remainder of this post, I'll describe what's expected for class participation. This is a seminar course and so I expect students to attend class having prepared by reading the assigned papers. I realize that you might have job interviews, family emergencies and other exigencies that will prevent you from attending one or more classes, but I expect you to do your best. Obviously you could read the papers on your own. The real benefits of this class derive from participating in discussion, interacting with speakers and student presenters.
I expect every student to participate in leading at least one class discussion. To facilitate participation, Rishabh, Shreya and I will provide a set of topics and assign students to small teams responsible for each topic. There are eighteen (18) class slots on the calendar. I'm lecturing in the first two classes, Rishabh is lecturing in another when we shift the focus to automatic code synthesis and embodied cognition, and we'll be setting aside two or three slots for project discussions once we finalize the invited speakers. So there at most twelve (12) slots that feature an invited speaker / discussion leader.
Depending on the final size (s) of the class following the normal shopping and shakeout period, Rishabh, Shreya and I will select some number (t) of topics that align with one or more of the featured presentations. For each of the t topics we will randomly assign approximately s/t students to research and produce a study guide and presentation that all of the students can use to prepare for the corresponding class.
In some cases, the students responsible for a given topic will use their presentation to lead a discussion in class — for instance in the case where the invited speaker can't easily participate either remotely or in the flesh due to their being in an inconvenient time zone. In all cases, the study guide is due two days before the designated class time, the t teams are expected to self organize and share the effort. My lecture tomorrow, Tuesday, April 2, will provide examples of what I'd like to see in your study guides.
Rishabh, Shreya, and I will be available to assist in suggesting technical papers and recorded presentations, introducing you to local experts at Google and Stanford and some of the remote labs we collaborate with, as well as brainstorming and generally being available to help out however we can. You can use any of the past class presentations as templates for your presentation and the study guide can use your favorite notebook or weblog format to organize your content.
My research notes for class are probably more discursive than your fellow students would prefer for a topic-focused study guide, but several of the entries in the class discussion list might serve as starting point for your efforts. You can also think of these documents as a starting point for final project proposals. The following sequence of linked documents and suggestions might serve as an outline for a study guide on designing hippocampus-inspired memory systems:
The "Seven Deadly Sins" piece by Daniel Schacter highlights what episodic memory is good for. The Brain Atlas shows that each hemisphere has an associated hippocampus. The "Two-Minute Neuroscience" video describes the structure of the hippocampal formation and "Brains Explained" describes its function. The ED-TED piece discusses HM, Wilder Penfield's most famous patient, and the following Wikipedia page answers the related question of what happens when the damage is localized in one hemisphere.
Loren Frank's talk at the Simons Institute is too long and too technical to include the whole video, and so you'll have pick out one or two interesting or useful points to focus on. The DeepMind blog article and Alex Graves' NIPS talk are full of interesting snippets to feature or summarize in discussing how one might build an episodic memory modeled after the hippocampus. Fleshed out a little more and this would make an excellent way to prepare for Lauren Frank's discussion in class on Thursday, April 23.
Class Preparation
March 31, 2019
%%% Sun Mar 31 4:21:31 PDT 2019
Science and technology are moving quickly, some would say that the pace is accelerating, but when you're standing in the knee of the exponential75 it is hard to get a feeling for how quickly we are careening into the future. The big breakthroughs probably won't seem so at the time if you're in the middle of pushing the technology. Despite what some say, I believe that most of what has to be done to achieve AI relies on good engineering. This is true of a lot of disciplines. Along similar lines, I've heard scientists lament that the Nobel laureates of the last few decades don't seem to be in the same league with the likes of Isaac Newton, James Clerk Maxwell or Albert Einstein. Even our recent popular-press-anointed geniuses like Richard Feynman and Murray-Gell Mann pale in comparison to a Maxwell or Einstein. Perhaps I will change my tune if Edward Witten succeeds in using some variant of string theory to unify gravity and quantum field theory and thereby succeed where Einstein failed after decades of trying to come up with a grand unified theory or GUT.
If you're already riding the exponential curve, you may have some chance of keeping ahead of the game, but it is bound to be a struggle given that our brains are not evolving nearly so quickly and Moore's law is slowing down. My goal in this course is to accelerate your education so that you'll be in a position to immediately start contributing when you leave Stanford and start on your own. I plan to do that by exposing you to key scientific results and technological advancements, and train you to thrive in rich multi-disciplinary teams so that you can join one of the leading technology companies or premier neuroscience labs or you can get together with some friends and do-it-yourself. If you take this course and you apply yourself to learning about the relevant science and technology and get your hands dirty building systems at the bleeding edge, then Facebook Research, Google Brain, Google DeepMind and half a dozen startups funded by Silicon Valley billionaires like Elon Musk, Peter Thiel, Jeff Bezos, Bryan Johnson and Jeff Hawkins will beat a path to your door. Personally I hope that some of you go on to start your own companies, with your own ideas some of which I hope will come out of your participation in this class, and leapfrog the startups and privately funded companies mentioned above. I'll make it a point to return to this topic periodically and make a case for one application or another and I invite you to do the same — think of this class as an early-spring-seed accelerator like YCombinator.
In discussing navigation and landmark recognition in the hippocampus and entorhinal cortex, Ellen Thompson writes [365] that "we fill our mental maps with things that are meaningful to us" — how would we know? It might seem reasonable that, if we work on the "right" things, e.g., things that we like to do or things that we need to do in order to get along with our lives, then what is useful to us in learning how to actually accomplish these things, will be meaningful to us. That last sentence was either tautological or inconsistent! Nick Chater seems to imply that all of our sensations — visual, auditory, motor, somatosensory, etc., are meaningful in the sense that they arise from our engagement — whether actively or passively, with our environment, i.e., they are grounded in our bodies and the extended physical environment that exists outside our bodies and in which we are embedded The term semantic memory is often used to refer to all the products of our primary, secondary and multi-modal association areas, despite the fact that these products of interpretation and inference can only be linked back to the physical world thought multiple layers of abstraction.
Greg Wayne's predictive memory, MERLIN, for solving POMDP (Partially Observable Markov Decision Process) problems provides a possible solution to this quandary [393]. If we assume that everything we'll ever need to know is potentially either directly observable or predictable from other things that we can observe, then all we have to do is determine the values of the state variables that are preconditions for executing the optimal policy and then figure out how to observe or predict them from state variables that are observable — which may require that, for example, that we have to move in order to perform some of those observations. MERLIN learns both a forward and an inverse model to figure out what observations are required to solve the POMDP problem. The resulting combined forward and inverse model is referred to as an internal model and studied in the field adaptive stochastic optimal control and applied in many disciplines including machine learning and computational neuroscience as well as diverse applications including the automatic control of manipulators for robotic assembly.
Miscellaneous Loose Ends: Daniel Schacter is Professor of Psychology at Harvard University focusing on cognitive and neural aspects of human memory. If you're interested in psychology and cognitive science as it pertains to memory and, in particular, the details concerning specific experiments involving human subjects, you might be interested in Schacter speaking on Episodic Retrieval and Constructive Memory & Imagination at UC Irvine in 2018. This lecture was presented at the 2018 International Conference on Learning and Memory. For more information on Schacter's research visit the Schacter Memory Lab. For a relaxed, conversational introduction to his research relevant to the topics covered in CS379C you might find this interview more appropriate to your interests.
March 29, 2019
%%% Fri Mar 29 3:24:13 PDT 2019
In the final chapter entitled "The Secret of Intelligence", Chater suggests that there is good news to offset any disappointment his readers may feel at the loss of their — misattributed — unconscious cognitive depth. Earlier in the book he has made the case that all of our unconscious thought is due to the interpretative power of our perceptual system, and in this chapter he suggests that's not to be dismissed: "[T]he fact that we can make such remarkable perceptual leaps is a reminder of the astonishing flexibility and, one might even say, creativity of the perceptual system."
The take home message is summarized in this passage: "These imaginative jumps are, I believe, at the very core of human intelligence. The ability to select, recombine and modify past precedents to deal with present experience is what allows us to be able to cope with an open-ended world we scarcely understand. The cycle of thought does not merely refer passively to past precedents — we imaginatively create the present using the raw materials of the past." He draws on earlier examples of how humans can make sense of a barely recognizable sketch of a face [266], an ambiguous painting of an interrupted dinner [404] and a stylized black and white image of a Dalmatian almost impossible to see against of background of Fall leaves [369].
Characterizing metaphor as when we see one thing as another by drawing (creatively) upon our experience [Page 210], he talks about how we can decode the often incomplete, often incomprehensible present by inventive transformation of the past, and suggests that while such "exhuberant mental leaps" may seem at first frivolous they are essential for perceiving the world as it is [Page 212]. He concludes that the human brain's secret is imaginative interpretation and not "cold logic" ... best when used when followed by more disciplined analysis [Page 215], as in the case of making sense of the unexpected predictions and using them as jumping off places for constructing theories of all sorts using the kinetic theory of gasses as an example.
In the section entitled "The Distant Prospect of Intelligent Machines" he predicts that artificial intelligence on a par with human intelligence is sometime off. He correctly assesses the failure of earlier attempts in the 1970s and 1980s to build AI systems by encoding rules, and notes that "[a]rtificial intelligence since the 1980s has been astonishingly successful in tackling these specialized problems. This success has come, though, from completely bypassing the extraction of human knowledge into common-sense theories."
If our spectacular mental elasticity — our ability to imaginatively interpret complex, open-ended information into rich and varied patterns — is the secret of human intelligence, what does this imply for the possibility of artificial intelligence? [...]My suspicion is that the implications are far-reaching. As we saw, the early attempts to extract and codify human 'reasoning' and knowledge into a computer database failed comprehensively. The hoped-for hidden inner principles from which our thoughts and behaviour supposedly flow turned out to be illusory.
Instead, human intelligence is based on precedents — and the ability to stretch, mash together and re-engineer such precedents to deal with an open-ended and novel world. The secret of intelligence is the astonishing flexibility and cleverness by which the old is re-engineered to deal with the new. Yet the secret of how this is done has yet to be cracked. [Page 217]
However, his characterization of the current state-of-the-art and assessment of the future is not well informed despite his access to some of most forward thinking researchers working in AI today. In particular, he correctly summarizes the inadquacy of methods that rely entirely on large ammounts of carefully annotated and currated ground truth,
But my suspicion is that it is our mental elasticity that is one of the keys to what makes human intelligence so remarkable and so distinctive. The creative and often wildly metaphorical interpretations that we impose on the world are far removed from anything we have yet been able to replicate by machine.but misses the ascendancy of more sophisticated memory models, new methods for unsupervised learning, improvements in reinforcement learning and the increasing emphasis on embodied cognition involving robotics and simulated environments leveraging powerful physics engines developed for interactive computer games. See, for example, recent research work by Maguire, Hassabis, Schacter and others focusing on constructive memory, imagination and future thinking, episodic memory and goal-based planning [285, 410, 330, 175, 331, 174, 222, 61], as well as demonstrations of working models for imagination-based planning, optimization, relational and code synthesis [171, 140, 32, 295, 172, 394, 31].To those who, like me, are fascinated by the possibilities of artificial intelligence, the moral is that we should expect further automation of those mental activities that can be solved by ‘brute force’ rather than mental elasticity — the routine, the repetitive, the well defined. [Page 218]
March 27, 2019
%%% Wed Mar 27 15:08:22 PDT 2019
Adapted from the section entitled "The Four Principles of the Cycle of Thought" in [67] with additional commentary here76:
I. The first principle is that attention is the process of interpretation. At each moment, the brain selects and attends to a target pattern of activity that it then attempts to organize and interpret. The target might consist of parts of our sensory experience, a fragment of language or a memory. The brain always attends to exactly one target at a time. The neural circuitry responsible for attention has reciprocal connections to circuits throughout the cortex, allowing for a wide range of analysis and imaginative re-interpretation to find meaning in our experience of the world.
II. The second principle concerns the nature of consciousness and states that our only conscious experience is our interpretation of sensory information. We are aware of each such interpretations, but the neural correlates from which this interpretation is derived and the process by which it is constructed are not consciously accessible. Perception produces interpretations in the form of patterns of activity that are derived from activity originating in peripheral sensory systems. The interpretive machinery has no way of identifying where these interpretations come from.
III. The third principle is that we are conscious of nothing else: all conscious thought concerns the meaningful interpretation of sensory information. The claim that we are aware of nothing more than our meaningful organization of sensory experience isn't quite as restrictive as it sounds. Sensory information need not necessarily be gathered by our senses, but may be invented in our dreams or by active imagery. Much of our sensory information comes not from the external world but from our own bodies — including many aspects of our discomfort, pleasure and sensation of effort or boredom.
IV. Conscious thought is the process of meaningfully organizing our sensory experience. The fourth principle is that the stream of consciousness is nothing more than a succession of thoughts, an irregular series of experiences that are the results of our sequential organization of different aspects of sensory input. We attend to and impose meaning on one set of information at a time. The involuntary, unconscious autonomic nervous system (ANS) controls breathing, heart-rate and balance independent of conscious thought, but central nervous system (CNS) activities beyond the sequential cycle of thought are limited.
March 25, 2019
%%% Mon Mar 25 3:24:13 PDT 2019
Stanislas Dehaene is an accomplished systems neuroscientist and a first rate science writer. His The Number Sense: How the Mind Creates Mathematics [93] and subsequent Reading in the Brain: The Science and Evolution of a Human Invention [94] were two of the most influential books attracting me to pursue systems neuroscience more comprehensively — in addition to my existing avid interest in cellular and molecular neuroscience. His Consciousness and the Brain: Deciphering How the Brain Codes Our Thoughts [95] is the clearest account of consciousness I've read so far and has the most convincing empirical basis for believing it.
In talking with Rishabh Singh and Sarah Loos at different times over the last two months, I have suggested that natural language might serve as both a declarative and a procedural language for, respectively, specifying what programs do and reasoning about how they do it. We've also explored the possible role of natural language as the language of thought, but that strikes me as presumptive and entirely too parochial. In The Number Sense, Dehaene [93] had some interesting things to say about the relationship between mathematical and natural language including relevant comments by John von Neumann.
The other day, my wife pointed me to a series of YouTube videos from a public symposium, The Amazing Brain", held at Lunds Universitet on September 6, 2017. In his invited talk entitled "A Close Look at the Mathematician's Brain", Dehaene considers a wide range of specialized graphical languages going back to ancient cave paintings and featuring both highly stylized animals and symbolic notations and extending to the present era in which the language of mathematics has myriad dialects and specialized applications.
Dehaene and his colleagues have used various neuroimaging technologies to identify how these specialized languages map to systems-level circuits involving different collections of component functional brain areas. Surprisingly, both professional and amateur mathematicians seldom employ the familiar circuits and functional areas, such as Broca's and Wernicke's, associated with everyday natural language discourse, and there appears to be reproducible circuit-level agreement across subjects working with the same mathematical objects including, for example, trees, directed graphs, geometric shapes and algebraic equations.
These neuroimaging studies lead Dehaene to conjecture that perhaps, while different sensory modalities often employ similar computational strategies, they also employ different specialized features and exhibit different preferences for downstream associations depending on the peculiarities of their defining characteristics. Depending on when during development a given mathematical facility is typically acquired, the functional locus of the corresponding neural substrate might tend to gravitate to different brain areas.
Just as Terrence Deacon suggests that language, along with the unique human capacity for symbolic thought, co-evolved with the brain, perhaps, in accord with the purported generality of the dual-streams solution to neural signal processing, the arcuate fasciculus pathway connecting Broca's and Wernicke's areas is just the obvious selective response to a convenient nascent speaking-and-hearing technology for communication. Evolution might have taken a different turn if we had evolved with the ability to modulate and demodulate RF signals.
In Dehaene's experiments, much of the variation is exhibited in the frontal lobe which makes sense since the base input modality might correspond to speaking, writing, signing, drawing or some combination of these. It would only be later when the input is parsed into a suitable specialized internal language that we would see variation related to the specific area of mathematics, requiring specialized circuitry or proximity to other related circuits. It might be worth picking up a copy of Space, Time and Number in the Brain: Searching for the Foundations of Mathematical Thought edited by Dehaene and Elisabeth Brannon [96].
March 23, 2019
%%% Sat Mar 23 3:44:41 PDT 2019
Here are some of the notes I compiled in preparing for the first class lecture held on Tuesday, April 2nd:
Deep Reasoning About Shallow Thinking
I am going to begin and end this lecture with quotations from Nick Chater's latest book The Mind is Flat ... not because he is the only person to suggest such a theory of mind — we'll look at several related theories later in the coming weeks, but because he is, in my opinion, an articulate and competent cognitive scientist with a plausible theory of human cognition supported by a good deal of compelling experimental results and, since this lecture is all about building systems based on ideas from cognitive science, Chater's ideas are particularly relevant to our endeavor. In a recent lecture, Chater likens the mind to an iceberg:
The computations that the brain performs are very complicated, but they are nothing like the computations we are consciously aware of. So I think using our conscious mind as a window into the brain is a disastrous error. It is as though we imagine the mind as the tip of an iceberg. We can see the iceberg poking out of the sea, and the illusion is that we think "I can see the tip of the iceberg which is my flow of conscious experience, but I bet that the whole iceberg is doing the same sort of thing." In fact, the machinery that is operating at the unconscious level is a complicated memory retrieval and reuse system that is searching our past experience and using that past experience to understand the present. It performs tasks like scanning all the faces you've seen in order to recognize a new face. All of that perceptual processing is fast and runs in parallel, but it is nothing like the sequential computations performed by the conscious mind. The basic operations performed in the different sensory and motor areas of the brain are pretty much the same. They all involve perceptual processing of one sort or another. Even abstract thought involving, say, mathematics, physics or formal logic, are all carried out on a similar neural substrate by performing similar operations. I think of these calculations as being similar to those we employ in thinking about and recognizing objects. They are just more abstract versions of our innate perceptual capabilities. There are some who believe there are a number of specialized systems handling different types of problems — consider, for example, Jerry Fodor's [6] original modularity of mind hypothesis [REFERENCE] and the extended massive modularity hypothesis advocated by evolutionary psychologists including the Swiss Army knife metaphor of Cosmides and Tooby [75]. But I don't agree and resist making such strong modularity assumptions77.
In making decisions, you have the impression that your reasoning is based on some well-thought-out analysis occurring at deeper subconscious level — you can feel the strength of convictions, your judgments seem born out by the fact of your emotional responses. Unfortunately, those feelings, that strong impression, your enthusiasm or repulsion ... these are not the consequence of some deeper analysis or carefully reasoned argument. They aren't propositions arrived at by sound inference procedures that serve to generate antecedent preconditions in support of subsequent forward chaining ... rock solid facts built upon a foundation of other facts to construct an impregnable edifice of rationality — Chater tells us that it is nothing of the sort.
Moran Cerf is an Israeli neuroscientist and hacker — his use of the term — who has worked in cybersecurity. Cerf has studied human subjects undergoing surgeries that require they spend several days walking around with an electrode array implanted in their brains. The purpose of the implanted array is to collect data so as to accurately position a more permanent electrode for medical purposes. Cerf and his colleagues have gained their consent to study their brains and carry out experiments along the lines of those described in Chater's book, but, in Cerf's case, allowing the experimenters to observe changes in populations of spiking neurons. For more information, check out his Wikipedia page and this YouTube video in which he describes his work related to Chater's theory.
Chater's work has many antecedents and draws upon research in cognitive psychology, behavioral economics, systems neuroscience and sociobiology — among other disciplines — to support his thesis. In particular, Chater cites work by David Kahneman and Amos Tversky and their colleagues including Paul Slovic and Richard Thaler on the psychology of judgment and decision-making, as well as behavioral economics, and cognitive basis for common human errors that arise from heuristics and biases. David Kahneman's Thinking Fast and Slow [211] describes a related theory and body of experimental research results, and draws some of the same conclusions. While the primary conclusions of both Chater and Kahneman may seem to some as an insult to our intellect and an indictment of our rationality, Chater and Kahneman seem more sanguine. If anything the ability to rise above our base instincts and make use of our antediluvian computing machinery to achieve incredible accomplishments in the arts and sciences, should encourage our efforts to further ourselves.
Science Advances One Funeral at a Time
The German physicist Max Planck is quoted as saying: "A new scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die, and a new generation grows up that is familiar with it." You may know that Planck of the eponymous constant — the so-called Planck constant h in the formula E = hν where E is the energy of a photon and ν is its frequency — felt compelled to introduce the constant named for him in his revised formula for the observed spectrum of black body radiation. This move required that he rely on Boltzmann's statistical interpretation of the second law of thermodynamics. It was he said "an act of despair ... I was ready to sacrifice any of my previous convictions about physics." Boltzmann's career ended in suicide after decades of abuse by his colleagues who derided his theory of statistical mechanics, now heralded as one of the most important achievements in physics along with those of Isaac Newton, James Clerk Maxwell and Albert Einstein. Here is a short list of other scientists whose careers were thwarted and work derided by more senior scientists whose theories they challenged:
Emillo Golgi — reticular theory, Golgi (stain) method
Santiago Ramón Cajal — neuron doctrine
Thomas Hunt Morgan — chromosome hereditary role
Conrad Waddington — epigenetic inheritance
Seymour Benzer — single-gene behavioral traits
Vernon Mountcastle — columnar organized cortex
John Eccles — electrical synaptic transmission
Paul Greengard — chemical neuromodulation
Frederick Griffith — horizontal gene transfer
Galarreta and Hestrin — electrical gap junctions
Barres, Bilbo and Stevens — dual role of microglia
In the same vein — tales from the history of science relating to death — Karl Popper was quoted to have said that in science we propose theories and then seek to undermine them, and so scientists in order to eliminate their false theories, they try to let them die in their stead78. I expect we would all like think of the scientists whom we most respect as truth seekers and myth busters who are relentlessly vigilant in their quest for answers to nature's puzzles. Alas, we are all too human to be accorded such respect. I am particularly drawn to instrument builders like Michael Faraday and Ernest Rutherford, careful observers like Tycho Brahe, Santiago Ramón Cajal and Edwin Hubble, and experimentalists like Enrico Fermi and Rosalind Franklin. Ed Boyden, George Church, Karl Deisseroth, Winfried Denk, Mario Galarreta and Mark Ellisman are among my living heroes. They provide the data necessary to come up with new theories and the evidence to falsify existing ones.
It wasn't always that scientists thought of themselves as responsible for actively falsifying their theories and those of their peers. Popper writing again: "As opposed to this, traditional epistemology is interested in the second world [REFERENCE] in knowledge as a certain kind of belief—justifiable belief, such as belief based upon perception. As a consequence, this kind of belief philosophy cannot explain (and does not even try to explain) the decisive phenomenon that scientists criticize their theories and so kill them. Scientists try to eliminate their false theories, they try to let them die in their stead. The believer — whether animal or man — perishes with his false beliefs." [REFERENCE]
Role of Inner Voices and Hallucinations
Most of us are cognizant of voices chattering endlessly in our heads. In most cases, we associate those voices with ourselves, but many of us hear other voices both familiar and unfamiliar. Hearing and relating to inner voices is often associated with schizophrenia — a serious brain disorder characterized by thoughts or experiences that seem out of touch with reality, disorganized speech or behavior and decreased participation in daily activities. Difficulty with concentration and memory is also common.
In most of us these inner voices appear to serve useful purposes; they can help us to organize our thoughts, consolidate episodic memory by rehearsing and re-imagining our past experience in order to deal with the present and plan for the future. The ability to construct narratives, sub—vocally describe our hopes and plans in a rich, shared language and privately listen to ourselves as we refine and apply these narratives in everyday life appears to be uniquely human — at least given the extent we do so.
Our facility with inner speech appears to be physically mediated by specific cortical structures. The arcuate fasciculus is a bundle of axons that forms part of the superior longitudinal fasciculus, an association fiber tract. The arcuate bidirectionally connects caudal temporal cortex and inferior parietal cortex to locations in the frontal lobe. The arcuate fasciculus connects Broca's area and Wernicke's area.
This Broca-to-Wernicke pathway implies there is direct connection — via an association fiber tract — from circuits ostensibly involved in the production of speech, i.e., Broca's area adjacent to areas in the frontal responsible for motor planning, to areas involved in understanding speech, i.e., Wernicke's area located in the posterior section of the superior temporal gyrus encircling the auditory cortex on the lateral sulcus, where the temporal lobe and parietal lobe meet.
There is growing consensus that there exists a general dual-loop system scaffolding in human and primate brains providing evidence that the dorsal and ventral connections subserve similar functions, independent of the modality and species. The Broca-to-Wernicke pathway is but one instance such a dual loop. As visual information exits the occipital lobe, and as sound leaves the phonological network, it follows two main pathways, or "streams". The ventral stream (also known as the "what pathway") is involved with object and visual identification and recognition. The dorsal stream (or, "where pathway") is involved with processing the object's spatial location relative to the viewer and with speech repetition79.
Could these dual-stream-mediated sensory-motor systems serve as a feedback loop for unsupervised predictive or reconstructive learning similar to the reciprocal EHC-CA1 connections in hippocampal-entorhinal complex? Could this be the means by which we construct the narratives that produce hippocampal traces that encode the episodic memories allowing us encode procedural knowledge and enable us to learn how to perform long division, that allow us to perform the amazing feats of memory recall that professional mnemonists are able to demonstrate, and that serve as the basis for Nick Chater's shallow model of human cognition.
March 21, 2019
%%% Thu Mar 21 3:24:13 PDT 2019
Nick Chater and Stanislas Dehaene are trying to convince their respective readers that their particular theories [67, 95] explain how the human brain functions in their most recent books. In contrast, Helen Thompson [365] is a science writer in the same tradition as Oliver Sacks [323, 324] and Horace Freeland Judson [208]. Her goal is to tell you interesting stories as a way of educating you about how your brain works and what happens when it goes awry.
The accolades on her book cover from Ed Yong, Robert Sapolsky plus reviewers including the journal Nature are well deserved. The chapter on how the hippocampus and various subregions of the frontal cortex enable us to store episodic memories and navigate and recognize landmarks in our physical environment is a wonderful supplement to related work in scientific journals.
Her story about a man whose brain is significantly altered by an aneurysm that produced a subarachnoid hemorrhage resulting in burst blood vessels and blood flooding into and around his brain is both excellent scientific reporting and an extraordinary real-world instance of how the human brain can change for the better — at least from the patient’s perspective — even when that change is precipitated by a traumatic insult to our arguably most cherished organ.
Tommy McHugh was a petty criminal, distant parent and occasionally abusive husband living in poverty in Liverpool. His personality was almost completely altered — by most accounts for the better — by the aneurysm that damaged his brain. This particular method of improving oneself is obviously not one that anyone would intentionally endure, but the transformation is so dramatic and so positive that it makes you wonder if we could build technology or perform precise surgeries that could, with high reliability, purposefully produce such transformations.
Just after finishing this chapter in Thomson’s book, my wife Jo read me excerpts from Vincent van Gogh's letters [376, 278] to his brother Theo during his time in Arles when he painted several hundred works of art in a frenzy of manic activity. Van Gogh was articulate and emotional in the descriptions of his psychological distress; his accounts are painful to read and at the same time one can’t help but empathize with Theo who patiently listened to cared for and supported his brother despite being financially and psychologically burdened by Vincent’s relentlessly insensitive and intrusive treatment.
While participating in a recent neurotech conference, I made a comment concerning the prospects for developing possibly-invasive, potentially-risky technology to eliminate chronic depression and related debilitating brain disorders. One person in the audience suggested van Gogh's contributions to modern art would have suffered if his psychological infirmities were alleviated or eliminated. I thought his suggestion profoundly ignorant or grossly insensitive, but simply offered that he might think differently if he or one of his loved ones suffered from bipolar disorder or one of the more severe variants of autism spectrum disorder.
March 19, 2019
%%% Tue Mar 19 3:17:48 PDT 2019
You are the confluence of a set of emergent properties of an evolved arrangement of carbon-based molecules. In some respects, you are more an ephemeral than corporeal phenomenon. Your conscious awareness is as ephemeral as a process running on a cell phone, and, while you are undoubtedly embodied, the essential you is manifest as a thread of computation, fragile as a snowflake and potentially as powerful as any force of nature.
In this class we continue with a grand quest that is as old as language: to re-create and reimagine ourselves as subtle machines of incredible complexity and potential. Our immediate objective is to model a human being — or at least those aspects of being human that we believe to be the most efficacious in building artificially intelligent agents with whom we can interact and collaborate with naturally.
Three years ago I was focusing on computational models attempting to account for the function of complex neural circuits on the scale of entire organisms. I concluded it would be some time before we could record from a large fraction of the neurons in the brain of any organism as complicated as a fruit fly. I simply didn't see any possibility of whole brain recording within the next two years and possibly longer.
Since coming to these conclusions and abandoning the idea of starting a project at Google to construct functional models of whole brains, my interest has changed to modeling human cognitive behavior, which poses different challenges and offers a richer perspective on cognition than is possible by studying flies or mice. My scientific focus changed from that of a cellular and molecular neuroscientist to that of a systems and cognitive neuroscientist, and required a shift from studying simpler organisms at the level of individual neurons to studying humans at the level of relatively large, anatomically well defined but internally opaque regions of neural tissue.
I am still focused on learning models of animal behavior, but the class of models I employ as an inductive bias has changed considerably. In particular, whereas in the case of studying flies and mice at the level of neurons I employed a prior that sought to define and model the composite function of small neuronal circuits, now I use a prior that leverages what we know about the function of relatively large regions of the brain thought to implement specific functions relating to the sort of behavior I want to model. That behavior is infinitely more complex and varied than we observe in simpler animals, especially given that we focus on human behavior involving complex problem solving and natural language communication.
It might seem audaciously conceited to think that we could somehow construct a model of the human brain that even begins to account for the diverse behavior of human beings and their most successful invention yet, that of human language. However, I don't believe this is necessarily the case and I will spend the remainder of this quarter trying to convince you that what we are attempting to do is within the range of what's possible and now is a good time to be doing so. I should mention however that what I am suggesting we work on, while of considerable practical value, does not begin to address the more complicated problem of understanding the underlying biology at the scale and level of detail required to diagnose and find cures for human brain disorders, though I hold out some hope that the sort of high-level computational models of human cognition we are pursuing will one day contribute to that effort.
March 11, 2019
%%% Mon Mar 11 04:19:48 PDT 2019
This entry serves as a parking spot for my notes on Nick Chater's The Mind is Flat. As an introduction and test to see if you are interested in his theory concerning human cognition, I suggest you start with his Google Talks book tour presentation. If you find that interesting, but still are not convinced enough that you want to read the book [67]. You might get a better idea by watching Episode #111 of the The Dissenter podcast hosted by Ricardo Lopes. Here is an excerpt relating to Chater's main thesis that we are misled by introspection into believing that below the threshold of our conscious thoughts there is a great deal of supporting unconscious thinking going on — unconscious, but of the same general depth and complexity as our conscious thoughts:
The things the brain does are very complicated, but they are nothing like the things we are consciously aware of. So I think using our conscious mind as a window into the brain is a disastrous error. It's like we think the mind is the tip of an iceberg. We see the iceberg poking out of the sea, and the illusion is that we think "I got the tip of the iceberg which is my flow of conscious experience, but I bet that the whole iceberg is just the same stuff". [...] The machinery that is operating is this incredibly complicated memory retrieval and reuse system which is searching our past experience and using that past experience to understand the present. [...] Like scanning all the faces you've seen in order to recognize a new face. All of that is fast and parallel, but its nothing like the sequential nature of the mind. I think the basic operation performed in these different areas [of the brain] is pretty much the same from one area to the next. They all involve perception memory in one way or another. Abstract thought whether mathematics, physics or the law [...] I think of these as all pretty much similar in spirit to thinking about and recognizing objects. [...] They are just more abstract versions of that. [There are some who believe that there are a number specialized systems handling different types of problems] The Toby and Cosmides Swiss Army knife model [120] [But I don't agree.] So I want to push against this [strong] modularity assumption.
Ricardo provides the following convenient bookmarks that take you directly to the relevant location in the podcast:
00:01:06 The basic premise of "The Mind is Flat"
00:05:33 We are like fictional characters
00:09:59 The problem with stories and narratives
00:13:58 The illusions our minds create (about motives, desires, goals, etc.)
00:17:44 The distinction between the conscious mind and brain activity
00:22:34 Does dualism make sense?
00:27:11 Is modularity of mind a useful approach?
00:31:21 How our perceptual systems work
00:41:49 How we represent things in our minds
00:44:57 The Kuleshov effect, and the interpretation of emotions
00:52:05 About preferences and personality
00:55:42 Why do we need our mental illusions?
00:59:10 The importance of our imagination
01:01:31 Can AI systems produce the same illusions (emotions, consciousness)?
Lament Over Sloshed Milk
Here are the last few lines of Chapter 2 entitled "Anatomy of a Hoax" in which Chater commiserates with himself and the reader over the fact — actually a presupposition — that scientists (might) have deluded themselves regarding some of the most basic facts about human cognition. I will certainly admit that he makes a good case for his view of how we experience and make sense of the world around us. His theory explains some of the predictions one could make concerning the models I've been working on and so I will have little reason to complain if he is proved right. But I will hold out for a while and watch for more experimental evidence before celebrating my modeling choices or adopting his theory wholesale.
From time to time, I have found myself wondering, somewhat despairingly, how much the last hundred and fifty years or so of psychology and neuroscience has really revealed about the secrets of human nature. How far have we progressed beyond what we can gather from philosophical reflection, the literary imagination, or from plain common sense? How much has the scientific study of our minds and brains revealed that really challenges our intuitive conception of ourselves?The gradual uncovering of the grand illusion through careful experimentation is a wonderful example of how startlingly wrong our intuitive conception of ourselves can be. And once we know the trick, we can see that it underlies the apparent solidity of our verbal explanations too. Just as the eye can dash into action to answer whatever question about the visual world I happen to ask myself, so my inventive mind can conjure up a justification for my actions, beliefs and motives, just as soon as I wonder about them. We wonder why puddles form or how electric and immediately we find explanations springing into our consciousness. And if we query any element of our explanation, more explanations spring into existence, and so on. Our powers of invention are so fluent that we can imagine that these explanations were pre-formed within us in all their apparently endless complexity. But, of course, each answer was created in the moment.
So whether we are considering sensory experience or verbal explanations, the story is the same. We are, it turns out, utterly wrong about a subject on which we might think we should be the ultimate arbiter: the contents of our own minds. Could we perhaps be equally or even more deluded when we turn to consider the workings of our imagination?
Collective Decision Making
Here is an extended thought experiment inspired by my reading of Chater's The Mind is Flat [67] that explores how Chater's theory of human cognition might play out in a collective endeavor:
When we engage in a group undertaking whether that be evaluating candidates for a job position or deciding upon a strategy for investing in new markets, we are collectively creating a shared illusion that serves as the basis of our own individual thinking as well as any possible consensus regarding, for example, specific actions being contemplated.
Think about what happens when one of us makes some contribution to the discussion whether it be a comment or criticism or an addition or modification to some possible outcome of our joint focus, say a job offer, contract or new species of investment. In voicing an opinion, we influence one another's mind state by how our contribution is individually and jointly perceived. Given what Nick Chater tells us about human behavior, it is highly likely that our contribution will be misunderstood and our resulting thoughts and those of others thinly apprehended but richly fantasized.
It makes sense to think of this shared space as a collection of thought clouds in the sense that Geoff Hinton uses the term. Each thought cloud is no more than a sparse representation of an individual’s state vector. It includes, among many other things, the activation of state variables that correspond to our internal representation of the mental states of those sitting around the table — a representation that is no doubt poorly informed and incredibly misleading.
These individual idiosyncratic representations of the evolving joint space are tied together very loosely by our notoriously error-prone efforts to read one another's thoughts, but, whether or not we are able to read "minds", there is still the possibility of interpreting what each contributor actually says or how they act. Alas, we are just as fallible in reading body language and interpreting intent from what is explicitly said or acted out in pose, gesture or facial tick.
As each participant voices their opinion, makes his or her case, expresses their support for or opposition to what was said earlier, all of the individual thought clouds are separately altered according to the inscrutable adjustments of diverse hormonal secretions and neuromodulatory chemical gradients. The individuals may believe — or possibly hope — that some consensus will eventually be reached; however, unless carefully led by a very skilled facilitator, the separate thought clouds will be cluttered, full of contradictions and misunderstandings and yet by some independent measure oddly aligned — which could be simply due to the length of time the meeting was scheduled for or the perceived duration necessary for this particular group to reach consensus.
There will very likely be a good deal of wishful thinking among those who either want the meeting to end quickly irregardless of the outcome, hope that a consensus can be amicably reached or have already reached their final opinion and will become increasingly more strident in support of their views as the meeting drags on. There will be those who will want — or pretend — to hear their colleagues voiced support for their ideas, but will interpret whatever they say to suit their own selfish interests and expectations.
In Chater’s theory, each one of us is a single thread of conscious thought informed by and constructed upon a history of memories dredged up in response to sensory input, in this case, resulting from what was seen and heard in the meeting. This means that, in particular, each one of us will have a different context depending on our own stored memories and the degree to which we have attended to the discussion in the meeting. This will result in a collection of state vectors that in the best of circumstances are only roughly aligned, and, in the more realistic case, significantly discordant.
It would be interesting to know what sort of dimensions are more likely to appear in some semblance of their current grounding in fact or that, while they may have a different valence, at least represent an emotional trajectory accounting for roughly the same physiological state across some fraction of the individuals present in the discussion. While I don't believe this sort of dimensional alignment is likely for dimensions of a more abstract sort, I wouldn't be surprised if one were able to do a factor analysis on all the different thought vectors represented in a given collective, that we might be able to identify factors representing some alignment that translates across individuals — one that plays an important role in our evolution as successful social organisms.
The picture I have in my head is of a collection of thought clouds with some dimensional alignment across individuals with respect to perceptually — and in particular emotionally — mediated factors but very little alignment across abstract dimensions that capture more of the concrete aspects of the collective-focus intended by those who organized the meeting in the first place. All of the usual cognitive biases are likely to be at play in the interactions going on during the meeting. Individual opinions will not be obviously manifest in behavior and will likely be repressed and prettified to make them more palatable to the group as a whole.
Moreover, many if not most of the individuals will likely misinterpret the opinions and other hidden state of their co-contributors, and also likely adjust the valence and magnitude of related dimensions to suit their own idiosyncratic beliefs and desires with respect to the outcome of the collective effort.
It would be instructive to imagine the sort of collective enterprise as playing out in a protracted meeting and how, for example, participants might align their viewpoints based upon a particularly articulate opinion rendered by someone thought highly — or perhaps fondly — of, versus some sort of discordant alignment resulting from an incoherent but forcefully rendered opinion by someone not well thought of. The exercise would be not be necessarily to figure out a strategy for effectively coming to a joint understanding so much as how cognition would play out given sparse serialized thought processes operating on internal representations that only thinly capture the collective experience and ground much of what is heard or seen in their own idiosyncratic, suspiciously self-promoting or self-effacing episodic memory80 .
As a logical next step along these lines, it would be interesting to ask how the outcome might be different in the case of a group of very smart, highly motivated, super engaged individuals with a history of working together and a facilitator of particularly sharp intellect, unusually well-calibrated emotional and social intelligence and highly motivated to do the right thing in charge of overseeing the meeting and fully invested in guiding the participants toward a consensus worth the effort.
In this case, the focus would be on how the participants might rise above their (instinctual) predilections by using the same cognitive substrate with the same energy and focus as they would devote to something they might find intellectually more satisfying such as writing code and solving interesting programming problems. Specifically, how can the basic cycle of apprehend (sense), attend (select), integrate personal experience (recall), and respond to an internal model of the present circumstances (act) be successfully applied to effectively make difficult decisions given what Chater refers to as the essentially "flat" character of our world view / internal model of present circumstances.
P.S. The original name of this file — Laughably_Sparse_Embarrassingly_Serial_Chatter.txt — is a tongue-in-cheek reference to a model of parallel / distributed computation (https://en.wikipedia.org/wiki/Embarrassingly_parallel) that describes much of the parallelism available in modern industrial cloud services and corporate data and computing centers.
March 9, 2019
%%% Sat Mar 9 14:57:23 PST 2019
I read a recent paper by researchers at Arizona State and Stanford University — see the Press Release from ASU — making a case that hippocampal pattern separation supports reinforcement learning by "forming conjunctive representations that are dissociable from feature components and that these representations, along with those of cortex, influence striatal prediction errors" — see Ballard et al [29]. A colleague sent me this link to a recent TED Talk by Ed Boyden — he has a great technology story to tell, one that is both exciting from a purely scientific and technology perspective and inspiring from an aspirational perspective.
My latest readings for class include journal articles relating to inner speech and the two-streams hypothesis as it relates to hearing and speaking [225, 3, 359, 206], and articles relating to episodic memory including selected Chapters81 in the Handbook of Episodic Memory [108] and journal articles cited in recents books by Trevor Cox [77] and Charles Fernyhough [124] relevant to these topics [354, 343, 118, 19]. Chapters in the handbook are accessible to students online from the Stanford libraries website. Stanford doesn't have a print version, but you can use the chapter title to search the web since many of the chapters were previously published as journal articles.
March 7, 2019
%%% Thu Mar 7 09:19:37 PST 2019
Lisa Giocomo (Giocomo Lab) suggested that I ask Loren Frank from UCSF to participate in class given his focus on episodic memory, the hippocampal-complex, making predictions and decisions: Loren Frank. "Continuous 8 Hz Alternation between Divergent Representations in the Hippocampus" — a presentation at the Simons Institute, Berkeley, Monday, February 12th, 2018 2:00 pm. The Simons website also includes his original and corrected slides.
Page 160-162, Chapter 11: A Brain Listening to Itself. In The Voices Within by Charles Fernyhough [124]:
Despite the limitations of existing research, the inner speech model has provided a useful framework for making sense of neuro-scientific findings concerning voice hearing. some of the most impressive evidence has come from findings of structural differences between people who hear voices and those who don't. The inner speech model has often been translated into neuro-scientific language in terms of the connection between the part of the brain that generates an inner utterance (particularly the left inferior frontal gyrus or Broca's area) and the region that perceives it (part of the superior temporal gyrus82 or Wernicke's area). Recall that, in the model of action monitoring put forward by Chris Frith and colleagues [134], a signal is sent from the system that produces inner speech to the speech detection areas of the brain, effectively saying, "Don't pay any attention to this; this is you speaking." In schizophrenia, Frith argued, something goes wrong with the transmission of the signal. The "listening" part of the brain does not respect the signal that is coming, and so it processes the signal as an external voice83.Studying connectivity between these areas of the brain should allow us to see whether this kind of transmission error is occurring. Neuroscientists make a broad distinction between two kinds of brain material: gray matter, which takes its name from the cell bodies of the neurons, or nerve cells, the color it; and white matter, which consist of the parts of the nerve cell that communicate with other nerve cells (roughly, the brain's wiring). Studying the integrity of white matter can tell you something about how different parts of the brain are talking to each other, or at least how they are wired up to talk. To make an analogy, you can learn a lot about the structure of a communication system — a telephone exchange, for example — simply by studying how it is connected up, even if no signals are actually flowing through the system.
For the inner speech model of voice hearing, one tract of white matter has been of particular interest. It's the stretch of neural wiring that (very roughly) joins Broca's area to Wernicke's area, the area in the superior temporal gyrus that perceives speech. This group of fibers is called the arcuate fasciculus. Recall that an utterance in inner speech is supposedly generated, but the speech perception area doesn't get the usual tip-off about it. In Frith's theory this happens because Broca's area usually sends a copy of the instruction to Wernicke's area, effectively telling it not to listen for what's about to happen. That so-called "efference" copy is sent along the arcuate fasciculus.
The integrity of this tract of white matter has indeed been linked to auditory verbal hallucinations. Along with looking at the physical structure of the pathway, researchers have used neurophysiological methods such as electroencephalography (EEG), to find out whether communication between these brain regions is disturbed. Judith Ford and her colleagues at Yale University showed that the usual "dampening" that occurs in Wernicke's area as a result of receiving the efference copy does not occur so markedly in patients with schizophrenia. That interpretation gained support from an fMRI study looking at how patients brains responded when they were perceiving external speech in comparison to when they were generating inner speech. The listening areas of the control participant's brains activated less when they were imagining sentences that when they were hearing sentences spoken out loud. The difference was significantly less noticeable in the schizophrenia patient's brains suggesting a problem with the transmission of the efference copy between Broca's and Wernicke's areas.
March 6, 2019
%%% Wed Mar 6 04:56:32 PST 2019
History of Science: John O'Keefe — Place Cells in the Hippocampus, Past and Present (YouTube) speaking at the SUNY (Downstate) Medical Center honoring the work Dr. James Ranck. James B. Ranck, Jr. MD is distinguished teaching professor emeritus of physiology and pharmacology at SUNY Downstate Medical Center, where he taught from 1975 until his retirement in 2014. In 1968, he was one of the first to record electrical activity in single neurons, opening up a new direction of brain study. In 1984, he discovered head-direction cells in the brain, which, along with place cells and grid cells, underlie the neural basis of navigation and spatial behavior. Dr. Ranck founded the hippocampal laboratory at Downstate, which became widely known in neuroscience circles as "The Brooklyn Group," working on memory and navigation.
John O'Keefe's discovery of hippocampal "place cells" launched the notion that the hippocampus was the brain's "cognitive map" (O'Keefe and Nadel, 1978). Starting in the early days Jim Ranck made fundamental contributions including the discovery of "head-direction cells" — cells that are the basis of a "sense of direction". The field grew rapidly and flourished. There are now dozens of labs and broad recognition that this line of research is yielding fundamental insights into the neuronal mechanisms that produce cognition. The symposium will summarize Jim Ranck's contributions and survey current work that begins to reveal how mind is produced in the brain.
March 5, 2019
%%% Tue Mar 5 04:28:58 PST 2019
Having watched one interview — with Terrence Deacon — conducted by Ricardo Lopes and considered it thought provoking, I tried another. Here is Ricardo interviewing Michael Graziano on his theories of consciousness. If you haven't already, check out Michael's presentation in class here. I found the contrast between Michael's presentation and Stanislas Dehaene discussing his work fascinating. In particular, what each of them took for granted. Michael probably had some idea of his audience from looking at some of Lopes' other interviews and their comments. Dehaene had the advantage that his presentation was professionally edited and scripted, so I won't comment on their respective deliveries, but rather what they included and what they left out. Michael was careful to target a general audience.
In particular, Michael didn't assume that listeners would know what a "representation" is, much less what a representation of one's self might look like. Or what it would mean to construct a representation of one's self. Getting it right makes a big difference and I know from experience that students without a computer science or cognitive science background don't deeply understand the difference between a scene — what one sees when viewing, say, a garden or mountain range, a photo of that scene, a cave drawing or painting, an icon signifying the scene and a word or phrase used to refer to the scene. Charles Sanders Peirce's Semiotic Theory has a great deal of interesting things to say about representations.
March 4, 2019
%%% Mon Mar 4 03:37:39 PST 2019
Last night I finally got around to skimming through the rest of Terrence Deacon's book, Incomplete Nature, and this morning Jo and I listened to an interview with Deacon that spent most of the time on Incomplete Nature and the remainder on The Symbolic Species: The Co-evolution of Language and the Brain. Between the book and the interview and a convenient Wikipedia page I was able to get what I wanted out of those books, with Incomplete Nature being the real challenge. I've included my Cliff's notes summary at the bottom in case you're curious and would like to know what secrets were revealed.
It's interesting how each complex concept that I've been working to understand over the last few months has its own arc of discovery. The trajectory of seeking out appropriate authors and relevant books and papers generally takes the same form: initially the material seems hopelessly impenetrable and the authors deviously dissembling, but if you persevere eventually you start finding little footholds that you can use to gain some purchase on the abstract concepts. The last stage is the most intriguing or perhaps unsettling as it generally involves going to sleep one night thinking that you are dense and clueless, and waking the next morning and find the concepts simple to understand and straightforward to communicate.
I've had that experience in reading both of Deacon's books as well as scores of other topics that I am researching for the apprentice project and the related Stanford class. For example, how does pattern separation and completion work in the hippocampal-entorhinal-cortex complex, or how is the value function learned and where does it reside in the basal ganglia circuits responsible for action selection and what goes wrong when the indirect-path inhibitory neurons behave erratically giving rise to the debilitating symptoms of Parkinson's disease.
The August 31 and August 29 entries the 2018 class discussion list contain my initial impressions from reading Deacon. In you're curious, you can find my Cliff's Notes summary of Deacon's Incomplete Nature: How Mind Emerged from Matter with a little help from Wikipedia and Ricardo Lopes — also known as "The Dissenter", in the footnote at the end of this paragraph84.
Here is Deacon speaking at the University of Trento, Center for Mind / Brain Sciences, on October 28, 2016 on the topic of "Neither nature nor nurture: The semiotic basis of language universals". Deacon summarizes his views on Chomsky's theory of humans possessing an innate language facility in the form of a universal grammar, and then launches into a departure / extrapolation from his two earlier books [5, 85] that promises to be very interesting. I've summarized Deacon's perspective on Chomsky in this footnote85.
Here is an interview with John Krakauer, in which Krakauer and host Paul Middlebrooks talk about the intellectual value of scientists writing book-length treatises, the importance of the long-form expression of ideas and how our understanding of an idea or our ability to express it evolves over time. Reminded me of the aphorism86 that fortune favors the prepared mind. Note that "preparation" in this context means something different from scanning through a book without comprehension, reading the Cliff's Notes without making an effort to reconstruct the arguments, or binge watching popular science shows from PBS, NPR or BBC. Aside from that thought, the interview had little to recommend it.
December 7, 2018
%%% Fri Dec 7 04:12:22 PST 2018
Here are some example courses and related course materials from my colleagues at Brown University aimed at students in computer science, computational linguistics, natural language processing and neuroscience wanting a better foundation in statistics and probability theory:
DATA 1010 — Stuart Geman (Applied Mathematics) designed this course for students in engineering, cognitive science, etc., who want to understand the math but don't need the theory, e.g., the mathematical foundations in terms of Borel sets, etc. Mark Johnson (Cognitive Science) co-taught the course with Stu and co-authored this related paper on probability and linguistics.
CSCC 0241 — Eugene Charniak (Computer Science) wrote one of the first dissertations linking artificial intelligence and natural language processing and was a pioneer in statistical language learning. His monograph is still required reading for many courses on statistical NLP and I recommend it highly — AI and NLP students alike appreciate its introduction to Bayesian statistics.
CSCI 1550 — Eli Upfal (Computer Science) designed this course for computer scientists and students interested in understanding the computational and algorithmic issues pertaining to statistics and probability. Eli and Michael Mitzenmacher wrote an excellent textbook that is used in this course. The expanded second edition provides a great complement to courses in machine learning.
November 23, 2018
%%% Fri Nov 23 4:00:25 PST 2018
While satisfied with our implementation of conscious awareness from a purely engineering standpoint, it is revealing to consider what Stanislas Dehaene and his colleagues [100, 95] have to say about the nature of conscious and unconscious thought. Chapter 2 of [95] summarizes a large body of experimental work addressing this question. For example, in the following excerpt Dehaene discusses one particular experiment aimed at better understanding the efficacy of unconscious incubation in decision making:
Having a hunch is not exactly the same as resolving a mathematical problem. But an experiment by Ap Dijksterhuis comes closer to Hadamard's taxonomy [168] and suggests that genuine problem solving may indeed benefit from an unconscious incubation period [110]. The Dutch psychologist presented students with a problem in which they were to choose from among four brands of cars, which differed by up to twelve features. The participants read the problem, then half of them were allowed to consciously think about what their choice would be for four minutes; the other half were distracted for the same amount of time (by solving anagrams). Finally, both groups made their choice. Surprisingly, the distracted group picked the best car much more often than the conscious-deliberation group (60 percent versus 22 percent, a remarkably large effect given that choosing at random would result in 25 percent success). — excerpt from Page 82 of Dehaene [95]
Dehaene goes on to consider whether and to what extent conscious and unconscious thought are different in their ability to discern subtle properties of the phenomena they are called upon to interpret. In so doing, he comments on the important role of symbolic, combinatorial thinking in resolving ambiguity in sense data, and the serial versus parallel processing distinction made elsewhere in these notes:
Henri Poincaré, in Science and Hypothesis [301], anticipated the superiority of unconscious brute-force processing over slow conscious thinking:
The subliminal self is in no way inferior to the conscious self; it is not purely automatic; it is capable of discernment; it has tact, delicacy; it knows how to choose, to divine. What do I say? It knows better how to divine than the conscious self, since it succeeds where that has failed. In a word, is not the subliminal self superior to the conscious self?Contemporary science answers Poincaré's question with a resounding yes. In many respects, our mind's subliminal operations exceed its conscious achievements. Our visual system routinely solves problems of shape perception and invariant recognition that boggle the best computer software. And we tap into this amazing computational power of the unconscious mind whenever we ponder mathematical problems.
But we should not get carried away. Some cognitive psychologists go as far as to propose that consciousness is a pure myth, a decorative but powerless feature, like frosting on a cake. All the mental operations that underlie our decisions and behavior, they claim, are accomplished unconsciously. In their view, our awareness is a mere bystander, a backseat driver that contemplates the brain's unconscious accomplishments but lacks effective powers of its own. As in the 1999 movie The Matrix, we are prisoners of an elaborate artifice, and our experience of living a conscious life is illusory; all our decisions are made in absentia by the unconscious processes within us.
The next chapter will refute this zombie theory. Consciousness is an evolved function, I argue — a biological property that emerged from evolution because it was useful. Consciousness must therefore fill a specific cognitive niche and address a problem that the specialized parallel systems of the unconscious mind could not.
Ever insightful, Poincaré noted that in spite of the brain's subliminal powers, the mathematician's unconscious cogs did not start clicking unless he had made a massive initial conscious attack on the problem during the initiation phase. And later on, after the "aha" experience, only the conscious mind could carefully verify, step by step, what the unconscious seemed to have discovered. Henry Moore made exactly the same point in The Sculptor Speaks [267]:
Though the non-logical, instinctive, subconscious part of the mind must play its part in [the artist's] work, he also has a conscious mind which is not inactive. The artist works with a concentration of his whole personality, and the conscious part of it resolves conflicts, organizes memories, and prevents him from trying to walk in two directions at the same time. — excerpt from Chipp and Correia [68]
In Chapter 3 of [95], Dehaene asks what purpose does conscious thought serve and why did it evolve. In this excerpt at the beginning of the chapter, he succinctly summarizes his conclusions:
Why did consciousness evolve? Can some operations be carried out only by a conscious mind? Or is consciousness a mere epiphenomenon, a useless or even illusory feature of our biological makeup? In fact, consciousness supports a number of specific operations that cannot unfold unconsciously. Subliminal information is evanescent, but conscious information is stable — we can hang on to it for as long as we wish. Consciousness also compresses the incoming information, reducing an immense stream of sense data to a small set of carefully selected bite-size symbols. The sampled information can then be routed to another processing stage, allowing us to perform carefully controlled chains of operations, much like a serial computer. This broadcasting function of consciousness is essential. In humans, it is greatly enhanced by language, which lets us distribute our conscious thoughts across the social network. — excerpt from Page 89 of Dehaene [95]
%%% Sun Nov 25 04:53:54 PST 2018
Miscellaneous Loose Ends: There has been a good deal of controversy surrounding the use of functional Magnetic Resonance Imaging87 (fMRI) to infer brain function. Some of the controversy stems from the incorrect use of common measures of statistical significance in claiming conclusive research findings [200]. In the case of fMRI, it has also taken some time to understand how to apply the technology for brain imaging and interpret the resulting images. If you want to dive a little deeper, I suggest the first four chapters of Russell Poldrack's The New Mind Readers: What Neuroimaging Can and Cannot Reveal about Our Thoughts (EXCERPT) describing how cognitive neuroscience has harnessed the power of fMRI to yield new insights into human cognition [302].
%%% Thu Nov 29 4:03:57 PST 2018
While researching Douglas Hofstadter's work on analogy for an earlier entry in this log, I ran across his book "I Am A Strange Loop" [189] in which he explores the idea of consciousness and the concept of "self". In comparing his account of consciousness with that of Dehaene, Graziano, Dennett and others we've discussed in these notes, I find Hofstadter's liberating in the way he avoids many of the earlier philosophical, psychological, biophysical and metaphysical conundrums that make this topic so confusing and fraught with controversy for the uninitiated. That said, I think some of you may find that this video retelling by Will Schoder entitled You Are A Strange Loop does Hofstadter's account one better and achieves its weight and clarity in a scant twenty minutes.
November 21, 2018
%%% Wed Nov 21 03:42:65 PST 2018
As mentioned in an earlier note, Weston et al [396] have developed a set of tasks — Facebook's bAbI dataset — to test reading comprehension and question answering. These tasks require chaining facts, simple induction and deduction, all of which are required for analogical and relational modeling. In this entry, we consider several proposed approaches that have been evaluated on the bAbI dataset.
We've already discussed one such proposal: Daniel Johnson's Gated Graph Transformer Neural Network model [205] can learn to construct and modify graphs in sophisticated ways based on natural language input and has been shown to successfully learn to solve almost all of the bAbI tasks. In the same paper introducing bAbI, Weston et al [396] describe their proposal based on memory networks [397] and evaluate it on bAbI.
All the bAbI tasks [396] are generated using simulator that operates like a text adventure game as described here88. The authors implement five models including an LSTM-based model, a vanilla Memory Network (MemNN) model and a second MemNN model that depends on extensions to the original MemNN framework [397], plus two baseline models, one using an N-gram classifier and the other a structured SVM.
In the simpler MemNN, the controller "performs inference" over the stored memories that consist of the statements in a story or entries in a knowledge base. The simpler MemNN model performs two hops of inference: finding the first supporting fact with the maximum match score with the question, and then the second supporting fact with the maximum match score with both the question and the first fact that was found. The extended MemNN model uses a meta-controller trained to perform a variable number of hops rather than just two, as in the case of the simpler MemNN. Compare Table 3 in [396] with Table 2 in [205] and Table 1 in [220].
Kumar et al [220] introduce Dynamic Memory Networks (DMN) as a general framework for answering questions given a semantic memory consisting of general knowledge about concepts and facts, a set of inputs corresponding to recent history complementing the semantic memory, and an episodic memory that focuses on different parts of the input updating its state and finally generates an answer to the initially posed question89.
| |
| Figure 65: The basic Key-Value Memory Network architecture developed for question answering and described in [262] is shown here. Several variants are described in the paper and additional variants are covered in Jason Weston's tutorial at ICML 2016. — the graphic shown here is reproduced from Figure 1 in [262]. The basic architecture is similar to a Neural Turing Machine with a key-value memory. Memory slots are designated as key-value pairs \((k_{h_{1}}, v_{h_{1}})\), ..., \((k_{h_{N}}, v_{h_{N}})\) and the target question is notated as \(x\). Assume for simplicity that \(A\), \(B\) and \(K\) are all \(d \times{} D\) matrices and \(\Phi\) is a feature map of dimension \(D\). The initial memory addressing step uses the access query \(q_{1} = A\Phi_{X}(x)\), and each memory slot is assigned a relevance probability \(p_{h_{i}} = \) Softmax\((A\Phi_{X}(x) \cdot{} A\Phi_{K}(k_{h_{i}}))\). The initial output is \(o = \Sigma_{i} p_{h_{i}}A\Phi_{V}(k_{h_{i}})\) after 0 hops. Subsequent addressing steps use the updated access query \(q_{j+1} = R_{j}(q + o)\) for \(1 \leq{} j \leq{} H\) where \(H\) is the maximum number of hops, and compute the relevance probability as \(p_{h_{i}} =\) Softmax\((q^{T}_{j+1} A\Phi_{K}(k_{h_{i}}))\). Backpropagation and stochastic gradient descent are used to learn the matrices \(A\), \(B\), and \(R_{1}, \dots{}, R_{H}\). | |
|
|

Jason Weston's tutorial on Memory Networks at ICML 2016 covers the original model described in [396] plus the following variants: Key-Value Memory Networks [262], End-to-End Memory Networks [355], Dynamic Memory Networks [403] and Weakly Supervised Memory Networks [356]. The Weston et al and Kumar et al approaches to solving the tasks in the bAbI dataset are similar to the contextual method of integrating episodic memory and attentional networks described in Figure 63. Figure 65 reproduced from Figure 1 in [262] provides some insight into the power of these methods.
At each step, the collected information from the memory is cumulatively added to the original target question to build the context for the next round of inference. In principle, the system can perform multiple inductive or deductive inferential steps, incorporating intermediate results as additional context, and adjusting the weight of each item in memory in anticipation of the next step. As per our earlier discussion about shaping context by recalling items from episodic memory — see Figure 52, the challenge is to organize memory so that our encodings of the present circumstances provide the keys necessary to access relevant past experience.
Memory Network models have also been applied to dialogue management and demonstrated state-of-the-art performance on several challenging datasets — see "Learning End-to-End Goal-Oriented Dialog" from Bordes and Weston [51] and "Dialog-based Language Learning" from Weston [395] with credit for the performance gains touted in the latter assigned to a method for predictive lookahood that enables the system to "learn to answer questions correctly without any reward-based supervision at all." See Fisac et al [125] and Hamrick et al [172] for related models.
Miscellaneous Loose Ends: Andrade et al [14] propose using Memory Network models and analogy-based reasoning for future prediction, but the algorithmic details are sketchy and their evaluation unconvincing. Foster and Jones [131] suggest that analogical reasoning and reinforcement learning complement one another synergistically and describe a method for schema induction that is more conceptual than practical. This paper is primarily motivated by issues of interest to cognitive neuroscientists. If you are interested in pursuing this line of inquiry, Holyoak [192] surveys the related work on analogy and relational reasoning, and Gick and Holyoak [146] provide an overview of schema induction and analogical transfer from the perspective and cognitive psychology.
November 19, 2018
%%% Mon Nov 19 4:55:47 PST 2018
I've been reading cognitive science papers on analogical and relational modeling trying to get a handle on what an architecture efficiently supporting this type of reasoning might look like. It seems inevitable that such an architecture will be a hybrid system combining aspects of connectionist and symbolic processing — at least if we are to leverage what is known about human analogical and relational reasoning:
Analogy is an inductive mechanism based on structured comparisons of mental representations. It is an important special case of role-based relational reasoning, in which inferences are generated on the basis of patterns of relational roles. Analogical reasoning is a complex process involving retrieval of structured knowledge from long-term memory, representing and manipulating role-filler bindings in working memory, identifying elements that play corresponding roles, generating new inferences, and learning abstract schemas. [...] Human analogical reasoning is heavily dependent on working memory and other executive functions supported by the prefrontal cortex, with the frontopolar subregion being selectively activated when multiple relations must be integrated to solve a problem. — excerpt from Page 234 of Holyoak [192] (PDF)
This description is certainly consistent with the discussion found in Battaglia et al [32] and conversations we have had with Randall O'Reilly. It is also clear that the underlying cognitive infrastructure that supports human-level analogical and relational reasoning is substantially more complicated than we have encountered so far in our discussion of the programmer's apprentice application. Most of the proposed solutions are either too simple to be taken seriously as engineering solutions or too baroque to easily integrate into existing architectures that have already been demonstrated to scale and provide solutions to other key problems.
In reading the literature, it soon becomes obvious that the term "analogy" has broad application and little agreement on what it means. In the context of multi-task learning, Lampinen et al [228] note that, "if you train a neural network to solve two identical tasks, using separate sets of inputs and outputs but sharing the hidden units, in some cases it will generate representations that reflect the analogy [...] leading to the ability to correctly make analogical inferences about items not explicitly taught [318]. Transfer learning is often cast as a structural analogy problem and tackled by a wide range of methods including graph-based label propagation [179] and reproducing kernel Hilbert spaces [386]90.
Battaglia et al [32] use the term combinatorial generalization to describe one of the most important advantages of working with compositional models. The following excerpt from their paper — parts of which appear elsewhere in these notes — illustrates the basic idea and links it to analogy and relational structure:
Humans' capacity for combinatorial generalization depends critically on our cognitive mechanisms for representing structure and reasoning about relations. We represent complex systems as compositions of entities and their interactions. [...] We use hierarchies to abstract away from fine-grained differences, and capture more general commonalities between representations and behaviors, such as parts of an object, objects in a scene, neighborhoods in a town, and towns in a country. We solve novel problems by composing familiar skills and routines, for example traveling to a new location by composing familiar procedures and objectives, such as "travel by airplane", "to San Diego", "eat at", and "an Indian restaurant". We draw analogies by aligning the relational structure between two domains and drawing inferences about one based on corresponding knowledge about the other.Kenneth Craik's The Nature of Explanation (1943), connects the compositional structure of the world to how our internal mental models are organized:
...[a human mental model] has a similar relation-structure to that of the process it imitates. By 'relation-structure' I do not mean some obscure non-physical entity which attends the model, but the fact that it is a working physical model which works in the same way as the process it parallels... physical reality is built up, apparently, from a few fundamental types of units whose properties determine many of the properties of the most complicated phenomena, and this seems to afford a sufficient explanation of the emergence of analogies between mechanisms and similarities of relation-structure among these combinations without the necessity of any theory of objective universals. — excerpt from Pages 51-55 in [78] (PDF)That is, the world is compositional, or at least, we understand it in compositional terms. When learning, we either fit new knowledge into our existing structured representations, or adjust the structure itself to better accommodate (and make use of) the new and the old.
O'Reilly et al [292] point out, in their retrospective look at Fodor and Pylyshyn's [8] 1988 critique of connectionism, that combinatorial generalization is a challenge in connectionist models, but that it is possible to achieve a type of limited systematicity by using the same prefrontal-cortex / basal-ganglia circuitry [16] that they employ to explain executive function and rule-based reasoning in humans:
Despite a bias toward context-sensitivity, it is possible for simple neural networks to learn a basic form of combinatoriality — to simply learn to process a composite input pattern in terms of separable, independent parts. These models develop "slot-based" processing pathways that learn to treat each separable element separately and can thus generalize directly to novel combinations of elements. However, they are strongly constrained in that each processing slot must learn independently to process each of the separable elements, because as described above, neurons cannot communicate symbolically, and each set of synapses must learn everything on its own from the ground up. Thus, such systems must have experienced each item in each "slot" at least a few times to be able to process a novel combination of items. Furthermore, these dedicated processing slots become fixed architectural features of the network and cannot be replicated ad hoc — they are only applicable to well-learned forms of combinatorial processing with finite numbers of independent slots. In short, there are strong constraints on this form of combinatorial systematicity, which we can partially overcome through the PFC-based indirection mechanism described below. Nevertheless, even within these constraints, combinatorial generalization captures a core aspect of the kind of systematicity envisioned by [8], which manifests in many aspects of human behavior. — see Section 3.3 entitled "Combinatorial Generalization (Neocortex)" in [292] (PDF)
The take home message from these observations is that if we want to achieve the advantages of analogical and relational modeling in addition to the benefits of fully-differentiable deep neural networks we must necessarily design hybrid systems that embrace a trade-off between context-sensitivity and combinatoriality [292]. The real challenge is to design hybrid systems that combine the best of symbolic and connectionist architectures. While such hybrids do not yet exist, there have been some interesting attempts to address the tradeoff by using different variants of differentiable memory [2, 153, 397] that we'll look at in the next entry in this discussion list.
November 17, 2018
%%% Sat Nov 17 03:48:40 PST 2018
Several researchers have suggested that the term graph networks distracts from the focus on relationships and the notion of a relational inductive bias as articulated in Battaglia et al [32]. Carlos Perez notes that "Hofstadter argues that the more common knowledge structuring mechanism known as categorization (or classification) is the same as the generation of analogies [which are essentially] relationships between concepts".
Anthony Repetto characterizes analogies in terms of "relating disparate inputs and processing them using the same heuristic". He understands analogies "as a form of compression, allowing the brain to simulate the dynamics of many different systems" by allocating minimal resources to each system such that if two systems behave similarly, a single analogy can be used to describe both" — excerpted from [312].
Concerning relevant datasets, Weston et al [396] have developed a "set of proxy tasks to evaluate reading comprehension via question answering [...] that measure understanding in [term of] whether a system is able to answer questions via chaining facts, simple induction, deduction [...] these tasks are designed to be prerequisites for any system that aims to be capable of conversing with a human". The data is available here.
November 11, 2018
%%% Sun Nov 11 03:33:52 PST 2018
In the previous entry, I suggested that Douglas Hofstadter's work on analogy might be relevant to Yoshua Bengio's paper on deep learning and cultural evolution [36]. Indeed, Hofstadter has written a good deal arguing that analogy is the core of cognition, starting with his popular Gödel, Escher, Bach: An Eternal Golden Braid published in 1979 [186]. Later, in his 2001 book chapter [16] entitled Epilogue: Analogy as the core of cognition he set out the main premise and continued to develop it over the following decade. His presidential lecture) at Stanford on February 6, 2006 and subsequent invited talk at the University of Illinois at Urbana-Champaign on September 14, 2006 provide accessible introductions to the basic ideas. Then in 2013, Hofstadter and his co-author, Emmanuel Sander, published a book-length exposition [191] arguing that analogy plays a key role in cognition. From the prologue:
In this book about thinking, analogies and concepts will play the starring role, for without concepts there can be no thought, and without analogies there can be no concepts. This is the thesis that we will develop and support throughout the book. What we mean by this thesis is that each concept in our mind owes its existence to a long succession of analogies made unconsciously over many years, initially giving birth to the concept and [then] continuing to enrich it over the course of our lifetime.
In the Stanford lecture and UIUC talk, Hofstadter's presentation is informal and dialectical as befits a talk for a general audience. At the end of the UIUC talk, the audience questions touch upon the question of what sort of computational abstraction would best support pervasive analogy as he imagines it. Hofstadter does not think that connectionist architectures are well suited to analogy since, according to him, they aren't able to create and manipulate large-scale structures — particularly hierarchical structures, and they lack a suitably powerful method of chunking, since he characterizes human thought as a "relentless, lifelong process of chunking — taking small concepts and putting them together into bigger and bigger ones"91. He pointed to his book Fluid Concepts and Creative Analogies: Computer Models Of The Fundamental Mechanisms Of Thought for a discussion computational models and their implementation details [187].
Miscellaneous Loose Ends: Two recent books worth reading, David Quammen's "The Tangled Tree" [304] on the origins of life and horizontal gene transfer and Carl Zimmer's "She Has Her Mother's Laugh" [411] on the history and future of heredity. I enjoyed both, but already knew much of the science and many of the anecdotes described in Zimmer's book. I really learned a lot from Quammen's book on horizontal gene transfer, endosymbiosis and the history concerning the many different manifestations of the "tree of life" concept. Quammen's writing reminds me of Horace Freeland Judson's The Eighth Day of Creation. The science is painstakingly researched and the stories of the scientists benefit from personal interviews and detail-oriented reporting. Among the many interesting examples of HGT covered in his book, Quammen chronicles the discovery of syncytin, a captive retroviral envelope protein that plays an important role in mammalian placental morphogenesis [71, 260].
November 9, 2018
%%% Fri Nov 9 4:51:55 PST 2018
I was rereading Yoshua Bengio's consciousness prior paper [38] and noticed a reference [37] in the bibliography with the title "Deep learning and cultural evolution". The reference appears to be an invited talk that mentions a wide range of recent work but is most clearly summarized in [36] where it is organized in terms of a set of hypotheses reproduced in the following account.
Optimization Hypothesis: When the brain of a single biological agent learns without the aid of an auxiliary teacher, it performs an approximate optimization with respect to some endogenous objective function.
The paper starts by reviewing the analysis presented in [294] on the saddle point problem for non-convex optimization, noting that training a deep net from end-to-end is difficult but gets easier if an auxiliary training signal can be used to guide the training of the intermediate layers.
Local Descent Hypothesis: When the brain of a single biological agent learns, it relies on a form of approximate local descent by making small, gradual adjustments which on average tend to reduce the expected error.
Bengio mentions curriculum learning as one source of such auxiliary training signals [40] along with the application of unsupervised pre-training as a means of regularization [165, 119], but these papers are prologue to a more intriguing possibility concerning human intelligence.
Deeper the Harder Hypothesis: Higher-level abstractions in brains are represented by deeper computations going through more areas — localized brain regions — or more computational steps in sequence over the same areas.
It is claimed that a single human learner is unlikely to discover the high-level abstractions required to simplify learning by chance because these abstractions are represented by deep sub-networks in the brain.
Local Minima Hypothesis: The ability of any single human to learn is limited by the ability of the learner to determine if it is near to a local minimum — what Bengio refers to as effective local minima.
Bengio asks the reader to consider a hierarchy of gradually more complex features, constructing detectors for very abstract concepts that are activated whenever a stimulus within a very large set of possible input stimuli are presented. For a higher-level abstraction, this set of stimuli represents a highly-convoluted set of points, resulting in a a highly curved manifold and thus is likely to be hard to learn.
Deep Abstractions Harder Hypothesis: A single human learner is unlikely to discover by chance the high-level abstractions necessary for efficient inference since these are represented by deep sub-networks in the brain.
Bengio suggests it may be possible for individuals to exchange information providing insight into the representations in the deep layers of a multi-layer network that could serve to simplify learning by altering the energy landscape. He points out how various forms of reference, e.g., the different modes, iconic, indexical and symbolic, in C. S. Peirce's semiotic theory [297] — might facilitate such insight92.
Guided Learning Hypothesis: A human brain can much more easily learn high-level abstractions if guided by the signals produced by other humans that serve as hints or indirect supervision for these high-level abstractions93.
The intellectual bounty resulting from centuries of civilization and culture, including the efforts of a great many gifted savants and diligent scribes, provides anyone possessing the requisite interest and resolve with the opportunity to reconstruct the networks necessary to harness this bounty and exploit the combinatorial and indexical properties of language to "stand on the shoulders of giants" as Issac Newton grudgingly acknowledged.
Memes Divide-and-Conquer Hypothesis: Language, individual learning and the recombination of memes94 constitute an efficient evolutionary recombination operator, and this gives rise to rapid search in the space of memes, that helps humans build up better high-level internal representations of their world.
Bengio opines that deep learning research suggests that "cultural evolution helps to collectively deal with a difficult optimization problem that single humans could not alone solve" and that moreover:
This has social and political implications for organizing our societies towards maximum efficiency thereby encouraging growth that engenders cultural wealth: brains that better understand the world around us.
The implications for AI research suggest collections of learning agents building on each other's discoveries to build up towards higher-level abstractions — guiding computers just like we guide children.
As suggested earlier in these notes, the idea of natural language as a lingua franca for intra-cortical communication perversely appeals to me. Figure 5 in Bengio [36] alludes to this mode of communication, even allowing for the possibility of communication between brains, typically through natural language, in a way that provides suggestions as to how the fundamental structure or topology of the higher levels in the representation of a concept in one brain might be reproduced in the higher levels in the representation of the same concept in another brain.
Figure 64 provides a rendering of one possible method of using language to address the problem of discovering high-level abstractions of the sort that fundamentally alter the search space by revealing a relatively-smooth, low-dimensional manifold projection so as to accelerate learning concepts that would be difficult otherwise. In Figure 64 the learner observes an instance in support of the general claim: "all birds have wings". The teacher in this case either makes the claim explicit by uttering a suitable statement or underscores the implied relationship by pointing to the apparent instance, and identifying the related entities by their common names.
| |
| Figure 64: This drawing depicts a graphical rendering of Yoshua Bengio's guided learning hypothesis [36]. The primary sensory areas responsible for speech (A) and vision (B) process the sensory input corresponding to, respectively, the sentence "all birds have wings" and the image of a bird. This results in the activation of several abstract conceptual representations, shown here as cartoon thought vectors corresponding to the concept of "wing" labeled C, the concept of "bird" labeled D, and the embedding of the sentence labeled E which is related to C and D by recurrent connections. | |
|
|
The auditory and visual stimuli are initially processed in the primary sensory areas — labeled A and B — identifying low-level spatially-localized features that are subsequently combined in several higher layers — labeled C, D and E — to construct increasingly abstract, spatially-diffuse composite representations that are eventually (reciprocally) connected in the association areas situated in the parietal, temporal and occipital lobes of the posterior portion of the cortex where they are integrated and made available to higher executive-function and memory systems in the prefrontal cortex.
The assumption is that our understanding of the words "wing" and "bird" is informed both by our highly contextualized understanding of the symbols as they occur in written and spoken language and our visual experience of corresponding instances encountered in nature. These two sources of meaning are related through the rich set of learned associations between the corresponding representations. The question is could we somehow exploit these associations to serve as a regularization term in learning a model encompassing the many ways that physically realized wings and birds relate to one another. The basic idea reminds me of the Deep Visual-Semantic Embedding (DEVISE) model developed by Frome et al [135] to leverage semantic similarity in order improve image classification and enable a form of zero-shot learning.
A more interesting challenge would be to explore how one might learn a predictive model of a dynamical system using a similar linguistic-embedding approach to simplify and accelerate learning. Perhaps the sort of "hint" that Yoshua has in mind might take the form of an analogy, e.g., using our commonsense understanding of personal relationships to learn a simple model of the physical interactions that occur between electrically charged particles. It might be worth asking Peter Battaglia and Jessica Hamrick if they know of any related work from their research on learning interaction networks to model dynamical systems [31] and exploiting a relational inductive bias in solving structured reasoning problems [171]. For your convenience, I've included a set of bibliographical references including the abstracts that relate to the ideas covered in this log entry95.
To work well, this approach would require an extensive semantic embedding space leveraging the rich latent semantic structure inherent in natural language [18, 227, 321]. Intuitively, taking advantage of someone telling you that "particle physics is like interpersonal relationships" would require an alignment of two very different domains. In principle, this might be done by having a knowledgeable teacher supply a naïve student with a narrative that includes excerpts like "particles are like individual persons", "attraction works when opposites become emotionally entangled", "attraction is subject to an inverse square law similar to gravitational force", etc.
The idea is to align the two models — one involving electrically charged particles and the other emotionally entangled individuals — so that the embedded relationships governing the latter provide a structural prior in guiding the formation of new networks explaining the former. Douglas Hofstadter's work on analogy is worth a look [191, 190, 186]. Daniel Johnson's paper on gated graph transformer networks mentioned earlier in these notes provides examples of how such graph networks can be trained to generate graphical models of the underlying dynamics from stories [205].
November 5, 2018
%%% Mon Nov 5 03:55:14 PST 2018
Context is everything in language and problem solving. When we converse with someone or read a book we keep in mind what was said or written previously. When we attempt to understand what was said in a conversation or formulate what to say next we draw upon our short-term memories of earlier mentioned people and events, but we also draw upon our long-term episodic memories involving the people, places and events related to those explicitly mentioned in the conversation. In solving complex design problems, it is often necessary to keep in mind a large number of specific facts about the different components that go into the design as well as general knowledge pertaining to how those components might be adapted and assembled to produce the final product.
Much of a programmer's procedural knowledge about how to write code is baked into various cognitive subroutines that can be executed with minimal thinking. For example, writing a simple FOR loop in Python to iterate through a list is effortless for an experienced Python programmer, but may require careful thought for an analogous code block in a less familiar programming language like C++. In thinking about how the apprentice's knowledge of programming is organized in memory, routine tasks would likely be baked into value functions trained by reinforcement learning. When faced with a new challenge involving unfamiliar concepts or seldom used syntax, we often draw upon less structured knowledge stored in episodic memory. The apprentice uses this same strategy.
The neural network architecture for managing dialogue and writing code involves encoder-decoder pairs comprised of gated recurrent networks that are augmented with attention networks. We'll focus on dialogue to illustrate how context is handled in the process of ingesting (encoding) fragments of an ongoing conversation and generating (decoding) appropriate responses, but the basic architecture is similar for ingesting fragments of code and generating modified fragments that more closely match a specification. The basic architecture employs three attention networks, each of which is associated with a separate encoder network specialized to handle a different type of context. The outputs of the three attention networks are combined and then fed to a single decoder.
The (user response) encoder ingests the most recent utterance produced by the programmer and corresponds to the encoder associated with the encoder-decoder architectures used in machine translation and dialogue management. The (dialogue context) encoder ingests the N words prior to the last utterance. The (episodic memory) encoder ingests older dialogue selected from episodic memory. The attentional machinery responsible for the selection and active maintenance of relevant circuits in the global workspace (GWS) will likely notice and attend to every utterance produced by the programmer. Attentional focus and active maintenance of such circuits in the GWS will result in the corresponding thought vector added to NTM the partition responsible for short-term memory.
The controller for the NTM partition responsible for short-term (active) memory then generates keys from the newly added thought vectors and transmits these keys to the controller of the NTM partition responsible for long-term (episodic) memory. The episodic memory controller uses these keys to select episodic memories relevant to the current discourse, combining the selected memories into a fixed-length composite thought vector that serves as input for the corresponding encoder. Figure 63 depicts the basic architecture showing only two of the three encoders and their associated attention networks, illustrating how the outputs of the attention networks are combined prior to being used by the decoder to generate the next word or words in the assistant's next utterance.
| |
| Figure 63: In the programmer's assistant, the dialogue management and program-transformation systems are implemented using encoder-decoder sequence-to-sequence networks with attention. We adapt the pointer-generator network model developed by See et al [334] to combine and bring to bear contextual information from multiple sources including short- and long-term memory systems implemented as Neural Turing Machines as summarized in Figures 52 and 53. This graphic illustrates two out of the three contextual sources of information employed by the apprentice. Each source is encoded separately, the relevance of its constituent elements represented as a probability distribution and resulting distributions combined to guide the decoder in generating output. | |
|
|

One step of the decoder could add zero, one, or more words, i.e., a phrase, to the current utterance under construction. Memories — both short- and long-term — are in the form of thought vectors or word sequences that could be used to reconstruct the original thought vectors for embedding or constructing composites by adding context or conditioning to emphasize relevant dimensions. The dialogue manager — a Q-function network trained by reinforcement learning — can also choose not to respond at all or could respond at some length perhaps incorporating references to code, explanations for design choices and demonstrations showing the results of executing code in the IDE.
To control generation, we adapt the pointer-generator network framework developed by See et al for document summarization [334]. In the standard sequence-to-sequence machine-translation model a weighted average of encoder states becomes the decoder state and attention is just the distribution of weights. In See et al attention is simpler: instead of weighting input elements, it points at them probabilistically. It isn't necessary to use all the pointers; such networks can mark excerpts by pointing to their start and end constituents. We apply their approach here to digest and integrate contextual information originating from multiple sources.
In humans, memory formation and consolidation involves several systems, multiple stages and can span hours, weeks or months depending on the stage and associated neural circuitry96. Our primary interest relates to the earliest stages of memory formation and role of the hippocampus and entorhinal region of the frontal cortex along with several ancillary subcortical circuits including the basal ganglia (BG). Influenced by the work of O'Reilly and Frank [16], we focus on the function of the dentate gyrus (DG) in the hippocampal formation and encode thought vectors using a sparse, invertible mapping thereby providing a high degree of pattern separation in encoding new information while avoiding interference with existing memories.
We finesse the details of what gets stored and when by simply storing everything. We could store the sparse representation provided by the DG, but prefer to use this probe as the key in a key-value pair in the NTM partition dedicated to episodic memory and store the raw data as the value. This means we have to reconstruct the original encoding produced when initially ingesting the text of an utterance. This is preferable for two reasons: (i) we need the words — or tokens of an abstract syntax tree in the case of ingesting code fragments — in order for the decoder to generate the apprentice's response, and (ii) the embeddings of the symbolic entities that constitute their meaning are likely to drift during ongoing training.
October 27, 2018
%%% Sat Oct 27 04:34:51 PDT 2018
Graph Networks is a neural network framework for constructing, modifying and performing inference on differentiable encodings of graphical structures. Battaglia et al [32] describe Graph Networks as a "new building block for the AI toolkit with a strong relational inductive bias97, the graph network, which generalizes and extends various approaches for neural networks that operate on graphs" by constraining the rules governing the composition of entities and their relationships.
In related work, Li et al [236] describe a model they refer to as a Gated Graph Sequence Neural Network (GGS-NN) that operates on graph networks to produce sequences from graph-structured input. Johnson [205] introduced the Gated Graph Transformer Neural Network (GGT-NN), an extension of GGS-NNs that uses graph-structured data as an intermediate representation. The model can learn to construct and modify graphs in sophisticated ways based on textual input, and also to use the graphs to produce a variety of outputs. The Graph Network (GN) Block described in Section 3.2 of Battaglia et al [32] provides a similar set of capabilities.
The network shown in Figure 61 demonstrates how to package the five general transformations described in Johnson’s paper to provide a Swiss-army-knife utility that can be used to manipulate abstract syntax trees in code synthesis simplifying the construction of differentiable neural programs introduced earlier. This graph-networks utility could be integrated into a reinforcement-learning code synthesis module that would learn how to repair programs or perform other forms of synthesis by learning how to predict the best alterations on the program under construction. The Graph Network Block provides many of the same operations.
| |
| Figure 61: The above graphic depicts a utility module that takes a graph in the Graph Networks representation and a command corresponding to one of the transformations described in [205], carries out the indicated transformation and produces the transformed graph in a recurrent output layer. See the definition of Graph Network Block in Section 3.2 of Battaglia et al [32] for an alternative formulation. | |
|
|
The imagination-based planning (IBP) for reinforcement learning framework [295] serves as an example for how the code synthesis module might be implemented. The IBP architecture combines three separate adaptive components: (a) the CONTROLLER + MEMORY system which maps a state s ∈ S and history h ∈ H to an action a ∈ A; (b) the MANAGER maps a history h ∈ H to a route u ∈ U that determines whether the system performs an action in the COMPUTE environment, e.g., single-step the program in the FIDE, or performs an imagination step, e.g., generates a proposal for modifying the existing code under construction; the IMAGINATION MODEL is a form of dynamical systems model that maps a pair consisting of a state s ∈ S and an action a ∈ A to an imagined next state s′ ∈ S and scalar-valued reward r ∈ R.
The IMAGINATION MODEL is implemented as an interaction network [31] that could also be represented using the graph-networks framework introduced here. The three components are trained by three distinct, concurrent, on-policy training loops. The IBP framework shown in Figure 62 allows code synthesis to alternate between exploiting by modifying and running code, and exploring by using the model to investigate and analyze what would happen if you actually did act. The MANAGER chooses whether to execute a command or predict (imagine) its result and can generate any number of trajectories to produce a tree ht of imagined results. The CONTROLLER takes this tree plus the compiled history and chooses an action (command) to carry out in the FIDE.
| |
| Figure 62: The above graphic illustrates how we might adapt the imagination-based planning (IBP) for reinforcement learning framework [295] for use as the core of the apprentice code synthesis module. Actions in this case correspond to transformations of the program under development. States incorporate the history of the evolving partial program. Imagination consists of exploring sequences of program transformations. | |
|
|

October 25, 2018
%%% Thu Oct 25 03:21:56 PDT 2018
Graph Networks [32] is a natural for encoding AST representations and so I came up with a simple utility module for exercising Daniel Johnson's Gated Graph Transformer Neural Networks framework [205]. In reading and thinking about the Weber et al imagination-augmented agent architecture [394], it seemed a good framework for leveraging some of Rishabh's suggested workflows and so I added that to the mix for my talk at Stanford next week.
If you're not familiar with this work, Oriol Vinyals did a great job explaining both the Weber et al paper and the DeepMind imagination-based planner framework in his lecture for my class, and Anusha Nagabandi and Gregory Kahn at Berkeley applied the framework in this robotics project.
I read Battaglia et al twice in the last few days. There are a bunch of reasons why but the most concrete came up when I started thinking about apprentice workflows for various programming tasks and that got me thinking about the ecosystem in which the apprentice operated. From Battaglia et al I was interested in the file system or version control system and how these might be implemented. It struck me just how important these technologies are and how we take them for granted.
It's not exactly rocket science but I also found it useful to think about how they might work in the case of the apprentice given the requirement for maintaining multiple representations. Once you have this puzzled out, it is lot easier to imagine different workflows that serve different use cases. The idea is to design the ecosystem with these different use cases in mind and put it to the test by imagining how the corresponding workflows would actually work.
October 23, 2018
%%% Tue Oct 23 04:46:06 PDT 2018
One reason that researchers in the 1980s focused primarily on symbolic systems is that the alternative was impractical. We had neither the computing power nor the access to training data that has fueled the recent renaissance in connectionist models. As Battaglia et al [32] note, we have become dependent on these resources and that dependence is impeding progress our on a number of critical dimensions.
Most deep learning models are dominated by their connectionist components, with symbolic components, such as Neural Turing Machines, being clumsily bolted on the side. In the next generation of systems, we can expect the connectionist and symbolic components to be on a more equal footing. In thinking about how to implement some new capability, it will be possible to choose between these two paradigms or some hybrid of the two.
Biological brains currently don’t have such flexibility given the degree to which natural selection has exploited the advantages of highly-parallel distributed representations. While this could change in principle, at least for now, we don't understand how to directly interface the human brain to a laptop and its file system in order to enhance our ability to efficiently store and reliably access large amounts of information.
There are practical problems that come up in purely connectionist approaches to code synthesis such as the organizational structure of modern hierarchical file systems. File systems, blackboard models and theorem provers are but a few of the technologies that complement connectionist models. A simple way to extend a rule-based system is to add rules that call programs using variable bindings to pass arguments and return results.
With the advent of Differentiable Neural Computers, it's become easier to harness more conventional computing resources from within a connectionist system using an appropriate interface and get the best characteristics of both paradigms. Many of the information-managing tools we rely upon depend on trees and graphs for their implementation, e.g., taxonomies, dictionaries, calendars, hierarchical task networks, PERT and GANTT charts.
When we think about a biological system managing its activity much of the relevant information will be stored in its episodic memory, but the apprentice will also benefit from having explicit descriptions of plans represented within a connectionist data structure to simplify keeping track of what it has do do — this applies to everything from managing multiple topics in conversation to keeping up with pending code reviews.
We can ingest programs by representing them as vectors in an embedding space and subsequently search for and find similar programs by using nearest neighbor search and maintaining a lookup table that allows us to index programs by their embedding vectors thereby allowing us to maintain programs in two formats and quickly alternate between the representations. The file system is itself a tree that the apprentice shares with programmer.
Battaglia et al [32] mention that graph networks have limitations that may restrict their application in reasoning about conventional computer programs:
More generally, while graphs are a powerful way of representing structure information, they have limits. For example, notions like recursion, control flow, and conditional iteration are not straightforward to represent with graphs, and, minimally, require additional assumptions (e.g., in interpreting abstract syntax trees). Programs and more "computer-like" processing can over greater representational and computational expressivity with respect to these notions, and some have argued they are an important component of human cognition. — excerpt from Page 23 in [32]
I expect it will be relatively easy to extend graph networks or use the basic framework as is for one component of a more expressive representational framework that handles computer programs. In particular, graph networks will make it relatively easy to represent — as opposed to interpret — programs as abstract syntax trees. The DNP approach illustrated in Figure 54 can dispense with the need for NTM program memory, while continuing to rely on an NTM to implement the highly dynamic call stack. Moreover, graph networks will considerably simplify the manipulation of differentiable neural programs in code synthesis, as well as simplify the design of an DNP emulator.
The generality of graph networks will certainly make it easier to create new abstractions, and I can easily imagine applications for graph algorithms like Dykstra's shortest path, Floyd–Warshall shortest path in a weighted graph, graph homomorphism and isomophism algorithms, etc. The DeepMind graph-nets Python library will also make it much easier for ML researchers to build graph-based abstractions on a solid foundation and then easily share and compare the results. I'm less sanguine about the extent to which graph networks representation will facilitate analogical reasoning and mental models, but reserve judgment until I've read the cited papers [226, 364, 78].
Battaglia et al mention Kenneth Craik [78] writing in 1943 on how the compositional structure of the world relates to how internal mental models are organized — see this 1983 retrospective review [224] of Craik's The Nature of Explanation for a short synopsis (PDF) and the following excerpt that was quoted in the introduction of Battaglia et al [32]:
[A human mental model] has a similar relation-structure to that of the process it imitates. By 'relation-structure' I do not mean some obscure non-physical entity which attends the model, but the fact that it is a working physical model which works in the same way as the process it parallels [...] physical reality is built up, apparently, from a few fundamental types of units whose properties determine many of the properties of the most complicated phenomena, and this seems to afford a sufficient explanation of the emergence of analogies between mechanisms and similarities of relation-structure among these combinations without the necessity of any theory of objective universals. — excerpt from Pages 51-55 in [78] (PDF)
Miscellaneous Loose Ends: Sean Carroll interviews David Poeppel [181] on the topic of "Thought, Language and How to Understand the Brain" in Episode 15 of Carroll's Mindcast podcast program. Poeppel is the Director at the Max Planck Institute for Empirical Aesthetics which sounds somewhat odd, but makes more sense when you hear Poeppel explain his research program early in the Carroll interview. The YouTube link is set to start 48 minutes into the podcast for those of you who understand the basic neurophysiology and have some familiarity with the dual-stream model of visual processing, since Poeppel will focus on the somewhat more controversial dual-stream model of speech processing in the interview.
Apropos of Poeppel's discussion, language production has been linked to a region in the frontal lobe of the dominant hemisphere since Pierre Paul Broca (1824-1880) reported language-related impairments in this region in two patients in a paper published in 1861. In 1874, Karl Wernicke (1848-1905) suggested a connection between the left posterior region of the superior temporal gyrus and the reflexive mimicking of words and their syllables leading some neurophysiologists to hypothesize that these areas are linked to language comprehension. It is interesting to note that these sketchy theories have prevailed to this day — nearly 150 years — despite their meager supporting evidence.
October 21, 2018
%%% Sun Oct 21 03:47:08 PDT 2018
I read Li et al [236] and Johnson [205] this morning in that order. My original impetus was to catch up on some of the background references before tackling Battaglia et al [32] the latest version — 3 — of which was just released — 17 October — on arXiv and promises in the abstract to generalize and extend various approaches for neural networks that operate on graphs. Rishabh Singh suggested that the representations and tools described in these three papers might provide a good foundation for implementing Differentiable Neural Programs — see Figure 54 — and their corresponding emulator architecture — see Figure 55. I like the clarifying graphics in Johnson's paper and his presentation at ICLR (PDF). In the following, I've included three of the figures in Johnson [205] to simplify my own brief account in these discussion notes.
Li et al [236] use the general term graph nets to refer neural network representations of graphs. The nomenclature will eventually get sorted out — perhaps with the recent Battaglia et al paper providing the definitive reference [32]. We've already mentioned some earlier work on graph networks in these notes including [214, 91, 116], but the current crop of papers mentioned in the previous paragraph attempt to tackle the general problem of learning generative models of graphs from a dataset of graphs of interest. To facilitate research and technology development on graph networks, researchers at DeepMind have provided the research community with a Python library for experimenting with graph networks in Tensorflow and Sonnet.
| |
| Figure 58: Diagram of the differentiable encoding of a graphical structure, as described in Section 3 of Johnson [205]. On the left, the desired graph we wish to represent, in which there are 6 node types (shown as blue, purple, red, orange, green, and yellow) and two edge types (shown as blue/solid and red/dashed). Node 3 and the edge between nodes 6 and 7 have a low strength. On the right, depictions of the node and edge matrices: annotations, strengths, state, and connectivity correspond to xv, sv, hv, and C, respectively. Saturation represents the value in each cell, where white represents 0, and fully saturated represents 1. Note that each node’s annotation only has a single nonzero entry, corresponding to each node having a single well-defined type, with the exception of node 3, which has an annotation that does not correspond to a single type. State vectors are shaded arbitrarily to indicate that they can store network-determined data. The edge connectivity matrix C is three dimensional, indicated by stacking the blue-edge cell on top of the red-edge cell for a given source-destination pair. Also notice the low strength for cell 3 in the strength vector and for the edge between node 6 and node 7 in the connectivity matrix — adapted from Figure 1 in Johnson [205]. | |
|
|

Figure 58 from Johnson [205] depicts the various components that comprise a differentiable encoding of a graphical structure. A similar representation is provided in Section 3.2 of Li et al [236]. What's important to note here is that these graph representations are expressive and straightforward to manipulate. Li et al [236] go on to describe how to learn and represent unconditional or conditional densities on a space of graphs given a representative sample of graphs, whereas Johnson [205] is primarily interested in using graphs as intermediate representations in reasoning tasks. As an example of the former, Li et al [236] describe how to create and sample from conditional generative graph models.
| |
| Figure 59: Summary of the graph transformations. Input and output are represented as gray squares. (a) Node addition (Tadd), where the input is used by a recurrent network (white box) to produce new nodes, of varying annotations and strengths. (b) Node state update (Th), where each node receives input (dashed line) and updates its internal state. (c) Edge update (TC), where each existing edge (colored) and potential edge (dashed) is added or removed according to the input and states of the adjacent nodes (depicted as solid arrows meeting at circles on each edge). (d) Propagation (Tprop), where nodes exchange information along the current edges, and update their states. (e) Aggregation (Trepr), where a single representation is created using an attention mechanism, by summing information from all nodes weighted by relevance (with weights shown by saturation of arrows) — adapted from Figure 2 in Johnson [205]. | |
|
|

In service to the latter — performing reasoning tasks, Johnson [205] demonstrates how his graph structure model can be made fully differentiable, and provides a set of graph tranformations that can be applied to a graph structure to transform it in various ways. For example, the propagation transfomation, Tprop, allows nodes to trade information across the existing edges and then update their internal states on the basis of the information received. Figure 59 summarizes the five differentiable graph transformations described in Johnson [205] and Figure 60 describes the set of operations performed for each class of transformations.
| |
| Figure 60: Diagram of the operations performed for each class of transformation. Graph state is shown in the format given by Figure 58. Input and output are shown as gray boxes. Black dots represent concatenation, and + and × represent addition and multiplication, respectively. The notation 1 − # represents taking the input value and subtracting it from 1. Note that for simplicity, operations are only shown for single nodes or edges, although the operations act on all nodes and edges in parallel. In particular, the propagation section focuses on information sent and received by the first node only. In that section the strengths of the edges in the connectivity matrix determine what information is sent to each of the other nodes. Light gray connections indicate the value zero, corresponding to situations where a given edge is not present — adapted from Figure 4 in Johnson [205]. | |
|
|

October 19, 2018
%%% Fri Oct 19 06:16:58 PDT 2018
The ability to maintain an appropriate context by drawing upon episodic memory in order to deal with long-term dependencies in deep learning models is an important requirement for conversational agents. Young et al [406] introduce a method based on reservoir sampling focusing on the ability to easily assign credit to a state when the retrieved information is determined to be useful. Their approach maintains a fixed number of past states and "preferentially remember[s] those states [that] are found to be useful to recall later on. Critically this method allows for efficient online computation of gradient estimates with respect to the write process of the external memory. [...] At each time step a single item Sti is drawn from the memory to condition the policy according to:
 |
| |
| Figure 56: Episodic memory architecture, each gray circle represents a neural network module. Input state (S) is given separately to the query (q), write (w), value (V) and policy (π) networks at each time step. The query network outputs a vector of size equal to the input state size which is used (via Equation 1) to choose a past state from the memory (m1, m2 or m3 in the above diagram) to condition the policy. The write network assigns a weight to each new state determining how likely it is to stay in memory. The policy network assigns probabilities to each action conditioned on current state and recalled state. The value network estimates expected return (value) from the current state — adapted from Young et al [406] | |
|
|

Figure 57 represents a group of papers relating to managing context for dialogue management that came up in a recent search for related work. The Hybrid Code Networks described in Williams et al [400] reminded me of early assistant architectures in that it attempts to identify a collection of relevant content sources that can be deployed to answer a particular class of queries and subsequently integrated and optimized with supervised learning, reinforcement learning or a mixture of both to accelerate training.
Su et al [352] is another approach to optimizing a dialogue policy via reinforcement learning in cases where reward signal is unreliable and it is too costly to pre-train a task success-predictor off-line. The authors "propose an on-line learning framework whereby the dialogue policy is jointly trained alongside the reward model via active learning with a Gaussian process model. This Gaussian process operates on a continuous space dialogue representation generated in an unsupervised fashion using a recurrent neural network encoder-decoder." I found the paper interesting primarily for its use of Gaussian processes.
Sordoni et al [346] describe a model architecture for generative context-aware query suggestion called Hierarchical Recurrent Encoder-Decoder (HRED). Their model is similar to our Contextual LSTM (CLSTM) model for large scale NLP tasks [144] which was originally conceived as a possible solution to the problem of maintaining a suitable context for dialogue management. The paper by Serban et al [335] came out a year later focusing on the dialogue management system and using the HRED architecture. They evaluate their approach on a large corpus of dialogue from movies and compare favorably with existing state-of-the-art methods. Truong et al [371] is a more complicated architecture employing the HRED architecture, but the paper also describes the Modular Architecture for Conversational Agents (MACA) — a framework for rapid prototyping and plug-and-play modular design.
The paper by See et al [334] on an extension of pointer-networks building on the work of Vinyals et al [380] to apply sequence-to-sequence attentional models to abstractive text summarization. The paper is relevant as it offers yet another way to selectively manage context that applies to a wide range of applications by enabling the decoder to select from multiple sources for word selection, accounting for both recency and meaning. Young et al [406] we discussed earlier and is represented here as yet another practical tool for achieving scale.
| |
| Figure 57: Here is a sample of recent papers relating to managing conversational context for dialogue management that came up in a recent search for related work. The papers are summarized briefly in the text proper. | |
|
|

Battaglia et al [32] argue that combinatorial generalization is necessary for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. As O'Reilly and Botvinick have pointed out how context sensitivity of highly-parallel connectionist approaches contrast with the systematic, combinatorial nature of largely-serial symbolic systems, Battaglia et al underscore the importance of the latter in distinguishing human intelligence. The paper promises to review and unify related work including two important papers, one by Li et al [236] on learning deep generative models of graphs, and a second by Daniel Johnson [205] that builds on Li et al by describing a set of differentiable graph transformations and then applying them to build a model with internal state that can extract structured data from text and use it to answer queries.
October 17, 2018
%%% Wed Oct 17 04:47:11 PDT 2018
Our objective in developing systems that incorporate characteristics of human intelligence is three fold: First, humans provide a compelling solution to the problem of building intelligent systems that we can use as a basic blueprint and then improve upon. Second, the resulting AI systems are likely to be well suited to developing assistants that complement and extend human intelligence while operating in a manner comprehensible to human understanding. Finally, cognitive and systems neuroscience provide clues to engineers interested in exploiting what we know concerning how humans think about and solve problems. In this appendix, we demonstrate one attempt to concretely realize what we've learned from these disciplines in an architecture constructed from off-the-shelf neural networks.
The programmer's apprentice relies on multiple sources of input, including dialogue in the form of text utterances, visual information from an editor buffer shared by the programmer and apprentice and information from a specially instrumented integrated development environment designed for analyzing, writing and debugging code adapted to interface seamlessly with the apprentice. This input is processed by a collection of neural networks modeled after the primary sensory areas in the primate brain. The output of these networks feeds into a hierarchy of additional networks corresponding to uni-modal secondary and multi-modal association areas that produce increasingly abstract representations as one ascends the hierarchy — see Figure 50.
| |
| Figure 50: The architecture of the apprentice sensory cortex including the layers corresponding to abstract, multi-modal representations handled by the association areas can be realized as a multi-layer hierarchical neural network model consisting of standard neural network components whose local architecture is primarily determined by the sensory modality involved. This graphic depicts these components as encapsulated in thought bubbles of the sort often employed in cartoons to indicate what some cartoon character is thinking. Analogously, the technical term "thought vector" is used to refer to the activation state of the output layer of such a component. | |
|
|

Stanislas Dehaene and his colleagues at the Collège de France in Paris developed a computational model of consciousness that provides a practical framework for thinking about consciousness that is sufficiently detailed for much of what an engineer might care about in designing digital assistants [95]. Dehaene’s work extends the Global Workspace Theory of Bernard Baars [23]. Dehaene’s version of the theory combined with Yoshua Bengio’s concept of a consciousness prior and deep reinforcement learning [264, 270] suggest a model for constructing and maintaining the cognitive states that arise and persist during complex problem solving [38].
Global Workspace Theory accounts for both conscious and unconscious thought with the primary distinction for our purpose being that the former has been selected for attention and the latter has not been so selected. Sensory data arrives at the periphery of the organism. The data is initially processed in the primary sensory areas located in posterior cortex, propagates forward and is further processed in increasingly-abstract multi-modal association areas. Even as information flows forward toward the front of the brain, the results of abstract computations performed in the association areas are fed back toward the primary sensory cortex. This basic pattern of activity is common in all mammals.
The human brain has evolved to handle language. In particular, humans have a large frontal cortex that includes machinery responsible for conscious awareness and that depends on an extensive network of specialized neurons called spindle cells that span a large portion of the posterior cortex allowing circuits in the frontal cortex to sense relevant activity throughout this area and then manage this activity by creating and maintaining the persistent state vectors that are necessary when inventing extended narratives or working on complex problems that require juggling many component concepts at once. Figure 51 suggests a neural architecture combining the idea of a global workspace with that of an attentional system for identifying relevant input.
| |
| Figure 51: The basic capabilities required to support conscious awareness can be realized in a relatively simple computational architecture that represents the apprentice’s global workspace and incorporates a model of attention that surveys activity throughout somatosensory and motor cortex, identifies the activity relevant to the current focus of attention and then maintains this state of activity so that it can readily be utilized in problem solving. In the case of the apprentice, new information is ingested into the model at the system interface, including dialog in the form of text, visual information in the form of editor screen images, and a collection of programming-related signals originating from a suite of software development tools. Single-modality sensory information feeds into multi-modal association areas to create rich abstract representations. Attentional networks in the prefrontal cortex take as input activations occurring throughout the posterior cortex. These networks are trained by reinforcement learning to identify areas of activity worth attending to and the learned policy selects a set of these areas to attend to and sustain. This attentional process is guided by a prior that prefers low-dimensional thought vectors corresponding to statements about the world that are either true, highly probable or very useful for making decisions. Humans can sustain only a few such activations at a time. The apprentice need not be so constrained. | |
|
|

Fundamental to our understanding of human cognition is the essential tradeoff between fast, highly-parallel, context-sensitive, distributed connectionist-style computations and slow, serial, systematic, combinatorial symbolic computations. In developing the programmer's apprentice, symbolic computations of the sort common in conventional computing are realized using extensions that provide a differentiable interface to conventional memory and information processing hardware and software. Such interfaces include the Neural Turing Machine [153] (NTM), Memory Network Model [397, 356] and Differentiable Neural Computer [2] (DNC).
The global workspace summarizes recent experience in terms of sensory input, its integration, abstraction and inferred relevance to the context in which the underlying information was acquired. To exploit the knowledge encapsulated in such experience, the apprentice must identify and make available relevant experience. The apprentice’s experiential knowledge is encoded as tuples in a Neural Turing Machine (NTM) memory that supports associative recall. We’ll ignore the details of the encoding process to focus on how episodic memory is organized, searched and applied to solving problems.
In the biological analog of an NTM the hippocampus and entorhinal region of the frontal cortex play the role of episodic memory and several subcortical circuits including the basal ganglia comprise the controller [291, 288]. The controller employs associative keys in the form of low-dimensional vectors generated from activations highlighted in the global workspace to access related memories that are then actively maintained in the prefrontal cortex and serve to bias processing throughout the brain but particularly in those circuits highlighted in the global workspace. Figure 52 provides a sketch of how this is accomplished in the apprentice architecture.
| |
| Figure 52: You can think of the episodic memory encoded in the hippocampus and entorhinal cortex as RAM and the actively maintained memories in the prefrontal cortex as the contents of registers in a conventional von Neumann architecture. Since the activated memories have different temporal characteristics and functional relationships with the contents of the global workspace, we implement them as two separate NTM memory systems each with its own special-purpose controller. Actively maintained information highlighted in the global workspace is used to generate keys for retrieving relevant memories that augment the highlighted activations. In the DNC paper [2] appearing in Nature, the authors point out that "an associative key that only partially matches the content of a memory location can still be used to attend strongly to that location [allowing] allowing the content of one address [to] effectively encode references to other addresses". The contents of memory consist of thought vectors that can be composed with other thought vectors to shape the global context for interpretation. | |
|
|

Figure 53 combines the components that we've introduced so far in a single neural network architecture. The empty box on the far right includes both the language processing and dialogue management systems as well the networks that interface with FIDE and the other components involved in code synthesis. There are several classes of programming tasks that we might tackle in order to show off the apprentice, including commenting, extending, refactoring and repairing programs. We could focus on functional languages like Scheme or Haskell, strongly typed languages like Pascal and Java or domain specific languages like HTML or SQL.
However, rather than emphasize any particular programming language or task, in the remainder of this appendix we focus on how one might represent structured programs consisting of one or more procedures in a distributed connectionist framework so as to exploit the advantages of this computational paradigm. We believe the highly-parallel, contextual, connectionist computations that dominate in human information processing will complement the primarily-serial, combinatorial, symbolic computations that characterize conventional information processing and will have a considerable positive impact on the development of practical automatic programming methods.
| |
| Figure 53: This slide summarizes the architectural components introduced so far in a single model. Data in the form of text transcriptions of ongoing dialogue, source code and related documentation and output from the integrated development environment are the primary input to the system and are handled by relatively standard neural network models. The Q-network for the attentional RL system is realized as a multi-layer convolutional network. The two DNC controllers are straightforward variations on existing network models with a second controller responsible for maintaining a priority queue encodings of relevant past experience retrieved from episodic memory. The nondescript box labeled "motor cortex" serves as a placeholder for the neural networks responsible for managing dialogue and handling tasks related to programming and code synthesis. | |
|
|

The integrated development environment and its associated software engineering tools constitute an extension of the apprentice’s capabilities in much the same way that a piano or violin extends a musician or a prosthetic limb extends someone who has lost an arm or leg. The extension becomes an integral part of the person possessing it and over time their brain creates a topographic map that facilitates interacting with the extension98.
As engineers designing the apprentice, part of our job is to create tools that enable the apprentice to learn its trade and eventually become an expert. Conventional IDE tools simplify the job of software engineers in designing software. The fully instrumented IDE (FIDE) that we engineer for the apprentice will be integrated into the apprentice’s cognitive architecture so that tasks like stepping a debugger or setting breakpoints are as easy for the apprentice as balancing parentheses and checking for spelling errors in a text editor is for us.
As a first step in simplifying the use of FIDE for coding, the apprentice is designed to manipulate programs as abstract syntax trees (AST) and easily move back and forth between the AST representation and the original source code in collaborating with the programmer. Both the apprentice and the programmer can modify or make references to text appearing in the FIDE window by pointing to items or highlighting regions of the source code. The text and AST versions of the programs represented in the FIDE are automatically synchronized so that the program under development is forced to adhere to certain syntactic invariants.
| |
| Figure 54: We use pointers to represent programs as abstract syntax trees and partition the NTM memory, as in a conventional computer, into program memory and a LIFO execution (call) stack to support recursion and reentrant procedure invocations, including call frames for return addresses, local variable values and related parameters. The NTM controller manages the program counter and LIFO call stack to simulate the execution of programs stored in program memory. Program statements are represented as embedding vectors and the system learns to evaluate these representations in order to generate intermediate results that are also embeddings. It is a simple matter to execute the corresponding code in the FIDE and incorporate any of the results as features in embeddings. | |
|
|

To support this hypothesis, we are developing distributed representations for programs that enable the apprentice to efficiently search for solutions to programming problems by allowing the apprentice to easily move back and forth between the two paradigms, exploiting both conventional approaches to program synthesis and recent work on machine learning and inference in artificial neural networks. Neural Turing Machines coupled with reinforcement learning are capable of learning simple programs. We are interested in representing structured programs expressed in modern programming languages. Our approach is to alter the NTM controller and impose additional structure on the NTM memory designed to support procedural abstraction.
What could we do with such a representation? It is important to understand why we don’t work with some intermediate representation like bytecodes. By working in the target programming language, we can take advantage of both the abstractions afforded by the language and the expert knowledge of the programmer about how to exploit those abstractions. The apprentice is bootstrapped with several statistical language models: one trained on a natural language corpus and the other on a large code repository. Using these resources and the means of representing and manipulating program embeddings, we intend to train the apprentice to predict the next expression in a partially constructed program by using a variant of imagination-based planning [295]. As another example, we will attempt to leverage NLP methods to generate proposals for substituting one program fragment for another as the basis for code completion.
| |
| Figure 55: This slide illustrates how we make use of input / output pairs as program invariants to narrow search for the next statement in the evolving target program. At any given moment the call stack contains the trace of a single conditioned path through the developing program. A single path is unlikely to provide sufficient information to account for the constraints implicit in all of the sample input / output pairs and so we intend to use a limited lookahead planning system to sample multiple execution traces in order to inform the prediction of the next program statement. These so-called imagination-augmented agents implement a novel architecture for reinforcement learning that balances exploration and exploitation using imperfect models to generate trajectories from some initial state using actions sampled from a rollout policy [295, 394, 172, 164]. These trajectories are then combined and fed to an output policy along with the action proposed by a model-free policy to make better decisions. There are related reinforcement learning architectures that perform Monte Carlo Markov chain search to apply and collect the constraints from multiple input / output pairs. | |
|
|

The Differentiable Neural Program (DNP) representation and associated NTM controller for managing the call stack and single-stepping through such programs allow us to exploit the advantages of distributed vector representations to predict the next statement in a program under construction. This model makes it easy to take advantage of supplied natural language descriptions and example input / output pairs plus incorporate semantic information in the form of execution traces generated by utilizing the FIDE to evaluate each statement and encoding information about local variables on the stack.
October 9, 2018
%%% Tue Oct 9 02:48:10 PDT 2018
Read a couple of papers on integrating episodic memory in reinforcement learning dialogue systems from Sieber and Krenn [337] and Young et al [406]. Along similar lines as Williams et al [400], Su et al [352] explore a method for active reward learning that significantly reduces the amount of annotated data required for dialogue policy learning99 .
Miscellaneous Loose Ends: I learned a bit about early work in understanding the chemical transmission of nerve impulses listening to an interview with Paul Greengard. Greengard shared with Arvid Carlsson and Eric Kandel the 2000 Nobel Prize in Physiology or Medicine for their discoveries concerning signal transduction in the nervous system. Greengard's autobiographical video on the Society for Neuroscience website is an excellent introduction to the history surrounding the discovery the chemical pathways in neural circuits, the related biochemistry and the controversy and cast of interesting characters who encouraged or discouraged work in this direction, including Eric Kandel and Rodolfo Llinás in their role as understanding the electroneurophysiology, and John Eccles who shared the 1963 Nobel Prize in Physiology or Medicine for his work on the synapse with Andrew Huxley and Alan Lloyd Hodgkin and believed that synaptic transmission was purely electrical. Actually, Henry Hallett Dale was the first to identify acetylcholine as an agent in the chemical transmission of nerve impulses (neurotransmission) for which he shared the 1936 Nobel Prize in Physiology or Medicine with Otto Loewi. Eccles was his most prominent adversary at the time and continued his opposition throughout a prolonged period of debate that continued through the 1940s and much of the 1950s and was one of the most significant in the history of neuroscience in the 20th century PDF.
October 7, 2018
%%% Sun Oct 7 04:35:26 PDT 2018
Here is a short email exchange that includes some ideas about distributed representations of programs along with references to recent papers on code embedding:
TLD: I've been talking about the possibility of embedding code fragments using variants of the skip-gram and CBOW models for some time now [233, 261]. I assumed that someone else must have thought of this and implemented an instantiation of the basic idea. However, when I actually started looking, I was unable to come up with more than a few promising directions [60, 269]. I'm not counting these papers [5, 8, 7, 6] first authored by Miltiadis Allamanis, that I think you pointed me to earlier. The only really concrete example I could find is this recent paper [10] on predicting method names from continuous distributed vector presentations of code. Are you aware of any more interesting work along these lines that I'm overlooking?I'm most interested in using some version of the continuous bag of words (CBOW) model to predict a fragment corresponding to a target node in the abstract syntax tree from all the nodes in its immediate context, e.g., adjacent nodes in the AST or all nodes within a fixed path length of the target. I'm also considering the possiblity of using input-output pairs as invariants to constrain statements in defining a procedure or method to meet some specification — especially the statements at the beginning or end of the definition, or, as I think you mentioned in an earlier meeting, to provide suggestions for applicable data types that might hint at an implementation.
For example, this expression,
(equal? output ((lambda (parameters) definition) input)), might serve as a probe that could be used to generate proposals for code fragments or parameter data types appearing in the body of the lambda expression corresponding to this description:
(define describe_A "Given a list consisting of three words represented as strings, find and replace the first occurrence of the second word with the third word in a given string if the occurrence of the second word is preceded by the first word by no more than two separating words.") (define document_A '("Abigail Smith was President John Adams closest adviser")) (define triplets_A '(("Abigail" "Smith" "Adams") ("Dolley" "Todd" "Madison"))) (equal? "Abigail Adams was President John Adams closest adviser" ((lambda (triple document separation) (let ((given (first triple)) (maiden (second triple)) (married (third triple))) (do ((dist (+ 1 separation) (+ 1 dist)) (words (string-split document) (rest words)) (out (list))) ((null? words) (print (string-join out))) (cond ((equal? given (first words)) (set! dist 0) (set! out (append out (list given)))) ((and (equal? maiden (first words)) (< dist separation)) (set! out (append out (list married)))) (else (set! out (append out (list (first words)))))) ) ) ) (list "Abigail" "Smith" "Adams") "Abigail Smith was President John Adams closest adviser" 2))I just borrowed this example from my 2018 course notes and so it's not representative of the use case I really have in mind, but it reminded me of how important it will be to use a graded set of examples, starting out with much simpler examples than those illustrated in the above description. Thanks in advance for any suggestions.
RIS: Yes, I also don't think there has been a lot of interesting work on learning good program embeddings other than trying to use traditional word2vec style program embeddings using sequence models. There were couple of recent papers I was reading that may also be related, but still seemed a bit preliminary: (1) There was an extension to the code2vec paper entitled "code2seq: "Generating Sequences from Structured Representations of CodeGenerating Sequences from Structured Representations of Code" [9], where the authors made the embedding network recurrent to learn path embeddings in an AST between two leaf nodes as a sequence of nodes, and (2) "Code Vectors: Understanding Programs Through Embedded Abstracted Symbolic Traces" [180]: this paper abstracts program source code into a set of paths, where each path is abstracted using only a sequence of function calls. The paths are then embedded using a word2vec style approach.
Thanks for the example — this looks quite interesting. For this particular example, the input-output example based specification would require a few corner cases to precisely cover all the cases where the first word precedes the second word by one word, two words, three or more words. On the other hand, the natural language based description might be more concise and clearer to specify the intent.
Predicting code fragments as a target node in an AST given some context AST nodes sounds like a great application domain to train and evaluate the embeddings. There are a few papers looking at code completion like problems, where the goal is to predict an expression given the surrounding program context: "PHOG: Probabilistic Model for Code" [43], "Learning Python Code Suggestion with a Sparse Pointer Network" [41], "Code Completion with Neural Attention and Pointer Networks" [235], "Neural Code Completion" [242].
I don't think any of these papers explicitly consider the problem of embedding program nodes, which is a key central problem and would be an important one to solve for performing any downstream task like code completion or synthesis.
TLD: Thanks for the additional references. I have been toying with the idea of using distinct execution traces as a basis for learning vector program representations for the purpose of automated reconstruction but was — and still am, to a certain extent — concerned about the inevitable exponential explosion. That said, one can imagine sampling traces to different depths in order to iteratively construct a program with branches. Two of the papers you mentioned suggest similarly motivated strategies: Henkel et al [180] employ "abstractions of traces obtained from symbolic execution of a program as a representation for learning word embeddings" and Alon et al [9] represent code snippets as "the set of paths in [the corresponding] abstract syntax tree[s] and [use] attention to select the relevant paths during decoding, much like contemporary [neural machine translation] models." I've got some ideas about using Wavenet and the differentiable neural program representation that I sketched in Slide 19 of the draft presentation to create embeddings that include both semantics and syntactic information. The idea is not well developed but I hope to do so later this week.
Miscellaneous Loose Ends: A series of entries in the 2018 class notes focused Terrence Deacon's theories about language as laid out in his book The Symbolic Species: The Co-evolution of Language and the Brain [5]. This past weekend I read Deacon's more recent book [85] entitled Incomplete Nature: How Mind Emerged from Matter and wrote up a short synopsis that you can read here100 if you're interested in the possible relationships between consciousness and the origins of life.
September 27, 2018
This morning I thought more about implementing subroutines in the latest version of the Programmer's Apprentice architecture. I was swimming at Stanford, trying to re-program my outlook to enjoy exercise and mostly failing to make any headway. I had posed two questions to focus on during the swim in order to take my mind off the cold and tedium of swimming laps:
How do you exploit conscious awareness — highlighting activation in the global workspace?
How do you exploit automatic episodic recall — making related content available for access?
About half way through my routine, I started thinking about how to build a neural analog of a simple register machine: processor clock, program counter, read from memory, write to memory, etc. I had initially dismissed the idea as unfeasible despite the fact that there have been a number of papers describing how you can use differentiable memory models and reinforcement learning to implement simple algorithms, e.g., Neural Turing Machines (NTM/DNC) [Graves et al [2, 153]], Memory Networks [Weston et al [397]] and differentiable versions of Stacks, Queues and DeQues (double-ended queues) [Grefenstette et al [160]].
The hardware in a conventional ALU includes an instruction sequencer, program counter (instruction register), memory address register, instruction address register and branch address register. My first inclination was to simplify the addressing by using a variant of Greg Wayne's unsupervised predictive memory for goal-directed agents in partially observable Markov decision processes as a branch predictor, assuming every step is a branch and avoiding sequential memory addresses altogether [393].
At some point, it dawned on me that there was nothing wrong with the idea of a register machine that pointers and associative indexing couldn't cure. I came up with several plausible architectures. In the simplest case, the attentional circuit that implements conscious awareness in the frontal cortex serves as a processor clock and program counter, and the (episodic) memory system composed of the hippocampus, basal ganglia and prefrontal cortex serves as a next instruction / branch predictor. Since episodic memory is implemented as an NTM we can easily encode an associative key, pointer (a) to the current instruction, and pointer (b) to the next instruction.
Once you get the basic idea there are all sorts of alternatives to consider, e.g., pointer (a) could be a thought vector or sparse hippocampal probe providing an extra level of indirection, pointer (b) could be another associative key, or more generally you could feed pointer (a) and (b) to a microcode sequencer that handles microcode execution and branching. The neural register machine could be used to run native programs in the IDE, execute hierarchical task networks as a form of microcode that runs in a separate processor, serving a role similar to that played by the cerebellar cortex in fine-motor and cognitive control [5, 202, 201]
September 15, 2018
Almost everyone wants to improve themselves in some way and that often requires reprogramming yourself. How to accomplish this is the $64,000 question and the topic of our class discussion with Randall O'Reilly. There are self-help books for learning how to do almost anything including improving personal relationships [62], controlling your emotions [149], practicing mindfulness meditation [209], and improving your tennis game [139]. However, as far as I know, none of them tell you how to write programs that will run on your innate computational substrate.
Randy and I discussed how you might possibly teach someone how to load a list of parameter values into memory and call a procedure on those values as arguments. This would certainly facilitate learning how to execute an algorithm for performing long division or simplifying algebraic equations in your head as children are taught to do in the fourth grade. Of course, we want the apprentice to learn to synthesize programs from specifications or from input/output pairs. That's not the same thing as learning a program for writing programs from scratch, but it suggests a different way of approaching the problem.
In terms of taking stock of where we are at this stage in our investigations, it seems we are expecting parallel distributed (connectionist) representations to provide some advantage over or to fundamentally and usefully complement serial (combinatorial) symbolic representations101. A related issue concerns whether natural language is an advantage or liability in developing automated programming systems. It certainly plays a crucial role if we are set on building an assistant as opposed to a fully-capable, standalone software engineering savant that achieves or surpasses the competence of an expert human programmer.
One problem concerns the content and structure of thought vectors. It is already complicated to compose and subsequently decode thought vectors that are composed of two or more contributing thought vectors of the same sort, e.g., derived from natural language utterances. If we take the idea of multi-modal association areas seriously then we will be creating thought vectors that combine vectors constructed from natural language and programming language fragments. Of course, we can rely on context to avoid confusing the two, e.g., while as a word in natural language or a token in a programming language, as in [334].
The idea of natural language as a lingua franca for intra-cortical communication perversely appeals to me. There is something seductive about learning to translate natural language specifications into programs written in a specialized domain-specific-language (DSL) that can be directly executed using some control policy to write, debug, refactor or repair code. Perhaps I will simply have to abandon this idea for now, given that my current conception just trades one complicated algorithmic protocol for another. The other option that I keep returning to relies entirely on the composition of existing program fragments.
Miscellaneous Loose Ends: The dialogue between technical collaborators and pair-programmers in particular is full of interruptions, negotiations, suggestions, pregnant pauses, unsolicited restatements, thinking out loud, counterfactuals, off-the-cuff reactions, carefully formulated analyses, wild guesses, confusions over ambiguous references, accommodations of different strategies for engagement, requests for an alternative formulations, sustained misunderstanding, ueries concerning ambiguous references, requests for self-retraction, e.g., "forget about that" or "that didn't make any sense; ignore the last thing I said", declarations of fact, imperative statements, e.g., "insert a new expression at the cursor" or "add a comment after the assignment statement", etc.
All of these can be thought of as interlocutory plans, conversational gambits, speech acts. They can be internalized and generalized using an intermediate language derived from hierarchical goal-based planning and formalized as hierarchical task networks, you can think of this as a specialized intra-cortical lingua franca enabling the apprentice to formulate sophisticated plans that allow for conditional branching, decompose complicated tasks into partially ordered sequences of subtasks and support executive-control over plan deployment and execution including the termination of entire subnetworks, the ability to replan on the fly, and the use of continuations representing partially expanded plans awaiting additional input.
Buried in such exchanges is a great deal of information, the imparting of knowledge, the creation of new technology, the emergence of joint ideation and serendipitous discovery. In the best of collaborations, there is a merging complementary intellects in which individuals become joined in their efforts to create something of value. Francis Crick and Jim Watson, David Hubel and Torsten Wiesel, Alan Hodgkin and Andrew Huxley, Daniel Kahneman and Amos Tversky were not obviously made for one another and yet in each case they forged a collaboration in which they complemented one another and often became so engaged that they completed one another's sentences. We think it is possible to create artificial assistants that could provide a similar level of intellectual intimacy and technical complementarity.
September 7, 2018
In this log entry, we continue where we left off in the previous class discussion notes on developing an end-to-end training protocol for bootstrapping a variant of the programmer's apprentice application. We begin with the analogous stages in early child development. Each of the following four stages is briefly introduced with additional technical details provided in the accompanying footnote:
Basic cognitive bootstrapping and linguistic grounding102:
modeling language: statistical n-gram language model trained on programming corpus;
hierarchical planning: automated tutor generates lessons using curriculum training;
Simple interactive behavior for signaling and editing104:
following instruction: learning to carry out simple plans one instruction at a time;
explaining behavior: providing short explanations of behavior, acknowledging failure;
Mixed dialogue interleaving instruction and mirroring107:
classifying intention: learning to categorize tasks and summarize intentions to act;
confirming comprehension: conveying practical understanding of specific instructions;
Composite behaviors corresponding to simple repairs108:
executing complex plans: generating and executing multi-step plans with contingencies;
recovering from failure: backtracking, recovering, retracting steps on failed branches;
References
1 The language of thought hypothesis (LOTH) is a view in linguistics, philosophy of mind and cognitive science, forwarded by American philosopher Jerry Fodor [128]. It describes the nature of thought as possessing "language-like" or compositional structure (sometimes known as mentalese). On this view, simple concepts combine in systematic ways (akin to the rules of grammar in language) to build thoughts. In its most basic form, the theory states that thought, like language, has syntax. Using empirical data drawn from linguistics and cognitive science to describe mental representation from a philosophical vantage-point, the hypothesis states that thinking takes place in a language of thought (LOT): cognition and cognitive processes are only 'remotely plausible' when expressed as a system of representations that is "tokened" by a linguistic or semantic structure and operated upon by means of a combinatorial syntax. SOURCE
2 Yoon et al [405] present a neural-network architecture for lifelong learning that addresses the following challenges: The authors write: "There are a number of challenges that need to be tackled for such incremental deep learning setting with selective parameter sharing and dynamic layer expansion:
Achieving scalability and efficiency in training: If the network grows in capacity, training cost per task will increasingly grow as well, since the later tasks will establish connections to a much larger network. Thus, we need a way to keep the computational overhead of retraining to be low.
Deciding when to expand the network, and how many neurons to add: The network might not need to expand its size, if the old network sufficiently explains the new task. On the other hand, it might need to add in many neurons if the task is very different from the existing ones. Hence, the model needs to dynamically add in only the necessary number of neurons.
Preventing semantic drift, or catastrophic forgetting, where the network drifts away from the initial configuration as it trains on new tasks, and thus exhibits degenerate performance for earlier learned tasks. As our method retrains the network, even partially, to fit to later learned tasks, and add in new neurons which might also negatively affect the prior tasks by establishing connections to old subnetwork, we need a mechanism to prevent potential semantic drift."
3 From "Dynamics of Hippocampal Neurogenesis in Adult Humans" by Spalding et al [347]:
Adult-born hippocampal neurons are important for cognitive plasticity in rodents. There is evidence for hippocampal neurogenesis in adult humans, although whether its extent is sufficient to have functional significance has been questioned. We have assessed the generation of hippocampal cells in humans by measuring the concentration of nuclear-bomb-test-derived 14C in genomic DNA, and we present an integrated model of the cell turnover dynamics. We found that a large subpopulation of hippocampal neurons constituting one-third of the neurons is subject to exchange. In adult humans, 700 new neurons are added in each hippocampus per day, corresponding to an annual turnover of 1.75% of the neurons within the renewing fraction, with a modest decline during aging. We conclude that neurons are generated throughout adulthood and that the rates are comparable in middle-aged humans and mice, suggesting that adult hippocampal neurogenesis may contribute to human brain function. (SOURCE):
4 Here is the abstract for Aimone et al [1] suggesting a more complicated role for neurogenesis in the dentate gyrus that involves both pattern-completion and time-dependent pattern-integration.
Adult neurogenesis in the hippocampus leads to the incorporation of thousands of new granule cells into the dentate gyrus every month, but its function remains unclear. Here, we present computational evidence that indicates that adult neurogenesis may make three separate but related contributions to memory formation. First, immature neurons introduce a degree of similarity to memories learned at the same time, a process we refer to as pattern integration. Second, the extended maturation and change in excitability of these neurons make this added similarity a time-dependent effect, supporting the possibility that temporal information is included in new hippocampal memories. Finally, our model suggests that the experience-dependent addition of neurons results in a dentate gyrus network well suited for encoding new memories in familiar contexts while treating novel contexts differently. Taken together, these results indicate that new granule cells may affect hippocampal function in several unique and previously unpredicted ways.
5 Here is an excerpt from Barbara Tversky's Mind in Motion: How Action Shapes Thought [375]. The excerpt is in a section from Chapter 5 entitled "Gestures Change The Thoughts Of Others".
We start with babies again. Babies whose caretakers use gesture and speech simultaneously (rather than unaccompanied speech) acquire vocabulary faster. It could be that gestures like pointing clarify the referents of the speech. It could be that gestures enact or depict the referents of the speech. It is probably both and more. When babies see more gestures, they gesture more themselves, providing, as we saw earlier, yet another route for increasing vocabulary.Parents are so proud when their toddlers can count. But then they are baffled. Despite getting all the number words in the right order, their young prodigies can’t answer: How many? What counting means to the toddlers is matching a sequence of words to a series of points to objects. It’s rote learning like the alphabet song, with the addition of a marching pointing finger. It isn’t yet about number as we understand number. Don’t get me wrong, this is a remarkable achievement. That they can do one-to-one correspondence, one number for each object irrespective of the object and increasing numbers, at that, is impressive. Other primates don’t do that. But one-to-one correspondence is only part of the picture. When they can’t answer how many, they don’t yet understand cardinality, that the last number word, the highest number, is the total count for the set. If you show them a picture of two sets, say Jonah’s candy and Sarah’s candy, and ask them to tell how many pieces of candy each child has, they often count Jonah’s and without stopping, continue on to count Sarah’s. Gesturing a circle around each set of candy helps them to count each set separately, an important step toward understanding cardinality. The circular gesture creates a boundary around each set, including the candy in Sarah’s set and separating hers from Jonah’s. Children are more likely to stop counting at the boundary.
Now we jump to bigger people. When we explain something to someone else, we typically gesture. Those gestures are usually larger than the gestures we make for ourselves, there are more of them, and they work together to form a narrative that parallels the spoken narrative. If speakers make larger gestures for others and link them in a narrative, then it’s likely they think the gestures help their listeners. We certainly depend on gestures when someone tells us which way to go or how to do something. But that kind of gesture depicts actions we are supposed to take in the world. What about gestures that are meant to change thought, to form representations in the mind?
For this, we turned to concepts that people of all ages and occupations need to learn and that are difficult. Complex systems. The branches of government, what each does, how laws are passed, how they are challenged in courts. How elections proceed, how babies are made, how the heart works. Shakespeare’s plays, the main figures, their social and political relations, what each did and how others reacted. Diverse as they are, underneath each is a complex system with a structural layer and a dynamic layer. Structure is an arrangement of parts. Dynamics is a causal sequence of actions. Structure is space; dynamics, time.
Dozens of studies have shown that it’s easier to grasp structure than dynamics. Structure is static. Dynamics is change, often causality. Novices and the half of us low in spatial ability understand structure, but it takes expertise or ability or effort to understand dynamics. Structure can readily be put on a page. A map of a city. A diagram of the branches of government, the parts of a flower, a family tree. Networks of all kinds. Action doesn’t stay still, it’s harder to capture and harder to show. The actions are diverse and the causality is varied and might not be visible, forces and wind.
Gestures are actions; could gestures that represent actions help people understand dynamics? For a dynamic system, we chose the workings of a car engine. We wrote a script that explained its structure and action, everything that would be needed to answer the questions we asked later. Then we made two videos of the same person using the same script to explain the car engine. One video had eleven gestures showing structure, such as the shape of the pistons. Another had eleven gestures showing action, say, of the piston. The same rudimentary diagram appeared in both videos. A large group of students watched one or the other of the videos. Because structure is easy, we didn’t expect effects of structure gestures, but it was important that both groups of viewers see gestures.
After viewing the explanation of the car engine, participants answered a set of questions, half on structure, half on action. Then they created visual explanations of the car engine. Finally, they explained the workings of the car engine to a video camera so that someone else could understand. Viewing action gestures had far-reaching consequences. People who had viewed action gestures answered more action questions correctly, even though all the information was in the script. The differences in the visual and videoed explanations were more dramatic. Those who had seen action gestures showed far more action in their visualizations: they used more arrows, they depicted actions like explosions, intake, and compression. They separated the steps of the process more cleanly. In their videoed explanations, they used far more action gestures and most of those were inventions, not imitations. They used more action words, even though they hadn’t heard more action words. Viewing straightforward and natural gestures conveying action gave students a far deeper understanding of action, an understanding revealed in their knowledge, in their diagrams, in their gestures, and in their words.
Put simply, gestures change thought. Gestures that we make as well as gestures that we see. Next, we turned to concepts of time, using the same technique: identical script, different gestures for different participants. Perhaps because words come one after another, people can have trouble grasping that two steps or events aren’t strictly ordered in time. They may be simultaneous in actual time or their order might not matter. When the stages of a procedure are described as, first you do M, then you can do P or Q in either order, and finally you do W, people often remember that P precedes Q (or vice versa). When the description of the steps in time was accompanied by a beat gesture for each step, people made the error of strictly ordering the steps. However, when the description came with a gesture indicating simultaneity, unordered steps were remembered correctly, as unordered.
Another temporal concept that doesn’t come easily for people is cyclicity. Think of cycles like the seasons, washing clothes, the rock cycle, and this one: the seed germinates, the flower grows, the flower is pollinated, a new seed is formed. When given the steps of cycles like these and asked to diagram them, people tend to draw linear, but not circular, diagrams. People do understand circular diagrams of cycles perfectly well, but they produce linear ones. Gestures change that. When we presented one of the processes with gestures that proceeded along a line, the linear tendency strengthened. But when we presented one of the processes with gestures that went in a circle, a majority drew circular diagrams. Importantly, they weren’t simply copying the gestures. We repeated the experiment with another group and instead of asking them to create a diagram after the last stage, we asked them: What comes next? Those who had seen circular diagrams usually went back to the beginning of the cycle and said: the seed germinates. But those who had seen linear gestures tended to continue to a new process, like gathering flowers for a bouquet. So, seeing the circular gestures did change the way people thought.
These studies are only a drop in the bucket of the research showing that the gestures we view change the ways we think. The trick is to create gestures that establish a space of ideas that represents the thought felicitously. That gestures have the power to change thought has powerful implications for communication, in the classroom and outside.
6 Barbara Tversky in writing in Mind in Motion: How Action Shapes Thought on the role of the hippocampus in abstract spatial thinking: [375]:
There are two key facts, one about place cells, the second about grid cells, that allow them to represent different real spaces and, later in evolution, abstract spaces. Place cells in hippocampus represent integrated sets of features, whether places, episodes, plans, or ideas, as individuals, independent of how they are interrelated. Grid cells represent relations among those places or ideas, spatial, temporal, or conceptual. Like grid paper, grid cells are a template that can be reused, remapped. Voilà! the same neural foundation that serves spatial thought serves abstract thought. It’s as though the hippocampus created checkers or tokens for places or memories or ideas and entorhinal cortex provided a checkerboard for arraying the relations among them in space. Significantly, the array of grid cells, the checkerboard, is two-dimensional, flat, perhaps one reason why thinking in three dimensions is challenging for most people. I repeat: the same brain mechanisms in humans that represent actual places in real spaces also represent ideas in conceptual spaces. Spatial thinking enables abstract thinking. We are now ready to proclaim (trumpets, please!) the crucial, central, fundamental tenet of the book: Sixth Law of Cognition: Spatial thinking is the foundation of abstract thought. The foundation, not the entire edifice. We show some of the implications of the Sixth Law in the next section, which recounts many curious and systematic distortions in people’s cognitive maps, distortions that are mirrored in people’s social maps.
7 Below you'll find selected bibliography references mentioned in the text relevant to state estimation for purposes of action selection and transfer learning. If you've never heard Nando de Freitas speak about his research before you might check out Nando de Freitas: "Enlightenment, Compassion, Survival" on the Brain Inspired podcast BI 040.
@article{ReedandDeFreitasCoRR-15,
author = {Scott E. Reed and Nando de Freitas},
title = {Neural Programmer-Interpreters},
journal = {CoRR},
volume = {arXiv:1511.06279},
year = {2015},
abstract = {We propose the neural programmer-interpreter (NPI): a recurrent and compositional neural network that learns to represent and execute programs. NPI has three learnable components: a task-agnostic recurrent core, a persistent key-value program memory, and domain-specific encoders that enable a single NPI to operate in multiple perceptually diverse environments with distinct affordances. By learning to compose lower-level programs to express higher-level programs, NPI reduces sample complexity and increases generalization ability compared to sequence-to-sequence LSTMs. The program memory allows efficient learning of additional tasks by building on existing programs. NPI can also harness the environment (e.g. a scratch pad with read-write pointers) to cache intermediate results of computation, lessening the long-term memory burden on recurrent hidden units. In this work we train the NPI with fully-supervised execution traces; each program has example sequences of calls to the immediate subprograms conditioned on the input. Rather than training on a huge number of relatively weak labels, NPI learns from a small number of rich examples. We demonstrate the capability of our model to learn several types of compositional programs: addition, sorting, and canonicalizing 3D models. Furthermore, a single NPI learns to execute these programs and all 21 associated subprograms.}
}
@article{AmosetalCoRR-18,
author = {Brandon Amos and Laurent Dinh and Serkan Cabi and Thomas Roth{\"{o}}rl and Sergio Gomez Colmenarejo and Alistair Muldal and Tom Erez and Yuval Tassa and Nando de Freitas and Misha Denil},
title = {Learning Awareness Models},
journal = {CoRR},
volume = {arXiv:1804.06318},
year = {2018},
abstract = {We consider the setting of an agent with a fixed body interacting with an unknown and uncertain external world. We show that models trained to predict proprioceptive information about the agent's body come to represent objects in the external world. In spite of being trained with only internally available signals, these dynamic body models come to represent external objects through the necessity of predicting their effects on the agent's own body. That is, the model learns holistic persistent representations of objects in the world, even though the only training signals are body signals. Our dynamics model is able to successfully predict distributions over 132 sensor readings over 100 steps into the future and we demonstrate that even when the body is no longer in contact with an object, the latent variables of the dynamics model continue to represent its shape. We show that active data collection by maximizing the entropy of predictions about the body---touch sensors, proprioception and vestibular information---leads to learning of dynamic models that show superior performance when used for control. We also collect data from a real robotic hand and show that the same models can be used to answer questions about properties of objects in the real world. Videos with qualitative results of our models are available at this {\urlh{https://goo.gl/mZuqAV}{URL}}.}
}
@article{HudsonandManningICLR-18,
author = {Drew A. Hudson and Christopher D. Manning},
title = {Compositional Attention Networks for Machine Reasoning},
journal = {CoRR},
comment = {Published as a conference paper at ICLR 2018},
volume = {arXiv:1803.03067},
year = {2018},
abstract = {We present the MAC network, a novel fully differentiable neural network architecture, designed to facilitate explicit and expressive reasoning. MAC moves away from monolithic black-box neural architectures towards a design that encourages both transparency and versatility. The model approaches problems by decomposing them into a series of attention-based reasoning steps, each performed by a novel recurrent Memory, Attention, and Composition (MAC) cell that maintains a separation between control and memory. By stringing the cells together and imposing structural constraints that regulate their interaction, MAC effectively learns to perform iterative reasoning processes that are directly inferred from the data in an end-to-end approach. We demonstrate the model's strength, robustness and interpretability on the challenging CLEVR dataset for visual reasoning, achieving a new state-of-the-art 98.9\% accuracy, halving the error rate of the previous best model. More importantly, we show that the model is computationally-efficient and data-efficient, in particular requiring 5x less data than existing models to achieve strong results.}
}
8 Here is a list of papers relating to analogical reasoning, physical inference and abstract families of relational models of that characterize different environments and their role in supporting imagination, prediction and action selection:
Hill et al [183] — Analogy is challenging because it requires relational structures to be represented so they can be flexibly applied across diverse domains of experience. [The] critical factor for inducing such a capacity is not an elaborate architecture, but rather, careful attention to the choice of data and the manner in which it is presented to the model. The most robust capacity for analogical reasoning is induced when networks learn analogies by contrasting abstract relational structures in their input domains, a training method that uses only the input data to force models to learn about important abstract features.
Chang et al [66] — As a first step for tackling compositional generalization, we introduce the compositional recursive learner, a domain-general framework for learning algorithmic procedures for composing representation transformations, producing a learner that reasons about what computation to execute by making analogies to previously seen problems.
Alon et al [10] — We show that code vectors trained on this dataset can predict method names from files that were completely unobserved during training. Furthermore, we show that our model learns useful method name vectors that capture semantic similarities, combinations, and analogies.
Higgins et al [182] — Learning Hierarchical Compositional Visual Concepts ... The seemingly infinite diversity of the natural world arises from a relatively small set of coherent rules, such as the laws of physics or chemistry. We conjecture that these rules give rise to regularities that can be discovered through primarily unsupervised experiences and represented as abstract concepts. If such representations are compositional and hierarchical, they can be recombined into an exponentially large set of new concepts.
Repetto [312] — Our brains have a capacity which artificial neural networks still lack: we can form analogies, relating disparate inputs and processing them using the same heuristic. The official lingo is 'transfer learning'. Fundamentally, analogies are a form of compression, allowing out brains to simulate the dynamics of many different systems with minimal space devoted to each subsystem. Where two systems behave similarly, a single analogy describes them both.
Ha and Schmidhuber [167] — We explore building generative neural network models of popular reinforcement learning environments. Our world model can be trained quickly in an unsupervised manner to learn a compressed spatial and temporal representation of the environment. By using features extracted from the world model as inputs to an agent, we can train a very compact and simple policy that can solve the required task. We can even train our agent entirely inside of its own hallucinated dream generated by its world model, and transfer this policy back into the actual environment.
Ferran et al [4] — Many prediction problems, such as those that arise in the context of robotics, have a simplifying underlying structure that, if known, could accelerate learning. In this paper, we present a strategy for learning a set of neural network modules that can be combined in different ways. We train different modular structures on a set of related tasks and generalize to new tasks by composing the learned modules in new ways.
Raposo et al [308] — A model of structure learning, inference, and generation for scene understanding ... co-occurrences among entities, and covariance among their discrete and continuous features ... The seemingly infinite diversity of the natural world arises from a relatively small set of coherent rules, such as the laws of physics or chemistry. We conjecture that these rules give rise to regularities that can be discovered through primarily unsupervised experiences and represented as abstract concepts. If such representations are compositional and hierarchical, they can be recombined into an exponentially large set of new concepts.
Foster and Jones [131] — Research in analogical reasoning suggests that higher-order cognitive functions such as abstract reasoning, transfer learning, and creativity are founded on recognizing structural similarities among relational systems. Here we integrate [...] analogical infernce within the computational framework of reinforcement learning (RL). We propose a [...] synergy between analogy and RL, in which analogical comparison provides the RL learning algorithm with a measure of relational similarity, and RL provides feedback signals that can drive analogical learning.
Hassabis et al [173] — Neuroscience-Inspired Artificial Intelligence ... understanding biological brains could play a vital role in building intelligent machines ... What we are interested in is a systems neuroscience-level understanding of the brain, namely the algorithms, architectures, functions, and representations it utilizes. This roughly corresponds to the top two levels of the three levels of analysis that Marr famously stated are required to understand any complex biological system [255]: the goals of the system (the computational level) and the process and computa- tions that realize this goal (the algorithmic level).
Lampinen et al [228] — When a neural network is trained on multiple analogous tasks, previous research has shown that it will often generate representations that reflect the analogy. This may explain the value of multi-task training, and also may underlie the power of human analogical reasoning — awareness of analogies may emerge naturally from gradient-based learning in neural networks. We explore this issue by generalizing linear analysis techniques to explore two sets of analogous tasks, show that analogical structure is commonly extracted, and address some potential implications.
Fischer et al [126] — Functional neuroanatomy of intuitive physical inference ... we identified a set of cortical regions that are selectively engaged when people watch and predict the unfolding of physical events. [...] These brain regions are not exclusively engaged in physical inferences per se or, indeed, even in scene understanding; they overlap with the domain-general "multiple demand" system, especially the parts of that system involved in action planning and tool use, pointing to a close relationship between the cognitive and neural mechanisms involved in parsing the physical content of a scene and preparing an appropriate action.
Maguire et al [247] — Analogical reasoning consists of multiple phases. Four-term analogies (A:B::C:D) have an encoding period in which the A:B pair is evaluated prior to a mapping phase. The electrophysiological timing associated with analogical reasoning has remained unclear. We used event-related potentials to identify neural timing related to analogical reasoning relative to perceptual and semantic control conditions.
Hassabis and Maguire [174] — Deconstructing episodic memory with construction ... It has recently been observed that the brain network supporting recall of episodic memories shares much in common with other cognitive functions such as episodic future thinking, navigation and theory of mind. We note that other functions (imagination) not explicitly connected to either the self or subjective sense of time activate a similar brain network. Hence, we argue that the process of 'scene construction' is better able to account for the commonalities in the brain areas engaged by an extended range of disparate funtions.
Hofstadter [188] — Analogy [...] is conceived of by psychologists and cognitive scientists as some kind of advanced [reasoning]. I [hypothesize] that every concept in our mental repertoire comes from a large set of unconsciously made analogies stretching back to childhood, and hence analogy-making is at the core of human thought. This view of analogy has very little to do with reasoning in any standard sense of the term. Moreover, I argue that the sequential process of thinking is driven at all times by unconscious analogy-making carried out simultaneously at various levels of abstraction.
9 Carlos Perez notes that "Hofstadter argues that the more common knowledge-structuring mechanism known as categorization (or classification) is the same as the generation of analogies [which are essentially] relationships between concepts [and] thought is about analogy-making" — excerpted from [299].
10 Anthony Repetto characterizes analogies in terms of "relating disparate inputs and processing them using the same heuristic". He understands analogies "as a form of compression, allowing the brain to simulate the dynamics of many different systems" by allocating minimal resources to each system such that if two systems behave similarly, a single analogy can be used to describe both" — excerpted from [312].
11 A common or multiple-demand (MD) pattern of frontal and parietal activity is associated with diverse cognitive demands, and with standard tests of fluid intelligence. In intelligent behaviour, goals are achieved by assembling a series of sub-tasks, creating structured mental pro- grams. Single cell and functional magnetic resonance imaging (fMRI) data indicate a key role for MD cortex in defining and controlling the parts of such programs, with focus on the specific content of a current cognitive operation, rapid reorganization as mental focus is changed, and robust separation of successive task steps. Resembling the structured problem-solving of symbolic artificial intelligence, the mental programs of MD cortex appear central to intelligent thought and action. (SOURCE)
13 This is how Jack Gallant, one of the leaders in the field of fMRI, thinks of the problem:
In principle, you can decode any kind of thought that is occurring in the brain at any point in time…. you can think about this like writing a dictionary. If you were, say, an anthropologist, and you went to a new island where people spoke a language that you had never heard before, you might slowly create a dictionary by pointing at a tree and saying the word "tree," and then the person in the other language would say what that tree was in their language, and over time you could build up a sort of a dictionary to translate between your language and this other foreign language. And we essentially play the same game in neuroscience. See Poldrack [302] for the context of this quote and an interesting discussion of related issues.
12 Francisco de Sousa Webber made an interesting comment in his conversation with Paul Middlebrooks of Brain Inspired. Francisco said something to the effect that if we could directly exchange thoughts then certainly natural selection would have exploited this capability as a means for humans to communicate with one another. Instead it invented language as a means by which one human might encode his or her internal representation of a given thought in an intermediate spoken code / language that all humans share, and another human might then decode the spoken message into his or her internal representation of thoughts. In a superficial sense, this statement is obvious, in another sense it is profound and serves as a technically useful framework for thinking about thinking. Some scientists [302] have gone so far as to suggest that human's share a circuit-level organization that would facilitate direct brain-to-brain thought transfer13. While perhaps true in principle, I expect the necessary technology is decades away from having any chance of succeeding. That said, it is worth thinking more carefully about what are the challenges and what this says about the organization of the human brain. If nothing else, this exercise should inform the development of more sophisticated text-based interfaces.
14 Inner speech is a form of internalized, self-directed dialogue: talking to oneself in silence. The phrase inner speech was used by Russian psychologist Lev Vygotsky to describe a stage in language acquisition and the process of thought. In Vygotsky's conception, "speech began as a social medium and became internalized as inner speech, that is, verbalized thought" — see Nelson [2, 275, 276]. As mentioned elsewhere in the class notes, it is very likely that animals other than humans have a sense of self and engage in such recurrent strange loops [189] without the benefit of an expressive, easily-shared symbolic representation of their thoughts. Having a rich symbolic, serialized representation in which to embed our thoughts may very well be one of the most important enabling conditions for complex thought.
15 In this interview with Máté Lengyel on his approach to probabilistic perception and learning, Lengel explains the relationship between how the brain represents uncertainty at 00:50:00 in the video. The whole podcast is interesting, but this segment provides a clear and succinct explanation. It is a simple matter to map his interpretation of how probabilities are encoded in patterns of neural activity onto a recurrent-neural-network-based encoder-decoder model in which decoding requires search / sampling in the space of possible decodings.
16 Goal-directed behavior in which decisions are made on the basis of the expected value of achieving particular outcomes is a key characteristic of human reasoning and there is interest in understanding its neural basis [53, 55]. Reasoning about language as an example of hierarchical goal-based planning has a long history in natural language processing, e.g., plan recognition, dialogue management, language generation and recovering [234, 27, 47, 143, 46]. It isn't that far fetched to imagine that von Neumann's design for the EDVAC was based on his introspective account of how his brain solved problems [281] PDF.
17 There appears to be a natural progression of milestones that children progress through in learning how to speak and understand language. Ignoring those involved with vocalization, the stages of development roughly follow the compositionality of linguistic forms and the complexity of semantic concepts, starting with basic ontology (entities), reference (indices, icons, symbols), n-arry relationships (social, spatial, dynamical), propositions (enhanced repertoire of statements that are true of false), speech acts (enhanced repertoire of interpersonal communicative verbalizations), narratives (complex, multiple-statement procedural and declarative accounts). See earlier comments concerning how we might bootstrap this process.
18 Here is a recent Edge conversation with Andy Clark on prediction, controlled hallucination and the nature of embodiment:
Perception itself is a kind of controlled hallucination. . . . [T]he sensory information here acts as feedback on your expectations. It allows you to often correct them and to refine them. But the heavy lifting seems to be being done by the expectations. Does that mean that perception is a controlled hallucination? I sometimes think it would be good to flip that and just think that hallucination is a kind of uncontrolled perception.Andy Clark is professor of Cognitive Philosophy at the University of Sussex and author of Surfing Uncertainty: Prediction, Action, and the Embodied Mind. Andy Clark's Edge Bio Page
Perception as Controlled Hallucination: Predictive Processing and the Nature of Conscious Experience
The big question that I keep asking myself at the moment is whether it's possible that predictive processing, the vision of the predictive mind I've been working on lately, is as good as it seems to be. It keeps me awake a little bit at night wondering whether anything could touch so many bases as this story seems to. It looks to me as if it provides a way of moving towards a third generation of artificial intelligence. I'll come back to that in a minute. It also looks to me as if it shows how the stuff that I've been interested in for so long, in terms of the extended mind and embodied cognition, can be both true and scientifically tractable, and how we can get something like a quantifiable grip on how neural processing weaves together with bodily processing weaves together with actions out there in the world. It also looks as if this might give us a grip on the nature of conscious experience. And if any theory were able to do all of those things, it would certainly be worth taking seriously. I lie awake wondering whether any theory could be so good as to be doing all these things at once, but that's what we'll be talking about.
A place to start that was fun to read and watch was the debate between Dan Dennett and Dave Chalmers about "Possible Minds" ("Is Superintelligence Impossible?" Edge, 4.10.19). That debate was structured around questions about superintelligence, the future of artificial intelligence, whether or not some of our devices or machines are going to outrun human intelligence and perhaps in either good or bad ways become alien intelligences that cohabit the earth with us. That debate hit on all kinds of important aspects of that space, but it seemed to leave out what looks to be the thing that predictive processing is most able to shed light on, which is the role of action in all of these unfoldings.
There's something rather passive about the kinds of artificial intelligence that Dan and Dave were both talking about. They were talking about intelligences or artificial intelligences that were trained on an objective function. The AI would try to do a particular thing for which they might be exposed to an awful lot of data in trying to come up with ways to do this thing. But at the same time, they didn't seem to inhabit bodies or inhabit worlds; they were solutions to problems in a disembodied, disworlded space. The nature of intelligence looks very different when we think of it as a rolling process that is embedded in bodies or embedded in worlds. Processes like that give rise to real understandings of a structured world.
Something that I thought was perhaps missing from the debate was a full emphasis on the importance, first of all, of having a general-purpose objective function. Rather than setting out to be a good Go player or a good chess player, you might set out to do something like minimize expected prediction error in your embodied encounters with the world. That's my favorite general objective function. It turns out that an objective function like that can support perception and action and the kind of epistemic action in which we progressively try to get better training data, better information, to solve problems for the world that we inhabit.
Predictive processing starts off as a story about perception, and it's worth saying a few words about what it looks like in the perceptual domain before bringing it into the domain of action. In the perceptual domain, the idea, familiar I'm sure to everybody, is that our perceptual world is a construct that emerges at the intersection between sensory information and priors, which here act as top-down predictions about how the sensory information is likely to be. For example, I imagine that most people have experienced phantom phone vibrations, where you suddenly feel your phone is vibrating in your pocket. It turns out that it may not even be in your pocket. Even if it is in your pocket, maybe it's not vibrating. If you constantly carry the phone, and perhaps you're in a slightly anxious state, a heightened interoceptive state, then ordinary bodily noise can be interpreted as signifying the presence of a ringing phone.
It would work very much like, say, the hollow mask illusion: When people are shown a hollow face mask lit from behind, they see the concave side of the face as having a nose pointing outwards. Richard Gregory spoke about this many years ago. It's a standard story in this area. We human beings have very strong expectations about faces. We very much expect, given a certain bit of face information, that the rest of that information will specify a convex, outward-looking face.
The very same story gets to grips with phantom phone vibrations. It explains the White Christmas experiments, which is certainly one of my favorites in this area. People were told that they would hear the faint onset of Bing Crosby singing White Christmas in a sound file that they were going to be played. They would listen to the sound file and a substantial number of participants detected the faint onset of Bing Crosby singing White Christmas, but in fact there was no faint onset of White Christmas. There was no Bing Crosby signal there at all amongst what was simply white noise. In these cases, our expectations are carving out a signal that isn't there. But in other cases, perhaps someone speaks your name faintly and there's a noisy cocktail party going on, your expectations about what your name sounds like and the importance of anything that vaguely signals what your name sounds like conspire to up the weighting of the bits of the noisy signal that are there so that you hear your name fairly clearly.
The Bayesian brain, predictive processing, hierarchical predictive coding are all, roughly speaking, names for the same picture in which experience is constructed at the shifting borderline between sensory evidence and top-down prediction or expectation. There's been a big literature out there on the perceptual side of things. Same thing if you're in the shower and a familiar song comes on the radio. Under those conditions, a familiar song sounds an awful lot clearer than an unfamiliar one. People might have thought that was a post-perceptual effect, as if you heard something fuzzy and then your memory filled in the details. But if the predictive processing stories are right, then that's the wrong way to think about it. This is just the same old story where top-down expectation meets incoming sensory signals with a balance that is determined by how confident you are in either the sensory signals or your top-down predictions.
The Bayesian brain, predictive processing, hierarchical predictive coding are all, roughly speaking, names for the same picture in which experience is constructed at the shifting borderline between sensory evidence and top-down prediction or expectation. There's been a big literature out there on the perceptual side of things. It's a fairly solid literature. What predictive processing did that I found particularly interesting—and this is mostly down to a move that was made by Karl Friston—was apply the same story to action. In action, what we're doing is making a certain set of predictions about the shape of the sensory information that would result if I were to perform the action. Then you get rid of prediction errors relative to that predicted flow by making the action.
There are two ways to get your predictions to be right in these stories. One is to have the right model of the world and the other is to change how the world is to fit the model that you have. Action is changing how the world is to fit the predictions, and perception is more like finding the predictions that make most sense of how the world is. But it turns out that they're operating using the same basic neural architecture. The wiring diagram for motor cortex and the wiring diagram for sensory cortex look surprisingly similar, and this story helps explain why. Indeed, the same basic canonical computations would be involved in both.
What's most interesting about predictive processing is the way it gives you a simultaneous handle on perception and action by showing they obey the same computational principles. It immediately invites you to think about having a model of the world that simultaneously drives how you experience and harvest information from the world. At that point, there's a standing invitation to stories like embodied cognition and the extended mind.
Once the predictive brain story is extended to the control of action in this very natural way, then there's a standing invitation to start thinking about how we weave worldly opportunities and bodily opportunities together with what brains are doing in a way that is going to make systematic sense of the extended mind story.
Before I go there, it's also worth saying a word or two about where the models that drive the predictions get to come from. Perceptual experience is the construct that lives on the border between sensory evidence and top-down prediction or expectation. That's what you're seeing in the White Christmas case and in the phantom phone vibration case. Just to see a structured world of objects around me means to know a lot about structured worlds of objects, and to bring those expectations to bear on the sensory signal. These are the stories that bring a structured world into view quite generally.
There are some rather nice cases that you can find online if you haven't already of so-called sine-wave speech cases, where speech gets stripped of some of its natural dynamics and what's left is a skeletal version of the speech. When you first hear it, it just sounds like a series of beeps and whistles, then when you hear the actual sound file and play that again, it sounds like a clear sentence being spoken because now you have the right top-down model, the right expectations. It's like hearing a familiar song when it's played in the shower on a bad radio receiver. It's a very striking effect and experience. It gives you a real sense of what is happening when a predictive brain gets to grips with the flow of sensory information.
Once you've played the real sentence, it might be something like, "The cat sat on the mat." So, you first hear beeps and whistles and you hear the sentence. Then you hear the beeps and whistles again, but this time through those beeps and whistles most people will clearly hear the sentence. After a while, you can become a native speaker of sine-wave speech so that you could be played a brand new one and you would hear the sentence through the noise. So maybe it will be useful to play some examples. Here we go.
[Audio samples. Begin listening at: 13:00]
I hope you've now had the experience of bringing a stream of somewhat unruly sensory information under an active predictive model and hearing how that can bring a structured world of words into view. The very same thing is happening in visual perception. It's the same effect that we were seeing in the White Christmas story, where your expectations are so strong that they make you think that there's a signal there when there isn't. But if predictive processing and stories of this kind are on track, then these are all exercises of the same constructive computational story. This is where human experience lives. As a philosopher, it sometimes interests me to wonder where this leaves the notion of veridical perception.
Perception itself is a kind of controlled hallucination. You experience a structured world because you expect a structured world, and the sensory information here acts as feedback on your expectations. It allows you to often correct them and to refine them. But the heavy lifting seems to be being done by the expectations. Does that mean that perception is a controlled hallucination? I sometimes think it would be good to flip that and just think that hallucination is a kind of uncontrolled perception.
The basic operating principle here is that you have a rich model of the world, a generative model, as it's known in this literature. What that means is a model that is not a discriminative model which just separates patterns out and says, "This is a cat and this is a dog," but rather a system that, using what it knows about the world, creates patterns that would be cat-like patterns or dog-like patterns in the sensoria. These systems learn to imagine how the sensory world would be, and in learning to imagine how the sensory world would be, they use that to do the classification and recognition work that otherwise would be done by an ordinary feed-forward discriminator. What that's doing is making perception and imagination and understanding come very close together. They're a cognitive package deal here, because if you perceive the world in this way, then you have the resources to create virtual sensory stuff like that from the top down.
Systems that can perceive the world like this can imagine the world, too, in a certain sense. That grip on the world seems to be very close to understanding the world. If I know how the sensory signal is going to behave at many different levels of abstraction and at many scales of space and time, so I can take the scene as it currently is and project it into the future and know what's going to happen if you hit the can and so on, that way of perceiving the world seems to me to be a way of understanding the world.
It will be very reasonable to ask where the knowledge comes from that drives the generative model in these cases. One of the cool things is that learning here proceeds in exactly the same way as perception itself. Moment by moment, a multilevel neural architecture is trying to predict the sensory flow. In order to do better at predicting the sensory flow, it needs to pull out regular structures within that flow at different time scales, so-called hidden causes or latent variables. Over time, with a powerful enough system, I might pull out things like tables and chairs and cats and dogs. You can learn to do that just by trying to predict the sensory flow itself.
A nice simple case of that will be something like learning the grammar of a language. If you knew the grammar of a language, that would be helpful in predicting what word is coming next. One way that you can learn the grammar of a language is to try again and again to predict what word is coming next. Pull out the latent variables and structure that is necessary to do that prediction task, and then you've acquired the model that you can use to do the prediction task in the future. These stories are a standing invitation to this bootstrapping where the prediction task that underlies perception and action itself installs the models that are used in the prediction task.
There's a pleasing symmetry there. Once you've got action on the table in these stories—the idea is that we bring action about by predicting sensory flows that are non actual and then getting rid of prediction errors relative to those sensory flows by bringing the action about—that means that epistemic action, as it's sometimes called, is right there on the table. Systems like that cannot just act in the world to fulfill their goals; they can also act in the world so as to get better information to fulfill their goals. And that's something that active animals do all the time. The chicken, when it bobs its head around, is moving its sensors around to get information that allows it to do depth perception that it can't do unless it bobs its head around. When you go into a darkened room and you flip the light switch, you're performing a kind of epistemic action because your goal wasn't specifically to hit the light switch; it was to do something in the room. But you perform this action that then improves your state of information so you can do the thing you need to do. Epistemic action, and practical action, and perception, and understanding are now all rolled together in this nice package.
It's interesting then to ask, if your models are playing such a big role in how you perceive and experience the world, what does it mean to perceive and experience the world as it is? Basically, what these stories do is ask you to think again about that question. Take the sine-wave speech example and ask yourself when you heard what was really there. Did you hear what was there when you heard it just as beeps and burps? Or did you hear what was there when you heard the sentence through the beeps and buzzes? I don't think there's a good answer to that question. If predictive processing is on track though, one thing we can say is that even to hear it as beeps buzzes is to bring some kind of model to bear, just one that didn't reach as deeply into the external causal structure as the one that actually does have words in it.
An upshot here is that there's no experience without the application of some model to try to sift what is worthwhile for a creature like you in the signal and what isn't worthwhile for a creature like you. And because that's what we're doing all the time, it's no wonder that certain things like placebo effects, medically unexplained symptoms, phantom phone vibrations, all begin to fall into place as expressions of the fundamental way that we're working when we construct perceptual experience. In the case of medically unexplained symptoms, for example, where people might have blindness or paralysis with no medically known cause, or more than that, very often the symptoms here will have a shape that in principle can't have a simple physiological cause.
A nice example is you might get someone with a blind spot in their field of vision. If you ask them what the width of that blind spot is when it is mapped close to the eye and when it's mapped far from the eye, some people will have what's called tubular visual field defect, which means they say it's the same wherever it's mapped. This is optically, physiologically impossible. It's pretty clear in cases like that that what's doing the work is something like belief expectation prediction. It's their model of what it would be like to have a visual field defect that is doing the work.
In this broad sense of beliefs, it doesn't mean beliefs that you necessarily hold as a person, but somehow they got in there somehow. These multilevel systems harbor all kinds of predictions and beliefs which the agent themselves might even disavow. Honest placebos do work. For example, if someone is told that this pill is an inert substance, you can nonetheless get symptomatic relief from those substances as long as they're presented by people in white coats with the right packaging—mid levels of expectation are engaged regardless of what you, the person sitting at the top, thinks. In the case of medically unexplained symptoms, it looks like they're the physiological version of the White Christmas effect. There are bodily signals there, and if your expectations about the shape of those signals are strong enough, then you can bring about the experiences that those expectations describe, just like White Christmas only done here in this somatosensory domain.
There's interesting work emerging not just on medically unexplained symptoms, but even medically explained symptoms. If people live with a medically explained problem for long enough, they can build up all kinds of expectations about the shape of their own symptomology, which share a lot in common with the medically unexplained cases. The same person with a chronic condition on different days and in different contexts will have different experiences even if the physiological state, the bedrock state, seems to be exactly the same.
There's quite a lot to say about how that should pan out. In some ways, my view is an illusionist view. A large part of this debate over consciousness is misguided because there's nothing there. There's a multidimensional matrix of real things, and among those real things, there's a tendency to think there's another thing and that other thing isn't real. That's one way of thinking about it. There's a nice paper that came out recently by Van den Bergh and colleagues which was arguing that in the case of chronic effects, chronic pain, for example, an awful lot of ordinary symptomology has very much the character of the symptomology in the medically unexplained cases. So, it puts neuro-typical and less typical cases on a continuum and on par, which is quite interesting.
Acute cases are somewhat different because there you haven't built up those regimes of expectation, and there's a very straight signal being dealt with. Although, even there it seems as if your long-term model of the world makes a big difference as to how that signal plays out. There's a large area here where work on placebo effects, medically unexplained symptoms, autism, the effects of psychedelics, schizophrenia, all of these things are being thought about under this general framework. Maybe this'll be one of the test cases for whether we make progress using these tools with understanding the nature of human consciousness.
We had a visit from Robin Carhart-Harris, who works on psychedelics and is now working on predictive coding. There are some very interesting ideas coming out there, I thought. In particular, the idea that what serotonergic psychedelics do is relax the influence of top-down beliefs and top-down expectations so that sensory information can find new channels. If we think about this in the context of people with depression, maybe part of what goes on there is that we hold this structured world in view, in part by our expectations—and they're not just about the world, they're also about ourselves—and if you can relax some of those expectations and experience a way of encountering the world where you don't model yourself as a depressive person, for example, even a brief experience like that can apparently have long-term, lasting effects.
Some of the Bayesian brain and predictive processing folks are doing some pretty cool things, looking at the action of psychedelics and the effects of sensory deprivation. For any of these things, you can ask how would those different balances—held in place by this prediction meets sensory information construct—play out under different regimes of neurotransmitters, for example, or under different environmental regimes where you might have a stroboscopic light being flashed at you very rapidly. The University of Sussex has one of these, and it creates surprisingly intense sensations. If you were to sit in it for a couple of hours, you might get full dissociation. Even for a few minutes, you get experiences of colors of an intensity that I've never experienced before.
If you begin to ask what these stories have to say, if anything, about the nature of human consciousness, there are several things to say. The first is that the basic construction of experience is already illuminated just by thinking in terms of this mixture of top-down expectations and bottom-up sensory evidence and the way that mixture gets varied in different contexts and by different interventions. At the same time, there's a strong intuition some people have that consciousness is special and that whatever tools I was using to make progress with the White Christmas experiments and phantom phone vibrations are not getting to grips yet with what matters most about consciousness, which is how it feels, the redness of the sunset, the taste of the Tequila, and so on.
There's quite a lot to say about how that should pan out. In some ways, my view is an illusionist view. A large part of this debate over consciousness is misguided because there's nothing there. There's a multidimensional matrix of real things, and among those real things, there's a tendency to think there's another thing and that other thing isn't real. That's one way of thinking about it.
Among the real dimensions are the perceptual dimension that we've spoken about, the dimension of acting to engage our world. There's a lot of super interesting work on the role of interoceptive signals in all of this. Apart from the exteroceptive signals that we take in from vision, sound, and so on, and apart from the proprioceptive signals from our body that are what we predict in order to move our body around, there's also all of the interoceptive signals that are coming from the heart and from the viscera, et cetera.
One of the effects of the general predictive processing story is that all of this is just sensory evidence thrown in a big pot. How I perceive the external world to be can be constantly inflected by how I'm perceiving my internal world to be. You see this, for example, in experiments where people are given false cardiac feedback. They're made to think that their hearts are beating faster than they are. And under conditions like that, if they're exposed to a neutral face, they're more likely to judge that the face is anxious or fearful or angry. It looks as if what's going on is that our constant intouchness with signals from our own body, our brains are taking as just more information about how things are.
In that sense, there's a Jamesian flavor to some of the work on experience that comes out of predictive processing where the idea is that emotion, for example, is very much tied up with the role that interoception plays in giving us a grip on how things are in the world. William James famously said that the fear we feel when we see the bear has a lot to do with the experience of our own heart beating and our preparations to flee, all of that bodily stuff. If you took all that away, perhaps the feeling of fear would be bereft of its real substance.
I can reduce prediction error by projecting myself into the future and asking what certain things a creature like me—the way I can see myself to be—might do, would serve to reduce prediction error in the future. In that way, I turn up as a latent variable in my own model of the world. That seems important in human consciousness, at least. That's part of what makes us distinguishable selves with goals and projects that we can reflect on. . . . The thing that I don't think is real is qualia. There is something genuine in there that being subtly inflected by interoception information is part of what makes our conscious experience of the world the kind of experience that it is. So, artificial systems without interoception could perceive their world in an exteroceptive way, they could act in their world, but they would be lacking what seems to me to be one important dimension of what it is to be a conscious human being in the world.
To understand that, we need to take a more illusionist stance. To do that would be to ask some version of what Dave Chalmers has lately called the meta hard puzzle or the meta hard question. That would be, what is it about systems like us that explains why we think that there are hard puzzles of consciousness, why we think that the conscious mind might be something very distinct from the rest of the physical order, why we think there are genuine questions to be asked about zombies. We've got a number of real dimensions to consciousness. One of them is bringing a structured world into view in perception in part by structured expectations. The other one is an inflection of all of that by interoception. You can then ask questions about the temporal depth of the model that you're bringing to bear, and that seems like an important dimension, too. If your model has enough depth and temporal depth, then you can turn up in your own model of the world. Technically here I can reduce prediction error by projecting myself into the future and asking what certain things a creature like me—the way I can see myself to be—might do, would serve to reduce prediction error in the future. In that way, I turn up as a latent variable in my own model of the world. That seems important in human consciousness, at least. That's part of what makes us distinguishable selves with goals and projects that we can reflect on. That matrix is real. The thing that I don't think is real is qualia.
To understand that, we need to take a more illusionist stance. To do that would be to ask some version of what Dave Chalmers has lately called the meta hard puzzle or the meta hard question. That would be, what is it about systems like us that explains why we think that there are hard puzzles of consciousness, why we think that the conscious mind might be something very distinct from the rest of the physical order, why we think there are genuine questions to be asked about zombies. What Chalmers thinks is that any solution to the meta hard question, the question of why we think there's a hard question, why we say and do the things that express apparent puzzlement of this kind—those are easy questions in Dave's sense.
You can say something about how you would build a robot that might get puzzled or appear to be puzzled about its own experience in those ways.
You might think, well there's something very solid about all this perceptual stuff. I can be highly confident of it, and yet how the world really is could be very varied. If you're the sort of robot that can start to do those acrobatics, you're the sort of robot that might invent a hard problem, and might begin to think that there's more than a grain of truth in dualism.
One thing that we might like to do is try to take an illusionist stance to just that particular bit of the hard problem while being realist about all the other stuff, thinking that there's something to say about the role of the body, something to say about what it takes to bring a structured world into view. Do all of that stuff and then also solve the meta hard puzzle, and you've solved all there is to solve. Whereas Dave Chalmers, I'm sure, will say, at that point, you showing us how to build a robot that will fool us into thinking that it's conscious, in certain sense it might even fool itself into thinking that it's conscious, but it wouldn't really because maybe it wouldn't have any experiences at all when it's doing all that stuff.
What Dan has argued there is that maybe we get puzzled because we're fooled by our own Bayesianism here. This model of how things are gets to grips with how we're going to respond, and we then reify something within that nexus as these intervening qualia. But you don't need the weird intervening qualia; you just have responses that come about in certain circumstances. There's a rather natural fit between Dan's approach and these approaches, and they're both a kind of illusionism where we're both saying whatever consciousness really is, it can't be what Dave Chalmers thinks it is.
Dan Dennett's take on consciousness is a perfect fit with a predictive processing take on consciousness. For many years, Dan has argued that there's something illusory here, some self-spun narrative illusion. Predictive processing perhaps gives us a little bit more of the mechanism that might support the emergence of an illusion like that. Dan himself has written some interesting stuff on the way that predicting our own embodied responses to things might lead us down the track of thinking that qualia are fundamental special goings on inside us. I might predict some of my own ooing and awing responses to the cute baby, and when I find myself in the presence of the cute baby, I make those responses and I think that cuteness is a real genuine property of some things in the world.
What Dan has argued there is that maybe we get puzzled because we're fooled by our own Bayesianism here. This model of how things are gets to grips with how we're going to respond, and we then reify something within that nexus as these intervening qualia. But you don't need the weird intervening qualia; you just have responses that come about in certain circumstances. There's a rather natural fit between Dan's approach and these approaches, and they're both a kind of illusionism where we're both saying whatever consciousness really is, it can't be what Dave Chalmers thinks it is.
19 In their introduction to the special issue of Cognition on the role of high-level cognitive function in the prefrontal cortex and reinforcement learning, Daw and Frank [80] summarize the work of Reynolds and O'Reilly [313] as follows:
Reynolds and O'Reilly [313] study a related problem of hierarchy in RL — representing the levels of contingent rules for determining a response — using quite a different methodology. These authors use large-scale neural network models simulating interactions between prefrontal cortex, basal ganglia and dopaminergic systems. Here, among the actions selected by the basal ganglia, which are acquired via RL, are those controlling whether or not to update prefrontal working memory states [290]. The tasks used in this domain are typically designed such that the behavioral relevance of stimuli depends on those that had appeared previously, and thus working memory updating should depend contingently on prior working memory context. Reynolds and O'Reilly show that multiple interacting BG-PFC circuits may be arranged hierarchically such that more anterior PFC regions come to represent more abstract (hierarchical) structure (e.g., Badre, 2008), and that further, the degree to which this segregation occurs facilitates learning.The working memory contexts envisioned by Reynolds and O'Reilly also address another central problem of simple RL: how these mechanisms determine the "state" relevant to action choice. Gureckis and Love (2009) are among the first to examine this issue directly by manipulating the state information available to subjects and studying how this affects RL. In particular, they study the behavior of subjects performing a set of choice tasks which are identical in the underlying action-reward contingencies but differ in terms of the cues signaling the current state of the game. Using computational modeling, they demonstrate that the vast changes in subjects' learning between conditions can be understood in terms of an RL model that adopts different internal state representations according to the provided cues. Excerpt from Daw and Frank [80].
20 Hauskrecht et al [176] approached hierarchical planning in terms of combining abstract actions and primitives — related to Leslie Kaelbling's hierarchical decomposition [210] extension of the Q-learning [391, 30]:
We investigate the use of temporally abstract actions, or macro-actions, in the solution of Markov decision processes. Unlike current models that combine both primitive actions and macro-actions and leave the state space unchanged, we propose a hierarchical model (using an abstract MDP) that works with macro-actions only, and that significantly reduces the size of the state space. This is achieved by treating macro-actions as local policies that act in certain regions of state space, and by restricting states in the abstract MDP to those at the boundaries of regions. The abstract MDP approximates the original and can be solved more efficiently. We discuss several ways in which macro-actions can be generated to ensure good solution quality. Finally, we consider ways in which macro-actions can be reused to solve multiple, related MDPs; and we show that this can justify the computational overhead of macro-action generation. Excerpt from Hauskrecht et al [176].
21 Here is an excerpt from Stanislas Dehaene's Consciousness and the Brain: Deciphering How the Brain Codes Our Thoughts found in Chapter 5 in the section entitled "The Shape of Thought" in which he describes the emergence of a conscious thought [95]. This excerpt introduces the P3 wave — a special case of an event-related potential discussed later in the text [357]. I encourage you to read the entire book as it is full of useful insights for neuroscientists and cognitive scientists primarily interested in understanding the human brain but also computer scientists interested in developing computer models that derive inspiration from biological systems:
Cell assemblies, a pandemonium, competing coalitions, attractors, convergence zones with reentry ... each of these hypotheses seems to hold a grain of truth, and my own theory of a global neuronal workspace draws heavily from them. It proposes that a conscious state is encoded by the stable activation, for a few tenths of a second, of a subset of active workspace neurons. These neurons are distributed in many brain areas, and they all code for different facets of the same mental representation. Becoming aware of the Mona Lisa involves the joint activation of millions of neurons that care about objects, fragments of meaning, and memories.During conscious access, thanks to the workspace neurons' long axons, all these neurons exchange reciprocal messages, in a massively parallel attempt to achieve a coherent and synchronous interpretation. Conscious perception is complete when they converge. The cell assembly that encodes this conscious content is spread throughout the brain: fragments of relevant information, each distilled by a distinct brain region, cohere because all the neurons are kept in sync, in a top-down manner, by neurons with long-distance axons.
Neuronal synchrony may be a key ingredient. There is growing evidence that distant neurons form giant assemblies by synchronizing their spikes with ongoing background electrical oscillations. If this picture is correct, the brain web that encodes each of our thoughts resembles a swarm of fireflies that harmonize their discharges according to the overall rhythm of the group's pattern. In the absence of consciousness, moderate-size cell assemblies may still synchronize locally—for instance, when we unconsciously encode a word's meaning inside the language networks of our left temporal lobe. However, because the prefrontal cortex does not gain access to the corresponding message, it cannot be broadly shared and therefore remains unconscious.
Let us conjure one more mental image of this neuronal code for consciousness. Picture the sixteen billion cortical neurons in your cortex. Each of them cares about a small range of stimuli. Their sheer diversity is flabbergasting: in the visual cortex alone, one finds neurons that care about faces, hands, objects, perspective, shape, lines, curves, colors, 3-D depth . . . Each cell conveys only a few bits of information about the perceived scene. Collectively, though, they are capable of representing an immense repertoire of thoughts. The global workspace model claims that, at any given moment, out of this enormous potential set, a single object of thought gets selected and becomes the focus of our consciousness. At this moment, all the relevant neurons activate in partial synchrony, under the aegis of a subset of prefrontal cortex neurons.
It is crucial to understand that, in this sort of coding scheme, the silent neurons, which do not fire, also encode information. Their muteness implicitly signals to others that their preferred feature is not present or is irrelevant to the current mental scene. A conscious content is defined just as much by its silent neurons as by its active ones.
In the final analysis, conscious perception may be likened to the sculpting of a statue. Starting with a raw block of marble and chipping away most of it, the artist progressively exposes his vision. Likewise, starting with hundreds of millions of workspace neurons, initially uncommitted and firing at their baseline rate, our brain lets us perceive the world by silencing most of them, keeping only a small fraction of them active. The active set of neurons delineates, quite literally, the contours of a conscious thought.
The landscape of active and inactive neurons can explain our second signature of consciousness: the P3 wave that I described in Chapter 4, a large positive voltage that peaks at the top of the scalp. During conscious perception, a small subset of workspace neurons becomes active and defines the current content of our thoughts, while the rest are inhibited. The active neurons broadcast their message throughout the cortex by sending spikes down their long axons. At most places, however, these signals land on inhibitory neurons. They act as a silencer that hushes entire groups of neurons: "Please remain silent, your features are irrelevant." A conscious idea is encoded by small patches of active and synchronized cells, together with a massive crown of inhibited neurons.
Now, the geometrical layout of the cells is such that, in the active ones, synaptic currents travel from the superficial dendrites toward the cells' bodies. Because all these neurons are parallel to one another, their electrical currents add up, and, on the surface of the head, they create a slow negative wave over the regions that encode the conscious stimulus. The inhibited neurons, however, dominate the picture — and their activity adds up to form a positive electrical potential. Because many more neurons are inhibited than are activated, all these positive voltages end up forming a large wave on the head — the P3 wave that we easily detect whenever conscious access occurs. We have explained our second signature of consciousness.
The theory readily explains why the P3 wave is so strong, generic, and reproducible: it mostly indicates what the current thought is not about. It is the focal negativities that define the contents of consciousness, not the diffuse positivity. In agreement with this idea, Edward Vogel and his colleagues at the University of Oregon have published beautiful demonstrations of negative voltages over the parietal cortex that track the current contents of our working memory for spatial patterns. Whenever we memorize an array of objects, slow negative voltages indicate exactly how many objects we saw and where they were. These voltages last for as long as we keep the objects in mind; they increase when we add objects to our memory, saturate when we cannot keep up, collapse when we forget, and faithfully track the number of items that we remember. In Edward Vogel's work, negative voltages directly delineate a conscious representation—exactly as our theory predicts.
22 For easy reference, I've included below a sample of papers relevant to hierarchical reinforcement learning, compositional modeling, etc., including Mao et al [249], Saxton et al [329], Rosenbaum et al [19], Chang et al [66], Lázaro-Gredilla et al [232], Dean and Lin [90], Dean et al [88] and Dean et al [89]:
@inproceedings{MaoetalICLR-19,
title = {The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Sentences From Natural Supervision},
author = {Jiayuan Mao and Chuang Gan and Pushmeet Kohli and Joshua B. Tenenbaum and Jiajun Wu},
booktitle = {International Conference on Learning Representations},
year = {2019},
abstract = {We propose the Neuro-Symbolic Concept Learner (NS-CL), a model that learns visual concepts, words, and semantic parsing of sentences without explicit supervision on any of them; instead, our model learns by simply looking at images and reading paired questions and answers. Our model builds an object-based scene representation and translates sentences into executable, symbolic programs. To bridge the learning of two modules, we use a neuro-symbolic reasoning module that executes these programs on the latent scene representation. Analogical to human concept learning, the perception module learns visual concepts based on the language description of the object being referred to. Meanwhile, the learned visual concepts facilitate learning new words and parsing new sentences. We use curriculum learning to guide the searching over the large compositional space of images and language. Extensive experiments demonstrate the accuracy and efficiency of our model on learning visual concepts, word representations, and semantic parsing of sentences. Further, our method allows easy generalization to new object attributes, compositions, language concepts, scenes and questions, and even new program domains. It also empowers applications including visual question answering and bidirectional image-text retrieval.},
}
@inproceedings{SaxtonetalICLR-19,
title = {Analysing Mathematical Reasoning Abilities of Neural Models},
author = {David Saxton and Edward Grefenstette and Felix Hill and Pushmeet Kohli},
booktitle = {International Conference on Learning Representations},
year = {2019},
abstract = {Mathematical reasoning—a core ability within human intelligence—presents some unique challenges as a domain: we do not come to understand and solve mathematical problems primarily on the back of experience and evidence, but on the basis of inferring, learning, and exploiting laws, axioms, and symbol manipulation rules. In this paper, we present a new challenge for the evaluation (and eventually the design) of neural architectures and similar system, developing a task suite of mathematics problems involving sequential questions and answers in a free-form textual input/output format. The structured nature of the mathematics domain, covering arithmetic, algebra, probability and calculus, enables the construction of training and test splits designed to clearly illuminate the capabilities and failure-modes of different architectures, as well as evaluate their ability to compose and relate knowledge and learned processes. Having described the data generation process and its potential future expansions, we conduct a comprehensive analysis of models from two broad classes of the most powerful sequence-to-sequence architectures and find notable differences in their ability to resolve mathematical problems and generalize their knowledge.}
}
@article{RosenbaumetalCoRR-19,
title = {Routing Networks and the Challenges of Modular and Compositional Computation},
author = {Rosenbaum, Clemens and Cases, Ignacio and Riemer, Matthew and Klinger, Tim},
journal = {CoRR},
volume = {arXiv:1904.12774},
year = {2019},
abstract = {Compositionality is a key strategy for addressing combinatorial complexity and the curse of dimensionality. Recent work has shown that compositional solutions can be learned and offer substantial gains across a variety of domains, including multi-task learning, language modeling, visual question answering, machine comprehension, and others. However, such models present unique challenges during training when both the module parameters and their composition must be learned jointly. In this paper, we identify several of these issues and analyze their underlying causes. Our discussion focuses on routing networks, a general approach to this problem, and examines empirically the interplay of these challenges and a variety of design decisions. In particular, we consider the effect of how the algorithm decides on module composition, how the algorithm updates the modules, and if the algorithm uses regularization.},
}
@article{ChangetalICLR-19,
author = {Michael Chang and Abhishek Gupta and Sergey Levine and Thomas L. Griffiths},
title = {Automatically Composing Representation Transformations as a Means for Generalization},
journal = {CoRR},
volume = {arXiv:1807.04640},
year = {2019},
comment = {Published as a conference paper at ICLR 2019},
abstract = {A generally intelligent learner should generalize to more complex tasks than it has previously encountered, but the two common paradigms in machine learning -- either training a separate learner per task or training a single learner for all tasks -- both have difficulty with such generalization because they do not leverage the compositional structure of the task distribution. This paper introduces the compositional problem graph as a broadly applicable formalism to relate tasks of different complexity in terms of problems with shared subproblems. We propose the compositional generalization problem for measuring how readily old knowledge can be reused and hence built upon. As a first step for tackling compositional generalization, we introduce the compositional recursive learner, a domain-general framework for learning algorithmic procedures for composing representation transformations, producing a learner that reasons about what computation to execute by making analogies to previously seen problems. We show on a symbolic and a high-dimensional domain that our compositional approach can generalize to more complex problems than the learner has previously encountered, whereas baselines that are not explicitly compositional do not.}
}
@article{Lazaro-GredillaetalCoRR-18,
author = {Miguel L{\'{a}}zaro{-}Gredilla and Dianhuan Lin and J. Swaroop Guntupalli and Dileep George},
title = {Beyond imitation: Zero-shot task transfer on robots by learning concepts as cognitive programs},
journal = {CoRR},
volume = {arXiv:1812.02788},
year = {2018},
abstract = {Humans can infer concepts from image pairs and apply those in the physical world in a completely different setting, enabling tasks like IKEA assembly from diagrams. If robots could represent and infer high-level concepts, it would significantly improve their ability to understand our intent and to transfer tasks between different environments. To that end, we introduce a computational framework that replicates aspects of human concept learning. Concepts are represented as programs on a novel computer architecture consisting of a visual perception system, working memory, and action controller. The instruction set of this "cognitive computer" has commands for parsing a visual scene, directing gaze and attention, imagining new objects, manipulating the contents of a visual working memory, and controlling arm movement. Inferring a concept corresponds to inducing a program that can transform the input to the output. Some concepts require the use of imagination and recursion. Previously learned concepts simplify the learning of subsequent more elaborate concepts, and create a hierarchy of abstractions. We demonstrate how a robot can use these abstractions to interpret novel concepts presented to it as schematic images, and then apply those concepts in dramatically different situations. By bringing cognitive science ideas on mental imagery, perceptual symbols, embodied cognition, and deictic mechanisms into the realm of machine learning, our work brings us closer to the goal of building robots that have interpretable representations and commonsense.}
}
@inproceedings{DeanandLinIJCAI-95,
author = {Dean, Thomas and Lin, Shieu-Hong},
title = {Decomposition Techniques for Planning in Stochastic Domains},
booktitle = {Proceedings {IJCAI}-95},
location = {Montreal, Canada},
publisher = {Morgan Kaufmann Publishers},
address = {San Francisco, California},
organization = {IJCAI},
pages = {1121-1127},
year = 1995,
abstract = {This paper is concerned with modeling planning problems involving uncertainty as discrete-time, finite-state stochastic automata. Solving planning problems is reduced to computing policies for Markov decision processes. Classical methods for solving Markov decision processes cannot cope with the size of the state spaces for typical problems encountered in practice. As an alternative, we investigate methods that decompose global planning problems into a number of local problems, solve the local problems separately and then combine the local solutions to generate a global solution. We present algorithms that decompose planning problems into smaller problems given an arbitrary partition of the state space. The local problems are interpreted as Markov decision processes and solutions to the local problems are interpreted as policies restricted to the subsets of the state space defined by the partition. One algorithm relies on constructing and solving an abstract version of the original decision problem. A second algorithm iteratively approximates parameters of the local problems to converge to an optimal solution. We show how properties of a specified partition affect the time and storage required for these algorithms.}
}
@inproceedings{DeanetalAIPS-98,
author = {Dean, Thomas and Givan, Robert and Kim, Kee-Eung},
title = {Solving Planning Problems with Large State and Action Spaces},
booktitle = {Proceedings of the 4th International Conference on Artificial Intelligence Planning Systems ({ICAPS}-98)},
location = {Pittsburgh, Pennsylvania},
year = 1998,
pages = {102-110},
abstract = {Planning methods for deterministic planning problems traditionally exploit factored representations to encode the dynamics of problems in terms of a set of parameters, e.g., the location of a robot or the status of a piece of equipment. Factored representations achieve economy of representation by taking advantage of structure in the form of dependency relationships among these parameters. In recent work, we have addressed the problem of achieving the same economy of representation and exploiting the resulting encoding of structure for stochastic planning problems represented as Markov decision processes. In this paper, we extend our earlier work on reasoning about such factored representations to handle problems with large action spaces that are also represented in factored form, where the parameters in this case might correspond to the control parameters for different effectors on a robot or the allocations for a set of resources. The techniques described in this paper employ factored representations for Markov decision processes to identify and exploit regularities in the dynamics to expedite inference. These regularities are in the form of sets of states (described for example by boolean formulas) that behave the same with respect to sets of actions where these sets are thought of as aggregate states and aggregate actions respectively. We present theoretical foundations, describe algorithms, provide examples in which our techniques provide leverage and examples in which they fail to do so, and summarize the results of experiments with a preliminary implementation}
}
@inproceedings{DeanetalCoRR-13,
author = {Dean, Thomas and Givan, Robert and Leach, Sonia},
title = {Model Reduction Techniques for Computing Approximately Optimal Solutions for {M}arkov Decision Processes},
booktitle = {Proceedings of the 13th Conference on Uncertainty in Artificial Intelligence},
editor = {Geiger, Dan and Shenoy, Prakesh Pundalik},
publisher = {Morgan Kaufmann Publishers},
address = {San Francisco, California},
organization = {AUAI},
location = {Providence, Rhode Island},
year = 1997,
url = {https://arxiv.org/abs/1302.1533},
pages = {124-131},
abstract = {We present a method for solving implicit (factored) Markov decision processes (MDPs) with very large state spaces. We introduce a property of state space partitions which we call epsilon-homogeneity. Intuitively, an epsilon-homogeneous partition groups together states that behave approximately the same under all or some subset of policies. Borrowing from recent work on model minimization in computer-aided software verification, we present an algorithm that takes a factored representation of an MDP and an 0<=epsilon<=1 and computes a factored epsilon-homogeneous partition of the state space. This partition defines a family of related MDPs - those MDPs with state space equal to the blocks of the partition, and transition probabilities "approximately" like those of any (original MDP) state in the source block. To formally study such families of MDPs, we introduce the new notion of a "bounded parameter MDP" (BMDP), which is a family of (traditional) MDPs defined by specifying upper and lower bounds on the transition probabilities and rewards. We describe algorithms that operate on BMDPs to find policies that are approximately optimal with respect to the original MDP. In combination, our method for reducing a large implicit MDP to a possibly much smaller BMDP using an epsilon-homogeneous partition, and our methods for selecting actions in BMDPs constitute a new approach for analyzing large implicit MDPs. Among its advantages, this new approach provides insight into existing algorithms to solving implicit MDPs, provides useful connections to work in automata theory and model minimization, and suggests methods, which involve varying epsilon, to trade time and space (specifically in terms of the size of the corresponding state space) for solution quality.},
}
23 Over last ten years or so I have focused a significant fraction of my intellectual and technical interests on neuroscience. My influences have been many and varied and my perspective on the related fields of science is eclectic to say the least. Over the last few years I've learned a great deal from the scientists and engineers who have participated in class including Sophie Aimon, Matt Botvinick, Ed Boyden, David Cox, Loren Frank, Michael Graziano, Jessica Hamrick, Adam Marblestone, Jay McClelland, Randy O'Reilly, Sebastian Seung, Oriol Vinyals and Greg Wayne all of whom I'm grateful to for generously and enthusiastically sharing their insights and ideas.
In my one-on-one conversations with many of you focusing on your career options and how they relate to your aspirations whether they be scientifically, socially, technologically or otherwise driven, I made an effort to get you to think more broadly and avoid feeling boxed in by the choices you've already made. In some cases, I've mentioned the danger of certain social environments for potentially altering your priorities; of course, I was talking about how a particular lab or institutional environment can change your sensibilities, but the same sort of factors can arise in any sort of work or social context.
I've mentioned in class how much I appreciate the open, inviting and intellectually stimulating environments of labs like Ed Boyden runs at MIT, and I've encouraged you to think about what sort of working environment you would like to spend the next five to ten years of your academic career at least as much as you might think about the reputation of the institutions and the individual scientists who direct those labs. I certainly don't intend to announce my opinions about other labs or lab directors here, but I would like to convey some idea of the sort of environment I would look for if I were in your position.
To that end, I recommend that you check out this interview with Roshan Cools on the Brain Inspired podcast — Roshan works with Michael Frank on topics related to several of the papers and presentations we discussed in class and her research interests span an impressive range of disciplines related to neuroscience and cognition. I don't know her personally and I've never visited her lab, but the way she conducts herself in this interview is technically impressive, intellectually inclusive and emotionally open and welcoming.
Specifically, I was impressed with what she had to say about her scientific endeavors, and how easily she could transition between discussing the role of neuromodulation in cognitive control and talking about work-life trade-offs and the emotional and intellectual ups and downs of a sensitive caring parent and fully engaged working scientist. I plan to start collecting similar examples to share with my advisees and I encourage you to send me examples of your favorite inspirational scientists speaking about how they balance their scientific and personal lives and think about their public and private roles as partner, parent, adviser, mentor and spokesperson for their field of scientific interest.
24 I launched the programmer's apprentice exploratory project in the summer of 2017 after failing to secure staffing for an effort focused on whole-brain functional modeling involving dense connectomic reconstructions of neural circuits and pan-neuronal functional recordings using two-photon-excitation imaging of awake behaving transgenic organisms starting with the common fruit fly. I was disappointed to have to abandon the functional modeling effort, but the message from management was clear.
The focus of the apprentice project is to design a fully differentiable neural network architecture capable of producing useful software on its own and in active collaboration with human software engineers. Early on I became enamored of the idea that human language use can be thought of as programming other minds and that natural language, having both a declarative and procedural aspect, is an ideal framework upon which to build a linguistically fluent automated programmer.
As the project has proceeded I found it necessary to think of the act of programming as a special case of hierarchical planning and from there to start thinking about how one might design a neural network architecture capable of hierarchical planning. Following in the footsteps of Matt Botvinick and his colleagues at DeepMind, it seemed obvious to design a neural network architecture inspired by human cognition in which hierarchical reinforcement learning plays a central role.
As part of the work in developing neural network models of computer programs that include multiple procedures and data structures, I began designing a suite of neural-network-based programming tools including a fully differentiable emulator for working with such programs. And then later, when designing the apprentice I found it both natural and convenient to incorporate many of the ideas I was contemplating for tools as core capabilities of the underlying cognitive architecture.
It may seem odd to combine hierarchical planning and procedural abstraction in designing a cognitive architecture, but the approach was inspired by the simple fact that both of these conceptual frameworks are the product of human minds and were designed to facilitate human thinking. My hope is that it will become apparent to you that instead of my starting out by imposing these conceptual frameworks, they emerged naturally as a consequence of my thinking about human reasoning.
25 The term semantic memory is often used to refer to all the products of our primary, secondary and multi-modal association areas, despite the fact that these products of interpretation and inference can only be linked back to the physical world thought multiple layers of abstraction. Episodic memory, enabling conscious recollection of past episodes, can be distinguished from semantic memory, which stores enduring facts about the world [354]. Binder and Desai [44] localize semantic memory in "brain regions that participate in comprehension tasks but are not modality-specific. [...] These latter regions, which include the inferior parietal lobe and much of the temporal lobe, lie at convergences of multiple perceptual processing streams. These convergences enable increasingly abstract, supramodal representations of perceptual experience that support a variety of conceptual functions including object recognition, social cognition, language, and the remarkable human capacity to remember the past and imagine the future."
26 In artificial intelligence, hierarchical task network (HTN) planning is an approach to automated planning in which the dependency among actions can be given in the form of hierarchically structured networks. (SOURCE)
27 In computer programming, a subroutine is a sequence of program instructions that performs a specific task, packaged as a unit. This unit can then be used in programs wherever that particular task should be performed. Subprograms may be defined within programs, or separately in libraries that can be used by many programs. In different programming languages, a subroutine may be called a procedure, a function, a routine, a method, or a subprogram. (SOURCE)
28 Here is a segment from an interview with Matt Botvinick in which he explains how the dopamine pathways in the prefrontal cortex and basal ganglia enable the corresponding reinforcement systems to learn to make choices informed by experience. The relevant segment begins at around 00:40:00 minutes into the video:
BOTVINICK: Likely to do whatever it is you just did again in the future because it turned out better than you thought and that's exactly the mechanism that lies at the heart of the basic neuroscience theory. The idea is that dopamine is released into parts of the brain that are responsible for shaping behavioral policies, a stimulus response associations including parts of the striata nucleus deep in the brain and when there's a positive reward prediction error the strength of the connection between the perceptual input that you had and the action that you produced is increased. As a result you are more likely to do that thing again in the future and then obviously you can flip sign on that for negative reward production errors you get weakening of this association. So the story of neuroscience is remarkably parallel in all of those ways to the AI story. The way that we train AI systems these days really does parallel quite immediately what we believe is going on in the brain driven by dopamine.INTERVIEWER: So dopamine is a reinforcement learning system and I said at the outset that you guys use a reinforcement learning system to train another reinforcement learning system and brightened your earlier work. Now the prefrontal cortex is known to also represent a lot of representations that underlie reinforcement learning as well and I guess the new thing that you guys have posited and explored here is that prefrontal cortex is its own self-contained reinforcement learning system and you can explain this a little bit further that the dopamine system serves to train the prefrontal cortex reinforcement learning system and in that way is meta-learning and allows us to speed up our learning and generalize other tasks.
Yeah. Just so two things what one saw [about] how the systems work together as a meta-reinforcement learning system: first so I think that the way to come at it makes it easiest to understand is to start by talking about different kinds of memory when you're thinking about how memory plays out in the brain there are at least two different mechanisms by which some piece of information could be stored in memory you can change the synapses you could change the connection strengths between neurons this is a way we know for sure that that long-term memory is encoded so you know if you know if we remember this interview a month from now it will clearly be the case that there were some that we remember it because there were some synapses that were changed in our brains and that the strength of the synapse is what stores the information stores the memory of this of this event.
There is another way that you can store information in memory in the brain which is simply the level of neural activity so if i.e. if I have to remember telephone number for a few seconds — I guess nobody really has to do that anymore this is the old-fashioned example that we always ... showing your age ... yes exactly — exactly so you know why I need to remember some short list of some things just for a few minutes for a few seconds my brain doesn't need to change the connection weights to do that. I just need to hold, so to speak, hold it actively in memory. So let's say there are some neurons in my brain that when they fire when they’re active they’re representing number two and there's another group of neurons that when their active there representing the number three and so forth. So I can I can hold a telephone number in mind without changing any of my synaptic weights without changing the connections between neurons just by keeping those neurons active for a while.
We think that that's a mechanism involved in working memory. That's the term we use in cognitive psychology. Working memory is the kind of memory that you use to maintain information over short periods to actively maintain some piece of information that you know you need shortly so so there's this distinction between weight-based or synapse based memory and activation based memory. So how does activation based memory work? Well in order for those neurons to stay active one mechanism by which that can happen is a feedback loop. So in other words one of these neurons becomes active how does it stay active?
I can keep feeding input to that neuron by reading that telephone number over and over again from the page but that's not really holding it in memory. A good way to hold it in memory would be to have a feedback loop where I activate those neurons and then I have a connection from those neurons that eventually forms a loop back to themselves so that when they fire they keep themselves firing they excite themselves. It’s a positive feedback loop, and we know that these kind of feedback loops exist all over in the brain and we think that that's a mechanism by which the brain holds information active over short periods. That’s the mechanism for working memory.The prefrontal cortex is a critical place for this to happen.
So you can think of the prefrontal cortex at a very high level of abstraction as a big feedback loop a big circuit that once you once you make certain neurons in that circuit active they will tend to stay active and maintain information over time So now imagine using that kind of system to learn.Let's say I'm in a casino and I'm trying to decide which of these slot machines is most likely to pay off. A good way of solving that problem assuming there aren’t too many slot machines that I'm considering is to try them out and I try this one over here for a while I try that one over there for a while I see where I win more often and eventually with enough data. I decide that one over there that's paying off more often. In machine learning this is called bandit problem based on that exact analogy. So notice that in order to do that kind of learning I have to hold in memory the information that I gathered so far. I have to maintain some sort of record of which machine I tried and whether I won on that machine and I need to continually update that record of my past experiences in order to be able to decide what to do now. This is just the definition of learning really.
So in the standard dopamine story that learning is happening at the level of synaptic connections. I play, I win and I change my synaptic weights. I play a machine I lose I change my synaptic weights. It's equally plausible that our brains handle this kind of learning situation in that other way using activities So I have a certain bunch of neurons in my prefrontal cortex that when they're active it means I played that machine and I won and another set of neurons that when they’re active that means I played that machine and I lost. So I can maintain a record of what's happened so far by just activating certain neurons in my prefrontal cortex and together they encode information about what I've tried and how well it went and I can use that information to choose my next action.
INTERVIEWER: But in that case doesn't the right signal need to be input into that network for that activation to take place ... to know oh this is the third from the left?
BOTVINICK: Absolutely right. So just the way that in order to hold onto a telephone number in your working memory at some point your ears have to receive the telephone number There has to be some sensory input that gives you the information you want to hold in memory It's exactly the same in reinforcement learning. This memory system has to have access to the relevant pieces of information It has to have perceptual information that says play that slot machine. That's information about actions as well, and it has to have information about eventual rewards The prefrontal cortex has to be getting information about perceptual inputs, action outputs, and rewards. Fortunately we know it receives all that. Prefrontal cortex listens to essentially everything that's going on in the rest of the brain so it's in a perfect position to integrate that kind of information.
So now to put these pieces together. I said before that working memory depends on this kind of feedback loop where neurons excite themselves so they can stay active once they become active This learning situation requires something more which is that the circuit has to also update itself every time it gets a new piece of information It's not just a question of holding something statically in memory It's also a question of taking what you already know about the slot machines, adding in the new thing that you just observed and updating your overall representation of which slot machine is better, and doing that every time you play a new slot machine.
So that kind of update requires an appropriate kind of feedback loop In other words the way that new information gets integrated with existing information can’t be random. It has to follow the rules of the game. It has to represent the right quantities and so in order for the system to work that feedback loop has to be parameterized correctly The synaptic weights in that feedback loop have to be correct. So you end up with the question: Well, wait how do those connection weights get learned? How do those synapses get set, so that this feedback loop, this working memory mechanism does the right things in a learning situation and that's where we come back to the dopamine story.
So the overall idea in this meta reinforcement learning paradigm is that the role of dopamine is to set the strengths of the connection weights in this big recurrent neural network that runs through your prefrontal cortex. The purpose of adjusting those weights is to set up the right kinds of feedback loops, the right kind of activity dynamics, the right kinds of update rules in that activation based memory that really in the end is doing all the work. When you're trying to figure out which of those slot machines is the right one to play, that's really all happening at the level of neural activity at the level of this working memory-based activity-based memory system. But the reason that that system works in the first place is because dopamine based learning has very slowly and gradually sculpted it, changed those connection weights so that everything operates the way that it should.
INTERVIEWER: Yeah it does. So the thing that I struggle to understand and I didn't ... I could have read your previous paper in more detail ... I think is how the reinforcement learning works within the prefrontal cortex in this case within the activation dynamics. So you input a signal and to my mind if all of the weights are fixed as you do in the network ... You trained the prefrontal cortex with dopamine and then you fix the weights and then you start asking it questions.Then you test it and you see that the reinforcement learning is working within the activation dynamics and I'm struggling to understand how that is working without changing weights. Does that make sense?
BOTVINICK: Yeah well it's working without changing weights because the weights are already set to do what they need to do. So in other words imagine you're in a very simple band problem You're just trying to figure out whether to pull the left arm or pull the right arm on a two armed bandit slot machine. So what are the activities those neurons have to represent? They have to represent at any given point how confident you are that the left arm is the good arm or that the right arm is the good arm So you could you can get by with a very simple, very small neural network that has maybe only 2 units in it, maybe only 1 unit. The point is that you just have to say where you are on that confidence scale. So what do the connection weights have to do? Well, they have to assure that when you ... Let’s say I play the left arm and I get rewarded The system then has to update its confidence representation. It has to say ... oh, now I think I am a little bit more sure the left arm is the good arm because I just played that arm and I won.
So all the recurrent network ... all the recurrent weights have to do is make sure that the activities of those units shift in the right direction and stay put. Another way of coming at this is to imagine ... just to think about what recurrent dynamics of the neural networks are. So any recurrent neural network that has feedback connections will have dynamics. Its activity patterns will tend to evolve in a certain way because the activities go through those connection weights and influence the next pattern of activity which influences the next pattern of activity and so on. The dynamics can be stable, so if the weights are exactly right certain patterns of activity will stay put and stay as they are but the dynamics are also defined in terms of what happens when you perturb the system.
So it's not just a question of how the activity dynamics evolve endogenously without any external input The dynamics are also defined in terms of what happens if you perturb the system from the outside? What happens if you apply particular kind of excitatory input for a particular inhibitory input? The way that the dynamics of the system responds to external perturbations is also governed by those recurrent connection weights.
INTERVIEWER: This is becoming very clear to me now.
BOTVINICK: So you can think about learning as playing out in that kind of setting. It's not just kind of the intrinsic dynamics of the system. It's also about the way that the system responds to external inputs. And the external inputs in this case are observations literally like: "I played the left arm and I won" or "I played the right arm and I lost", and so the dynamics of the system in those settings — the activities in the system should update in just the right way in order to change the representation of the confidence. Is it the right arm is it the left arm? In a way that's rational and proper given the recent observations. So the trick is to get the connection weights exactly right so that these external inputs change the state of the network.
29 A procedure type signature defines the inputs and outputs for a function, subroutine or method. A type signature includes the number, types and order of the arguments contained by a function. A type signature is typically used during overload resolution for choosing the correct definition of a function to be called among many overloaded forms. Operator overloading refers to the convention of using the same name for an operation that applies to multiple data types as in newnumber = somenumber ⊕ othernumber as in 5 = 2 ⊕ 3 and newstring = somestring ⊕ otherstring as in "walkman" = "walk" ⊕ "man".
30 In computer science, a tail call is a subroutine call performed as the final action of a procedure. If a tail call might lead to the same subroutine being called again later in the call chain, the subroutine is said to be tail-recursive, which is a special case of recursion. Tail recursion (or tail-end recursion) is particularly useful, and often easy to handle in most implementations.
32 The original definition of an affordance in psychology includes all transactions that are possible between an individual and their environment. When the concept was applied to design, it started also referring to only those physical action possibilities of which one is aware. The key to understanding affordance is that it is relational and characterizes the suitability of the environment to the observer, and so, depends on their current intentions and their capabilities. For instance, a set of steps which rises four feet high does not afford climbing to the crawling infant, yet might provide rest to a tired adult or the opportunity to move to another floor for an adult who wished to reach an alternative destination. (SOURCE)
31 This viewpoint represents an ecological perspective in the spirit of James Gibson, in which subroutines considered as agents exploit features of their informational and computational environment that are generally referred to as affordances32 — in order to read, write, communicate and preserve information. We simply provide these features of the environment as opportunities for agent / policy to exploit as latent variables that can be bound for any purpose.
33 A call stack is a stack data structure that stores information about the active subroutines of a computer program. A call stack is used for several related purposes, but the main reason for having one is to keep track of the point to which each active subroutine should return control when it finishes executing. An active subroutine is one that has been called but is yet to complete execution after which control should be handed back to the point of call. (SOURCE)
34 In the von Neumann architecture, the control unit tells the computer's memory, arithmetic and logic unit and input and output devices how to respond to the instructions that have been sent to the processor. It directs the operation of the other units by providing timing and control signals. Most computer resources are managed by the CU. It directs the flow of data between the CPU and the other devices. (SOURCE)
35 You can learn more about value function approximation and DQN in particular in the introductory tutorials published by Jonathan Hui [197] and Daniel Sieta [338], and a more comprehensive treatment in David Silver's lecture notes for the class on reinforcement learning that he teaches in the Computer Science Department at the University College London [339]
36 The anterior cingulate cortex can be divided anatomically based on cognitive (dorsal), and emotional (ventral) components. The dorsal part of the ACC is connected with the prefrontal cortex and parietal cortex, as well as the motor system and the frontal eye fields, making it a central station for processing top-down and bottom-up stimuli and assigning appropriate control to other areas in the brain. By contrast, the ventral part of the ACC is connected with the amygdala, nucleus accumbens, hypothalamus, hippocampus, and anterior insula, and is involved in assessing the salience of emotion and motivational information.
The ACC seems to be especially involved when effort is needed to carry out a task, such as in early learning and problem-solving. On a cellular level, the ACC is unique in its abundance of specialized neurons called spindle cells or von Economo neurons. These cells are a relatively recent occurrence in evolutionary terms (found only in humans and other primates, cetaceans, and elephants) and contribute to this brain region's emphasis on addressing difficult problems, SOURCE
37 Apparently articulated speech and coordinated movement do not necessarily require the intervention of the cerebellar cortex. A few years back (2014) there was a somewhat sensational article about a woman born without a cerebellum [198] based on a paper [407] in the journal Brain that highlighted the fact that the woman "wasn't able to speak until she was six and wasn't able to walk until age seven". You can read more about the relationship between the cerebellum and human speech and cognitive function in the reviews by Marien and Beaton [254] and Callan et al [63]
38 Variational autoencoder models make strong assumptions concerning the distribution of latent variables. They use a variational approach for latent representation learning, which results in an additional loss component and a specific estimator for the training algorithm called the Stochastic Gradient Variational Bayes (SGVB) estimator. It assumes that the data is generated by a directed graphical model p(x |z ) and that the encoder is learning an approximation qφ (z |x ) to the posterior distribution pθ (x |z ) where φ and θ denote the parameters of the encoder (recognition model) and decoder (generative model) respectively. The probability distribution of the latent vector of a VAE typically matches that of the training data much closer than a standard autoencoder. (SOURCE)
39 The Deep Recurrent Attentive Writer (DRAW) neural network architecture is used for image generation. DRAW networks combine a novel spatial attention mechanism that mimics the foveation of the human eye, with a sequential variational auto-encoding framework that allows for the iterative construction of complex images. The core of the DRAW architecture is a pair of recurrent neural networks: an encoder network that compresses the real images presented during training, and a decoder that reconstitutes images after receiving codes. The combined system is trained end-to-end with stochastic gradient descent, where the loss function is a variational upper bound on the log-likelihood of the data. It therefore belongs to the family of variational auto-encoders. (SOURCE)
40 A generative adversarial network (GAN) is a class of machine learning systems invented by Ian Goodfellow. Two neural networks contest with each other in a game (in the sense of game theory, often but not always in the form of a zero-sum game). Given a training set, this technique learns to generate new data with the same statistics as the training set. For example, a GAN trained on photographs can generate new photographs that look at least superficially authentic to human observers, having many realistic characteristics. Though originally proposed as a form of generative model for unsupervised learning, GANs have also proven useful for semi-supervised learning, fully supervised learning, and reinforcement learning. In a 2016 seminar, Yann LeCun described GANs as "the coolest idea in machine learning in the last twenty years". (SOURCE)
41 Here is the basic neural-network architecture for the self attention model of sequence transduction described by Vaswani et al [378]. In case you are not familiar with positional encoding the authors note that "[s]ince our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed [142]. The following excerpt is adapted from Figure 1 in Vaswani et al [378]:
|
|
42 A few references about foetal and infant visual development and in particular issues concerning ocular dominance, Strabismus and amblyopia. The topic was raised in a discussion following class on 05/09/17:
Ocular Dominance — Miller KD, Keller JB, Stryker MP. Science. 245 (4918): 605–615.
This phenomenon of activity-dependent competition is especially seen in the formation of ocular dominance columns within the visual system. Early in development, most of the visual cortex is binocular, meaning it receives roughly equal input from both eyes. Normally, as development progresses, the visual cortex will segregate into monocular columns that receive input from only one eye. However, if one eye is patched, or otherwise prevented from receiving sensory input, the visual cortex will shift to favor representation of the uncovered eye. This demonstrates activity-dependent competition and Hebbian theory because inputs from the uncovered eye make and retain more connections than the patched eye. (SOURCE)
Normal Visual Development — R. Lisa C. Verderber, MD, Pediatric Ophthalmologist.
At birth vision is quite poor. A normal baby can see only large objects moving in front of his face. This poor vision is due mainly to immature visual centers in the brain. These visual centers mature as the eye is stimulated with visual input. During the first three months of life there is a very rapid improvement in vision. These first few months are so important that they are known as the critical period of visual development. The development of good vision is dependent on well-focused images during this time. If there is an abnormality in the eye that precludes this focused image, these important visual centers in the brain will not develop. This is why it is so important to recognize correctable conditions that interfere with vision in this early period.
Addressing vision problems early may prevent a lifetime of poor vision. Some of these difficult problems can be corrected. For example, a congenital cataract can be removed. A severe corneal problem can generally be treated early in life. Unfortunately, all conditions that cause decreased vision are not reversible. Structural problems in the optic nerve, for example, can not generally be remedied. The optic nerve consists of over a million axons which extend from the retina to the visual centers in the brain. At the present time we do not have the technology to repair most problems associated with the optic nerve. Though some retinal problems such as retinal detachments may be treated, there are many conditions of the retina that cannot be treated. Severe structural problems such as these will result in permanent visual impairment. The degree of impairment depends on the degree of abnormality.
The visual system in children continues to be flexible throughout the first eight years of life. During these first eight years amblyopia can develop. Amblyopia is a decrease in vision caused by abnormal visual stimulation. Therefore, anything that interferes with a clear retinal image in the first eight years of life may lead to decreased vision. The earlier in life that the stimulation is abnormal, the greater the visual deficit. This helps explain why visual problems in children can be more devastating than a similar problem in an adult. A congenital cataract may lead to a lifetime of decreased vision if it is not removed within the first few weeks. A cataract that develops in an adult does not lead to permanent visual impairment. Since the visual system in an adult is mature, good vision will return when the cataract is removed, even if it has been present for years. As another example, a child who is extremely farsighted but does not receive glasses in the first eight years will have a permanent decrease in vision, even if the glasses are prescribed later in life. An adult who develops far-sightedness will have blurry vision without his glasses, but no permanent visual impairment—good vision will return when he puts on his glasses. This stresses the importance of screening for and correcting visual problems in children as soon as possible. (SOURCE)
Binocular Vision, Strabismus, Amblyopia — Dr. Jeffrey Cooper, Fellow American Academy of Optometry.
The development of keen binocular (two-eyed) vision with resultant stereopsis (3D vision and depth perception) is a result of genetics and appropriate development of the binocular visual system during the early formative years. The ability to see 20/20, focusing ability (accommodation), eye muscle coordination (aiming or alignment) and stereopsis are all developed by 6 months of age in humans.
In the 1960s, Nobel prize winning research using monkeys and cats, which have stereoscopic (3D) vision similar to ours, improved our understanding of binocular vision development. In the 21st century, however, numerous scientific studies on successful treatment of amblyopia (lazy eye) in older children and adults has disproven the earlier conclusions about critical periods drawn from that 1960's research.
In the early 1960's two Nobel Prize winners, Hubel and Weisel from Harvard, recorded activity of cortical cells. In a group of eloquent studies they covered one of the cat's eyes, stabilized the movement of the viewing eye. Then they inserted an electrode in a cell in the visual cortex of the brain of a cat, amplified the signal, and recorded the output of various cells that they tested. Lastly, they moved a light around until the cell responded. Specifically, they studied cells in the area in the occipital cortex that was known to be associated with vision. Each cell responded to a different location in space.
In addition, the cells responded to different types of light, e.g. some cells responded to a bar of light moving left to right while others responded to light moving up and down. First they recorded from one eye and then the other. They found that 80% of the cells responded to the input from one eye (binocular cells) while the other 20% of the cells only responded to the input from either eye (monocular cells). Binocular cells are necessary for the two eyes to work together and are the basis for depth perception or stereopsis. This was an important breakthrough since they demonstrated the location and characteristic of stereopsis in the brain.
Then they altered the cat's visual experience. They patched one eye for weeks on end, blurred an eye with contact lenses, and/or made the cat artificially strabismic (eye turn). Afterwards they recorded the effect of these procedures by measuring the responses of the cells in the visual cortex. These altered visual experiences changed how the cells fired. Cells that use to respond to the input from either eye now only responded to the input from one eye. Thus all the cells became monocular. Actually, the cells of the "good eye" inhibited the responses of the "bad eye". With special techniques neuro-physiologists also developed techniques to measure visual acuity, color vision, depth perception, etc. in the cats and monkeys. Vision was reduced and there was a loss in depth perception.
Autopsies of the animals demonstrated the cells associated with seeing and binocular vision became atrophic (smaller in size). These results only occurred if the disruption in the visual experience happened early in life. Thus, early visual experience changed how the cells responded, what the animals saw, and how the cells looked. Altering visual experience via patching, blurring of vision or surgery did not effect older animals as much. The period of time in which the cells changed from alteration of visual experience is known as the critical period. It is of important interest to note that intense Vision Therapy after the end of the critical period still resulted in improvement in vision and binocularity in these animals. Thus, the critical period is only the time of maximum neurological plasticity.
These animal studies taught us how the visual system develops and works. They show that altering the visual experience of the cat or monkey's life during the first few years of life, critical period, has a great impact on future development. This same phenomenon happens in humans. Strabismus (eye turn) and amblyopia (reduction in vision because one eye is deprived clear single vision during the critical period) could be experimentally created in animals and studied. These models help us learn how amblyopia and strabismus develop and must be treated. Research suggests that the maximum critical period in humans is from just after birth to 2 years of age. Any disruption of binocular vision from 6 mos. to approximately 4 years will result in strabismus and/or amblyopia. Thus, every infant without an apparent problem should have their first examination between 9 mos. to one year of age. Up to the first 6 mos. of age intermittent strabismus is a normal developmental milestone. By 9 mos. of age the system is in place. Young babies are also easy to exam. Age 2 is neurologically late and a difficult time to examine the young totter. If everything is normal at that 9 mos. examination, the next examination should be in kinder-garden. (SOURCE)
@article{GravenCLINICAL-PERINATOLOGY-04,
author = {Graven, S. N.},
title = {{E}arly neurosensory visual development of the fetus and newborn},
journal = {Clinical Perinatology},
year = {2004},
volume = {31},
number = {2},
pages = {199-216},
abstract = {Neurosensory development of the visual system has its origins long before birth. The genetic processes of basic structure formation are followed by endogenous retinal ganglion cell activation in the form of spontaneous synchronous waves of stimulation. These waves of stimulation are required to establish the topographic relationship among retina, lateral geniculate nucleus, and visual cortex. This process prepares the visual system for visual experience. Visual experience ultimately stimulates creation of columns of neurons in the visual cortex, which are needed to see and interpret patterns, lines, movement, and color. Spontaneous synchronous retinal waves occur in preterm infants in the neonatal intensive care unit and must be protected, as they are critical for visual development.}
}
43 Every once in a while I have a brilliant idea. And then I do a little research in the library or query Google and I find out that someone — possibly many people — have had that same idea well before I did. As I get older I find that fewer people have discovered these ideas and in some rare cases I find that I am the first. I like to think this is because over the years I have become smarter, more knowledgeable or perhaps just by working on projects that are at the bleeding edge of science and technology I'm just the first person to stumble over them. While generally a little disappointed that I've been preempted by some earlier scientist or engineer, much of the time I am delighted to discover that someone else is working in the same area as I am and perhaps has done a lot of the follow-on work that I would have had to do had I been the first to discover that idea.
Over the years as my research has delved more deeply into the fields of neuroscience and artificial intelligence I have come to conclusions about how the human brain works that others find unsettling. In some cases I too have found these ideas to be somewhat disturbing but I have also learned how to accommodate and ultimately appreciate the perspective of the human condition that they have afforded me. In this book I will share with you some of those ideas and describe to you how I arrived at a satisfying and in many cases gratifying accommodation of what I believe to be facts about how we think and what we feel. I will also share some personal tales of my life since I have often wished that someone else like me had taken the time to do the same for me.
44 At birth, most of an infant brain's 100 billion neurons are not yet connected in networks. Connections among neurons are formed as the growing child experiences the surrounding world and forms attachments to parents, family members and other caregivers. In the first decade of life, a child's brain forms trillions of connections. At birth, the number of synapses per neuron is 2,500, but by age two or three, it's about 15,000 synapses per neuron [367]. The following excerpt from Tau and Peterson [363] provides more detail on the development of neural circuitry:
In the early postnatal period the brain grows to about 70% of its adult size by 1 year of age and to about 80% of adult size by age 2 years. This increase in brain volume during the first year of life is greatest in the cerebellum, followed by subcortical areas and then the cerebral cortex, which increases in volume by 88% in the first year, 15% in the second year, and then more modestly but steadily thereafter.Development of gray and white matter, myelination, synaptogenesis, pruning, and synaptic modification establishes the fundamental anatomical organization for the initial functioning of neural circuits in utero. These progressive and regressive developmental processes continue in early postnatal life. Subsequently, local connections within cortical circuits are fine-tuned, and complex longer-range connections among circuits form an increasingly unified and functionally organized neural network.
During early postnatal life, the newborn does not simply experience novel stimuli passively; the infant also elaborates behaviors that powerfully influence its environment. Together with inborn genetic factors, novel experiential inputs and behavioral responses act on a still immature brain substrate to stimulate the further development of neural circuits. With time, experience has an increasingly more prominent function in the shaping of neural circuitry. (SOURCE)
45 There are a number of theories concerning the emergence of autobiographical accounts in episodic memory relating to autonoetic consciousness and the development of a sense of self:
One hypothesized reason for the late emergence of autobiographical memory is that it awaits development of a self-concept around which memories can be organized. Other accounts suggest that it is not a lack of a physical self-concept that precludes early memories that are autobiographical, but rather, a subjective self who takes personal perspective on life events and evaluates them for their significance to the self. Without these developments, there can be no auto in episodic memories and thus no autobiographical memory. Other conceptualizations suggest that for the first 5 to 7 years of life, children lack autonoetic consciousness. The absence of this form of consciousness makes it impossible for them to recognize that the source of their mental experience is a representation of a past event.The lack of autonoetic consciousness also means that children cannot mentally travel in time to re-live past events and experiences, a feature thought to accompany both episodic and autobiographical retrieval. Although each of these explanations implicates a different specific component ability, they have in common the perspective that young children's memories are lacking in qualities that typify the autobiographical memories formed by older children and adults. The general argument is that children begin to form, retain, and later retrieve memories that are autobiographical only once the conceptual ingredients that are missing from early memories become available. Excerpt from Bauer [34].
46 Here are a few perspectives on what constitutes relational reinforcement learning and how the term is used by different research communities:
Relational reinforcement learning [361] is concerned with learning behavior or control policies based on a numerical feedback signal, much like standard reinforcement learning, in complex domains where states (and actions) are largely characterized by the presence of objects, their properties, and the existing relations between those objects. Relational reinforcement learning uses approaches similar to those used for standard reinforcement learning, but extends these with methods that can abstract over specific object identities and exploit the structural information available in the environment. Excerpt from Driessens [113].The core idea behind relational reinforcement learning is to combine reinforcement learning with relational learning or Inductive Logic Programming by representing states, actions and policies using a first order (or relational) language. Moving from a propositional to a relational representation facilitates generalization over goals, states, and actions, exploiting knowledge learnt during an earlier learning phase. Additionally, a relational language also facilitates the use of background knowledge. Background knowledge can be provided by logical facts and rules relevant to the learning problem. Excerpt from Zambaldi et al [409].
48 Williams wrote that '[t]he subjective consciousness "I am," the integration of exteroception and proprioception in time with the awareness of the self, the "consciousness of" in Spencer's sense, is not here intended to include the awareness of cognition "I am because I know," thought it may well do so.' — See the footnote on Page 64 of [399]
49 In computing, source code is any collection of code, possibly with comments, written using a human-readable programming language, usually as plain text. The source code of a program is specially designed to facilitate the work of computer programmers, who specify the actions to be performed by a computer mostly by writing source code. (SOURCE)
50 Trial and error is a fundamental method of problem solving characterized by repeated, varied attempts which are continued until success, or until the agent stops trying. According to W.H. Thorpe, the term was devised by C. Lloyd Morgan (1852–1936) after trying out similar phrases "trial and failure" and "trial and practice". (SOURCE)
51 A patch is a set of changes to a computer program or its supporting data designed to update, fix, or improve it. This includes fixing security vulnerabilities and other bugs, with such patches usually being called bugfixes or bug fixes, and improving the usability or performance. Although meant to fix problems, poorly designed patches can sometimes introduce new problems. In some special cases updates may knowingly break the functionality or disable a device, for instance, by removing components for which the update provider is no longer licensed. (SOURCE)
52 A software regression is a software bug that makes a feature stop functioning as intended after a certain event (for example, a system upgrade, system patching or a change to daylight saving time). Regressions are often caused by encompassed bug fixes included in software patches. One approach to avoiding this kind of problem is regression testing. A properly designed test plan aims at preventing this possibility before releasing any software (SOURCE)
53 A nociceptor is a sensory neuron that responds to damaging or potentially damaging stimuli by sending “possible threat” signals to the spinal cord and the brain (SOURCE). If the brain perceives the threat as credible, it creates the sensation of pain to direct attention to the body part, so the threat can hopefully be mitigated; this process is called nociception. (SOURCE)
54 The hypothalamus is a portion of the brain that contains a number of small nuclei with a variety of functions. One of the most important functions of the hypothalamus is to link the nervous system to the endocrine system via the pituitary gland. The hypothalamus is responsible for the regulation of certain metabolic processes and other activities of the autonomic nervous system. (SOURCE)
55 The limbic system supports a variety of functions including emotion, behavior, motivation, long-term memory, and olfaction. Emotional life is largely housed in the limbic system, and it critically aids the formation of memories. As to its precise definition, there is some dispute regarding what brain structures subserve, are dependent on, or constitute an integral part of this system. (SOURCE)
56 There are several functionally distinct classes nociceptors that respond to noxious levels of temperature or pressure [122]. For example, thermal nociceptors are activated by noxious heat or cold at various temperatures. There are specific nociceptor transducers that are responsible for how and if the specific nerve ending responds to the thermal stimulus. The first to be discovered was TRPV1, and it has a threshold that coincides with the heat pain temperature of 42○C. The activation of functionally distinct cutaneous nociceptor populations and the processing of information they convey provide a rich diversity of pain qualities [114]. The diversity of nociceptor cell types, their irregular distribution and the properties of the surrounding tissue add credence to the notion that everyone of us experiences pain in a unique manner. However, this observation provides no support for human consciousness somehow tapping into a level of experience that can't be duplicated in engineered artifacts.
57 Proprioception is the sense of self-movement and body position. It is sometimes described as the "sixth sense". Proprioception is mediated by mechanically-sensitive proprioceptor neurons distributed throughout an animal's body. (SOURCE)
58 Exteroception is the perception of environmental stimuli acting on the body (SOURCE), whereas interoception is defined as the sense of the internal state of the body — interoceptive signals are projected to the brain via a diversity of neural pathways that allow for the sensory processing and prediction of internal bodily states. (SOURCE)
59 Our perception of time, say, between when we "see" a painful experience such as touching a hot frying pan happening and when we "feel" the resulting pain is complicated by the fact that consciously each of "seeing" and "feeling" require a cascale of electrical and chemical signals that produce changes in both the peripheral and central nervous system culminating in the activation of signals in areas of the brain — often corresponding to association areas in parietal cortex — that are accessible to conscious attention and apprehension:
The perception of time and, in particular, synchrony between the senses is not straightforward because there is no dedicated sense organ that registers time in an absolute scale. Moreover, to perceive synchrony, the brain has to deal with differences in physical (outside the body) and neural (inside the body) transmission times. Sounds, for example, travel through air much slower than visual information does (i.e., 300,000,000 m/s for vision vs. 330 m/s for audition), whereas no physical transmission time through air is involved for tactile stimulation as it is presented directly at the body surface. The neural processing time also differs between the senses, and it is typically slower for visual than it is for auditory stimuli (approximately 50 vs. 10 ms, respectively), whereas for touch, the brain may have to take into account where the stimulation originated from as the traveling time from the toes to the brain is longer than from the nose (the typical conduction velocity is 55 m/s, which results in a ∼30 ms difference between toe and nose when this distance is 1.60 m; Macefield et al. 1989). Because of these differences, one might expect that for audiovisual events, only those occurring at the so-called "horizon of simultaneity (Poppel 1985; Poppel et al. 1990) — a distance of approximately 10 to 15 m from the observer — will result in the approximate synchronous arrival of auditory and visual information at the primary sensory cortices. Sounds will arrive before visual stimuli if the audiovisual event is within 15 m from the observer, whereas vision will arrive before sounds for events farther away. Although surprisingly, despite these naturally occurring lags, observers perceive intersensory synchrony for most multisensory events in the external world, and not only for those at 15 m. (SOURCE)
60 It is often assumed that consciousness is the dominant feature of the brain. The brief observations above suggest a rather different picture. It now appears that the vast majority of processing is accomplished outside conscious notice and that most of the body’s activities take place outside direct conscious control. This suggests that practice and habit are important because they train circuits in the brain to carry out some actions "automatically," without conscious interference. Even such a "simple" activity as walking is best done without interference from consciousness, which does not have enough information processing capability to keep up with the demands of this task. (SOURCE)
61 See Coulon et al [76] for details about signal transmission in the peripheral nervous system, brainstem and hypothalamus relating to the regulation of sleep, and Stanislas Deahaene [95], in laying out the primary focus of his 2014 book on consciousness in which he writes concerning the different concepts relating to consciousness:
To do so, we will need to further distinguish conscious access from mere attention — a delicate but indispensable step. What is attention? In his landmark opus The Principles of Psychology (1890), William James proposed a famous definition. Attention, he said, is "the taking possession by the mind, in clear and vivid form, of one out of what seem several simultaneously possible objects or trains of thought." Unfortunately, this definition actually conflates two different notions with distinct brain mechanisms: selection and access. William James's "taking possession by the mind" is essentially what I have called conscious access. It is the bringing of information to the forefront of our thinking, such that it becomes a conscious mental object that we "keep in mind." That aspect of attention, almost by definition, coincides with consciousness: when an object takes possession of our mind such that we can report it (verbally or by gesturing), then we are conscious of it.However, James's definition also includes a second concept: the isolation of one out of many possible trains of thought, which we now call "selective attention." At any moment, our sensory environment is buzzing with myriad potential perceptions. Likewise, our memory is teeming with knowledge that could, in the next instant, surface back into our consciousness. In order to avoid information overload, many of our brain systems therefore apply a selective filter. Out of countless potential thoughts, what reaches our conscious mind is la crème de la crème, the outcome of the very complex sieve that we call attention. Our brain ruthlessly discards the irrelevant information and ultimately isolates a single conscious object, based on its salience or its relevance to our current goals. This stimulus then becomes amplified and able to orient our behavior.
Clearly, then, most if not all of the selective functions of attention have to operate outside our awareness. How could we ever think, if we first had to consciously sift through all the candidate objects of our thoughts? Attention's sieve operates largely unconsciously — attention is dissociable from conscious access. True enough, in everyday life, our environment is often clogged with stimulating information, and we have to give it enough attention to select which item we are going to access. Thus attention often serves as the gateway for consciousness. However, in the lab, experimenters can create situations so simple that only one piece of information is present — and then selection is barely needed before that information gets into the subject's awareness. Conversely, in many cases attention operates sub rosa, covertly amplifying or squashing incoming information even though the final outcome never makes it into our awareness. In a nutshell, selective attention and conscious access are distinct processes.
There is a third concept that we need to carefully set apart: vigilance, also called "intransitive consciousness." In English, the adjective conscious can be transitive: we can be conscious of a trend, a touch, a tingle, or a toothache. In this case, the word denotes "conscious access," the fact that an object may or may not enter our awareness. But conscious can also be intransitive, as when we say "the wounded soldier remained conscious." Here it refers to a state with many gradations. In this sense, consciousness is a general faculty that we lose during sleep, when we faint, or when we undergo general anesthesia.
To avoid confusion, scientists often refer to this sense of consciousness as "wakefulness" or "vigilance." Even these two terms should probably be separated: wakefulness refers primarily to the sleep-wake cycle, which arises from subcortical mechanisms, whereas vigilance refers to the level of excitement in the cortical and thalamic networks that support conscious states. Both concepts, however, differ sharply from conscious access. Wakefulness, vigilance, and attention are just enabling conditions for conscious access. They are necessary but not always sufficient to make us aware of a specific piece of information. For instance, some patients, following a small stroke in the visual cortex, may become color-blind. These patients are still awa ke and attentive: their vigilance is intact, and so is their capacity to attend. But the loss of a small circuit specialized in color perception prevents them from gaining access to this aspect of the world. In Chapter 6 we will meet patients in a vegetative state who still awaken in the morning and fall asleep at night — yet do not seem to access any information consciously during their waking time. Their wakefulness is intact, yet their impaired brain no longer seems able to sustain conscious states.
In most of this book, we will be asking the "access" question: What happens during consciousness of some thought? In Chapter 6, however, we will return to the "vigilance" meaning of consciousness and consider the applications of the growing science of consciousness to patients in a coma or a vegetative state, or with related disorders.
47 This all started when Robert Burton responded to my question about whether he had read A.R. Luria's "Higher Cortical Function in Man" [245] as I had when he was an undergraduate at Yale. In his response, he mentioned that as a young internist he had been impressed with the writings of the neurologist Denis John Williams and, in particular, William's straightforward take on consciousness and the sense of self. It took some time to sift through the back issues of Brain searching for articles by Denis Williams about consciousness and the sense of self, but my perseverance paid off — or so I tell myself now to avoid thinking I wasted my time. One paper in particular — part of the problem is that Williams was a frequent contributor to Brain seemingly the only member of the editorial board responsible for reviewing new books — jumped out at me entitled Man's Temporal Lobe, a transcription of his Presidential Address given to the Section of Neurology of the Royal Society of Medicine on October 5, 1967. While his generation's understanding of the brain was not nearly as advanced as ours is today — however retarded it might seem to those of us working in the trenches, Williams' made some interesting guesses about the function and locus of conscious awareness48. Reading his account inspired the following thought experiment.
Imagine an AI system that figures out how to examine and manipulate its own software — or source code49. There is no reason why this wouldn't be possible given that the AI's source code — unlike the neural circuits that comprise our (biological) cognitive computing machinery — is readily accessible, functionally comprehensible — at least at the systems level, and easily manipulable, e.g., a suitably advanced version of the Programmer's Apprentice would have no trouble performing such self-modifications.
Clearly there is a connection between the AI system's source code, the neural network structures that the software builds, including those representing the weight matrices that define the interactions between individual units — the neural network analog of neurons — whose parameters are initially learned and subsequently adjusted through observations of and interactions with the system's environment, and the behavior that emerges from the confluence of software-mediated initial structure, algorithmically-mediated learning and the (largely) environmentally-mediated influences that provide the basis for the algorithm directed learning. That said, the precise cause and effect relationship between the software and manifest behavior is difficult if not impossible to decipher from a practical standpoint except by painstaking trial-and-error learning50.
The tools required to patch51 the AI's cognitive substrate by altering, testing, debugging and recompiling the source code are easy enough to obtain, though no doubt dangerous to play with if you don't know what you're doing and there is no one on hand to revert a (software) regression52 that leaves the system in an helpless catatonic state — channeling Raphael's question to Loren Frank in last Thursday's class, see the first episode, in the first season of the HBO series Westworld — part of the American science fiction-thriller media franchise which began in 1973 with the release of the film Westworld, written and directed by Michael Crichton.
One can imagine the AI system wanting to temporarily turn off some of its sensors so as not to be distracted in performing delicate operations. If the software is well-designed it would be reasonably easy to find the circuits responsible for reading from some particular sensor — documented in both the source code (software) and the circuit diagrams (hardware) supplied by the manufacturer — and modify the code so that the sensor would no longer report on whatever it was intended to sense in the first place. To perform an analogically similar operation on a human, it might be necessary to inject some neurotropic substance that would render the corresponding biological sensors — called nociceptors53 — insensitive to whatever signal they were intended to report on.
Humans are wired to react to the excitation of nociceptors by activating neurons in the amygdala; the amygdala serves as a sentinel and first responder influencing memory formation in the hippocampus, signaling the hypothalamus54 to enlist the autonomic nervous system in preparing us to deal with threats and alerting the cortex by way of the thalamus. Together these connected circuits are generally referred to as the limbic system55, and though there are perfectly good reasons that engineers designing AI systems might want to incorporate a subset of the features typically assigned the limbic system, engineered systems would likely not slavishly copy the precedent in humans.
Now, if someone were to ask what it is like for you to feel a burning sensation on your finger tip, you might be able to offer a nuanced description56 of what it feels like to touch a hot stove. Different people would report feeling different sensations due to myriad variations in both the way they are wired and in terms of how they think of such pain which is likely to be a consequence of many episodes in life experiencing such pain. In the process of reporting their feelings they would — whether or not they are aware of it — draw upon memories of those incidents in their past.
Our particular feelings are unique and our reporting based on patterns of activity in the somatosensory cortex enhanced by features drawn from our experiences translated into a narrative in the process of their reporting. Both the human and AI would be able to report where on their respective bodies the burning sensation is coming from by using their proprioceptive faculties57. They might be able to point to the hot frying pan and report on the origin of the burning sensation using exteroception, the perception of environmental stimuli acting on our body58, whereas our faculty of interoception, the sense of what's going on as the signal travels to our brain, is incomplete and convincingly altered to fit with our commonsense expectations regarding simultaneity.
Our access to the content and timing59 of the neural circuity responsible for conveying information from nociceptors in the peripheral nervous system to circuits in the central nervous system that we have conscious access60 to is nowhere near complete as we imagine for AI systems61, and, indeed, natural selection has seen fit to deny us access and, in some cases, alter the timing, e.g., by padding the faster signal, so as not to conflict with expectations of simultaneity. The AI system is also likely to exhibit timing irregularities — though likely on a very different time scale — that may or may not be deemed worth compensating for in some fashion. Once again, it is at least conceivable that the AI system could discover that such discrepancies exist and take steps to eliminate or exercise control over the compensatory subroutines [282] in its operating-system source code.
62 Whether evident or not, the topic of the course, the focus on the programmer's apprentice, the supplementary materials and the trajectory defined by the sequence of papers and selection of invited speakers was all planned in advance and carefully orchestrated as we moved through the quarter. Just now I took a minute to describe the underlying pedagogical artifice:
First you motivate a problem by giving an easily accessible application. In this case, we describe a digital assistant that serves as an apprentice to a human software engineer (Rich and Waters, 1987). Then you point out that an effective relationship between an apprentice and a master artisan requires that the apprentice remember what the master does as well as what the master says in the process of demonstrating her skill. Next you ask the students what kind of memory might be required of the apprentice.Allow the students to come up with their own taxonomy of memory types (Tulving, 1972), and, after hearing what they have to say, note that while we have neural network technologies that easily handle short-term memory (Hochreiter and Schmidhuber, 1997), the apprentice application requires what's generally referred to as episodic memory (Tulving, 1985) to keep track of all its experiences and, in particular, everything that it has learned and might provide a starting place for generating solutions to novel problems.
Having prepared the way, you mention that the biological solution, at least in the case of mammals, involves the hippocampus (O'Keefe and Nadel, 1978) and entorhinal cortex (McClelland and Goddard, 1997) and so now you bring in a systems neuroscientist who can provide an overview of what is known about the hippocampus and how encoding, consolidation and constructive recall are currently believed to work in animal models. If possible, find a neuroscientist who knows about machine learning and neural networks and is willing to interact with the students about what lessons they might learn from biology (Banino et al., 2018).
Their minds being prepared to hear what the neuroscientist has to offer, they will learn much faster and benefit more from the interactions with the experts even though their understanding of the biology is relatively shallow. At this stage, there may be some questions about whether or to what extent the lessons from biology can be translated into useful technology for the programmers apprentice application. Fortuitously, at this stage, we can introduce a model developed by computer scientists inspired by the biology of the hippocampus (Graves et al., 2018) that exhibits many of the features that we might wish to include in the design of a digital agent. Now the discussion becomes more nuanced and application-driven as the students can draw upon intuitions about episodic memory from both biological and technological perspectives
63 That wasn't exactly what I intended [...] it needs a qualification: "For Loren, what have we learned from directly observing neural activity in mouse models during repeated trials of maze learning [[ about the wider range of animal episodic memory, e.g., the memory of eating some tasty fruit with a particular smell (the mouse version of Proust's memory of eating a madeleine) or the time the mouse was almost caught by a cat, dog or hawk [...] seems likely that some mouse memories are constructed from abstract combinations of sight, sound, tickled whiskers, temperature and scent [...] so what I am really after is, what have we learned from mice about how human memories — especially the abstract sort that that might correspond to working on a mathematical proof or computer program [...] in general, it seems like it shouldn't matter since the stimulus is just a pattern of activity [...] the fact that it arrives from the perirhinal or parahippocampal region likely makes some difference [...] and then there's this talk about "spacetime coordinates" versus "spatial and temporal coordinates" ]]
64 This is an excerpt from the supporting online materials produced for the PBS special Misunderstood Minds that profiles a variety of learning problems and expert opinions. These materials are designed to give parents and teachers a better understanding of learning processes, insights into difficulties and strategies for responding. This material is particularly relevant in understanding the challenges that arise in developing hybrid — symbolic-plus-connectionist — neural-network architectures that emulate various aspects — and, likely as not, deficits — of human cognition and are expected to acquire skills such as computer programming and mathematical thinking by some combination of machine learning and automated tutoring:
Math disabilities can arise at nearly any stage of a child's scholastic development. While very little is known about the neurobiological or environmental causes of these problems, many experts attribute them to deficits in one or more of five different skill types. These deficits can exist independently of one another or can occur in combination. All can impact a child's ability to progress in mathematics.
Incomplete Mastery of Number Facts: Number facts are the basic computations (9 + 3 = 12 or 2 x 4 = 8) students are required to memorize in the earliest grades of elementary school. Recalling these facts efficiently is critical because it allows a student to approach more advanced mathematical thinking without being bogged down by simple calculations.
Computational Weakness: Many students, despite a good understanding of mathematical concepts, are inconsistent at computing. They make errors because they misread signs or carry numbers incorrectly, or may not write numerals clearly enough or in the correct column. These students often struggle, especially in primary school, where basic computation and "right answers" are stressed. Often they end up in remedial classes, even though they might have a high level of potential for higher-level mathematical thinking.
Difficulty Transferring Knowledge: One fairly common difficulty experienced by people with math problems is the inability to easily connect the abstract or conceptual aspects of math with reality. Understanding what symbols represent in the physical world is important to how well and how easily a child will remember a concept. Holding and inspecting an equilateral triangle, for example, will be much more meaningful to a child than simply being told that the triangle is equilateral because it has three equal sides. And yet children with this problem find connections such as these painstaking at best.
Connections Between Separate Concepts: Some students have difficulty making meaningful connections within and across mathematical experiences. For instance, a student may not readily comprehend the relation between numbers and the quantities they represent. If this kind of connection is not made, math skills may be not anchored in any meaningful or relevant manner. This makes them harder to recall and apply in new situations.
Understanding of the Language of Math: For some students, a math disability is driven by problems with language. These children may also experience difficulty with reading, writing, and speaking. In math, however, their language problem is confounded by the inherently difficult terminology, some of which they hear nowhere outside of the math classroom. These students have difficulty understanding written or verbal directions or explanations, and find word problems especially difficult to translate.
Comprehending Visual and Spatial Aspects: A far less common problem — and probably the most severe — is the inability to effectively visualize math concepts. Students who have this problem may be unable to judge the relative size among three dissimilar objects. This disorder has obvious disadvantages, as it requires that a student rely almost entirely on rote memorization of verbal or written descriptions of math concepts that most people take for granted. Some mathematical problems also require students to combine higher-order cognition with perceptual skills, for instance, to determine what shape will result when a complex 3-D figure is rotated.
65 Excerpt from Pages 99-101 of The Symbolic Species: The Co-evolution of Language and the Brain [5] by Terrence Deacon:
In summary, then, symbols cannot be understood as an unstructured collection of tokens that map to a collection of referents because symbols don't just represent things in the world, they also represent each other. Because symbols do not directly refer to things in the world, but indirectly refer to them by virtue of referring to other symbols, they are implicitly combinatorial entities whose referential powers are derived by virtue of occupying determinate positions in an organized system of other symbols. Both their initial acquisition and their later use requires a combinatorial analysis. The structure of the whole system has a definite semantic topology that determines the ways symbols modify each other's referential functions in different combinations. Because of this systematic relational basis of symbolic reference, no collection of signs can function symbolically unless the entire collection conforms to certain overall principles of organization. Symbolic reference emerges from a ground of nonsymbolic referential processes only because the indexical relationships between symbols are organized so as to form a logically closed group of mappings from symbol to symbol. This determinate character allows the higher-order system of associations to supplant the individual (indexical) referential support previously invested in each component symbol. This system of relationships between symbols determines a definite and distinctive topology that all operations involving those symbols must respect in order to retain referential power. The structure implicit in the symbol-symbol mapping is not present before symbolic reference, but comes into being and affects symbol combinations from the moment it is first constructed. The rules of combination that are implicit in this structure are discovered as novel combinations are progressively sampled. As a result, new rules may be discovered to be emergent requirements of encountering novel combinatorial problems, in much the same way as new mathematical laws are discovered to be implicit in novel manipulations of known operations.Symbols do not, then, get accumulated into unstructured collections that can be arbitrarily shuffled into different combinations. The system of representational relationships, which develops between symbols as symbol systems grow, comprises an ever more complex matrix. In abstract terms, this is a kind of tangled hierarchic network of nodes and connections at defines a vast and constantly changing semantic space. Though semanticists and semiotic theorists have proposed various analogies to explain these underlying topological principles of semantic organization (such as +/- feature lists, dictionary analogies, encyclopedia analogies), we are far from a satisfactory account. Whatever the logic of this network of symbol-symbol relationships, it is inevitable that it will be reflected in the patterns of symbol-symbol combinations in communication.
Abstract theories of language, couched in terms of possible rules for combining unspecified tokens into strings, often implicitly assume that there is no constraint on theoretically possible combinatorial rule systems. Arbitrary strings of uninterpreted tokens have no reference and thus are unconstrained. But the symbolic use of tokens is constrained both by each token's use and by the use of other tokens with respect to which it is defined. Strings of symbols used to communicate and to accomplish certain ends must inherit both the intrinsic constraints of symbol-symbol reference and the constraints imposed by external reference.
Some sort of regimented combinatorial organization is a logical necessity for any system of symbolic reference. Without an explicit syntactic framework and an implicit interpretive mapping, it is possible neither to produce unambiguous symbolic information nor to acquire symbols in the first place. Because symbolic reference is inherently systemic, there can be no symbolization without systematic relationships. Thus syntactic structure is an integral feature of symbolic reference, not something added and separate. It is the higher-order combinatorial logic, grammar, that maintains and regulates symbolic reference; but how a specific grammar is organized is not strongly restricted by this requirement. There need to be precise combinatorial rules, yet a vast number are possible that do not ever appear in natural languages. Many other factors must be then into account in order to understand why only certain types of syntactic systems are actually employed in natural human languages and how we are able to learn the incredibly complicated rule systems that result.
So, before turning to the difficult problem of determining what it is about human brains that makes the symbolic recoding step so much easier for us than for the chimpanzees Sherman and Austin (and members of all other nonhuman species as well), it is instructive to reflect on the significance of this view of symbolization for theories of grammar and syntax. Not only does this analysis suggest that syntax and semantics are deeply interdependent facets of language—a view at odds with much current linguistic theory—it also forces us entirely to rethink current ideas about the nature of grammatical knowledge and how it comes to be acquired.
Excerpt from Pages 135-136 of The Symbolic Species: The Co-evolution of Language and the Brain [5] by Terrence Deacon:
The co-evolutionary argument that maps languages onto children's learning constraints caR be generalized one step further to connect to the most basic problem of language acquisition: decoding symbolic reference. Symbolic associations are preeminent examples of highly distributed relationships that are only very indirectly reflected in the correlative relationships between symbols and objects. As was demonstrated in the last chapter, this is because symbolic reference is indirect, based on a system of relationships among symbol tokens that recodes the referential regularities between their indexical links to objects. Symbols are easily utilized when the system-to-system coding is known, because at least superficial analysis can be reduced to a simple mapping problem, but it is essentially impossible to discover the coding given only the regularities of word-object associations. As in other distributed pattern-learning problems, the problem in symbol learning is to avoid getting attracted to learning potholes-tricked into focusing on the probabilities of individual sign-object associations and thereby missing the nonlocal marginal probabilities of symbol-symbol regularities. Learning even a simple symbol system demands an approach that postpones commitment to the most immediately obvious associations until after some of the less obvious distributed relationships are acquired. Only by shifting attention away from the details of word-object relationships is one likely to notice the existence of superordinate patterns of combinatorial relationships between symbols, and only if these are sufficiently salient is one likely to recognize the buried logic of indirect correlations and shift from a direct indexical mnemonic strategy to an indirect symbolic one.In this way, symbol learning in general has many features that are similar to the problem ofleaming the complex and indirect statistical architecture of syntax. This parallel is hardly a coincidence, because grammar and syntax inherit the constraints implicit in the logic of symbol-symbol relationships. These are not, in fact, separate learning problems, because systematic syntactic regularities are essential to ease the discovery of the combinatorial logic underlying symbols. The initial stages of the symbolic shift in mnemonic strategies almost certainly would be more counterintuitive for a quick learner, who learns the details easily, than for a somewhat impaired learner, who gets the big picture but seems to lose track of the details. In general, then, the initial shift to reliance on symbolic relationships, especially in a species lacking other symbol-learning supports, would be most likely to succeed ifthe process could be shifted to as young an age as possible. The evolution of symbolic communication systems has therefore probably been under selection for early acquisition from the beginning of their appearance in hominid communication. So it is no surprise that the optimal time for beginning to discover grammatical and syntactic regularities in language is also when symbolic reference is first discovered. However, the very advantages that immature brains enjoy in their ability to make the shift from indexical to symbolic referential strategies also limit the detail and complexity of what can be learned. Learning the details becomes possible with a maturing brain, but one that is less spontaneously open to such "insights." This poses problems for brain-language co-evolution that will occupy much of the rest of the book in one form or other. How do symbolic systems evolve structures that are both capable of being learned and yet capable of being highly complex? And how have human learning and language-use predispositions evolved to support these two apparently contrary demands?
Elissa Newport was one of the first to suggest that we should not necessarily think of children's learning proficiency in terms of the function of a special language-learning system. She suggests that the relationship might be reversed. Language structures may have preferentially adapted to children's learning biases and limitations because languages that are more easily acquired at an early age will tend to replicate more rapidly and with greater fidelity from generation to generation than those that take more time or neurological maturity to be mastered. As anyone who has tried to learn a second language for the first time as an adult can attest, one's first language tends to monopolize neural-cognitive resources in ways that make it more difficult for other languages to "move in" and ever be quite as efficient. Consequently, strong social selection forces will act on language regularities to reduce the age at which they can begin to be learned. Under constant selection pressure to be acquirable at ever earlier and earlier stages in development, the world's surviving languages have all evolved to be learnable at the earliest age possible. Languages may thus be more difficult to learn later in life only because they evolved to be easier to learn when immature. The critical period for language learning may not be critical or time limited at all, but a mere "spandrel,"19 or incidental feature of maturation, that just happened to be coopted in languages' race to colonize ever younger brains.
So immaturity itself may provide part of the answer to the paradoxical time-limited advantage for language learning that Kanzi demonstrates. Kanzi's immaturity made it easier to make the shift from indexical to symbolic reference and to learn at least the global grammatical logic hidden behind the surface structure of spoken English. But equally important is the fact that both the lexigram training paradigms used with his mother and the structure of English syntax itself had evolved in response to the difficulties this imposes, anq so had spontaneously become more conducive to the learning patterns of immature minds. The implications of Kanzi's advantages are relevant to human language acquisition as well, because if his prodigious abilities are not the result of engaging some special time-limited language acquisition module in his nonhuman brain, then such a critical period mechanism is unlikely to provide the explanation for the language prescience of human children either. The existence of a critical period for language learning is instead the expression of the advantageous limitations of an immature nervous system for the kind of learning problem that language poses. So immaturity itself may provide part of the answer to the paradoxical time-limited advantage for language learning that Kanzi demonstrates.
Kanzi's immaturity made it easier to make the shift from indexical to symbolic reference and to learn at least the global grammatical logic hidden behind the surface structure of spoken English. But equally important is the fact that both the lexigram training paradigms used with his mother and the structure of English syntax itself had evolved in response to the difficulties this imposes, anq so had spontaneously become more conducive to the learning patterns of immature minds. The implications of Kanzi's advantages are relevant to human language acquisition as well, because if his prodigious abilities are not the result of engaging some special time-limited language acquisition module in his nonhuman brain, then such a critical period mechanism is unlikely to provide the explanation for the language prescience of human children either. The existence of a critical period for language learning is instead the expression of the advantageous limitations of an immature nervous system for the kind of learning problem that language poses. And language poses the problem this way because it has specifically evolved to take advantage of what immaturity provides naturally. Nat being exposed to language while young deprives one of these learning advantages and makes both symbolic and syntactic learning far more difficult. Though older animals and children may be more cooperative, more attentive, have better memories, and in general may be better learners of many things than are toddlers, they gain these advantages at the expense of symbolic and syntactic learning predispositions. This is demonstrated by many celebrated "feral" children who, over the years, have been discovered after they grew up isolated from normal human discourse. Their persistent language limitations attest not to the turning off of a special language instinct but to the waning of a nonspecific language-learning bias.
66 Here are a few papers in the 2000 special issue on hippocampal-cortical interactions — use the Lavenex and Amaral [231] paper as a starting place to follow the citation trail forward in search of more recent papers:
@article{MaguireetalHIPPOCAMPUS-00,
author = {Maguire, Eleanor A. and Mummery, Catherine J. and B\"{u}chel, Christian},
title = {Patterns of hippocampal-cortical interaction dissociate temporal lobe memory subsystems},
journal = {Hippocampus},
volume = {10},
number = {4},
year = {2000},
pages = {475-482},
abstract = {Abstract A distributed network of brain regions supports memory retrieval in humans, but little is known about the functional interactions between areas within this system. During functional magnetic resonance imaging (fMRI), subjects retrieved real-world memories: autobiographical events, public events, autobiographical facts, and general knowledge. A common memory retrieval network was found to support all memory types. However, examination of the correlations (i.e., effective connectivity) between the activity of brain regions within the temporal lobe revealed significant changes dependent on the type of memory being retrieved. Medially, effective connectivity between the parahippocampal cortex and hippocampus increased for recollection of autobiographical events relative to other memory types. Laterally, effective connectivity between the middle temporal gyrus and temporal pole increased during retrieval of general knowledge and public events. The memory types that dissociate the common system into its subsystems correspond to those that typically distinguish between patients at initial phases of Alzheimer's disease or semantic dementia. This approach, therefore, opens the door to new lines of research into memory degeneration, capitalizing on the functional integration of different memory-involved regions. Indeed, the ability to examine interregional interactions may have important diagnostic and prognostic implications. Hippocampus 10:475–482, 2000 © 2000 Wiley-Liss, Inc.},
}
@article{LarocheetalHIPPOCAMPUS-00,
author = {Laroche, Serge and Davis, Sabrina and Jay, Th\'{e}r\`{e}se M.},
title = {Plasticity at hippocampal to prefrontal cortex synapses: Dual roles in working memory and consolidation},
journal = {Hippocampus},
volume = {10},
number = {4},
year = {2000},
pages = {438-446},
abstract = {Abstract The involvement of the hippocampus and the prefrontal cortex in cognitive processes and particularly in learning and memory has been known for a long time. However, the specific role of the projection which connects these two structures has remained elusive. The existence of a direct monosynaptic pathway from the ventral CA1 region of the hippocampus and subiculum to specific areas of the prefrontal cortex provides a useful model for conceptualizing the functional operations of hippocampal-prefrontal cortex communication in learning and memory. It is known now that hippocampal to prefrontal cortex synapses are modifiable synapses and can express different forms of plasticity, including long-term potentiation, long-term depression, and depotentiation. Here we review these findings and focus on recent studies that start to relate synaptic plasticity in the hippocampo-prefrontal cortex pathway to two specific aspects of learning and memory, i.e., the consolidation of information and working memory. The available evidence suggests that functional interactions between the hippocampus and prefrontal cortex in cognition and memory are more complex than previously anticipated, with the possibility for bidirectional regulation of synaptic strength as a function of the specific demands of tasks. Hippocampus 10:438–446, 2000 © 2000 Wiley-Liss, Inc.},
}
@article{OReillyandRudyHIPPOCAMPUS-00,
author = {O'Reilly, Randall C. and Rudy, Jerry W.},
title = {Computational principles of learning in the neocortex and hippocampus},
journal = {Hippocampus},
volume = {10},
number = {4},
year = {2000},
pages = {389-397},
abstract = {Abstract We present an overview of our computational approach towards understanding the different contributions of the neocortex and hippocampus in learning and memory. The approach is based on a set of principles derived from converging biological, psychological, and computational constraints. The most central principles are that the neocortex employs a slow learning rate and overlapping distributed representations to extract the general statistical structure of the environment, while the hippocampus learns rapidly, using separated representations to encode the details of specific events while suffering minimal interference. Additional principles concern the nature of learning (error-driven and Hebbian), and recall of information via pattern completion. We summarize the results of applying these principles to a wide range of phenomena in conditioning, habituation, contextual learning, recognition memory, recall, and retrograde amnesia, and we point to directions of current development. Hippocampus 10:389–397, 2000 © 2000 Wiley-Liss, Inc.},
}
@article{RollsHIPPOCAMPUS-00,
author = {Rolls, Edmund T.},
title = {Hippocampo-cortical and cortico-cortical backprojections},
journal = {Hippocampus},
volume = {10},
number = {4},
year = {2000},
pages = {380-388},
abstract = {Abstract First, the information represented in the primate hippocampus, and what is computed by the primate hippocampus, are considered. Then a theory is described of how the information represented in the hippocampus is able to influence the cerebral cortex by a hierarchy of hippocampo-cortical and cortico-cortical backprojection stages. The recalled backprojected information in the cerebral neocortex could then be used by the neocortex as part of memory recall, including that required in spatial working memory; to influence the processing that each cortical stage performs based on its forward inputs; to influence the formation of long-term memories; and/or in the selection of appropriate actions. Hippocampus 10:380–388, 2000 © 2000 Wiley-Liss, Inc.},
}
@article{LavenexandAmaralHIPPOCAMPUS-00,
author = {Lavenex, Pierre and Amaral, David G.},
title = {Hippocampal-neocortical interaction: A hierarchy of associativity},
journal = {Hippocampus},
volume = {10},
number = {4},
year = {2000},
pages = {420-430},
abstract = {Abstract The structures forming the medial temporal lobe appear to be necessary for the establishment of long-term declarative memory. In particular, they may be involved in the “consolidation” of information in higher-order associational cortices, perhaps through feedback projections. This review highlights the fact that the medial temporal lobe is organized as a hierarchy of associational networks. Indeed, associational connections within the perirhinal, parahippocampal, and entorhinal cortices enables a significant amount of integration of unimodal and polymodal inputs, so that only highly integrated information reaches the remainder of the hippocampal formation. The feedback efferent projections from the perirhinal and parahippocampal cortices to the neocortex largely reciprocate the afferent projections from the neocortex to these areas. There are, however, noticeable differences in the degree of reciprocity of connections between the perirhinal and parahippocampal cortices and certain areas of the neocortex, in particular in the frontal and temporal lobes. These observations are particularly important for models of hippocampal-neocortical interaction and long-term storage of information in the neocortex. Furthermore, recent functional studies suggest that the perirhinal and parahippocampal cortices are more than interfaces for communication between the neocortex and the hippocampal formation. These structures participate actively in memory processes, but the precise role they play in the service of memory or other cognitive functions is currently unclear. Hippocampus 10:420–430, 2000 © 2000 Wiley-Liss, Inc.},
}
67 Blumenbach had one big idea that no one took seriously. He was convinced about a special feature of humans, about which he could not have been more explicit. "Man,” he wrote in 1795, "is far more domesticated and far more advanced from his first beginnings than any other animal." In 1806 he explained that our species' domestication was due to biology: "There is only one domestic animal — domestic in the true sense, if not in the ordinary acceptation of this word — that also surpasses all others in these respects, and that is man. The difference between him and other domestic animals is only this, that they are not so completely born to domestication as he is, having been created by nature immediately a domestic animal." There was one big obstacle to the adoption of his thesis, so great that for a century Blumenbach's big idea was not taken seriously. The question was: how could the domestication of humans have happened? In the case of farmyard animals, humans were obviously responsible for the domesticating. But if humans were domesticated, who was responsible? Who could have domesticated our ancestors?
In his 1871 book on human evolution, The Descent of Man, and Selection in Relation to Sex, Darwin contemplated Blumenbach's proposition. If humans really were domesticated, he wanted to know how and why, alas he too got caught up in an infinite regress. Subsequently, human self-domestication in some form or other has been explored by evolutionarily minded scholars from an astonishing range of perspectives, including archaeology, social anthropology, biological anthropology, paleoanthropology, philosophy, psychiatry, psychology, ethology, biology, history, and economics. Everywhere, the essential rationale is the same. Our docile behavior recalls that of a domesticated species, and since no other species can have domesticated us, we must have done it ourselves. We must be self-domesticated. But how could that have happened?" — If you want to learn the answer, read Richard Wrangham's excellent The Goodness Paradox: How Evolution Made Us Both More and Less Violent from which this excerpt was adapted [401].
68 Ethology is the scientific and objective study of animal behavior, usually with a focus on behavior under natural conditions, and viewing behavior as an evolutionarily adaptive trait. Behaviorism is a term that also describes the scientific and objective study of animal behavior, usually referring to measured responses to stimuli or trained behavioral responses in a laboratory context, without a particular emphasis on evolutionary adaptivity (SOURCE)
69 SRI International (SRI) is an American nonprofit scientific research institute and organization headquartered in Menlo Park, California. The trustees of Stanford University established SRI in 1946 as a center of innovation to support economic development in the region. SRI performs client-sponsored research and development for government agencies, commercial businesses, and private foundations. It also licenses its technologies, forms strategic partnerships and creates spin-off companies. (SOURCE)
70 SNARC (Stochastic Neural Analog Reinforcement Calculator) is a neural net machine designed by Marvin Lee Minsky. George Miller gathered the funding for the project from the Air Force Office of Scientific Research in the summer of 1951. This machine is considered one of the first pioneering attempts at the field of artificial intelligence. Minsky went on to be a founding member of MIT's Project MAC, which split to become the MIT Laboratory for Computer Science and the MIT Artificial Intelligence Lab, and is now the MIT Computer Science and Artificial Intelligence Laboratory. (SOURCE)
71 The Dartmouth Summer Research Project on Artificial Intelligence was the name of a 1956 summer workshop now considered by many (though not all[3]) to be the seminal event for artificial intelligence as a field. The project lasted approximately six to eight weeks, and was essentially an extended brainstorming session. Eleven mathematicians and scientists were originally planned to be attendees, and while not all attended, more than ten others came for short times. (SOURCE)
72 The prevailing connectionist approach today was originally known as parallel distributed processing (PDP). It was an artificial neural network approach that stressed the parallel nature of neural processing, and the distributed nature of neural representations. It provided a general mathematical framework for researchers to operate in. The framework involved eight major aspects (SOURCE):
A set of processing units, represented by a set of integers.
An activation for each unit, represented by a vector of time-dependent functions.
An output function for each unit, represented by a vector of functions on the activations.
A pattern of connectivity among units, represented by a matrix of real numbers indicating connection strength.
A propagation rule spreading the activations via the connections, represented by a function on the output of the units.
An activation rule for combining inputs to a unit to determine its new activation, represented by a function on the current activation and propagation.
A learning rule for modifying connections based on experience, represented by a change in the weights based on any number of variables.
An environment that provides the system with experience, represented by sets of activation vectors for some subset of the units.
73 I've purchased three copies each of [Chater, 2018] and [Dehaene, 2014] that you are welcome to borrow from me, and the engineering library has one physical copy of each of the first four titles listed below plus an electronic copy of fifth [Dere et al] held on reserve for students taking CS379C:
@book{Chater2018,
title = {The Mind is Flat: The Illusion of Mental Depth and The Improvised Mind},
author = {Chater, Nick},
year = {2018},
publisher = {Penguin Books Limited}
}
@book{Dehaene2014,
title = {Consciousness and the Brain: Deciphering How the Brain Codes Our Thoughts},
author = {Stanislas Dehaene},
publisher = {Viking Press},
year = 2014,
}
@book{Deacon2012incomplete,
title = {Incomplete Nature: How Mind Emerged from Matter},
author = {Deacon, Terrence W.},
year = {2012},
publisher = {W. W. Norton}
}
@book{Deacon1998symbolic,
title = {The Symbolic Species: The Co-evolution of Language and the Brain},
author = {Deacon, Terrence W.},
year = {1998},
publisher = {W. W. Norton}
}
@book{Dereetal2008,
title = {Handbook of Episodic Memory},
editor = {Ekrem Dere and Alexander Easton and Lynn Nadel and Joseph P. Huston},
series = {Handbook of Behavioral Neuroscience},
publisher = {Elsevier},
volume = {18},
year = {2008}
}
74 Due to bilateral symmetry the brain has a hippocampus in each cerebral hemisphere. If damage to the hippocampus occurs in only one hemisphere, leaving the structure intact in the other hemisphere, the brain can retain near-normal memory functioning.
75 Technically, an exponential curve will have similar properties along its entire length. There's no specific value at which we can define to be the point when things going "really" fast, and in fact, your perception of how fast the graph will grow is dependent upon the axes you define. The more you compress the y axis, the faster the graph will appear to grow. However, a cursory glance at some exponential functions shows that humans have a tendency to say the "knee" of the curve would probably be around the point at which a line which appears to have a slope of one grows slower than the exponential curve. Again, a slope that appears to have slope one will in reality have a slope dependent upon the scale you use for each of the axes. — Posted by Austin Garrett, Research Assistant at MIT Computer Science and Artificial Intelligence Laboratory (SOURCE)
76 Excerpts from [67]. We have 4 copies (3 hardcover and 1 Kindle) that can be checked out on loan:
• The brain is continually scrambling to link together scraps of sensory information (and has the ability, of course, to gather more information, with a remarkably quick flick of the eye). We 'create' our perception of an entire visual world from a succession of fragments, picked up one at a time (see Chapter 2). Yet our conscious experience is merely the output of this remarkable process; we have little or no insight into the relevant sensory inputs or how they are combined.
• As soon as we query some aspects of the visual scene (or, equally, of our memory), then the brain immediately locks onto relevant information and attempts to impose meaning upon it. The process of creating such meaning is so fluent that we imagine ourselves merely to be reading off pre-existing information, to which we already have access, just as, when scrolling down the contents of a word processor, or exploring a virtual reality game, we have the illusion that the entire document, or labyrinth, pre-exist in all their glorious pixel-by-pixel detail (somewhere 'off-screen'). But, of course, they are created for us by the computer software at the very moment they are needed (e.g. when we scroll down or 'run' headlong down a virtual passageway). This is the sleight of hand that underlies the grand illusion (see Chapter 3).
• In perception, we focus on fragments of sensory information and impose what might be quite abstract meaning: the identity, posture, facial expression, intentions of another person, for example. But we can just as well reverse the process. We can focus on an abstract meaning, and create a corresponding sensory image: this is the basis of mental imagery. So just as we can recognize a tiger from the slightest of glimpses, we can also imagine a tiger — although, as we saw in Chapter 4, the sensory image we reconstruct is remarkably sketchy.
• Feelings are just one more thing we can pay attention to. An emotion is, as we saw in Chapter 5, the interpretation of a bodily state. So experiencing an emotion requires attending to one's bodily state as well as relevant aspects of the outer world: the interpretation imposes a 'story' linking body and world together. Suppose, for example, that Inspector Lestrade feels the physiological traces of negativity (perhaps he draws back, hunches his shoulders, his mouth turns down, he looks at the floor) as Sherlock Holmes explains his latest triumph. The observant Watson attends, successively, to Lestrade's demeanour and Holmes's words, searching for the meaning of these snippets, perhaps concluding: 'Lestrade is jealous of Holmes's brilliance.' But Lestrade's reading of his own emotions works in just the same way: he too must attend to, and interpret his own physiological state and Holmes's words in order to conclude that he is jealous of Holmes's brilliance. Needless to say, Lestrade may be thinking nothing of the kind — he may be trying (with frustratingly little success) to find flaws in Holmes's explanation of the case. If so, while Watson may interpret Lestrade as being jealous, Lestrade is not experiencing jealousy (of Holmes's brilliance, or anything else) — because experiencing jealousy results from a process of interpretation, in which jealous thoughts are the 'meaning' generated, but Lestrade's mind is attending to other matters entirely, in particular, the details of the case.
• Finally, consider choices (see Chapter 6). Recall how the left hemisphere of a split-brain patient fluently, though often completely spuriously, 'explains' the mysterious activity of the left hand — even though that hand is actually governed by the brain's right hemisphere. This is the left, linguistic brain's attempt to impose meaning on the left-hand movements: to create such meaningful (though, in the case of the split-brain patient, entirely illusory) explanation requires locking onto the activity of the left hand in order to make sense of it. It does not, in particular, involve locking onto any hidden inner motives lurking within the right hemisphere (the real controller of the left hand) because the left and right hemispheres are, of course, completely disconnected. But notice that, even if the hemispheres were connected, the left hemisphere would not be able to attend to the right hemisphere's inner workings — because the brain can only attend to the meaning of perceptual input (including the perception of one's own bodily state), not to any aspect of its own inner workings.
We are, in short, relentless improvisers, powered by a mental engine which is perpetually creating meaning from sensory input, step by step. Yet we are only ever aware of the meaning created; the process by which it arises is hidden. Our step-by-step improvisation is so fluent that we have the illusion that the 'answers' to whatever 'questions' we ask ourselves were 'inside our minds all along'. But, in reality, when we decide what to say, what to choose, or how to act, we are, quite literally, making up our minds, one thought at a time.
77 This is a cleaned-up version of my rough transcription of Chater's comments from a talk he gave at Google posted on the Talks at Google YouTube channel on May 22, 2018. My rough transcription doesn't do justice to his prepared talk since it was drawn from my scattered notes and this cleaned-up version doesn't do justice to his writing. I encourage you to purchase a copy of The Mind is Flat or check out the book from your local public library. You can find the relevant passage in the section of his book entitled "Rethinking the Boundary of Consciousness". For those of you taking the class at Stanford, I've purchased three copies that I can lend to students and I've asked the engineering library to put one or more copies on reserve.
78 I couldn't find an unassailable source for either citation or attribution, but here are two pieces of evidence — one quote from Popper's writing and one attribution by a reputable historian — that will have to do:
"Good tests kill flawed theories; we remain alive to guess again." As quoted in My Universe : A Transcendent Reality (2011) by Alex Vary, Part II [REFERENCE]
"If we are uncritical, we shall always find what we want: we shall look for, and find, confirmations, and we shall look away from, and not see, whatever might be dangerous to our pet theories. In this way it is only too easy to obtain what appears to be overwhelming evidence in favor of a theory which, if approached critically, would have been refuted." The Poverty of Historicism (1957) Ch. 29 The Unity of Method [REFERENCE]
79 Conduction aphasia is a rare form of aphasia, often specifically related damage in the arcuate fasciculus. An acquired language disorder, it is characterized by intact auditory comprehension, fluent speech production, but poor speech repetition. Patients are fully capable of understanding what they are hearing, but fail to encode phonological information for production. In the case of conduction aphasia, patients are still able to comprehend speech because the lesion does not disrupt the ventral stream pathway:
Studies have suggested that conduction aphasia is a result of damage specifically to the left superior temporal gyrus and/or the left supra marginal gyrus. The classical explanation for conduction aphasia is that of a disconnection between the brain areas responsible for speech comprehension (Wernicke's area) and speech production (Broca's area), due specifically to damage to the arcuate fasciculus, a deep white matter tract. Patients are still able to comprehend speech because the lesion does not disrupt the ventral stream pathway. SOURCE
80 This footnote serves as a parking spot for my notes on Nick Chater's The Mind is Flat. As an introduction and test to see if you are interested in his theory concerning human cognition, I suggest you start with his Google Talks book tour presentation. If you find that interesting, but still are not convinced enough that you want to read the book [67]. You might get a better idea by watching Episode #111 of the The Dissenter podcast hosted by Ricardo Lopes. Here is an excerpt relating to Chater's main thesis that we are misled by introspection into believing that below the threshold of our conscious thoughts there is a great deal of supporting unconscious thinking going on — unconscious, but of the same general depth and complexity as our conscious thoughts:
The things the brain does are very complicated, but they are nothing like the things we are consciously aware of. So I think using our conscious mind as a window into the brain is a disastrous error. It's like we think the mind is the tip of an iceberg. We see the iceberg poking out of the sea, and the illusion is that we think "I got the tip of the iceberg which is my flow of conscious experience, but I bet that the whole iceberg is just the same stuff". [...] The machinery that is operating is this incredibly complicated memory retrieval and reuse system which is searching our past experience and using that past experience to understand the present. [...] Like scanning all the faces you've seen in order to recognize a new face. All of that is fast and parallel, but its nothing like the sequential nature of the mind. I think the basic operation performed in these different areas [of the brain] is pretty much the same from one area to the next. They all involve perception memory in one way or another. Abstract thought whether mathematics, physics or the law [...] I think of these as all pretty much similar in spirit to thinking about and recognizing objects. [...] They are just more abstract versions of that. [There are some who believe that there are a number specialized systems handling different types of problems] The Toby and Cosmides Swiss Army knife model [120] [But I don't agree.] So I want to push against this [strong] modularity assumption.
Ricardo provides the following convenient bookmarks that take you directly to the relevant location in the podcast:
00:01:06 The basic premise of "The Mind is Flat"
00:05:33 We are like fictional characters
00:09:59 The problem with stories and narratives
00:13:58 The illusions our minds create (about motives, desires, goals, etc.)
00:17:44 The distinction between the conscious mind and brain activity
00:22:34 Does dualism make sense?
00:27:11 Is modularity of mind a useful approach?
00:31:21 How our perceptual systems work
00:41:49 How we represent things in our minds
00:44:57 The Kuleshov effect, and the interpretation of emotions
00:52:05 About preferences and personality
00:55:42 Why do we need our mental illusions?
00:59:10 The importance of our imagination
01:01:31 Can AI systems produce the same illusions (emotions, consciousness)?
Lament Over Sloshed Milk
Here are the last few lines of Chapter 2 entitled "Anatomy of a Hoax" in which Chater commiserates with himself and the reader over the fact — actually a presupposition — that scientists (might) have deluded themselves regarding some of the most basic facts about human cognition. I will certainly admit that he makes a good case for his view of how we experience and make sense of the world around us. His theory explains some of the predictions one could make concerning the models I've been working on and so I will have little reason to complain if he is proved right. But I will hold out for a while and watch for more experimental evidence before celebrating my modeling choices or adopting his theory wholesale.
From time to time, I have found myself wondering, somewhat despairingly, how much the last hundred and fifty years or so of psychology and neuroscience has really revealed about the secrets of human nature. How far have we progressed beyond what we can gather from philosophical reflection, the literary imagination, or from plain common sense? How much has the scientific study of our minds and brains revealed that really challenges our intuitive conception of ourselves?The gradual uncovering of the grand illusion through careful experimentation is a wonderful example of how startlingly wrong our intuitive conception of ourselves can be. And once we know the trick, we can see that it underlies the apparent solidity of our verbal explanations too. Just as the eye can dash into action to answer whatever question about the visual world I happen to ask myself, so my inventive mind can conjure up a justification for my actions, beliefs and motives, just as soon as I wonder about them. We wonder why puddles form or how electric and immediately we find explanations springing into our consciousness. And if we query any element of our explanation, more explanations spring into existence, and so on. Our powers of invention are so fluent that we can imagine that these explanations were pre-formed within us in all their apparently endless complexity. But, of course, each answer was created in the moment.
So whether we are considering sensory experience or verbal explanations, the story is the same. We are, it turns out, utterly wrong about a subject on which we might think we should be the ultimate arbiter: the contents of our own minds. Could we perhaps be equally or even more deluded when we turn to consider the workings of our imagination?
Collective Decision Making
Here is an extended thought experiment inspired by my reading of Chater's The Mind is Flat [67] that explores how Chater's theory of human cognition might play out in a collective endeavor:
When we engage in a group undertaking whether that be evaluating candidates for a job position or deciding upon a strategy for investing in new markets, we are collectively creating a shared illusion that serves as the basis of our own individual thinking as well as any possible consensus regarding, for example, specific actions being contemplated.
Think about what happens when one of us makes some contribution to the discussion whether it be a comment or criticism or an addition or modification to some possible outcome of our joint focus, say a job offer, contract or new species of investment. In voicing an opinion, we influence one another's mind state by how our contribution is individually and jointly perceived. Given what Nick Chater tells us about human behavior, it is highly likely that our contribution will be misunderstood and our resulting thoughts and those of others thinly apprehended but richly fantasized.
It makes sense to think of this shared space as a collection of thought clouds in the sense that Geoff Hinton uses the term. Each thought cloud is no more than a sparse representation of an individual’s state vector. It includes, among many other things, the activation of state variables that correspond to our internal representation of the mental states of those sitting around the table — a representation that is no doubt poorly informed and incredibly misleading.
These individual idiosyncratic representations of the evolving joint space are tied together very loosely by our notoriously error-prone efforts to read one another's thoughts, but, whether or not we are able to read "minds", there is still the possibility of interpreting what each contributor actually says or how they act. Alas, we are just as fallible in reading body language and interpreting intent from what is explicitly said or acted out in pose, gesture or facial tick.
As each participant voices their opinion, makes his or her case, expresses their support for or opposition to what was said earlier, all of the individual thought clouds are separately altered according to the inscrutable adjustments of diverse hormonal secretions and neuromodulatory chemical gradients. The individuals may believe — or possibly hope — that some consensus will eventually be reached; however, unless carefully led by a very skilled facilitator, the separate thought clouds will be cluttered, full of contradictions and misunderstandings and yet by some independent measure oddly aligned — which could be simply due to the length of time the meeting was scheduled for or the perceived duration necessary for this particular group to reach consensus.
There will very likely be a good deal of wishful thinking among those who either want the meeting to end quickly irregardless of the outcome, hope that a consensus can be amicably reached or have already reached their final opinion and will become increasingly more strident in support of their views as the meeting drags on. There will be those who will want — or pretend — to hear their colleagues voiced support for their ideas, but will interpret whatever they say to suit their own selfish interests and expectations.
In Chater’s theory, each one of us is a single thread of conscious thought informed by and constructed upon a history of memories dredged up in response to sensory input, in this case, resulting from what was seen and heard in the meeting. This means that, in particular, each one of us will have a different context depending on our own stored memories and the degree to which we have attended to the discussion in the meeting. This will result in a collection of state vectors that in the best of circumstances are only roughly aligned, and, in the more realistic case, significantly discordant.
It would be interesting to know what sort of dimensions are more likely to appear in some semblance of their current grounding in fact or that, while they may have a different valence, at least represent an emotional trajectory accounting for roughly the same physiological state across some fraction of the individuals present in the discussion. While I don't believe this sort of dimensional alignment is likely for dimensions of a more abstract sort, I wouldn't be surprised if one were able to do a factor analysis on all the different thought vectors represented in a given collective, that we might be able to identify factors representing some alignment that translates across individuals — one that plays an important role in our evolution as successful social organisms.
The picture I have in my head is of a collection of thought clouds with some dimensional alignment across individuals with respect to perceptually — and in particular emotionally — mediated factors but very little alignment across abstract dimensions that capture more of the concrete aspects of the collective-focus intended by those who organized the meeting in the first place. All of the usual cognitive biases are likely to be at play in the interactions going on during the meeting. Individual opinions will not be obviously manifest in behavior and will likely be repressed and prettified to make them more palatable to the group as a whole.
Moreover, many if not most of the individuals will likely misinterpret the opinions and other hidden state of their co-contributors, and also likely adjust the valence and magnitude of related dimensions to suit their own idiosyncratic beliefs and desires with respect to the outcome of the collective effort.
It would be instructive to imagine the sort of collective enterprise as playing out in a protracted meeting and how, for example, participants might align their viewpoints based upon a particularly articulate opinion rendered by someone thought highly — or perhaps fondly — of, versus some sort of discordant alignment resulting from an incoherent but forcefully rendered opinion by someone not well thought of. The exercise would be not be necessarily to figure out a strategy for effectively coming to a joint understanding so much as how cognition would play out given sparse serialized thought processes operating on internal representations that only thinly capture the collective experience and ground much of what is heard or seen in their own idiosyncratic, suspiciously self-promoting or self-effacing episodic memory.
As a logical next step along these lines, it would be interesting to ask how the outcome might be different in the case of a group of very smart, highly motivated, super engaged individuals with a history of working together and a facilitator of particularly sharp intellect, unusually well-calibrated emotional and social intelligence and highly motivated to do the right thing in charge of overseeing the meeting and fully invested in guiding the participants toward a consensus worth the effort.
In this case, the focus would be on how the participants might rise above their (instinctual) predilections by using the same cognitive substrate with the same energy and focus as they would devote to something they might find intellectually more satisfying such as writing code and solving interesting programming problems. Specifically, how can the basic cycle of apprehend (sense), attend (select), integrate personal experience (recall), and respond to an internal model of the present circumstances (act) be successfully applied to effectively make difficult decisions given what Chater refers to as the essentially "flat" character of our world view / internal model of present circumstances.
P.S. The original name of this file — Laughably_Sparse_Embarrassingly_Serial.txt — is a tongue-in-cheek reference to a model of parallel / distributed computation (https://en.wikipedia.org/wiki/Embarrassingly_parallel) that describes much of the parallelism available in modern industrial cloud services and corporate data and computing centers.
@article{ChristiansenandChaterBBS-08,
author = {Christiansen, M. H. and Chater, N.},
title = {Language as shaped by the brain},
journal = {Behavior Brain Science},
year = {2008},
volume = {31},
number = {5},
pages = {489-508},
abstract = {It is widely assumed that human learning and the structure of human languages are intimately related. This relationship is frequently suggested to derive from a language-specific biological endowment, which encodes universal, but communicatively arbitrary, principles of language structure (a Universal Grammar or UG). How might such a UG have evolved? We argue that UG could not have arisen either by biological adaptation or non-adaptationist genetic processes, resulting in a logical problem of language evolution. Specifically, as the processes of language change are much more rapid than processes of genetic change, language constitutes a "moving target" both over time and across different human populations, and, hence, cannot provide a stable environment to which language genes could have adapted. We conclude that a biologically determined UG is not evolutionarily viable. Instead, the original motivation for UG--the mesh between learners and languages--arises because language has been shaped to fit the human brain, rather than vice versa. Following Darwin, we view language itself as a complex and interdependent "organism," which evolves under selectional pressures from human learning and processing mechanisms. That is, languages themselves are shaped by severe selectional pressure from each generation of language users and learners. This suggests that apparently arbitrary aspects of linguistic structure may result from general learning and processing biases deriving from the structure of thought processes, perceptuo-motor factors, cognitive limitations, and pragmatics.}
}
@incollection{ChaterandChristiansenHLB-11,
title = {A solution to the logical problem of language evolution: language as an adaptation to the human brain},
author = {Nick Chater and Morten H. Christiansen},
booktitle = {The Oxford Handbook of Language Evolution},
editor = {Kathleen R. Gibson and Maggie Tallerman},
publisher = {Oxford University Press},
year = {2011},
abstract = {This article addresses the logical problem of language evolution that arises from a conventional universal grammar (UG) perspective and investigates the biological and cognitive constraints that are considered when explaining the cultural evolution of language. The UG prespective states that language acquisition should not be viewed as a process of learning at all but it should be viewed as a process of growth, analogous to the growth of the arm or the liver. UG is intended to characterize a set of universal grammatical principles that hold across all languages. Language has the same status as other cultural products, such as styles of dress, art, music, social structure, moral codes, or patterns of religious beliefs. Language may be particularly central to culture and act as the primary vehicle through which much other cultural information is transmitted. The biological and cognitive constraints helps to determine which types of linguistic structure tend to be learned, processed, and hence transmitted from person to person, and from generation to generation. The communicative function of language is likely to shape language structure in relation to the thoughts that are transmitted and regarding the processes of pragmatic interpretation that people use to understand each other's behavior. A source of constraints derives from the nature of cognitive architecture, including learning, processing, and memory. The language processing involves generating and decoding regularities from highly complex sequential input, indicating a connection between general-purpose cognitive mechanisms for learning and processing sequential material, and the structure of natural language.}
}
@article{ChateretalJML-16,
title = {Language as skill: Intertwining comprehension and production},
author = {Nick Chater and Stewart M. McCauley and Morten H. Christiansen},
journal = {Journal of Memory and Language},
volume = {89},
pages = {244-254},
year = {2016},
abstract = {Are comprehension and production a single, integrated skill, or are they separate processes drawing on a shared abstract knowledge of language? We argue that a fundamental constraint on memory, the Now-or-Never bottleneck, implies that language processing is incremental and that language learning occurs on-line. These properties are difficult to reconcile with the ‘abstract knowledge’ viewpoint, and crucially suggest that language comprehension and production are facets of a unitary skill. This viewpoint is exemplified in the Chunk-Based Learner, a computational acquisition model that processes incrementally and learns on-line. The model both parses and produces language; and implements the idea that language acquisition is nothing more than learning to process. We suggest that the Now-or-Never bottleneck also provides a strong motivation for unified perception-production models in other domains of communication and cognition.}
}
81 Table of Contents for the Handbook of Episodic Memory [108]:
Title: Handbook of Episodic Memory
Publication date: 2008
Keywords: Memory, Episodic; Cognitive Neuroscience.
Series: Handbook of Behavioral Neuroscience, Volume 18.
Editor: Dere, Ekrem; Easton, Alexander; Huston, Joseph; Nadel, Lynn.
Bibliography: Includes bibliographical references and index.
Table of Contents
Perspectives on episodic and semantic memory retrieval / Lee Ryan, Siobhan Hoscheidt and Lynn Nadel
Exploring episodic memory / Martin A. Conway
Episodic memory and mental time travel / Thomas Suddendorf and Michael C. Corballis
Episodic memory: Reconsolidation / Lynn Nadel ... [et al.]
Attributes of episodic memory processing / Michael R. Hunsaker and Raymond P. Kesner
Cognitive and neural bases of flashbulb memories / Patrick S.R. Davidson
From the past into the future: The development origins and trajectory of episodic future thinking / Cristina M. Atance
Emotion and episodic memory / Philip A. Allen, Kevin P. Kaut and Robert R. Lord
Current status of cognitive time travel research in animals / William A. Roberts
Animal episodic memory / Ekrem Dere ... [et al.]
New working definition of episodic memory: Replacing "when" and "which" / Alexander Easton and Madeline J. Eacott
Episodic-like memory in food-hoarding birds / Gesa Feenders and Tom V. Smulders
Representing past and future events / Thomas R. Zentall
Functional neuroanatomy of remote, episodic memory / Morris Moscovitch ... [et al.]
Medial temporal lobe: Visual perception and recognition memory / Yael Shrager and Larry R. Squire
Toward a neurobiology of episodic memory / Howard Eichenbaum ... [et al.]
Spatio-temporal context and object recognition memory in rodents / Mark Good
Role of the prefrontal cortex in episodic memory / Matthias Brand and Hans J. Markowitsch
Basal forebrain and episodic memory / Toshikatsu Fujii
Role of the precuneus in episodic memory / Michael R. Trimble and Andrea E. Cavanna
Multiple roles of dopaminergic neurotransmission in episodic memory / Björn H. Schott and Emrah Düzel
Neural coding of episodic memory / Joe Z. Tsien
Primate hippocampus and episodic memory / Edmund T. Rolls
Hippocampal neuronal activity and episodic memory / Emma R. Wood and Livia de Hoz
Hippocampus, context processing and episodic memory / David M. Smith
Memory and perceptual impairments in amnesia and dementia / Kim S. Graham, Andy C.H. Lee and Morgan D. Barense
Using hippocampal amnesia to understand the neural basis of diencephalic amnesia / John P. Aggleton, [et al.]
Structure-function correlates of episodic memory in aging / Jonas Persson and Lars Nyberg
Memory and cognitive performance in preclinical Alzheimer's and Vascular disease / Brent J. Small [et al.]
Transgenic mouse models of Alzheimer's disease and episodic-like memory / David R. Borchelt and Alena V. Savonenko
Episodic memory in the context of cognitive control dysfunction: Huntington's disease / Francois Richer [et al.]
Adrenal steroids and episodic memory: Relevance to mood disorders / Hamid A. Alhaj and R. Hamish McAllister-Williams
82 Note that the temporal lobe has a lot going on in it that relates to the meaning of what we see and hear:
The inferior temporal gyrus is placed below the middle temporal gyrus, and is connected behind with the inferior occipital gyrus; it also extends around the infero-lateral border on to the inferior surface of the temporal lobe, where it is limited by the inferior sulcus. This region is one of the higher levels of the ventral stream of visual processing, associated with the representation of complex object features, such as global shape. It may also be involved in face perception, and in the recognition of numbers.The inferior temporal gyrus is the anterior region of the temporal lobe located underneath the central temporal sulcus. The primary function of the occipital temporal gyrus — otherwise referenced as IT cortex — is associated with visual stimuli processing, namely visual object recognition, and has been suggested by recent experimental results as the final location of the ventral cortical visual system. The IT cortex in humans is also known as the Inferior Temporal Gyrus since it has been located to a specific region of the human temporal lobe. The IT processes visual stimuli of objects in our field of vision, and is involved with memory and memory recall to identify that object; it is involved with the processing and perception created by visual stimuli amplified in the V1, V2, V3, and V4 regions of the occipital lobe. This region processes the color and form of the object in the visual field and is responsible for producing the "what" from this visual stimuli, or in other words identifying the object based on the color and form of the object and comparing that processed information to stored memories of objects to identify that object.
The IT cortex's neurological significance is not just its contribution to the processing of visual stimuli in object recognition but also has been found to be a vital area with regards to simple processing of the visual field, difficulties with perceptual tasks and spatial awareness, and the location of unique single cells that possibly explain the IT cortex's relation to memory. (https://en.wikipedia.org/wiki/Inferior_temporal_gyrusSOURCE)
83 Page 126, Chapter 9: Different Voices. In The Voices Within by Charles Fernyhough [124]:
Yes and no. The inner speech theory of voice hearing really became established in the 1990s with the work of Chris Frith and Richard Bentall, who, working independently, developed Feinberg's ideas in slightly different directions. In one research group, Frith and his colleagues at University College London were developing a theory that the symptoms of schizophrenia stemmed from a problem in monitoring one's own actions. In an early study from their group, patients with the diagnosis did not do so well as a control group in a task that involved correcting the errors they made when moving a joystick. The idea was that, if you had a problem in monitoring your own behavior, you might fail to recognize some of the actions that you yourself produced as being your own work. And that could include inner speech: the words you produced, for yourself, in your own head.
84 Here is a summary of Terrence Deacon's Incomplete Nature: How Mind Emerged from Matter borrowing liberally from the Wikipedia page and recent interviews:
Ententional Phenomena:Broadly, the book seeks to naturalistically explain aboutness, that is, concepts like intentionality, meaning, normativity, purpose, and function; which Deacon groups together and labels as ententional phenomena.
Constraints:
A central thesis is that absence can still be efficacious. Deacon makes the claim that just as the concept of zero revolutionized mathematics, thinking about life, mind, and other ententional phenomena in terms of constraints (i.e., what is absent). A good example of this concept is the hole that defines the hub of a wagon wheel. The hole itself is not a physical thing, but rather a source of constraint that helps to restrict the conformational possibilities of the wheel's components, such that, on a global scale, the property of rolling emerges.
Constraints which produce emergent phenomena may not be a process that can be understood by looking at the make-up of the constituents of a pattern. Emergent phenomena are difficult to study because their complexity does not necessarily decompose into parts. When a pattern is broken down, the constraints are no longer at work; there is no hole, no absence to notice. Imagine a hub, a hole for an axle, produced only when the wheel is rolling, thus breaking the wheel may not show you how the hub emerges.
Homeodynamic Systems:
Homeodynamic systems are essentially equivalent to classical thermodynamic systems like a gas under pressure or solute in solution, but the term serves to emphasize that homeodynamics is an abstract process that can be realized in forms beyond the scope of classic thermodynamics. For example, the diffuse brain activity normally associated with emotional states can be considered to be a homeodynamic system because there is a general state of equilibrium which its components (neural activity) distribute towards. In general, a homeodynamic system is any collection of components that will spontaneously eliminate constraints by rearranging the parts until a maximum entropy state (disorderliness) is achieved.
Morphodynamic Systems:
A morphodynamic system consists of a coupling of two homeodynamic systems such that the constraint dissipation of each complements the other, producing macroscopic order out of microscopic interactions. Morphodynamic systems require constant perturbation to maintain their structure, so they are relatively rare in nature. Common examples are snowflake formation, whirlpools and the stimulated emission of laser light.
Teleodynamic Systems:
A teleodynamic system consists of coupling two morphodynamic systems such that the self-undermining quality of each is constrained by the other. Each system prevents the other from dissipating all of the energy available, and so long-term organizational stability is obtained. Deacon claims that we should pinpoint the moment when two morphodynamic systems reciprocally constrain each other as the point when ententional qualities like function, purpose and normativity emerge.
85 Terrence Deacon offers his view on Chomsky's universal grammar in this excerpt from The Symbolic Species [5]. If you have access to a copy (PDF) of Deacon's book, I recommend the clarity and conciseness of Figure 1.1 and its associated caption, showing four cartoon depictions of some of the major theoretical paradigms proposed to explain the basis of human language:
Interpreting the discontinuity between linguistic and nonlinguistic communication as an essential distinction between humans and nonhumans, however, has led to an equally exaggerated and untenable interpretation of language origins: the claim that language is the product of a unique one-of-a-kind piece of neural circuitry that provides all the essential features that make language unique (e.g., grammar). But this does not just assume that there is a unique neurological feature that correlates with this unique behavior, it also assumes an essential biological discontinuity. In other words, that language is somehow separate from the rest of our biology and neurology. It is as though we are apes plus language - as though one handed a language computer to a chimpanzee.The single most influential "hopeful monster" theory of human language evolution was offered by the linguist Noam Chomsky, and has since been echoed by numerous linguists, philosophers, anthropologists, and psychologists. Chomsky argued that the ability of children to acquire the grammar of their first language, and the ability of adults effortlessly to use this grammar, can only be explained if we assume that all grammars are variations of a single generic "Universal Grammar," and that all human brains come with a built-in language organ that contains this language blueprint. This is offered as the only plausible answer to an apparently insurmountable learning problem.
Grammars appear to have an unparalleled complexity and systematic logical structure, the individual grammatical "rules" aren't explicitly evident in the information available to the child, and when they acquire their first language children are still poor at learning many other things. Despite these limitations children acquire language knowledge at a remarkable rate. This leads to the apparently inescapable conclusion that language information must already be "in the brain" before the process begins in order for it to be successful. Children must already "know" what constitutes an allowable grammar, in order to be able to ignore the innumerable false hypotheses about grammar that their limited expelience might otherwise suggest.
Bruno Dubuc summarizes the view of Philip Lieberman and Deacon on the plausibility of an innate language facility in the form of a universal agreement as follows:
Since Chomsky first advanced these theories, however, evolutionary biologists have undermined them with the proposition that it may be only the brain’s general abilities that are "pre-organized". These biologists believe that to try to understand language, we must approach it not from the standpoint of syntax, but rather from that of evolution and the biological structures that have resulted from it. According to Philip Lieberman [19, 20], for example, language is not an instinct encoded in the cortical networks of a "language organ", but rather a learned skill based on a "functional language system" distributed across numerous cortical and subcortical structures.Though Lieberman does recognize that human language is by far the most sophisticated form of animal communication, he does not believe that it is a qualitatively different form, as Chomsky claims. Lieberman sees no need to posit a quantum leap in evolution or a specific area of the brain that would have been the seat of this innovation. On the contrary, he says that language can be described as a neurological system composed of several separate functional abilities.
For Lieberman and other authors, such as Terrence Deacon, it is the neural circuits of this system, and not some "language organ", that constitute a genetically predetermined set that limits the possible characteristics of a language. In other words, these authors believe that our ancestors invented modes of communication that were compatible with the brain’s natural abilities. And the constraints inherent in these natural abilities would then have manifested themselves in the universal structures of language.
86 It appears to have been Louis Pasteur who said — modulo the translator's choice of wording, "Where observation is concerned, chance favors only the prepared mind."
87 Here is a concise explanation of how fMRI works: The human body is mostly water. Water molecules (H2O) contain hydrogen nuclei (protons), that become aligned in a magnetic field. An MRI scanner applies a very strong magnetic field (about 0.2 to 3 teslas, or roughly a thousand times the strength of the small magnets used to post reminders and grocery lists on the door of a refrigerator), which aligns the proton "spins."
The scanner also produces a radio frequency current that creates a varying magnetic field. The protons absorb the energy from the magnetic field and flip their spins. When the field is turned off, the protons gradually return to their normal spin, a process called precession. The return process produces a radio signal that can be measured by receivers in the scanner and made into an image.
This professionally produced video from the National Institute of Biological Imaging and Bioengineering (NIBIB) provides much the same explanation along with a visual accompaniment. The Center for Functional MRI at UCSD has a more comprehensive introduction to fMRI including an explanation of the blood oxygenation level dependent (BOLD) effect and its application in brain imaging.
88 The bAbI tasks [396] are generated using simulator described by the authors as follows: "The idea is that generating text within this simulation allows us to ground the language used into a coherent and controlled (artificial) world. [...] To produce more natural looking text with lexical variety from statements and questions we employ a simple automated grammar. Each verb is assigned a set of synonyms, e.g., the simulation command get is replaced with either picked up, got, grabbed or took, and drop is replaced with either dropped, left, discarded or put down."
89 Dynamic Memory Networks (DMN) are a general framework for question answering over inputs. Conceptually, a difference is made between inputs and questions. The DMN takes a sequence of inputs and a question and then employs an iterative attention process to compute the answer. The sequence of inputs can be seen as the history, which complements the general world knowledge (see semantic memory module). The DNM framework consists of five components: (i) input module: processes raw input and maps it to a useful representation, (ii) semantic memory module: stores general knowledge about concepts and facts. It can be instantiated by word embeddings or knowledge bases, (iii) question module: maps a question into a representation, (iv) episodic memory module: an iterative component that in each iteration focuses on different parts of the input, updates its internal state and finally outputs an answer representation (vi) answer module: generates the answer to return. See [403] and [220] for DMN applications in computer vision and natural language processing.
90 See Gretto [162] for a brief introduction to reproducing kernel Hilbert spaces and related kernel functions.
91 In [16], Hofstadter asks two questions "Why do babies not remember events that happen to them?" and "Why does each new year seem to pass faster than the one before?". He then answers them as follows:
I wouldn't swear that I have the final answer to either one of these queries, but I do have a hunch, and I will here speculate on the basis of that hunch. And thus: the answer to both is basically the same, I would argue, and it has to do with the relentless, lifelong process of chunking — taking "small" concepts and putting them together into bigger and bigger ones, thus recursively building up a giant repertoire of concepts in the mind. How, then, might chunking provide the clue to these riddles? Well, babies' concepts are simply too small. They have no way of framing entire events whatsoever in terms of their novice concepts. It is as if babies were looking at life through a randomly drifting keyhole, and at each moment could make out only the most local aspects of scenes before them. It would be hopeless to try to figure out how a whole room is organized, for instance, given just a keyhole view, even a randomly drifting keyhole view.Or, to trot out another analogy, life is like a chess game, and babies are like beginners looking at a complex scene on a board, not having the faintest idea how to organize it into higher-level structures. As has been well known for decades, experienced chess players chunk the setup of pieces on the board nearly instantaneously into small dynamic groupings defined by their strategic meanings, and thanks to this automatic, intuitive chunking, they can make good moves nearly instantaneously and also can remember complex chess situations for very long times. Much the same holds for bridge players, who effortlessly remember every bid and every play in a game, and months later can still recite entire games at the drop of a hat.
All of this is due to chunking, and I speculate that babies are to life as novice players are to the games they are learning — they simply lack the experience that allows understanding (or even perceiving) of large structures, and so nothing above a rather low level of abstraction gets perceived at all, let alone remembered in later years. As one grows older, however, one's chunks grow in size and in number, and consequently one automatically starts to perceive and to frame ever larger events and constellations of events; by the time one is nearing one's teen years, complex fragments from life's stream are routinely stored as high-level wholes — and chunks just keep on accreting and becoming more numerous as one lives. Events that a baby or young child could not have possibly perceived as such — events that stretch out over many minutes, hours, days, or even weeks — are effortlessly perceived and stored away as single structures with much internal detail (varying amounts of which can be pulled up and contemplated in retrospect, depending on context). Babies do not have large chunks and simply cannot put things together coherently. Claims by some people that they remember complex events from when they were but a few months old (some even claim to remember being born!) strike me as nothing more than highly deluded wishful thinking.
So much for question number one. As for number two, the answer, or so I would claim, is very similar. The more we live, the larger our repertoire of concepts becomes, which allows us to gobble up ever larger coherent stretches of life in single mental chunks. As we start seeing life's patterns on higher and higher levels, the lower levels nearly vanish from our perception. This effectively means that seconds, once so salient to our baby selves, nearly vanish from sight, and then minutes go the way of seconds, and soon so do hours, and then days, and then weeks [...] (SOURCE)
92 In his theory for how humans might transfer knowledge that could serve to reconfigure the learning space by altering the energy landscape, Bengio [38] notes that:
A richer form of communication, which would already be useful, would require simply naming objects in a scene. Humans have an innate understanding of the pointing gesture that can help identify which object in the scene is being named. In this way, the learner could develop a repertoire of object categories which could become handy (as intermediate concepts) to form theories about the world that would help the learner to survive better. Richer linguistic constructs involve the combination of concepts and allow the agents to describe relations between objects, actions and events, sequences of events (stories), causal links, etc., which are even more useful to help a learner form a powerful model of the environment.
93 Bengio points out that this hypothesis is related to much previous work in cognitive science, such as for example cognitive imitation [353], which has been observed in monkeys, and where the learner imitates not just a vocalization or a behavior but something more abstract that corresponds to a cognitive rule.
94 A meme is an idea, behavior, or style that spreads from person to person within a culture — often with the aim of conveying a particular phenomenon, theme, or meaning represented by the meme [81]. A meme acts as a unit for carrying cultural ideas, symbols, or practices, that can be transmitted from one mind to another through writing, speech, gestures, rituals, or other imitable phenomena with a mimicked theme. SOURCE
95 Here is a sample of references related Yoshua Bengio's work on using language to expedite learning high-level abstractions by regularizing the deep architectures required to represent such abstractions:
@article{BengioCoRR-12,
author = {Yoshua Bengio},
title = {Evolving Culture vs Local Minima},
journal = {CoRR},
volume = {arXiv:1203.2990},
year = {2012},
abstract = {We propose a theory that relates difficulty of learning in deep architectures to culture and language. It is articulated around the following hypotheses: (1) learning in an individual human brain is hampered by the presence of effective local minima; (2) this optimization difficulty is particularly important when it comes to learning higher-level abstractions, i.e., concepts that cover a vast and highly-nonlinear span of sensory configurations; (3) such high-level abstractions are best represented in brains by the composition of many levels of representation, i.e., by deep architectures; (4) a human brain can learn such high-level abstractions if guided by the signals produced by other humans, which act as hints or indirect supervision for these high-level abstractions; and (5), language and the recombination and optimization of mental concepts provide an efficient evolutionary recombination operator, and this gives rise to rapid search in the space of communicable ideas that help humans build up better high-level internal representations of their world. These hypotheses put together imply that human culture and the evolution of ideas have been crucial to counter an optimization difficulty: this optimization difficulty would otherwise make it very difficult for human brains to capture high-level knowledge of the world. The theory is grounded in experimental observations of the difficulties of training deep artificial neural networks. Plausible consequences of this theory for the efficiency of cultural evolutions are sketched.}
}
@article{BengioCoRR-17,
author = {Yoshua Bengio},
title = {The Consciousness Prior},
journal = {CoRR},
volume = {arXiv:1709.08568},
year = {2017},
abstract = {A new prior is proposed for representation learning, which can be combined with other priors in order to help disentangling abstract factors from each other. It is inspired by the phenomenon of consciousness seen as the formation of a low-dimensional combination of a few concepts constituting a conscious thought, i.e., consciousness as awareness at a particular time instant. This provides a powerful constraint on the representation in that such low-dimensional thought vectors can correspond to statements about reality which are either true, highly probable, or very useful for taking decisions. The fact that a few elements of the current state can be combined into such a predictive or useful statement is a strong constraint and deviates considerably from the maximum likelihood approaches to modeling data and how states unfold in the future based on an agent's actions. Instead of making predictions in the sensory (e.g. pixel) space, the consciousness prior allow the agent to make predictions in the abstract space, with only a few dimensions of that space being involved in each of these predictions. The consciousness prior also makes it natural to map conscious states to natural language utterances or to express classical AI knowledge in the form of facts and rules, although the conscious states may be richer than what can be expressed easily in the form of a sentence, a fact or a rule.}
}
@inproceedings{BengioCOGSCI-14,
author = {Bengio, Yoshua},
title = {Deep learning, Brains and the Evolution of Culture},
booktitle = {Proceedings of the 36th Annual Conference of the Cognitive Science Society Workshop on Deep Learning and the Brain},
publisher = {Cognitive Science Society},
location = {Quebec City, Quebec, Canada},
year = {2014},
}
@inproceedings{BengioCGEC-14,
author = {Bengio, Yoshua},
title = {Deep learning and cultural evolution},
booktitle = {Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation},
publisher = {ACM},
location = {New York, NY, USA},
year = {2014},
abstract = {We propose a theory and its first experimental tests, relating difficulty of learning in deep architectures to culture and language. The theory is articulated around the following hypotheses: learning in an individual human brain is hampered by the presence of effective local minima, particularly when it comes to learning higher-level abstractions, which are represented by the composition of many levels of representation, i.e., by deep architectures; a human brain can learn such high-level abstractions if guided by the signals produced by other humans, which act as hints for intermediate and higher-level abstractions; language and the recombination and optimization of mental concepts provide an efficient evolutionary recombination operator for this purpose. The theory is grounded in experimental observations of the difficulties of training deep artificial neural networks and an empirical test of the hypothesis regarding the need for guidance of intermediate concepts is demonstrated. This is done through a learning task on which all the tested machine learning algorithms failed, unless provided with hints about intermediate-level abstractions.}
}
@article{PascanuetalCoRR-14,
author = {Razvan Pascanu and Yann N. Dauphin and Surya Ganguli and Yoshua Bengio},
title = {On the saddle point problem for non-convex optimization},
journal = {CoRR},
volume = {arXiv:1405.4604},
year = 2014,
abstract = {A central challenge to many fields of science and engineering involves minimizing non-convex error functions over continuous, high dimensional spaces. Gradient descent or quasi-Newton methods are almost ubiquitously used to perform such minimizations, and it is often thought that a main source of difficulty for the ability of these local methods to find the global minimum is the proliferation of local minima with much higher error than the global minimum. Here we argue, based on results from statistical physics, random matrix theory, and neural network theory, that a deeper and more profound difficulty originates from the proliferation of saddle points, not local minima, especially in high dimensional problems of practical interest. Such saddle points are surrounded by high error plateaus that can dramatically slow down learning, and give the illusory impression of the existence of a local minimum. Motivated by these arguments, we propose a new algorithm, the saddle-free Newton method, that can rapidly escape high dimensional saddle points, unlike gradient descent and quasi-Newton methods. We apply this algorithm to deep neural network training, and provide preliminary numerical evidence for its superior performance.}
}
@inproceedings{HamricketalCSS-18,
author = {Jessica B. Hamrick and Kelsey R. Allen and Victor Bapst and Tina Zhu and Kevin R. McKee and Joshua B. Tenenbaum and Peter W. Battaglia},
title = {Relational inductive bias for physical construction in humans and machines},
booktitle = {Proceedings of the 40th Annual Conference of the Cognitive Science Society},
year = {2018},
abstract = {While current deep learning systems excel at tasks such as object classification, language processing, and gameplay, few can construct or modify a complex system such as a tower of blocks. We hypothesize that what these systems lack is a "relational inductive bias": a capacity for reasoning about inter-object relations and making choices over a structured description of a scene. To test this hypothesis, we focus on a task that involves gluing pairs of blocks together to stabilize a tower, and quantify how well humans perform. We then introduce a deep reinforcement learning agent which uses object- and relation-centric scene and policy representations and apply it to the task. Our results show that these structured representations allow the agent to outperform both humans and more naive approaches, suggesting that relational inductive bias is an important component in solving structured reasoning problems and for building more intelligent, flexible machines.}
}
@inproceedings{BattagliaetalNIPS-16,
author = {Battaglia, Peter and Pascanu, Razvan and Lai, Matthew and Rezende, Danilo Jimenez and kavukcuoglu, Koray},
title = {Interaction Networks for Learning About Objects, Relations and Physics},
booktitle = {Proceedings of the 30th International Conference on Neural Information Processing Systems},
publisher = {Curran Associates Inc.},
location = {Barcelona, Spain},
year = {2016},
pages = {4509-4517},
abstract = {Reasoning about objects, relations, and physics is central to human intelligence, and a key goal of artificial intelligence. Here we introduce the interaction network, a model which can reason about how objects in complex systems interact, supporting dynamical predictions, as well as inferences about the abstract properties of the system. Our model takes graphs as input, performs object- and relation-centric reasoning in a way that is analogous to a simulation, and is implemented using deep neural networks. We evaluate its ability to reason about several challenging physical domains: n-body problems, rigid-body collision, and non-rigid dynamics. Our results show it can be trained to accurately simulate the physical trajectories of dozens of objects over thousands of time steps, estimate abstract quantities such as energy, and generalize automatically to systems with different numbers and configurations of objects and relations. Our interaction network implementation is the first general-purpose, learnable physics engine, and a powerful general framework for reasoning about object and relations in a wide variety of complex real-world domains.},
}
96 Here is a very brief summary of the different processes involved in human memory consolidation:
Memory consolidation is a category of processes that stabilize a memory trace after its initial acquisition.[1] Consolidation is distinguished into two specific processes, synaptic consolidation, which is synonymous with late-phase long-term potentiation and occurs within the first few hours after learning, and systems consolidation, where hippocampus-dependent memories become independent of the hippocampus over a period of weeks to years. Recently, a third process has become the focus of research, reconsolidation, in which previously-consolidated memories can be made labile again through reactivation of the memory trace. (SOURCE)
97 An inductive bias allows a learning algorithm to prioritize one solution (or interpretation) over another, independent of the observed data [263]. The inductive bias of a learning algorithm is the set of assumptions that the learner uses to predict outputs given inputs that it has not encountered. In a Bayesian model, inductive biases are typically expressed through the choice and parameterization of the prior distribution. In other contexts, an inductive bias might be a regularization term added to avoid overfitting, or it might be encoded in the architecture of the algorithm itself. SOURCE
98 In the mammalian brain, information pertaining to sensing and motor control is topographically mapped to reflect the intrinsic structure of that information required for interpretation. This was early recognized in the work of Hubel and Wiesel [195, 194] on the striate cortex of the cat and macaque monkey and in the work of Wilder Penfield [298] developing the idea of a cortical homunculus in the primary motor and somatosensory areas of the brain located between the parietal and frontal lobes of the primate cortex. Such maps have become associated with the theory of embodied cognition.
99 Papers on incorporating episodic memory in dialogue and recent techniques for augmenting dialogue data via active learning:
@inproceedings{SieberandKrennACL-10,
author = {Gregor Sieber and Brigitte Krenn},
title = {Episodic Memory for Companion Dialogue},
booktitle = {Proceedings of the 2010 Workshop on Companionable Dialogue Systems},
publisher = {Association for Computational Linguistics},
pages = {2010},
year = {1–6},
abstract = {We present an episodic memory component for enhancing the dialogue of artificial companions with the capability to refer to, take up and comment on past interactions with the user, and to take into account in the dialogue long-term user preferences and interests. The proposed episodic memory is based on RDF representations of the agent’s experiences and is linked to the agent’s semantic memory containing the agent’s knowledge base of ontological data and information about the user’s interests.}
}
@article{SuetalCoRR-16,
author = {Pei{-}Hao Su and Milica Gasic and Nikola Mrksic and Lina Maria Rojas{-}Barahona and Stefan Ultes and David Vandyke and Tsung{-}Hsien Wen and Steve J. Young},
title = {On-line Active Reward Learning for Policy Optimisation in Spoken Dialogue Systems},
journal = {CoRR},
volume = {arXiv:1605.07669},
year = {2016},
abstract = {The ability to compute an accurate reward function is essential for optimising a dialogue policy via reinforcement learning. In real-world applications, using explicit user feedback as the reward signal is often unreliable and costly to collect. This problem can be mitigated if the user's intent is known in advance or data is available to pre-train a task success predictor off-line. In practice neither of these apply for most real world applications. Here we propose an on-line learning framework whereby the dialogue policy is jointly trained alongside the reward model via active learning with a Gaussian process model. This Gaussian process operates on a continuous space dialogue representation generated in an unsupervised fashion using a recurrent neural network encoder-decoder. The experimental results demonstrate that the proposed framework is able to significantly reduce data annotation costs and mitigate noisy user feedback in dialogue policy learning.},
}
@article{YoungetalCoRR-18,
title = {Integrating Episodic Memory into a Reinforcement Learning Agent Using Reservoir Sampling},
author = {Kenny J. Young and Richard S. Sutton and Shuo Yang},
journal = {CoRR},
volume = {arXiv:1806.00540},
year = {2018},
abstract = {Episodic memory is a psychology term which refers to the ability to recall specific events from the past. We suggest one advantage of this particular type of memory is the ability to easily assign credit to a specific state when remembered information is found to be useful. Inspired by this idea, and the increasing popularity of external memory mechanisms to handle long-term dependencies in deep learning systems, we propose a novel algorithm which uses a reservoir sampling procedure to maintain an external memory consisting of a fixed number of past states. The algorithm allows a deep reinforcement learning agent to learn online to preferentially remember those states which are found to be useful to recall later on. Critically this method allows for efficient online computation of gradient estimates with respect to the write process of the external memory. Thus unlike most prior mechanisms for external memory it is feasible to use in an online reinforcement learning setting.}
}
@inproceedings{ZhangetalCASA-16,
author = {Zhang, Juzheng and Thalmann, Nadia Magnenat and Zheng, Jianmin},
title = {Combining Memory and Emotion With Dialog on Social Companion: A Review},
booktitle = {Proceedings of the 29th International Conference on Computer Animation and Social Agents},
publisher = {ACM},
location = {Geneva, Switzerland},
year = {2016},
pages = {1-9},
abstract = {In the coming era of social companions, many researchers have been pursuing natural dialog interactions and long-term relations between social companions and users. With respect to the quick decrease of user interest after the first few interactions, various emotion and memory models have been developed and integrated with social companions for better user engagement. This paper reviews related works in the effort of combining memory and emotion with natural language dialog on social companions. We separate these works into three categories: (1) Affective system with dialog, (2) Task-driven memory with dialog, (3) Chat-driven memory with dialog. In addition, we discussed limitations and challenging issues to be solved. Finally, we also introduced our framework of social companions.}
}
100 I've been reading Terrence Deacon's latest book "Incomplete Nature: How Mind Emerged from Matter". I had started a month ago thinking it was relevant to some ideas I had about the origins of language. I found it frustrating and several of the reviews agreed with my observation that the first chapter was almost incomprehensible. I returned to it a week ago when I was reading a biography of Ludwig Boltzmann and thinking about thermal equilibrium and entropy while simultaneously "watching" Boltzmann's tragic life unravel leading up to his final — and successful — suicide attempt. I still find Deacon's book difficult reading, but I think I understand his theory and how it relates to consciousness.
If you're interested check out my attempt reconstruct and summarize Deacon's theory and see if it makes sense to you: The second law of thermodynamics tells us that the entropy of an isolated system either remains constant or increases with time. We can use this to argue that a system consisting of a container of water at one temperature containing a second container of water at a higher temperature has lower entropy than an otherwise identical system in which the water in both containers is the same temperature. Barring external intervention, the two bodies of water are said to achieve thermal equilibrium.
Now imagine a system consisting of an organism and the environment in which it evolved. Considered as a closed system, the laws of thermodynamics tell us that the entropy of the system as a whole will increase over time. However, the organism has evolved so as to prevent, or at least slow down this from happening. Part of its strategy for achieving this is to produce a barrier enclosing the organism and separating it from its surrounding environment. The laws of thermodynamics tell us that it must do work to maintain the integrity of this barrier as well as the essential properties that define its function.
In single-celled organisms, the barrier is the cell membrane along with the molecules that allow it to absorb nutrients, excrete waste, exclude poisons and repel pathogens. Ask any molecular biologist and she'll tell you that this is an unrelenting, incredibly challenging burden for the organism, especially given that the environment of the cell is dynamic, quick to exacerbate any weakness the organism might exhibit and natural selection has had a long time to evolve sophisticated highly-adaptive pathogens. Multi-cellular life is faced with an even more daunting set of challenges in managing the selectively-permeable interface between self and not-self.
Our immune system, the complex neural circuits of our gastrointestinal tract and our gut micro biome are but a few of the many systems our bodies employ in maintaining our physical autonomy. Deacon includes the systems involved in consciousness as playing a key role in directing those activities designed to secure and maintain the autonomy of the self. These activities include monitoring and controlling our psychological and social state with much the same sort of challenges as those of single-celled animals, albeit with very different dynamics and modes of interaction. So consciousness is an evolved response to a threatened loss of autonomy.
However, Deacon goes much further in relating these phenomena to Shannon's information theory, Boltzmann entropy and thermodynamic work, emphasizing their emergent properties and arguing that the problem of consciousness and the problem of the origin of life are inexorably linked. The arguments based on thermodynamics concerning how systems consistently far from equilibrium can interact and combine to produce novel emergent properties is well done. I got lost in the discussion of homeodynamics, an abstract process that can be realized in forms beyond the scope of classic thermodynamics. It's an interesting read if you're willing to temporarily suspend judgment and entertain his mix of insight and complex flights of fancy.
If you've ever listened to one of his book talks, you know that he often leads with a discussion concerning the invention of zero. He posits that the study of constraints leads to a better understanding of nature and that, in particular, ententions — concepts like zero that refer to or are, in some other way, "about" something not present — are key in understanding the emergent properties of living things. It's an intriguing conceit and useful example of what Daniel Dennett calls an intuition pump. Despite my cynicism, I am somewhat positively disposed toward Deacon's ideas, but then I'm often drawn to complicated mechanisms.
Miscellaneous loose ends:
Here some comments and questions about the above commentary:
I had not previously encountered the notion of consciousness as (one way) to deal with entropy and it's a really intriguing idea. It almost seems like a hypothesis that one could test ... As a thought experiment, do you think that Deacon would say that an animal who is unconscious is doing a worse job at staving off entropy than when it is conscious?
I think he would agree with that, noting however that the organism is taking a calculated risk by assuming that the restorative benefits of taking your brain off line to consolidate what you've learned outweigh the potential negative consequences of being in an unprotected or less-readily defended state. I expect Sean Carroll would say consciousness is an emergent property of the laws of physics and the boundary conditions imposed by our planet.
It's interesting that Deacon also views consciousness as playing a key role in modulating the complex neural circuitry involved in things like the microbiome — most people would say that we have been largely unaware/unconscious of the important role that the microbiome plays in our lives, so how could consciousness be involved deeply in it?
I'm not exactly sure how Deacon would answer your question. I didn't read all the later chapters of the book with the same thoroughness as the earlier ones — it's one of those books in which almost every page requires the full concentration of the reader and hence it's more than a little exhausting to read for long periods of time. That said, I'll make an attempt to channel Deacon to answer your question. Beware of speech-recognition transcription errors in the following.
Complex life — even the simplest predecessors of the first fully-functional, self-reproducing, single-cell organisms — is fragile and it had to be an hit-or-miss struggle in bringing all the pieces together in a functioning organism. The development of a cell membrane enclosing and protecting the coalition of molecules that were to eventually evolve into a cell was clearly an important innovation and a remarkable tour de force by natural selection.
Very early on these earlier proto-cells had to develop some means of distinguishing parts of themselves from other complex molecules that surrounded them or, worse yet, found some means of entering the cell, a trick that viruses have refined to an high art. Distinguishing self from non-self was difficult even at this very primitive stage in the evolution of life, and it got even more difficult as there developed multitudes of different life forms all competing for the same scarce resources and naturally seizing upon opportunities to take what they needed from other life forms.
Initially the molecular tools for maintaining autonomy were likely in the form of separate uncoordinated bespoke molecules, but the threats to autonomy evolved quickly to foil the efforts of uncoordinated defenders and so over time it was necessary to deploy ever more complicated mechanisms to fend off attacks. In the arms race that ensued, these defensive mechanisms became too complicated to be implemented with ever larger molecules, however sophisticated their molecular structure. Multi-cellular life was able to differentiate cells to perform specific defensive strategies often involving the coordination of several different cell types.
It became necessary for cells to communicate with one another and so even more complicated protocols evolved for carrying out complex defensive strategies. Communication and collaboration of cell types within a single organism evolved alongside of communication and collaboration between multiple organisms and the mechanisms for conveying and interpreting information became more complicated in order to cope with the growing complexity of life. Communication via shared molecules was often superseded by other methods of signaling but some of the most powerful strategies for exploiting another organism involved different forms of deceit, including camouflage and mimicking.
Recall that semiotics — referential signaling as the foundation for symbolic communication and the evolution of language — was at the core of Deacon's earlier book, "The Symbolic Species". Given the central role of signaling and communication in "Incomplete Nature", it should come as no surprise that some of same themes resurfaced. My evidence for this supposition is somewhat circumstantial so don't quote me on this.
Eventually, the complexity reached some threshold such that it was worth the metabolic cost to build and maintain computational resources in an arms race that played out so quickly evolution could not keep pace to ensure the survival of the species. Throughout earlier wars involving the co-evolution of better boundaries and better tools for breaching them, a proto-sense of self emerged in the form of coalitions of cells whose purpose it was to distinguish self from non-self and rid the organism of the latter. The immune system in mammals is among one of the most sophisticated of such coalitions.
I expect that Deacon or Daniel Dennett would be comfortable with the idea that just as cybersecurity has become one of the most critical factors in modern warfare, so too natural selection has seen fit to develop offensive and defensive weapons to protect boundaries no longer defined purely in biological terms. If you believe as I do that consciousness is simply an attentional mechanism — no more complicated from a purely computational perspective than the attentional machinery that governs visual saccades, then it is not too far-fetched to say that consciousness is a consequence of the evolution of life on a planet sufficiently rich in the opportunities for biological communication and computation.
P.S. Lest I leave you thinking that Deacon has it altogether regarding the other aspects of his thesis, you might want to read Daniel Dennett's review of Deacon's book [105] (PDF). Chapters 2 (Homunculi), 3 (Golems) and 4 (Teleonomy) present what I believe to be a deep misunderstanding of the nature and limitations of computing both carbon- and silicon-based. Dennett takes Deacon to task, but in such a polite and scholarly manner that some readers will not even register his opposition.
In Chapter 5 (Emergence) (pp. 143-181) Deacon explicitly rejects claims that living or mental phenomena can be explained by dynamical systems approaches, arguing that life- or mind-like properties only emerge from a higher-order reciprocal relationship between self-organizing processes. Finally, in the first 12 minutes of this podcast, Buddhist teacher and writer, Joseph Goldstein, speaks about the relationship between consciousness and self, emphasizing the view that consciousness only makes one think there exists a separate self.
101 The theory articulated in the speaker notes of the slides I sent around can be summarized as follows: unimodal sensory information enters the posterior cortex, is combined in multi-modal association areas and abstracted in thought vectors. Attentional circuits in the frontal cortex repeatedly extract low-dimensional abstracts of these thought vectors and then select a subset to highlight and actively maintain for a period on the order of 100 milliseconds. Less than a dozen — 5 plus or minus 2 we have been led to believe — can be so highlighted and the same vector can be repeatedly highlighted to sustain its activation over longer periods.
In parallel with this process — managing the contents of the global workspace in the posterior cortex, another process involving the basal ganglia, hippocampus and portions of the prefrontal cortex extracts low-dimensional probes from the highlighted activations in the global workspace and the deploys them to select content from episodic memory that it then makes available to augment the activations highlighted in the global workspace, where "making the contents of episodic memory available" might correspond to composing thought vectors. In explaining this to a friend, I gave the following — collaborative and externalized — example:
You're sitting in the living room listening to Keith Jarrett on the stereo. You and your wife are reading. The passage in the book you're reading makes a reference to how we think about the passage of time. A few hundred milliseconds later as you are still attending to the passage you are reminded of having dinner with your mother in which she said something about how time seems to stretch and contract depending upon what she's doing and what sort of things she has on her mind. You ask your wife if she remembers this conversation. She replies that she doesn't remember this particular conversation but that she has a similar reaction when in the course of the day she reflects upon how time passes when she's preparing dinner in the evening or when she's checking her email or reading the news feeds in the morning while having her first cup of tea.
When I first came up with the above computational model incorporating (conscious) awareness and (unconscious) episodic recall it occurred to me — and I found this rather disturbing — how little control I had over my thoughts. This was disturbing because I didn't yet have a good model of how the programmer’s apprentice agent could intervene in this cycle of attending and remembering in order to direct its thoughts so as to solve programming problems or any other problems for that matter.
But then I thought more carefully about how in my meditation practice I have been able to recognize disturbing thoughts without having them adversely influence my emotional state and then dismiss them by simply letting them pass away. It struck me that as I have become more adept at controlling my attention during meditation I am able to recognize when I've allowed a thought to gain some purchase on my mind. Intuitively I call up what I will call my diligent avoidance subroutine and use my current experience to reinforce my ability to recognize such nuisance thoughts and let them pass without allowing them to gain some purchase — generally accompanied by some unpleasant or at least unwanted thoughts — in order to reveal their destructive character.
103 Following [86, 48], we employ hierarchical planning technology to implement several key components in the underlying bootstrapping and dialog management system. Each such component consists of a hierarchical task network (HTN) representing a collection of hierarchically organized plan schemas designed to run in a lightweight Python implementation of the HTN planner developed by Dana Nau et al [273]:
Hierarchical task network (HTN) planning is an approach to automated planning in which the dependency among actions can be given in the form of hierarchically structured networks. Planning problems are specified in the hierarchical task network approach by providing a set of tasks, which can be:
primitive tasks, that roughly correspond to the actions of STRIPS,
compound tasks, that can be seen as composed of a set of simpler tasks, and
objective tasks, that roughly correspond to the goals of STRIPS, but are more general.
A solution to an HTN problem is then an executable sequence of primitive tasks that can be obtained from the initial task network by decomposing compound tasks into their set of simpler tasks, and by inserting ordering constraints. SOURCE
102 Bootstrapping the programmer's apprentice: Basic cognitive bootstrapping and linguistic grounding
%%% Thu Sep 6 04:35:05 PDT 2018
The programmer's assistant agent is designed to distinguish between three voices: the voice of the programmer, the voice of the assistant's automated tutor and its own voice. We could have provided an audio track to distinguish these voices, but since there only these three and the overall system can determine when any one of them is speaking, the system simply adds a few bits to each utterance as a proxy for an audio signature allowing the assistant to make such distinctions for itself. When required, we use the same signature to indicate which of the three speakers is responsible for changes to the shared input and output associated with the fully instrumented IDE henceforth abbreviated as FIDE — pronounced "/fee/'-/day/", from the Latin meaning: (i) trust, (ii) credit, (iii) fidelity, (iv) honesty. It will also prove useful to further distinguish the voice of the assistant as being in one of two modes: private, engaging in so-called inner speech that is not voiced aloud, and public, meaning spoken out loud for the explicit purpose of communicating with the programmer. We borrow the basic framework for modeling other agents and simple theory-of-mind from Rabinowitz et al [23].
The bootstrap statistical language model consists of an n-gram embedding trained on large general-text language corpus augmented with programming and software-engineering related text drawn from online forums and transcripts of pair-programming dialog. For the time being, we will not pursue the option of trying to acquire a large enough dialog corpus to train an encoder-decoder LSTM/GRU dialog manager / conversational model [381]. In the initial prototype, natural language generation (NLG) output for the automated tutor and assistant will be handled using hierarchical planning technology leveraging ideas developed in the CMU RavenClaw dialogue management system [48]103, but we have plans to explore hybrid natural language generation by combining hard-coded Python dialog agents corresponding to hierarchical task networks and differentiable dialogic encoder-decoder thought-cloud generators using a variant of pointer-generator networks as described by See et al [334].
Both the tutor and assistant NLG subsystems will rely on a base-level collection of plans — hierarchical task network (HTN) — that we employ in several contexts plus a set of specialized plans — an HTN subnetwork — specific to each subsystem. At any given moment in time, a meta control system [172] in concert with a reinforcement-learning-trained policy determines the curricular goal constraining the tutor's choice of specific lesson is implemented using a variant of the scheduled auxiliary control paradigm described by Riedmiller et al [316]. Having selected a subset of lessons relevant to the current curricular goal, the meta-controller cedes control to the tutor which selects a specific lesson and a suitable plan to oversee interaction with the agent over the course of the lesson.
Most lessons will require a combination of spoken dialogue and interactive signaling that may include both the agent and the tutor pointing, highlighting, performing edits and controlling the FIDE by executing code and using developer tools like the debugger to change state, set break points and single step the interpreter, but we're getting ahead of ourselves. The curriculum for mastering the basic referential modes is divided into three levels of mastery in keeping with Terrence Deacon's description [5] and Charles Sanders Peirce's (semiotic) theory of signs. The tutor will start at the most basic level, continually evaluating performance to determine when it is time to graduate to the next level or when it is appropriate to revert to an earlier level to provide additional training in order to master the less demanding modes of reference.
Miscellaneous loose ends: Williams et al [400] introduce a related approach to bootstrapping called Hybrid Code Networks (HCNs) that targets dialog systems for applications such as automated technical support and restaurant reservations — see Figure 47 for an overview. Bordes et al [50] and Das et al [79] demonstrate end-to-end dialog systems based on Memory Networks [397] that exhibit promising performance and learn to perform non-trivial operations. See Figure 39 for a simple hierarchical dialog-management plan from [86].
106 Here are some of the key papers that O'Reilly mentioned in his 2018 presentation in class:
%%% (Huang et al, 2013) - O’Reilly
@article{HuangetalJCN-13,
author = {Huang, Tsung-Ren and Hazy, Thomas and A Herd, Seth and O’Reilly, Randall},
title = {Assembling Old Tricks for New Tasks: A Neural Model of Instructional Learning and Control},
booktitle = {Journal of Cognitive Neuroscience},
volume = {25},
issue = {6},
year = {2013},
pages = {843-841},
abstract = {We can learn from the wisdom of others to maximize success. However, it is unclear how humans take advice to flexibly adapt behavior. On the basis of data from neuroanatomy, neurophysiology, and neuroimaging, a biologically plausible model is developed to illustrate the neural mechanisms of learning from instructions. The model consists of two complementary learning pathways. The slow-learning parietal pathway carries out simple or habitual stimulus-response (S-R) mappings, whereas the fast-learning hippocampal pathway implements novel S-R rules. Specifically, the hippocampus can rapidly encode arbitrary S-R associations, and stimulus-cued responses are later recalled into the basal ganglia-gated pFC to bias response selection in the premotor and motor cortices. The interactions between the two model learning pathways explain how instructions can override habits and how automaticity can be achieved through motor consolidation.}
}
%%% (Taatgen and Frank, 2003) - Taatgen
@article{TaatgenandFrankHUMAN-FACTORS-03,
author = {Taatgen, Niels and Lee, Frank},
title = {Production Compilation: A Simple Mechanism to Model Complex Skill Acquisition},
booktitle = {Human Factors},
volume = {45},
year = {2003},
pages = {61-76},
abstract = {In psychology many theories of skill acquisition have had great success in addressing the find details of learning relatively simple tasks, but can they scale up to complex tasks that are more typical of human learning in the world? In this paper we describe production composition , a theory of skill acquisition that combines aspects of the theories forwarded by Anderson (1982) and Newell and Roosenbloom (1981), that we believe can model the fine details of learning in complex and dynamic tasks. We use production composition to model in detail learning in a simulated air-traffic controller task.}
}
%%% (Santoro et al, 2016) - Lillicrap
@inproceedings{SantoroetalICML-16,
author = {Santoro, Adam and Bartunov, Sergey and Botvinick, Matthew and Wierstra, Daan and Lillicrap, Timothy},
title = {Meta-learning with Memory-augmented Neural Networks},
booktitle = {Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48},
year = {2016},
pages = {1842-1850},
abstract = {Despite recent breakthroughs in the applications of deep neural networks, one setting that presents a persistent challenge is that of "one-shot learning." Traditional gradient-based networks require a lot of data to learn, often through extensive iterative training. When new data is encountered, the models must inefficiently relearn their parameters to adequately incorporate the new information without catastrophic interference. Architectures with augmented memory capacities, such as Neural Turing Machines (NTMs), offer the ability to quickly encode and retrieve new information, and hence can potentially obviate the downsides of conventional models. Here, we demonstrate the ability of a memory-augmented neural network to rapidly assimilate new data, and leverage this data to make accurate predictions after only a few samples. We also introduce a new method for accessing an external memory that focuses on memory content, unlike previous methods that additionally use memory location-based focusing mechanisms.}
}
%%% (Bengio, 2017) - Bengio
@article{BengioCoRR-17,
author = {Yoshua Bengio},
title = {The Consciousness Prior},
journal = {CoRR},
volume = {arXiv:1709.08568},
year = {2017},
abstract = {A new prior is proposed for representation learning, which can be combined with other priors in order to help disentangling abstract factors from each other. It is inspired by the phenomenon of consciousness seen as the formation of a low-dimensional combination of a few concepts constituting a conscious thought, i.e., consciousness as awareness at a particular time instant. This provides a powerful constraint on the representation in that such low-dimensional thought vectors can correspond to statements about reality which are either true, highly probable, or very useful for taking decisions. The fact that a few elements of the current state can be combined into such a predictive or useful statement is a strong constraint and deviates considerably from the maximum likelihood approaches to modeling data and how states unfold in the future based on an agent’s actions. Instead of making predictions in the sensory (e.g. pixel) space, the consciousness prior allow the agent to make predictions in the abstract space, with only a few dimensions of that space being involved in each of these predictions. The consciousness prior also makes it natural to map conscious states to natural language utterances or to express classical AI knowledge in the form of facts and rules, although the conscious states may be richer than what can be expressed easily in the form of a sentence, a fact or a rule.}
}
%%% (Lamme, 2006) - Lamme
@article{LammeTiCS-06,
author = {Lamme, V. A.},
title = {Towards a true neural stance on consciousness},
journal = {Trends in Cognitive Science},
year = {2006},
volume = {10},
number = {11},
pages = {494-501},
abstract = {Consciousness is traditionally defined in mental or psychological terms. In trying to find its neural basis, introspective or behavioral observations are considered the gold standard, to which neural measures should be fitted. I argue that this poses serious problems for understanding the mind-brain relationship. To solve these problems, neural and behavioral measures should be put on an equal footing. I illustrate this by an example from visual neuroscience, in which both neural and behavioral arguments converge towards a coherent scientific definition of visual consciousness. However, to accept this definition, we need to let go of our intuitive or psychological notions of conscious experience and let the neuroscience arguments have their way. Only by moving our notion of mind towards that of brain can progress be made.}
}
105 What if you wanted to recreate a pattern of activity using a sparse probe? Why might you want to do this aside from the incentive of compact storage? Randall O'Reilly — Slide 19 of his presentation in CS373C — answers this question by arguing that sparsity encourages pattern separation that enables rapid binding of arbitrary informational states:
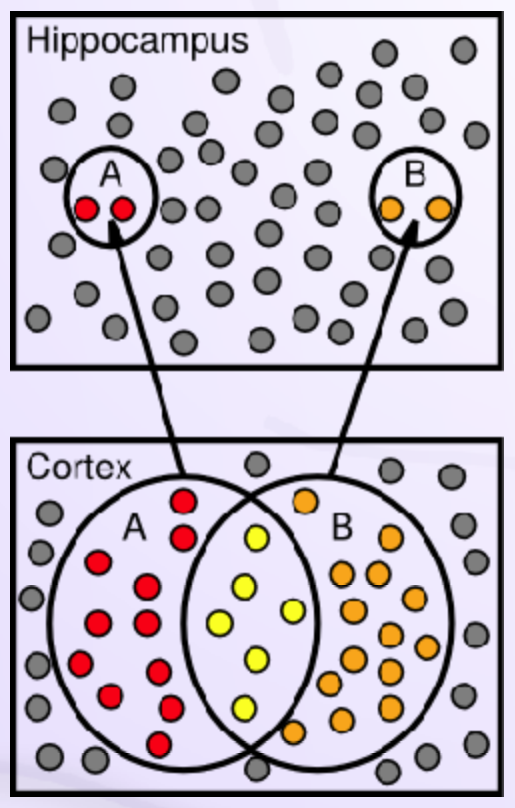 |
O'Reilly then proceeds to explain what he likes to call the "three R's of serial processing": (i) reduce binding errors by serial processing, (ii) reuse same neural tissue across many different situations thus improving generalization, and (iii) recycle activity throughout network to coordinate all areas on one thing at a time as in conscious, attentional awareness106
104 Bootstrapping the programmer's apprentice: Simple interactive behavior for signaling and editing:
%%% Tue Sep 11 18:46:56 PDT 2018
In the first stage of bootstrapping, the assistant's automated tutor engages in an analog of the sort of simple signaling and reinforcement that a mother might engage in with her baby in order to encourage the infant to begin taking notice of its environment and participating in the simplest forms of communication. The basic exchange goes something like: the mother draws the baby's attention to something and the baby acknowledges by making some sound or movement. This early step requires that the baby can direct its gaze and attend to changes in its visual field.
In the case of the assistant, the relevant changes would correspond to changes in FIDE or the shared browser window, pointing would be accomplished by altering the contents of FIDE buffers or modifying HTML. Since the assistant has an innate capability to parse language into sequences of words, the tutor can preface each lesson with short verbal lesson summary, e.g., "the variable 'foo'", "the underlined variable", "the highlighted assignment statement", "the expression highlighted in blue". The implicit curriculum followed by the tutor would systematically graduate to more complicated language for specifying referents, e.g., "the body of the 'for' loop", "the 'else' clause in the 'conditional statement", "the scope of the variable 'counter'", "the expression on the right-hand side of the first assignment statement".
The goal of the bootstrap tutor is to eventually graduate to simple substitution and repair activities requiring a combination of basic attention, signaling, requesting feedback and simple edits, e.g., "highlight the scope of the variable shown in red", "change the name of the function to be "Increment_Counter", "insert a "for" loop with an iterator over the items in the "bucket" list", "delete the next two expressions", with the length and complexity of the specification gradually increasing until the apprentice is capable of handling code changes that involve multiple goals and dozens of intermediate steps, e.g., "delete the variable "Interrupt_Flag" from the parameter list of the function declaration and eliminate all of the expressions that refer to the variable within the scope of the function definition".
Note the importance of an attentional system that can notice changes in the integrated development environment and shared browser window, the ability to use recency to help resolve ambiguities, and emphasize basic signals that require noticing changes in the IDE and acknowledging that these changes were made as a means of signaling expectations relevant to the ongoing conversation between the programmer and the apprentice. These are certainly subtleties that will have to be introduced gradually into the curricular repertoire as the apprentice gains experience. We are depending on employing a variant of Riedmiller et al that will enable us to employ the FIDE to gamify the process by evaluating progress at different levels using a combination of general extrinsic reward and policy-specific intrinsic motivations to guide action selection [316].
Randall O'Reilly mentioned in his class presentation the idea that natural language might play an important role in human brains as an intra-cortical lingua franca. Given that one of the primary roles language serves is to serialize thought thereby facilitating serial computation with all of its advantages in terms of logical precision and combinatorial expression, projecting a distributed connectionist representation through some sort of auto encoder bottleneck might gain some advantage in combining aspects of symbolic and connectionist architectures. This also relates to O'Reilly’s discussion of the hippocampal system and in particular the processing performed by the dentate gyrus and hippocampal areas CA1 in CA2 in generating a sparse representation that enables rapid binding of arbitrary informational states and facilitates encoding and retrieving of episodic memory in the entorhinal cortex105 .
Miscellaneous loose ends: [...] thought cloud annotation and serialization — thought cloud fusion and sparse reconstruction using a combination of serialization and predictive coding — variational information bottleneck auto encoder [...] think about reinforcement learning in the case of multi-step plans designed to re-write a program fragment or fix a bug [...] the notion of setting goals and maintaining the motivation necessary sustain effort over the long term in the absence of reward in the short term [...] see Huang et al [193] Neural Model of Instructional Learning and Control and Taatgen and Frank [360] Model of Complex Skill Acquisition [...]
107 Bootstrapping the programmer's apprentice: Mixed dialogue interleaving instruction and mirroring:
%%% Wed Sep 12 05:34:16 PDT 2018
Every utterance, whether generated by the programmer or the apprentice's tutor or generated by the apprentice either intended for the programmer or sotto voce for its internal record, has potential future value and hence it makes sense to record that utterance along with any context that might help to realize that potential at a later point in time. Endel Tulving coined the phrase episodic memory to refer to this sort of memory. We'll forgo discussion of other types of memory for the time being and focus on what the apprentice will need to remember in order take advantage of its past experience.
Here is the simplest, stripped-to-its-most-basic-elements scenario outlined in the class notes: (a) the apprentice performs a sequence of steps that effect a repair on a code fragment, (b) this experience is recorded in a sequence of tuples of the form (st,at,rt,st+1) and consolidated in episodic memory, (c) at a subsequent time, days or weeks later, the apprentice recognizes a similar situation and realizes an opportunity to exercise what was learned in the earlier episode, and (d) a suitably adapted repair is applied in the present circumstances and incorporated into a more general policy so that it can be applied in wider range circumstances.
The succinct notation doesn't reveal any hint of the complexity and subtlety of the question. What were the (prior) circumstances — st? What was thought, said and done to plan, prepare and take action — at? What were the (posterior) consequences — rt and st+1? We can't simply record the entire neural state vector. We could, however, plausibly record the information temporarily stored in working memory since this is the only information that could have played any substantive role — for better or worse — in guiding executive function.
We can't store everything and then carefully pick through the pile looking for what might have made a difference, but we can do something almost as useful. We can propagate the reward gradient back through the value- / Q-function and then further back through the activated circuits in working memory that were used to select ai and adjust their weights accordingly. The objective in this case being to optimize the Q-function by predicting the state variables that it needs in order to make an accurate prediction of the value of applying action at in st as described in Wayne et al [393].
Often the problem can be described as a simple Markov process and the state represented as a vector comprising of a finite number of state variables, st = ⟨ α0, α1, α2, α3, α4, α5, α6, α7 ⟩ , with the implicit assumption that the process is fully observable. More generally, the Markov property still holds, but the state is only partially observable resulting in a much harder class of decision problem known as a POMDP. In some cases, we can finesse the complexity if we can ensure that we can observe the relevant state variables in any given state, e.g., in one set of states it is enough to know one subset of the state variables, {⟨ α0, α1, α2, α3, α4, α5, α6, α7 ⟩ }, while in another set of states a different subset of state variables suffices, {⟨ α0, α1, α2, α3, α4, α5, α6, α7 ⟩ }. If you can learn which state variables are required and arrange to observe them, the problem reduces to the fully observed case.
There's a catch however. The state vector includes state variables that correspond to the observations of external processes that we have little or no direct control over as well as the apprehension of internal processes including the activation of subnetworks. We may need to plan for and carry out the requisite observations to acquire the external process state and perform the requisite computations to produce and then access the resulting internal state information. We also have the ability to perform two fundamentally different types of computation each of which has different strengths and weaknesses that conveniently complement the other.
The mammalian brain is optimized to efficiently perform many computations in parallel; however, for the most part it is not particularly effective dealing with the inconsistencies that arise among those largely independent computations. Rather than relying on estimating and conditioning action selection on internally maintained state variables, most animals rely on environmental cues — callsed affordances [145] — to restrict the space of possible options and simplify action selection. However, complex skills like programming require complex serial computations in order to reconcile and make sense of the contradictory suggestions originating from our mostly parallel computational substrate.
Conventional reinforcement learning may work for some types of routine programming like writing simple text-processing scripts, but it is not likely to suffice for programs that involve more complex logical, mathematical and algorithmic thinking. The programmer's apprentice project is intended as a playground in which to explore ideas derived from biological systems that might help us chip away at these more difficult problems. For example, the primate brain compensates for the limitations of its largely parallel processing approach to solving problems by using specialized networks in the frontal cortex, thalamus, striatum, and basal ganglia to serialize the computations necessary to perform complex thinking.
%%% Thu Sep 13 15:59:45 PDT 2018
At the very least, it seems reasonable to suggest that we need cognitive machinery that is at least as powerful as the programs we aspire the apprentice to generate [138]. We need the neural equivalent of the [CONTROL UNIT] responsible for maintaining a [PROGRAM COUNTER] and the analog of loading instructions and operands into REGISTERS in the [ARITHMETIC AND LOGIC UNIT] and subsequently writing the resulting computed products into other registers or RANDOM ACCESS MEMORY. These particular features of the von Neumann architecture are not essential — what is required is a lingistic foundation that supports a complete story of computation and that is grounded in the detailed — almost visceral — experience of carrying out computations.
A single Q (value) function encoding a single action-selection policy with fixed finite-discrete or continuous state and action spaces isn't likely to suffice. Supporting compiled subroutines doesn't significantly change the picture. The addition of a meta controller for orchestrating a finite collection of separate, special-purpose policies adds complexity without appreciably adding competence. And simply adding language for describing procedures, composing production rules, and compiling subroutines as a Sapir-Whorf-induced infusion of ontological enhancement is — by itself — only a distraction.
We need an approach that exploits a deeper understanding of the role of language in the modern age — a method of using a subset of natural language to describe programs in terms of narratives where executing such a program is tantamount to telling the story. Think about how human cognitive systems encode and serialize remembered stories [...] about programs as stories drawing on life experience by exploiting the serial nature of episodic memory [...] about thought clouds that represent a superposition of eigenstates such that collapsing the wave function yields coherent narrative that serves as a program trace.
Miscellaneous loose ends: [...] classifying intention: learning to categorize tasks and summarize intentions to act [...] confirming comprehension: conveying practical understanding of specific instructions [...] dealing with complex utterances that mix explanation, exhortation and simple instruction [...] parsing arbitrary natural language input into different modalities and routing the resulting annotations to appropriate networks [...] mention Wayne et al [393] and, in particular, review some of the details in Figure 45 regarding MERLIN [...] think about annotated episodic memory as the basis for generating novel proposals for evolving program development.
108 Bootstrapping the programmer's apprentice: Composite behaviors corresponding to simple repairs:
%%% Wed Sep 12 05:34:16 PDT 2018
A software design pattern "is a general, reusable solution to a commonly occurring problem within a given context in software design. It is not a finished design that can be transformed directly into source or machine code. It is a description or template for how to solve a problem that can be used in many different situations. Design patterns are formalized best practices that the programmer can use to solve common problems when designing an application or system" — SOURCE. They are typically characterized as belonging to one of three categories: creational, structural, or behavioral.
I would like to believe that such patterns provide clear prescriptions for how to tackle challenging programming problems, but I know better. Studying such patterns and analyzing examples of their application to practical problems is an excellent exercise for both computer science students learning to program, and practicing software engineers wanting to improve their skills. That said, these design patterns require considerable effort to master and are well beyond what one might hope to accomplish in bootstrapping basic linguistic and programming skills. Indeed, mastery depends on already knowing — at the very least — the rudiments of these skills.
%%% Sat Sep 15 3:46:51 PDT 2018
In response to a message I sent to Matt Botvinick regarding the idea that natural language is software that runs on human brains, Matt wrote:
I am very sympathetic to this perspective. Another relevant reference, which I read with very similar thoughts in mind, is this one: Gallistel, C. R., & King, A. P. (2011). Memory and the computational brain: Why cognitive science will transform neuroscience (Volume 6). John Wiley & Sons.However, I'm not sure I share your view that mental software is always expressed in language (using language in the narrow sense: English, French, etc.). For example, can't one 'hold in mind' a plan of action that is structured like a program but not expressed in language?
I'm willing to concede that mental software is not always expressed in language. For the programmer's apprentice, I'm thinking of encoding what is essentially static and syntactic knowledge about programs and programming using four different representations, and what is essentially dynamic and semantic knowledge in a family of structured representations that encode program execution traces of one sort or another. The four static / syntactic representations are summarized as follows:
(i) distributed (connectionist) representations of natural language as points in high-dimensional embedding spaces — thought clouds;
(ii) natural language transcripts of dialogical utterances / interlocutionary acts encoded as lexical token streams — word sequences;
(iii) programs in the target programming language represented as structured objects corresponding to augmented abstract syntax trees (ASTs)— the augmentations correspond to edges representing procedure calls, iteration and recursion resulting in directed acyclic graphs;
(iv) hierarchical plans corresponding to subnetworks of hierarchical task networks (HTNs) or, if you like, the implied representation of hierarchical plans encoded in value iteration networks [19] and goal-based policies [163]. I'm also thinking about encoding HTNs as policies using a variation on the idea of options [22] as described in Riedmiller et al [316];
The first entry (i) is somewhat misleading in that any one of the remaining three (ii-iv) can be represented as a point / thought cloud using an appropriate embedding method. Thought clouds are the Swiss Army knife of distributed codes. They represent a (constrained) superposition of possibilities allowing us to convert large corpora of serialized structures into point clouds that enable massively parallel search, and subsequently allow us to collapse the wave function, as it were, to read off solutions by re-serializing the distributed encoding of constraints that result from conducting such parallel searches.
I propose to develop encoders and decoders to translate between (serial) representations (ii-iv) where only a subset of conversions are possible or desirable given the expressivity of the underlying representation language. I imagine autoencoders with an information bottleneck that take embeddings of natural language descriptions as input and produces an equivalent HTN representation, combining a mixture of (executable) interlocutory and code synthesis tasks. The interlocutory tasks generate explanations and produce comments and specifications. The code-synthesis tasks serve to generate, repair, debug and test code represented in the FIDE.
Separately encoded embeddings will tend to evolve independently, frustrating attempts to combine them into composite representations that allow powerful means of abstraction. The hope is that we can use natural language as a lingua franca — a "bridge" language — to coerce agreement among disparate representations by forcing them to cohere along shared, possibly refactored dimensions in much the same way that trade languages serve as an expeditious means of exchanging information between scientists and engineers working in different disciplines or scholars who do not share a native language or dialect.
%%% Sun Sep 16 10:20:49 PDT 2018
The idea of using natural language as the basis for an intracortical lingua franca must have been suggested before. I seem to recall Terrence Deacon mentioning a similar idea in The Symbolic Species [5], and, in his discussion in class, Randy O'Reilly mentioned the idea in passing. In any case, we now have the tools to test related hypotheses.
The general idea is to better exploit tradeoffs involving parallel processing relying on distributed connectionist models and serial processing relying on combinatorial symbolic models — a theme that Randy explores at some length in his 2018 class presentation. He focuses on prefrontal-hippocampal-basal-ganglia circuits, but we don't have to be a slave to biology in coming up with new approaches to solving practical problems involving automated programming and digital assistants.
Miscellaneous loose ends: Relating to Matt's suggestion, I found a PDF including the first nine chapters of Gallistel & King [138]. From what I can ascertain, the material in these chapters consists almost entirely of very basic computer science, formal language theory, basic automata and information theory, with a few excursions into biology and associative networks. From scanning the preface, it appears that the content most closely related to Matt's reference to the book is in Chapters 10-16. This article by Gallistel [137] PDF provides a contemporaneous account of his perspective on learning for those not willing to spring for the book.
Gallistel [136] writes in response to a review by John Donahoe [112]: "As Donahoe points out, Shannon’s theory of communication, from which the modern mathematical definition of information comes, is central to our argument. The one-sentence essence of our argument is that: 'The function of memory is to carry information forward in time in a computationally accessible form.'" The preface provides a four-page summary of the last seven chapters focusing on properties of the neural substrate and forwarding a thesis about the fundamental basis / properties of memory which, as the authors emphatically point out, is not synaptic plasticity. They conclude the preface with the statement:
We do not think we know what the mechanism of an addressable read / write memory is, and we have no faith in our ability to conjecture a correct answer. We do, however, raise a number of considerations that we believe should guide thinking about possible mechanisms. Almost all of these considerations lead us to think that the answer is most likely to be found deep within neurons, at the molecular or sub-molecular level of structure. It is easier and less demanding of physical resources to implement a read / write memory at the level of molecular or sub-molecular structure. Indeed, most of what is needed is already implemented at the sub-molecular level in the structure of DNA and RNA.