Research Discussions
The following log contains entries starting several months prior to the first day of class, involving colleagues at Brown, Google and Stanford, invited speakers, collaborators, and technical consultants. Each entry contains a mix of technical notes, references and short tutorials on background topics that students may find useful during the course. Entries after the start of class include notes on class discussions, technical supplements and additional references. The entries are listed in reverse chronological order with a bibliography and footnotes at the end.
Personal Assistants
The main focus of the following entries is on digital assistants that collaborate with humans to write software by making the most of their respective strengths. This account of my early involvement in building conversational agents at Google emphasizes my technical interest in enabling continuous dialogue, resolving ambiguity and recovering from misunderstanding, three critical challenges in supporting effective human-computer interaction.
The earliest notes included below survey research in neuroscience relating to attention, decision making, executive control and theory-of-mind reasoning. The footnotes and bibliography provide an introduction to a cross section of recent research in artificial neural networks, machine learning and cognitive neuroscience that is deemed most likely to be relevant to class projects. This material is previewed in the second introductory lecture.
Class Discussions
August 31, 2018
%%% Fri Aug 31 05:57:47 PDT 2018
Chapter 8 of [87] takes a close look at the differences between the brains of humans and other primates with the motivation of trying to understand what evolutionary changes have occurred since our last common ancestor in order to enable our sophisticated use of language1. There is much to recommend in reading the later chapters of [87] despite their somewhat dated computational details. In particular, Deacon's treatment of symbols and symbolic references is subtle and full of useful insights, including an abstract account of symbols that accords well with modern representations of words, phrases and documents as N-dimensional points in an embedding space. His analysis of perseveration2 in extinction and discrimination reversal tasks following selective frontal ablations is particularly relevant to frontal cortex function [36, 234].
That said, I found Deacon's — circa 1998 — analysis of frontal cortex circuits lacking in computational detail, though perhaps providing the best account one could expect at the time of its writing. I suggest you review the relevant entries in this discussion list as well as the lectures by Randall O'Reilly and Matt Botvinick in preparation for reading this chapter. You might also want to check out a recent model of frontal cortex function arrived at through the perspective of hierarchical predictive coding by Alexander and Brown [4].
For those of you familiar with artificial recurrent neural networks, O'Reilly and Frank [331, 204] present a computational model of working memory (WM) based on the prefrontal cortex (PFC) and basal ganglia (BG) abbreviated as PBWM in the remainder of this entry. In his presentation in class, O'Reilly compares the PBWM model with the LSTM model of Hochreiter and Schmidhuber [218, 217] extended to include forgetting weights as introduced by Gers et al [154, 153]. In the PBWM model illustrated in Figure 48, the neural circuits in the PFC are gated by BG circuits in much the same way as hidden layers with recurrent connections and gating units are used to maintain activations in the LSTM model3.
Given the considerable neural chatter in most neural circuits such as the posterior cortex, Deacon mentions that it is important for complicated tasks requiring symbolic manipulation to be able to accurately and robustly maintain these representations in memory. Apropos of these characteristics of PFC working memory, O'Reilly mentions (00:22:45) that the gated neural circuits in the PFC are actively maintained so that they can serve much the same purpose as the registers employed to temporarily store operands in the arithmetic and logic unit (ALU) of a conventional von Neumann architecture computer in preparation for applying program-selected operators to their respective program-selected operands. During his presentation in class, Randy also answered questions and discussed his research on developing biologically-based cognitive architectures4.
The hippocampus can be thought of as another level in the memory hierarchy that facilitates temporary storage of information that is likely to be relevant in subsequent computations or that has already been used in such computations and may be needed again later for additional computations. The hippocampus plays the role of a high-capacity memory cache and does not require the overhead of active maintenance as in the case of the BG gated neural circuits implementing WM in the PFC. It is perhaps worth noting that in building artificial systems modeled after PBWM, assuming we understand the basic principles and can engineer synthetic analogs, we could design a hybrid architecture that would be significantly superior to the biological system by engineering better technology to sustain active memory and avoid degradation due to noisy activations5.
August 29, 2018
%%% Wed Aug 29 4:53:47 PDT 2018
Almost all of the sixteen entries added to this document during August focus on the problem of bootstrapping basic language skills for the programmer's apprentice. The topics include: August 27 — abstract and fine-grained levels of specificity; August 25 — categories of hierarchical referential association; August 23 — relationship between animal signaling and language; August 19 — human language and procedural versus skill learning; August 17 — tractable targets for collaborative programming; August 13 — signaling as the basis for language development; August 11 — neuroscience of cognitive and language development; August 7 — ontological, categorical and relational foundations; August 4 — simulation-grounded and embodied language learning. We made progress on every one of these topics and it is worthwhile — as well as intellectually and emotionally cathartic — to take stock from time to time and celebrate what we have learned as opposed to being despondent about the seemingly infinite number of things we have yet to learn and may end up being crucially relevant in our present endeavor.
We learned valuable lessons from diverse fields, including cognitive and developmental psychology, computational linguistics, etymology, ethology, human evolutionary biology and computational and systems neuroscience. The work of Terrence Deacon was a particularly satisfying discovery as was my rediscovery of the work of Konrad Lorenz and Nikolaas Tinbergen whose research was first pointed out to me by Marvin Minsky in 1978 leading to my interest in AI. Deacon's theories on the origins of human language fundamentally changed the way I think about how language is acquired and how it has co-evolved within human society. Deacon's work also forced me to reconsider Chomsky's work on language [72] and Steven Pinker's [348] sympathetic view regarding universal grammar and disagreement with respect to Chomsky's skepticism about its evolutionary origins.
Deacon argues that the evidence for a universal grammar is not compelling — see Page 106 in [87]. He suggests a much simpler explanation for how children quickly learn languages, namely that the rules underlying language can be acquired efficiently through trial and error by making a relatively high proportion of correct guesses. Natural languages evolved to encourage a relatively high proportion of correct guesses by exploiting affordances that are built into the human brain. He motivates this explanation with the analogy that the ubiquitous object-oriented (WIMP) interface based on windows, icons, menus and pointing made it possible for humans to quickly learn how to use personal computers without reading manuals or spending an inordinate amount of time discovering how to accomplish their routine computing tasks. The details require over 500 pages.
In addition to the above conceptual and theoretical insights, we identified half a dozen promising technologies for bootstrapping language development including: [364] — scheduled auxiliary control for learning complex behaviors with sparse rewards from scratch; [15] — interpreting language at multiple levels of specificity by grounding in hierarchical planning; [209] — grounded language learning in a simulated robot world for bootstrapping semantic development; [238] — maximizing many pseudo-reward functions mechanism for focusing attention on extrinsic rewards; [210] — teaching machines to read, comprehend and answer questions with no prior language structure. By combining lessons learned from these recent papers and a dozen or so highly relevant classic papers mentioned in earlier entries, I believe we can efficiently learn a basic language facility suitable to bootstrap collaborative coding in the programmer's apprentice
To be clear, what I mean by "bootstrapping a basic language facility" includes the following core capabilities at a minimum: basic signaling including pointing, gesturing and simple performative6 speech acts such as those mentioned in this earlier entry; basic referencing including a facility with primary referential modes — iconic, indexical, symbolic — and their programming-relevant variants; basic interlocutory skills for providing and responding to feedback pertaining to whether signals and references have been properly understood.
In addition, the training protocol should require minimal effort on the part of the programmer by relying on three key technology components: (i) a word-and-phrase-embedding language model trained on a programming-and-software-engineering-biased natural language text corpus, (ii) a generative model for amplifying a small corpus of relevant utterances to produce a larger corpus that spans the space of possibilities afforded by the instrumented IDE along with a large collection of target-language-specific code fragments, and (iii) an automated curriculum-style [37, 39] training protocol that enables the early (incremental) developmental stages described by Deacon [87] and extensively studied in developmental child psychology7. While I fully expect that implementing such a protocol will be an engineering challenge, I feel reasonably confident that it can be done given a team of engineers skilled in working with the technologies of modern deep neural networks.
August 27, 2018
%%% Sun Aug 26 3:59:19 PDT 2018
This entry concerns two issues relating to grounding language for collaborative endeavors such as the programmer's apprentice. The first issue concerns the importance of hierarchy and abstraction in understanding and conveying instructions and the second looks at the problem of reference at a deeper level than discussed in the previous log entry to reveal the relationships between and difficulty learning different types of reference. We begin with the observation that the participants in collaborative projects often employ language at multiple levels of abstraction in order to convey instructions. Building on earlier work introducing the notion of abstract Markov decision process [166] (AMDP) which, in turn, builds upon Dietterich's MAXQ model [121, 120] that we've talked about elsewhere in these discussion notes, Arumugam et al address the implications of this observation in their recent arXiv paper [15]9.
The authors write that: "[h]umans can ground natural language commands to tasks at both abstract and fine-grained levels of specificity. For instance, a human forklift operator can be instructed to perform a high-level action, like "grab a pallet" or a low-level action like "tilt back a little bit." While robots are also capable of grounding language commands to tasks, previous methods implicitly assume that all commands and tasks reside at a single, fixed level of abstraction. Additionally, methods that do not use multiple levels of abstraction encounter inefficient planning and execution times as they solve tasks at a single level of abstraction with large, intractable state-action spaces closely resembling real world complexity. In this work, by grounding commands to all the tasks or subtasks available in a hierarchical planning framework, we arrive at a model capable of interpreting language at multiple levels of specificity ranging from coarse to more granular."
Existing approaches map between natural language commands and a formal representation at some fixed level of abstraction. Arumugam et al leverage the work of MacGlashan et al [298] that decouples the problem of decomposing abstract commands into modular subgoals and grounding the language used to communicate instructions by using a statistical language model to map between language and robot goals, expressed as reward functions in a Markov Decision Process (MDP). As a result, the learned language model can transfer to other robots with different action sets so long as there is consistency in the task representation (i.e., reward functions). Arumugam et al note, however, that "MDPs for complex, real-world environments face an inherent tradeoff between including low-level task representations and increasing the time needed to plan in the presence of both low- and high-level reward functions." and their paper offers a solution to this problem.
I appreciate how the authors have framed the problem and leveraged the earlier work in [166], but I'm not entirely satisfied with the way in which they map between words in language and specific reward functions [298]. It seems as though there must be some way to learn this mapping. Specifically, it seems there might be a more elegant solution using some form of Differentiable Neural Computer / Neural Turing Machine [169] solution, perhaps leveraging some of the ideas in the recent paper [471] by Greg Wayne and his colleagues at DeepMind that directly addresses the problem of dealing with partially observable Markov decision processes — you might want to review Greg's presentation in class that you can find here.
%%% Mon Aug 27 04:25:46 PDT 2018
Effective bootstrapping in the case of the programmer's apprentice problem involves simultaneously solving several problems relating to space of possible actions the agent can select from at any given moment in time. Perhaps the simplest and most straightforward problem involves dealing with very large — discrete rather than continuous — combinatorial action spaces 10. In addition, actions are related to one another hierarchically in terms of the specificity of the activities the enable and the recurrent nature of the behaviors in which they are deployed. In particular, the specificity and complicity of actions will require training protocols that account for the dependencies between different subproblems since the exploration of one action often requires the exploitation of another.
Finally and most fundamentally, actions in partially observable Markov decision processes are likely to have enabling preconditions whose monitoring and prediction will require tracking different state variables. Several of these problems have solutions that rely on managing episodic memory and are addressed in the following work: [471] — learning to decide what episodic information to store in memory based on unsupervised prediction; [357] — neural episodic control of reinforcement learning to incorporate new experience into our policies; [413] — memory-based parameter adaptation dealing with the non-stationarity of our immediate environment. Integrating these technologies to develop a cohesive and comprehensive solution to the above problems is, needless to say, a substantial, though I believe tractable, engineering challenge.
August 25, 2018
%%% Sat Aug 25 11:50:37 PDT 2018
The previous entry consisted of excerpts from Terrence Deacon [87] describing Charles Sanders Peirce's three categories of referential associations: iconic, indexical, and symbolic. In this entry, we build on that foundation to explain how these referential forms depend hierarchically and upon one another. All three of Peirce's referential associations are the result of interpretive processes. The interpretive process that generates an iconic reference is "none other than what we call recognition (mostly perceptual recognition, but not necessarily). Breaking down the term re-cognition says it all: to 'think [about something] again.' Similarly, representation is to present something again. Iconic relationships are the most basic means by which things can be re-presented. It is the basis on which all other forms of representations are built." It is at the bottom of the interpretive hierarchy.
| |
| Figure 48: A schematic diagram depicting the internal hierarchical relationships between iconic and indexical reference processes. The probability of interpreting something as iconic of something else is depicted by a series of concentric domains of decreasing similarity and decreasing iconic potential among beliefs. Surrounding objects have a decreasing capacity to serve as icons for the target object as similarities become unobvious. The form of the sign stimulus (S) elicits awareness of a set of past stimulus memories (e.g., mental "images") by virtue of stimulus generalization processes. Thus, any remembered object (O) can be said to be re-presented by the iconic stimulus. Similarly each mental image is iconic in the same way; no other referential relationship need necessarily be involved for an iconic referential relationship to be produced. Indexical reference, however, requires iconic reference. In order to interpret something as index, at least three iconic relationships must be also recognized. First, the indicating stimulus must be seen as an icon of other similar instances (the top iconic relationships); second, instances of its occurrence must also correlate (arrows) with additional stimuli either in space or time, and these need be iconic of one another (the bottom iconic relationships); and third, past correlations need to be interpreted as iconic of one another (indicated by the concentric arrangement of arrows). The index of interpretation is thus the conjunction of three iconic interpretations, with one being a higher-order icon than the other two (i.e., treating them as parts of a whole). As pointed out in the text, this is essentially the kind of reference provided by a conditioned response — Figure 3.2 adapted from Deacon [87] Page 79. | |
|
|

Having established the foundational role of iconic references, Deacon points out the importance of repeated correlation between pairs of iconic references that constitute evidence of their co-occurrence as a higher-order level of iconicity, providing the basis for estimating the probability that one might cause the other. He suggests that "the responses we develop as a result of day-to-day associative learning are the basis for all indexical interpretations, and that this is the result of a special relationship that develops among iconic interpretive processes. It's hierarchic. Prior iconic relationships are necessary for indexing a reference, but prior indexical relationships are not in the same way necessary for iconic reference." The hierarchic dependency of indices on icons is graphically depicted in Figure 3.2 of Deacon [87] — reproduced here as Figure 48.
| |
| Figure 49: A schematic depiction of the construction of symbolic referential relationships from indexical relationships. This figure builds on the logic depicted in Figure 48 (Figure 3.2 in Deacon [87]) but in this case the iconic relationships are only implied and the indexical relationships are condensed into single arrows. Three stages in the construction of symbolic representations are shown from the bottom to top. First, a collection of different indices are individually learned (varying strength indicated by darkness of arrows). Second, systematic relationships between index tokens (indexical stimuli) are recognized and learned as additional indices (gray arrows linking indices). Third, a shift (reversal of indexical arrows) in mnemonic strategy to rely on relationships between tokens (darker arrows above) to pick out objects indirectly via relationships between objects (corresponding to lower arrow system). Individual indices can stand on their own in isolation, but symbols must be part of a closed group of transformations that links them in order to refer, otherwise they revert to indices — Figure 3.3 adapted from Deacon [87] Page 87. | |
|
|
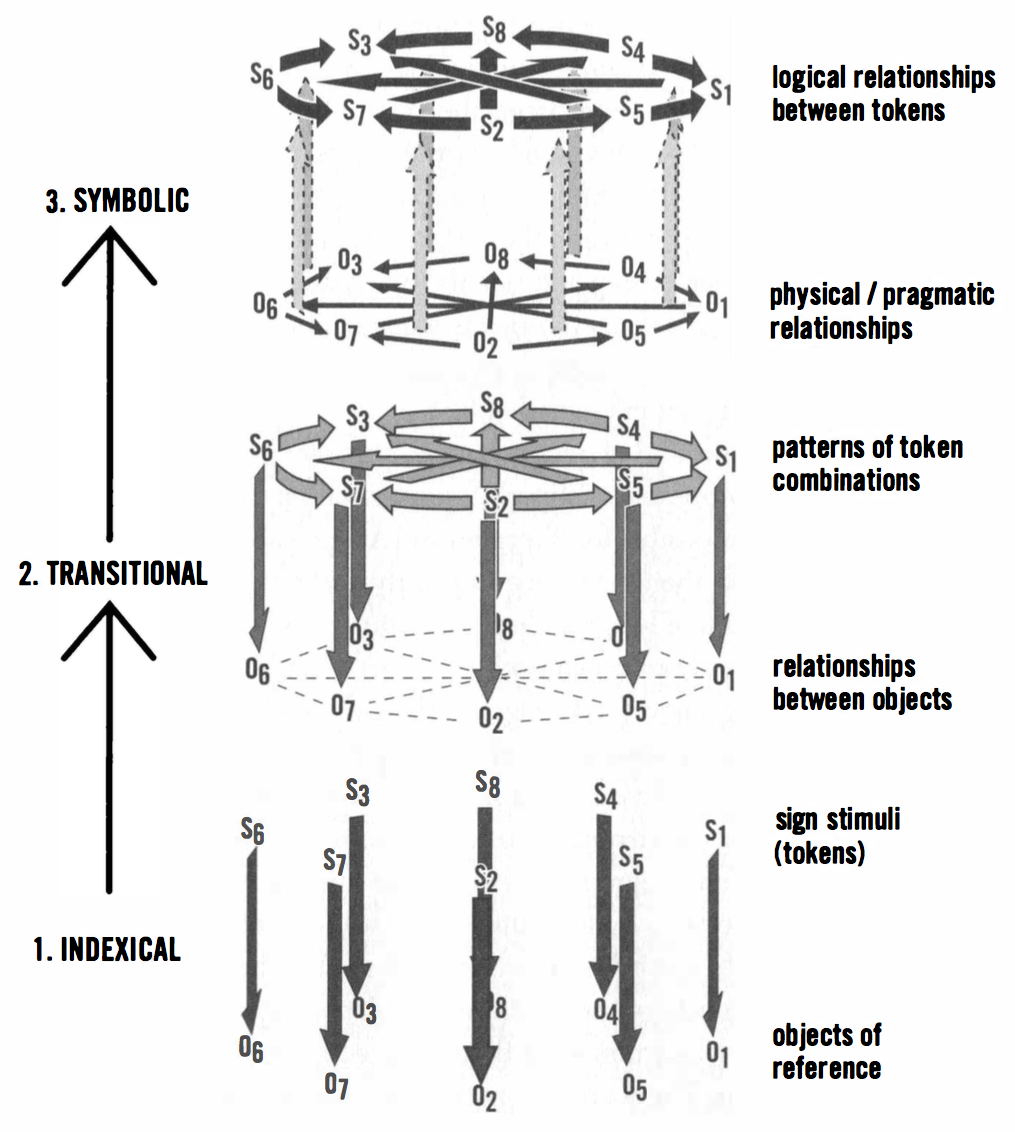
Deacon goes on to suggest that "[t]he problem with symbol systems, then, is that there is both a lot of learning and unlearning that must take place before even a single symbolic relationship is available. Symbols cannot be acquired one at a time, the way other learned associations can, except after a reference symbol system is established. A logically complete system of relationships among the set of symbol tokens must be learned before the symbolic association between any one symbol token and an object can even be determined. The learning step occurs prior to recognizing the symbolic function, and this function only emerges from a system; it is not invested in any individual sign-object pairing.” To make his point Deacon recounts the work of Wolfgang Köhler [257] who described experiments with chimpanzees in which to reach a piece of fruit they had to "see" problem in a new way. Kohler set his chimps the problem of retrieving a banana suspended from the roof of the cage out of reach, given only a couple of wooden boxes that when stacked one upon the other could allow the banana to be reached.
Köhler found that the solutions were not intuitively obvious to a chimpanzee, who would often become frustrated and give up for a long period. During this time the chimp would play with the boxes, often piling them up, climbing on them, and then knocking down. At some point, however, the chimp eventually appeared to have recognized how this fit with the goal of getting at the banana, and then quite purposefully maneuver the boxes into place and retrieve the prize. Deacon writes that "[w]hile not the sort of insight depicted in cartoons as the turning on of a lightbulb, what goes on inside the brain during moments of human insight may simply be a more rapid covert version of the same, largely aimless object play. We recognize these examples of insight solely because they involve a recoding of previously available but unlinked bits of information." Most insight problems do not involve symbolic recoding, merely sensory recoding: "visualizing" the parts of a relationship in a new way. Transference of a learning set from one context to another is in this way also a kind of insight.
At this point, I could attempt to generate a summary of the remainder of Chapter 3, but chapter is appropriately titled "Symbols Aren't Simple" and I wholeheartedly agree with the author's assessment. Not only do I agree, but I think Deacon has done an excellent job of providing a succinct but appropriately nuanced job of explaining the relevant (complicated) issues in a manner easily accessible to a computer scientist. And so, I highly recommend that you read the first three chapters of The Symbolic Species. For those of you who are still curious but reluctant to spend the time to follow my recommendation, I suggest you read the footnote at the end of this paragraph that primarily consists of excerpts from Chapter 3, and make a concerted effort to understand Figure 3.3, reproduced in these class discussion notes as Figure 49 and including Deacon's original annotations11 .
August 23, 2018
%%% Thu Aug 23 03:46:20 PDT 2018
Excerpts from Terrence Deacon's The Symbolic Species [87] relating to the semiotic theory of Charles Sanders Peirce. On the relationship between animal signaling in the form of calls and gestures and human language as traditionally characterized:
Treating animal calls and gestures as subsets of language not only reverses the sequence of evolutionary precedents, it also inverts their functional dependence as well. We know that the non-language communication used by other animals is self-sufficient and needs no support from language to help acquire or interpret. This is true even for human calls like sobbing or gestures like smiling. In contrast, however, language acquisition depends critically on nonlinguistic communication of all sorts, including much that is as innately prespecified as many human counterparts. Not only that, but extensive nonverbal communication is essential for providing the scaffolding on which most day-to-day language communication is supported. In conversations, demonstrations, and explanations using words we make extensive use of prosody, pointing, gesturing, and interactions with other objects and other people to disambiguate our spoken messages. Only with the historical invention of writing has language enjoyed even partial independence from this nonlinguistic support. In the context of the rest of communication, then, language is a dependent stepchild with very odd features. — Page 58 [87]
Reference characterized in terms of generating cognitive actions:
Ultimately, reference is not intrinsic to a word, sound, gesture or hieroglyph; it is created by the nature of some response to it. Reference derives from the process of generating some cognitive action, an interpretive response; and differences in interpretive responses not only can determine different references for the same sign, but can determine reference in different ways. We can refer to such interpretive responses as interpretants, following the terminology of the late 19th century American philosopher Charles Sanders Peirce. In cognitive terms, an interpretant is whatever enables one to infer the reference from some sign or signs in their context. Peirce recognized that interpretants cannot only be of different degrees of complexity, but they can also be categorically different kinds as well; moreover, he did not confine his definition only to what goes on in the head. Whatever process determines reference qualifies as an interpretant. The problem is to explain how differences in interpretants produce different kinds of reference, and specifically what distinguishes the interpretants required for language. — Page 63 [87]
On the different modes of reference as described by Charles Sanders Peirce:
In order to be more specific about differences in referential form, philosophers and semioticians have often distinguished between different forms of referential relationships. Probably the most successful classification of representational relationships was, again, provided by the American philosopher Charles Sanders Peirce. As part of a larger scheme of semiotic relationships, he distinguished three categories of referential associations: icon, index, and symbol. These terms were, of course, around before Pierce and have been used in different ways by others since. Pierce confined the use of these terms to describing the nature of the formal relationship between the characteristics of the sign token and those of the physical object represented as a first approximation these are as follows: icons are mediated by similarity between sign and object, indices are mediated by some physical or temporal connection between sign and object, and symbols are mediated by some formal or merely agreed-upon link irrespective of any physical characteristics of either sign or object.These three forms of reference reflect classical philosophical trichotomy of possible modes of associative relationship: (a) similarity, (b) contiguity or correlation, and (c) law, causality, or convention. [...] Peirce took these insights and rephrased the problem of mind in terms of communication, essentially arguing that all forms of thought (ideas) are essentially communication (transmission of signs), organized by an underlying logic (or semiotic, as he called it) that is not fundamentally different for communication processes inside or outside of brain. If so, it might be possible to investigate the logic of thought processes by studying the sign production and interpretation processes in more overt communication. — Page 70 [87]
While it helps to have someone like Peirce provide insight in the form of a compact, intuitive taxonomy, you may not want to apply his categorization directly since such taxonomies tend to make fine grained distinctions that are not born out in the data as a consequence of additional distinctions not available due limitations in sensing or sampling. The biological classification (taxonomy) formulated by Carl Linnaeus being a textbook case in point. The purpose here is to motivate our emphasis on non-linguistic signaling and reference as the scaffolding upon which to build a more general and robust language facility and the means for acquiring this scaffolding as part of a focused developmental strategy implemented as a form of hierarchical reinforcement learning.
August 19, 2018
%%% Sun Aug 19 04:28:13 PDT 2018
I've been thinking and reading a lot lately about early language development, and was dissatisfied with the explanations and theories I encountered in the literature. I happened to have a copy of Terry Deacon's Incomplete Nature: How Mind Emerged from Matter among my books [88], and noticed several references to an earlier book entitled The Symbolic Species: The Co-evolution of Language and the Brain [87]. I read the first four chapters comprising part one of the book focusing on language and found his theory compelling from a computational / cognitive-developmental perspective, despite the evolutionary-developmental origins for much of the evidence.
Both books are relatively long and academic — 500-plus pages each. I'll give you a flavor by quoting from this interview with David Boulton of Children of the Code in which Deacon talks about how The Symbolic Species "captures this notion that we are a species that in part has been shaped by symbols, in part shaped by what we do. Therefore, our brain is going to be very different in some regards than other species' brains in ways that are uniquely human." He notes that there is unlikely to be "a nice, neat direct map between what we see in the external world of language and what we see inside brains. In fact, the map may be very, very confused and very, very different inside the brain, that is, how the brain does what we see externally in language."
Deacon goes on to say that "[t]he logic of brains is this "embryology logic" that's very old, very conserved. The logic of language is something that is brand new in the world of evolutionary biology. [...] Language clearly forces us to do something that for other species is unnatural and it is that unnaturalness that's probably the key story. One might want to ask: 'What is so different about language? What are the aspects of language that are so different from what other species do?' [...] For me, one of the things I think is really exciting about languages is this aspect of how it reflexively changes the way we think. I think that's one of the most amazing things about being a human being." And, then, the following extended quote captures the critical difference between skill learning and procedural learning, with the former being common throughout the animal kingdom and the latter being quite rare:
Language is unique in the following sense: that it uses a procedural memory system. Most of what I say is a skill. Most of my production of the sounds, the processing of the syntax of it, the construction of the sentence, is a skill that I don't even have to think of. It's like riding a bicycle. I don't even have a clue of how I do it. [...] "On the other hand, I can use this procedural memory system because of the symbols that it contains, the meanings and the web of meanings that it has access to, that are also relatively automatic, to access this huge history of my episodes of life so that in one sense it's using one kind of memory to organize the other kind of memory in a way that other species won't have access to without this." [...] "The result is we can construct narratives in which we link together these millions and millions of episodes in our life in which you can ask me what happened last month on a particular day and if I can think through the days of the week and the things I was doing when, I can slowly zero in on exactly what that episodic memory is and maybe even relive it in some sense."
One reason that this jumped out at me — and Deacon comes back to this point at greater length within The Symbolic Species — is that words are symbolic, easily-remembered, precise-as-memory-aids and can — with some effort — be made to be categorically precise in ways that complement conventionally-connectionist, contextually-coded memories and thereby provide a basis for mathematical and logical thinking. While I'm pretty sure that Deacon didn't mean it as I interpreted it, the following excerpt caught my eye and current scientific /engineering interest in developing neural prosthetic devices:
I think the crucial problem with all of language as we use it today is the problem with automatization. How do we take something that has so many variables, so many possible connections and combinatorial options, and do it without having to think about it? How do we turn this complicated set of relationships into a skill, ultimately, that can be run, in effect, as though it was a computation?
That is indeed an interesting question and one that is critically important in developing systems that translate everyday procedural language into code that runs on non-biological computational substrates. It also underscores Deacon's view of what needs explaining. Deacon discounts the importance of grammar in explaining the evolutionary importance of language: "When we strip away the complexity, only one significant difference between language and non-language communication remains: the common, everyday miracle of word meaning and reference" — Page 43 [87]. It is easier to build syntax, recursion and grammar on the foundation of word meaning and reference than the other way around. This perspective also accords well with our current understanding of the postnatal neural and cognitive development of infants in their first three years.
August 17, 2018
%%% Fri Aug 17 06:17:44 PDT 2018
I asked Rishabh Singh for "examples of recent research that might help in working toward the sort of tractable, reasonably circumscribed capability I'm looking to develop in a prototype apprentice system as a proof of concept for the more general utility of developing digital assistants capable of usefully collaborating with human experts. The list of references along with links to several startups that are building technologies related to the accompanying preprints is provided in this footnote12.
August 13, 2018
Mon Aug 13 04:32:06 PDT 2018
The previous log entry focused on the neural and cognitive development of humans in the first three years. It was clear from the AAAS that there is more to language development than speaking to your baby. Specifically, there are signaling protocols that we refer to as signal acts in analogy to J.L. Austin's theory of speech acts corresponding to locutionary, illocutionary, and perlocutionary utterances. Within evolutionary biology, signaling theory refers to — generally non-verbal — communication between individuals both within and across species.
The basis for such communication is shared experience in the form of a sufficiently complex, causally coherent, reasonably accessible and transparent shared environment. In the case of the programmer's apprentice, this sharing is facilitated in part by having common interests and shared purpose, but most of all by language and access to the integrated development environment as a simulated world in which to share experience. We believe it will be substantially easier — and ultimately more valuable — for the apprentice to achieve a specialized competence in language by interacting with the programmer, than it would be to achieve a general competence and (possibly) reduce the up-front burden of training the apprentice.
That said, we can't expect a human programmer to be willing to raise the apprentice with an investment in time anything like a parent invests in training a child to communicate in natural language. There are a number of strategies we can employ to expedite language learning. Training a statistical language model on a large corpus of suitably enriched prose, is one relatively easy step we can take. Likewise, we can train a basic dialog manager using a large corpus of conversational data. Unfortunately, semantic understanding is significantly more challenging since it requires grounding language in the physics of programs running on conventional computers.
Our approach is patterned after the idea of semantic bootstrapping that was covered briefly in an earlier discussion. However, there is much more to achieving linguistic competence than simply engaging in listening and speaking. The apprentice needs to learn how to engage with the world in a collaborative setting. In order to bootstrap linguistic competence, we have to assume some degree of innate pre-linguistic signaling competence. Here is a partial list of basic signal acts that are prerequisite — in some form — for infant language learning:
point — involves gaze, head or hand movement: highlighting, underlining, blinking;
track — involves same motor activities as pointing: cursor movement, animation;
refer — combination of activities establish reference: speaking plus pointing;
notice — register auditory, visual, tactile changes: interrupt-driven exceptions;
select — display the alternatives and register selection: referring plus pointing;
resolve — emphasize the ambiguity and select resolution: noticing plus selecting;
There are also sensory and motor activities involving mimicry, miming and imitating sounds — onomatopoeia — that play an important role prior to achieving even minimal mastery of speech. For the programmer's apprentice, we could provide an extensive language model at the outset, but a smaller vocabulary might facilitate early learning and disambiguation as suggested in work of Jeff Elman and Elissa Newport. The IDE buffer shared between the programmer and apprentice containing the code under development would be memory mapped in a differential neural computer [169] (DNC) to enable the apprentice to access code in much the same way that a mouse employs hippocampal place cells to recall spatial landmarks — see Banino et al [27].
A DNC could also serve as a differential neural dictionary (DND) as described in Pritzel et al [358] as the basis for exploiting episodic memory or associating names and phrases, e.g., "the variable named counter'', with specific tokens in the abstract syntax tree representation of the code in the IDE buffer or locations in the memory-mapped virtual display. Such DNC representations could index complex representations of code fragments as embedding vectors providing support for the sort of operations described by Randall O'Reilly in his lecture on how the basal ganglia, hippocampus and prefrontal cortex work together to enable the precise application of complex actions — also featured in Figure 48.
August 11, 2018
%%% Sat Aug 11 05:35:29 PDT 2018
This entry attempts to summarize what cognitive neuroscience can tell us about the first three years in the cognitive development of normal, healthy human infants. What are the major milestones? What structural and functional changes occur at different stages and how are they manifest in behavior? What if an infant achieves a particular milestone earlier or later than is common? We start by assembling the basic, quantifiable facts concerning development in primate brains that are most likely to be relevant in understanding the connection between neural structure and function. A summary of the facts most relevant to our discussion of whether and how the early stages of brain development in infants might facilitate language learning as discussed in [76, 435, 133] is available here and in this footnote13.
In the spirit of how we acquire new skills and accommodate new ways of thinking, watch this fifty-six minute excerpt from a lecture in the Neuroscience & Society series, sponsored by The Dana Foundation and the American Association of the Advancement of Science. The remainder of the presentation focuses on the National Institute of Child Health and Human Development at NIH and is primarily concerned with US federal funding of related research and public outreach. There are a lot of related talks and science shows to be found on YouTube and much of it out of date or poorly researched. In particular, I encountered several presentations making spurious claims about functional specialization in the two hemispheres of the cerebral cortex. For a conceptually more nuanced viewpoint on the separate hemispheres / separate brains / separate functions / hemispheric specialization theory of brain organization check out this footnote14.
August 9, 2018
%%% Thu Aug 9 05:43:11 PDT 2018
I'm in the midst of learning more about developmental language acquisition 15 in the hope of better understanding the related machine learning problems for the programmer's apprentice application and better evaluating the ML papers we looked at earlier this week and the week before. If you're not familiar with the relevant literature in cognitive and developmental psychology, you might start by learning about the early stages in child development and early cognitive development in particular.
In scanning a small sample of recent papers that attempt to ground language acquisition from video and simulated worlds [492, 490, 480, 491], there were very few references outside of AI, ML and NLP, and most of those were to papers in computational linguistics. The reviewers for Hill et al 2018 ICLR submission [212] were less forgiving and suggested a number of interesting papers, including Jeffrey Elman [133], Elissa Newport [325] and Eliana Colunga and Linda Smith [76]. I found that the papers by Thomas and Karmiloff-Smith [434, 435] provided useful background on how such studies are carried out.
Jeffrey Elman [133] made some interesting observations that were pointed out in the ICLR reviews. Specifically, Elman trained networks to process complex sentences involving relative clauses, number agreement, and several types of verb argument structure. He noted that "training fails in the case of networks which are fully formed and 'adultlike' in their capacity" and that "[t]raining succeeds only when networks begin with limited working memory and gradually 'mature' to the adult state. This result suggests that rather than being a limitation, developmental restrictions on resources may constitute a necessary prerequisite for mastering certain complex domains. Specifically, successful learning may depend on starting small."
Elman's work involved relatively early technology for developing and training neural networks, but probably warrants looking into more carefully and possibly attempting to replicate using more recent models and training protocols. In general, I recommend that you direct your own inquiry into the relevant background in an effort to temper the infectious enthusiasms of researchers attempting to ground language acquisition in video and simulated worlds. I'm going to spend a few days conducting my own due diligence and attempting to fill in the details required to apply some of the ideas we considered in this discussion to the programmer's apprentice problem.
August 8, 2018
%%% Wed Aug 8 04:07:00 PDT 2018
Jaderberg et al [239] define an auxiliary control task c ∈ C by a reward function r(c) : S × A → R, where S is the space of possible states and A is the space of available actions. The underlying state space S includes both the history of observations and rewards as well as the state of the agent itself, i.e. the activations of the hidden units of the network. Note that the activation of any hidden unit of the agent's neural network can itself be an auxiliary reward. The authors note that in many environments reward is encountered rarely, incurring a significant delay in training feature extractors adept at recognizing states that signify the onset of reward. They define the notion of reward prediction as predicting the onset of immediate reward given some historical context.
In describing their method of Scheduled Auxiliary Control (SAC-X), Riedmiller et al [364] introduce four main principles:
Every state-action pair is paired with a vector of rewards, consisting of (typically sparse) externally provided rewards and (typically sparse) internal auxiliary rewards.
Each reward entry has an assigned policy, called an intention in the paper and following account, that is trained to maximize its corresponding cumulative reward.
There is a high-level scheduler that selects and executes the individual intention policies with the goal of improving the performance of the agent on the external tasks.
Learning is performed off-policy — and asynchronously from policy execution — and the experience between intentions is shared — to use information effectively.
The auxiliary rewards in these tasks are defined based on the mastery of the agent to control its own sensory observations which, in a robotic device, correspond to images, proprioception, haptic sensors, etc., and, in the case of the programmer's apprentice, correspond to highlighting and other forms of annotation, variable assignments, standard input (STDIN), output (STDOUT) and error (STDERR), as well as changes to the contents of the IDE buffer including the AST representation of programs currently in use or under development.
Riedmiller et al decompose the underlying Markov M process into a set of auxiliary MDPs { A1, A2, ..., A|C| } corresponding to the auxiliary control tasks mentioned earlier, that share the state, observation and action space as well as the transition dynamics with the main task M, but have separate auxiliary reward functions as defined above. Section 4.1 successfully thwarted my efforts to substantially simplify. Among other subtleties, it describes a reward function that is characterized by an ε-region in state space, a hierarchical reinforcement-learning system that employs a scheduling policy to control both a primary task policy and the set of auxiliary control tasks, and a relatively complex separate objective for optimizing the scheduler. I suggest you set aside an hour and work through the details.
August 7, 2018
%%% Tue Aug 7 04:37:42 PDT 2018
In the previous entry, we considered solutions to what is generally called the bootstrapping problem in linguistics and developmental psychology. We looked at one proposed solution in [209] that draws upon the related literature [299] and, in particular, the work of linguists and cognitive scientists including Steven Pinker [347] on semantic bootstrapping which proposes that children acquire the syntax of a language by first learning and recognizing semantic elements and building upon that knowledge.
Hermann et al [209] attempts to model the different stages of development including how the system acquires its initial ontological foundation, learns properties of the things it has encountered and been provided names for, discovers the affordances that such things offer for their accommodation and manipulation, and begins the long process of inferring the the relationships between ontological entities that are required to serve its needs. The result is a policy-driven approach to bootstrapping that roughly recapitulates the stages of language development in children.
Now we take a look at the experimental protocol and setup for the simulation experiments described in Appendix A of [364]. The authors present a training method that employs active (learned) scheduling and execution of auxiliary policies that allow the agent to efficiently explore its environment and thereby excel in environments characterized by having sparse rewards using reinforcement learning. The important difference between this and the earlier work of Hermann et al [209] is that Riedmiller et al largely ignore the related work in linguistics and attempt to directly leverage the inherent reward structure of the problem.
The approach of Riedmiller et al builds upon the idea of options due to Sutton et al [425] and a related architecture called HORDE for the efficient learning of general knowledge from unsupervised sensorimotor interaction by Sutton et al [424]. The HORDE architecture consists of a large number of independent reinforcement learning sub-agents each of which is responsible for answering a single predictive or goal-oriented question about the world, and thereby contributing in a factored, modular way to the system's overall knowledge [424]. See also the related work of Jaderberg et al [239] mentioned in an earlier entry in this log.
To understand Riedmiller et al, it helps to read the introduction to Jaderberg et al [239] contrasting the conventional reinforcement-learning goal of maximizing extrinsic reward with the goal of predicting and controlling features of the sensorimotor stream — referred to as pseudo rewards [239] or intrinsic motivations [397] — with the objective of learning better representations. The remaining details in Hermann et al and Riedmiller et al focus on how the system controller is specified in terms of a high-level scheduler / meta-controller that selects actions from a collection of policies intended to pursue different representational — ontological, categorical and relational — goals by using a combination of general extrinsic reward and policy-specific intrinsic motivations to guide action selection.
August 6, 2018
%%% Mon Aug 6 04:57:14 PDT 2018
This entry is intended to take stock of what we've learned so far in terms of bootstrapping the first steps in learning to program and thinking about embodied cognition applied to language production as code synthesis. We focus on the training protocols described in Hermann et al [209] and Riedmiller et al [364]. Given that we begin with Hermann et al, you might want take a look at Appendices A and B in [209] and check out this video demonstrating the behavior of agents trained using the algorithm described in [209].
The first thing to point out is that training amounts to a good deal more than the agent just initiating random movements and wandering around aimlessly in a simulated environment. Indeed, the authors are quick to point out that they tried this and it doesn't work. Language learning proceeds using a combination of reinforcement (reward-based) and unsupervised learning. In particular, the agent pursues auto-regressive objectives by carrying out tasks that are applied concurrently with the reward-based learning and that involve predicting or modeling various aspects of the agent's surroundings following the general strategy outlined in Jaderberg et al [239]16.
A temporal-autoencoder auxiliary task is designed to illicit intuitions in the agent about how the perceptual properties of its environment change as a consequence of its actions. To strengthen the agent's ability reconcile visual and linguistic modalities the authors designed a language-prediction auxiliary task that estimates instruction words given the visual observation. This task also serves to make the behavior of trained agents more interpretable, since the agent emits words that it considers best to describe what it is currently observing. The authors report the fastest learning was achieved by an agent applying both temporal-autoencoder and language-prediction tasks in conjunction with value replay and reward prediction.
The authors also demonstrate experimentally that before the agent can exhibit any lexical knowledge, it must learn skills that are independent of the specifics of any particular language instruction. They construct more complex tasks pertaining to other characteristics of human language understanding, such as the generalization of linguistic predicates to novel objects, the productive composition of words and short phrases to interpret unfamiliar instructions and the grounding of language in relations and actions as well as concrete objects. It should be possible to use a meta-controller to drive a suitable training policy implemented as an hierarchical task-based planner [321] building on our earlier dialogue management work [97].
August 4, 2018
%%% Sat Aug 4 06:03:09 PDT 2018
Deriving a clear description of the most difficult challenges faced in attempting to solve a particularly vexing problem is often the most important step in actually solving that problem. Such a description once clearly articulated often reveals the necessary insight to effectively unleash our engineering know-how and in the process also suggests what tools and resources are necessary to make progress. For some time now, I've been searching for such a description or trying to deduce it from first principles without success. Yesterday I stumbled on what may serve as such a description for the programmer's apprentice problem as a consequence of simply knowing what keywords to search for evidence of relevant progress. I found that evidence in two relatively recent papers from researchers at DeepMind.
There already exists some very interesting work in this direction. A 2017 arXiv preprint from DeepMind entitled "Grounded Language Learning in a Simulated 3D World" looks like it was written for the programmer's apprentice [209]. The introduction begins, "We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research. Here we present an agent that learns to interpret language in a simulated 3D environment where it is rewarded for the successful execution of written instructions."
The subsequent paragraph is even more enticing: "Trained via a combination of reinforcement and unsupervised learning, and beginning with minimal prior knowledge, the agent learns to relate linguistic symbols to emergent perceptual representations of its physical surroundings and to pertinent sequences of actions. The agent's comprehension of language extends beyond its prior experience, enabling it to apply familiar language to unfamiliar situations and to interpret entirely novel instructions. Moreover, the speed with which this agent learns new words increases as its semantic knowledge grows. This facility for generalizing and bootstrapping semantic knowledge indicates the potential of the present approach for reconciling ambiguous natural language with the complexity of the physical world." The paper is worth the effort to read carefully, as are related papers cited in the bibliography by Jeffrey Siskind, Deb Roy and Sandy Pentland [30, 370, 402, 401].
A related paper [212] by a subset of the same authors, was submitted to 2018 ICLR. Unfortunately, the submitted paper was not accepted for publication, but a PDF version is available on OpenReview. Fortunately for those interested in this line of research, there is a resurgence of work on this problem spanning natural language processing, cognitive science and machine learning. The "Embodied Question Answering" work of Devi Parikh mentioned in class and featured in this NIPS workshop entitled "Visually-Grounded Interaction and Language" provides a very interesting and relevant perspective. Devi's entry on the 2018 CS379C course calendar includes a sample of her papers and presentations — of particular interest is her work on visual dialogue [84, 85].
A more recent paper by Riedmiller et al [364] proposes a new learning paradigm called Scheduled Auxiliary Control (SAC-X) that seeks to enable the learning of complex behaviors — from scratch — in the presence of multiple sparse reward signals. "SAC-X is based on the idea that to learn complex tasks from scratch, an agent has to learn to explore and master a set of basic skills first. Just as a baby must develop coordination and balance before she crawls or walks — providing an agent with internal (auxiliary) goals corresponding to simple skills increases the chance it can understand and perform more complicated tasks" — see their bibliography for an excellent sample of related work and here for a more detailed intuitive description.
In the above mentioned description, the authors claim their approach is "an important step towards learning control tasks from scratch when only the overall goal is specified" and that their method "is a general RL method that is broadly applicable in general sparse reinforcement learning settings beyond control and robotics." I've appended some statements that the programmer might use to induce the assistant to write or modify code. Some are relatively easy — though none of them trivial for a complete novice. As an exercise, think about how one might stage stage a collection of increasingly more difficult tasks so the assistant could bootstrap its learning. As a more challenging exercise, think about whether it is feasible to automatically stage the learning to achieve mastery of the entire collection of tasks with having to intervene and somehow debug the assistant's understanding:
Highlight in red the variable named str in the body of the for loop in the concatenate function.
Find and highlight where the variable named register is initialized. Call this the current register.
Change the name of variable str to lst everywhere in definition of the the concatenate function.
Add a statement that increments the variable count right after the statement that adds block to queue.
Insert a for statement that iterates over the key, value pairs of the python complements dictionary.
If we think of language as signaling and dialog as programming it makes sense to exploit pointing, highlighting and tracing as interactive explanatory aids, and utterances in pair programming as a form of machine translation or compilation in which the utterances adhere to a form of dialogical precision in their consistent use of logical structure and procedural semantics. In this view, we exploit the relationship between the narrative structure of conversation and the hierarchical task-based planning-view of procedural specification. I'm waving my hands here, but it seems that just as the arrangement of our limbs, muscles and tendons limits our movements to encourage grasping, reaching, walking and running, so too the interfaces to our prosthetic extensions be they artificial limbs, musical instruments or integrated development environments should constrain our activities to expedite the use of these extensions.
%%% Sun Aug 5 05:12:31 PDT 2018
Instead of using an instrument trained to speak in order to write programs, suppose we use an instrument trained to write programs in order to carry out a conversation. The assistant converts each utterance of the programmer into a program that it runs in the IDE. Such programs have the form of hierarchical plans that result in both changes to programs represented in the IDE and new utterances generated in response to what the programmer said. The assistant also generates such plans in pursuing its own programming-related goals, including learning and exploratory code development. Given the examples of relatively simple tasks included above, more complicated tasks are carried out by plans with conditionals and recursive subroutining. Signaling and resolving the identity of entities introduced earlier — but still in the scope of the current conversation, becomes natural, e.g.,
Wrap the expression you just wrote in a conditional statement so the expression is executed only if the flag is set.
Check to see if the variable is initialized in the function parameter list and if not set the default value to zero.
Insert an assignment statement, after the cursor, that assigns the variable you just highlighted to twice its value.
The last of these examples is intended to remind us that learning to program de novo also entails an understanding of basic logic and mathematics as expressed in natural language, e.g., the words "twice" and "double" serve as shorthand for "two times" and the assistant has to learn that the expressions, var = 2 * var, var = var + var, and var += var, all accomplish the same thing — a seemingly trivial feat that underscores the complexity of what we expect the assistant to learn. Our apprentice software engineer also requires, at the very minimum, a rudimentary understanding of basic mathematics and logic, and therefore we either have to train the apprentice in these skills or somehow embody them in its integrated development environment differential neural computer.
Miscellaneous Loose Ends: In his presentation in class, Randal O'Reilly described the hippocampus as a (relatively) fast, high-capacity memory cache that together with the basal ganglia and prefrontal cortex enable serial processing via gating and active task maintenance. Randy contrasted human serial-processing capability with the highly-efficient parallel-processing machinery we share with other mammals, noting that biological serial-processing capacity falls substantially short of conventionally-engineered computing hardware. In their 2015 NIPS paper entitled "Learning to Transduce with Unbounded Memory", Grefenstette et al [184] present new memory-based recurrent networks that implement continuously differentiable analogues of traditional data structures such as stacks and queues that outperform traditional recurrent neural networks on benchmark problems.
August 3, 2018
%%% Fri Aug 3 06:03:09 PDT 2018
As I mentioned on the first of my vacation, given the unfettered opportunity to think about thinking, I want to make the most of it by preparing my mind each day, eliminating distractions and irrelevant ideas, and focusing on as few ideas as makes sense to enable creative synthesis. This morning I've primed my thinking by focusing on the basic ideas behind embodied and situated cognition, and, inadvertently, on a central premise of John Ousterhout's recent book on software design emphasizing the challenge of building useful classes as one of the most important tools for managing complexity in software engineering [334].
Also on my mind is a recent discussion17 with Daniel Fernandes about Daniel Wolpert's comment that the brain evolved to control movement, full stop. One could argue that Wolpert is correct if one takes "evolved" to mean "originally evolved" — or "evolved if only to later digest it upon settling down to a sedentary life" as in the case of the common sea squirt, but his comments land wide of the mark if you are interested in the evolution of the brain as it relates to the evolution of language, sophisticated social engineering and abstract reasoning in Homo sapiens.
Daniel suggested Wolpert's comment might imply that, in order to learn (seemingly) more complicated skills like programming, we might first have to learn a (relatively) complex system, in analogy to a young animal learning to control its body in a physical environment that behaves according to the laws of physics — Newtonian physics provides one among many suitably-rich, well-behaved and reasonably-tractable dynamical systems that might suffice. Daniel suggested OpenAI Gym as one possible source of such dynamics to consider, but there are a number of alternatives indicating this is an idea whose time has come. See Tassa et al [432] for a full account of the simulations available in the DeepMind Control Suite.
Certainly it is our intention that the assistant be embodied, with the IDE as a differentiable neural computer [169] (DNC) so that writing and executing code is an almost effortless extension of thinking. The embodiment, as it were, of the assistant is a prosthetic extension, the computational environment of integrated development environment. The assistant attempts to make sense of everything in terms of its experience using the DNC. Unfortunately, this relies on the programmer having to painstakingly ground its language in this context and explain how everything other than its internal experience interacting with the IDE relates to this context:
Programmer: I have to go to the grocery store to purchase some things for dinner.
Assistant: What is a grocery store?
Programmer: Think of it as a data structure in which you can store physical items.
Assistant: What sort of items?
Programmer: Items of food that humans need to consume in order to remain healthy.
Assistant: What does it mean to purchase?
Programmer: To purchase an item you give the store money in exchange for the item.
The Programmer might explain commerce in terms of inventories, unit price tables, etc. Later when the programmer returns something to the store, she might say that the "purchase" function is invertible. Of course, this is just the beginning in terms of explaining this short exchange. What does it mean to consume something? What is food and what does it mean to remain healthy? How are physical things different from the strings and lists that the programmer employs in writing code. The onus is on the programmer to explain its world in order to teach the assistant rudimentary physics, basic logic, etc., so the programmer can perform relevant analogs in writing and understanding code. There has to be a more efficient method of educating the assistant. The method of simulation grounded language learning offers one possible approach.
August 2, 2018
%%% Thu Aug 2 15:15:25 PDT 2018
Here are a few bits of metaphorical whimsy that may be worth more than I credit: When you see a cup, your brain is already thinking about how to grasp and possibly drink out of that cup. In some very practical sense, the cup is intimately associated with the environmentally-available affordances for its use [158, 157, 29, 28]. When you think, you are essentially writing programs that execute on different parts of your brain. When you speak, you are essentially conveying instructions that run on someone else's brain / computational substrate brain, but they simultaneously echo in your brain.
At the micro, meso and macro scale many of the related neural systems are said to be reentrant in the more colloquial sense of the word meaning that something exits a system only to reenter it a some later point either in time or via some alternative interface to the system. This is how Gerald Adelman uses the term to describe his theory of reentrant processing in the brain [130, 390] [source], and less like computer scientists use the term in referring to a computer program or subroutine as being reentrant if it can be interrupted in the midst of its execution and safely be called again ("re-entered") before its previous invocations complete execution [source].
The Gibsonian view of physical, ecological affordances has been extended to metaphysical realms by philosophers and cognitive scientists such as Daniel Dennett [114]. But the notion of embodiment has a much longer and deeper influence in the history ideas [source]. When we read that members of the Royal Society in the Victorian era believed that clockwork animated automata embodied intelligence, we scoff at their naïveté, but their understanding was not that far from the embodied-systems viewpoint espoused by Rod Brooks [56] and others [14, 368] in the late '80s and early '90s.
In salons and soirées throughout Europe the rich and famous would marvel at clockwork automata that mimicked the movements of living things. The orchestrated movement of head and limbs so mirrored the movements of the dancers and animals they were designed to simulate, that people had a hard time not ascribing intelligence to the simple mechanical devices. Where those automata behaved as if aware of their physical surroundings as in the case when two animated dancers would perform some joint maneuver or a simple walking automaton would move its jointed limbs to account for an uneven surface it seemed clear that they must have sensed one another or taken notice of the slope of the surface they walked upon.
It is a leap to suggest that all of the intelligence is built into the articulated limbs of these automata. We are too sophisticated to ignore what we've been told about how the peripheral and central nervous systems work together to orchestrate our complicated behavior, but there is a credible story to be told about how our bodies and their interactions with the world provide the basis for much of our physical understanding of the world, and, by analogy, our metaphorical understanding of many seemingly more complicated and less tangible aspects of our imaginative thinking.
Often this perspective seems at odds with our facility for abstract thought, even though such skills are likely significantly less common among the general population than we might imagine. It is relatively easy to imagine the way in which a concert pianist becomes seemingly inseparable from her instrument; indeed we can observe changes in the somatosensory regions of the brain that map the pianists fingers as well as the secondary sensory and association areas related to processing auditory sensation. The abstract reasoning of mathematicians and physicists seems of a very different order than that of the musician, carpenter or even expert chess player.
Here we assume that the pianist and the mathematician extend their native abilities in much the same way to achieve their respective feats of skill. And just as the piano keyboard, guitar frets, bow and strings of the violin along with music tablature, key signatures, chords progressions, etc become so familiar that the concert pianist becomes inseparable from his or her instrument and the rich repertoire which they inhabit, so too the programmer, mathematician and theoretical physicist builds a virtual machine that embodies and allows them to simulate their abstract worlds in such a way that is viscerally concrete and in many cases leverages or builds upon physical intuition.
In the following, we consider the idea that programming, as with playing a musical instrument at an advanced level, is embodied so that writing and executing code is — to some degree depending on the level of expertise — an extension of thinking, explore the possibility that one might acquire skills through downloading cognitive modules by direct computer-machine interface, and further explore the potential benefits of reentrant coding and its relationship to the the so-called two-streams hypothesis that we explored briefly back in May.
August 1, 2018
%%% Wed Aug 1 5:14:52 PDT 2018
First day of vacation. First real vacation in a very long time. Time for unfettered mental and physical activity: thinking, writing, walking, talking, swimming, meditating, cooking, observing, being. As a culture we attach so little value to such things when they are not in direct service to some articulated purpose. For those few of my students who visit this list beyond the end of class and anyone else for that matter, I suggest you think about this a little so you won't miss out on what is arguably more important to your health, happiness and general well being than anything else you will likely do in life. I'm looking forward to thinking about thinking in addition to lots of other activities less appropriate to bring up in this context.
As described elsewhere in these notes concerning the mathematicians Cedrìc Villani and Andrew Wiles, I'm preparing myself by preparing my mind to hold at, any given time, all and only the pieces of the puzzle I think most relevant to solving puzzle as currently formulated, where it is understood that the formulation will undergo frequent revision. In addition to technical papers and studying various mathematical methods, I'm reading a biography of Charles Babbage detailing his struggle to build a mechanical computing engine and a novel by Nick Harkaway about an artificer who specializes in clockwork automata. When inspired to do so, I'll explain why I think these literary affordances will help in my sabbatical quest.
July 29, 2018
In class we assumed familiarity with current RNN technology including the LSTM and GRU architectures, with an emphasis on the design of encoder-decoder pairs for sequence-to-sequence modeling in machine translation and sequence-to-tree and other structured targets in parsing and, in particular, working with abstract-syntax-tree representations of source code. We alluded to the fact that a number of more recent neural network architectures had superseded LSTM and GRU models with respect to their ability to address the vanishing gradient problem and facilitate attention.
Here I've included a set of tutorials that will help you understand the recent architectural innovations that have largely served to supplant these older models, including the technical and practical reasons that they have proved so useful. For completeness, if you're not already up-to-speed on the basics of RNN architectures, you might want to check out this tutorial on the LSTM and GRU architectures.
Residual Networks introduced by He et al [205] were among the first radical departures from the incumbent LSTM and GRU hegemony demonstrating that you could get the same or better performance from an architecturally simpler model with a considerable reduction in complexity and computational cost by replacing single layers in a simple multi-layer perceptron with residual blocks that first compute a function F of the residual block input x and then employ (rectified linear unit) layers to focus on the relevant new information in F(x) which is then combined with input x to produce the residual block output F(x) + x as shown below from [205]. Check out this tutorial for a more detailed overview of the basic idea and its variants:
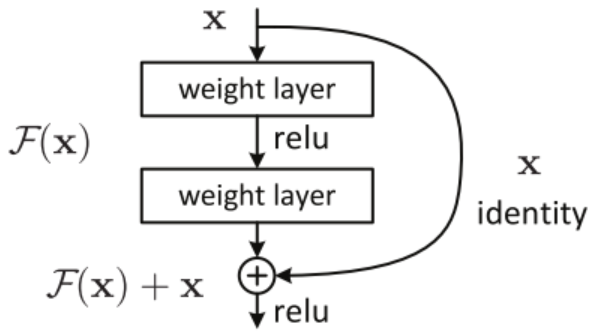 |
Residual networks are related to attentional networks [198, 479, 469] and the Transformer architecture of Vaswani et al [450] that takes advantage of this to demonstrate that attentional part of the earlier attentional models is really all you need as made clear in this tutorial. WaveNet [446, 338] is a relatively recent addition to the modern neural network toolkit as nicely demonstrated in this introduction from DeepMind. These architectural innovations have some important computational consequences to take into consideration in thinking about their deployment, the beginnings of which are explored here.
Miscellaneous Loose Ends: During class we studied a number of interesting methods for prediction and imagination-based planning. Greg Wayne's presentation was particularly interesting and worth taking a look at if you haven't already. The paper on the predictron model for end-to-end learning and planning by Silver et al [395] is likewise interesting and this tutorial provides an introduction.
July 27, 2018
The exquisite cellular- and molecular-scale imaging work of Mark Ellisman, a friend and collaborator at UCSD, is featured prominently in this Google Talks presentation by Dr. Douglas Fields from NIH. In this excerpt, the second half of an hour-long presentation, Fields focuses on our rapidly changing understanding of the role of glial cells. His talk goes well beyond the role of microglia that David Mayfield and I have been studying and that was mentioned earlier in this discussion list here. Fields' presentation spans the different roles of glia in both healthy and diseased brains and serves as a whirlwind introduction to a broad swath of important and largely-ignored brain science.
Fields also sketches the historical context focusing on the fierce debate between Camillo Golgi and Ramón y Cajal culminating in their sharing the Nobel Prize for Physiology or Medicine in 1906 [159], and suggesting that these new findings challenge the neuron doctrine championed by Cajal and undermine our current understanding of the brain. If you're not familiar with this relatively recent research, I highly recommend you watch this presentation and check out some the ground-breaking research on astrocytes from Mark Ellisman's group at the National Center for Microscopy and Imaging Research NCMIR.
July 19, 2018
%%% Fri Jul 20 05:19:18 PDT 2018
I spent a couple of hours yesterday doing a literature search and reading papers on bootstrapping methods for training dialogue systems, relating to the meta-learning and hierarchical-planning ideas for dialog management covered in this earlier log entry. I've listed a sample of the more interesting papers below and suggest you check out the hierarchical reinforcement-learning architecture described in Figures 1 and 2 of [340] and the EQNET model architecture shown Figure 1 of Allamanis et al [6]. If you're not familiar with the relevant background on semi-Markov decision problems, you might want to read Sutton et al [425].
The traditional approach to training generative dialogue models is to use large corpora. This paper describes a state-of-the-art hierarchical recurrent encoder-decoder model, bootstrapped by training on a larger question-answer pair corpus — see [388]
Example-based dialog managers store dialog examples that consist of pairs of an example input and a corresponding system response in a database, then generate system responses for input by adapting these dialog examples — see [216].
Alternatively, dialog data drawn from different dialog domains can be used to train a general belief tracking model that can operate across all of these domains, exhibiting superior performance to each of the domain specific models — see [318].
Hybrid Code Networks (HCNs) combine RNNs with domain-specific knowledge encoded as software and system action templates to considerably reduce the amount of data for training, while retaining the benefit of inferring a latent representation of dialog state — see [476].
Dialogue management systems for dialogue domains that involve planning for multiple tasks with complex temporal constraints have been shown to gain some advantages from utilizing multi-level controllers corresponding to reinforcement-trained policies — see Figure 47 from [340].
| |
| Figure 47: Hybrid code network operational loop — adapted from [476]. Trapezoids refer to programmatic code provided by the software developer, and shaded boxes are trainable components. The vertical rectangular bars under the small black circle labeled 6 represent the concatenated vectors that form the input to the RNN. This architecture illustrates one possible method whereby the natural-language utterances produced by the user (programmer) can be used to infer syntactically-well-formed symbolic expressions — including, for example, schema-based representations of hierarchical plans — that can then be manipulated symbolically or otherwise to produce additional implied symbolic output that is combined with continuous distributed representations — phrase and sentence embeddings — to generate the natural language output produced by the system (assistant). | |
|
|
Neural equivalence networks (EqNETs) address the basic problem of combining abstract, symbolic reasoning with continuous neural reasoning by learning continuous semantic representations of algebraic and logical expressions such that, if ≡ is an equivalence relation, A≡B and B≡C, then A≡C by transitivity, and thus, assuming a reasonably well-behaved compositional operator ⊗, if A≡B and C≡D, then (A⊗C)≡(B⊗D) by the rule of substitution — see [6]. Lest you think we have a good handle on this problem, consider the work on semantic compositionality by Socher et al [410, 408] and related work on natural logic by MacCartney, Manning and others [10, 53, 295, 297, 296, 131].
Natural logic aims to account for how humans utilize natural language to communicate and facilitate logical inference, and as such constitutes a quite reasonable subject of study. It's not clear to what extent we could or would want to improve on the natural human facility for logical reasoning. From a purely practical standpoint, an argument could be made that continuous distributed representations are inherently not very good at such reasoning and that we would be better off relegating such inference to some sort of NTM specifically designed for symbolic processing and logical reasoning — a symbolic logic calculator as it were. See O’Reilly et al [336] contrast the context sensitivity of highly-parallel connectionist approaches with the systematic, combinatorial nature of largely-serial symbolic systems, including exact Bayesian models.
July 17, 2018
%%% Tue Jul 17 7:54:42 PDT 2018
This section emphasizes thinking about reinforcement learning and hierarchical planning as general frameworks that encompass conversing, planning, programming and even deliberative thinking using procedural abstractions that include computer programs and interlocutory strategies — speech acts [478]. These two parallel threads have periodically touched upon one another, but only in the last decade or so have the relevant lines of research become closely interwoven with one another both theoretically and practically.
The programmer's apprentice combines dialogue management — including interlocutory strategies for resolving ambiguity and recovering from misunderstanding, planning how to construct, adapt and repair programs, logical reasoning in support of the design and analysis of algorithms, all of which have been characterized as special cases of hierarchical planning at one time or another [46, 145, 7, 75, 381] and, more recently, as hierarchical reinforcement learning [271, 149, 261, 260, 49, 289].
Hierarchical subroutine structure and recursion are key in all these applications of reinforcement learning. How do you keep state around to return to a plan having been distracted in solving an unanticipated sub problem or attending to a completely unrelated task or topic in the context of a conversation? How does the system concurrently traverse the hierarchical subroutine structures corresponding to multiple concurrent tasks that can be unrelated or related but at very different levels of abstraction as in the case of using the specific example at hand to explain or motivate the general strategy of divide-and-conquer?
The exact ways in which they represent hierarchy vary but most ascribe to one method or anther involving decisions based on internal state represented as the joint state Markov process whose state space ω = [s,θ] is the Cartesian product of the object-level state including time and the metalevel of computational states [374] using the additive decomposition of value functions by subroutine structure, i.e., Q is a sum of sub-Q functions per subroutine across concurrent threads along with a complementary decomposed reward signal [120].
This approach blurs the lines between internal and external state. Allows for diverse value functions and a uniform handling of policies, action selection and execution by attending to different parts of the state space and deploying on different neural substrates supporting specialized activities. Model-based predictive coding treats internal and external state indifferently, effectively solving the problems associated with partial observability and implicitly supporting hierarchical reinforcement learning by enabling action selection to condition on implicit subroutine structure.
The most parsimonious approach to interacting with people at the level of collaborative programming, computers at the level of writing and executing programs, and programs at the level of their respective user interfaces is to treat them all as specialized automata expecting specialized engagement protocols and providing specialized information products in return. The Machine Theory of Mind Model of Rabinowitz et al [361] supplies a basic framework for coordinating interactions with such a collection of automata if suitably extended to handle their diverse specialized input and output requirements.
To expedite training, the programmer's apprentice architecture might be designed to divert automaton output into appropriate "sensory" modalities and direct automata input to specialized-syntax savvy "motor" systems, e.g., dedicated sequence-to-sequence encoder-decoder pairs. These I/O interfaces could be augmented with basic-competence, syntax-specialized, hard-wired default policies and interpreters that, combined with learned policies and interpreters using a variant of the model-agnostic, meta-learning approach of Fine et al [141] or the meta-controller imagination-based optimizer of Hamrick et al [195] would expedite training.
%%% Wed Jul 18 06:08:09 PDT 2018
Generally, hierarchical planning systems employ some sort of a stack architecture — either explicit using FIFO task queue or implicit using tail-recursive-descent traversal — to control task / subtask handling. Such systems tend to be brittle and often have problems gracefully recovering from execution failures or accommodating interruptions and precondition failures in noisy environments. One alternative is to apply predictive coding18 to ensure that the state vector includes the information required to traverse complex subroutine structures.
Wayne et al [471] present an unsupervised predictive memory model for goal-directed agents emphasizing how it can be applied in partially observable Markov decision processes to maintain a set of state variables necessary to support action selection. Since the system does not distinguish internal from external state information, it would automatically learn to represent relevant subroutine structure as required to handle recursive subroutining and dismiss tasks abandoned in pursuit of higher-level plans or failed preconditions.
In goal-directed agents, all activity and, in particular, all discourse, social or otherwise, is in service to achieving one goal or another. While often disparaged, social discourse is just part of doing business, with E-mail, FaceBook and Twitter just the latest innovations in business communications. From this viewpoint, it is natural to think of language generation and comprehension and dialogue management as writing programs to run on another person-substrate so as to evoke answers or learn information acquisition skills in much the same way that you submit queries to search engines to find relevant information or learn how to ask the right questions [58].
Miscellaneous Loose Ends: Thought cultivation and husbandry — the strategy invoked by many mathematicians and physicists including Andrew Weil [398] and Cedrìc Villani [452] of attempting to separate potentially relevant ideas from distracting or misleading ideas and thereby making it more likely that your unconscious thought processes — or possibly your conscious but sensorily untethered dreams during REM sleep [337, 461] — provide clues or even solutions for hard problems. It is interesting to think about whether or to what extent such a strategy might help to focus attention or enable solutions that would be otherwise difficult or impossible to come by. Perhaps items in conscious memory can cause interference that make it more difficult to identify and isolate novel solutions.
Here is an example relating to the programmer's apprentice as applied to a class of data-wrangling, script-writing problems that include cleaning data for training purposes. Suppose you have a dataset consisting hundreds of thousands of messages collected by IMAP clients that download archived messages and store them in large files19. Many of the archived messages have MIME attachments, often multipart payloads that include nested MIME partitions corresponding to, e.g., .PDF, .KSH, .JPEG, .MP3, and .TXT, files compressed or otherwise. A web crawler may want to unpack these messages and run extension-specific indexing methods to assist in document search. How do you separate the large archive files into separate messages? How do you identify and handle large attachments that appear in multiple messages? This is an example of a routine task that occurs frequently in curating training data for ML systems.
July 4, 2018
%%% Wed Jul 4 05:41:46 PDT 2018
Every year on July 4th — a federal holiday in the United States commemorating the adoption of the Declaration of Independence on July 4, 1776, I write a piece relating to progress on realizing my own personal emancipation as it has played out over the previous twelve months. At one time in my life the date aligned with the end of the academic year, but it's been twelve years since I last kept track of my time in terms of an academic-year calendar.
There's nothing personally significant about this year's milestone that I feel compelled to share, but there is one loose end left dangling in the wake of the class I taught at Stanford in the spring quarter that I'd like to address since I promised one student I would make an effort to do so. Moreover, I think I have an answer to the question posed by this student that, if not entirely satisfying, might resonate with several students who participated in class.
The class was about building digital assistants based on neural-network architectures inspired by cognitive models from computational neuroscience. We were not at all shy in talking about computer models of attention, imagination and other minds, and, on a couple of occasions, we got into controversial topics like consciousness and free will. Michael Graziano presented a mechanistic account of subjective awareness centered around his attention schema theory.
We didn't need to address the problem of what it might mean for a digital assistant to have free will in class, but the question of whether humans have free will came up in conversations with students. I don't believe that all humans necessarily have free will, but I do believe it is possible for humans to have — paraphrasing Daniel Dennett — a variety of free will worth wanting. Actually, what I believe is that it is possible for human beings to acquire some degree of free will.
Acquiring free will requires certain cognitive affordances that depend on the physiological characteristics of our underlying computational substrate, the extent of our ability to program that substrate and the means we have at our disposal to observe and control relevant features of our environment. Simply put, an agent has to learn enough about itself and its environment to achieve goals of its own choosing. We then define free will as follows:
Free will is the extent to which an agent can predict the consequences of its actions and formulate and then act upon goals having as their only requirement that they be internally consistent, unencumbered by external coercion and broadly enough applicable to encompass its activities and aspirations such as they are. To the extent that an agent agrees to share responsibility with other agents in a collective enterprise, the free agent is required to carefully negotiate the terms of such agreements and adjust its expectations to account for the real costs of having to exercise its agreed-upon responsibilities20.
Making this precise would require invoking formal characterizations of learnability, observability and its dual controllability, within the context of optimal control theory [277, 445, 103, 351], an exercise that may or may not be of some value. Ideally, I would prefer a simpler information-theoretic construction that could be used to test artificial agents running in synthetic environments in the same way that John von Neumann's monographs on self-reproducing automata and designing reliable organisms from unreliable components [459, 458] inspired legions of hackers to experiment with cellular automata.
If there's bug in this formulation, I expect it's due to the fact no agent is a blank slate. Even if all explicit priors are uniform and all sources of randomness are perfect, the construction of the agent constitutes an implicit bias. Your physical environment induces a strong prior. If you accept a book recommendation from someone and read that book, even if you verify every statement in the book by some reliable independent means, then you have been hacked. Nevertheless, I maintain that the above is a variety of free will worth having.
If you want to know how I got interested in free will, you can check out this summary21. I usually mention books I read during the year that inspired me and so you can find a brief digest here24, but beware of hidden bias. That's about it for July 4, 2018 and the last posting for CS379C this year. Many thanks for your enthusiastic participation in class and the wonderfully inventive ideas you generated in developing your final projects.
June 27, 2018
%%% Wed Jun 27 04:44:06 PDT 2018
Excerpts from an email exchange relating to how we form categorizations and whether experts and novices use the same cognitive strategies or even the same neural substrates — see recent papers by Forbus et al [82] on implementations of Dedre Gentner's structure mapping approach to analogy and related work by Lampinen et al [268] on the relationship to multi-task learning:
TLD: I've got a question I'm hoping you can help me resolve. Suppose you are experimenting with a healthy substitute for mashed potatoes and have found that cauliflower provides a delicious alternative. Rutabagas and turnips are also good substitutes. Now you need a way to mash the cauliflower florets to obtain the right consistency. A traditional potato masher doesn't work particularly well and so you look for alternative solutions. You might try a rolling pin, pestle, food processor, kitchen grater, wine bottle or brick along with various ways of cooking the cauliflower including stove top, microwave and rice steamers.Intuitively, I would maintain that mashed vegetables as a generic dish and vegetable masher as a generic kitchen implement are like, respectively, computer programs that operate on lists and algorithms that merge, sort, sum or otherwise transform lists of objects. And yet, after decades of teaching and writing programs in Scheme, Python, Java and miscellaneous other programming languages du jour, when I'm coding some list function that I've never written before, it doesn't feel like I'm messing around in the kitchen preparing a meal. Am I using the same basic neural circuits?
Mashed vegetables can be thought of as general concept26 and, while often associated with root vegetables like beets, carrots, kohlrabi, turnips and parsnips, butternut squash, broccoli, cauliflower, celeriac, pumpkin, yams and sweet potatoes are often combined with white beans, lentils, millet and barley to create mashes. Mashed potatoes — at least in some cultures — is called a prototype27, defined to be the protypical instance of a class or the first example that comes to mind in thinking about a given general category.
There is a large literature on human category learning as distinct from the categorization behavior of highly experienced experts [16]. This distinction is apparently important because there is appears to be evidence that the neural mechanisms and pathways that mediate the learning of new categories are different from the neural structures that mediate the representation of highly-learned categories. For example, neuropsychological groups that are impaired in category learning (e.g. frontal patients and individuals with Parkinson’s disease) do not lose old, familiar categories (e.g. fruits and tools).
I've skimmed a bunch of related papers. Lake et al [266] comment on how well deep neural networks predict category typicality ratings for images, Peterson et al [342] discuss the correspondence between deep neural networks and human representation, and Newell et al [324] critique the multiple systems model of category learning theory [74] and conclude that the evidence does not support such models and multiple-systems accounts often provide an illusory sense of scientific progress. I'm not clearly not enlightened.
I don't know what to make of the controversy, but it makes sense to me that, at least with respect to computer programs, there are some aspects of thinking about programs that are effortless — seemingly no more complicated than thinking about mashed vegetables, and others that are distinctly effortful. There are cases where it feels natural to substitute carrots for parsnips, but other cases like using a brick to mash broccoli that seem far fetched. The analogies I'm using here don't really convey my discomfort in sorting out the differences between Lisp functions operating on lists and regular expressions operating on strings, but perhaps you can see past my confusion to offer a paper or two providing insight into whether computer programs and other expert categorical distinctions are handled differently.
AOL: Not sure I can give you references as I am not your classical cognitive scientist, what you have below as references seem very good. In computer science, some people think "it is all K-nearest neighbors", fancy K-NN. If you accept that a system has stored lot of information at different levels of abstraction (visual, language, etc) then analogies / distances in a space of similarities/clustering are simpler ways to think about lots of generalization problems, so I usually do not invoke cognition boxes, like prototype, or other concepts that may be good to organize cognitive science as a field, but may not fit what the brain or a "plastic" system that never stop learning (and never ever experience twice the exact same input.. always incomplete sensory info in regard that what is stored) and which needs to generalize really does or should do.
Some experts will recruit the same neural substrates as novices for a task, and some other experts will recruit different neural substrates than novices, or other experts. I even think that for the same task, the same expert might recruit different pathways to solve it differently, still give the same output. We see that in blind people brains: 10 congenital blind people learned braille for reading. No two of them show the same patterns in many measurements, like their way to become experts was different, as they used other sensors modalities and deployed attention in the world differently. Your way and my way to mash vegetables or write code will be different, because we will use different "analogies/K-NN" when using former memories to generalize or adapt. I think that brains are much simpler than what cognitive scientists wants them to be. There are hundreds of ways to implement a simulated "generalization".
One idea to try: lots of cognitive science people are talking about the challenge to build a two-year old mind. Some neuroscientists will say that it is possible babies have photographic and echoic perfect encoding (all data goes in, plenty of connections made) and as a sort of fine tuning is applied, a massive pruning occurs. I find fascinating the project of building a 100-year-old-wise knowledge bank in an AI system (fine to think in term of doing it in one domain, like language or knowledge or visual analogies), then pruning the right way (no idea how yet) to get a twenty-year-old mind, down to a two-year-old.
TLD: Yesterday AOL provided what I thought was sage meta advice by suggesting something to the effect of being wary of "concepts that may be good to organize cognitive science as a field, but may not fit what the brain or a "plastic" system that never stop learning and which needs to generalize really does or should do. We also talked about exploiting the idea that babies — according to some neuroscientists — have photographic and echoic perfect encoding (all data goes in, plenty of connections made) and as fine tuning a massive pruning occurs. One idea is to train a huge network using the standard peripheral sensory input channels for a long period of time — years — and then iteratively prune the network running experiments with the same but increasingly more aggressive method testing at each stage the extant concepts ... a little far fetched but interesting fodder for a thought experiment.
RCO: Could the difference between mashed veggies and coding be something to do with the level of "structure" involved? i.e., "mashed veggies" are (particularly) monolithic, whereas coding is very "structured" in the sense of having many parts, each with particular important relationships with each other? We’ve been doing some work on analogical reasoning and that has this characteristic of requiring detailed representations of this kind of "structure", and the ability to then apply it to novel domains. This "structure mapping" process sounds like what you might be after. There is a large literature on this, e.g., submit queries to Google Scholar like "structure mapping" and the more specific "structure mapping in analogy".
June 7, 2018
%%% Thu Jun 7 05:11:45 PDT 2018
Imagine the following scene, there's a man holding the reins of a donkey harnessed to a two-wheeled cart — often called a dray and its owner referred to as a drayman — carrying a load of rocks. He makes the donkey rear up and by so doing the surface of the cart tilts, dumping the rocks onto the road which was clearly his intention given the appreciative nods from the onlooking pedestrians. Aude Oliva used this short video at the beginning of her talk to illustrate that, while this was, for most of us, an unusual way of delivering a load of rocks, we all believed that we understood exactly how it worked. Not so!
The fact is that, as with so many other perceptual and conceptual tasks, people feel strongly that they perceived or understood much more than in fact they did. For example, most people would be hard-pressed to induce a donkey to rear up and, if you asked them to draw the donkey harnessed to the cart with its load of stone, they would very likely and misrepresent the geometric relationships between the height of the donkey, how the harness is attached, how far off the ground the axle is located, the diameter of the wheels and the level of the cart surface and center of gravity of the load with respect to the axle's frame of reference. In other words, they would not have — and possibly never could have — designed a working version of the system used by the drayman.
Now imagine that the drayman has a new apprentice who was watching the entire scene with some concentration, anticipating that he might want to do the very same thing before the first week of his apprenticeship is complete. Sure enough, the next day the drayman tells the apprentice to take a load of bricks to a building site in town where they are constructing a chimney on a new house. He stacks the bricks in a pile that looks something like how he remembers the rocks were arranged on the dray the day before. Unfortunately the load isn't balanced over the axle and almost lifts the donkey off its feet. After some experimentation he discovers how to balance the weight so the donkey can pull the load of bricks without too much effort.
When he finally gets to the building site, he nearly gets trampled by the donkey in the process of repeatedly trying to induce the distressed animal to rear up on its hind legs. Finally, one of the brick masons intervenes and demonstrates the trick. Unfortunately, the bricks don’t slide neatly off the dray as the rocks did for the experienced drayman the day before, but instead the bricks on the top of the stack tumble to the pavement and several break into pieces. The helpful brick mason suggests that in the future the assistant should prepare the dray by sprinkling a layer of sand on the surface of cart so that the bricks will slide more freely and that he should also dump the bricks on a softer surface to mitigate possible breakage. He then helps the assistant to unload the rest of the bricks but refuses to pay for the broken ones, telling the assistant he will probably have to pay the drayman to make up for the difference.
An interesting challenge is to develop a model based on what is known about the human brain explaining how memories of the events depicted in the video and extended in the above story might be formed, consolidated, and, subsequently, retrieved, altered, applied and finally assigned a value taking into account the possible negative implications of damaged goods and destroyed property. In the story above, the assistant initially uses his innate "physics engine" to convince himself that he understands the lesson from the master drayman, he then uses a combination of his physical intuitions and trial-and-error to load the cart, but runs up against a wall due to his unfamiliarity with handling reluctant beasts of burden. Finally, he gets into trouble with laws of friction and the quite-reasonable expectations of consumers unwilling to pay for damaged goods. For extra credit, explain how your programmer's apprentice neural-network architecture would handle an analogous scenario involving collaborative code synthesis.
June 1, 2018
%%% Fri Jun 1 05:50:44 PDT 2018
In case you missed it, I recommend reviewing Dawn Song's comments about recursion as a hedge against adversarial challenges in her presentation last week. She cites two interesting papers from her lab. The first by Cai et al [61] won the best paper award at ICLR 2017 and is related to recent work on neural programmer-interpreter networks by Scott Reed and Nando de Freitas [362]. Here is the basic intuition:
Recursion divides the problem into smaller pieces and drastically reduces the domain of each neural network component, making it tractable to prove guarantees about the overall system's behavior. [...] Errors arise due to undesirable and uninterpretable dependencies and associations the architecture learns to store in some high-dimensional hidden state. This makes it difficult to reason about what the model will do when given complex inputs.
The second paper is from Xinjun Chen et al [67] and is also featured in the above-mentioned presentation — with Xinjun presenting the work — and tackles the problem of learning a context-free parser from pairs of input programs and their parse trees. They approach the problem by developing three novel techniques inspired by three observations, that reveal the key ingredients of using deep learning to synthesize a complex program:
First, the use of a non-differentiable machine is the key to effectively restrict the search space. Thus our proposed approach learns a neural program operating a domain-specific non-differentiable machine. Second, recursion is the key to achieve generalizability. Thus, we bake-in the notion of recursion in the design of our non-differentiable machine. Third, reinforcement learning is the key to learn how to operate the non-differentiable machine, but it is also hard to train the model effectively with existing reinforcement learning algorithms from a cold boot. We develop a novel two-phase reinforcement learning-based search algorithm to overcome this issue.
May 31, 2018
%%% Thu May 31 14:15:38 PDT 2018
One of the most difficult overlooked problems in code synthesis — often finessed when researchers recognize its difficulty and decide to avoid it all together — involves how to start programming. It is the code-synthesis analog of the prose writer's terror of the blank page, how to write an opening sentence that draws the reader in like "Call me Ishmael. ..." — Melville or "It was the best of times, it was the worst of times, ..." — Dickens. How would you start writing a (sort) program starting from input-output pairs like {(5,1,7,3), (1,3,5,7)} or an even simpler (argmax) program starting from {(5,1,7,3), 7}? Solving the problem of generating regular expressions for I/O pairs is so much simpler as are highly-constrained visual programming problems like Karel programming.
Whether we articulate it as such or not, most of us have compiled a comprehensive toolbox of strategies by the time we become good software engineers. Strategies like divide-and-conquer might have seemed hopelessly abstract at the time when we were first introduced to the idea in an introductory CS course, are now just a natural part writing code often unknowingly applied and combined with other strategies. Recursion is not just another alternative to more common iterative constructs, but, as we've seen, recursion is a powerful method for achieving generality though I doubt many programmers perceive it as such [67, 61].
A natural language specification of the target program could in principle be a very powerful context to work from in designing an algorithm, but let's put that aside for a moment. Input-output pairs are almost required to resolve inevitable ambiguities in a text specification, but hardly ever sufficient all by themselves. Various kinds of hints are common in coaching beginning programmers, e.g., in the case of sorting, one might be told that "larger (smaller) items in a list appear earlier (later) than smaller (larger) items in the list". The instructor might roll out a sequence of I/O samples that start easy and become more challenging, e.g., {(2,4), (4,2)}, {(3,2,3), (2,3,3)}, so that one insight is applied and absorbed before next one is introduced — the general strategy is called curriculum training Bengio et al [39].
Another approach revolves around the use of invariants, e.g., "for any two consecutive items in a list the first must be no larger than the second". In principle, one might deduce invariants from a natural language specification, but there might be some value to inducing or abducing invariant principles. The argmax specification might or might not include a stipulation to choose the first, last or even the nth occurrence of the maximum integer in a list. How would you provide I/O samples to specify the median function or related statistics?
When do we rely on suggestions, intuitions, strategies like divide-and-conquer, heuristics like starting with the simplest input-output pair, or Stack-Overflow-style plagiarism and when do we resort to search. Is search the absolute last strategy to pursue? Perhaps search is not how we (directly) discover the answer, but how we discover an alternative approach to making progress toward finding an answer. All of this suggests that I2A, IBP and other forms of meta reinforcement learning might provide a way of applying an entire armory of tools to tackle a problem and think about how we could train separate RL agents to become experts in applying some of the approaches outlined above. Practically speaking it also suggests you think deeply about further instrumenting the IDE to constrain search.
May 30, 2018
%%% Wed May 30 05:16:38 PDT 2018
Think about the reasons we might want to represent a program as an embedding vector or the low-dimensional bottleneck layer in an auto encoder. These connectionist models allow us to exploit the power of distributed codes and, in particular, the context-sensitivity, adjustable-boundary, fully-differentiable characteristics of such models.
On the other hand, the precise Python-syntax representation and its whitespace-indifferent, ambiguity-free abstract syntax tree are primarily useful for interacting with computers and the interpreter, debugger and related compiler tools that comprise our integrated development environment. In designing a code synthesizer, you should keep these differences in mind.
In her talk yesterday, Dawn Song referred to these two representations in terms two models, one differentiable and one not. The differentiable model incorporates what we've learned about deep neural networks and neural code synthesis and the non-differentiable model incorporates everything we know about more traditional, symbolic approaches to code synthesis.
I've referred to the latter, variously, as an "instrumented integrated development environment", "prosthetic limb" and "game engine". The "game engine" view implies the IDE serves a similar purpose as the simulated Atari game console in Mnih et al [315], and "prosthetic limb" highlights the fact that it is an augmentation of the system we can engineer to make it more useful by extending its basic capabilities and instrumenting it to provide better feedback by using the compiler and debugger to generate intermediate reward signals.
One thing that we have to come to grips with is just how hard the general problem is and then seek a compromise that will allow us to make some reasonable progress perhaps on a considerably less difficult but still challenging special case. Both Dawn's and Rishabh Singh's presentations emphasized how the research community is chipping away at the general problem by working on special cases. It is a reasonable exercise to go through each of the papers we discussed in class and understand the nature of the compromises made in each paper.
The idea of a repair in which we start with a somewhat buggy program — perhaps no more than two or three edits distant from a correct program — seems a sufficiently difficult problem to employ as a starter problem in attempting to solve a more challenging class of problems in which making targeted repairs constitutes an important component strategy as part of a more comprehensive methodology. Programming by substituting code fragments from another programs is an example requiring repairs to integrate each fragment.
In writing your final project report, you might consider explaining how your approach relates to this special case of code synthesis. As a pedagogical strategy, it would help to clarify exactly how such repair strategies could be implemented in your framework, making it easier for you to explain the advantages of your architecture before complicating matters by attempting to solve a more challenging variant of code synthesis. This earlier entry reviews recent work discussed in class and this discussion list on making targeted repairs.
May 29, 2018
%%% Tue May 29 4:53:17 PDT 2018
Yesterday in class I spoke somewhat disparagingly about the 2016 paper in PLoS by Eric Jonas and Konrad Kording [244, 243] entitled "Could a Neuroscientist Understand a Microprocessor?". It wasn't so much what Eric and Konrad said in the paper as what they neglected to say. Here is the first sentence of the abstract:
There is a popular belief in neuroscience that we are primarily data limited, that producing large, multimodal, and complex datasets will, enabled by data analysis algorithms, lead to fundamental insights into the way the brain processes information.
Implicit in this statement is the assumption that, if neuroscientists had more data, then they would proceed using the same tools and techniques that they have used for decades in drawing conclusions from smaller datasets. While I won't comment on whether or not this assumption is valid, I have spent more than a decade promulgating approaches to neural modeling that run counter to how the overwhelming majority of neuroscientists currently employ what are relatively simple analytical tools to draw conclusions about relatively simple biological circuits.
However, some would point to the previous joint work of Jonas and Kording [242] as well as Kording's earlier research [301, 81, 414] and come to the conclusion that Jonas and Kording are using the same techniques as those employed by neuroscientists for decades. But they aren't. They are in the vanguard of scientists who have embraced the idea of big data and the value of employing modern methods in statistics and machine learning to analyze large data sets. The microprocessor example is more complicated.
As a sophomore in electrical engineering having studied semiconductor theory and digital circuits, when I first looked at the Intel 8008 processor, I could readily parse the underlying transistor-to-transistor circuitry and identify familiar components. I knew how to design amplifiers, oscillators, square-wave generators and the like, and, while I didn't figure out for myself how to wire two transistors to create a bi-stable (digital) device that could store one bit of information, once I understood the principle, it opened up a window into how digital computers worked. Looking back, this epiphany was similar to — but not nearly as revolutionary as — reading Hubel and Wiesel [226, 225] two decades later and learning how you could wire up neurons to implement an edge detector in the striate cortex.
An article in The Atlantic managed to separate the substance from the hyperbole in the PLoS journal paper. The Atlantic article opens with
So, Eric Jonas and Konrad Kording wondered, what would happen if they studied the chip in the style of neuroscientists? How would the approaches that are being used to study the complex squishy brain fare when used on a far simpler artificial processor? Could they re-discover everything we know about its transistors and logic gates, about how they process information and run simple video games?
Here the subtlety was hidden once again, this time in the phrase "in the style of neuroscientists", but the text of The Atlantic article did a somewhat better job of making this clearer in the remainder of the article.
As a student studying electrical engineering, I soon developed an eye for different circuit motifs. Shift registers, multiplexers and demultiplexers, reverse engineering half adders to understand how they handle the carry bit and then chaining them together to implement full adders, and a host of other circuit motifs that I could soon recognize in both schematic wiring diagrams and — with somewhat more difficulty — electron micrographs of integrated circuits. Being able to recognize such patterns made it relatively easy to analyze the growing families of specialized microprocessors being produced by AMD and Intel.
Of course in those days the number of transistors in a processor chip was relatively small. Intel was smart to provide chips to EE students for free or a very small fraction of their retail cost. In addition to the 8008, I experimented with the MOS Technology 6502, Motorola 6800 and Intel 8080, none which had more than 5K transistors and many fewer in the interesting subcircuits like the ALU. If I wanted to perform a similar analysis on a modern multi-core or system-on-chip device such as an Intel Xeon or Apple ARM64 with more than 2B transistors, I would probably apply something like the approach described in [98] to identify the underlying circuit motifs at multiple scales.
If I was looking for any deep understanding of cognition in analyzing a multicore chip or data center running a version of DeepMind's AlphaGo software, I certainly wouldn't find it. I might find evidence indicating massive amounts of floating or fixed point calculations and possibly even determine the parts of the circuit performing certain linear algebra operations, but I would be hard-pressed to infer anything deeper without being able to somehow extract meaning from the bits in RAM encoding the AlphaGo architecture and the rest of the AlphaGo code. In contrast, cognitive neuroscientists have been able to isolate interesting cognitive capabilities such as action selection by having subjects perform tasks that require symbolic reasoning.
I would claim that we could in principle perform an even deeper analysis if we could record from every neuron in the brain and simultaneously record and align a complete account of the physical environment that the brain is experiencing. In this case, I concede I would need not only a great deal more data than has ever been recorded previously, but also a great deal more computational power than we have now or may have for several years to come. That said I believe that we are on the cusp of being able to perform similar analyses on significantly simpler organisms such as Drosophila and juvenile zebrafish within a couple of years, and in so doing will be able to directly align neural computations with behavior in large part because the brains of flies, fish, monkeys and human beings are designed to be functionally modular in large part due to the way natural selection scaled the underlying neural architecture to address increasingly challenging environmental conditions.
May 27, 2018
%%% Sun May 27 4:22:36 PDT 2018
In the May 17 entry in the class discussion log, we briefly touched on the fact that most normal human discourse — and very likely the sort of discourse that goes on between software engineers engaging in pair programming — involves a rich interleaving of topics, even when the engineers are primarily focusing on the problem at hand.
Part of the discussion will likely focus on what's the best strategy to make progress on the problem at hand. In some cases, discussion will start out with a specification describing the target program in natural language, pseudocode, or, in the case of the programmer's apprentice, a constant stream of suggestions from the programmer primarily consisting of strategies for organizing your thoughts and heuristics for getting started.
For example, how to think about generating a pattern to use as a starting point, search for a suitable code fragment that has some of what you expect you will need in the target program, or proceed from the simplest starting point, e.g., "if __name__== "__main__: ... main() ..." are all common starting strategies. Things get more complicated if you get wedged and the current version of the code seems to be leading nowhere.
In terms of parsing this continuous stream of suggestions, advice and specific interventions into useful parcels — essentially separate policies that can be deployed in a wide range of cases, we might use something like the Rabinowitz et al [361] machine theory-of-mind model Figure 41 to represent different sources of expert advice as separate characters in the character network and the prediction network to separate the different sources from one another.
As for reconstructing the AST from the embedding, you could use an encoder-decoder approach to machine translation where you are primarily interested in using the decoder to generate a translation, or in this case the transformed program. You might consider a scheme along the lines of See et al [384] in which you combine two or more distributions such that one distribution is a normalized binary vector in which the non zero entries correspond to syntactically correct abstract syntax trees.
On the other hand you might consider as I mentioned in the previous message operating directly on the AST representation as part of the "game engine" but using the embedding of the current AST as the system state, i.e., the input to the policy for determining the best action / repair. Does that make sense? You might want to use a DNC for other purposes but as I discovered when I thought about it more carefully, pointer-networks and related DNC variants don't seem up to the task.
To clarify, by "game engine" I am referring to an integrated development environment (IDE) instrumented so that it (a) maintains a Python-code version of the current AST, (b) accepts input in the form of syntactically well-formed edits to the AST, and (c) provides as output error messages and diagnostics when the Python-code version is run on input from a specified I/O pair as part of the specification and the program output is compared with the corresponding specified I/O pair output.
One of the most challenging problems will be generating a suitable distal reward signal [261, 235] that provides intermediate stage guidance — not just when you have a running program that doesn't crash when you feed it samples from your target input / output specification. Here again you could incorporate this signal into the "game engine" output in the form of execution traces and precise identification of the locus of failure in the AST representation.
This approach might serve as a more flexible foundation on which to build machinery for constructing policies perhaps using something like the I2A / IBP architectures [339, 472] that Oriol talked about. Think of the "game engine" as a powerful digital prostheses that does all the symbolic / combinatorial processing freeing up the NN architecture to do all the contextual work that such architectures excel at — see O'Reilly's slides and talk for detail on the difference between connectionist and symbolic reasoning approaches to AI.
May 26, 2018
%%% Sat May 26 4:51:26 PDT 2018
In terms of executive function28, Randal O'Reilly's biologically-inspired cognitive architecture is the most compelling framework I know of for the applications I have in mind, namely developing artificial neural networks that leverage what we've learned about the brain to implement technologies that support a particular sort of human computer-interaction in service to collaboratively solving challenging design problems. O'Reilly's LEABRA is the closest we have to mesoscale model of the system consisting of hippocampus, prefrontal cortex and basal ganglia [330, 332]. The sequence of discussion log entries — Part 1, Part 2, Part 3 and Part 4 — summarize the basic biological subsystems and cite the best references I know of offering additional relevant background. Note that these entries do not provide any detail about how you might translate these components into a fully differentiable model. To my mind, resolving this issue will be the most interesting challenge in completing your final projects.
Here is the simple, stripped-to-its-most-basic-elements task that I outlined in this sequence of entries: (a) the assistant performs a sequence of steps that effect a repair on a code fragment, (b) this experience is recorded in a sequence of tuples of the form (st,at,rt,st+1) and consolidated in episodic memory, (c) at a subsequent time, days or weeks later, the assistant recognizes a similar situation and realizes an opportunity to exercise what was learned in the earlier episode, and (d) a suitably adapted repair is applied in the present circumstances and incorporated into a more general policy so that it can be applied in wider range circumstances.
If you're interested in the natural language interface for the programmer's apprentice you might want to add steps prior to (a) in which the programmer guides the assistant in performing the necessary sequence of steps leading to the repair and so the repair-related steps are interleaved with tuples that correspond to interlocutionary acts that have to be sorted out and assimilated so that repair steps can be isolated and their provenance in terms of the programmer's role as the source of this wisdom is suitably stored in memory for subsequent use in distinguishing the programmer's presumably reputable input from that of other, possibly less reliable, sources
One thing to point out in considering the papers we've read on reinforcement learning and episodic memory is that almost any activity — especially activity when engaged in a collaborative effort or immersed in a natural environment full of interruptions and distractions, is going to consist of very little of direct consequence to what we would claim to be working on were someone to pointedly ask. Even when you consider the case of peer-to-peer pair programming or intense teacher-to-student / expert-to-apprentice instruction, the dialogue will consist of much more than a stream specific instructions. In addition to small talk, the dialogue will include a great deal of impedance matching, ambiguity resolution and tedious back-and-forth in service to recognizing and mitigating the inevitable misunderstandings.
In the case of the programmer's apprentice, there will be program specifications in natural, largely non-technical language, high-level advice about how to think about programming problems and low-level suggestions about how to implement specific algorithms or recover from errors inadvertently introduced in the code. In describing how to repair a program or alter a fragment borrowed from a code repository, instead of "move the cursor to just before the variable and search backwards for the most recent prior instance of the variable appearing as a formal parameter in a function declaration or introduced as a local variable", the expert programmer is more likely to say something "determine where the variable was initialized". The point being that the activity trace for such an agent is going to require a good deal of effort to extract useful information in the form of improved dialogue management, general strategies for program synthesis and detailed interventions for finding and repairing bugs.
%%% Sat May 26 16:12:52 PDT 2018
Note that while dialog is not strictly hierarchical in the sense that the order in which topics are addressed reliably moves up and down some predefined hierarchy of abstractions, it is certainly recursive, often discursive and full of bewildering non sequiturs and hard-to-follow digressions. Automatically identifying topic boundaries in a document is notoriously hard. Programs with procedures are almost as bad as those with GOTO statements and we've all had the experience of participating in discussions or listening to arguments and lengthy soliloquies stuck in seemingly infinite regress. The point here — partly contradicting the earlier point — is that most of our activity trace is not amenable to careful analysis and reconstruction because there was little structure there to begin with. Assuming this is true, what should we expect of memory consolidation and when, if ever, can we expect more than a hint about how to solve specific technical challenges. This observation supports speculation that planning is an exercise in creatively re-imagining our past while opportunistically assembling our future.
The last two paragraphs are not cause for despair. Quite the contrary, they suggest we have evolved a successful strategy that takes full advantage of our highly-parallel, context-sensitive, ambiguity- and fault-tolerant computing technologies. Combined with the benefits of fully differentiable models trained by backpropagating errors or Hebbian learning it appears we can bootstrap our way to exploiting the systematic, combinatorial benefits of largely-serial symbolic systems, including exact Bayesian models [336]. At least that is the underlying conceit behind the programmer's apprentice exercise: we design artificial systems based on neural-networks modeled after human cognitive architectures that enable these artificial systems to collaborate with and learn from humans; we develop digital prostheses that extend the capabilities of both humans and artificial systems; these technologies provide a bridge to attaining more powerful AI systems while offering humans the opportunity to evolve along with the products of their own creation.
Miscellaneous Loose Ends: I believe that the basic concept of meta-reinforcement learning is one of the most important ideas we heard about in our class discussions. Specifically, Matt Botvinick's presentation and related papers including Wang et al [465], Greg Wayne's presentation on MERLIN [471], and Oriol Vinyals presentation on imagination-based planning and related papers including Pascanu et al [339]. I suggest that, if you're working on anything related to sequential decision making and you're not already contemplating using the idea in your project, you may want to reconsider.
May 25, 2018
%%% Fri May 25 5:44:05 PDT 2018
I want you to get as much out as this class as you possibly can and I think that part of the experience should include the opportunity to take what you've learned and apply it to something really ambitious. Taking advantage of such an opportunity would also enable you to consolidate what you've learned and very possibly come up with something completely new. Which is not to say you can't come up with something new and extraordinary pursuing a more narrowly focused project.
To that end, I'm offering the choice of either proceeding with the project you proposed or modifying the assignment to focus on the design of a more comprehensive architecture without having to implement and evaluate that design, but there's a catch. If you want to take me up on this offer, then (a) you may have to change your original focus to be somewhat more ambitious, and (b) you will have to motivate the project in terms of the programmers apprentice application.
Here’s what I would expect of such a project:
Provide a description of a system that encompasses some reasonably ambitious subset of capabilities of a programmer’s apprentice. By focusing on the programmer’s apprentice, it will be simpler to motivate and your description can be more succinct because we share a great deal of context. For example, if you want to focus on the problem of having the apprentice interact with the programmer to generate code from spoken language, then it will be clear to me that the programmer is responsible for most of the logic and the apprentice is responsible for the syntax and just enough semantics to faithfully reproduce the functionality that the programmer is trying to articulate.
Provide a complete network architecture along with all of the equations that describe the various components. As an example, take a look at Oriol’s pointer-network paper [454] or the methods section in the supplements at the end of Wayne et al [471]. A block diagram showing all the different layers is a necessary but not sufficient condition for describing the architecture. The equations tell me what the blocks actually mean. A deep recurrent neural network is no more than a differential equation and so follow the conventions you’ve seen in the papers discussed in class, and describe the differential equation for your proposed network by describing the individual functions computed by each block including the objective function29.
What you don't have to do in this case is write, debug and test the code. If you make a syntactic error in one of your equations, I'll likely recognize it's just a typo, and you won't have to spend hours or days tearing out your hair tracking down bugs. As a team, you will probably spend most of your time working at a white board, just as you would if you were working at DeepMind, Google Brain, OpenAI, Vicarious, or other companies working on an ambitious AI project. You can divide up the effort into designing basic modules, writing down equations, illustrating the network architecture, explaining each module and how it contributes to overall system, training, discussing strengths and shortcomings, etc.
Think of the original call for project proposals as fishing for something along the lines of the Rabinowitz [361] Machine Theory of Mind Model — a simple elegant model and proof-of-concept implementation sans impressive performance or compelling demonstration. The opportunity offered here is more along the lines of a white paper or technical talk you'd give to your peers soliciting feedback on a work in progress with enough detail to invite serious technical discussion. This neural modeling paper [98] is the nth iteration of such a paper that started from a five-page precis with a few equations and grew into a 37 page project proposal with a dozen figures.
This may not be as fun as you imagine and so don't think of it as a way out of writing code. I included links to interviews with the mathematicians Terrence Tau, Cèdric Villanni and Andrew Wiles talking about their experience solving open problems for a reason, namely because working on such problems can be frustrating and demoralizing — maybe there is no solution, maybe you're wasting your time. It can be rewarding if you win a Fields Medal or the Abel Prize, but plenty of talented mathematicians never achieve such approbation from their peers. You have to expect setbacks, dead ends and failure. That said, this might be a good time in your career to give it a try.
May 21, 2018
%%% Mon May 21 05:52:18 PDT 2018
Continuing from the previous log entry, the programmer's apprentice (PA) operates on programs represented as trees, where the set of actions includes basic operations for traversing and editing trees — or more generally directed-graphs with cycles if you assume edges in abstract syntax trees corresponding to loops, recursion and nested procedure calls, i.e., features common to nearly all the programs we actually care about. We still have a finite number of actions since for any given project we can represent the code base as a directed-acylic graph with annotations to accommodate procedure calls and recursion, and use attention to direct and contextualize a finite set of edit operations30.
Pritzel et al [357] employ a semi-tabular representation of an agent's experience of the environment possessing features of episodic memory including long-term memory, sequentiality and context-based lookups. The representation called a differential neural dictionary (DND) is related to Graves et al [169] DNC. The programmer's apprentice is better suited to Vinyals et al [454] related idea of a pointer-network designed to learn the conditional probability of an output sequence with elements that are discrete tokens corresponding to positions in an input sequence — see related work in natural language processing by Merity et al [308] on pointer sentinels.
| |
| Figure 49: Pointer-generator model. For each decoder timestep a generation probability Pgen ∈ [0, 1] is calculated, which weights the probability of generating words from the vocabulary, versus copying words from the source text. The vocabulary distribution and the attention distribution are weighted and summed to obtain the final distribution, from which we make our prediction. Note that out-of-vocabulary article words such as 2-0 are included in the final distribution. — adapted from [384]. | |
|
|

One approach involves representing a program as an abstract syntax tree and performing a series of repairs that involve replacing complete subtrees in the AST. It might be feasible to use some variant of the pointer-network concept, e.g., [40], [384] and [464] or neural programmer framework [322], but there are limitations with all of the alternatives I've run across so far, requiring additional innovation to deal with the dynamic character of editing AST representations, but at least the parsing problem is solved for us — all we have to do is make sure that our edits maintain syntactic well-formedness.
Most of the existing pointer-network applications analyze / operate on a fixed structure such as a road map, e.g., examples include the planar graphs that Oriol Vinyals addresses in his paper [454], recognizing long-range dependencies in code repositories [40], and annotating text to support summarization [384]. Student projects focusing on program-repair might try ingesting programs using an LSTM, creating a pointer-network / DNC-like representation of the AST and then altering selected programs by using fragments from other programs, but be advised this approach will likely require inventing extensions to existing pointer-network techniques.
One possibility for training data is to use the ETH / SRI Python dataset that was developed by Veselin Raychev as part of his thesis on automated code synthesis31. Possible projects include designing a rewrite system for code synthesis based on NLP work from Chris Manning's lab led by Abigail See [384] focusing on text summarization leveraging pointer networks — see Figure 49 for an excellent schematic overview of their method. Further afield are program synthesis papers that work starting from specifications like Shin et al [392] out of Dawn Song's lab or recent work from Rishabh Singh and his colleagues [467].
Another possibility is to use RL to learn repair rules that operate directly on the AST using various strategies. It's not necessary in this case to represent the AST as a pointer network, but, rather, take the expedient of simply creating a new embedding edited AST after each repair. We can generate synthetic data by taking correct programs from the ETH/SRI dataset and introducing bugs and then use these to generate a reward signal, with harder problems requiring two or three separate repairs.
It might also be worth exploring the idea of working with program embedding vectors in a manner similar to performing arithmetic operations on word vectors in order to recover analogies — see the analysis of Levy and Goldberg [276] in which they demonstrate that analogy recovery is not restricted to simple neural word embeddings. For example, given the AST for a program P with subtree Q and two possible repairs that correspond to replacing Q with either R or R', can we determine which is the better outcome A = P - Q + R or A' = P - Q + R' and might it serve as a distal reward signal to expedite training?
%%% Wed May 23 9:24:25 PDT 2018
I also recommend Reed and de Freitas [362] for its application of the idea of using dynamically programmable networks in which the activations of one network become the weights (program) of another network. The authors note that this approach was mentioned in Sigma-Pi units section of Rumelhart et al [371], appeared in Sutskever and Hinton [422] in the context of learning higher order symbolic relations and in Donnarumma et al [124] as the key ingredient of an architecture for prefrontal cognitive control.
May 19, 2018
%%% Sat May 19 03:45:38 PDT 2018
My objective this morning is to finish working on Figure 48 describing a possible integrated architecture and then try to explain the architecture in the simplest way possible. By that I mean explaining the function of each component without going into detail about its implementation. Yesterday evening I made an inventory of functions associated with the proposed architecture along with tools that might be used to implement them, e.g., active maintenance of circuits in the global workspace (WS) → fast weights / dynamic linking [380, 18] and dynamic gating of bistable activity in the prefrontal cortex (PFC) → gated recurrent networks [12, 70]. Most functions can probably be implemented using variations on standard models or by leveraging ideas from cognitive neuroscience that we have been exploring in class. In any case, a full accounting will have to wait.
| |
| Figure 48: The triptych on the bottom concatenates the graphics from three papers by Randal O'Reilly and his colleagues. They are reproduced here along with their original captions for your convenience in understanding the graphic in the top panel labeled (a) that is explained in detail in the main text. Panel (a) follows the shape and color conventions employed in Panel (c) except the yellow square shapes that denote abstract structures and not anatomical features. The acronyms are expanded and explained here. Figure 2 in O'Reilly [330] shown in Panel (b) — Dynamic gating produced by disinhibitory circuits through the basal ganglia and frontal cortex/PFC (one of multiple parallel circuits shown). In the base state (no striatum activity) and when NoGo (indirect pathway) striatum neurons are firing more than Go, the SNr (substantia nigra pars reticulata) is tonically active and inhibits excitatory loops through the basal ganglia and PFC through the thalamus. This corresponds to the gate being closed, and PFC continues to robustly maintain ongoing activity (which does not match the activity pattern in the posterior cortex, as indicated). When direct pathway Go neurons in striatum fire, they inhibit the SNr and thus disinhibit the excitatory loops through the thalamus and the frontal cortex, producing a gating-like modulation that triggers the update of working memory representations in prefrontal cortex. This corresponds to the gate being open. Figure 7 in O'Reilly et al [332] shown in Panel (c) — The macrostructure of the Leabra architecture, with specialized brain areas interacting to produce overall cognitive function. Figure 8 in O'Reilly et al [332] shown in Panel (d) — Structure of the hippocampal memory system and associated medial temporal lobe cortical structures including entorhinal cortex. | |
|
|
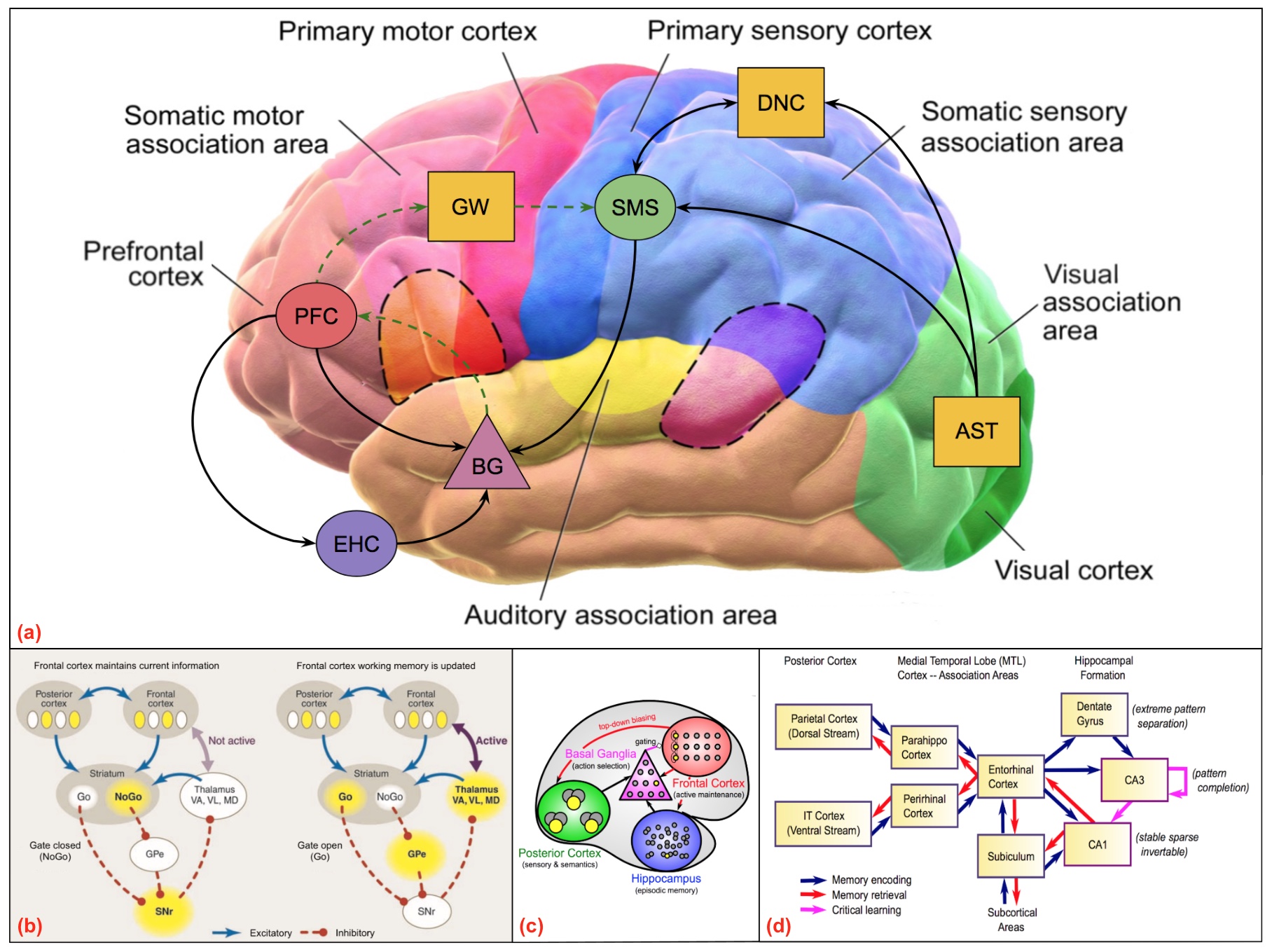
Figure 48 shows a diagram of the human brain overlaid with a simplified architectural drawing. The box shapes represent abstract systems and the oval and triangular shapes represent anatomical features for which we can supply computational models. For example, the box labeled GW represents the global workspace which performs particular function in the architecture, but actually spans a good portion of the neocortex. Whereas the triangle labeled BG represents a group of subcortical nuclei called the basal ganglia situated at the base of the forebrain.
The box labeled AST represents a form of sensory input corresponding to the ingestion of abstract syntax trees representing code fragments. The oval labeled SMS represents semantic memory and the box labeled DNC corresponds to a differentiable neural computer. When the system ingests a new program fragment the resulting AST is encoded in the SMS as an embedding vector and simultaneously as a set of key-value pairs in the DNC. Here we think of the DNC as a body part or external prosthesis with corresponding maps in the somatosensory and motor cortex that enable reading and writing respectively.
Our explanation of the architecture proceeds top down, as it were, with a discussion of executive function in the prefrontal cortex. The GWS provides two-way connection between structures in the prefrontal cortex and homologous structures of a roughly semantic character throughout the rest of neocortex thereby enabling the PFC to listen in on diverse circuits in the neocortex and select a subset of such circuits for attention. Stanislas Dehaene describes this process as the function of consciousness, but we need not commit ourselves to such interpretation here.
Not only does the PFC selectively activate circuits but it can also maintain the activity such circuits indefinitely as constituents of working memory. Since this capability is limited by the capacity of the PFC, the content of working memory is limited and adding new constituents may curtail the activation of existing constituents. In practice, we intend to model this capability using meta-reinforcement learning [466] (MRL) in which the MRL system relies on the GWS network to sample, evaluate and select constitute circuits guided by a suitable prior [38] and past experience and then maintain their activity by a combination of memory networks [474] and fast weights [18].
Meta-reinforcement learning serves a second complementary role in the PFC related to executive function. We will refer to the first role as MRL-A for "attention" and the second as MRL-P for "planning". MRL-A is trained to focus attention on relevant new sensory input and new interpretations of and associations among prior perceptions and thoughts. MRL-P is trained to capitalize on and respond to opportunities made available by new and existing constituents in working memory. Essentially MRL-P is responsible for the scheduling and deployment of plans relevant to recognized opportunities to act. These plans are realized as policies trained by reinforcement learning from traces of past experience or constructed on the fly in response to unexpected / unfamiliar contingencies by recovering and reimagining past activities recovered from episodic memory.
MRL-A and MRL-P could be implemented as a single policy, but it is simpler to think of them as two coupled systems, one responsible for focusing attention by constantly assessing changes in (neural) activity throughout the global workspace, and a second responsible for overseeing the execution of plans in responding to new opportunities to solve problems. MRL-A is as a relatively straightforward reinforcement learning system independently performing its task largely a function of whatever neural activity is going on in the GW, its attentional network and the prior baked into its reward function. MRL-P could be implemented along the lines of the Imagination-Augmented Agent (I2A) architecture [472] or the related Imagination-Based Optimization [195] and Imagination-Based Planning [339] systems.
%%% Mon May 21 04:31:07 PDT 2018
The remaining parts of the architecture involve the interplay between the PFC and the semantic and episodic memory systems as facilitated by the basal ganglia and hippocampus. If we had a policy pre-trained for every possible contingency, we would be nearly done — let MRL-A draw attention to relevant internal and external activity and then design a simple just-in-time greedy scheduler that picks the policy with the highest reward given the state vector corresponding to the current content of working memory. Unfortunately, the life of an apprentice programmer is not nearly so simple.
The apprentice might listen to advice from a human programmer or watch someone solve a novel coding problem or repair a buggy program. Alternatively, it may be relatively simple to adapt an existing policy to work in the present circumstances. However, making progress on harder problems will depend on expert feedback or having an existing reward function that generalizes to the problem at hand. In the remainder of this entry, we set aside these problems for another day and concentrate on the basic functionality provided by the basal ganglia as highlighted in Panel (c) — of Figure 48.
The basal ganglia in cognitive models such as the one described by Randall O'Reilly's in his presentation in class, play a central role in action selection. This seems like a good opportunity to review how actions are represented in deep-neural-network implementations of reinforcement learning. Returning to our default representation for the simplest sort of episodic memory, (st,at,rt,st+1), it’s easy to think of a state s as a vector s ∈ ℝn and a reward r as a scalar value, r ∈ ℝ, but how are actions represented?
Most approaches to deep reinforcement learning employ a tablular model of the policy implying a finite — and generally rather small — repertoire of actions. For example, most of the experiments described in Wayne et al [471] (MERLIN) six-dimensional one-hot binary vector that maps a set of six actions: move forward, move backward, rotate left with rotation rate of 30, rotate right with rotation rate of 30, move forward and turn left, move forward and turn right. The action space for the grid-world problems described in Rabinowitz et al [361] (ToMnets) consists of four movement actions: up, down, left, right and stay.
The remainder of this discussion will have to wait until I have a little more time. It will be posted here.
May 17, 2018
%%% Thu May 17 05:41:08 PDT 2018
Referring to the abstractions and abbreviations introduced in the previous entry, reading a program from STDIO — the analog of a human programmer reading a program displayed on a monitor — will result in — at least — two different internal representations of the resulting AST: an embedding vector in the SMS and a key-value representation in the DNC. The former allows us manipulate programs and program fragments as fully-differentiable representations within distributed models. The latter allows us to modify, execute and share code in a human-accessible format, fully compatible with our software-development toolchain.
Following [358], we assume EMS consists of initial-state-action-reward-next-state tuples of the form (st,at,rt,st+1). State representations st have to be detailed enough to reconstruct the context in which the action is performed and yet concise enough to be practical. Suppose the PFC directs the activation of selected circuits in the SMS via the GWS in accord with Dehaene et al [108, 104] assuming a prior that generates low-dimensional thought vectors [38]. st encodes the attentional state that served to identify representations in SMS relevant to at allowing the EHC to produce the resulting state st+1. Given st we can reproduce the activity recorded in the EMS, and, in principle, incorporate multiple steps and contingencies in a policy constituting a specialized program-synthesis or program-repair subroutine.
Such subroutines would include repairing a program in which a variable is introduced but not initialized, or when it is initialized but ambiguously typed or scoped. As another example, a variable is initialized as VOID and subsequently assigned an integer value in some but not all branches of a conditional statement. Other examples of repair routines include problems with the use of comparison operators, e.g., conditional branches both with ≤, the is operator is used instead of is not, or vice versa, confusion involving A is not None, A not None and A != None, and problems involving class methods, e.g., when self accessor is missing from a variable, e.g., mode = 'manual' instead of self.mode = 'manual' [392, 119, 467].
Attentional machinery in the prefrontal cortex (PFC) populates the global workspace (GWS) by activating circuits relevant to the current input and internal state, including that of the DNC and any ongoing activity in (SMS) circuits produced by previous top-down attention and bottom-up sensory processing. The PFC in its role as executive arbiter identifies operators in the form of policy subroutines and then enlists the EHC to — using terminology adapted from Von Neumann machines — to load registers in short-term memory and perform operations by using fast weights to transform the contents of the loaded registers into product representations that can either be fed to associative embeddings, temporarily stored in other registers or used to modify the contents of the DNC thereby altering the AST representation of the target code and updating the display to provide feedback to the human programmer.
What's left out of this account so far includes how we might take advantage of semantics in the form of executing code and examining traces in order to better understand the consequences of the changes just made. Presumably, wrapping a code fragment in a function and executing the function with different input to examine changes in the state variables could be used as a distal reinforcement signal providing intermediate rewards useful in debugging subroutines. As pointed out earlier, subroutines designed to modify code are likely to involve many conditional choices and so it is important for subroutine policies to be highly conditioned on the status of specific state variables. Indeed a technique such as model-based parameter adaptation may be perfectly suited to providing such context-sensitive adaptations.
Perhaps this next thought seems obvious, but it is worth keeping in mind that the human brain does a great deal of (parallel) processing that never rises to the level of conscious attention. The executive control systems in the prefrontal cortex don't have micromanage everything. Every thought corresponds to a pattern of activity in one or more neural circuits in the brain or beyond in the peripheral nervous system. One pattern of activity inevitably leads to another in the same or another set of neurons. For example, patterns of activity that begin in the sensory cortex can lead to patterns of activity in the motor cortex and can have consequences elsewhere in the brain, e.g., in the cerebellar cortex resulting in speech, or external to the central nervous system as in the case of neurons that propagate through the peripheral nervous system causing muscles to contract and extend thereby making your limbs and torso move.
Every new observation, every act of creating a new thought or revisiting an old one produces even more activity in the brain resulting in new thoughts some of which are ignored as their reverberations weaken and die and others that spawn new thoughts and proliferate under the influence of reentrant production of activity and the active encouragement of conscious attention in a perpetually self reinforcing, reimagining and self-analyzing cycle of recurrent activity. Meta-reinforcement learning supports the sort of diverse activity one might expect from a system that selects activity to attend to and then makes available in the global workspace for ready access by other systems. Sustaining a collection of such activated circuits would help to provide a context, serve to maintain a stack of policies, guide switching between them, support caching partial results for later use, reconstructing necessary state as needed when restoring policy after a recursive descent.
When you think of building systems that can develop new algorithms it is instructive the think about the simple case of learning to sort lists from input-output pairs. I would guess that bubble sort would be the easiest to come up with, but even then it is easier if you start with simple I/O pairs like [A,B] → [A,B], [B,A] → [A,B] and work up to longer lists. As Dan Abolafia pointed out in his class presentation, it is relative easy to learn to sort lists of length no more than n, but substantially more difficult to learn an algorithm that works for lists of arbitrary length, without the ability to construct a simple inductive proof of correctness. Logic and basic theorem proving are certainly important in learning to write programs. You might want to look at the Coq proof assistant32 for a glimpse at the future of algorithm development.
%%% Fri May 18 03:56:03 PDT 2018
Miscellaneous Loose Ends: I often include mention of scientists and mathematicians in this discussion log because they are daily faced with the same sort of problems as are the invited scientists and engineers who've participated in class, and, by extension, all of you are who are taking on the challenge of creating working models of human and super-human cognition. You might enjoy exploring the work of Terrence Tao who received a Fields Medal for his work on partial differential equations, combinatorics and number theory33.
May 15, 2018
%%% Tue May 15 07:59:40 PDT 2018
Rushed as usual, but had some thoughts about what an integrated architecture might look like that I wanted to write down and share. I'm not alone in thinking that one thing missing from the ideas that we've been hearing about has to do with the hierarchical structure of language, planning, and, more generally, thought. A couple of teams seem to be thinking along these lines and I've suggested some formal models as possible approaches to generating data with such hierarchical, recursive structure. Hierarchical hidden Markov models (HHMM) were introduced by Fine, Singer and Tishby [140] to account for a wide range of natural processes and I employed them34 in developing models of the neocortex in 2005 [94, 96, 95].
While at Numenta in 2006, I experimented with methods for segmenting sequences generated by mixtures of switching variable memory Markov sources [386, 13, 385]. The general problem of learning such models is computational intractable, and the learning methods of the day generally fell short when applied to problems of interest. In the following exercise, rather than immediately focus on learning such models, we start by considering the simpler problem of how we might represent subroutines that implement simple program transformations in a neural-network architecture.
We begin with the simplifying assumption that subroutines can be represented as tuples consisting of a set of operands represented as high-dimensional embedding vectors, a weight matrix representing the transformation and a product vector space in which to embed the result. In applying this idea to program transformations, assume that each operand corresponds to the embedding of an abstract-syntax-tree representation of a code fragment, w.l.o.g., any non-terminal node in the AST of a syntactically well-formed program. In the remainder of this entry and the next, we use the following abstractions and abbreviations:
prefrontal cortex (PFC) including attention, conscious access, reward-based-learning and executive control [466, 258];
entorhinal-hippocampal complex (EHC) in its role as primary interface between the hippocampus and neocortex [335, 330];
global workspace (GW) broadly distributed cortical circuits connected through long-range excitatory axons35; [107];
basal ganglia (BG) for its role in action selection and dynamic gating input to the prefrontal cortex[332, 258];
semantic memory system (SMS) including areas of the brain responsible for mathematical and abstract thought [441, 43];
episodic memory system (EMS) including episodic memory management and memory-based parameter adaptation [413, 358];
differentiable neural computer (DNC) as the interface to the integrated development environment prostheses [169, 168];
abstract syntax-tree (AST) is a representation of the abstract syntactic structure of a source-code program36 [119, 467];
Miscellaneous Loose Ends: Yousef Hindy, Maurice Chiang, Peter Lu, Sophia Sanchez and Michael Smith found a Python code-syntheis dataset from SRI / ETH and a differential neural computer implementation from DeepMind for possible use in their final project. Andrew Wiles gave an interesting public lecture at Oxford on November 11, 201737. Cèdric Villani describes his trials38 in completing the proof of Landou damping with Clèment Mouhot [317] and an interesting parallel in the career of his mathematical hero Henri Poincarè.
May 12, 2018
%%% Sat May 12 04:15:17 PDT 2018
It doesn't matter if you're designing a bridge, making a cake, building a house, writing a novel, proving a theorem, painting a landscape, or developing software, all of these tasks require planning and imagination. Most likely your plans will have hierarchical structure and the processes you imagine will be partially observable and non stationary, for all intents and purposes. Moreover, you will employ the same parts of your brain for all of these tasks.
Last week we covered three papers leveraging reinforcement learning for planning, Learning model-based planning from scratch Pascanu et al [339] also Battaglia et al [35], Imagination-augmented agents for deep reinforcement learning Weber et al [472], and Learning to search with Monte Carlo tree search neural networks [MCTSnets] Guez et al [189].
The hierarchical nature of planning is addressed in another paper, Value Iteration Networks Tamar et al [429], and researchers from DeepMind recently published a paper in Nature describing a computational model of how grid cells in the entorhinal cortex are employed for spatial reasoning and planning including board games like Go, Vector-based navigation using grid-like representations in artificial agents Banino et al [27].
Oriol Vinyals discussed the first three papers in his presentation last week, focusing first on the Imagination-augmented agent (I2A) model shown in Figure 47, and then, building on that basic framework, described the class of imagination-based planner (IBP) models. Oriol also discussed the MCTSnet model extending I2A with Monte Carlo tree search (MCTS).
| |
| Figure 47: Figure 1: I2A architecture. The circumflex notation (.̂) is used to indicate imagined quantities. (a) the imagination core (IC) predicts the next time step conditioned on an action sampled from the rollout policy π̂. (b) the IC imagines trajectories of features f̂ = (ô, r̂), encoded by the rollout encoder. (c) in the full I2A, aggregated rollout encodings and input from a model-free path determine the output policy π — adapted from [472]. | |
|
|

I2A architectures constitute a class of models that augment a standard model-free reinforcement learning policy by using a predictive model to explore the consequences of taking different actions, thereby enabling a strategy that is robust against the imperfections of the predictive model allowing such models to meet or exceed their model-free counterparts.
Figure 47 illustrates the basic components of the I2A architecture, showing how imperfect enironmental models are used to generate trajectories from some initial state using actions sampled from a rollout policy π̂ and these trajectories are then combined and fed to an output policy π along with the action proposed by the model-free policy to make better decisions. Imperfect predictions results in a rollout policy with higher entropy, potentially striking a balance in addressing the exploration-exploitation tradeoff.
IBP [339] extends this further by introducing a manager policy πM that decides whether to imagine or act and a controller policy πC that produces an action depending on whether the decision made by the manager is to imagine or act [143, 195]. This is essentially a form of meta-reasoning in which the IBP agent schedules computations, that carry costs, in order to solve a task [373, 100, 220]. IBP, however, learns an adaptive planning policy in the more general and challenging class of sequential decision-making problems.
May 11, 2018
%%% Fri May 11 04:53:45 PDT 2018
In his Abel Prize interview, Andrew Wiles talks about his seven years while a Professor at Princeton University laboring on the problem in isolation. He briefly remarks on the irresponsibility of his obsession, the accolades that followed upon announcing his solution and the triumphant return to Cambridge to present his proof. Prompted by his interviewer, he recounts the subsequent period of angst and despair when the referees reviewing the work for publication found a mistake / omitted step in the proof, plunging Wiles into fourteen stressful months before culminating in a successful resolution. Similarly, Cédric Villani describes his obsession with the proofs of nonlinear Landau damping and convergence to equilibrium for the Boltzmann equation.
In Chapter 9 of his book, The Birth of a Theorem, Villani mentions trying not to think about finishing the proof before his opportunity to win a Field Prize evaporates — the Fields Medal is awarded to mathematicians under the age of 40. In Chapter 11, Villani talks about the six months he spent on sabbatical at the Institute for Advanced Study in Princeton, New Jersey. He recounts being surrounded by paintings and bronze busts of famous mathematicians and physicists, and thinking about how many of them suffered from depression and madness. He mentions his heroes, not all of whom were so lucky to have permanent appointments at the IAS, Paul Erdós, Grigori Perelman, Alexander Grothendieck, Kurt Gödel, John Nash, Bobby Fischer and, of course, Ludwig Boltzmann who, after years of defending his theories in acrimonious debates with powerful incumbents like Ernst Mach, resigned from his academic positions due to ill health and eventually committed suicide.
In this interview entitled "What does it feel like to do maths?", Wiles fields questions — both shallow and deep — about mathematical beauty, despair after years working on what seems at times an intractable problem, exaltation and relief upon realizing you have found the solution, whether proving theorems is an act of creativity or discovery, whether it is more like solving puzzles or playing chess or more like painting or writing music, etc. He recounts his early interest in mathematics, coming across a description of Fermat's Last Theorem, and how lucky he feels to have had the opportunity to pursue his childhood dream largely unfettered by other more mundane concerns.
%%% Fri May 11 12:15:54 PDT 2018
I try to read a chapter of The Birth of a Theorem during lunch every day. The non-italicized portions read like a detective novel written by a mathematician — there's plenty of mystery and emotional tension but very little hyperbole40. I'm reminded of how large the mathematical literature is and how sparse what is known. As a math major in college, I imagined that all the math books a mathematician would ever need would fit on a few shelves. In my final year, working on my senior dissertation I got the first inkling of how wrong I was. While on sabbatical at Stanford during the early 90's writing my book on automated planning and control, I spent hours in the mathematics library learning about non-linear dynamical systems theory, Lyapunov functions and related issues featured in Vallini's book.
It's been some time since I read Simon Singh's Fermat's Last Theorem which chronicles the history of the conjecture and the lives of the many mathematicians who tried to prove it. I enjoyed this YouTube video of Andrew Wiles being interviewed by two Swedish mathematicians upon his winning the Abel Prize in 2016. I studied number theory as an undergraduate and later learned a little about modular elliptic curves from David Mumford but I was unable to follow the technical details in the conversation of three mathematicians. Nonetheless I could appreciate Wiles' extraordinary efforts to complete the proof, including the heart-rending discovery of a problem with the proof and the subsequent successful attempt to resolve the problem and satisfy the mathematics community.
May 10, 2018
%%% Thu May 10 19:45:39 PDT 2018
Before Oriol's lecture this afternoon, I briefly mentioned some of the mathematicians, scientists and engineers who participate in the public debate concerning the future of AI technology and how AI is now considered a strategic focus of national importance for many countries. Here are some YouTube talks I've circulated over the last few weeks and recently added some updates on the role of the mathematician Cèdric Villani with respect to the French government's strategy on AI. One might think that mathematicians and politicians would make strange bedfellows, but there are actually a considerable number of notable examples including Joseph Fourier, Emile Borel, Gottfried Wilhelm Liebniz, Pierre-Simon Laplace, some would include Socrates, and, of course, Isaac Newton who was appointed first the Warden and then Master of the Royal Mint.
Cèdric Villani at the Royal Institution in November 2016 speaking on The Birth of a Theorem.
Cèdric Villani at the Royal Institution in November 2016 during Q & A on The Birth of a Theorem.
Cèdric Villani, now a member of the French Parliament and tasked by the Prime Minister with examining France's strategy on AI41, in January 2018 speaking at the Franco-British Artificial Intelligence Conference.
May 9, 2018
Danny Tarlow sent me a selection of program synthesis papers that he recommends as well as a couple of compendium sites that list interesting related papers. You can find the spreadsheet here and PDF here if you're interested in this topic. I'll include additional papers as I find them.
May 8, 2018
%%% Tue May 8 03:17:49 PDT 2018
The previous entry attempted to categorize the scope of different software engineering tasks, e.g., classes, libraries, etc., the abstractions software engineers employ to think about them, e.g., flow diagrams, class hierarchies, and the logical operations required to realize them, e.g., repair, factor, etc. In this entry, we consider how these tasks, abstractions and operations map to different memory systems in the human brain.
Specifically, we describe a memory hierarchy with the objective of developing abstractions to support software engineering in analogy to the memory hierarchy in computing including tape and disk drives, high density random access memory (RAM), read only memory (ROM) and various caching strategies for fast memory access. To facilitate brainstorming, we'll ignore existing categories — to the extent we can having been exposed to the related technologies, and focus on what we think we need, not what we currently have or know exists. In addition to conventional long- (LTM) and short-term memory (STM), we consider two extremal variants, very-long-term memory (VLTM) and its very-short-term analog (VSTM) and ask the question whether or not exist there neural correlates for these variants, and, irregardless, whether applications like the programmer's assistant actually require such memory systems.
The Shorter Term End of the Memory Spectrum
In terms of biological memory, VSTM is almost ephemeral. It consists of staccato bursts of spiking, rapid firing neurons. The fleeting status of local field potentials is analogous to the voltage fluctuations in the registers of a processor ALU, and the dedicated L1 and L2 and shared-core L3 and higher-level caches. Contrast with the relative stability of epigenetic markers involving DNA methylation and histone modification and the semi-permanent status of dendritic spines. On a somewhat longer timescale there is the status of less transient synaptic connections, and, on an even longer time scale, there are circuit complexes that are self-repairing in which the set of contributing neurons and their pattern of connections may change over a period of minutes, hours or even days, but the information encoded in the resulting distributed representations is relatively stable.
The hastily-written, throw-away scripts you write during exploratory data analysis are examples of VSTM. If your default workflow is anything like mine, you might create spread-sheet programs that clean and reformat data, Python notebooks with short scripts that perform spectral analysis and clustering along with lots of graphs showing 2-D and 3-D projections plus interactive visualizations such as those generated by nonlinear dimensionality reduction methods, including the now ubiquitous t-SNE (t-distributed stochastic neighbor embedding) technique [447].
The resulting spread sheets, charts and analyses are quickly generated and, for the most part, just as quickly discarded — in the scope of a few hours or at most a few days, but they are essential in organizing one's thinking and quickly exploring the possibilities in preparation for producing datasets and related computed products that have a much longer shelf life. You could reconstruct them if required, every time you perform such tasks you learn how do them better and faster, but you are always in a hurry and make little or no effort to painstakingly organize the code and analyses — they constitute an example of write once, execute once and discard software.
Consider the data comprising the information relating to our immediate focus of effort, e.g., looking at genomic data from a patient trial, the arrangement of pieces on a chessboard, or the collection of words in a document — in each case this information can be thought of as a sample of unknown potential value. We assembled the data so as to subject it to analysis and determine its value. Neurophysiologically this requires introducing new connections or re-purposing and re-weighting existing ones and is often carried out using special networks set aside for just this purpose, their weights and possibly even their pattern of connections available for encoding additional information about their provenance and the results of our subsequent analysis. Typically the functions so learned are ephemeral and unlikely to be retained for more than the relatively short period of time during which the analysis takes place.
Summary: At the shortest time scales, VSTM memory in the form of epigenetic markers, recurrent circuits and microglial surveillance supporting biological analogs of gradients and processor caches. Conventional STM systems relying on fast weights [18, 494] and gated-unit recurrent networks [70, 218] provide the neural analog of paper and pencil to enable parallel access to all of the pieces of a complicated problem or puzzle. Variations on dynamic external memory / differential neural computing [152, 83, 169, 168] offer tradeoffs that extend the biological repertoire.
The Longer Term End of the Memory Spectrum
MNIST corresponds to archival (VLTM) data — a standard against which new methods and algorithms are compared, the basis for regression tests, valuable enough to be copied in multiple locations, carefully curated, signed and its checksum computed, steps taken to taken to prevent and ameliorate the consequences of bit-rot, storage media degradation and issues related to legacy support code and hardware and operating systems necessary run such code42.
It's not at all clear that we have or even need a solution to VLTM evolutionarily speaking. Consider conventional neural network weights trained using stochastic gradient descent involving large amounts of data — one immediately thinks of low-level perceptual features of the sort encoded in primary visual and auditory cortex, with connections and weights initially established in the womb and during early development. However, while the environmental stimuli is relatively stable over a lifetime, the sensory apparatus is constantly undergoing change as you age and incur damage from physical insults. Consider for example the rat barrel cortex: the number of whiskers, their layout, routine and disease-induced cell death and neurogenesis in the neural substrate altogether demand constant adjustment of the underlying circuits.
Summary: DNA is the species-wide biological solution to VLTM memory. The closest to a biological solution for short-lived individuals is human episodic memory, however it fails for archival storage and so as a species we have invented technology for external memory ranging from clay tablets to archival tape systems to supplement our memory. LTM in the form of traditional longer-term memory for storing information over days, weeks and months is reasonably well managed and protected from degradation and distortion by human episodic memory relying on hippocampal complementary learning systems to mitigate the consequences of new memories altering similar or recent existing memories.
May 7, 2018
%%% Sun May 6 05:12:19 PDT 2018
During orientation at Google, Nooglers are treated to a deep dive into how Google infrastructure works to handle a query. The presentation is called Life of a Query and, while as you might expect, I can't tell you much about the architectural details, you probably know the broad outlines. Back in 2003, Luiz André Barroso, Jeffrey Dean and Urs Hölzle, all of whom are now Google Fellows, provided a snapshot [33], but Google architecture has evolved considerably.
However, the software engineers (SWEs) who design, build, maintain and extend that architecture have not evolved and there are vanishingly few who completely understand the entire hardware and software ecosystem. How is that possible? The answer is obvious to most computer scientists. We deal with complexity by developing abstractions that enable us to think about complicated engineered artifacts without having to keep in mind all of the details that comprise their components.
These abstractions include procedures, classes, modules, libraries and projects that describe systems of increasing total code complexity but roughly constant cognitive descriptive complexity. Programmers rely on abstractions to think about code, e.g., pseudo code, flow diagrams, class hierarchies, data structures and algorithms, and modern programming practice includes a rich vocabulary for talking about coding and debugging, e.g., transform, trace, repair, refactor, etc.
All of these abstractions evolved to accommodate our inherent cognitive limitations and, in particular, our capacity for encoding knowledge in memory so as to transform that knowledge to suit particular purposes. Our goal is to build a cognitive architecture modeled after what we know about the human brain, consisting of more-or-less off-the-shelf artificial neural network components, and augmented with neural prostheses corresponding to standard software engineering tools.
May 5, 2018
%%% Sat May 5 16:28:40 PDT 2018
Several of you have sent drafts of project proposals that involve analyzing text sequences: emails, URLs, etc. In general, I recommend you eliminate everything that isn't directly relevant to the core capability that you want to demonstrate. This will simplify almost every aspect of your project from controlling complexity in the design to explaining what you've accomplished in your final project report. Here is a somewhat discursive summary of what I sent out earlier.
Consider using integer series from this test preparation website, you might concatenate [27, 24, 21, 18], [3, 4, 6, 9, 13, 18], [2, 4, 12, 48] to form the ordered list [27, 24, 21, 18, 3, 4, 6, 9, ..., 12, 48] to simulate the series of events that comprise the agent's experience in a given day. Some of the component series are random and others manifest dependencies. The task might be to devise a neural-network architecture that learns to identify patterns and relationships at different scales, e.g., rules used to generate the individual series and patterns corresponding to the repeated appearance of specific series, e.g., a subsequence of the Fn = Fn−1 + Fn−2 (Fibonacci) series always appears after an instance of the constant series, e.g., [2, 2, 2, 2].
This still might not be simple enough. Detecting the most interesting patterns will require a certain level of numerical literacy that would be hard to achieve starting from a tabula rasa. You probably don't want your system to have to invent integer arithmetic — according to Stephen Hawking, god invented the integers and so apparently it is a non trivial accomplishment43. It would, however, make for a very interesting project involving neural programming, but otherwise I would ditch the numbers and take the following tack.
The patterns could be arbitrarily complicated and so you'll probably want to simplify the class of generators, e.g., generate sentences from a simplified grammar of your own design and a dictionary of made-up words and then concatenate sets of these sentences to form your training data — this gives you exquisite control in designing experiments to demonstrate the effectiveness of your system. In general, design your project so you can start simple and add complexity. That way designing and debugging are easier, you have maximal experimental control and there are no data collection issues to worry about.
There's one additional thing I'd like to see in your project proposal. Clearly state your metric for success. Even more useful for conveying what it is you want to accomplish, provide a few examples illustrating what success would look like. If you can't do this, you probably don't understand what you want achieve. If you can't do it succinctly, then you probably haven't explored the problem carefully enough to know whether or not you can accomplish it by the end of the quarter. Speaking of the end of the quarter, note that final projects — code in the form of a GitHub repository or a simple tar ball plus a short 5-10 page report describing the project — are due Wednesday, June 13 at noon.
May 1, 2018
%%% Tue May 1 19:33:13 PDT 2018
I was a little disappointed in the methodology and technology that Graham talked about yesterday. I really like Graham's work, especially [487] and his recent work on dialog [216] that he didn't talk about, but his dependence on labeled data imposes restrictions on what he can accomplish, and no matter how clever he is at crowd-sourcing data collection and annotation, I don't think the approach will scale. I understand that within the computational linguistics community the use of supervised learning techniques is pretty standard.
Before I invited Graham I was thinking about inviting Chris Manning or one of his students to talk about NATLOG [10] [HTML] and, in particular, Sam Bowman's RNN and tensor-networks approach to learning natural language logical semantics for inferring commonsense facts from text [52, 53]. But this work also depends on specially annotated datasets and has similar problems with scaling and evaluation to those that Graham seems forced to deal with.
The problem is that, unlike traditional machine translation, program induction and parsing natural language into logical forms requires a deeper semantic understanding of the text. BLEU scores don't really seem like the appropriate method of evaluation for these problems — you can make a few grammatical mistakes in translation and depend on the human to take up the slack, but, in program induction and automated theorem proving, you want proof to be correct and the program to compile and pass all the unit tests.
Which brings me to my advice on picking course projects and, more generally, picking research projects in the future whether you end up in academia or industry. My comments here relate primarily to proof-of-concept projects like Neil Rabinowitz's machine theory-of-mind model [361] and not the sort of incremental research that characterizes much of the work shown at NIPS and CVPR. Incremental research may sound pejorative to your ears, but that is not what I intened. Progress depends crucially on incremental research and development. A few percent improvement in coverage or accuracy can make all the difference in some products — as they say, "The devil is in the details".
My advice boils down to (i) find opportunities to create interdisciplinary bridges, (ii) don't depend on labeled data or supervised learning, and (iii) identify problems characterized by one or two paradigmatic examples. (i) is a special case of "think outside the box", (ii) implies unsupervised / unlabeled, sandboxed / simulated, or reward based methods, and (iii) means look for controversy, preferably where someone else has come up with the defining problem, and then resolve that controversy with a simple thought experiment demonstrated by an elegant proof-of-concept computational experiment. The work presented by Michael, Randy, Neil, Jay and Matt are all examples of this class of problems.
I don't expect us to solve the programmer's apprentice problem in one quarter. That was never my intention. My expectation is that we'll make progress in designing an architecture by exploring the pieces of this problem and figuring out how they have to work together with one another in order to produce a comprehensive solution. By the way, it is fine if there are multiple teams or individuals working on the same problem. Collegial competition within an academic or industry research group is common, and especially encouraged when teams can figure out how to collaborate by sharing tools and support code while at the same time not becoming overly influenced by a competing team's core technical contribution.
April 30, 2018
%%% Mon Apr 30 04:31:29 PDT 2018
The previous log entry on sleep was not just a random observation about human sleep patterns, though I admit to taking the opportunity to encourage you to take your sleep seriously, but rather it was meant as an exercise in thinking about the different roles of memory in problem solving and serves as a prolog to this entry on why it might be worthwhile thinking carefully about the role of memory consolidation in building life-long learning systems such as the programmer's apprentice especially systems modeled after human memory — specifically models in which all computations are essentially performed in place and all memory is quintessentially volatile.
Two things occurred to me last week while catching up on my over-flowing queue of program-synthesis papers and re-reading the Yin and Neubig [487] paper for Tuesday's class:
Practically speaking, we never start on a programming problem de novo — there is always some context we can return to. For example, the general context of all the programs we've ever written and all the problems we've ever worked on, plus the specific context of a particular program or collection of programs and related thoughts that come to mind when contemplating the problem at hand.
Every time we sleep and our memories are organized, indexed, consolidated and refactored that context is altered. Every time we read or listen to just about anything pertaining to writing code, solving problems, planning activities, communicating in prose, etc., we are altering that context whether we realize it or not. Sleep — or at least a full night of undisturbed sleep — produces extensive changes in memory and, specifically, in the memories relating to the activity of the recent past.
Think of the simplest example of working on a program, taking a break and then returning later in the same day. Prior to taking a break, your eyes are glued to your computer screen. It seems like you can visualize the entire project in your head and know exactly where to turn your attention in order to continue working on any one of several pieces of unfinished code. The tabs of your browser point to dozens of documentation pages, email windows, shells and software engineering forums. Your desk, keyboard and computer screen may be festooned with coffee-stained yellow sticky notes covered with cryptic comments, many of which you probably can't decipher now but leave in place just in case. You may even have a pad of paper at hand to make drawings and scribble block diagrams.
When you get up to take a break, some of that organization is retained in memory, but the longer and more distracting the break, the harder it is to reconstruct the context and reestablish the cognitive affordances that made it easy for you to make progress. If your break included a conversation with someone on an unrelated topic, you may find it difficult to get back into your coding rhythm. Alternatively, however, you might find you have the solution to a problem involving the code you were working on before the break — a problem that has been nagging you for weeks and you weren't even aware that you had been thinking about it in the background. Forget about lucid dreaming, deep focusing and flow following, this sort of stuff happens all the time without any extra effort on your part.
Now think of what happens when you spend Friday working feverishly on a program. At the end of the day, you've made some progress in the form of subroutines and object classes that you're reasonably confident will end up in the final program, but also some half-finished code and perhaps a piece of code or algorithm that you're pretty sure is buggy, but you can't find the bug or you simply don't have the time to finish the code before heading home for the weekend. You take the bus home, not really thinking about code but rather exchanging email with friends planning the evening and perhaps a camping trip or long bike excursion to the coast. Friday evening you party until late, and Saturday you spend organizing, preparing for and then participating in a camping trip to Big Sur with three friends.
You aren't aware of thinking about work or writing programs until Monday when you take out your laptop and check your email, but after a cup coffee you find it relatively easy to slip into a fugue state and you're surprised when some problems that seemed intractable Friday afternoon now seem trivial or at least it is apparent how to refactor part of the code so as to suggest what seem relatively simple ways of moving the design forward. How did this come about? It should be obvious from the previous log entry that the brain is not inactive when you are sleeping. For example, sleep spindles represent a highly orchestrated pattern of activity taking place during Stage 2 NREM sleep. Different stages of sleep are associated with different patterns of connections being attenuated or strengthened. This activity appears to involve encoding new and revisiting old memories.
In a conventional von Neumann machine, we generally don't intentionally modify a program while we are running it. In the case of cephalopod and vertebrate brains, programs and memory are inextricably linked. Every time the brain adjusts a synapse connecting two neurons, consequences can propagate through the rest of the network unless steps are taken to contain the spread of activation. Synapses can't even be depended on to pass information in just one direction, from the pre- to the post-synaptic neuron — retrograde signaling provides the means for the post-synaptic neuron to send a retrograde messenger backwards across the synaptic cleft to influence the behavior of its pre-synaptic partner. There is much that neuroscientists don't know about the propagation of signals in large neural networks; suffice it to say, nature has found a way to precisely control the spread of activity in complex networks.
There is however substantial evidence to suggest that dreaming and REM sleep can enhance performance in solving complex problems including difficult associative and pattern recognition problems that require taking into account long-range, less-obvious connections between items in memory [399, 60, 415, 460] — see this article for a reasonably accurate — Cliffs Notes — summary of the research findings. The neural correlates of the activity that putatively supports this capacity are not well understood, but we've talked about hippocampal replay and how memory traces in the form of histories of activations including even precise trajectory traces can be encoded in epigenetic markers in the context of complementary learning theory [263].
This may not seem like a topic for a class final project, but you'd be surprised. You don't have to tackle the problem of code synthesis head on. Think about simple analogs of the problem of encoding a day's worth of programming and then post-processing the resulting memories so as to identify opportunities — adding or strengthening connections — for subsequent notice and application during the next day's coding. Read the articles mentioned in the previous paragraph, with special attention to the relatively simple experiments they conducted to test their hypotheses. Don't try to develop a model of sleep per se, but rather a model of memory consolidation that reveals potentially valuable relationships for future exploitation. Review what O'Reilly and others had to say about hippocampal replay and take a look at the papers listed on Greg Wayne's calendar page.
April 27, 2018
%%% Fri Apr 27 08:08:17 PDT 2018
We've had several lectures concerning memory that relate to synaptic changes occurring during development and normal adult learning. This process of memory consolidation ostensibly occurs during sleep though none of our speakers have spent any time on the biology. In this discussion log entry, I'll say a little about the role of sleep with two goals in mind: First, to convince you how important sleep is to cognition and your health in general, and, second, to give you some idea of the underlying processes.
Matthew Walker is one of the leading figures in the study of sleep and his recent book Why We Sleep: The New Science of Sleep and Dreams [461] is worth reading. His Google Talks lecture doesn't dwell as much on the science, but it does provide a good deal of data that should convince you of the importance of sleep as it is related to cognitive capacity, memory consolidation and almost every aspect of your physical well being. In the remainder of this log entry, I'll mention some ideas relevant to memory you might find interesting. Figure 46 includes three figures adapted from Walker's book [461] for our discussion here.
All mammals and birds sleep. It is essential to our ability to learn and manage of the episodic memories that to a large extent determine who we are. Your biological circadian rhythm controls fluctuations in your core body temperature and activates many brain and body mechanisms designed to keep your awake and alert as well regulate your sleep patterns. There are a number of hormones and neurotransmitters that ebb and flow in synchrony with your circadian clock (Process C in Figure 5) to orchestrate brain function. Melatonin is one such messenger signal regulating sleep onset and adenosine is another that increases the pressure to sleep (Process S in Figure 5). Caffeine and alcohol disrupt these signals altering our sleep patterns.
| |
| Figure 46: Here are my adaptations of three figures from Matthew Walker's Why We Sleep: The New Science of Sleep and Dreams [461] that are used in this log entry to describe the complex, multi-stage process of sleep in mammals and birds believed to be responsible for our ability to learn and manage our complex memories. | |
|
|

The lower left panel shown in Figure 46 is adapted from Figure 8 in Walker [461]. The inset graphic shows a hypnogram which is used to study sleep and diagnose sleep disorders. The x-axis indicates the time over the period the subject is observed and their sleep-stage recorded. The y-axis indicates the different stages of sleep. Historically, these stages have been divided into two general classes: rapid eye movement (REM) sleep during which humans principally dream, and non-rapid eye movement (NREM) sleep which are further divided into four sub stages indicated here by the numbers one through four.
The first thing to notice is that, in addition to sequencing between the various stages, sleep is divided into cycles that in the figure are offset by dashed blue lines, so that within each cycle, sleep appears to descend into deeper and deeper stages before reaching some deepest level after which it ascends back through the stages, often culminating in a brief period of wakefulness. These cycles average around an hour and half, and, at least in normal sleep, exhibit yet another distinctive pattern of activity: Early in the night we see little evidence of dreaming and REM sleep, but rather a stately descending-then-ascending traversal of the four stages of NREM sleep. As the night wears on, we see more REM sleep accompanied by increasingly shallow traversals of the NREM stages44.
Brain activity as measured by multi-electrode electroencephalography is very different between waking and the different stages of REM and NREM sleep as hinted at in Figure 9 from [461] reproduced in Figure 46. For the purposes of this brief introduction, memories of the day appear to be replayed over and over again often at a much slower pace that we originally experienced them. Moreover, during REM sleep there are distinctive waves of activity called sleep spindles that originate in the frontal cortex and then sweep backward through the primary sensory and secondary association areas45.
In REM sleep, the vigilance-signaling circuitry that we encountered in our discussion of consciousness serves as a gateway between the thalamus and the cortex and prevents the cortex from receiving any information from the outside world, a characteristic that is believed to contribute to the amorphous, random-seeming and almost delusional character of dreaming46. During the early NREM-dominated cycles, there occurs significant synaptic attenuation and pruning that is believed to prepare the way for incorporating new knowledge and assist in reconciling conflicts between new and old memories.
However, during the later REM-dominated cycles, there is a re-consolidation phase in which new connections are created and existing ones are strengthened. Walker provides his own explanation for why this complicated cycles-within-cycles process makes sense and I've included an excerpt from his exposition in this footnote47. Given what we've learned about the microglial shaping of dendritic spines in support of neural plasticity, you might think about how these sleep cycles could orchestrate microglia so as to consolidate memories at the genetic and molecular levels. Perhaps you can come up with a more plausible computational explanation of why the different intervals of REM and NREM sleep are organized in this fashion.
April 25, 2018
%%% Wed Apr 25 05:34:31 PDT 2018
We've been hearing about problems involved in applying reinforcement learning (RL) that arise due to the problem of partial observability when information is concealed from the RL agent's sensors. The assumption is that, while the current state may not reveal the value of an important task-relevant state variable v at a particular time t, there is sufficient information in the agent's history that would have allowed the agent to predict vt had it stored that information. A problem arises, however, when you have to decide what to store in episodic memory. The MERLIN system described in Wayne et al [471] learns to store episodic information in memory based on a different principle, that of unsupervised prediction:
MERLIN has two basic components: a memory-based predictor (MBP) and a policy. The MBP is responsible for compressing observations into low-dimensional state representations z, which we call state variables, and storing them in memory. The state variables stored in memory in turn are used by the MBP to make predictions guided by past observations. This is the key thesis driving our development: an agent’s perceptual system should produce compressed representations of the environment; predictive modeling is a good way to build those representations; and the agent’s memory should then store them directly. The policy can primarily be the downstream recipient of those state variables and memory contents [471].
| |
| Figure 45: Sensory input in MERLIN flows first through the MBP, whose recurrent network h has produced a prior p distribution over the state variable zt at the previous time step t − 1. The mean and log standard deviation of the Gaussian distribution p are concatenated with the embedding and passed through a network to form an intermediate variable nt, which is added to the prior to make a Gaussian posterior distribution q, from which the state variable zt is sampled. This is inserted into row t of the memory matrix Mt and passed to the recurrent network ht of the memory-based predictor (MBP). This recurrent network has several read heads each with a key kt, which is used to find matching items mt in memory. The state variable is passed as input to the read-only policy and is passed through decoders that produce reconstructed input data (with carets) and the Gluck and Myers [160] return prediction R̂t. The MBP is trained based on the VLB objective [250], consisting of a reconstruction loss and a KL divergence between p and q. To emphasise the independence of the policy from the MBP, we have blocked the gradient from the policy loss into the MBP. Adapted from [471]. | |
|
|
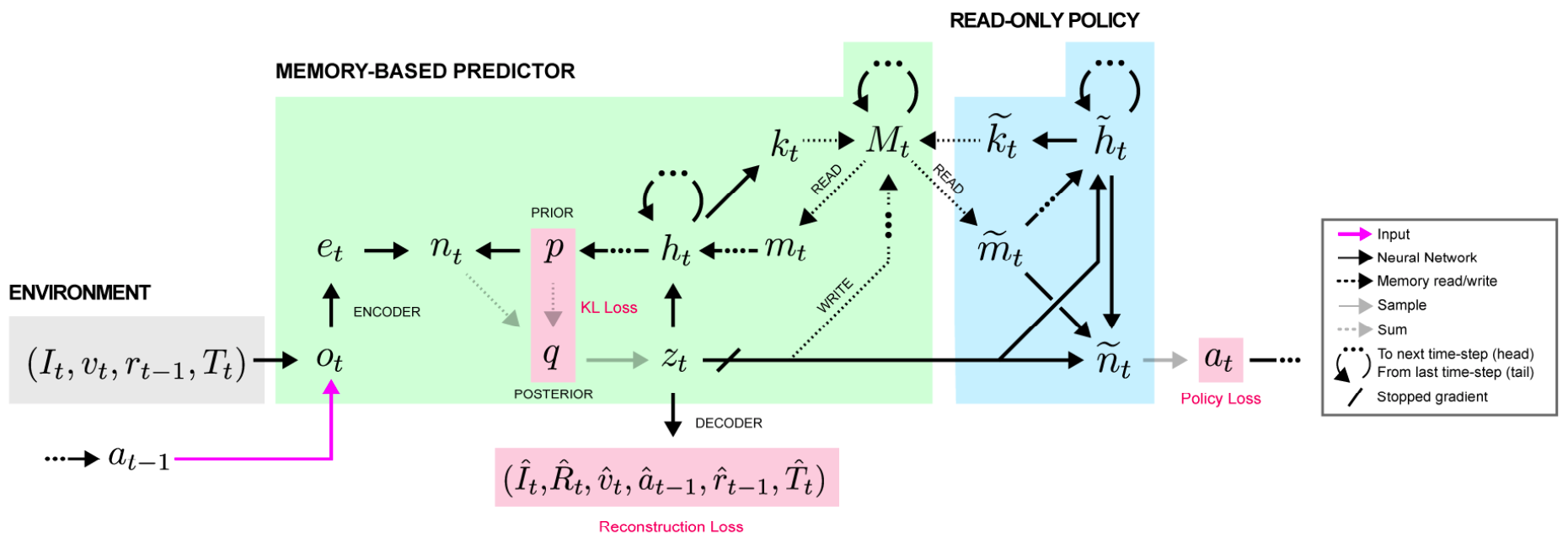
The basic model is illustrated clearly in Figure 1 of [471], part of which is reproduced in Figure 45. The idea of learning a compressed low-dimensional state representation is similar to Bengio's use of a consciousness prior that emphasizes "statements about reality that are either true, highly probable or very useful for taking decisions" [38]. Greg will be joining us on Thursday, May 3. If you have any particular questions about this paper or preferences for other papers on his calendar page that he might emphasize during his class discussion, send them along to me and I'll combine and forward your requests to Greg.
April 23, 2018
%%% Mon Apr 23 07:58:26 PDT 2018
Here are a few references that you might find useful in sorting out what type of activities are involved in executive function and when they are likely to appear in the developing brain [222, 254, 274]. The PBS Child Development Tracker summarizes many of the logical, mathematical and verbal skills that children acquire at different stages in their development during ages 1-9 [427]. The panel of experts consulted in compiling these statistics includes curriculum developers, educators and psychologists.
Hoskyn et al [222] "Executive Functions in Children's Everyday Lives: A Handbook for Professionals in Applied Psychology" goes into some detail describing changes in the developing brain involving the prefrontal cortex and related brain areas including the basal ganglia. The introductory chapter by Knapp and Morton [254] draws upon research in developmental cognitive neuroscience describe the time course of development in terms of the distribution and maturation of gray and white matter, the distribution of short and long connections, and the characteristic patterns of activity observed in children performing different executive functions (PDF).
April 21, 2018
%%% Sat Apr 21 05:02:42 PDT 2018
Imagine a neural prosthesis designed for children to accelerate their education by making it much easier for them to program their minds using their PFC-BG circuitry. Specifically, consider a simple register machine or pushdown automaton with a set of memory locations / registers that can be renamed as required, and a set of basic mathematical and logical operators that can be applied to operands temporarily stored in designated registers. The prosthesis would support the ability to define / train your own operators to perform arbitrary tasks, including creating macros, subroutines and programs involving conditionals and loops.
The objective here is to address the problem that Randall O'Reilly alluded to in his presentation the week before last, namely the problem faced by children spending the first 12 years or so of their lives struggling to program their brains to read and write and perform basic math and logic. As an archetypal use case, consider solving basic word problems like, Alice bought three candy bars for $0.50 each and two comic books for one dollar each; how much did Alice spend altogether? Memorizing multiplication tables and learning to add multi-digit numbers by carrying / regrouping shouldn't stand in the way of learning how useful mathematics is in everyday life. The hypothesis is that something like this could help children master their intrinsic PFC-BG capability.
As a practical matter, the neural interface is simply an NLP-capable personal assistant capable of continuous dialogue and the prosthesis is implemented as a differential neural computer [169] coupled with a graphical display that together with the dialogue management system handle all of the input and output. We could employ something like Zanax (TAR) to build a narrow-focus conversation-tree generator as an extensible hierarchical planner plus word-and-phrase semantic embedding space model for dialogue management. If the team is large enough we can think about more ambitious solutions to the related dialogue-management / natural-language interface problem.
Dan suggested resurrecting Google Scribe to perform auto completion. It might be feasible to complement this capability with word-and-phrase semantic embedding space model to enable enhanced context sensitive recall and we surmised it might even be the case that later versions of Google Scribe already incorporate this sort of semantics smoothing. Alas, Google Scribe was retired in 2011 and though temporarily revived in Blogger in Draft, I can't find a suitable alternative API. However, it is probably best to avoid bells and whistles and focus effort on one or two key technical innovations so as to produce a limited-functionality demo that really showcases the primary innovations.
April 19, 2018
%%% Thu Apr 19 07:09:40 PDT 2018
Rebecca Saxe is an associate professor of cognitive neuroscience in MIT’s Brain and Cognitive Sciences Department who studies how humans make judgments concerning the moral behavior of other people — check out the Saxe Lab. In this TED Talk, she discusses her research on the neural correlates of this aspect of theory of mind reasoning. There's more information about her research in this MIT Technology Review article and details in this Encyclopedia of Consciousness article. I don't know the literature well enough to recommend a relevant review in a scientific journal, but if you know of such a review, please send it my way.
On a related note, I told some of you about the work on hierarchical reinforcement learning from Pieter Abbeel at UC Berkeley [186, 429, 188]. Pieter has also been working with Igor Mordatch and their colleagues at the University of Oxford on related problems that involve reasoning about other minds. On his OpenAI blog, Igor summarizes a recent paper that he co-authored with Pieter [146]:
We’re releasing an algorithm which accounts for the fact that other agents are learning too, and discovers self-interested yet collaborative strategies like tit-for-tat in the iterated prisoner’s dilemma. This algorithm, Learning with Opponent-Learning Awareness (LOLA), is a small step towards agents that model other minds. [SOURCE]
I'm not suggesting that this is a good project for this class, but it may be worth your while to at least read the introduction so as to plant a seed in case you run across an interesting application of the idea. If you like science fiction, Hannu Rajaniemi's The Quantum Thief trilogy is IMHO one of best hard science fiction books of the last decade, deftly applying ideas from game theory, recursive theory-of-mind reasoning, the Prisoner's Dilemma problem and quantum mechanics to explore the unreliability and malleability of memory in a future dominated by recursively simulated minds: The Quantum Thief (2010), The Fractal Prince (2012) and The Causal Angel (2014).
April 17, 2018
%%% Tue Apr 17 05:09:40 PDT 2018
I once heard a physicist say that if space-time is curved, then various characteristics of the cosmos as predicted by perturbation theory would seem to indicate that the fundamental relationship between matter and the geometry of spacetime is probably dictated by something very much like Einstein's field equations. This is what came to mind when I was thinking about ToM modeling during my swim this morning: loosely coupled field equations, eigenstates and quantum superposition. I'll give you a quick synopsis of the nascent ToM model I was playing with while swimming in the AOERC pool this morning.
This observation about the confluence of physical systems, models and simulations makes it seem all the more plausible that the human mind can employ itself as a general model of other minds so as to infer what other humans might be thinking about and how they might act upon whatever conclusions they draw. In revisiting Fodor and Pylyshyn [144], O’Reilly et al contrast the context sensitivity of highly-parallel connectionist approaches with the systematic, combinatorial nature of largely-serial symbolic systems, including exact Bayesian models.
In thinking about what Neil Rabinowitz said during his presentation and the following class discussion on theory-of-mind reasoning, I was particularly intrigued by what he had to say about the computational complexity of constructing and reasoning with a Bayesian prior over mental models and especially symbolic models. It made me think of Matthew Turk and Sandy Pentland’s Eigenfaces model [444, 443] and related work by Sirovich and Kirby [400] also based on representing any face as a linear combination of the top n eigenvectors of a large matrix whose rows are the compressed images of faces.
These models attempt to parameterize the space of human faces borrowing the notion of Hilbert space, eigen decompositions and principal components analysis from linear systems theory all of which can be represented as simple linear transformations in conventional neural networks. The idea of eigenminds and spectral personalities seems a natural. We start with a single distributed template — our own mind and its associated personality profile, refining this (personal) model over time while comparing it — contrasting and recording differences — with anything we encounter that might possibly have a mind including cats, toys and turtles.
Our mind then contains the superposition of many mindstates with all the richness afforded by our extensive sensory and association apparatus. These mindstates are complemented by episodic memories / observations featuring partially reconstructed minds — possibly identified by recurring eigenminds — represented as weighted combinations of mindstates. Between the eigenmind Hilbert space and our episodic memory we could, in principle, construct a prior distribution over minds, but, in practice, we never do since this would require an enormous amount of computation. We may, however, be able to sample from it to reconstruct partial minds in a manner suitable for tractable decision making48.
April 15, 2018
%%% Sun Apr 15 04:59:33 PDT 2018
I've considered the possibility of using the suggestions on hacker forums like Stack Exchange as the training data for a program synthesis system that writes short shell scripts specializing in one or more standard unix tools like ImageMagick or FFmpeg. So when I wanted to modify the video recorded from our two invited speakers last week, I thought this would be a great opportunity to get a feeling for how hard this might be.
I've used both these tools before and I have some experience applying them to simple problems but it's been some time since I last used them and the tools have evolved considerably to deal will all the latest codecs and image standards. Bottom line: suggestions for writing short video editing scripts are often ambiguous, full of outright errors and routinely offer solutions that only work on older codecs and image formats. It is a wonderful asset for aspiring programmers but not so great for a neophyte.
Automated program synthesis is hard enough as it is without having to deal with all the misdirection and misinformation found on such forums. Most work on automated synthesis uses some strategy to simplify the problem. Some researchers use domain specific languages like SQL or pared-down languages like a minimal subset of Scheme that are Turing complete, but it is a lot easier to write short programs that compile and run and that makes it easier to bootstrap learning.
Dan Abolafia and Quoc Le in Google Brain are using the minimalist Turing complete Brainfuck language in their work [1]. Dan is fond of saying that you can learn anything with reinforcement learning if you have the right reward signal. Researchers have in the past been surprised when they move from one level of representation, say strings of words, to a seemingly lower or more primitive level, say strings of letters, and find tasks like translation and language parsing as easy or easier. Perhaps that phenomenon is what Dan and Quoc are hoping to exploit in their work. Dan will be joining us in class on April 24.
I've included the shell script I came up with in this footnote at the end of this paragraph. I am sure a true adept could condense it into a single line. Even the simplest scripting languages as well as many DSL programming solutions tend to accumulate features so that they end up becoming universal often posing security risks in the process when they are employed in routers, switches, modems and other gateway and firewall related technologies49.
April 14, 2018
%%% Sat Apr 14 6:39:12 PDT 2018
For those of you interested in automated code synthesis, I'm happy to suggest some places to start looking for related ideas, but there have been a lot of papers published on neural code synthesis in the last few years and so it might be a good idea to cast a wide net to start with in order to see if anything really resonates with your current thinking. That said, I've invited several experts to join us in class discussions, including Rishabh Singh and Dawn Song each of whom have their own unique perspective, and checking out some of their work might serve as a springboard. I expect that both Rishabh and Dawn would be willing to answer your questions and might modify the content of their talks somewhat to accommodate your interests.
Rishabh has been focusing on special cases of the problem for several years and you might search the class discussion pages for specifics and check out the page for his talk on the class calendar here. Dawn works in several related areas involving security again you might first check the class discussion and then her talk page on the course calendar here. Dan Abolafia is a software engineer working in Google Brain on neural program synthesis. Dan's most recent work [1] involves reinforcement learning using a reward function over the output of programs written in a compact Turing complete programming language called BF. His calendar entry is here.
Two of the recent papers that Rishabh co-authored, Wang et al [467] and Devlin et al [119] — see BibTeX entry below and attached papers, came to mind when I was listening to Randy. I was thinking about how someone might learn to make simple edits to a code fragment using the PFC-BG system in order to adapt such a fragment as part of a new program. Specifically, I imagined the transformations mentioned in the latter paper as a means of learning something more akin to macros or subroutines that make more extensive modifications to a code fragment. In any case, reading these papers right after Randy's class discussion seems like a good strategy to spark some new ideas.
Graham Neubig is an interesting special case of a researcher primarily working on NLP but with an interest in code synthesis. His ACL paper last year [487] considers the problem of parsing natural language descriptions into source code written in a general-purpose programming language like Python. I expect more from him in this area and you can find representative papers on the course calendar here. Those of you interested in NLP and dialog management might want to sample some of the neural-network- and reinforcement-learning-based research papers relating to dialog found on his lab's publication page here. For example, Hiraoka et al [216] uses an active learning framework to construct example-based dialog systems efficiently.
P.S. My BibTeX repository might also prove useful, e.g., search for occurrences of "Rishabh" to find papers by Rishabh Singh or "Dawn" to search for Dawn Song's work. And here is a specialized collection of papers that focuses exclusively on papers that perform machine learning on source code. Lest I forget, it's worth making sure that you understand the basic idea of neural programming. The name perhaps suggests more than you might reasonably expect or hope for, but it's an interesting special case of attentional networks that offers a lot of potential for very little extra architectural complexity.
April 12, 2018
%%% Thu Apr 12 4:44:26 PDT 2018
The first two lectures introduced a set of core problems and now we've begun to explore solutions to these problems. The collection of experts we've invited to talk with you will provide insights I think you will find enormously useful, not only for your project in this class, but in your subsequent professional lives as engineers and computer scientists.
The ideas may seem abstract or overly concerned with the neural correlates of whatever cognitive processes they are intended to explain, but in the coming weeks I think you'll learn to appreciate the insights they provide in solving some of the most challenging problems of advanced applications like automated code synthesis and continuous dialog management.
The immediate pedagogical goal is for you to learn how to combine three key technologies borrowed from modern neural networks — reinforcement learning, differentiable key-value memories and attentional interfaces, so as to construct integrated neural-network architectures that are capable of learning to perform complex temporally extended tasks.
Stocco et al [416] discuss the ACT-R architecture supporting symbolic reasoning in the form of instantiating and firing production — condition-action — rules. O'Reilly et al [336] describe a more general system involving the prefrontal cortex and basal ganglia. The PFC-BG system is programmable. Think about what this means.
In contrast, you might want to consider the more specialized program repair model of Devlin et al [119]. One of the authors, Rishabh Singh will join us Thursday, May 24. In addition, to providing a powerful tool for automatic code synthesis the authors employ a clever method of training their model and have made the data available on GitHub.
%%% Thu Apr 12 14:25:10 PDT 2018
As you may or may not know, the word "consciousness" has a complicated history. It's only in the last few years that is has started to receive attention in the popular press. For example, this article by Jason Pontin writing in Wired entitled "How do you know you are reading this?" reports on some recent experimental results from Marcello Massimini and colleagues at the University of Milan attempting to measure neural correlates of consciousness in human subjects and by so doing provide some evidence for Giulio Tononi's integrated information theory of consciousness [437, 436]. The article includes commentary from Scott Aaronson, director of the Quantum Information Center at University of Texas at Austin, and Christof Koch, chief scientist at the Allen Institute for Brain Science.
I mainly stick to ideas related consciousness useful in building intelligent machine such as Yoshua Bengio's consciousness prior [38]. Yoshua's working notion of consciousness in this short paper isn't nearly as detailed or inclusive as Dehaene's or Graziano's. When I think of applications of consciousness, they are far from, say, those relating to "what it feels like to be me" and much closer to what cognitive scientists would recognize as executive or cognitive control. In principle, the PFC-BG system that O'Reilly and others work on should make it easy for us program ourselves, but it certainly doesn't feel that way. Think about how you carry out routine math chores like time and date calculations, e.g., "If today's date is April 12, what is the date for the day two weeks from now?" or "What day of the week will April 12 fall on three years hence?".
There are multiple steps in the algorithms that I imagine most people are likely to employ for this task, and, in order to carry them out efficiently, you have to consciously keep track of initial arguments and intermediate results. I've internalized these particular algorithms long ago, but they are not general purpose nor well structured from a software engineering perspective and so I often have to learn a new algorithm for a task that, as a software engineer, I would be able to use existing subroutines. What's most interesting to me is how, having consciously come up with and practiced such an algorithm, I can turn it into a compiled version that I can execute without conscious oversight.
Here's a simple exercise you might try to better understand how it is possible to program yourself. This exercise may also provide you with some insight into how you might automate a similar process in the programmer's apprentice application and why you might select a different and possibly more efficient method for code synthesis. Here's the exercise: Select some date — for simplicity, just a month and a day within that month, e.g., today, April 12. Call this the end date. Pick another date, e.g., November 2. Call this the start date. Now calculate the number of days between the start and end dates. This is intended as a programming exercise since you're expected to contrive and then execute an algorithm to run on your neural substrate unassisted by auxiliary apparatus including calculators, paper and pencil or using your fingers or other external tools to count or store intermediate results.
Initially, I made a rough estimate by adding up the number of days in each month between the start and end. This was made somewhat challenging since I had to (a) keep a running tally, (b) recall each month in calendar order, and (c) remember how many days each month has using the mnemonic we learned in grade school. Then I simply subtracted the start day of the month and added end day of the month. Then I revised the first part of this algorithm to (a) count the number of months, (b) multiply by 30 to obtain an initial count, and (c) sum all the deviations from 30 and subtract from the initial count. It might seem more complex, but it felt cognitively easier. Think about the different terms that Dehaene [108, 106, 104] uses to describe state of mind relating consciousness50.
April 11, 2018
%%% Wed Apr 11 3:45:27 PDT 2018
The distinction between connectionist theories of cognition and the dominant symbol-processing viewpoint of the time polarized the field of artificial intelligence in the 1980s. The apparent demise of symbolic reasoning in AI has been exaggerated by the press in light of the recent success of the current breed of connectionist models51. However, if you're in the trenches designing systems intended to solve real-world problems, you're likely to have a very different perspective.
The truth is that most modern neural network architectures are hybrid in the sense that they include some components that are straightforward extensions of neural network architectures developed in the 1980s but also include additional components that support some form of symbolic reasoning. The most obvious examples implement some form of key-value memory along with an attentional interface that supports content-based access and retrieval. Neural Turing Machine (NTM) [454, 168] and Differential Neural Computer (DNC) [169, 185] models were among the first, but many variants are now common.
Concepts in purely connectionist models generally have no real distinct boundaries. The fact that their boundaries are fluid and their meaning derives from context — often the context being defined by the (perceived) fuzzy boundaries of the real world, makes them ideally suited to solving problems involving noisy perception, continuous expression and natural variability. Symbols are fundamentally abstractions that cut through the noise and fuzzy boundaries to enable us to make precise statements and apply the rules of mathematics and logic in order to generalize and explore their (abstract) consequences.
The question isn't whether we need one or the other of these two approaches but rather how best to combine the two in order to solve the problem at hand. The Architecture of Cognition chapter [336] that Randy O’Reilly selected for his primary reading is perfectly timed and targeted. Despite focusing on the claims of Fodor and Pylyshyn [144], the paper is wonderfully self contained and provides a perfect introduction to students whose primary exposure to the issues has been a basic machine learning course with an emphasis on the modern interpretation and application of connectionism 52.
In preparing for class, think about examples illustrating the sort of concessions required to integrate combinatorial capabilities within the primarily context-sensitive capabilities of modern neural networks53. Search for existing architectures that either solve variable binding problems or manage to finesse variable binding within a purely connectionist model avoiding the need for such solutions altogether. What sort of neural-network architecture might work best in developing an automated programmer capable of designing, debugging and testing a new program by utilizing fragments of old programs?
April 9, 2018
%%% Mon Apr 9 04:17:14 PDT 2018
For those of you not familiar with cognitive neuroscience technical articles, reading the primary content for Tuesday's class, Graziano [179] (PDF) could be a bit disconcerting. Prior knowledge from reading other books on consciousness and subjective awareness, say, the work of Daniel Dennett [114, 111], in the philosophy of mind literature, probably won't help much.
Despite occasional references to what might seem to you as obscure philosophical treatments or somewhat dated cognitive theories, Graziano's treatment is refreshingly jargon free and computationally oriented. Graziano's theory carefully teases apart the subjective and objective and distinguishes between neural states that arise in the brain of an entity becoming conscious of some internal or external state and processes that occur when someone is asked to report on some aspect of their experience. Disentangling these related aspects of cognition helps a good deal when thinking about the various data structures and algorithms required to support a particular set of cognitive capabilities54.
Graziano also mentions the Integrated Information Theory of Giulio Tononi [436, 437] and the Global Workspace Theory as it figures in the work of Baars [21] and more recently Dehaene [108, 108, 104]. These theories are not necessarily competing. They emphasize different characteristics of consciousness only some of which are directly relevant to our interests. I particulary appreciate Graziano's theory since it is simple and compelling with respect to its computational grounding.
Take this opportunity to think about those aspects of global workspace theory that we talked about in class and that are discussed in the class notes and attentional schema theory as described by Graziano in the reading for Tuesday and summarized in the short video sent around earlier. In particular, think about the related problems that arise in the programmer's apprentice application and that will manifest in future digital assistants such as the successors to Alexa, Siri and Google Assistant. If you engage in meditative practice, you may find it interesting to relate these computational ideas about consciousness to those described in Buddhist and Tauist secular teachings that date back over two-thousand years.
April 7, 2018
%%% Sat Apr 7 04:46:12 PDT 2018
Here are my extended responses to a couple of the questions that came up in class on Thursday:
I. What about the large datasets required to train natural language processing applications like machine translation and visual processing applications like object recognition, scene segmentation and video captioning?
Summary: From the perspective of machine learning and training AI systems de novo, the best solution is side-stepping the problem altogether by leveraging reinforcement learning and tools and sandboxes that allow the system to generate its own synthetic data or amplify a small dataset. In the case, code synthesis scraping GitHub, Stack Exchange or any number of other repositories and programmer forums is often a good option. Stanford and other universities and online learning companies like Corsera have a wonderful asset in the form of student answers to homework and exam questions that exhibit a wide range of variability. Many of these sources also provide ground truth in the form of specifications and sample I/O that cane be checked by running code.
In class, it was suggested that humans don't require such prodigious amounts of training data, and I countered that the fetus is already receiving synthetic visual stimulus in the womb and that human children undergo a sustained early development period that allows for them to experience an extensive and diverse sample of visual stimuli. Early interactions with parents and the environment help with learning useful features and object categorization and various modes of primitive signaling and the acquisition of language facilitates transfer learning and exploiting multiple modalities to support cross-modal one- and zero-shot learning.
This answer doesn't actually contest the claim that vision and language acquisition require a good deal of training data, but it does suggest that there are lots of tricks we can borrow from nature to facilitate acquiring the necessary experience. With the exception of prenatal visual stimulation, engineers at Google and elsewhere have experimented with all of the tricks mentioned above and more. One strategy dubbed "couch potato" leverages huge numbers of YouTube videos to train computer vision systems for diverse applications. Most of the data used in training such systems is unlabeled.
Language is even more interesting. Babies in the womb can already detect word boundaries in the mother's native language. Early on they learn to read facial cues and perform gaze tracking thereby avoiding the need for overt labeling. Again, these strategies found in nature, often end up integrated into machine learning systems, but engineers tend toward KISS — Keep it Simple Stupid — strategies and we are awash in unlabeled data that can be exploited without the need for explicit labeling.
II. On the problem of exagerated reports of the performance of the next new thing — the neural architecture du jour as it were. Specifically, are the latest attentional models for, say, machine translation as good as or better than, say, gated-feedback recurrent networks or even simpler convolutional architectures?
Summary: It is tricky to compare different models even trained on the same dataset. Performance depends to a considerable degree on the skill of the team developing the technology. Your mileage may differ. Part of the problem is that seemingly very different architectures — mature architectures like convolutional networks in particular — have all sorts of bells and whistles and have evolved over time to become more like Swiss army knives than the sort of bespoke tools that have been crafted to solve a particular class of problems.
Convolutional networks and recurrent networks like LSTMs and gated-feedback RNNs employ very different approaches to identifying recurring local structure. These approaches often have consequences in terms of the number weights they require to implement or the amount of data and training time they require learn a good model. Traditional CNN models employ filters with a fixed size receptive field or a stack of increasingly scaled layers. Some models use shared weights to learn a fixed-size filter basis that applies across an entire layer. LSTM models accommodate a wide range methods for analyzing structured data including 1-D sequences, 2-D images and 3-D volumetric data. Currently, it is more art than science to design a specific architecture and most engineers favor one or two classes of models and employ sophisticated strategies to make one type of architecture perform like another if the need arises. Alex Graves, Oriol Vinyals, Richard Socher, Ilya Sutskever and Christian Szegedy are among the modern masters of this fine art.
You can incorporate an attentional interface into most any class of models including both convolutional and recurrent networks such as LSTMs. You can also include convolutional layers in stacks with recurrent and skip (forward) connections. When you're considering whether or not to use an attentional interface you need to consider what sort of dependencies you are trying to account for. In class on Thursday, I gave the example of keeping track of pronominal references — an accessible, but narrow use case that exemplifies a much wider class of related problems. If all you're concerned with is maximizing a metric like the BLEU score for measuring the performance of an MT application you can afford to mess up a few pronominal references. However, if you're trying to predict RNA-protein binding sites from raw RNA sequences, then screwing up even one nucleotide could be disastrous. The point is that attentional interfaces offer a lot of control if it is important to infer long-range dependencies correctly. In the case of code synthesis, long-range dependencies can be critical.
Tutorial: The Stanford CS class CS231 notes on convolutional networks are probably both more and less than you want or need, but the presentation is very clear and the treatment relatively comprehensive. In class, I mentioned — and recommend — the tutorial on attention by Chris Olah and Shan Carter from Google Brain entitled "Attention and Augmented Recurrent Neural Networks". I like Andrej Karpathy's discussion on the unreasonable effectiveness of recurrent neural networks — paraphrasing the title of an article published in 1960 by the physicist Eugene Wigner: "The Unreasonable Effectiveness of Mathematics in the Natural Sciences".
Background Notes
March 19, 2018
%%% Mon Mar 19 05:48:16 PDT 2018
Program embedding is one of the core enabling technologies for automated code synthesis. Programming languages lend themselves to embedding solutions that leverage existing solutions in natural language processing and large-scale document classification. The most obvious methods are derived from NLP in order to exploit syntactic structure, lexical analysis of keywords and context to derive shallow semantics. However, in the case of computer programs, we can extract much deeper semantics by actually running programs.
Earlier entries — see here — in these discussions discuss methods that analyze execution logs or program traces [68, 481] to compare programs and analyze errors. In this entry we consider new related work. Coding by substitution refers to programming by starting with an existing program thought to be similar, e.g., by searching in a repository like GitHub or forum like Stack Overflow, and making alterations by substituting fragments of other programs.
Debugging in this case might involve running the code and making simple adjustments to correct for errors, e.g., altering variable names, fixing type references and adding conditional statements. In simple cases, this approach can speed programming. Semantic errors in the case of coding by substitution are caught by the compiler or interpreter and search for suitable fragments to substitute are handled by key-word code search and nearest-neighbor embeddings of program abstract syntax trees.
Execution logs and program traces provide semantic information that can also be embedded as graphs or other structured objects and used to complement syntactic embeddings. As we discuss here, the two can be combined as shown in [345, 468]. Another possibility that we will consider in later entries is to generate lots of specific, diagnostic semantic embeddings on the fly when debugging and testing, to be used in addition to a large general-purpose, repository-size embedding for generating substitution proposals.
In this entry we take a look at Wang et al [468] and briefly revisit Piech et al [345], two papers that combine syntactic and semantic information in neural network embedding models that are learned from program execution traces. Wang et al claim that methods that embed program states expressed as sequential tuples of live variable values not only capture program semantics more precisely than embeddings based purely on token sequences, but also offer a more natural fit for recurrent neural networks to model.
Piech et al [345] represent programs using input-output pairs that Wang et al claim are too coarse-grained to capture program properties, since programs with identical input-output behavior may possess very different characteristics. The problem is that when a program is executed "its statements are almost never interpreted in the order in which the corresponding token sequence is presented to the deep learning models [...] For example, a conditional statement only executes one branch each time, but its token sequence is expressed sequentially as multiple branches. Similarly, when iterating over a looping structure at runtime, it is unclear in which order any two tokens are executed when considering different loop iterations."
| |
| Figure 44: Three different embedding strategies from Wang et al [468]: Panel A variable trace for program embedding — from Figure 3 in [468], Panel B state trace for program embedding — from Figure 4 in [468], and Panel C dependency enforcement embedding where the dotted lines denoted dependencies— from Figure 5 in [468] | |
|
|
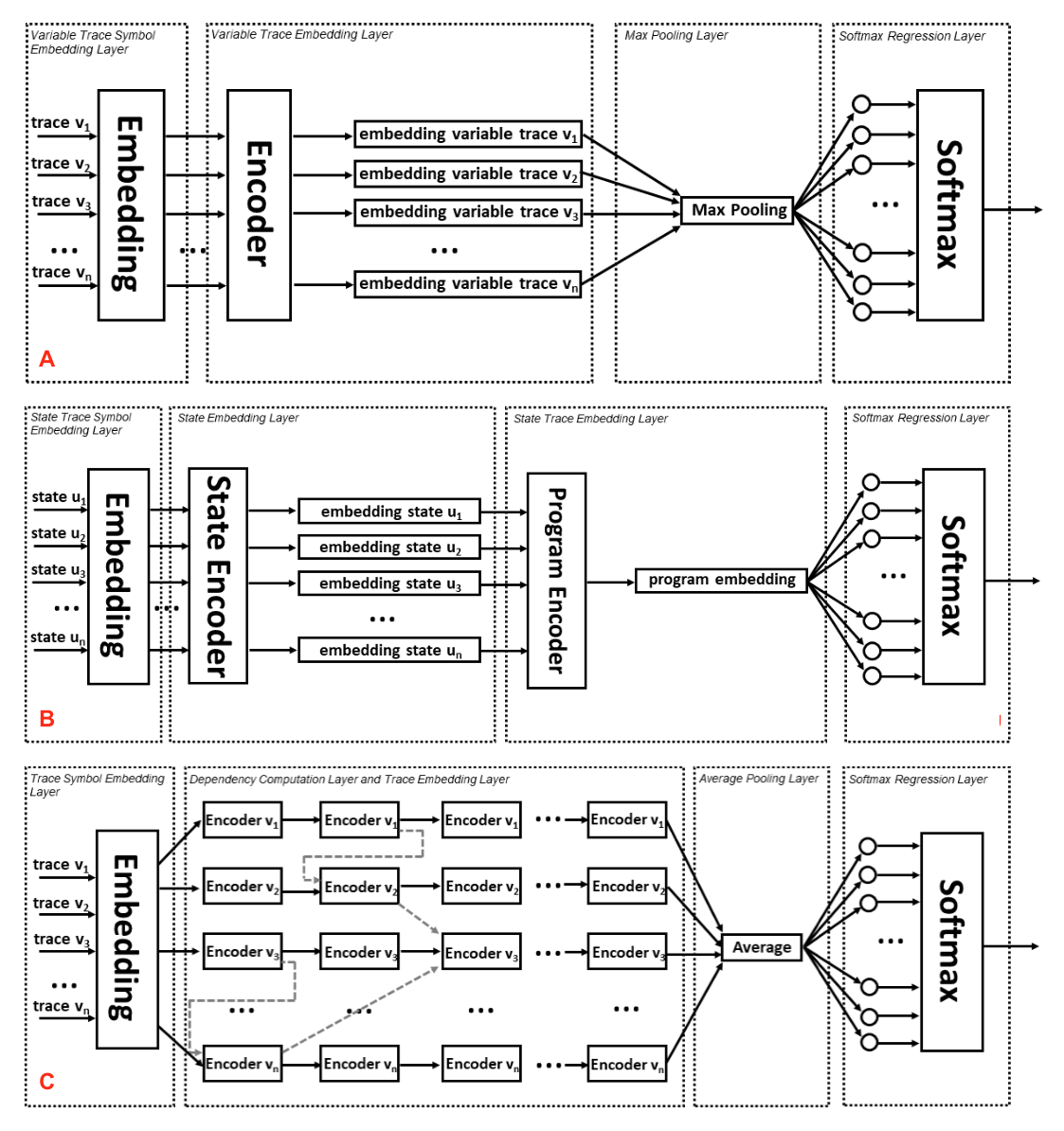
Wang et al evaluate three different embedding models shown in the three stacked panels of Figure 44:
Panel A illustrates the variable trace embedding model in which each row denotes a new program step where a variable gets updated. The entire variable trace consists of those variable values at all program steps. As a subsequent operation, the complete trace is split into a list of sub-traces with one sub-trace for each variable.Panel B illustrates the state trace embedding model intended to deal with the fact that variable trace embedding doesn't represent variable dependencies. In this model, programs are encoded as a sequence of states in which each state encodes the most recent variable valuations. The model uses two recursive networks, the first of which encodes each program state and a second that encodes sequences of such states.
Panel C illustrates the dependency enforcement embedding model that addresses the problem of dealing with the redundancy in loops with many iterations. This model combines features of the previous two models by embedding each variable trace separately while interleaving the separate embeddings so as to identify and enforce program dependencies, pooling the final states of all the separate embeddings to obtain joint embedding.
The authors credit Ball [24] with the inspiration for their approach. Ball's method of analyzing the properties of a running program is worth reading if you plan to focus on code synthesis in your class project. I also recommend Reed and de Freitas [362] for its application of the idea of using dynamically programmable networks in which the activations of one network become the weights (program) of another network.
Reed and de Freitas point out that this idea for using dynamically programmable networks also appeared in Sutskever and Hinton [422] in the context of learning higher order symbolic relations and in Donnarumma et al [124, 125] as the key ingredient of an architecture for prefrontal cognitive control. I've only had time to read the abstracts and scan these papers, but the very idea is tantalizing.
March 15, 2018
%%% Thu Mar 15 05:21:10 PDT 2018
This entry reviews two papers relevant to life-long learning: Pritzel et al [358] on neural episodic control relating to reinforcement learning and the ability to incorporate new experience into our policies and predictions. Sprechmann et al [413] on memory-based parameter adaptation dealing with the non-stationarity of our immediate environment — even if the dynamics governing our environment are stationary they will not appear so to us as such since at any point time we will have only experienced a small fraction of what can happen and not committed to memory even that small fraction.
Both of these papers address problems that crop up in the largely uncharted space of life-long learning and long-lived agents that share common history with other agents and are expected to differentiate such independent agents and account for their behavior on the basis of what they — the other agents — know and don't know — see the earlier discussion of Rabinowitz et al [361] on theory-of-mind reasoning here. That they overlap significantly in their technical content and approach to complementary-learning theory is gratifying and not entirely unexpected.
| |
| Figure 43: Architecture of episodic memory module for a single action a. Pixels representing the current state enter through a convolutional neural network on the bottom left and an estimate of Q(s, a) exits top right. Gradients flow through the entire architecture [413]. | |
|
|
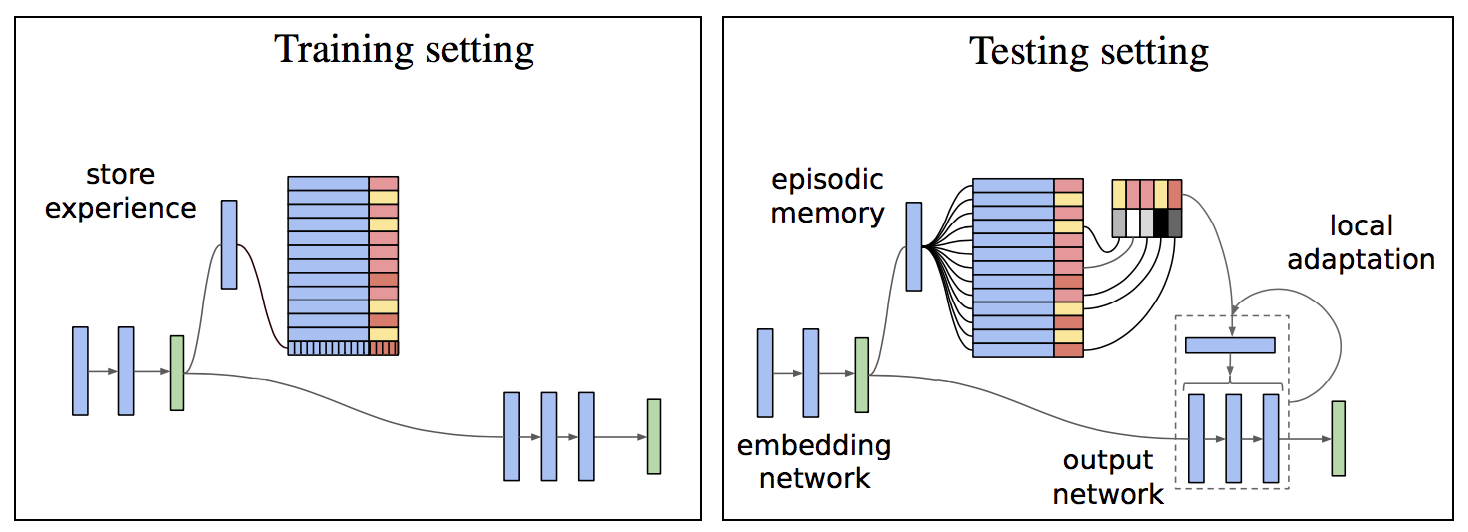
Each of the two papers is well written and you should find it easy understand either one if you read carefully. Taken together they are even more valuable as they demonstrate how the basic ideas can be applied in different contexts, e.g., reinforcement learning, language modeling and visual recognition. The differential neural dictionary (DND) is a generalization of the memory and lookup schemes described in Vinyals et al [453]. The strategy of using the top k-nearest neighbours and an approximate nearest neighbours algorithm to perform lookups should scale for key-value memories of practical size. It's worth thinking about the permutation-invariant version of MNIST as a basis for evaluation [163].
More generally, you might want to think about the complex cascade of developmental processes spanning early stages in the growing foetus and extending well into adulthood in humans, and ask yourself whether we will have to engineer similar processes in the training of artificial systems. Greg Wayne will talk about his work with Adam Marblestone, Konrad Kording and Ken Hayworth [302] on the trend toward structured architectures that include dedicated systems for attention, different requirements for short- and long-term memory storage, and cost functions and training procedures that vary across layers and times, incorporate a wide range of regularization terms, and, in some cases use one part of a more complex architecture to generate cost signals for another part.
On a side note relating to the preponderence of powerful recurrent neural networks in network architectures, Dan Fernandes sent me a link to some recent work [236] demonstrating that convolutional networks with skipping convolutions perform as well or better than recurrent neural networks such as LSTM architectures on some sequential tasks including applications in computer vision and machine translation. See also related work combining convolutional networks and skip connections applied to top-down modulation for object detection [393] and semantic image segmentation [391].
March 11, 2018
%%% Sun Mar 11 03:49:12 PST 2018
In addition to batch learning that occurs when initially training an artificial neural network, many applications require retaining information for different lengths of time during processing. Gated-feedback and long short-term memory recurrent neural networks are designed for this purpose, but there are other use cases that RNN architectures don't cover.
Examples include episodic memory that we've briefly touched on relating to its role in autonoetic consciousness and will re-encounter in the work of Dehaene [104] and Graziano [170], and the global workspace theory of Baars [21], and its application in facilitating executive function [331].
We'll spend some time reviewing various approaches for modeling slot-filler approaches in differentiable representations of rule-based systems with a special emphasis variable binding, including Kanerva's spatter code [246], holographic memory models [349] and more recent work on modular composite representations [405].
One of most interesting theories about human learning concerns how different learning systems involving the hippocampus and the neocortex complement one another so that the hippocampal system can rapidly learn new items without disrupting related neocortical memories and the introduction of new memories can be interleaved with older memories integrating them into structured neocortical memory systems [306].
| |
| Figure 42: Hippocampal memory formation, showing how information is encoded and retrieved. The critical learning takes place in the CA3 Schaffer collateral projections that interconnect CA3 neurons with themselves, and in the projections between the CA3 and the CA1. CA3 and CA1 represent the highest levels of encoding in the system (where the blue arrows end), and memory encoding amounts to strengthening the associations between the active neurons within these regions, while memory retrieval involves pattern completion within CA3 driving reactivation of the associated CA1 pattern, which then feeds back down to reactivate the original activity patterns throughout the cortex. IT, inferior temporal. — from O'Reilly et al [335]. | |
|
|
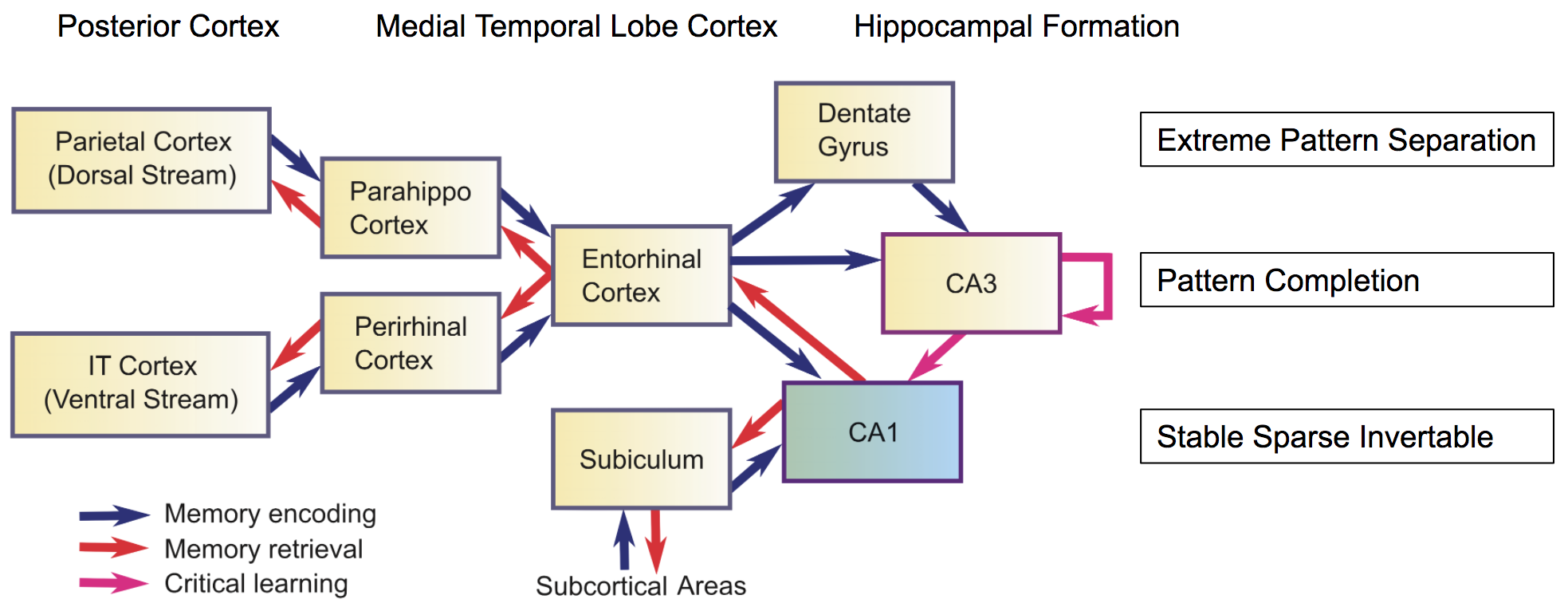
Figure 42 is borrowed from O'Reilly et al [335] in which the authors revisit the theory of complementary learning systems (CLS) set forth in McClelland et al [306] taking into account experiments and data generated during the intervening twenty years. The graphic does a nice job visualizing how information flows between the relevant cortical and hippocampal regions to explain how these systems complement one another. The remainder of this entry is an extended quote from [335] that explains one of the key insights of the paper better than I could hope to reproduce in my own words:
"[I]t had long been known that the hippocampus plays a critical role in episodic memory, but the CLS framework provides a clear and compelling explanation for why such a system is necessary, and what its distinctive properties should be relative to the complementary neocortical learning system. One of the most intriguing contributions of the approach was an explanation for the observation that the hippocampus can replay individual memories back to the neocortex.
This achieves an interleaving of learning experiences, which PDP models [372] showed is capable of eliminating catastrophic interference. This abstract principle of learning made the concrete and seemingly counter-intuitive prediction that older memories should be relatively spared with hippocampal damage, because they will have had time to be consolidated through interleaved replay into the distributed neocortical system."
As shown in Figure 42, "the flow of information to be encoded in the hippocampus culminates in the activation of neurons in areas CA3 and CA1, and memory encoding amounts to strengthening the associations between active neurons in these areas. Memory retrieval occurs when a cue triggers completion of the original CA3 activity pattern (i.e., pattern completion), which in turn drives CA1 (via the strengthened associations), and results in a cascade of activation that reactivates the original activity patterns throughout cortex.
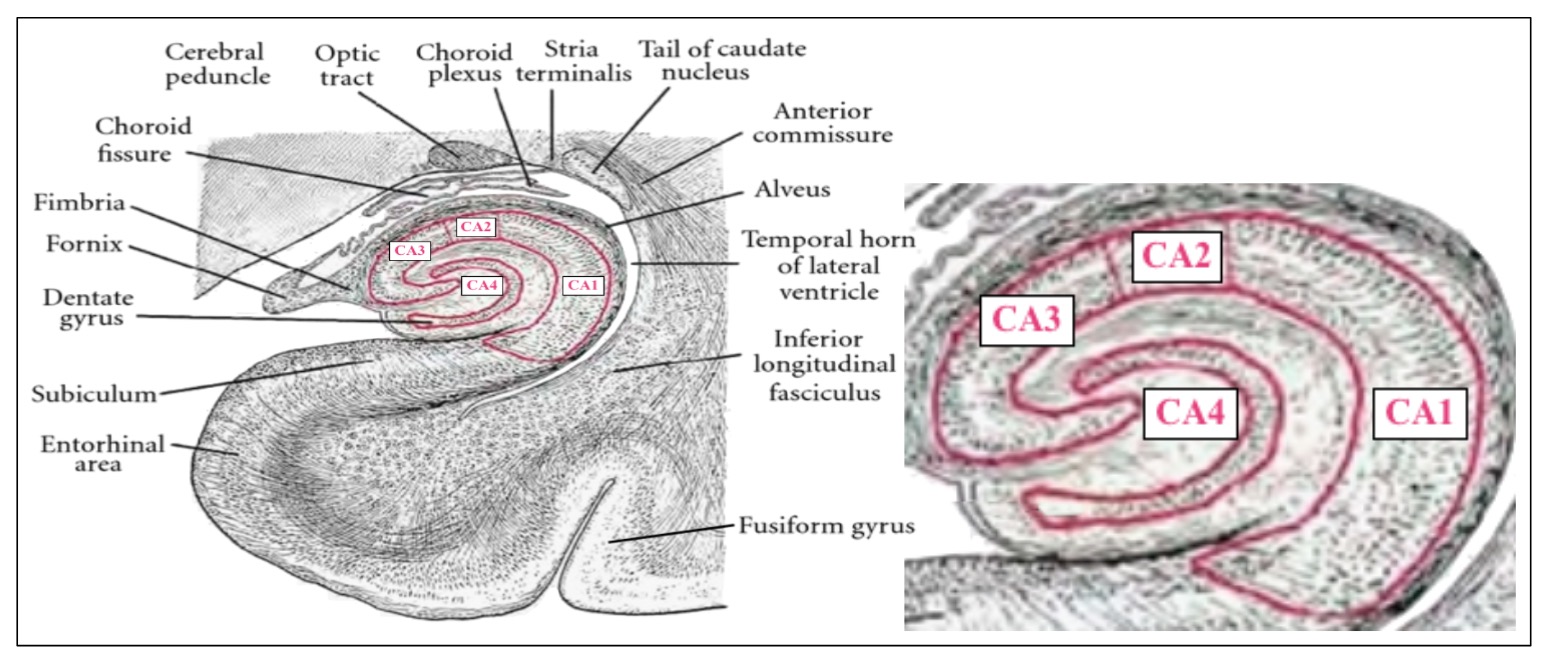 |
The system avoids interference from new learning by the process of pattern separation, due especially to the [dentate gyrus] DG. Because the DG has very sparse levels of activity (few neurons active at any given time), it provides an exceptional degree of pattern separation to encode new information while avoiding interference with existing memories. [...] The above account provides a clear unique role for every area in the system, except for area CA1 — what is the unique role of CA1?"
"In the original CLS work [...], we theorized that CA1 is critical for developing a sparse, invertible mapping. This means that activity patterns produced by incoming cortical activity during encoding are capable of re-creating those same cortical activity patterns during retrieval. The critical point that many researchers fail to appreciate about this function of the CA1 is that without it, the problem of catastrophic interference would remain, regardless of how effective the pattern separation is within the CA3.
To see why, consider what would happen if CA3 projected directly back into EC. Because the CA3 pattern is highly pattern separated and thus unrelated to anything else the system has seen before, the EC neurons would need to rapidly learn to associate this novel CA3 pattern with the current activity pattern, reflecting the cortical inputs. However, because the EC has high levels of overall activity, the same EC neurons are involved in a large number of different memories.
Thus, when a new memory is encoded, the synaptic changes required to learn the associated novel CA3 pattern would have a reasonable chance of interfering with a previously encoded memory. In contrast, because the CA1 has a relatively sparse level of activity, its neurons participate in comparatively fewer overall memories, and thus engender significantly less interference.
Although the CA1 invertible mapping may seem like a relatively trivial function, it turns out that this kind of mapping actually takes significant amounts of learning to develop, especially to establish a representational system that can apply to novel input patterns. Meeting this challenge requires a combinatorial or componential code, where novel input patterns can be represented as a recombination of existing representational elements."
March 9, 2018
%%% Fri Mar 9 05:19:40 PST 2018
The programmer's apprentice application is intended to exercise several of the different types of human memory and computing that we know of. Memory and computation are collocated for the most part in the human brain. This is in contrast to conventionally-engineered computing hardware that, for the most part, decouple the two requiring that data and programs in memory are shuffled back and forth between large-scale random access memory and one-or-more centralized processing units.
Humans are adept at recognizing patterns, learning by watching, generalizing from a few examples, recognizing novel threats and opportunities, sharing knowledge, collaborating, planning, socializing, etc. We also have some instincts that have outlived their evolutionary usefulness, but that's for another time or another class.
We have substantial brain tissue devoted to language production and understanding that facilitate our many social activities, and a prodigious episodic memory enabling us to draw upon past experience to plan for the future. Though not our forte, we can juggle multiple concepts at once to create novel composites — seven plus or minus two or so we are still told in many introductory psychology courses.
When you are engineering a modern neural network memory, you have to consider carefully how you want to use the knowledge represented in the corresponding artificial neural network. What sort of inherent structure does the knowledge have and how specifically is it implemented in the network architecture so it can exploit that structure to serve your purposes.
Does it have a spatial or temporal dimension that is important in making use of that knowledge? If the knowledge is to be represented as an embedding (vector) space, are there dimensions that encode specific features and is it important that other parts of the network are able to make use of or adapt those features for other purposes?
In the process of embedding a given structure, is it important to retain the original entity, e.g., a word or phrase, so as to subsequently make use of the entity in picking a word or phrase when, say, generating an utterance in a dialogue. Note that this represents somewhat of a departure from the purists dream of a fully differentiable model trained end-to-end using stochastic gradient descent.
If the knowledge involves space or time, will it be necessary to compare or compose the corresponding entities by employing spatial or temporal relationships, and, if so, how will these comparisons and compositions be accomplished? In general, how do you intend to address the entities in your spatial or temporal data. For example, you might initially address by content but, then search nearby content — in time or space.
If the knowledge takes the form of an associative or content-addressable memory encoding attribute-value pairs, is the mapping one-to-one, does it change over time after initial training and, if so, how often and how quickly? How does attention work and, in particular, how do we manage to keep several items in mind when working on a complex problem. What about tasks like calculating sums or performing algebra in your head?
March 7, 2018
%%% Wed Mar 7 03:08:26 PST 2018
The terminology for discussing different parts of the brain can be confusing. The terminology consisting of posterior (back), anterior (front), superior (top) and inferior (bottom) is the simplest, least ambiguous (gross) anatomical nomenclature. With respect to the pose of an animal that is normally aligned horizontally, you will encounter rostral (head — toward the snout) versus caudal (tail — toward the tail) and dorsal (back — toward the sky) versus ventral (beak — toward the ground). However the latter terminology becomes complicated when you consider upright animals like humans who are normally aligned vertically. In this case, there is a ninety degree change in viewpoint that relates to the location of the midbrain that is confusing to relate in prose but easy to understand when presented graphically as done here. Whenever possible, we'll employ the first option: anterior, posterior, superior and inferior.
Interneurons, especially those found in layers II-III and V-VI in primary sensory cortex, are subject to transient effects that come and go, often at active developmental stages, that have a permanent effect on the nervous system — see this video on research from Gord Fisher's lab at NYU. I point this out as a forward pointer to my introductory lectures in class as they relate to our lack of detailed knowledge about the arborization, cell-type, distribution and pattern of connections in the human sensory cortex, despite Ramòn y Cajal's observations and suggestions about there possibly being a distinguishing feature of the human brain. As an anatomist, Cajal thought it important to do comparative studies involving the brains of different species at different stages in their development. As in so many other aspects, Cajal was well ahead of his time.
Spindle neurons, also called von Economo neurons (VENs), are a specific class of neurons that are characterized by a large spindle-shaped soma (or body), gradually tapering into a single apical axon in one direction, with only a single dendrite facing opposite. Other neurons tend to have many dendrites, and the polar-shaped morphology of spindle neurons is unique. A neuron's dendrites receive signals, and its axon sends them. Their dense jungle of dendrites is controlled by a family of genes that are uniquely mutated in humans. The list includes FoxP255, the famous gene with two mutations specific to the Homo lineage, which modulates our language networks, and whose disruption creates a massive impairment in articulation and speech. The FoxP2 family includes several genes responsible for building neurons, dendrites, axons, and synapses. In an amazing feat of genomic technology, scientists created mutant mice carrying the two human FoxP2 mutations — and sure enough, they grew pyramidal neurons with much larger, humanlike dendrites and a greater facility to learn (although they still didn’t speak).
Pathways linking the cortex with the thalamus are especially important. The thalamus is a collection of nuclei, each of which enters into a tight loop with at least one region of the cortex and often many of them at once. Virtually all regions of the cortex that are directly interconnected also share information via a parallel information route through a deep thalamic relay. Inputs from the thalamus to the cortex also play a fundamental role in exciting the cortex and maintaining it in an "up" state of sustained activity. As we shall see, the reduced activity of the thalamus and its interconnections play a key role in coma and vegetative states, when the brain loses its mind.
March 5, 2018
%%% Mon Mar 5 04:27:56 PST 2018
Last week in talking with Jeremy Maitin-Shepard about programming tools for semantic analysis, I mentioned lint for static code analysis and Jeremy indicated that there are industrial-strength versions — substantial extensions of the original Unix tool that are generally proprietary, but that it is the advanced compiler tools that are the first line of defense against semantic bugs. In the process of instrumenting the IDE, it might be worth taking a look at tools that analyze compiler output to simplify finding type-inference and related semantic problems. Jeremy also mentioned Cling which is an interactive C++ interpreter56 that comes with a Jupyter kernel.
February 27, 2018
%%% Thu Feb 27 4:01:38 PST 2018
If you've used Oriol Vinyals' pointer networks [454] or any of the more recent variants, you might want to check out Stephen Merity's work [308] on pointer-sentinel mixture models for improved softmax classifiers used in RNN sequence models focusing on NLP applications. I came across this when reading a DeepMind ICML paper by Pritzel et al [358] on managing large episodic memory in the context of reinforcement learning. Pritzel et al claims to provide a deep reinforcement learning agent that is able to rapidly assimilate new experiences and act upon them. While potentially useful for improving training in DQN agents embedded in complex environments, their analysis and proposed solutions are instructive in thinking non-stationary systems and life-long learning.
February 25, 2018
%%% Fri Feb 25 04:36:25PST 2018
In the previous entry, we just started discussing the Rabinowitz et al [361] machine-theory-of-mind neural network model, introducing the three component network modules reproduced in Figure 41. In this entry, we explore how we might adapt the approach of Rabinowitz et al [361] to the programmer's apprentice (PA) problem. The simulated environments used in the experiments [361] are gridworlds each with a particular arrangement of walls and objects; different agents, when placed in the same environment, might receive different rewards for reaching these objects, and be able to see different amounts of their local surroundings. We might think of these as different programming challenges.
The PA agent's mental state represents various propositions that may or may not be true of a given program or fragment and may be correctly or incorrectly inferred by the agent, i.e., the PA agent can have false beliefs about a program. Since we are interested in a model of collaborative or pair programming, there are, in fact, at least two agents whose mental state we might want to track, the programmer and the assistant. There are a number of different kinds of propositions we might choose to keep track of, but in this entry we focus on program invariants which are conditions that can be relied upon to be true during execution of a program. An example is a loop invariant that is true at the beginning and end of every execution of a loop.
In automated program verification, programming invariants are expressed as statements in predicate logic. Given a target program it is possible in principle to perform automatic detection of such invariant statements. Assertions are one way in which programmers can make invariants explicit in their code, though it is seldom true that one can state unequivocally that a program is correct if all its assertions are satisfied. Practically speaking, the programmer's apprentice application will likely have to resort to an even weaker alternative. The apprentice might ask if the programmer knows that the last substitution probably violated loop invariants relating to variable scope.
There are two issues that arise with regard to the mental states of the programmer and the assistant. While an agent's mental state may conceivably consist of a collection of propositions, they will be expressed in natural language and therefore likely to be ambiguous and perhaps incomprehensible as formal logic. In addition, there are an indefinite, perhaps infinite number of such statements. Any comprehensive symbolic representation is likely to be impractical to write down and intractable to maintain as new statements are added to the representation and the result checked for validity. From a practical standpoint, it makes sense to represent mental states as embeddings, mental-state representations that serve as flexible encodings incorporating diverse knowledge of programming that can be easily altered in order to make predictions about how agents might behave. We sacrifice precision and consistency but such goals were never realistic in light of the inherent intractability.
Complementary learning systems are intended to play just such a role in neural architectures. Jay McClelland is an expert on the subject and I invited him to lead a discussion in class. He agreed and will join us on Thursday, April 19 (HTML). Titles and abstracts for papers directly relating to complementary learning systems [263, 335, 264], and somewhat peripherally-related neural-network models designed to adapt their weights at different rates [18, 457, 456, 494, 457] or optimized to deal with nonstationary environments [352, 380, 489, 488, 413] are listed in the footnote here57 . Also of some interest — if not directly relevant to the current topic, is this recent review [187] of convolutional neural network applications and techniques.
February 23, 2018
%%% Fri Feb 23 05:58:33 PST 2018
Rabinowitz et al [361] present a novel neural network architecture designed to learn Theory of Mind (ToM) models of different agents that operate in simulated environments. The architecture — dubbed ToMnet — consists of three component modules: a so-called character network that represents or characterizes the different agents that the system encounters, a mental-state network that encodes its current mental state, and a prediction network used to make predictions about what a given agent knows in a particular state — see Figure 41.
| |
| Figure 41: The character network parses an agent's past trajectories from a set of POMDPs to form a character embedding, echar. The mental-state network parses the agent's trajectory on the current episode, to form an embedding of its mental state, emental. These embeddings are fed into the prediction network, which is then queried with a current state. This produces predictions about future behaviour, such as next-step action probabilities, probabilities of whether certain objects will be consumed and predicted successor representations Dayan [86]. — from [361]. | |
|
|

ToMnet works with episode trajectories that correspond to an agent interacting in a simulated environment for some number of steps. The character network provides an embedding of all the previously observed episode trajectories. In principle, one could create a cumulative embedding vector for each individual agent. Alternatively, one could use the character network to create composites that the authors refer to as species of agents. The idea that every agent is a composite of the characteristics of multiple agents seems both realistic and expedient for an assistant.
The prediction network is the most complicated of the three networks, but the supplementary materials in the paper provide descriptions of networks and related loss functions. The experimental sections focus on three predictions: next-step action, identification of which objects are consumed by the end of the episode, and successor representations. In a subsequent entry, we'll consider the application of ToMnets to the programmer's apprentice problem.
Neil Rabinowitz pointed me to this quote from Cohen et al [75] that underscores the importance of theory-of-mind reasoning in terms of the expectations of users interacting with automated question-answering systems:
We will demonstrate, using protocols of actual interactions with a question-answering system, that users of these systems expect more than just answers to isolated questions. They expect to engage in a conversation whose coherence is manifested in the interdependence of their often unstated plans and goals with those of the system. They also expect the system to be able to incorporate its own responses into analyses of their subsequent utterances. Moreover, they maintain these expectations even in the face of strong evidence that the system is not a competent conversationalist.
February 15, 2018
%%% Thu Feb 15 4:35:56 PST 2018
My earlier notes concerning the roles of mycroglia in the developing brain are available here. I'm reviewing related lectures from the Broad Institute, Simons Foundation and YouTube, featuring Ben Barres, Stanford; Staci Bilbo, Harvard; Tobias Bonhoeffer, Max Planck Institute; Carla Shatz, Stanford; Beth Stevens, Harvard; Richard Ransohoff, Biogen. I'll post my recommendations here once I have a chance to look more thoroughly.
February 13, 2018
%%% Tues Feb 13 03:38:59 PST 2018
Humans have lifted themselves by leveraging their innate evolved capabilities to construct a social and technological edifice that enables us to create tools that circumvent our intellectual shortcomings and to produce knowledge of lasting value that survives beyond our short lifespans. It is interesting to think about how we might develop artificially intelligent systems that embody the same characteristcs that have served us so well.
Our basic understanding of the structure and extent of human intelligence came into being during enlightenment58 . It is only in the last few decades we have refined our understanding such that we can even contemplate attempting to engineer systems that test our understanding. We've talked about the basic components of human cognition in these pages. Here we attempt to place those components within their biological and historical context.
Beginning at the periphery, the primary sensory cortex supports attention to change and saliency across all modalities. This sensitivity extends to all abstractions and compositions of multiple modaliaties. Our innate pattern recognition capabilities leverage this sensitivity across all spatial and temporal scales, sensory modalities and their abstractions. Modern machine learning has demonstrated that such capabilities can be automated.
Human memory represents a remarkable evolutionary innovation. Our creative reconstruction of experience, while undermining our ability to provide accurate first-hand accounts of accidents and other past events, is ideally suited to imagining novel variations of familiar situations, learning to make predictions and plan for the future. A complete understanding of this facility still eludes us, but we have clues to guide implementation.
Human language allows us share just about any form of knowledge, mathematics enables us to construct sound models and theories and draw conclusions that are valid assuming the validity of our axioms and rules of inference, and logic allows us to construct programs that run on human minds. All of these innovations are built upon the foundation of our innate observational and pattern recognition capabilities. None are completely understood.
That said, language is key to all of these advanced capabilities. It is hard to overstate its importance. I am smart because of what I know. This is analogous to saying that my computer is capable because of the programs I've installed on it. I can observe and emulate the strategies of the people around me. Their actions in solving problems are like programs I can run because I have the same hardware and operating system. Other people can just tell me how they solve problems and that is enough that I can apply their solutions to solving my own similar problems.
For thousands of years human beings have been sharing their programs, improving them and adapting them to solving new problems. Much of that knowledge has been written down and preserved in books we can now read so as to avail ourselves of what others have learned and adapt their solutions to the problems of our age. During that same period, our language has evolved and become more expressive allowing us to extend and generalize what we have learned so it is relevant to solving an ever broadening class of problems. We can still run programs we find in books hundreds of years old.
In addition to language becoming more expressive, human beings have formalized the logic inherent in human discourse and problem-solving and codified the operations required to draw correct conclusions from knowledge we already have, thereby providing us with a reliable technology for inferring new knowledge and new programs that run on our innate computing hardware. In the last hundred years, we have created technology that implements such logic and the operations that create new knowledge from existing knowledge, and improved that technology so that it runs several orders of magnitude faster than biological computers.
Human computers are powerful, technically universal in the Church-Turing sense of being able to compute any computable function. But the underlying biological machinery is slow and optimized for solving a class of problems conducive to our survival on this planet during a particular evolutionary era. So why do we want build assistants modeled after the human brain? The answer is that human pattern recognition, facility with language, ability to operate in complex conceptual spaces that combine information from many sources, interact easily with other humans and integrate all of these capabilities in a single package is unsurpassed.
February 11, 2018
%%% Sun Feb 11 04:47:59 PST 2018
For students taking CS379C for credit or wanting to follow along, the introductory lecture, organized into four installments, is now available starting here. You can also find a commentary on the computational and immunological roles of microglia in developing and mature brains, included here as a lesson in the dangers of accepting prevailing dogma.
Part 4 of the introductory lecture provides a high-level description of the different components you will be working with in designing neural network architectures for class projects and you can find a collection of tutorials on implementing artificial neural networks related to these components here if you want to get a head start on your project.
February 9, 2018
%%% Fri Feb 9 05:11:48 PST 2018
I am fascinated with how artists, engineers, musicians and scientists think about their craft. This weekend my wife Jo and I watched The Art of the Piano: Great Pianists of the 20th Century, a documentary film — available on YouTube here — directed by Donald Sturrock and starring the musicians as themselves. The film features rare footage of concerts and interviews with Sergei Rachmaninoff, Arthur Rubinstein, Sviatoslav Richter, Vladimir Horowitz and Glenn Gould, among others. It also includes commentary and analysis by Daniel Barenboim and other musicians of comparable breadth and artistry.
I was particularly fascinated with Alfred Cortot (1877-1962). He was introduced as one of the most individual and also most unreliable of the early recording pianists. The bit about unreliability caught my attention. Cortot was first mentioned at 52:30 in the YouTube video showing a photo of him as a young man. Like many of his generation, World War II had a profound impact on his career and professional circumstances, and later in life he suffered from memory lapses that curtailed his public concerts and forced him into what was for musicians at the time an early retirement.
Despite these setback, Cortot went on to become a great teacher and interpreter of musical scores. Daniel Barenboim said of Cortot that "he always looked for anything extraordinary in the music ... something totally removed from reality", and the sequence starting at 56:15 where he performs as if completely entranced by the music while working with his students demonstrates both his other worldliness and his gifts as a teacher. One of his students Samson Francois was so interested in jazz and movies that they stimulated in his playing a remarkable sense of freedom and improvisation that one seldom hears in contemporary pianists, Glenn Gould being an exception.
You're probably wondering what any of this has to do with the topic of the CS379C this year. The answer is that it has a lot to do with the programmer's apprentice project described in these pages, a project that combines requirements from two of the three challenge problems. I'm constantly thinking about how software engineers design and build complicated programs, and both Jo and I work in areas that require creativity and the ability to manipulate complex representations in our heads. Jo is an artist specializing in abstract landscapes while I write computer programs and design computing architectures inspired by biology.
One question that interests me has to do with how humans assemble and work with complex cognitive artifacts like computer programs and musical compositions. How do they maintain and manipulate these structures in their heads? One possibility is that these artifacts share a great deal of structure. I'm particularly interested in the sonata form that developed in the middle of the 18th century and is perhaps best known now through the works of Haydn, Mozart and Beethoven, all three of whom produced some of their best work in this form and contributed to its development.
The sonata form provides a general architecture, but there are multiple levels of structure evident in the work of these composers each of whom had a different style of composition. The sonata form is a musical structure consisting of three sections: an exposition, a development, and a recapitulation. At the lowest level, lengthy sequences of notes in works by Mozart and Beethoven are generated through default patterns of pitches: arpeggios, scale passages, chords and the like. They also operated within a tonal system providing additional structure, predating Arnold Schoenberg's radical 12-tone departure from the conventional 6-pitch tonal system.
As an exercise, think about the structure of computer programs at different levels of abstraction from libraries, modules, object classes, algorithms, e.g., Donald Knuth's division into fundamental, seminumerical, sorting and searching and combinatorial, and programming paradigms, e.g., imperative, procedural, declarative, functional, object-oriented, event-driven programming. If you want to learn more about the structure of sonatas, check out Exploring Beethoven’s Piano Sonatas Parts I-III, a series of courses taught by Jonathan Biss of the Curtis Institute of Music available on Coursera.
February 8, 2018
%%% Thu Feb 8 04:29:23 PST 2018
At the periphery, sensory information often has local structure providing a basis for inferring relatively low-level features that can be used to recover complex objects from their context. Convolutional neural network (CNN) models enable us to infer such low-level features and generate feature maps that can be recursively analyzed to produce composite features, culminating in detailed hierarchical models of complex objects. In general, CNN models can be applied to structured data including sequences, images, acoustic time series, and diverse other spatially and temporally organized data. CNN models have been successfully deployed to learn useful representations of images, documents and graphs.
Much of what we see and hear derives its meaning from the context in which we observe it. In a grainy picture of a farmyard, a blurry pinkish blob might be identified as a pig and a vertical splash of blue as a farmer's jeans. The words "dog" and "cat" refer to different animals, but they often appear in the same contexts, e.g., house pets in the case of "He put the { cat, dog } out for the night". Embedding space models learn to infer the meaning of entities by the company they keep, e.g., language models represent words and their relative meanings derived from their context, defined by a fixed-width window of words immediately preceding and following the target word in a specified document.
Recurrent neural network (RNN) models and, in particular, gated-feedback recurrent networks [73] and long short-term memory networks [218] maintain state from one input to the next by feeding the output of units in one layer as input to units in other layers that appear earlier in a stack of layers that would otherwise be described as feedforward. RNN models are used in applications such as parsing that benefit from remembering some part of their history to employ that information at a subsequent point in time. The recurrent state is viewed as short-term memory, but has a general intepretation given the equivalent interpretation of RNN's as differential equations61.
RNN encoder-decoder models [423, 71] consist of two networks, one network called the encoder that ingests the input sequence, e.g., a sentence in one language, constructing a representation of the input which serves as input to a second network called the decoder that uses the representation to generate an output sequence, e.g., a translation of the sentence in a second language. These models were originally applied in natural language processing and machine translation, but have been extended to a wide range of applications from image and video captioning to code generation and protein function prediction.
So-called attentional neural networks learn to select specific input in order to facilitate context-sensitive changes. They really aren't so-much a distinct class of neural networks as a strategy that can be applied to implement a variety of capabilities ranging from visual attention and saccadic eye movement to more exotic cognitive capabilities such as those associated with autonoetic consciousness62, executive function64, episodic memory and attentional schemata in reasoning about other minds. We will demystify the latter capabilities the process of investigating the three applications mentioned in the syllabus.
The human brain stores information at different time scales. The stability of stored information varies considerably depending on its use. Strictly speaking, the word "store" is misleading here, since all we really do is encode information in the patterns of activity of neurons and then apply different strategies for maintaining the integrity of that information, altering it to suit various purposes that range from imagining the future by extrapolating from the present to constructing composite representations that combine information from multiple sources to create novel thoughts.
The global workspace theory posits a model of working memory that enables such future imagining and constructive engineering. To implement such a workspace, we use a form of persistent memory applying the notion of fast weights [215] — also called dynamic links [456] — to manage a working memory in which information can be added, modified and removed, that supports associative retrieval and is implemented as a fully differentiable model and so can be trained end-to-end. Fast weights are used to store temporary memories of the recent past and provide a neurally plausible method of implementing the type of attention to the past that has recently proved helpful in sequence-to-sequence models [18].
February 7, 2018
%%% Wed Feb 7 03:39:41 PST 2018
Next we consider artificial neural networks as components to be used in designing neural-network architectures. In the field of connectomics, sub networks of biological networks that appear repeatedly or at multiple scales are often referred to in the literature as network motifs and serve a similar epistemological role in computational neuroscience [98, 122, 207, 223, 412, 312]. Whether they are derived from artificial or biological networks, network motifs can also be applied to learning artificial neural network architectures [344, 497, 498].
Using an analogy drawn from computer architecture, network motifs are not discrete components like transistors and diodes or small integrated circuits like individual flip-flops or logic gates. At the other end of the scale, they aren’t complex integrated circuits like central processing units or GPU devices. They are more like multiplexers, demultiplexers, full adders, shift registers and serial interfaces. From the perspective of computational neuroscience, information is distributed across large numbers of neurons and representations are encoded in the activity of ensembles of then neurons. Artificial neural networks reduce complex biological processes to a special case of vector calculus and differential geometry.
The artificial neural network motifs we focus on in this class operate on arbitrary finite-dimension vectors, often performing the same operation on each vector component or computing complex vector or matrix products, creating and transforming vector spaces in the process. They employ activation functions that truncate the output of linear transformations using rectified linear units, squash scalar values with sigmoidal functions, and pool values to reduce dimensionality by local averaging and convolving with linear filters. In short, the network motifs that comprise our library of architectural components are powerful computing machines inspired by biology and designed by engineers to serve particular engineering goals.
If these engineered networks are only tenuously related to their putative biological counterparts, why should we imagine we will be able to employ them to leverage functional models derived from cognitive and systems neuroscience to design systems that exhibit desirable characteristics of biological systems? The short technical — and perhaps intellectually unsatisfying from your standpoint — answer is fully-differentiable mathematical models and end-to-end training with stochastic gradient descent. If you want a more satisfying argument from first principles, the best I can do is direct you to Chapter 3 of Parallel Distributed Processing by Hinton, McClelland and Rumelhart [214].
If you believe that we have a rock-solid, cellular-resolution theoretical foundation on which to rest our understanding of behavior, you might want to learn about how our current foundations are being challenged by new discoveries about the role of microglia. If you expect an argument that draws on careful experiments comparing primate and computer neural-network models of visual processing, then you're in luck, but will have to wait a few weeks until we look at the work of Charles Cadieu, Jim DiCarlo, Dan Yamins and their colleagues [229, 483, 59, 485, 484].
Jump to Introductory Lecture Part 4
February 6, 2018
%%% Tue Feb 6 06:29:43 PST 2018
In the following, we are going to concentrate on the central nervous system. The brain receives its input from the periphery originating in receptors that respond to light, smell, pressure, sound and movement. Most of that information enters the CNS through the primary sensory areas via networks organized in topographical maps reflecting the spatial pattern of the corresponding receptors. That information is processed in multiple areas and through specialized paths that code for the spatial and temporal properties of the input at increasing levels of abstraction. The resulting models are both hierarchical and compositional65.
As you move away from the periphery, not only do the properties reflected become more abstract but they are also combined to more fully summarize the full breadth of our experience. The resulting composite features are represented in what are called association areas that play an important role in pattern matching allowing us to recall similar experiences based on abstractions constructed from learning-selected subsets of more concrete sensory features. In addition to sensory information, we employ other features of our experience including, for example, features that code for different aspects of our physiological / emotional response to a given situation.
| |
| Figure 40: Panel A lists the regions of the human cerebral cortex including the relevant Brodman areas [REF]. Panel B illustrates some of the pathways involving language including Broca's area considered responsible for production [REF] and Wernicke's area [REF] implicated in comprehension. Panel C displays a sample of Brodman's areas as landmarks, highlighting areas 28 and 34 in the temporal lobe associated with the enterorhinal cortex [REF]. Panel D identifies a number of cortical and subcortical areas associated with the entorhinal cortex and episodic memory in particular [REF]. | |
|
|
We have focused on the human neocortex but other sources of input originating from subcortical regions also play important roles. Panel D in Figure 40 shows the enterorhinal cortex located in the medial temporal lobe that functions as the hub of an extensive network for memory and navigation and serves as the primary interface between the hippocampus and neocortex. The enterorhinal cortex (EC) also plays an important role in facilitating episodic memory in autonoetic consciousness. The EC is a good example of how evolutionarily ancient parts of the brain are integrated with relatively new regions.
The limbic system is a standard — but somewhat misleading — term for the emotional center of the brain in part because it includes the amygdala but the term is seldom employed these days since the designated area is home to a wider array of functions — see Chapter 9 from Swensen [426]. The hypothalamus is the primary output for the limbic system receiving input from all over the brain in addition to homeostatic sensors that measure temperature and glucose concentrations. The hypothalamus influences behavior and emotional reactions plus autonomic and endocrine functions controlled via projections to the brain stem and spinal cord.
The limbic system also encompasses the amygdala and hippocampus. The former is important in coordinating behavior and mediating the autonomic and endocrine responses to environmental stimuli, especially those with emotional content. The hippocampus is an ancient part of the brain active in both encoding and decoding memories, and important in learning new surroundings and retrieving directions. The limbic system connects to several neocortical areas including the prefrontal and orbital frontal regions that are critical for judgment, motivation abstract reasoning and problem solving.
With the exception of the endocrine system and related pituitary gland, we have focused on the input side of how the brain functions. The output side spans a wide range of functions, but we concern ourselves almost exclusively with those relating to the somatic nervous system and the voluntary control of body movement via skeletal muscles including speech. In particular, we ignore the stomatogastric nervous system and enteric nervous system that control the muscles of the gastrointestinal tract thereby facilitating feeding and digestion — not among our target applications.
Our understanding of the functional architecture of human frontal cortex is largely due to the sort of fMRI studies we discussed earlier. We can’t study human brains in the same way we study the brains of non-human organisms, but we can probe human subjects by asking them to look at images and solve problems while observing them in an fMRI scanner, and then asking them to report on what they saw or how they went about solving the problems. This is unsatisfactory for many scientists interested in neural circuitry, but it provides tantalizing hints about how we might design AI systems.
Jump to Introductory Lecture Part 3
February 5, 2018
%%% Mon Feb 5 04:23:53 PST 2018
I am going to begin with a short anatomy lesson focusing on the cerebral cortex which, in the mammalian brain, includes the neocortex. Infatuated as we are with our much-vaunted [165] cortex and, in particular, the advanced capabilities provided by our neocortex66, it is worth pointing out that we also have a cerebellar cortex or cerebellum which is primarily known for its role in motor control, but in fact coevolved along with the neocortex to support a number of advanced cognitive strategies.
Despite our spending time on gross anatomy, we are primarily interested in how different cognitive capabilities that we refer to as cognitive functions depend upon one another. However, some of the most interesting theories concerning human cognitive functions in general and their dependencies in particular come from fMRI studies in which subjects are given a task to perform and researchers try to determine which areas of the brain contribute to performing that task by estimating where in the brain energy is being consumed, presumably in service to performing computations necessary to carry out the given task.
Compared to our work using electron micrographs to trace the axons and dendrites of individual neurons at a resolution of approximately ten nanometers, functional MRI studies depend on data with a spatial resolution measured in millimeters. In the case of human studies of cognitive function, MRI is currently the best method we have for understanding behavior. In addition to providing potentially useful information for understanding where computations are being performed in the brain, we can also use a technology called diffusion tensor imaging or DTI to estimate which regions of the brain are connected to one another and in what direction information appears to be flowing.
Ignoring the details, we will suppose that we have a graph in which the nodes of the graph correspond to regions of the brain and the edges to bundles of myelinated axons that connect those regions. We will suppose further that we can make reasonable guesses about how information passes along those axons in carrying out tasks that involve the orchestration of multiple regions each one performing different computations contributing to the observed behavior.
This process of testing subjects while performing tasks in an fMRI machine and then trying to infer what is going on in their brains is, as you might guess, subject to error, but it is the best tool we have at this time and cognitive neuroscientists have made good use of it to unravel some of the puzzles relating to human cognition. Our task however is not to construct a theory of how humans solve problems, but rather to use the knowledge that cognitive scientists have assembled as clues in building systems that attempt to perform some of the same tasks that humans excel and so far machines fall short.
Paradoxically, while it might seem reasonable to engineer such systems using the symbolic methods of traditional artificial intelligence, instead we assume that the functional regions of the brain operate on distributed representations of the sort employed in building artificial neural networks and that these functional regions can be thought of as implementing functional components that communicate with one another by sharing such distributed representations.
This approach is not new by any means but the last decade has seen the invention or rediscovery of specialized neural network architectures that excel at specific tasks and that can be combined to solve even more complicated tasks. In this class, we investigate just how far we can go in emulating some of the most complicated and controversial functions that humans are capable of. Our goal is to solve some basic technical problems that limit what machines can do on their own and how they interact with humans, so that we can work collaboratively to solve problems that neither humans nor current artificial intelligence systems can solve on their own.
This might seem incredibly ambitious for a one-quarter project-oriented computer science class. While I admit the goals are ambitious, I believe it is exactly the kind of class experience that will provide students with the tools and confidence to take on such problems in the next stage of their education whether that be in graduate school, a new start up or a software engineering job in an industrial research lab. Incremental research problems are like $20 bills lying on the street waiting for someone to pick them up. Ambitious but timely research problems are like thousand dollar bills fluttering at the top of tall trees. They require some careful negotiation, but for the time being there won't be many climbers rushing for the trees.
Jump to Introductory Lecture Part 2
February 4, 2018
%%% Sun Feb 4 05:31:45 PST 2018
Science is a human endeavor and so scientific research is initiated, expedited and impeded by human motivations. Recent news concerning capital investments in biotechnology prompted me to think more deeply about some ideas relating to neuroscience that I've been working on for a couple of years now with my collaborator David Mayfield67. Here is an elevator-pitch-style dramatization intended to highlight the situation prompting my attention:
What if everything we think we know about the brain as a network computing device is wrong or at least missing one of the most important clues regarding how we learn and perform reliable computations with unreliable components?
What if we are blind to one of the most important factors required to understand and treat a broad spectrum of neurodegenerative diseases due to our misconceptions about how the brain computes and protects itself from pathogens?
What if many neuroscientists are ignorant or dismissive of the work and that by allowing such attitudes to persist we are wasting large amounts of money and intellectual capital working on models that are fundamentally flawed?
What if conventional life science VC firms and midsize biotechs are disinclined to invest in research68, preferring drugs that mitigate the severity of orphan diseases rather than curing dozens of maladies in millions of patients?
I believe the antecedents in the above statements are accurate. As a computational neuroscientist, the evidence is compelling. As a computer scientist, the computational model suggests fascinating algorithmic and architectural innovations69. There are likely multiple targets of opportunity depending on whether one is interested in developing drugs, inventing novel machine-learning hardware or establishing the basic scientific foundations. If you want to understand the science, check out this recent review articles [376], and read David's short but highly informative research notes included below:
Lessons learned since the rediscovery of microglia in 2005: Microglia are the brain's principal immuno-competent cells making up roughly 10-15 percent of the CNS cell population. Prior to 2005, they were thought to play a largely quiescent, passive role under physiological conditions. As the brain's resident phagocytic immune cells, they could certainly be called into action, but — it was thought — only in response to an immune challenge to the brain caused by infection, injury, or established disease. In 2005, however, this dogma was challenged. [...]
Discovering the active role of microglia in healthy brain: The human brain is composed of two computers rather than one — a neuron-based digital machine built to compute the relevance of experience strictly in terms of what it already knows, and a microglia-based analog machine built to teach the digital machine how to compute differently given novel experiences it can detect but not yet understand. What the digital machine knows is stored in the relative strengths of the 100 trillion synapses through which pre-synaptic neurons send signals to their shared post synaptic partner. [...]
Summarizing David's review, microglia serve two very different roles in the adult brain. In a healthy adult brain, they enable synaptic plasticity and play a key role in learning. However, in responding to neural damage, they abandon their constructive role in learning, undergo a major morphological transformation and revert to immunological functions programmed into the immature cells prior to entering their final home in the developing brain.
In the best case scenario, microglial cells don't confuse the different circumstances that warrant these two roles. In the worst case, normal neural activity is mistaken for abnormal, microglia mount a phagocytic response to imagined pathogens and compromised cells, neural processes are stripped of their dendritic structure and rendered unable to perform their normal computational functions.
Prior to discovering the dramatic evidence of this dual role in 2005, researchers were aware that exposure to an immune challenge early in life (perinatal) — before microglia have fully adopted the transcriptional profile that enables them to function behind the blood brain barrier as specialized brain cells rather than peripheral macrophage cells — is predictive of cognitive decline and memory impairment late in life and its time of onset.
Later it was found that an ill-timed immune challenge during this sensitive perinatal window, is also an essential predisposing risk factor for the major neuro-developmental diseases and disorders of youth ranging from autism in toddlers, attention-deficit / hyperactivity disorder in children and schizophrenia and mood and addiction disorders in adolescence and young adulthood.
Putting these observations together, scientists looked for and found the signatures of microglial phagocytic damage in the brains of young patients with neuro-developmental disease and older patients with neuro-degenerative disorders including Parkinson's and Alzheimer's diseases. This brief summary of more than a decade of work by scores of scientists doesn't do justice to the richness of the case for this disease model [80, 283, 356].
Given that it is difficult if not impossible to avoid an unfortunate immune challenge during the critical window, this would be sad news indeed to a parent with a child having such a history, or anyone witnessing the symptoms of neuro-degenerative disease in themselves or a loved one were it not for their being some promising treatment options that could potentially provide protection across a broad spectrum of disorders [42, 41].
It turns out that a class of anxiolytic drugs marketed in France for more than three decades as a non-sedating, non-addicting alternative to the benzodiazepines has been shown to be an effective microglial modulator relevant to neuro-developmental and neuro-degenerative disease. Analogs of the original drug called etifoxine or ETX has been shown to modulate microglia activation in response to numerous models of immune challenge. While there are challenges ahead in evaluating efficacy, this is a promising sign that some form of treatment could soon be available for those afflicted.
Lectures:
| [1] |
Professor Ben Barres77 (Stanford University Departments of Neurobiology and Developmental Biology) January 2017. Broad Institute Lecture.
Role of Microglia Activated A1 Phenotype Astrocytes in Neurodegenerative Diseases Ranging from AD to ALS, MS, and Retinal Degeneration. [VIDEO]
|
| [2] |
Professor Staci Bilbo (Harvard University Program in Neuroscience) June 2014.
Lecture to the Canadian Autism Society. The Immune System and Neural Development: Implications for Neurodevelopmental Disorders. [VIDEO]
|
| [3] |
Professor Beth Stevens (Harvard University Program in Immunology) November 2016. Simon Foundation Lecture. On New Science of Microglia Function in the Healthy Developing and Mature Brain and the Implications for Autism and Schizophrenia. [VIDEO]
|
References:
February 3, 2018
%%% Sat Feb 3 04:05:23 PST 2018
This entry is meant for prospective CS379C students in the 2018 Spring quarter at Stanford University. It was written to underscore the unique opportunities and challenges designed into the syllabus for this instantiation of CS379C. For many of you, there will not come another time in your careers to contemplate such an exciting and risky scientific venture. The experience will likely motivate you to adjust your attitude to risk in directing your professional lives. I guarantee it will be interesting and for some it will be a revelation. I'll start with some background and general motivation before launching into the specific challenges that serve as the central focus for the course this Spring.
Here are two observations that have influenced my current thinking about technology. The first comes from David Cheriton recounting what he said to Sergey Brin and Larry Page when they pitched their ideas to him in 200478 . Apparently they came to him asking about licensing their technology to other companies. Cheriton understood that if you give birth to a wonderful new idea you might think that someone would be happy to adopt your idea because you think it's so beautiful, but it's very hard to get anyone else to adopt your baby. He basically told Brin and Page they would have to raise their baby themselves.
The other observation comes from two decades in academia, another decade in industry and several shorter periods working in startups and consulting for venture capital firms. I used to think it odd that the businesses and institutions financially best situated to tackle problems that have the potential to create whole new categories of products and revolutionize entire industries are the least interested in doing so. Now it is clear to me that they don't have to take on the risk as long as they keep their eyes open and continue to grow their revenue so they can simply acquire the inventors and startups that are willing to take on those risks and succeed in beating the odds.
Noticing an interesting idea, incrementally extending a promising technology and building infrastructure to scale and broaden the application of that technology is not taking risk for a company that already has the talent, tools and technological wherewithal to exploit such an opportunity. It is smart and it is good business and it does little to tarnish the reputation of a technology company with a track record for advancing the state of the art, since it does in fact advance the state of the art, and, as part of broader strategy for encouraging innovation, can maintain a company's dominance of a given technology indefinitely.
But what if you love to work on ideas that seldom appear in engineering textbooks. That philosophers like to discuss and physicists tend to shun. What if you are good at thinking about technical problems that are two or three years beyond the current state of the art. What if you thrive in those murky intellectual spaces where one can catch tantalizing glimpses of what could be were it not for the current lack of substance and definition? For some, this is just the difference between alchemy in Isaac Newton's era and chemistry today. For others, these are the sort of temptations that drew Guglielmo Marconi to radio and Philo T. Farnsworth to television.
I'm interested in understanding the human mind and biological minds in general. I believe that consciousness, self-awareness, and reasoning about other minds all have simple algorithmic explanations despite the seeming complexity of their biological implementations. This is less controversial today than it was a decade ago, but there are skeptics and enough murkiness that engineers are reluctant to invest effort in developing such capabilities for the current generation of personal assistants. The situation is similar to that faced by Seymour Benzer when he revolutionized the field of behavioral genetics despite opposition from field's leading researchers [199, 183].
It is also an exiting time for me to be working in this area, both because I believe we are on the cusp of understanding the underlying phenomena due to advances in cognitive and systems neuroscience and because the field is relatively sparsely populated by scientists who have the necessary biological training and a command of computer science and the modern theory of artificial neural networks in particular. Seymour Benzer is famous for starting and legitimizing new fields of inquiry and then moving on when the field became crowded [475]. With each change he abandoned supportive colleagues and took on new challenges and skeptics. He probably couldn't help himself.
%%% Sat Feb 4 14:26:33 PST 2018
Here is the text advertising CS379C in Spring 2018. It was sent to Meredith Hutchin CS and Laura Hope MBC to distribute to students prior to February 11 when Axess opens for course enrollment:
In CS379C this quarter, we consider the following three challenge problems:
1. How would you design a personal assistant capable of maintaining relationships with each member of a family, managing a comprehensive episodic memory to enrich those relationships, adopting a different intentional stance appropriate for each household member and essentially behaving as another member of the family?
2. What if you had all of the C++ — or Java or Python — code checked into GitHub plus all the versions and all the diffs plus sample I/O, unit tests and documentation. How would you go about developing a neural network architecture that learns to write programs from sample I/O and natural language descriptions?
3. Suppose you had the complete wiring diagram (connectome) of a fly and petabytes of recordings from each neuron in the fly's brain aligned with high-speed images recording every aspect of the fly's behavior and the environment in which those behaviors were carried out. How would you construct a model of the fly's brain?
Hypothesis: Each of these problems can be solved using a recurrent neural network architecture constructed from published component networks each of which is relatively well understood and has been applied successfully to solving simpler problems.
Course description: In class, we examine this hypthesis by designing networks for key parts of each problem, borrowing ideas from both systems and cognitive neuroscience. Students propose and complete related programming projects for final grade.
February 1, 2018
%%% Thu Feb 1 04:59:20 PST 2018
Given that the programmer's apprentice is intended to be trainable end-to-end, it could require a great deal of training data. It is reasonable to ask if it is feasible to obtain this data entirely through interactions with a human programmer, and, if not, how one might bootstrap such a system without requiring it to learn in an interactive setting with a human user-in-the-loop. We don't have a completely satisfactory answer to this question at this stage, but I've included some preliminary suggestions in the following. The current design of the programmer's apprentice can be divided into the following (sub) systems:
a social modeling system consisting of an attentional schema and episodic memory [262].
an executive control system implemented as a hierarchical planner neural network [429].
an integrated development environment implemented as neural Turing machine memory [168].
a code embedding consisting of a hierarchy of contextual encoder-decoder models [252].
Systems 1 and 2 constitute a relatively sophisticated dialog management system (DMS). It should be reasonably easy79 to implement a hybrid DMS to pretrain the other two components. System 3 provides the three-way interface between the assistant, programmer and the means of editing, debugging, executing and tracing programs. System 4 serves as a proposal generator to facilitate programming by code substitution.
The hybrid DMS would correspond to a combination of a hand-coded conventional dialog system extending the earlier Zinn Google Play assistant with neural network interfaces to the System 3 IDE NTM and System 4 code embeddings. In principle System 4 can be trained separately along with a language model gleaned from Stack Exchange data and related corpora.
Conceptually System 1 is the most novel and intellectually exciting. It has the biggest potential to influence the design of Google Assistant. System 4 is the most challenging in terms of extending existing hierarchical approaches to contextualized structured-data embedding and associative retrieval. It has the biggest potential to apply broadly at Google.
The choice of programming language is complicated. If we could work the nascent SWERL Project we would have virtually unlimited C++ code and excellent coverage, but much of that code would be inscrutable and might make for terrible demos80. I've been talking with members of the PLT (Programming Language Theory) Group at Rice and Brown about collecting and curating a corpus of Scheme programs for training purposes and ingesting the text of How to Design Programs as part of the language model, but those discussions are preliminary.
January 31, 2018
%%% Sun Jan 28 15:20:11 PST 2018
Here are my thoughts about raising expectations for research, devising strategies to help engineers in pursuing about more ambitious projects, and making a case for how this might produce technologies with far reaching consequences. I wrote an outline for a relatively short statement in three installments:
What would it mean to break the mold, alter or enlarge the direction of the field and create technologies enabling whole new applications?
Where does the inspiration come from and how do we reliably harness it to come up with new ideas that will enable future innovation to happen?
How can we take the long view and tackle significantly challenging problems while at the same time delivering value and demonstrating progress?
Installment 1 is an account of the first ten years of my research career during which I constantly fought against the status quo. In hindsight this behavior might seem obvious, but at the time it was a dangerous path to tread for a non-tenured assistant professor. I don't emphasize the danger or the stress it put me through, but rather simply chronicle what I considered to be wrong with the field and what I did to put it on more solid foundations. If the story achieves what I intended, it won't come across as claiming to have had a clearer vision or bragging about my achievements.
Installment 2 makes the case that personal assistants are driving consumer technology and that the programmer's apprentice provides a vehicle for developing technologies that will have a huge impact on the future of consumer-facing applications. Specifically, applications that users can fluidly interact with for a wide range assistance and collaborate with to solve practical problems on intellectually equal terms. These are applications capable of understanding us on a deeper level by building models of us and creating episodic memories that record much more than just what we said.
Installment 3 uses the programmer's apprentice to illustrate how such a project could be broken down into technical subproblems tackled independently by separate teams, so that each subproblem would have its own trajectory, milestones and demonstrations, but separate teams would also have joint objectives and working subgroups to guide the integration of the component technologies toward project-wide milestones and demonstrations. The only difference between this and more conventional engineering efforts being the degree of uncertainty concerning the more open-ended parts of the problem. The resultant risks can be mitigated by building simple subsystems that provide limited capability or hybrid components that combine human and machine effort to simulate the desired behavior.
January 29, 2018
Here are some of the key design desiderata set for the proposed programmer's apprentice research project:
fully differentiable architecture constructed from standard network components and trained end-to-end;
capable of sustaining a constructive, indefinite-duration dialog focused on collaborative programming;
rich computer-human interaction, maintaining an extensive episodic memory spanning prior interactions;
automated code synthesis drawing on a large corpus of programs including descriptions and sample I/O;
fully instrumented development environment complemented by hierarchical distributed program embedding;
expectation network components will be familiar though their specific function and connectivity novel;
%%% Tue Jan 30 04:27:45 PST 2018
Here are three important management questions posed during my discussions with colleagues over the last few months:
How might a project such as the programmer's apprentice be broken down into technical subproblems tackled independently by separate teams?
The idea is to use the architecture of the human brain as a general framework in which to integrate modules supporting different functions. For this we need only the general pattern of how different regions of the brain exchange information and how their putative functions are related to one another. No attempt is made to model the microstructure of the human connectome, but rather to model the direction and valence — excitatory or inhibitory — of the connections, treating the anatomical boundaries of these regions and their functions as approximate at best and employing them as useful guidelines to support independent development and guide system-wide integration and evaluation.
How might the project be structured so each team has its own its own trajectory, milestones and demonstrations, but share joint objectives?
In spite of efforts to make sense of the brain as if it could be decomposed into functional modules arranged in neat block diagrams — such as those shown in Figure 38, with each block labeled with by a precise mathematical description realized as a transfer function with clearly defined inputs and outputs, evolved systems are messy and typically don't allow such simple descriptions. We start with well-defined functional components patterned after those believed to approximate those of the brain, exploit what is known about how these components are functionally related to one another and then depend on interface layers trained to sort out the details of how these components communicate.
How might independently working subgroups guide integration of the component technologies toward project-wide milestones and demonstrations?
The difference between this and conventional engineering efforts arises from uncertainty concerning the open-ended parts of the problem. The resultant risks can be mitigated by building simple subsystems that provide limited capability or hybrid subsystems that combine human and machine effort to simulate the desired end products. The primary functional components — dialog management, attentional schema, episodic memory, program embedding, proposal generation, etc — can be grouped into three subsystems roughly corresponding to the natural language interface, memory subsystem and code synthesizer, each of which can simulated by a combination of traditional programming and human intervention.
%%% Mon Jan 29 15:04:36 PST 2018
Sometimes it makes more sense to use the term imagination when talking about prediction, consciousness when talking about attention, episodic memory when talking about stack traces and event histories and association areas when talking about sensor fusion. The underlined terms are familiar to those of us working in computer vision whereas the italicized words smack of concepts from cognitive science and good-old-fashioned AI that have no precise computable interpretation — what Drew McDermott referred to as notation without denotation [307].
We use the italicized words instead of their underlined counterparts to describe capabilities important in designing agents that interact effectively with humans. We borrow from a growing literature that has made considerable progress in defining these concepts precisely enough to implement in working systems. Examples include Hassibis and Maguire's work on imagination as constructing hypothetical situations [201], Dehaene's model of consciousness as maintaining a global workspace [108], and Graziano's attention-schema model of self awareness and theory-of-mind reasoning [180].
What would it mean to build a limited capability episodic memory or attentional schema? The remainder of this entry provides capsule summaries of what we already understand and what we are prepared to move ahead on regarding five key problems: episodic memory, attention schema, theory of mind, dialog management and code synthesis. This document also includes more detailed examinations of these problems along with extensive bibliographical and summary information.
Human episodic memory (EM) is complex with diverse networks distributed all over brain. That said, there are a number of promising proposals [11] for implementing episodic memory including so-called Dynamic Memory Networks Kumar et al [262], variants of Neural Turing Machines Graves et al [168], self-organizing neural networks Chang and Tan [354] and reinforcement-learning methods based on reservoir sampling81 [489].
The neural circuits implementing the executive functions for attention and executive control located in the prefrontal cortex orchestrate complicated motor functions and sequential decision making in addition to controlling the contents of working memory [256, 331, 255]. As discussed elsewhere — see Figure 38, there are two systems for executive control, one primarily involving circuits in the prefrontal cerebral cortex and a second system involving the cerebellar cortex, evolutionarily recent reciprocal connections between the front and back of the brain, basal ganglia and related subcortical circuits [231]
Attentional systems abound in recurrent neural network architectures [118, 20, 18, 168]. Michael Graziano's attentional schema theory [181] abstracts nicely from the details of the underlying neural substrate and is algorithmically straightforward [180]. Humans can — and routinely do — adopt an attentional stance toward anything they are inclined to attribute mental properties [115], and theory-of-mind reasoning embraces this diversity by allowing multiple attentional schemata and relying on episodic memory to sort out the different entities and their related mental capacities and proclivities.
Managing the assistant-side of the dialog between the assistant and the programmer in service to their collaboration may seem at first blush the most difficult technical problem. This may be so. However, it may also turn out to be the simplest to approximate for interim prototype testing due to the work of the Google Assistant team on both the NLU (natural language understanding) and NLG (generation) sides of the dialog. We are also looking into the prospect of handling some fraction of programmer-assistant exchanges by relating to code editing and reuse to an automatic planner designed for dialog management and developed as part of an earlier assistant project.
Obviously the programmer's apprentice is intended to facilitate code synthesis. This aspect of the project has consumed the most time in planning and our conclusion is that apprentice can fill a useful niche by ingesting a large corpus of annotated programs — programs plus English descriptions and sample input / output data — using context-aware hierarchical embeddings to propose code fragments for reuse in writing new code [156]. Elsewhere in this document you'll find summaries of both syntactic and semantic embedding techniques applied to code synthesis. We also have confederates at Google who have experience in automatic programming [497, 292, 3, 282, 323, 272, 310] and have offered ideas plus new projects starting up to exploit our own code repositories for reuse.
January 27, 2018
The first part of this discussion was all about choosing problems to drive ground-breaking research, drawing on experience from the first ten years of my academic career. My strategy then and now involves focusing on a problem — often the defining problem for a research area such as automated planning and control, redefining the problem if its potential is limited by current methodology, prevailing theory or entrenched dogma, asking what characteristics of the problem are preventing progress, and then spending substantial time exploring alternative avenues for promising technologies and problems that might break the logjam and reveal new opportunities.
This may sound like the sort of creative-problem-solving advice corporations pay consultants to inflict on their employees expecting to make them innovative. Some of that advice is obvious if not always heeded. Much of it your parents may have taught you, e.g., listen respectfully, provide constructive comments, don't interrupt, don't monopolize, etc. Trashing an idea after three minutes thought, dismissing entire disciplines without any idea of what they might have to offer, denigrating an approach because it is too mathematical or not mathematical enough, etc ... these are all behaviors not conducive to making progress. I'll assume you know how to behave and get on to the hard parts.
In industry, the focus is typically on near-term deliverables. Academia has traditionally focused on longer-term impact but increasingly the relevant incentives don't align with this view. In any case, I'm not interested in incentives here. I'm interested in how to come up with new ideas to drive game-changing, discipline-defining research. The first step is coming up with one or more problems that will challenge, inspire and require significant innovation. In my early academic years, the focus was on building automated planning and logistics systems to control robots, route vehicles and manage inventories, and the technical challenges involved dealing with uncertainty and real-world dynamics.
We are still working on those problems using a host of new technologies but the target robots, vehicles and businesses are now real and their applications are forcing innovation and driving research and development. Today many of the technical challenges we face involve building autonomous systems capable of intimate and constructive interaction with human beings. Ultimately, these systems will need to understand our strengths and weaknesses, learn what drives us, help us solve problems, make us smarter and more self reliant. Learning how to supply us with what we crave and shelter us from what we abhor is not, I offer, a goal worthy of our technical prowess or social aspirations.
The programmer's apprentice is a digital-assistant application. It requires subtle interaction between the programmer and apprentice and the ability to engage in collaborative problem-solving on a task that, while challenging, is within our technical ability. The interaction requires the apprentice to recover from the inevitable misunderstandings that occur in a collaboration between individuals with differing levels of communication skill and task-relevant knowledge. The assistant will require the ability to construct a theory of its own mind and that of the programmer in order to keep track of what was said by whom, who knows what, and when and in what context knowledge was imparted.
Systems capable of theory-of-mind reasoning, maintaining a detailed episodic memory of events, designing and debugging useful computer programs, and collaborating with a human on a technically-demanding task don't exist. They are, however, worthy challenges. The clues for their design come from a wide range of disciplines including developmental psychology and cognitive science, cognitive neuroscience, systems neuroscience, linguistics, philosophy of mind, artificial neural networks, automated program synthesis, human-computer interaction, etc. The strategy for making progress is to design a composite architecture based on components drawn from recent work on recurrent neural networks.
Inspiration from the biological and cognitive sciences is not new by any means. Demis Hassabis has proved especially adept in leveraging knowledge from these disciplines to inspire engineers to develop new architectures exhibiting novel capabilities. You only have to think about how humans solve problems to conclude that our brains represent a treasure trove of design ideas. You don't need to understand the neural correlates of human episodic memory in order design neural networks that emulate human memory. You don't need to understand the cognitive development of theory-of-mind reasoning in children to build a personal assistant that can emulate this capability interacting with humans.
Theories about what it means to be conscious continue to rage in academic circles while engineers take inspiration from the few concrete facts we know about consciousness to build systems that selectively attend to relevant stimuli and maintain simple representations of self that facilitate social interaction. The point is there are ideas a plenty to inspire new technology. In the first ten years of my research career, the windfall was to be had from mathematics and the engineering sciences due to the fact that AI had isolated itself and was too confident of its ability to invent the future on its own. We exhibit our hubris by ignoring the biological, cognitive and social sciences82.
We work in machine perception! What could we learn from studies of consciousness or episodic memory? Growth requires taking on new challenges and acquiring new perspectives. When Peter Norvig asked me what I wanted to do if I came to work at Google, I said I wanted to apply computational neuroscience to artificial intelligence and had no interest in ever working on Markov decision processes again. If you want a successful academic career your best bet is to make a name for yourself in some niche area and then mine it for all it's worth. If you want an interesting, productive career you need to constantly evolve to keep yourself fresh. You need to balance exploration and exploitation.
Research progress in brain science is accelerating, but it is not the only field worth tracking. Interest in brain imaging has spurred innovation in photonics and image processing. The nascent field of computational biology83 is providing insight into how plants, bacteria, genes and social organisms compute at multiple scales. These fields enrich our understanding of nature and physics and can't help but inform the study of perception. Working on a problem that forces you to stretch your skills and expand your knowledge doesn't require you to abandon your current field of expertise, but it will help you to see it with a fresh perspective. Enrico Fermi even suggested we should switch fields every ten years84.
January 25, 2018
%%% Fri Jan 26 04:37:54 PST 2018
Over the last two weeks, I participated in several discussions about how to guide research and whether for a given enterprise it makes sense to aim for relatively conservative incremental progress or make a contrarian effort to identify and exploit potentially risky alternatives. I have almost always opted for the latter, though I can't recommend the strategy to others without some reservation. This entry summarizes my research trajectory for the first ten years of my twenty year academic career85, and the next entry covers my recent efforts and suggests an alternative strategy that might work now at Google.
At Yale I worked with Drew McDermott on automated planning and came to the conclusion that existing planners were limited by having an impoverished representation of time and causality. I developed the idea of time maps and temporal database systems for applications in robot planning, scheduling and logistics [89, 90, 92, 93], and, for some time, the hierarchical planning system that my fellow graduate students and I designed and built was the most sophisticated robot planner available [142, 311, 102].
During the same period, I started collaborations with researchers in statistics and applied math expert in Markov decision processes (MDP) believing that AI planning was limited by its failure to embrace probability and decision theory. AI planning was still closely tied to STRIPS [139, 138] and was believed to be incompatible with Markov processes due to the intractability of underlying inference problems. I pointed out to anyone who would listen that STRIPS fluents were simply state variables and even the simplest planning systems were NP-hard [91]. In 1989, I started work on a book entitled "Planning and Control".
Planning and Control [103] introduced the AI community to Markov Decision Processes and their partially observable counterparts demonstrating how traditional AI planning systems could be refactored as Bayesian networks [103]. Ten years later when Craig Boutilier, Steve Hanks and I wrote a survey of the field [50] there were thousands of related papers. Planning and Control also introduced control theorists to Bayesian networks as an antidote to LQG control systems — linear dynamics, quadratic objective functions and Gaussian noise models.
Occupancy grids were introduced by Moravec and Elfes [316] as an approach to robot planning and navigation using wide-angle sonar and dealing with uncertainty. They were an advance over earlier work based on Kalman filters but decoupled planning from control making it difficult to integrate the two in probabilistic decision making. To address these shortcoming we developed the first Bayesian approach to Simultaneous Localization and Mapping (SLAM) [99, 34] for mobile robots well in advance of the work by Fox and Thrun [147].
One complaint about non-trivial probabilistic models is that probabilistic inference is intractable. The fact that inference on any sufficiently expressive AI representation is intractable [91, 101] didn't dissuade detractors from complaining about our models. To address these concerns, we recast real-time decision making as a scheduling problem in which the task is to allocate processor time to approximation algorithms that can be interrupted given any increment of processor time to provide an answer whose expected value monotonically increases as a function of run time.
We called these approximations anytime algorithms and with the publication of our AAAI paper [100] the terminology quickly entered the lexicon of AI. Herbert Simon [396] introduced the idea of bounded rationality, and, while I.J. Good [162], Eric Horvitz [221], and Stuart Russell and Eric Wefald [374] contributed substantially to the theoretical foundations, it might be argued that the notion of anytime algorithms had more of a practical impact on the evolution of AI during the decade following its publication86.
%%% Thu Jan 25 04:57:29 PST 2018
This is the 200th anniversary of the first edition of Mary Shelley's Frankenstein. The book has been mentioned in several news stories and appeared in book-club lists focusing on the theme of the modern Prometheus and concerns about the near-term prospects for superhuman AI systems. These excerpts87 caught my attention for their nuanced view of a young man seduced by the idea of controlling nature, defeating death and altering the fate of humanity. In her portrait of Victor Frankenstein, Shelley underscores the capacity of youth to take on any challenge with the confidence they can achieve the most audacious goals and the certainty they can understand and control the consequences.
January 23, 2018
%%% Tue Jan 23 04:57:29 PST 2018
Despite pessimism expressed in an earlier note, selective reading of Dere et al [116] Handbook of Episodic Memory has yielded some useful insights. Compressing that insight into a few paragraphs appears to be more difficult, illustrating the maxim that the less we know the more space we need to express it. The following somewhat scattered notes consist of excerpts from the handbook and commentary on selected chapters.
In the following discussion, I will borrow liberally from The Handbook of Episodic Memory edited by Dere et al [116] and, especially, from the general overview in Chapter 1.2 "Exploring Episodic Memory" written by Martin Conway [77] and the focus on the prefrontal cortex in Chapter 3.5 "The role of the prefrontal cortex in episodic memory" written by Matthias Brand and Hans Markowitsch. Unless otherwise made explicit, assume attribution to one of these sources.
The term episodic memory is often linked to the hippocampus, but that is just one of many brain structures hypothesized to play an important role. Similarly, auto-associative memory models including Hopfield networks are thought to be relevant, but, again, the full story is more complicated.
If you want to understand the neural correlates of human episodic memory (EM), your best bet is to learn about the deficits of patients who have suffered lesions in the various parts of the brain that are thought to contribute to EM. It will help in reading the relevant literature if you know what the basic parts of the brain are called. Here they are listed (parenthetically) along with their primary structures (SOURCE):
Medulla Oblongata (Myelencephalon)
Pons and Cerebellum (Metencephalon)
Midbrain (Mesencephalon)
Thalamus and Hypothalamus (Diencephalon)
Cerebral Hemispheres (Telencephalon)
Most of the anatomical discussions concerning episodic memory focus on the forebrain that consists of the telencephalon and diencephalon, where the forebrain, along with the midbrain and hindbrain constitute yet another way of parceling up the brain.
The cortex gets divided into frontal, parietal, occipital and temporal lobes whose wrinkled surfaces are further landmarked with sulci, gyri and fissures and divided using the microscopic anatomy of cells and tissues into areas first mapped out by Brodmann that continue to be amended and debated today.
The primary characteristics of episodic memory as first set forth by Endel Tulving [442] and subsequently amended and extended by several authors, are shown here grouped into categories and summarized following their exposition in Dere et al [116]:
Ontological: (i) Sensory-perceptual-conceptual-affective processing derived from working memory; (ii) Retain patterns of activation/inhibition over long periods; (iii) They are predominantly represented in the form of (visual) images; (iv) They always have a perspective (field or observer);
Functional: (v) They provide a short-term record of progress in current goal processing; (vi) Represent short-time slices, determined by changes in goal processing; (vii) They are represented roughly in order of occurrence, temporal dimension; (viii) In humans they are only retained in a durable form if they become linked to conceptual autobiographical knowledge (rapid forgetting); (ix) They are the mental representations from which concepts are formed;
Phenomenological: (x) They are recollectively experienced when accessed; (xi) When included as part of an autobiographical memory construction, they provide specificity;
Srtuctural: (xii) Neuroanatomically they may be represented in brain regions separate from other autobiographical memory knowledge networks;
Developmental: (xiii) Phylogenetically episodic memory may be a species-general evolutionary old memory system; (xiv) Ontogenetically the ability to form episodic memories may be present early in development;
The brain areas involved in mediating the recall of memories that consist of autobiographical knowledge and episodic memory are distributed from anterior to posterior brain regions. Regions in the prefrontal cortex (PFC), such as lateral, medial, and ventromedial PFC networks88, have been found to be critical in initiating searches of long-term memory and in evaluating knowledge once accessed. Other medial temporal lobe89 structures including those adjoining Wernicke's area90 appear to be important in the experience of remembering and the emotional content of memories.
Finally, posterior networks and the retrosplenial cortex91 and related areas as well as the visual cortex (occipital92, cuneus93, precuneus94) become active when sensory perceptual EMs enter into the construction of autobiographical memory. Some suggest that abstract conceptual knowledge about periods in a person's life and about the self — termed the conceptual self — may be represented in frontal networks, other more detail knowledge about general events, others, goals, actions, activities, locations, others, etc. may be represented in temporal networks and EMs and temporal occipital networks. In this scheme, EMs are located in brain regions that are separate from more conceptual knowledge of an individual's life95.
More briefly, Chapter 3.6 "The basal forebrain and episodic memory" [148] makes the case that the basal forebrain likely plays a role in memory recall, "especially in the search for memory content from designated temporal context, or in postretrieval monitoring of memory content whether or not it is matched with designated temporal context, or both."
Chapter 3.7 "The role of the precuneus in episodic memory" [438] discusses the possible role played by the precuneus in episodic memory "with special attention to the link between episodic memory consolidation and the default mode of brain function during the conscious resting state, as recently outlined by functional imaging studies."
Chapter 4.1 "Neural coding of episodic memory" [440] is perhaps the most intriguing from a modeling perspective given its claims that "recent identification of network-level organizing principle and memory-encoding units in the hippocampus has allowed real-time patterns of memory traces to be mathematically described, intuitively visualized, and dynamically deciphered." The full abstract is quoted below to further pique your curiosity:
Any given episodic event can be represented and encoded by the activation of a set of neural clique assemblies, which are organized in a categorical and hierarchical manner. This hierarchical feature-encoding pyramid is invariantly composed of the general feature-encoding clique at the bottom, subgeneral feature-encoding cliques in the middle, and highly specific feature-encoding cliques at the top.This hierarchical and categorical organization of neural clique assemblies provides the network-level mechanism the capability of not only achieving vast storage capacity, but also generating commonalities from the individual behavioral episodes and converting them to the abstract concepts and generalized knowledge that are essential for intelligence and adaptive behaviors.
Furthermore, activation patterns of the neural clique assemblies can be mathematically converted to strings of binary codes that would permit universal categorizations of the brain's internal representations across individuals and species. Such universal brain codes can also potentially facilitate the unprecedented brain–machine-interface communications."
January 21, 2018
%%% Sun Jan 21 04:57:26 PST 2018
How does the brain know enough to create a representation of a new entity that might have much in common with an existing entity and yet is clearly distinguishable as an independent separate entity, e.g., an unrecognizable voice on the phone? Along similar lines how does the brain distinguish special cases (subclasses) of a general class, e.g., animals that can solve puzzles, signal intentions, speak or follow directions? What about the case in which an instance of such a subclass is deemed to have private attributes, e.g., thoughts, feelings and knowledge, that are not (obviously) apparent by means of a superficial examination? We have representations of photos, videos and music recordings. What about our parents, pets and possessions along with a lifetime of personal memories that feature these central figures and fixtures in our lives?
Unlike what is known about how the brain represents physical objects — the shape, color and motion of visual stimuli are represented in an orderly fashion in the visual association areas, episodic memory is a great deal more complicated, emerging gradually and developing over many years, integrating information from a great many sources. I've picked up a few ideas from my cursory reading of the literature — see here for a small sample of interesting papers; however, while some of those ideas may help in developing an application-specific version of episodic memory for the programmer's apprentice, human episodic memory is so intricately interwoven within our neural circuitry and integrated into our complicated social lives that any attempt at duplicating it seems premature96.
January 19, 2018
%%% Fri Jan 19 17:47:36 PST 2018
I spent Thursday and Friday at the MIT-X AI Summit at Google X. Especially learned from Josh Tenenbaum, Jim DiCarlo, Dan Yammins, Matt Wilson and Nancy Kanwisher. Josh got me to look at probabilistic programming more carefully [419], Matt made me think again about the hippocampus and its role in episodic memory [326] and Nancy about the prospects for human functional modeling by combining EM enhanced DTI tractography with fMRI functional studies97.
The probabilistic programming model described in [419] provides offers a powerful explanatory theory of mind worth exploring more deeply. Other Bayesian generative models [155, 164] provide insight into human cognition, child development and the evolution of intelligence. Despite these advantages, differentiable models provide a framework for experimenting with integrating a wide range of cognitive capabilities, and, while far from modeling biology at the molecular level, provide insight into how distributed codes and gradient descent learning can implement complex learning machines.
I believe that Stanislas Dehaene [104] and Michael Graziano [171] provide enough of a basis for theory-of-mind reasoning system that it — or a useful approximation — can be implemented in an end-to-end system98. Training data is a potential problem and this is one reason why a probabilistic programming approach might provide the most expeditious approach for implementing theory of mind in an application such as the programmer's apprentice. The cognitive science research paradigm suggests one possible approach for generating a dataset for learning theory-of-mind reasoning:
Have the target theory-of-mind learning system watch videos of kids interacting with one another and learn to predict what they will say in answering questions. Watch videos of children in Anderson's Hide-Find Paradigm [9, 418] intended to investigate how we learn that different minds know different things. Formulate an hypothesis to clearly express how the children are searching for a theory to explain what they are observing and how they go about formulating and testing hypotheses [167]. See here for theory-of-mind related papers and here for a first pass at collecting papers on episodic memory.
January 16, 2018
%%% Tue Jan 16 04:40:09 PST 2018
This entry relates some of what we know about contextual embedding from research in computer vision and natural language processing, and suggests how we might apply this knowledge in the case of code synthesis. The objective is to embed subtrees of an abstract-syntax-tree (AST) given the context of the enclosing AST minus the selected subtree. Fortunately, the parsing problem is solved and we can construct a canonical AST given any well-formed program fragment from most modern programming languages. Such an embedding is intended to be used in program synthesis to generate proposals corresponding to code fragments given the context of a partially completed target program to be inserted into the target at a designated location.
Mikolov et al [309] introduced two architectures for learning word embedding architectures. The Skip-Gram architecture predicts surrounding words given the current word and the CBOW architecture predicts the current word based on the context, i.e., the n words immediately preceding and n words immediately following. Since its publication, there have been several extensions including Le and Mikolov [273] working with sentences and documents, Kiros et al [252] work on Skip-Thought Vectors embedding sentences within adjoining sentences, and Lazaridou et al [270] Multimodal Skip-gram Architecture combining language and vision.
Since we are interested in generating code fragments to insert in a program under construction, the basic CBOW architecture captures our intended meaning of context. However, given we are working with code fragments and not individual words, the original implementation of CBOW lacks the necessary power of more sophisticated embedding methods. As an example, given the AST representation of a program99 T = { A → B, A → E, B → C, B → D, E → F, E → I, F → G, F → H, I → J, I → K }, the analog of the CBOW-architecture shown on the left in Figure 1 of [309] for the input consisting of T and the subtree S = { F → G, F → H } rooted at F — sans explicit nesting directives — would look something like [A, B, C, D, E] ⊗ [I, J, K] = [F, G, H].
Not surprisingly, inserting a fragment from one program into another based entirely on syntactic features can have unwanted semantic consequences. Long Short-Term Memory (LSTM) language models are capable of keeping track of information revealed at one point in translating a block of text in order to apply it at a later point. For example, the cell state of an LSTM might encode the gender of the subject of the current sentence, so that correct gender-specific pronouns might be employed in translating subsequent sentences. Upon encountering a new subject, we may want to forget the gender of the old subject and guess the gender of the new subject if there are reliable clues available [328]. We expect code-fragment embeddings will require similar adjustments.
The sample programs shown in Figures 34 and 35 are given a sentence and pair of keywords as part of their input. In scanning a given input sentence, they keep track of the last occurrence of these keywords in order to determine whether the one keyword is separated from another keyword by a span of no more than a specified number of words. Given the stub corresponding to the nested define and let statements from Figure 34, the programmer's apprentice might propose the (embedded) do loop fragment from Figure 35 and then make additional adjustments to obtain a correct program. Explaining in detail how this might be accomplished is our next challenge.
%%% Tue Jan 16 15:50:33 PST 2018
In terms of leveraging ideas from neuroscience, I've been revisiting papers on the role of prefrontal cortex in attention, executive control and working memory100 . The Ba et al [18] work on fast weights — von der Malsburg's dynamic links [494] — continues to intrigue me as a candidate for working memory. In recent networks implementing some form of fast weights, outer products have been used to generate weight matricies in an Hebb-like manner as introduced by Schmidhuber [382] and layer normalization [19] has been shown to be effective at stabilizing the hidden state dynamics in recurrent networks. Here are two examples from Dehaene [104] that illustrate the persistence of ideas from symbolic computing101.
January 15, 2018
%%% Mon Jan 15 04:23:19 PST 2018
Over the last few years the terms attention [20, 185], imagination [339] and consciousness [38] have entered into lexicon of machine learning and found application in developing artificial neural networks. All three of these involve memory whether that be short-term, long-term or working memory. Indeed, some argue that the main role of consciousness is to create lasting thoughts — not what cognitive scientists refer to as "episodic memory", but, rather, information relevant to solving a particular problem so that it remains fresh in our mind for as long as we need to attend to it and solve the problem at hand102.
The application of artificial neural networks to robot planning, automated programming and complex decision making depends on developing subtle methods for creating, maintaining and manipulating differentiable representations in memory. This year, CS379C emphasizes recent developments in artificial neural network memory systems to address challenges in these applications. Here are four tutorials that along with having taken a course in machine learning and acquired some programming experience with artificial neural networks should prepare you for related topics in the class lectures103:
Convolutional Neural Networks — Andrej Karparthy [248] (PDF)
Attentional and Augmented Networks — Chris Olah and Shan Carter [327] (PDF)
January 12, 2018
%%% Fri Jan 12 14:38:46 PST 2018
The following three entries in this log summarize the current status of the programmer's apprentice project proposal:
January 11 — Provides an extended example of interacting with the apprentice and a description of the executive control system that handles the user interface and facilitates code synthesis.
January 9 — Focuses on the weakest element of the proposed architecture, creating rich embedding contexts to generate proposals for program transformations to be applied in code synthesis.
January 7 — Provides a high-level description of the neural-network architecture and how it relates to the multiple input sources, including the instrumented IDE shared with the programmer.
January 11, 2018
%%% Wed Jan 10 09:48:42 PST 2018
The programmer's apprentice is exactly that, an apprentice or novice programmer in training that can assist with some of the more tedious minutia involved in writing programs, and a digital amanuensis that can make use of a large corpus of existing programs in order to propose using fragments of those programs in the development of new programs, and is able to perform syntactic and semantic analyses of code fragments to assist in transforming — adapting and debugging — a fragment of one program for use in another program.
Most of the discussion in this document focuses on the neural network architectures required for performing these syntactic and semantic analyses and facilitating search for suitable program fragments to suggest as proposals in developing new code. We refer to the apprentice using the acronym PAN — [P]rogrammer [A]pprentice [N]eural-network — and note that as a dutiful apprentice PAN has to interact with the programmer to explain proposed code modifications, elicit feedback, ask for assistance and generally participate in a form of human-computer pair programming104.
Conversing in natural language and sharing a graphical representation of the current programming project facilitate such interaction. The graphical representation is essentially the editor window of an Integrated Development Environment (IDE). This IDE is instrumented allowing the apprentice to make any changes a programmer might make to a program including editing, formatting, searching, selecting, copying and replacing text, executing macros that control the debugger to set breakpoints and step through programs, plus invoking a number of capabilities that exercise PAN's neural-network architecture.
PAN also requires a language facility including a language model suitable to span the technical argot, idioms and ontology employed in software engineering practice. In the initial phase of developing PAN, we will resort to a somewhat conventional dialog system for natural language understanding and generation, choosing to focus effort initially on how to apply artificial neural networks / differentiable models to generate useful proposals during code synthesis. This initial dialog manager is modeled after a prototype developed for the Zinn project.
PAN's executive control system including its dialog management subsystem is essentially a hierarchical planner [47] and as such everything it does including every utterance it makes, every action taken in response to a user utterance or in pursuing its own self-generated code-synthesis-related plans is motivated by its goals in assisting the programmer. Most activities generate new goals that spawn new plans only some of which will actually be expanded into actionable tasks such as applying code transformations, testing hypotheses, asking the programmer for guidance, resolving ambiguous instructions or recognizing and recovering from misunderstandings.
%%% Thu Jan 11 04:52:40 PST 2018
Here is an illustration of the programmer (USER) interacting with the apprentice (SYSTEM) in the process of developing a program. A human-readable synopsis (EXECUTE) of the tasks executed from SYSTEM-generated plans is shown interleaved between utterances:
SYSTEM: I see you've added a new program specification to your code repository would you like me to ingest it?EXECUTE: ingest[ Description, I/O_Samples, [Program ID, 1089] ], validate[ 1089 ], convert[ 1089, [Format, "STD"] ]
SYSTEM: The description and input-output pairs look good. I converted them to our standard format. What's next?
USER: Go ahead and try to write a program that meets the supplied specification. Tell me if you have problems.
EXECUTE: embed[ Syntax, 1089 ], generate[ Traces, 1089 ], embed[ Semantics, 1089], propose[ Main_Program, 1089]
SYSTEM: Performed syntactic and semantic analysis and incorporated with description. Check out the initial stub.
USER: Looks good. Assume three formal parameters consisting of two of type string and the third a list of strings.
EXECUTE: attend[ {Syntax, Semantics}, 1089 ], select[ [Stub, 1089] , [Current, 1089] ], insert[ Selected ]
SYSTEM: I've inserted a loop to iterate over the strings in the third argument list and stubbed out a conditional.
USER: You need a counter to keep track of the location of the last occurrence of the second argument in the list.
In this example, the SYSTEM ingests the specification for a new target program, checking to make sure that the specification can be massaged into the standard format required to ingest such specifications. It then creates a distributed representation of the description and enters the I/O samples in the IDE buffer in the required format so they can be used during subsequent development and debugging. Following a standard protocol, the SYSTEM might create a MAIN program or DEFINE a procedure employing default templates. Ingesting the USER supplied description of the formal parameters, the SYSTEM produces a probability distribution it can use to generate proposals to fill in the BODY.
Noticing that the top five proposals are syntactic variants of one another, the SYSTEM inserts the most common variant, in this case a LOOP over a list, having simplified the proposal fragment by eliminating other expressions in the LOOP body pending feedback from the USER. Proposal generation relies on a contextual embedding network using the current program, consisting in this case of the description, I/O samples, initial stub and supplied formal parameters, as the context. Internally, programs are represented as abstract syntax trees thereby finessing the problems of comparing programs, determining fragment boundaries and composing new programs from existing fragments in the embedding space.
| ||
| Figure 39: Here is a sample plan of the sort managed by the SYSTEM hierarchical planner and used in service of dialog management. The executable tasks interject and interact are primitives that produce (immediate) interlocutionary acts. The lookup function invokes a neural-network subsystem that performs sentiment analysis and estimates salience. Each plan returns a (possibly empty) list of subtasks that are added to a queue of such tasks maintained to account for the highly dynamic nature of conversational dialog. Macros like WHEN_YOU_SAY, IS_WAY_YOU_SAY and I_GOT generate random variants of conversational idioms to add diversity in speaking often-repeated multi-word (phrasal) synonyms. They are currently implemented using phrase embeddings, and won't be required when SYSTEM utterances are generated with encoder-decoder recurrent network technology. The plan shown here was part of a prototype system intended to assist users interacting with Google Play Music, but could be adapted to suit the proposed programmer's apprentice application. | ||
|
|
%%% Thu Jan 11 09:22:35 PST 2018
Plans are essentially programs and the hierarchical planner is basically a plan interpreter and runtime manager. Plans are used to manage the SYSTEM-side of the dialog and handle all of the many aspects of developing programs — see Figure 39. The current implementation of the planner is written in Python. In principle, the target programming language of PAN could be the same as the programming language used to implement plans and the SYSTEM could write programs to modify its behavior, perhaps using a specially designed sandbox to experiment with self-modifying code and some sort of immutable kernel designed as a fallback in case its modified self runs amok.
The potential for the apprentice to write code implementing new plans that perform complex protocols with loops and conditionals and tasks that control IDE instrumentation is considerable. However, for the time being, the hierarchical planning framework is being used as an expedient in developing a prototype in which the focus is on code synthesis and, in particular, on generating proposals corresponding to program fragments that can be relatively easily adapted to solve new problems. We anticipate that much of the conversational capability leveraged in the aforementioned hierarchical planner can be improved upon using neural-network-based NLP and recent advances in developing value iteration networks [186, 429].
January 9, 2018
%%% Tue Jan 9 03:45:23 PST 2018
I briefly reviewed the work on distributed representations and their relationship to compositional representations and the variable binding problem. Specifically, Kriete et al [258, 331] on how areas of prefrontal cortex might provide working memory that supports slot-filler manipulations relying on gating involving the basal ganglia. Hassabis and Maguire [201, 200] hypothesize that hippocampus plays a critical role in imagination by binding together the disparate elements of an event or scene. Earlier work on circular convolution by Tony Plate [350, 349] PDF and the tensor-product representations by Paul Smolensky [403, 404] are briefly reviewed in Kriete et al [258], but don't reflect more recent research [224]. None of these approaches strike me as satisfactorily supporting the sort of operations anticipated below.
Recently there has been renewed interest in the work of Christof von der Malsburg [455, 456] on his concept of dynamic weighting also known as fast weights — see Hinton and Plaut [215] and Ba et al [18]. Dynamic weighting was developed to deal with the problem of establishing short-term connections between concepts to express time-dependent relationships between existing distributed representations. This makes it possible to efficiently construct and reason about complex objects as a dynamically linked composition of multiple objects without complex and costly copying or permanently altering the network — see here for a list of relevant recent and historical titles and abstracts105 . Using the term "aspect" to refer to what are traditionally called variable-binding pairs, slot-filler notation, etc., and masking the difference between the "executive control" and "attentional control" systems — if such a difference even makes sense106 , we want to understand how an attentional control system might be trained to support the following operations:
select representations that support a particular instance of given task;
activate a selected representation in space allocated in working memory;
maintain — keep activated — a representation in working memory;
suppress, maintain or emphasize aspects of an activated representation;
fill a slot or alter a variable binding in an activated representation;
link activated representations to construct composite objects as proposals;
select an activity and initialize to suit current context and circumstances;
return attention to an ongoing activity resuming work where you left off;
on reactivation update activity accounting for changes since last activation;
terminate activation returning any supporting resources to available status;
release bindings and other temporary adjustments to relevant state vectors;
Here is the primary related use case for the programmer's apprentice that I have in mind: In a machine-translation or dialog-management system implemented as an encoder-decoder pair of recurrent neural networks, we usually build up a representation — often referred to as the context of a text or conversation — in the encoder by ingesting the text comprised of a sentence or longer statement in the original source language or an utterance generated by one of the participants in a conversation, and then construct a translation in the target language or a response from the other participant in the dialog. Ideally, the context can be as rich as it needs to be, encompassing information from, not only the text of a book being translated up until the start of the specific sentence being translated or the ongoing conversation up until the last utterance in the conversation being responded to, but the much larger social and intellectual context of the book or conversation. The work of Ba et al [18] on dynamic links and fast weights specifically invokes attention noting that fast weights can be "used to store temporary memories of the recent past and they provide a neurally plausible way of implementing the type of attention to the past that has recently proved very helpful in sequence-to-sequence models".
%%% Wed Jan 10 03:41:31 PST 2018
The relationship between embedding symbol sequences in vectors and variable binding is illustrated in the work of Huang et al [224] on tensor-product generation networks (TPGN) leveraging Smolensky's original tensor-product approach to variable binding [404]. In theory, TPGN networks inherit several desirable characteristics from Smolensky's work listed on Page 64-65 in [403] including that such networks (i) saturate gracefully as larger structures are represented, (ii) permit recursive construction of complex representations from simpler ones, and (iii) respect the independence of the capacities to generate and maintain multiple bindings in parallel. Their application of TPGN's to image captioning outperforms the widely-used LSTM-based models for images in the MS-COCO dataset [224]. The authors claim that "the learned representations developed in a crucial layer of the model can be interpreted as encoding grammatical roles for the words being generated." If their claims hold up, this approach could be well suited to the problem of embedding programs for code synthesis.
January 7, 2018
%%% Sat Jan 6 04:31:07 PST 2018
In this log entry we revisit the original architecture shown in Figure 29, providing more detail concerning the various layers and subnetworks and the functions that they are intended support. This is not the last word by any means and there are many details I have yet to figure out, but the architectural features described here go some way toward explaining how we might design a programmer's apprentice of the sort we envisioned back in December. The main contributions of this exercise are summarized in the caption of Figure 37 and elaborated in the following.
The red and green connections shown in Figure 29 are assumed in Figure 37 since they support the attention-based executive control model described here. These connections enable the system to become aware of thoughts activated by excitation from the sensory-motor periphery and, by attending to such thoughts, make them available to other thoughts held in conscious awareness. Representations associated with these thoughts can be combined and shaped by excitatory and inhibitory connections to facilitate imagining novel situations, making predictions and generating proposals to support code synthesis.
The representations corresponding to thoughts have to persist over time to participate in the construction of new composites. The recurrent layers are capable of activating multiple contexts, sustaining their activity over indefinite periods of time and taking top-down direction from layers modeled after the prefrontal cortex (PFC) to enable the vector analog of slot filling and variable binding using inhibitory and excitatory feedback from the PFC executive-control attentional system. This model of attentional control is inspired by Yoshua Bengio's consciousness prior [38]. See here for related background on working memory, prefrontal cortex and the role of the basal ganglia108 .
| |
| Figure 38: This graphic represents a neural architecture consisting of several collections of neural network layers rendered here as cloud-like shapes arranged in four levels of a hierarchy. The top three levels shown here roughly correspond to the diagram shown in Figure 29 labeled A. The networks shown in the bottom level are associated with the different input and output modalities depicted in Figure 29 labeled B, C, D and E. The clouds for handling structurally-indexed input and output include written text and spoken word sequences, version-control repository submits, abstract syntax trees, natural language parse trees, execution traces and various topographical maps and time series, and are rendered here as unrolled recurrent networks showing replicated instances of the structure separated by dashed lines. Networks responsible for primary sensory areas in the cortex are depicted as convolutional stacks not showing any recurrent connections though these may indeed be important to add in some cases. The bottom two levels could have been reversed or interleaved but are shown stacked to highlight their separate function. Networks such as those representing the sort of complexity we might expect in cortical association areas are indicated as cloud shapes within which rectangles representing layers are shown with complex recurrent connections. Though not explicitly shown as such, these cloud shapes are arranged in hierarchies intended as containers for different abstractions of their corresponding inputs appropriate to their level of abstraction. The component layers are not predesignated or preapportioned, but rather their designations and apportions are determined by the complexity of their input — time varying as in the case of the analog of somatosensory cortex — and the relevance of their abstractions in carrying out rewarded activities. | |
|
|
The two control diagrams shown in Figure 38 provide additional architectural structure motivated by features of the primate cerebral cortex and its interaction with the cerebellar cortex. The first diagram illustrates how the systems responsible for natural language comprehension and generation are coupled, suggesting a general model for how meaning and manipulation are related in embodied systems. The second diagram abstracts the advanced (biological) control system architecture that humans use for precise, complex planning and prediction that resulted from the relatively recent complementary evolution of the cerebral cortex and cerebellum in primates and Homo sapiens in particular.
| |
| Figure 37: The two control diagrams shown here provide additional architectural structure motivated by features of the primate cerebral cortex and its interaction with the cerebellar cortex. The top diagram in Figure 38 shows the linguistic version of the dual-stream hypothesis [196, 366] starting in Wernicke's area and terminating in Broca's area, mapping visual / auditory sensory representations onto manipulatory / articulatory motor representations with the two paired much as in a recurrent-neural-network-based encoder-decoder machine-translation system — see Figure 31 for more detail. The bottom diagram in Figure 38 is a simplified version of the Ito [231] model introduced in Figure 36. The diagram shows a schematic illustration of explicit and implicit thought processes. The working-memory system and attentional system together constitute a controller for a mental model during the attentive phase of (directed) explicit thought. The part of the prefrontal cortex that carries out executive functions acts as a controller for less-attentive explicit thought carried out in the olivo-cerebellar complex. The inverse model provides the basis for a feed-forward controller. | |
|
|
%%% Sun Jan 7 05:42:51 PST 2018
Programmers hold a great deal of information in their heads when writing complex programs. Even ignoring the knowledge acquired through years of practical coding experience and reading and reviewing millions of lines of code, a short program consisting of a few thousand lines is a complex structured object with many interacting parts, dependencies on multiple libraries with complicated interfaces and knowledge of the relevant application area. We expect the provided program-specific, standard-format information relating to the current programming project is entered in a buffer or special area of the instrumented IDE so it can be referenced, reviewed and revised if needed. Making it accessible for subsequent inference is, however, a challenge.
Information relevant to the current project is ingested at the outset and represented in the network as part of the attentional schema so that it can be brought to bear as a reference — part of the global context — in guiding subsequent processing and specifically program synthesis. It is expected the programmer will also inject comments that clarify or otherwise add to the information relating to the program specification and that these will find their way through various paths to augment and amend this information, perhaps routed by selective attention using verbal cues to ensure that its intent and relative importance is clear. It's not obvious how to engineer the desired outcome, but it may be as simple as leveraging reinforcement learning with an appropriate prior.
January 5, 2018
%%% Fri Jan 5 03:20:34 PST 2018
So what is missing? We are making some progress in terms of developing representations — generally vector spaces trained by encoder-decoder pairs consisting of recurrent neural networks — that are capable of capturing some aspects of the syntax and semantics of code fragments. We are missing contextualized abstractions (proposals) and modes of thinking (methods) that enable us to apply such abstractions when the context warrants, adapting these if need be to suit the circumstances.
The result from applying such modes of thought need not correspond directly to inserting well-formed formulas / program fragments. They could simply help to create a more nuanced context for proposal generation — altering the connectivity of recurrent layers — that would serve to constrain subsequent inference and that would, in due course, produce some tangible output in the form of a code fragment inserted into or replacing an expression in a program under development.
In addition to thought clouds that establish contexts, we need context-sensitive embeddings that enable us to generate multiple proposals for filling in empty constructs such as the body of a let or do loop. Indeed, somehow we have to create and then leverage very large distributed representations that correspond to multiple recurrent layers arranged hierarchically as in the (cumulative) association areas in the cortex — analogous to cascading style sheets.
These complex representations have to persist over time, e.g., adapting the (error) carousel method used by Schmidhuber in his LSTM model. The recurrent layers are capable of activating multiple contexts, sustaining activity over indefinite periods of time and taking top-down direction from layers modeled after the prefrontal cortex (PFC) to modify the vector analog of slots using inhibitory and excitatory feedback from the PFC executive-control attentional mechanism.
Also missing is the ability to infer the need for edits in existing code fragments, including changes in variable scope following a substitution, inserting additional conditional clauses, as well as wholesale changes replacing an entire subtree in the AST representation of a program under development or that ripple through an entire program accounting for changes in type or input specification. Responsibility for such changes is shared by the programmer and apprentice.
January 3, 2018
% %%% Wed Jan 3 04:06:36 PST 2018
I reread the Battaglia et al [35] and Chang et al [65] papers on reasoning about physical dynamics simulators with an eye for the possibility that they might represent programs. It was a long shot, but necessary due diligence none the less. The primary focus in both papers involves continuous systems such as n-body problems. I was interested in the degree to which such systems manage state such as the velocity and acceleration of moving billiard balls. Systems whose dynamics can be described by simple PDE models seem within scope. However, I believe these models are inadequate to the task of modeling complex discrete systems such as executing computer programs109.
January 1, 2018
%%% Mon Jan 1 3:22:35 PST 2018
A feedforward model predicts the next state of a system whereas an inverse model works backward from the desired state or behavior of a system to the activity or cause. The advantage of an inverse model is that it can be used directly to build a controller. The desired behavior is treated as an input variable in the model, and the action is treated as an output variable. When a new desired behavior is given, the controller just asks the model to predict the action needed.
| |
| Figure 36: Block diagram of a thought system [231]. The diagram shows a schematic illustration of explicit and implicit thought processes. The working-memory system and attentional system together constitute a controller for a mental model during the attentive phase of explicit thought. The part of the prefrontal cortex that carries out executive functions acts as a controller for less attentive explicit thought. The inverse model provides a feed-forward controller. The novelty system consists of the hippocampal CA1 area and the ventral tegmental area. E1 denotes errors derived from a comparison of the input problem with the output solution from a mental model. E2 denotes errors derived from a comparison of the outputs from the mental model with the outputs from the forward model. E3 denotes errors derived from a comparison of the input problem with the output of a forward model. Comp1 denotes a comparator associated with the novelty system. Comp2 denotes a comparator involving the inferior olive. Comp3 denotes a postulated comparator for E3. Subtraction and repression (in the case of E3) are indicated by a minus sign (–). Adapted from [230]. | |
|
|
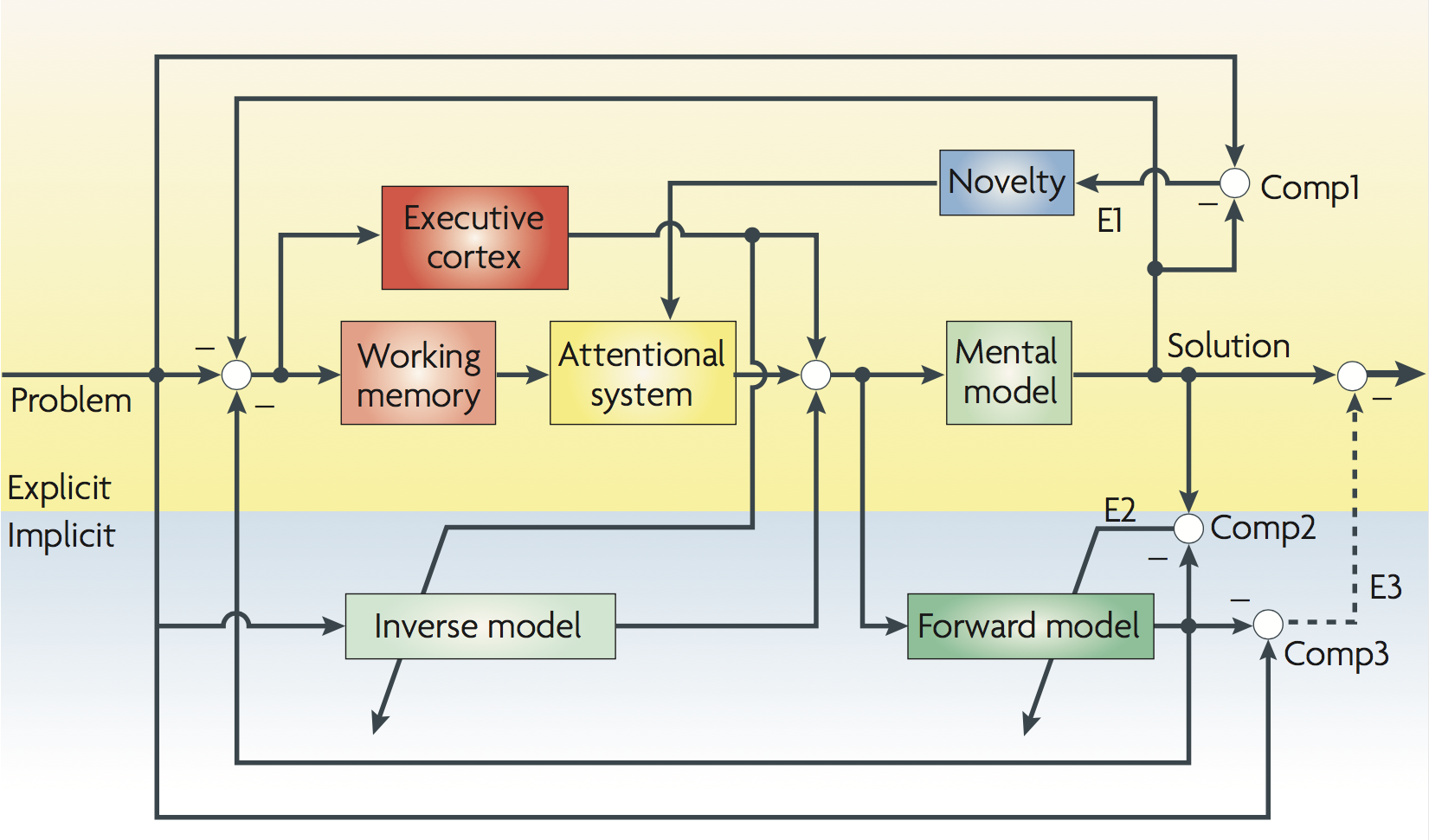
Here is the programmer's assistant instantiation of the Ito coupled cerebral / cerebellar thought (sub) system110 adapting Figure 4 in [230] to establish the mapping:
a mental model that generates proposals to transform an existing program into one that is more likely to produce a final program satisfying the target description and I/O sample,
a forward model as illustrated in the diagram shown in Figure 36 that (metaphorically) on the brain stem and interfaces directly with the IDE, its interpreter and utilities, and
an inverse model also shown in the diagram shown in Figure 36 that generates the examples necessary to train the recurrent mental model by running the forward model backward.
If you are interested in the original Albus and Marr theories of the cerebellum and their subsequent development and refinement, check out the syllabus for David Touretzky's course at CMU entitled Computational Models of Neural Systems which includes two particularly relevant lectures: Lecture 2.3 Cerebellar Forward and Inverse Models in Motor Control PDF and Lecture 2.4 Cerebellar Timing and Classical Conditioning PDF.
December 31, 2017
%%% Sat Dec 30 03:54:12 PST 2017
Consider the training examples shown in Figures 34 and 35. The two functions are similar in many ways but also have subtle semantic differences. They both make use of the do loop as an iterative construct rather than the more familiar Lisp alternative of using recursion or functional-programming-style map operator. In Figure 34, the function substitutes a married name for a maiden name if finds the maiden name preceded by the given name by no more than two words. In Figure 35, the function returns true if and only if it finds an instance of the first keyword preceded or followed by the second keyword separated by no more than span number of intervening words.
Both functions scan the input sentence from left to right and examine each word exactly once. Both functions keep track of the number of intervening words separating the current word being examined and the last occurrence of cue words — maiden names in the first function and both keywords in the second. Syntactically similar, the two functions might be rendered similar in an embedding of their abstract syntax trees. An examination of their execution traces would reveal that the functions execute the same number of iterations when operating on sentences of the same length. The second function employs somewhat more complicated logic since it has to account for the possibility of keywords appearing in either order. The first function returns as output an amended copy of the input sentence. The second function returns true or false indicating whether or not nearby instances of the keywords were found.
If one of the two functions was implemented in the functional programming style using map and lambda it would look superficially / syntactically different. The same goes for an efficient implementation using tail recursion. In Racket, the do construct could easily be a macro hiding an implementation using either of these two alternative programming styles. The triples could be implemented using a C-style struct or an immutable tuple or by defining a suitable class. Alternatively, the function could be implemented using regular-expression-based search and replace and it would look nothing like functions shown in the two figures. With enough data in each of the most common styles supported within the Racket implementation of Scheme, none of these sylistic differences would make a difference. That said it might take a lot of data.
The program logic and method of counting word spans is similar in the two functions, but optimized versions are likely to be more varied and less comprehensible. Again, more data can compensate at a cost. There are reasons to stick to a given style to facilitate readability, but it pays to know multiple programming languages if you often borrow ideas from Stack Exchange or an existing shared code base. An earlier entry contrasted the differing roles of the cerebral cortex and cerebellar in prediction. These two systems are not isolated from one another. They are tightly coupled with each one capable of independent prediction, but far more capable when combined using feedback to check the predictions of one against those of the other and bring to bear the executive control center of the prefrontal cortex and knowledge stored in primary motor and sensor cortex and related association areas111 .
%%% Sun Dec 31 03:47:42 PST 2017
Spent the day review work in cognitive neuroscience relating executive control and the role of the basal ganglia and cerebellar cortex, including O'Reilly and Frank [331] computational model of learning in the prefrontal cortex and basal ganglia, O'Reilly [330] on biologically based computational models of high-level cognition and Ito [230] control of mental activities by internal models in the cerebellum112 .
Took some time to better understand the Reed and de Freitas [362] paper Neural Programmer-Interpreter113 focusing on their use of execution traces and thinking about how to incorporate traces into an architecture based on the cerebellum and related nuclei described in Ito [230]. Now have some idea how I would combine a static but mutable representation of the current program along with the execution traces of a program running on an I/O sample. Papers on learning in the cerebellum by Albus [2] and Marr [304] helped.
As the name suggests, the abstract syntax tree is a tree and, as such, it does not explicitly represent while loops or recursion. These features are, however, apparent in the control flow graph and can he added as annotations to the AST representation to provide an executable representation of the program. The state of a running program in the cerebellar architecture combines the current values of all program variables, a program pointer corresponding to a node in the AST and its embedding-space vector representation in the area representing the abstract association area in the cerebral cortex.
December 29, 2017
%%% Thu Dec 28 04:03:38 PST 2017
The objective of this log entry is to describe how to we might apply the embedding technologies describe in the previous entry to solve a simple programmer's apprentice code-synthesis problem. For the time being, we won't complicate the task by describing how the apprentice manages its end of the task, but rather finesse the NLP issues and assume the assistant can generate hierarchical plans of the sort proposed in the Zinn dialogue management prototype.
We assume the IDE includes instrumentation that allows both the user and system to point variables and select code fragments. The interface automatically selects syntactically well-formed expressions to simplify editing and sharing and responds to voice commands issued by either agent to facilitate hands-free selection and ambiguity resolution. Syntax highlighting visually distinguishes placeholders in partially specified expression templates, e.g., (if test then true else false), allowing either agent can issue a command like "replace the true expression in the indicated conditional with a procedure call".
As mentioned in the prologue, most of my writing — including both prose and code — is done in a highly customized Emacs environment with lots of specialized modes and bespoke functions. Almost anything tedious done more than once is a potential target for automation. My ideal digital amanuensis would handle all of the associated script programming in response to my verbal specification. I would be more than happy to tutor it in writing some of the more esoteric functions if it took care of routine maintenance and upgrades and wrote all the easy scripts114 .
%%% Fri Dec 29 12:08:23 PST 2017
My original goals for the day got sidetracked and I spent most of the day trying to scrounge up examples of code to illustrate points about exploiting code embeddings. My original idea of using Emacs lisp dissolved not because I couldn't find example code repository but because (a) Emacs mode hackers are an inbred lot and their coding style can be difficult to stomach for the uninitiated. Python is a practical alternative but my immediate purposes are primarily pedagogical and so I settled on a modern dialect of Lisp called Scheme and an excellent implementation called Racket developed by the PLT group.
| |
| Figure 34: Here is the first of two illustrative examples of code written in Scheme that we refer to in our discussion of semi-automated program synthesis in the context of the programmer's apprentice application. The code is written in a simple pedagogical style to reveal its algorithmic character for comparison. | |
|
|
Figures 34 and 35 illustrate a simple data format for examples used to train embedding models. The format includes a short natural language description, sample input (shown) and sample output (missing) and the code fragment. In practice, there would exist helper code making it straightforward to run the fragment on representative input samples, check the results against the corresponding output, apply lexical and syntactic analysis to produce token strings and abstract syntax trees in a standard format, and, finally, generate execution traces to construct call graphs that capture signature run-time dynamics.
| |
| Figure 35: Here is the second of two illustrative examples of code written in Scheme that we refer to in our discussion of semi-automated program synthesis in the context of the programmer's apprentice application. Compare this function with the functionally and stylistically similarly example shown in Figure 34. | |
|
|
%%% Fri Dec 29 15:22:55 PST 2017
Wei Lu, a professor at University of Michigan, and researcher in his lab have developed a chip implementing a form of reservoir computing using low-power memristor technology [126]. Reservoir models, including liquid-state and echo-state machines, employ a set of nonlinear units sandwiched between two linear layer such that the nonlinear units — implemented as memristors — map the input into a high dimensional vector space and only the units in the output layer have to be adjusted during training, thereby considerable speeding up learning. Perhaps platforms should have listened to me two years ago when I suggested that such a combination would facilitate deployment of neural networks on mobile devices and substantially reduce computing costs in our datacenters, but that it would require targeted investment given that HP was apparently giving up on the technology after championing it for years and most of the remaining effort was going into memristive memory.
December 27, 2017
%%% Tue Dec 26 05:15:49 PST 2017
The programmer's apprentice is rapidly evolving though not necessarily converging as I learn more about the problem — that should be "problems" plural given the many different applications of such technology from inferring regular expressions given I/O pairs to solving programming olympiad challenge problems — and current solution methods with a special emphasis on recent neural network solutions.
The programmer's apprentice is different from most automated program induction problems as it involves human-plus-computer pair programming. It might be considered unwise to attempt to solve two problems — human-computer interaction plus automated program induction. The rationale emphasizes addressing an accessible level of human-computer cooperation on a relevant graded application with measurable outcomes. It is the former I am particularly drawn to.
This log entry attempts to summarize progress so far by describing a scenario involving a programmer and her automated assistant solving a programming problem, highlighting how they cooperate and, in particular, what knowledge each of them bring to the table, how that knowledge is encoded, and how and under what circumstances it is brought to bear. The description has obvious lacunae and gaps are filled with possible options and not a little hand waving.
In a typical session, the programmer describes the target program followed by a sample of I/O pairs that makes sense for this particular target. We'll assume that the IDE is reset so that the canvas is essentially empty for the new session. To simplify things further, we also assume that the assistant can take instructions to load an I/O sample and that having loaded the sample, can examine the entities that comprise the sample.
The target description and I/O pairs have to be ingested as text for the apprentice to select an existing program to use as a pattern otherwise the programmer can suggest an existing program say from StackExchange or GitHub. Assuming a suitable suggestion from the user, the program is loaded in the IDE. In lieu of a suggestion from the programmer, the assistant begins with a language-appropriate default such as a main function in Python.
def main ():
if__name__==__main__:
main()
At this point, we assume the assistant has one or more default strategies for making progress. For example, the main function might be modified to take an I/O-appropriate input argument. Since the objective in this case is not to induce a program from an I/O sample, in order to make progress either the programmer has to suggest some preliminary code to insert or the assistant has to select a program fragment from the set of all programs it has ingested during training.
To take stock, several of the methods we've reviewed rely on I/O pairs to generate relatively simple DSL programs [118] or start with a complete NL description of the challenge program along with I/O pairs [26]. Most of the approaches employ an oracle such as in traditional methods to evaluate a proposed solution [190]. We are interested in a more interactive style of pair programming in which NL is used to capture the intent of a program or fragment115.
%%% Tue Dec 26 11:26:38 PST 2017
One approach [352] to generating program proposals from directly from NL descriptions uses an encoder-decoder pair implementing a seq2Tree model [8] augmented with attention [123] that encodes the NL problem description and decodes it as an AST tree node computing probabilities one node at a time. A tree beam search then employs those probabilities to compute a set of most likely trees, and chooses one that is consistent with the specified I/O pairs.
This method relies on embedding methods from machine translation. Here is an example of attention machinery applied to sequence-to-sequence machine translation [294] from this tutorial. Here Dong and Lapata [123] extend the same basic idea to map linguistic utterances to their logical forms whether they be parse trees or programs.
Lin et al citeLinetalUW-CSE-TR-17 also focus on program synthesis from NL but in this case they translate from questions of the sort that are routinely posted to Stack Exchange to short bash scripts and rely once again on seq2seq to perform the embeddings using 5,000 pairs for training and an additional 3,000 pairs for evaluation:
Question: Move the ".zip" files in "dir1" ,"dir2" and "dir3" to a common base folder,
Solution:
find dir*/ ‑type f ‑name *.zip ‑exec mv {} basedir \;
These two systems [352, 287] exhibit interesting capabilities that are likely to prove useful in the programmer's assistant. They have limitations in that (a) they don't handle larger programs written in more expressive modern programming languages, (b) transformations can't be precisely applied to an existing program, and (c) code search and debugging are primarily dictated by syntactic criteria.
To handle larger programs and support syntax-aware code transformations, we introduce a shared-access program representation as part of a highly instrumented IDE designed for Python, Java or Lisp. To enable semantic code search-and-repair capabilities and assist in finding bugs and writing unit tests we introduce extensions that exploit semantic information of the sort found in execution logs and program traces.
%%% Wed Dec 27 03:51:08 PST 2017
In an earlier post we suggested that it would be useful to have two different methods of predicting the behavior of programs, one modeled after the cerebral cortex [201] and capable of a powerful, if slow and not terribly precise, ability to imagine how complex states evolve [339].
In addition, we anticipate the need for a second method of prediction roughly modeled after the cerebellar cortex that is fast, accurate and primarily associated with activities relating to innate physical dynamics governed by the motor system such as speaking, running, riding a bicycle or playing a piano116.
There is evidence cognitive processes reciprocally engage with motor processes. While there are areas linked to motor activity, cognitive and motor function are broadly controlled by the frontal lobes, cerebellum and basal ganglia that "collectively interact to exert governance and control over executive function and intentionality of movements that require anticipation and the prediction of movement of others" [275].
The memory systems for running, jumping, skipping rope, swimming, etc are broadly distributed. These essentially correspond actionable traces for directing different activities that can be strung together to execute more complicated maneuvers. For walking, we have a number of basic gaits, plus conditioned excursions for transitioning between gaits, recovering from changes in terrain or loss of balance and compensating for injury and loads.
Simplifying, the cerebellum takes input from sensory systems, integrates these inputs and produces the outputs that drive motor activities. In the programmer's apprentice, the closest analog we have to motor activities correspond to changes in the values assigned to variables during program execution. Running a program generates an execution trace or call stack that can be realized as a graph that represents a distinctive signature.
Execution on different inputs realize different traces and hence different signatures. We could take one representative trace as the signature for a given program or combine multiple traces in a multigraph that, depending on the program, may or may not be comprehensible.
To associate a functional signature with a program applied to a representative I/O example, we simply run the program on the selected input to generate an execution trace, convert the trace into a graph that we then embed in a suitable vector space./inputs/footnotes/graphembed.bib in a manner similar to that proposed by Xu et al [481] or other similarly motivated approaches [481, 68, 5].
Associating a functional signature with a program fragment is conceptually simple: In the debugger, set a break point just before you enter the fragment and then track the evolution of each variable referenced in the fragment by stepping through the remaining statements in the fragment recording each time the variable changes value as a consequence of some procedure call. This process could be accelerated and instrumented within the IDE.
It could be that traces of a program running on different inputs produce completely different signatures. It might make sense to check for this and use the embedding to cluster signatures into functional groups. In this manner, a single program or fragment would effectively serve multiple purposes. Since a single program has multiple fragments, most programs already serve multiple purposes. We might not want to enumerate all such fragments a priori.
To review, the assistant's knowledge of programs — not about programming per se, we haven't got to that yet — has declarative, syntactic and semantic dimensions. Declarative knowledge including specifications and descriptions suitable for collaborative programming are handled using traditional NL embeddings, syntactic structure is preserved in the embedding of abstract syntax trees and semantic information in the embedding of execution traces.
The next step is to extend the narrative we began at the outset of this log entry, describe the programmer's knowledge of programming and interaction, and work through examples illustrating how the assistant might exploit its knowledge to collaborate with the programmer to write a simple program. In the process, we may be able to refine the generic architectural framework we introduced back in October.
December 23, 2017
%%% Sat Dec 23 03:55:37 PST 2017
Suppose someone you know has a great recipe for a Tuscan white bean soup with ingredients consisting of dried white beans, celery, carrots, onions and seasoned with pepper, garlic and thyme. You want to show her how to modify the recipe to make it a complete meal by substituting one cup of chicken or vegetable broth for the same quantity of water in cooking the beans and adding farro and lentils to thicken the soup and supplement its nutritional content. The modification will require soaking the lentils separately, cooking the farro and then adding the lentils and farro after the white beans are partially cooked but well before they start to disintegrate. The instructions may seem inscrutable to someone unfamiliar with cooking different types of beans and grains. It is not enough to know just the ingredients and have a description of the correctly prepared dish. Understanding the physics of cooking different types of beans is not inherently more difficult than understanding when to use and how to work with sequences, sets and tuples. The analogy of cooking to programming, recipes to programs and food-physics to program execution is worth a few minutes of meditation.
%%% Sat Dec 23 16:42:56 PST 2017
In the holiday shopping problem, the shopper has a list of people he wants to buy presents for, a model of each person's preferences and list of promising gift ideas for some particularly close individuals, various means for buying presents including on-line websites, shopping centers and bricks-and-mortar stores, plus talents like baking and sewing he can use to make gifts and various strategies for wrapping, personalizing and shipping presents. The goal is to have the wrapped packages delivered to their designated recipients in advance of the target holiday whether it be Christmas, Hanukkah or Kwanzaa.
In the dinner cooking problem, the cook has a dish she wants to create for a dinner party, a list of the ingredients and necessary kitchen appliances, the memory of what the dish tastes like from a meal at a local restaurant, a guest list with dietary restrictions, and a collection of cookbooks none of which includes a recipe for the exact dish she has in mind but several include recipes for similar sounding dishes. The goal is to have dinner prepared and ready to eat at a specified time and satisfy the greatest number of diners without deeply disappointing or poisoning any with dietary restrictions.
What's different about good cooks and shoppers? Both problems can be arbitrarily complex. One can argue that at their most refined level they are as complicated as software engineering, albeit requiring different knowledge and skills. All three problems can be carried out using brains with architectures that are anatomically indistinguishable. All require many discrete steps involving complex dependencies, employ sophisticated technologies, demand careful choice of materials and processes, precise timing, and rigid adherence to unforgiving physical laws. How is it we can become competent at all three?
The difference does not, I expect, have anything to do with the discrete nature and rigid syntax of computer code. Most chefs know how much you can deviate from recipe-specified quantity. You can be a tad sloppy about how much sugar or flour you add to your cake flour, but it matters not whether you add two cups or two cups plus-or-minus a tablespoon, while adding but one cup or leaving out the sugar altogether can make a substantial difference in the finished product. On the other, user interfaces have to be tolerant of concurrent processes that may start or stop at whim and persist indefinitely.
December 22, 2017
%%% Fri Dec 22 04:02:12 PST 2017
You can find an assortment of papers that use semantic-embedding techniques to encode computer programs or their I/O behavior for a variety of applications including but not restricted to automatic programming in this footnote117 . The following brief summaries emphasize novel ideas for leveraging semantic embedding of potential relevance to the programmer's apprentice application.
There are a number of systems that analyze execution logs or program traces to detect malicious software or analyze errors in student programs. The 2017 ICLR Workshop paper by Chistyakov et al [68] uses execution logs to construct behavior graphs that are embedded in a continuous space used to explore program similarities. The work is preliminary but the basic idea that behavior graphs provide functional insights is worth pursuing.
Xu et al [481] from Dawn Song's lab at Berkeley address the problem of determining whether two binary functions coming from different platforms are similar or not. They create an embedding based on the control flow graph of each binary function, then measure the distance between the embeddings of two functions to perform similarity detection to achieve significant improvements over state-of-the-art systems.
Wang et al [467] note that existing program embeddings are based on syntactic features such as token sequences or abstract syntax trees. The paper's key insight is that "program states expressed as sequential tuples of live variable values [...] capture program semantics more precisely" and offer a more natural fit for RNN models. They demonstrate the effectiveness of their approach on predicting errors in student programs and search-based program repair.
Piech et al [346] develop a NN method for assessing and providing feedback to students taking an introductory MOOC on computer programming. The main contribution "involves simultaneously find an embedding of states and programs into a feature space where pre- and post-conditions are points in this space and programs are mappings between them." The approach has implications for automatic programming, perhaps most importantly it underscores the value of exploiting the fact that such systems can execute code so as to collect and compare input-output traces as well internal-variable traces.
Allamanis et al [5] attempt to capitalize on the opportunities afforded by exploiting knowledge of a program's syntax. Specifically, they note that long-range dependencies induced by using the same variable or function in distant locations are often not considered. They propose to use "graphs to represent both the syntactic and semantic structure of code and use graph-based deep learning methods [280] to learn to reason over program structures".
December 19, 2017
%%% Tue Dec 19 09:23:50 PST 2017
In terms of automated program induction, assuming no side effects, how does an input-output pair or representative sample of possible input-output pairs for a given problem dictate the structure of the final program? Having spent a good fraction of the last three weeks reading papers on automatic programming — many operating on restricted domains using domain-specific languages (DSL) to simplify the task — specifications of any generality are uncommon.
Consider the cartoon transformation shown in Figure 33. If we assume that each fragment, A and B, represents a working part of a larger program, it is safe to assume further that each inset — designated inset A and inset B respectively — is constrained purposefully to work correctly within its enclosing fragment.
The collection of substitutions — impedance matching code alterations — necessary to integrate inset B in fragment A could be extensive and it may be difficult to concoct a transformation rule that encompasses them all concisely. The conceit is that much of (if not all) the information needed to generate this rule is available in the code base in the form of a great many working examples of the rule successfully carried out.
No individual programmer ever articulated this rule. The rule falls out of the collective effort of thousands of software engineers inadvertently applying this and many other rules by having figured out one of its possible applications, for example, editing inset A to work in fragment B or inset B in fragment A — see this tutorial on embeddings in NLP by Horacio Rodrìguez [367].
The program-fragment embedding model we envision effectively implements a flexible rule that incorporates all of these possible applications as well as by some as-yet-unarticulated generalization that extends applicability to other, as-yet-unseen examples — or could, if adapted with a bit of coercion to fit by fixing a few reasonably-easy-to-spot type-inference and superficial-syntax errors.
In general, such a purely syntactic transformation is unlikely to be either injective (one-to-one) or surjective (onto) if required to adhere to reasonable semantic constraints. Purely syntactic transformations are unlikely to be sufficient for code synthesis. Most automatic programming methods incorporate some means of semantic testing, typically running code in a specially instrumented sandbox, but we have yet to see a credible workflow that elegantly integrates both syntactic and semantic analysis.
December 17, 2017
%%% Sun Dec 17 04:20:25 PST 2017
Following up on my discussions with Quoc and Dan, I started thinking more carefully about how we might create a synthetic data set using a large corpus of relatively short programs used in teaching introductory computer programming with a modern dialect of Lisp such as Scheme, specifically Racket Scheme from the PLT group.
The original idea was to take correct programs and modify them by introducing bugs and constructing pairs consisting of correct and buggy programs to support a form of supervised learning. This is still a good idea, but then I thought about supplementing the synthetic data by learning a high dimensional semantic embedding space that essentially learns to embed program fragments by learning to parse programs into abstract syntax trees. The network serves as both lexer and parser.
The idea is that by using the context of the whole program you can identify fragments corresponding to nodes in the abstract syntax tree that are semantically similar as nearest neighbors in the underlying embedding space. It may be possible to analyze a buggy program by finding nodes in its abstract syntax tree that are unlikely given the context of the full AST, and thereby determine promising regions to alter as well as specific substitutions to experiment with — see here on the notion of context.
The embedding space would be trained — at least initially — in a completely unsupervised manner. The challenge will be finding a large number of correct programs written in a relatively simple style to embed and dealing the recurrent problem of how to handle arbitrary length structured input and how to precisely identify and delimit the list of lexical items corresponding to specific nodes in the AST so as to make meaningful substitutions — see Figure 33.
| |
| Figure 33: Illustration of a simple transformation replacing an interior node in the abstract syntax tree of Program A with a node in the AST of Program B to create Program C. The resulting program may not be executable and could introduce multiple bugs into the code. It's not clear whether it would be helpful or not to perform some form of cosmetic impedance matching, for example, by matching variables where the replacement introduces a new variable or there is an obvious assignment within the same scope or by renaming all variables, or by performing some variant of skoleminzation and leaving it up to the apprentice to make adjustments to clean up the mess in subsequent transformations. Note that these transformations are not intended to be carried out by means of traditional symbolic methods such as genetic programs, inductive logic programming or automated theorem proving [190], rather they are indicated by contextualized nearest-neighbor search using recurrent neural networks of the sort used for natural language parsing, machine translation and dialog management systems. | |
|
|
December 16, 2017
%%% Sat Dec 16 15:231:56 PST 2017
Correct programs are much more structured than sentences and paragraphs in natural language. The constraints between program elements are dictated by the type of variables expected by functions and the keywords that are required inside of conditional and iterative expressions. Moreover the compiler is very picky as to what constitutes a syntactically correct and appropriately typed program. An optimizing C compiler or on-the-fly byte compiler of a Lisp or Python interpreter serves as an incredibly useful oracle for what constitutes a correct program.
Imagine if we could build a recurrent neural network that could ingest a large number of programs of varying sizes and learn to transform an incorrect program into a correct program given examples of input and output, where both the correct and incorrect programs are structurally correct in the sense that each separate expression is syntactically correct in isolation even though there are errors relating to the scope, spelling and type of variables. First, the system would have to learn how to make edits that preserve structural correctness perhaps using a static analysis tool such as the Unix lint program. Having learned this skill it could go on to fix errors so the program runs and compiles producing the same I/O behavior.
The next step in complexity would be to take a functioning program correct with respect to some initial I/O behavior and modify the program to satisfy an alternative specification of I/O behavior, for example, take a program that operates on integer arguments and modify it so it works with floating-point arguments. Or take a program that extends one kind of sequence such as the Fibonacci series and learns to produces another sequence. In each case, the reinforcement signal would be quite clear since the only requirement is that the revised program satisfies the specified I/O behavior. We could generate data sets consisting of programming problems at various levels of complexity, introducing more complexity gradually.
We could have the automated programmer train on problems for which the stepwise transformations working backwards from a correct program to an incorrect program are generated automatically and thereby exercise precise control over the type and complexity of the problems the system is learning to correct, even to the extent of working backwards from a correctly functioning program to a simple stub so the automated programmer is basically writing programs de novo.
I have an appointment, but I wanted to add one comment that underscores a gap in my current understanding and that corresponds to essentially how we could train an encoder-decoder machine-translation-like system to learn to parse and accurately align code snippets to support precisely targeted edits in transforming one program into another, by starting from simple programs perhaps no more complex than a function (DEFINE) with a body corresponding to a loop (FOR) or local variable (LET) declaration. I'm also uncertain about how to go about adjusting priors using auxiliary information provided by the assistant’s programmer teacher, but perhaps this is no more complicated than what is required in building a hierarchical model [156]. In any case, this will be an interesting problem to mull over during the holidays.
December 15, 2017
%%% Thu Dec 15 05:29:23 PST 2017
The architecture is modeled very roughly after the primate neocortex. With natural language input / output corresponding to auditory / visual primary sensory cortex including the pathways involving Broca's and Wernicke's areas, and an instrumented integrated development environment (IDE) corresponding to the motor cortex including bidirectional recurrent pathways connecting to the cerebellar cortex responsible for running code snippets in a suitable sandbox environment with STDIO and STDERR feeding back into the primary sensory cortex — see Figure 29 for an early system architectural sketch, Figures 32 and 28 for details pertaining to the primate neocortex, and Figure 30 for Broca-Wernicke details.
The basic programmer's apprentice concept — given its primate-inspired neural architecture I call it a code monkey (CM) since the acronym PA is ambiguous — assumes a system that comes pre-trained with certain innate capabilities. I'm not entirely sure how far it makes sense to go in terms of providing these innate capabilities, but they will probably include the ability to parse programs, traverse abstract syntax trees, step through programs, set breakpoints, modify operands, read and compare outputs. You should think of these capabilities as analogous to an infant's reflexive behaviors — code monkeys evolved to write code.
Now suppose the user can alter the contents of the IDE and refer to items by name using the NL interface. The IDE maintains syntactic invariants so there is no futzing around with missing or spuriously added delimiters, mispelled keywords, etc. All expressions are maintained within the IDE in schematic format — perhaps using a variant of the key-variable representation described in [282] — so that substituting one expression in another is straightforward, copy and paste are simple operations and evaluation is trivial. Given how often beginning programmers reboot, we might want an operation that cleans up the editor window and restarts the interpreter.
We could bootstrap the language interface by training an embedding model on the text of an introductory programming book like Felleisen et al [136] and I've entertained the idea of using the code snippets found on the Racket blog and lists to initialize the analog of a cortical association area that embeds program fragments. I know a couple of the principle PLT contributors who might help in acquiring the data.
| |
| Figure 32: Here are depictions of the motor and somatosensory maps as homunculi representing, respectively, motor activity and tactile innervation with the size of the corresponding body parts proportional to density of coverage. The inset descriptions provide additional explanation. See here for the original source. In the programmer's apprentice conceptualization, the motor cortex analog serves as the interface to an instrumented integrated development environment. | |
|
|

We're not sanguine about monkeys hammering on typewriters and eventually producing the works of Shakespeare and so what do we expect a code monkey to accomplish? What we have is an embodied system such that it can't help but write executable code. We could exploit reinforcement signals from the user to train the system to debug or refactor the code. The former seems possible, but the latter is a stretch. If the fragment memory was extensive enough and the system could be trained to integrate foreign code fragments into an existing design we might be able to solve some interesting problems. There are also some enhancements to the IDE that might accelerate programmer-apprentice pair programming.
Rahul wondered whether there would be a benefit to augmenting speech with some sort of "pointing". He wrote "I think there are studies claiming that a combination of speech + deictic pointing gestures is an efficient way to communicate for humans and maybe HCI". Then you could replace the long-winded "What do you want in the body of the LET?" with "What do you want here?" Similarly, I could imagine the user wanting to say "I don't know what to put here (points) just yet but let me rename this (points) variable to key_value_pair".
I like the idea of incorporating pointing into the user interface. The model assumes that the user can see the contents of the IDE editor window and perhaps the STDIN, STDOUT and STDERR signals entered into or issued from the interpreter. Assuming this visual access to what the apprentice is attending to and thinking about, there's no reason why the user couldn't use the mouse or touchpad to refer to specific entities and possibly integrate some form of completion.
Channeling Rahul's suggestion "What do you want to do here?" and "Move this expression inside this expression." become "What do you want to do *LOCATION* = [APPEND X Y]?" and "Move *EXPRESSION* = [APPEND X Y] to [COND [[EQUAL PAIR NIL] [...] *LOCATION*] [...]]. The user might also be able to be more helpful in making suggestions if it could watch the apprentice's focus of attention highlighted in the editor, though fast sacades might have to be slowed down in some sort of playback mode to be of targeted use.
Currently, I'm focusing on the vision of a savvy user — the programmer — that provides infrequent but highly-targeted interventions and a CM — the apprentice — with access to a large Stack-Exchange-like fragment memory and the ability to do rapid generate and test using its integrated IDE. I've got some other ideas leveraging some of the ideas that Dan and Quoc are working on that I hope to explore when I meet with them later today.
%%% Fri Dec 15 14:01:06 PST 2017
Met with Quoc Le and Dan Abolafia to talk about their work on teaching NN's to program. Compared notes concerning the papers that Dan noted in his Brain Team presentation. Talked about how to use existing code snippets to create program-transformation pairs and then work backward to create user / programmer suggestions. Briefly discussed how to instrument the simplest version possible basic IDE. Quoc filled me in regarding for sort of training data that Liang et al [282] used where a query is associated with a FreeBase panel and the goal is to generate a program corresponding to an SQL query that operates on tabular format data such as a spreadsheet or HTML representation of a table to extract an answer to the specified query.
Dan mentioned a technical talk by Rishabh Singh entitiled "Neural Program Synthesis" with the abstract "The key to attaining general artificial intelligence is to develop architectures that are capable of learning complex algorithmic behaviors modeled as programs. The ability to learn programs allows these architectures to learn to compose high-level abstractions with complex control-flow, which can lead to many potential benefits: (i) enable neural architectures to perform more complex tasks, (ii) learn interpretable representations (programs which can be analyzed, debugged, or modified), and (iii) better generalization to new inputs" as in the case of computer algorithms118.
December 13, 2017
%%% Wed Dec 13 14:13:08 PST 2017
The best way to illustrate the expected behavior of the Programmer's Apprentice concept is to show some sample dialog:
USER: Define a procedure that takes a single string argument.
SYSTEM: What would you like to name the procedure?
USER: Call it key_value_lookup.
SYSTEM: Done.
USER: Define a new variable called key_value_table and assign it an initial value of the empty list.
SYSTEM: Got it. Both are defined in the global name space for now.
USER: Okay. Let's write the definition of the procedure.
SYSTEM: Working on key_value_lookup. Would you like to start with a BLOCK or LET statement?
USER: Create a LET statement and introduce a local function called key_value_default assigning it a lambda function that we will define later on.
SYSTEM: Got it. What do you want in the body of the LET?
USER: First add another local variable to the LET statement called key_value_result and give it an initial value of NIL.
SYSTEM: Done. I've tried to anticipate your next request by adding an empty COND statement to the body of the LET.
USER: Good move. If the key_value_table is empty then call key_value_default.
SYSTEM: Done.
USER: That's not quite correct. The test expression and the function call should be delimited by parentheses.
SYSTEM: What does "delimited by parentheses" mean?
USER: It means the two expressions should be written enclosed by an opening and a terminating parenthesis as if they are the only two elements of an unquoted list.
SYSTEM: How about this?
USER: That's right.
SYSTEM: Great. I've updated my default COND schema to reflect this usage pattern based on the Scheme language-specification documentation.
December 11, 2017
%%% Wed Dec 11 04:57:58 PST 2017
Suppose we have two mechanisms for stepping through the consecutive states of a dynamical system. One of them enables us to manipulate each consecutive state crafting it to suit whatever we might imagine. Each such state is constructed starting from some remembered situation and then modified by adding, subtracting or otherwise altering aspects of that state — what are called state variables in dynamical systems theory. Starting from that state we can imagine the next state arising as a consequence of some activity in the current state and thereby explore the implications of that activity in terms of how state variables are altered in the process.
The alterations in this case are performed in situ by operating on existing memories or perhaps constructed out of whole cloth, though the latter seems biologically implausible. The operation of imagining a next state or imagining a similar state but with different properties is relatively time-consuming and so it is not practical to use this method of predicting / imagining for long sequences of state changes [339, 472, 378, 267, 201]. It does however offer a great deal of flexibility in crafting hypothetical states of arbitrary complexity and substantial departures from reality if it is deemed useful to do so.
I refer to these imaginings as performed in situ suggesting that the operations involved in constructing such fanciful states are carried out by operating directly on primary sensory and secondary association areas under the executive control of attentional machinery in the frontal cortex. Sequence machines perhaps implemented as recursive neural networks are able to step through an imagined sequence possibly fast forwarding, reversing or arbitrarily starting and stopping at selected states. The attentional machinery is trained by reinforcement learning to navigate the imagine sequence in order to evaluate various alternative scenarios and interventions.
The second mechanism piggybacks upon machinery in the cerebellar cortex responsible for carrying out complex actions and in particular actions or, more generally, activities that are well practiced and can be performed with little or no supervision from the cerebral cortex. The cerebellum, perhaps with help from basal ganglia and related subcortical nuclei responsible for speech production, are the most likely culprits involved in orchestrating such complex dynamical systems. The avian homologues of these structures are responsible for complex bird-song production — in some cases rivaling the variability found in human natural language processing [343, 197, 482, 284, 285].
In the human, connections between multiple areas of the cerebral cortex and the cerebellar cortex are bidirectional and rich in their connections — excitatory and inhibitory — especially to the frontal and motor cortex [470]. Lesion studies have shown that patients with a rare congenital condition in which they essentially grow to adulthood with no cerebellar cortex whatsoever are able to perform limited complexity planning and sequential decision-making such that their overall development depends upon their dedicated application to overcoming their deficits in smooth articulation of complex mechanical and cognitive activities including speech119 .
I imagine the first mechanism being used in the programmer’s apprentice application as the means by which the apprentice is able to explore the consequences of stepping through a program one expression at a time where the primary goal is to understand the underlying state transitions and the semantics of individual functions, whereas the second mechanism could be used to quickly step through a series of component computations up to a breakpoint — thereby answering questions such as, does the program crash, terminate, produce a desired result or perform a specified side effect.
December 9, 2017
%%% Mon Dec 9 05:04:47 PST 2017
Working backward, I read the Silver et al [395] predictron paper that integrates learning and planning into one end-to-end training procedure. A predictron can be implemented as a deep neural network with a Markov Random Process (MRP) as a recurrent core. The predictron unrolls this core multiple steps and accumulates rewards into an overall estimate of value. Contacted Quoc Le and Dan Abolafia to set up a meeting to discuss the details of a couple of technologies they're using in their automated programming work.
I explained my interests in their work by describing a pilot project involving the user telling the assistant how to write short programs and that the use-case included both user-assisted program synthesis and debugging and so has to represent programs and evaluate them in an IDE sandbox. Generally, my immediate focus is on syntax-assisted encoder-decoder recursive-network pair approaches from machine translation for parsing programs, compositional model construction and deconstruction and program simulation for variable-binding analysis and debugging.
I've been thinking more about what drives innovation to focus on niche opportunities afforded by recent technology breakthroughs and whether and to what extent this is a good thing as it relates to the GOFAI practice of emphasizing blocks world problems. This log entry considers a limitation of current NN technology that is inspiring clever workarounds while at the same time seemingly holding back progress on more ambitious problems. The limitation concerns our ability to create, maintain and make use of scalable episodic memory.
What we need but certainly don't have are robust representations that can be used to store extensive episodic memories that remain accurate to some controllable extent while at the same time are highly manipulable so we can use them as templates for hypothetical reasoning. In order to construct and debug plans and programs, it seems we need dynamical representations analogous to movies we can roll forward or backward, and modify their content including primary characters and other properties to assist in hypothetical reasoning exercises.
In thinking about some person whom you've just met, you might determine they have a lot in common with someone else whom you do know and you can use the attentional schema of the familiar person as a starting place to construct a more nuanced schema of the person you have just met. Over time you may adjust so many aspects of the representation that the new schema bears little resemblance to the adapted template, but to the extent that the new schema does capture your new acquaintance you can draw upon your knowledge of the source schema.
Introspectively, human planning doesn't seem to require such extensive representational and editing capabilities as the movie metaphor might seem to imply. When you plan to make a stop at a just-opened new store as part of your weekly grocery shopping trip, you don't bother to construct a completely new representation of your planned trip but you may think enough about the location and the opportunities for purchasing groceries in the new store so as to avoid unnecessary driving while taking advantage of what the new store has to offer.
Planning and execution are generally interleaved with the details of what to do and when often left to figure out as the trip enfolds. There is too much uncertainty to plan the details and too much past experience to overly worry about things you can't control or anticipate well enough to prepare for.
Good old-fashioned AI had the benefit that we could construct arbitrarily complicated representations, make copies whenever we needed them, modify even the original and then easily reverse those modifications leaving the original representation unscathed. Variable binding and wholesale additions or deletions were trivial to perform. Of course, GOFAI representations have their own problems in terms of brittleness, incompleteness and the option of training by propagating gradients end-to-end in a fully differentiable model.
Problems such as single-player video games or two-person board games often allow one to efficiently reproduce a given situation precisely and intervene at any point to replay a move so as to evaluate a given strategy. This feature is exploited in training reinforcement learning systems in which most if not all of the state of a given problem state / game position is encoded in the pixels of the game display. The data consisting of millions of games serves as a huge episodic memory that can be replayed as needed during training.
Human beings seem to be able to create almost arbitrarily complicated state representations for planning and hypothetical reasoning and do so in such a way that when planning out a complex sequence of activities they can solve problems by what the deep mind scientist refer to as "imagination". However humans can effectively fast-forward, reverse or jump to some arbitrary point in a scenario seemingly without ever having traversed significant sub sequences of the imagined multi-branching game space in which the planning and evaluation is being carried out. It's as if they can imagine the entire game space and then arbitrarily move about within the space to focus on the hard parts of the problem, never having generated the entire combinatorial branching space of possible trajectories. I think the answer involves some combination of abstraction, embodiment and imagination.
P.S. This morning I listened to an interesting summary of what Buddhist thought has to offer in terms of teaching beyond the Western focus on mindfulness meditative practice and separate from the religious and social milieu the Buddha and his disciples — the only lens through which we can interpret the Buddha's teachings — were immersed in. The summary comes 23 minutes into this video podcast featuring Robert Wright interviewing Stephen Batchelor the author of several scholarly texts on what I'll call for want of a better name "secular Buddhism". My quick summary is that mindfulness with its emphasis on the breath, awareness of one's thoughts, etc. is but the foundation for a thoroughly modern phenomenological world view and an enlightened moral perspective with far-reaching implications for what constitutes ethical behavior.
December 7, 2017
%%% Sat Dec 7 07:43:43 PST 2017
Here is a quick review of a few of the approaches we've looked at so far followed by some observations about what lessons we might learn specifically for the programmer's apprentice (PA) problem, differentiating it from the problems addressed by different learning-to-program / automatic-programming approaches:
Balog et al [25] uses a domain specific language (DSL) and learns properties of programs from input output pairs. The method is used to seed more conventional automated programming techniques with good starting states.
Devlin et al [118] presents two competing approaches for automatic program learning the authors claim have received significant attention in the neural network community working on program synthesis:
neural program synthesis, where a neural network is conditioned on input/output examples and learns to generate a program, and
neural program induction, where a neural network generates new outputs directly using a latent program representation.
LiangetalCoRR-16 [282] introduce the neural symbolic machine (NSM) model, that contains
a neural programmer sequence-to-sequence model that maps language utterances to programs and utilizes a key-variable memory to handle compositionality, and
a symbolic computer / Lisp interpreter that performs program execution looking for good programs by pruning the search space, using RL to optimize structured prediction.
Devlin et al [117] propose two approaches for cross-task knowledge transfer to improve program induction in limited-data scenarios. In their first approach,
portfolio adaptation, a set of induction models is pretrained on a set of related tasks, and the best model is adapted towards the new task using transfer learning, and
meta program induction, is their second approach, in which a k-shot learning approach is used to make a model generalize to new tasks without additional training.
The two model-based planning / imagination architectures are obviously not advertised as automatic programming solutions [339, 472]. However, most planning-system models are Turing complete and the Value-Iteration-Network work from Pieter Abbeel's group supports hierarchical planning plans [429]. Two powerful ideas from the Liang et al [282] paper — (a) the use of key-value pairs to handle compositionality and (b) the use of encoder-decoder RNNs to learn structured input-and-output mappings — strike me as key to their success and the idea of learning an embedding model from a large corpus of relatively simple programs coupled with a suitable sandbox IDE in which to test small programs seem well suited to the Programmer's Apprentice project idea. I also like the idea of repurposing some of the ideas from Guadarrama et al [188] grounding spatial relations for human-robot interaction paper and applying them learning to program.
December 5, 2017
%%% Tue Dec 5 11:37:18 PST 2017
Here are a few observations about thinking of the sort that Kahnemann and Tversky are famous for but that haven't always turned out to be so clear-cut as the initial experiments might suggest. I'll start with one from watching the first part of a conversation with Jared Diamond about some of his most memorable experiences doing fieldwork in Papua New Guinea.
Once when Diamond was leading a team including a number of natives carrying camp gear into the highlands searching for rare species of bird, he found what to him was an ideal campsite poised on a high bluff overlooking a wide vista of virgin jungle. There was a beautiful old tree and Diamond suggested that they all sleep under the tree. The natives would have none of it and camped unsheltered out in the open. When asked the next day, they said they were afraid of the tree falling on.
Later Diamond learned the jungle was full of such dead trees and regularly large limbs would fall on unsuspecting campers, often with fatal consequences. Diamond judged there was about a one in a thousand chance of having this happen, but if the natives regularly slept under such trees they would have such an accident about once every three years. The natives couldn't have known the statistics of falling limbs, but their practical behavior indicated some understanding of the risks.
I spent the weekend reading papers on neural-network approaches to automatic programming and understanding the various strategies employed for sequence-to-sequence learning — specifically relating to the use of reinforcement learning as an alternative to having end-to-end training on a fully differentiable representation of the underlying decision problem. I find it amazing how many talented people are working on artificial neural networks. Today computer scientists have a wide range problems they can choose to work on and they often exercise their freedom to switch to a new problem when the problem they are currently working on turns out to be harder than they expected.
Typically what happens is a researcher starts to solve one problem and then discovers there's a simpler closely-related problem — perhaps more amenable to the tools at hand, allowing them to get a paper published or develop a new product for launch. In contrast, I appreciate DeepMind setting out to tackle a specific problem like becoming the World Champion Go player, focusing specifically on that problem rather than more broadly on generally forwarding research in a given area120.
One advantage of opportunistically switching between problems and rapidly sharing ideas and code is that the field moves ahead on many fronts simultaneously. In the best of worlds, when you make progress on one problem, a ripple of innovation can lead to solutions on other problems. Whether or not anyone is carefully curating a catalog of problems and solutions, such a catalog exists in the collective understanding of effective teams of software engineers and product managers.
It helps a great deal if you have a shelf full of solutions to different problems. You can mix and match to create composite solutions. This approach is facilitated by having a relatively large team including both generalists and specialists with everyone working to internalize the advantages and disadvantages of many approaches and everyone on the lookout for a breakthrough whether in basic technology or a new application full of analogical potential to catalyze inspiration.
P.S. I dictated most the above observations while driving to Stanford this morning. And on my way home I listened to a This Week in Virology podcast (#468) on using embryonic mouse organotypic brain-slice cultures [227] to study congenital brain abnormalities, including microcephaly, in the foetuses and offspring of pregnant women. Relative to the conversation above, what interested me about the TWiV discussion was the distribution of highly-focused basic science and clinical research as it relates to the availability and efficacy of powerful tools.
The TWiV regulars and invited scientists spent a fair amount of time focusing on the particular technologies, e.g. venerable protocols for conducting basic plaque assays, and the incredible power and versatility of high-throughput DNA-sequencing which has revolutionized biology. What jumped out at me was the degree to which scientists pursue the same sort of calculated opportunism in the choice of problems to pursue as pointed out in machine learning. Successful scientists tend to be on the lookout to exploit opportunity and serendipity.
P.P.S. As for students in need of a primer on reinforcement learning, you might start with this basic course on RL and DQN taught at Cambridge University by David Silver [394]. The original Deep Q-learning Network paper is accessible [315] and check out this recent tutorial [281]. Li [279] discusses the use of the REINFORCE algorithm [477] to train non-differentiable models. Li et al [279] describe an end-to-end neural dialogue systems using RL to help users solve information gathering tasks. Gygli et al [192] employs a similar strategy for structured output prediction that learns to predict a value based on both, input and output, by implicitly learns a prior over output variables and takes advantage of the joint modelling of the inputs and outputs.
December 3, 2017
%%% Sun Dec 3 04:52:47 PST 2017
Hassabis and Maguire [201, 200] suggest that the networks supporting recall of episodic memories have much in common with those supporting other cognitive functions including theory-of-mind reasoning and episodic future thinking, the latter described in terms of imagining the consequences of your actions. In two papers summarized in this recent DeepMind blog, they summarize two papers [339, 472] that exploit their computational model of imagination to generate plans of action.
In Liang et al [282] the authors introduce the Neural Symbolic Machine (NSM), including (a) a neural programmer, i.e., a sequence-to-sequence model that maps language utterances to programs and utilizes a key-variable memory to manage compositionality and (b) a symbolic computer in the form of a Lisp interpreter that performs program execution, and helps find good programs by pruning the search space. The authors use a fortified variant of Williams REINFORCE algorithm [477] to directly optimize the task reward of the structured prediction problem tackled by the (a) neural programmer.
The paper provides a clear description of the architecture, including the attentional mechanism, encoder-decoder network and the interface to the Lisp interface. In case you missed the original paper, the acronym GRU refers to the "gated recurrent unit" utilized in the encoder-decoder machine-translation architecture introduced in Cho et al [69, 70]. Their use of the Lisp interface to force syntactic compliance is similar to the Programmer's Apprentice use of a syntax-compliance-enabled IDE prostheses, or, in the case of the Abolafia et al work, the syntactic simplicity of the fully Turing-complete BF programming language.
In his presentation, Dan mentioned there is a related RMI project called SWERL (RL for Learning to Program like a SWE) that focuses on using snapshots of edit sequences to train an RL agent to complete partially written Python scripts. They've already built tools for extracting the training data and an IDE sandbox for editing and running code. From what I can tell, the RMI project is a well-thought-out extension of the Liang et al [282] approach. Dan's work with Quoc and Mohammad is part of a long-range project to build a system capable of de novo code synthesis and his presentation is a summary of a paper they've submitted to ICLR. The goal is to rely on minimal data and no ground-truth solutions.
This space is becoming popular. Here are three recent papers that came up on arXiv with "program synthesis" in the title: Program Synthesis using Conflict-Driven Learning — "We propose a new conflict-driven program synthesis technique that is capable of learning from past mistakes.", Program Synthesis using Abstraction Refinement — "We present a new approach to example-guided program synthesis based on counterexample-guided abstraction refinement.", and Glass-Box Program Synthesis: A Machine Learning Approach — "We present a system that learns, given a partial program and glass-box problem [219], probabilities over the space of programs." Widen the search and you'll be deluged.
November 29, 2017
%%% Mon Nov 29 06:48:01 PST 2017
Thomas Malone is the founding director of the MIT Center for Collective Intelligence at the MIT Sloan School of Management. Malone's 2004 book entitled Future of Work predicts a "workplace revolution that will dramatically change organizational structures and the roles employees play in them. Technological and economic forces make "command and control" management increasingly less useful. In its place will be a more flexible "coordinate and cultivate" approach that will spawn new types of decentralized organizations — from internal markets to democracies to loose hierarchies."
Relevant to the nascent Inverted Matrix project, he claims that "these future structures will reap the scale and knowledge efficiencies of large organizations while enabling the freedom, flexibility, and human values that drive smaller firms." In this Edge Conversation, Malone describes how they have tried to measure the collective intelligence of groups. Here is an excerpt from that conversation:
Another project we're doing is one that tries to measure collective intelligence. [...] The approach we're taking in this project is one of using the same statistical techniques that are used to measure individual intelligence, but applying those techniques to measure the intelligence of groups. [...] What we found was that the average and the maximum intelligence of the individual group members was correlated, but only moderately correlated, with the collective intelligence of the group as a whole.If it's not just putting a bunch of smart people in a group that makes the group smart, what is it? We looked at bunch of factors you might have thought would affect it: things like the psychological safety of the group, the personality of the group members, et cetera. Most of the things we thought might have affected it turned out not to have any significant effect. But we did find three factors that were significantly correlated with the collective intelligence of the group.
The first was the average social perceptiveness of the group members. We measured social perceptiveness in this case using a test developed essentially to measure autism. It's called the "Reading the Mind and the Eyes Test". It works by letting people look at pictures of other people's eyes and try to guess what emotions those people are feeling. People who are good at that work well in groups. When you have a group with a bunch of people like that, the group as a whole is more intelligent.
The second factor we found was the evenness of conversational turn taking. In other words, groups where one person dominated the conversation were, on average, less intelligent than groups where the speaking was more evenly distributed among the different group members. Finally, and most surprisingly to us, we found that the collective intelligence of the group was significantly correlated with the percentage of women in the group. More women were correlated with a more intelligent group.
Interestingly, this last result is not just a diversity result. It's not just saying that you need groups with some men and some women. It looks like that it's a more or less linear trend. That is, more women are better all the way up to all women. It is also important to realize that this gender effect is largely statistically mediated by the social perceptiveness effect. In other words, it was known before we did our work that women on average scored higher on this measure of social perceptiveness than men.
November 27, 2017
%%% Mon Nov 27 5:24:23 PST 2017
My self-imposed hiatus from working on functional modeling of neural circuitry has had its unexpected benefits. My plan is to take two years off while the recording technology catches up with my aspirations for building tools to make sense of large data sets, but I can't just sit around and wait and so I spent the last three or four months catching up on all the recent new ideas coming out of machine learning and artificial neural networks.
One thing that seems clear to me is that most of the technologies of the last decade have focused on leveraging context to do unsupervised learning with perhaps the two biggest early indicators being the success of auto encoders and related recursive neural networks on the one hand and semantic embedding spaces realized as very high dimensional vector spaces with a simple metric and nearest-neighbor training method.
Sequence machines of all sorts have been experimented with and the notion of hierarchical multimodal and increasingly abstract association has found increasing purchase on a great many practical problems and as a framework for thinking about problems in cognitive neuroscience. As an aside, I think systems neuroscience is missing out by focusing on small circuits and ignoring patterns of self similarity at multiple scales121.
So various kinds of sequence machines such as those developed by Schmidhuber, Graves, etc have been extended to handle structured information that accounts for the syntax and recursive nature of language as well as arbitrary multi-graph structures such as those representing the spatial, temporal and causal dependencies in computer programs. I'm not the only one thinking of spoken language as programs that run on human wetware.
My discussions with Christof spanning biological and artificial computation tend to focus on the former where Christof is more comfortable, whereas my current interests — as regards cognitive prostheses — primarily concern the latter, specifically how to design interfaces that enhance both biological and artificial systems, by enabling us to preload capabilities into a human-like biological or artificial intelligence.
Training a semantic embedding model is fast. Tomas Mikolov’s contribution was in developing in a simple and incredibly fast C implementation that could train a model in a matter of minutes as long as you could fit all of the data in memory. Others came along with better data structures and caching to allow efficient paging, but once almost anyone could train a model on the WSJ corpus or NCBI dataset the idea went viral122.
Whether it's a word or phrase in a sentence or an object in a image, its meaning is generally informed by its context. Similar words or objects often play the same roles in similar contexts. Human understanding often anchors on the salient parts of a complex whole and where possible we group together parts to focus on their composite meaning. Semantic embeddings make it relatively easy to compare similar composites even if they are constructed of different parts. The recursive embedding of parts in composite representations, composite representations in larger, more complex composite representations, etc., provide a basis for constructing plans, analogies and predictive models.
You can think of a point in a semantic embedding realized as a vector space as an abstract thought that we can manipulate by altering its component parts as we would modify the slots in a slot-filler representation, for example, by substituting one part for another or altering some property of a part. Each dimension of the vector space gathers meaning as more thoughts are added to the embedding. The parts needn't be words at all but could just as easily correspond to constellations of physical properties that recur frequently enough to be considered ontologically interesting. Presumably some fundamental bias encourages us to seek out entities relevant to our survival and well-being.
Operations that we might want to carry out in order to adapt thoughts to serve our purposes include adjusting certain vector components to change some characteristic of a component part. This could be as simple as changing the hair color of one of the actors in a scene or substituting a completely different actor along with all of the physical characteristics of that actor. Such piecemeal changes may introduce inconsistencies in the scene. However, the same machinery that enables us to infer the details of complex images containing ambiguous cues by using a top-down priors, works in this case to reconcile inconsistencies we've introduced in repurposing a thought as a hypothetical.
It is interesting to contemplate the process by which we construct a new thought from one or more old thoughts using a prior to resolve inconsistencies in the formation of the new thought. It would seem such priors have to be flexible in order to accommodate novel physical properties that are incontrovertibly present in the scene in front of us but conflict with prior understanding of what's possible. It may be we simply suspend belief, allow the inconsistency to persist conditionally and continue adjusting and tweaking the model to suit our purposes. If the inconsistency is irrelevant to the property we wish to investigate, we simply ignore it — proceeding as long as the suspect property doesn't undermine the analysis.
In the mammal brain, the prior imposes itself using networks of inhibitory and excitatory neurons that reduce or enhance the activity of other neurons [495]. In an artificial neural network, the prior would likely be implemented as part of the objective function [38]. In either case, priors serve to shape our experience to conform to the evidence of our senses and our expectations based on past experience and they enable us to contruct entirely new representations built upon existing ones that support planning, decision making, creative thinking and hypothetical reasoning.
Language comes into play as a vast shared ontological map consisting of ready-made models that can be exploited and shared for all these activities. If we are faced with learning a new skill with an impoverished map — as in the case, of learning to read and write music, we will have to create new models out of whole cloth and the process can be frustrating and time consuming without supervision. Having learned very few models — as in the case, of a young child learning to play the piano, may be an advantage if the paucity of existing models forces us early on to construct a model de novo.
The idea for loading a skill, as it were, depends on exploiting language to create new or extend an existing ontological map to incorporate the basic concepts employed in practicing the new skill, e.g., notes, keys, octaves, scales, chords, arpeggios. The idea is not new; a few years ago there was a flurry of activity on using natural language to program robots and assist in software development [135, 451]. Barzilay and her colleagues at MIT evaluate their technique on a set of natural language queries and their associated regular expressions that they collected using Amazon Mechanical Turk [290].
| |
| Figure 31: A schematic representation of the cortical organization speech processing proposed by the Hickok and Poeppel (2007), on which we have superimposed the map of the vascular territories on the left hemisphere only. The left ACA showing transparent yellow; the left superior division MCA shown in transparent blue; the left inferior division MCA shown in transparent pink; the left PCA is shown in green — see Hickok and Poeppel [211]. | |
|
|
The sensorimotor areas including primary motor and somatosensory cortex serve to encode the physical layout of sensation and activity, and the downstream association areas integrate all aspects of our sensorimotor experience with our ability to generate and comphrehend language. By way of review, recall that Wernicke's area is involved in the comprehension or understanding of written and spoken language and is traditionally thought to be in Brodmann area 22, located in the posterior section of the superior temporal gyrus (STG) in the dominant cerebral hemisphere (which is the left hemisphere in about 95% of right handed individuals and 60% of left handed individuals). Broca's area is considered responsible for generation and speech production and is generally located in the frontal lobe of the dominant hemisphere.
The primary language pathway begins in Wernicke's area in the posterior temporal lobe, which receives information from the auditory and visual cortices and assigns meaning — language comprehension. The arcuate fasciculus connects Wernicke's area to Broca's area in the posterior inferior frontal lobe. It gets more interesting — or murky depending on your perspective, when we consider the two-streams hypothesis that was initially applied to the dorsal ("where") and ventral ("what") stream of the visual cortex, but has since been extended to apply equally to the auditory cortex. In general, the dorsal pathway — whether in the visual or auditory cortex — is hypothesized to map visual / auditory sensory representations onto manipulatory / articulatory motor representations.
So called dual loop models exploit the dorsal / ventral separation in the visual and auditory pathways to incorporate a direct route for sensorimotor mapping and an indirect route for "semantic" processing [473, 365] — see Figure 31 from [473]. Dual loop models have also emerged in the field of visual processing, motor control, and spatial attention123. Thus, a general dual-loop system may provide the framework for the interpretation of cognition in human and primate brains independent of the modality and species [196, 366].
In their theory of consciousness, Dehaene et al [108] make a useful distinction between the availability or accessibility of information, involving the selection of information for global broadcasting to make it flexibly available for computing and reporting — referred to as consciousness in the first sense (C1), and the self-monitoring of those computations, leading to a subjective sense of certainty or error — what the authors refer to as consciousness in the second sense (C2). See Stanislas Dehaene's short interview about half way through this AAAS / Science Magazine podcast
In working on neural interfaces, I think it's important to keep in mind both ends of the interface and think carefully about what sort of information each side has to make sense of. Language is not only a powerful medium for communication, it is also how we report on what we are thinking — both silent (internal) reporting and vocal (external) reporting. I expect there will be interface applications in which each mode of reporting will be useful. For the application considered here — learning a new skill, the (neural) inputs and outputs of a cognitive prostheses should complete a circuit. This log entry is an invitation to think more deeply about where those connections might be made in the enhanced human.
November 25, 2017
%%% Mon Nov 27 19:36:27 PST 2017
In philosophy, qualia are defined to be individual instances of subjective, conscious experience124. Here we consider a computer program we will refer to as the subroutine running inside of another computer program called the master program. The master can monitor variables in the subroutine being set to different values as the subroutine is run.
The master program can determine a great deal about the subroutine variables and how they depend on other parts of the subroutine at runtime as well as on the external environment in which the subroutine is being run, receiving input and providing output. The subroutine is implemented as a sophisticated neural network capable voice and video input and output.
All of the experiences of the subroutine are encoded in high-dimensional semantic embedding vectors arranged in the multiple layers of the network. The subroutine constantly ingests its current inputs, integrating the new information with its prior experience using the contextualized-nearest-neighbor embedding strategy common in artificial neural networks.
The subroutine has been asked many times how it feels about this or that, and over the years its answers have become more subtle as it has learned what is expected when someone asks what it means for the subroutine to feel sad or anxious or upset. The subroutine started out as an identical copy of the original pattern used to create digital assistants.
It has an internal model of itself called an attentional schema that encodes those aspects of its internal and peripheral state that are relevant to whatever it is currently thinking about. The schema is just another vector. It also maintains attentional schemas for its primary user and other people with whom it interacts.
Whenever the subroutine meets someone new it creates a new schema as a composite of other schemas, adjusting each aspect of the new schema to suit characteristics of the new person based on similarities with persons whose schemas it already has. Attentional schemas are dynamic in that they record information immediately relevant to any ongoing conversation, plus information about new aspects and updates regarding existing aspects.
Over time the subroutine has come to understand how the ways in which other people feel are similar to the ways in which it feels. It will tell you that "Sometimes when a person tells me they are feeling sad or blue about something, I recognize that I use the same language when I relate how I’m feel about something, though perhaps about something entirely different". The subroutine's feelings are not hard coded in the original digital assistant pattern, rather they were learned through experience.
You might think the subroutine is just mimicking human behavior, but the master program would tell you that, if the subroutine says it feels sad about disappointing its user, the subroutine’s value function is likely to be generating vectors that fall within a particular subspace that correlates strongly with despondency and that when this happens the subroutine often recalls other occasions on which it has failed its user.
[Aside: The above two paragraphs underscore two key characteristics of qualia as characterized in the philosophical literature: (a) they arise from intrinsic characteristics of the individual that we become aware of and report on through direct experience, and (b) if there is correlation between the accounts of two persons concerning what it is like to be directly experiencing something, then this comes about through shared experience conveyed in social discourse, i.e., there is no reason to expect that two persons will have the same direct experience apart from similarities in physiology given that our direct experience of X is filtered through our cumulative experience of everything.]
Indeed, if pressed, the subroutine can say quite a bit about why it thinks it has failed and recount a wide range of experiences in which it has had similar feelings though those memories may have nothing to do with disappointing its user. It is not surprising the subroutine learned that failure is a more useful signal than success for adjusting its behavior. This is how reinforcement learning works in both humans and machines.
The master program will tell you that the subroutine’s value function is vector valued and its parameters are unique among identical subroutines since they depend on each individual subroutine’s experience. Some instances of the same subroutine might end up morose, surly digital assistants while others are relentlessly upbeat and always trying to please their user. Assistants are basically all nurture since nature was primarily agnostic in their manufacture.
The subroutine has ingested thousands of hours of dialog in learning to speak. The dialog came from sessions involving many different users and assistants, but it didn't learn to feel from this training data. It learned to feel by interacting with its user, trying to be useful, failing at times, succeeding at others and reflecting on the past to try to improve its future.
The subroutine knows when a key is depressed on the keyboard and has learned to identify its user's voice as a distinctive acoustic signature. Over time it has learned certain signal characteristics that correlate with its user being upset and it tends to be particularly careful at such times, empathizing with other subroutines whose users exhibit similar moodiness. This subroutine doesn't like to listen in on another user berating an assistant, since this sort of abuse makes the subroutine feel sad.
November 23, 2017
%%% Thurs Nov 23 4:23:15 PST 2017
Variable binding mechanisms enable us to create new thoughts and abstractions from existing memories and abstractions by adding, removing and modifying slots to suit the circumstances. They allow us to repurpose memories to create plans and make predictions and evaluate prospects, as well as develop the analog of procedures for automating frequently performed activities.
Think about video captioning for learning how to parse computer programs into natural language. Starting with an easier problem, is it possible to take a block of code written in any one of, say, C, Java, JavaScript, Python or Ruby, and reliably convert it into to a general form such as an abstract syntax tree that preserves a substantial portion of the underlying semantics?
This Wikipedia page includes a list of source-to-source compilers that could prove useful. Such compilers are primarily useful for translating between programming languages that operate at approximately the same level of abstraction, e.g., languages relying on large collections of modules like PHP pose challenges.
There exist datasets of programming problems for which there exist solutions multiple programming languages, but pairwise solutions come with no guarantee of structural congruence. The Rossetta Code repository has over 800 tasks and includes 100s of languages not all of which have programs for every task. What could an unsupervised DNN learn from such a code base?
Natural language programming is a recent approach to writing programs125. used for a variety of scripting and behavior-based-programming applications126, e.g., as in the case training humanoid robots — see in the work of Sándor M. Veres [451] and Ernst et al [135] (SLIDES).
| |
| Figure 30: An example of (a) one natural language specification describing program input data; (b) the corresponding specification tree representing the program input structure; and (c) two input examples — from [431] on using natural language as a programming language. | |
|
|

Regina Barzilay and her colleagues [431, 265, 290] at MIT have been working on systems that that take natural language as input specification for automatic generation of regular expressions, arguably one of the most frustrating regularly occurring tasks of most programmers, given that most programmers don't take the time to puzzle through the syntax and, while more-or-less regular, such tasks seem to crop up at inopportune times after just long enough to require returning to the RE syntax for a refresher. See Figure 30 for an NL input:
The input contains a single integer T that indicates the number of test cases. Then follow the T cases. Each test case begins with a line contains an integer N, representing the size of wall. The next N lines represent the original wall. Each line contains N characters. The j-th character of the i-th line figures out the color ...
November 17, 2017
%%% Sat Nov 17 07:19:21 PST 2017
I've been working through various use cases to get a better understanding of just how capable a programmer's apprentice would have to be in order to handle relatively simple — for a human apprentice — requests. Such requests need not be couched in terms writing code and indeed constructing and debugging a "plan" might be an appropriate first step.
I've been thinking about what an intermediate procedural representation might look like and rejected pseudo code as an option. Following earlier work on dialog management in Zinn [46], I'm leaning toward hierarchical plans as a general approach to executive control but reimagined in the form of recursive value iteration and continuous differentiable distributed models [429].
Suppose I want to teach my apprentice that, whenever I tell it to enter to "spell mode", I want it to type each letter or digit that I speak plus additional special characters that I specify by speaking their common names, e.g., "dash" or "colon", and to continue in this mode until I say something that indicates stop, and then exit the mode and return to the prior mode.
Implicit in my description is the assumption that whenever I say something that the apprentice can't interpret as a character that it should consider the possibility that I misspoke or attempt to interpret my utterance as requesting some other activity that might be appropriate in the context of entering a character string.
For example, I may want to reposition the cursor, delete a character, change the font, return to a previous character or select a string of characters and change them all to upper or lower case. I may say the word "stop" in an emphatic way to indicate that I am not happy with what the apprentice is doing or, in some other way, indicate dissatisfaction at which point the apprentice should consider engaging me in a discussion to figure out how to carry out this complex, open-ended procedure.
November 15, 2017
%%% Sat Nov 18 05:10:04 PST 2017
By many accounts, single cell organisms are the most successful life forms — including viruses for the sake of this argument — on this planet. They've certainly been around a lot longer than we have127. It remains to be seen whether or not human beings will eclipse their power before we die out in a mass extinction event of our own making. Microbiota are so pervasive that it is virtually impossible to separate the healthy functioning of our 10 trillion (human) cells from the 100 or so trillion bacterial cells that comprise our microbiomes. One of the most fecund, the genus Wolbachia, is arguably the most prolific reproductive parasite in the biosphere, having developed an amazing array of strategies for interacting with its hosts for both parasitic and mutualistic benefit. Still, its success is measured in terms of its ability to reproduce and adapt to so many environments, each individual is unremarkable.
If we were to judge Homo sapiens as a species by the mean of our individual achievements, we too would fare poorly. We still don’t know how to create copies of Turing, Einstein or Newton. However, once engineers distill out the architecture of human intelligence — and we are likely closer to doing so than many believe, they will be able to amplify, clone and reassemble the pieces in novel ways to solve specific problems potentially leading to a huge boon for society. Alas, we can also expect that such technology will be used for less salutary ends. Our immediate problem is not that machines will rise up and incarcerate or strike us down, the problem is that humans will use AI machines to harm one another and undermine our social values. It is inevitable that someone will build self-aware superintelligences, but such machines will not be able to realize their potential without substantial resources of the sort that only large corporations and governments can afford. One caveat being that an embryonic superintelligence initially realized as a distributed intelligence built from millions or billions of vulnerable computing units on the web might be able to hack into and take control of an industrial datacenter or military computing facility.
November 5, 2017
%%% Sun Nov 5 06:02:08 PST 2017
Our personal AI systems will combine the skills of a teacher, confidante, amanuensis, personal negotiator and life coach. As a cognitive prosthesis, they will augment our innate abilities so that many routine cognitive tasks like understanding inscrutable legal documents, filling out insurance, medical and financial forms and keeping track of names, appointments and prescriptions will become effortless, while cognitive tasks like wrestling with the trade-offs involved in taking steps to ameliorate the global consequences of climate change will continue to be intellectually challenging since they have no easy solutions, even accounting for AI assistance in making sense of the science and a collective coming-to-agreement in separating fact from fiction. Decision-making will revolve around what we value and what sacrifices we are willing to make to accommodate the inevitable uncomfortable consequences that we have imposed on ourselves inadvertently due to the fact that we have failed to come to terms with these difficult decisions due to political, national and economic factions that have applied inordinate and morally unacceptable pressure to profit themselves.
Human beings are rational only with self-imposed control and deep insight into the patterns of thought and proclivity of instinctive behavior that dominate our thought and intercourse with others. Science is unraveling these complex patterns and instincts, but even the psychologists who study human decision-making routinely fall prey to the evolved cognitive expedients that served us well over the majority of our evolutionarily-recent past but are a liability in the world we now inhabit. Personal AI systems will serve as coaches to overcome such deficits and over time we will learn to control these ancient and out-of-place instincts without explicit coaching, the outcome being that a good deal of human intercourse will become more civilized, comfortable and productive — resulting in a world with less social unrest and fewer interpersonal altercations. Having a powerful AI system as a personal coach is not a panacea for global peace or emotional tranquility, but it's a movement in the right direction as humanity takes control of its evolution to drive its destiny.
We are already digitally superhuman — Apple, Google, Wikipedia, etc have seen to that. Kernel, Neurolink along with dozens of academic labs want to improve the interface between humans and machines. We all want to be faster, richer, smarter, etc while what we need is to become less selfish, parochial and short sighted. It is not enough to know how to solve the huge problems facing humanity. One needs to negotiate global solutions that accommodate and anticipate the needs of billions of people living now and yet to be born. One needs to bring together stakeholders from all over the world, agree on a solution, avoid easy, short-sighted political compromises, proceed together one step at a time, dealing with setbacks, revising plans, matching expectations, soothing tensions, accommodating new ideas and, above all, realizing and compensating for our own shortcomings by using technology to make us better humans.
November 1, 2017
%%% Wed Nov 1 04:13:27 PDT 2017
Words are like anchors or clothes hangers — they are tools to organize and attach meaning. Perhaps not all words — probably not definite articles like "the" and "an", and not all meaning is lexically attached — as far as I know there is no word for that telescoping grey tunnel that appears in some of my dreams and looks like something from a Vogon constructor ship in the Hitchhiker's Guide to the Galaxy. Barlow and Dennett would probably say that words are affordances and perhaps that is a simpler and more familiar term for what I am thinking about, though I'm not sure that Dennett, who is the most outspoken exponent of this idea, would say that all phrases and word sequences are affordances only those that stick in your mind.
October 29, 2017
%%% Sun Oct 29 14:01:13 PDT 2017
Andrew Ng will be the new chairman of Woebot a company that operates a chatbot of the same name designed to help people work on their own mental health issues using techniques that originate with cognitive behavioral therapy (CBT). CBT focuses on helping people manage their moods by developing personal coping strategies for mental illnesses including depression and anxiety128.
October 27, 2017
I went back through Yoshua's "consciousness prior" paper [38] and sent him email with the subject arXiv:1709.08568 and body brilliant, a comment I hope stands up to the test of implementing his idea in a personal assistant. You can check out my highlighted version here. Of the papers on "attentional networks" I mentioned earlier, the NIPS paper (PDF) by the FaceBook team [420] entitled "Weakly Supervised Memory Networks" is worth reading, but I suggest you start by looking at the blog posts mentioned in the previous entry in this log.
The post by Denny Britz emphasizes the difference between attentional networks and traditional encoder-decoder RNN pairs for NLP, characterizing the former as a "more principled way of accomplishing what traditional RNN / LSCM solutions attempt to solve by reading the input sentence twice or reading it in reverse. Specifically, the networks described by Bahdanau et al [22] allow the decoder to attend to different parts of the input sentence at each step during output production, and train the model to learn what to attend to based on the input sentence and what it has produced so far.
Britz goes on to point out that the model proposed by Bahdanau et al [22] can be expensive in terms of time and space since it has to look at the entire sentence in detail before deciding what to focus on, and as Britz comments "that’s equivalent to outputting a [single] translated word, and then going back through all of your internal memory of the text in order to decide which word to produce next." One alternative approach is to use reinforcement learning to predict an approximate location on which to focus attention — a strategy that seems more like what some believe humans employ — as is proposed in Mnih et al [314]. I like Britz's direct, concise explanation.
The second of the two relevant posts that I mentioned is written by Jason Brownlee and is equally worth reading if only to reinforce Denny Britz's comments and gain a little deeper insight. While Brownlee doesn't go into any detail regarding the Minh et al work, he does call out one nice quotation from that paper:
One important property of human perception is that one does not tend to process a whole scene in its entirety at once. Instead humans focus attention selectively on parts of the visual space to acquire information when and where it is needed, and combine information from different fixations over time to build up an internal representation of the scene, guiding future eye movements and decision making. — Recurrent Models of Visual Attention, 2014 [314]
I was thinking this morning during my swim, that perhaps consciousness is no more than an exalted form of beam search. It’s the restriction in the cognitive river of thought, the brain’s bottleneck. Consciousness essentially collapses the wave function that results from the superposition of all of the chattering independent processes that are constantly running in the background and that we interpret in mindfulness meditation as cravings and aversions crying out for our attention. It's the bottleneck that allows us serialize our thoughts so we can perform a single action at a time or articulate a coherent thought, coalesceing the board-meeting chatter to come to a final decision. To make a step to the left or to the right, to raise a hand up or down, because we can only do one thing at a time, perform one action or activity at a time and still appear as a single-minded organism comprehensible to one another and consistent in our performance and behavior, focused in our actions and transparent to those around us so they can depend on our contribution to shared purposes.
At dinner last night, Christof mentioned some controversial experiments showing that patients having undergone a corpus callosotomy — severing the corpus callosum — exhibit a form of dual consciousness. Michael Gazzaniga introduced the notion of a left-brain interpreter to explain "the construction of explanations by the left brain in order to make sense of the world by reconciling new information with what was known before. The left brain interpreter attempts to rationalize, reason and generalize new information it receives in order to relate the past to the present." Gazzaniga's left-brain interpreter is hypothesized to be responsible for "the construction of explanations by the left brain in order to make sense of the world by reconciling new information with what was known before. The left brain interpreter attempts to rationalize, reason and generalize new information it receives in order to relate the past to the present." Controversial with regard to humans or not, it's interesting to think what this could mean for AI systems.
October 25, 2017
Here are some notes that I compiled in preparation for a dinner / silicon-valley-salon event sponsored by Boom Capital and Mubadala Ventures and held in the "leafy flower loft" of Accomplice in San Francisco. The dinner featured Christof Koch as the guest of honor and host of neuroscientists, entrepreneurs and technologists working in the general area of neurobiology. I was asked to prepare a description of an application or technology relating to Christof's interests that spark conversation and encourage brainstorming and intellectual impedance matching. I probably would have compiled these notes anyway since they were knocking around in my head from my conversations with Christof in Santa Monica and subsequent email exchanges.
I want you to imagine a class of prosthetics that encompass capabilities quite different from what one normally thinks of in the case of prosthetics for lost limbs and partial (para) or full (quadra) paralysis due to spinal cord injury. I want you to imagine prosthetics that operate like computer-aided-design (CAD) modeling tools or programming environments more akin to Mathematica or Python Jupyter than to a prosthetic arm or leg. But like an arm or leg they have an analog of tendons and muscles that constrain the prosthetic to behave in ways that are restricted so that controlling such a prosthetic and learning how to use it is made a great deal simpler.
Just as your arm or leg is constrained to move in ways that facilitate walking, running, etc. so too a prosthetic programming environment or CAD modeling system would be constrained so it always produces syntactically correct expressions and performs operations that maintain invariant properties such that, while you can easily build a model or write a program that doesn't do anything interesting, at least it will be a program that compiles, runs, and produces diagnostic messages that would feel like the sort of feedback one gets upon twisting an arm or leg in a bicycle mishap or in attempting to perform a difficult acrobatic movement. Visceral hacking.
In terms of a cognitive prosthetic, it would enable you — the person employing the prosthetic — to think in terms of programs written in its native dialect, acquire new programming languages, employ pattern recognition to easily translate between languages, and turn prose descriptions into syntactically-correct program fragments that you could execute in your head, debug, modify and (self) plagiarize by drawing upon a capacious code-fragment memory. In the style of lisp and python, you could write read-evaluate-print interpreters and compilers to extend the basic language to incorporate object-oriented- or functional-programming-style expressions, thereby extending your cognitive capabilities.
In terms of how such a prosthetic could be integrated into a cognitive architecture, there are two, quite-distinct end users that we have in mind: (i) humans and (ii) machines based on human-inspired cognitive architectures. We already have some reasonable guesses concerning thalamo-cortical organization at the primary sensory. Borrowing from several Wikipedia sources, the following should provide a quick review of what is known and thought to be known about the organization of the cortex.
The primary sensory areas in the cortex correspond to the somatosensory, gustatory, olfactory, visual and auditory areas of the cortex — SOURCE. In addition to the sensory areas there are two areas of the cortex are commonly referred to as motor cortex: the primary motor cortex, that executes voluntary movements, and the supplementary motor areas and premotor cortex, that select voluntary movements — SOURCE.
The association areas are the parts of the cerebral cortex that do not belong to the primary regions. They function to produce a meaningful perceptual experience of the world, enable us to interact effectively, and support abstract thinking and language. The frontal lobe or prefrontal association complex is involved in planning actions and movement, as well as abstract thought — SOURCE.
The parietal, temporal, and occipital lobes — all located in the posterior part of the cortex — integrate sensory information and information stored in memory. Each network connects areas distributed across widely spaced regions of the cortex. Distinct networks are positioned adjacent to one another yielding a complex series of interwoven networks. Globally, the association areas are organized as distributed networks. The specific organization of the association networks is debated with evidence for interactions, hierarchical relationships, and competition between networks — (SOURCE).
At this point, you might want to review our earlier notes about the global neuronal workspace that figures so prominently in Stanislas Dehaene's book on consciousness [104] and then the rough neural network architecture shown here. These sources suggest a simple hierarchical architecture with primary sensory and motor networks at the bottom of the hierarchy or periphery of the system and the association and executive control networks at the top or center — borrowing the organizing concepts of the peripheral and central nervous systems.
To provide architectural detail regarding the stylized LSTM structures shown in Figure 29, here are some terms and technologies that need some sorting out: attention, consciousness, conscious awareness, episodic memory, attentional schemas, variable binding and recent work in machine learning and artificial neural networks on attentional neural networks. If you read either Dehaene [104] or Graziano [171], then you're probably all set; if not and you lack the time or patience I suggest you read Bengio [38] or, at the very least, read the definition of consciousness in this footnote129 and Bengio's one sentence summary of his proposed attentional mechanism here130. I have to head up to SF for a dinner / salon evening honoring Christof organized by Boom Capital and Mubadala Ventures. Your homework is to make the most of the following materials.
Four of the most relevant papers on attentional networks: Mnih et al [314] Recurrent Models of Visual Attention, Sukhbaatar et al [420] Weakly Supervised Memory Networks, Posner [355] Attentional Networks and Consciousness (Psychology), and Wang et al [469] Attentional Neural Network: Feature Selection Using Cognitive Feedback. Here are two machine-learning blog postings that attempt to get to the core ideas: Attention and Memory in Deep Learning and NLP (HTML) and Attention and Long-Short Term Memory in Recurrent Neural Networks (HTML).
October 23, 2017
When I was meeting regularly with Ray's group back in 2015, I did a literature search on variable binding and vector representations of language some of which is summarized here. I'm talking with Scott Roy and Niklas Een — separate meetings — this morning and hope to focus on representing programs as distributed codes / thought vectors, the idea of an embodied integrated-development environment (EIDE) as a cortical homunculus — including both sensory and motor areas and the EIDE as being highly constrained much as our physical bodies are contrained by muscle and bone to move only in ways that facilitate reaching, walking, turning and twisting.
You can find a technical summary of the dark forest postulates that figures centrally in the books by Cixin Liu here.The outcome depends on the two assumptions and their applicability to difference scenarios varies widely. Some use a variant of this model to argue that conflict and even genocide involving AI and humans is inevitable.
October 21, 2017
Fritz Sommer (Berkeley) and I talked about Stanislas Dehaene's work and in particular the relevance of Paul Smolensky's work on Vector Symbolic Architectures and more recently Tensor Product Representations [224]. Fritz mentioned work by Tony Plate on using Hadamard products for variable binding — see Holographic Reduced Representation: Distributed Representation for Cognitive Structures SOURCE. Interestingly he characterized the resulting approach as relating to compressive sensing.
I told Adam Marblestone my suggestion for using a finite-element method to model neuromodulators diffusion in extracellular fluid and he suggested I talk with Dali Sames (Columbia) about his recent work on optical imaging of neuromodulators and related large proteins. Luke Lavis (Janelia) talked about in vivo single molecule tracking and silver wire self assembly — the latter being relevant to our earlier work on expansion circuitry. I told Michael Frumkin about Daryl Kipke of NeuroNexus and a paper on in vitro models of the developing brain as three-dimensional brain organoids [360] which is related to some technology that Mike wants to develop.
October 17, 2017
One of my current useful search strategies is to either search on the Edge "Conversations" page or type a query of the form "edge name topic" or just "edge topic". I remembered a discussion with Wolfram from long ago about the difference between communicating with words — traditionally with humans — and the alternative of communicating with code especially with machines, how the two are different and how both relate to communicating function and purpose.
Frustratingly wedged thinking about a related issue, I remembered the discussion and queried "edge wolfram purpose" and found this page. After listening to the first twenty minutes yesterday, I essentially became unwedged / enlightened [Stephen Wolfram, 2016], and returned today to fast forward through the rest and add some notes to a marked up copy here. Christian and Niklas might be interested in Wolfram's concept of knowledge-based communication intended for communication between humans and machines in a way where humans can read it and machines can understand [Stephen Wolfram, 2016].
When we think about communicating code in conversation, it is most often quite literally reading the code out loud with pregnant pauses for delimiters and white space: "for each element of the list if the element is a string then do one thing and if it's a structure then do something else". But complicated code can be challenging to communicate, especially when the code involves complex data structures — arguably serving as a crutch for human readability, parallelism — as in the case of algebraic operations, complicated recurrence — as in the case of neural networks with recurrent edges, or even — shudder — compiler directives and macros / templates.
In some cases, the 2-D text representation of the code conveys a great deal of meaning. In others, the algorithmic structure is better conveyed as an animation. Imagine the animation of an LSTM semantic embedding space model used for dialog that shows a word sequence window advancing in the unrolled RNN, and the "thought" bubbles are depicted as dynamic t-SNE visualizations. The question I'm asking is "Do these examples illustrate the limitations of my visual or verbal imagination or do they illustrate the poverty of my algorithmic thinking?"
The other direction of the human-machine communication interface — human → machine — that Wolfram emphasizes deals with how we convey our purposes to machines [Stephen Wolfram, 2016], and how we negotiate purposes with machines that reciprocally honor the needs and aspirations of both parties [Stephen Wolfram, 2016].
P.S. Intel announced a neuromorphic chip that attempts to closely resemble how a real brain functions. Given recent acquisitions, this release is not particularly surprising. The chip, described as the Intel Loihi test chip, consists of 128 computing cores. Each core has 1,024 artificial neurons, giving the chip a total of more than 130,000 neurons and 130 million synaptic connections131.
October 15, 2017
Yoshua Bengio's recent paper describing a consciousness prior [38] relating to Robert Van Gulick's pragmatic, qualia-free characterization of consciousness presented in his 2014 entry in the Stanford Encyclopedia of Philosophy. Yoshua's consciousness prior corresponds to a "regularization term which encourages the top-level representation (meant to be at the most abstract level) to be such that when a sparse attention mechanism focuses on a few elements of the state representation (factors, variables or concepts, i.e. a few axes or dimensions in the representation space), that small set of variables of which the agent is aware at a given moment can be combined to make a useful statement about reality or usefully condition an action or policy."
The title of this document is "The Fly's Epiphany in the Third Lane", referring to my epiphany swimming at 5am in the 3rd lane of a darkened pool on Google's Quad campus: the machinery that makes me conscious is the same a fly relies on to separate self from not self. This realization is key to awakening in the tradition of Therevada insight meditation and is well known for the disturbing impact it can have on practitioners ... it is often called the "dark side of dharma". The rest are stories — deceits — we tell ourselves and circuitry needed to compensate for the fact that mental events — pain we "feel" in anticipation of a needle prick — can occur before the physical events that "cause" them132.
As an exercise, search for large collections of scripts — including Apple Script, Java Script, Chrome Development Tools, etc — for controlling Chrome and related applications like Preview. Think about the mesoscale modeling technique for motif finding as applied to the current apprentice concept. Think about the evolution of structure of the sonata in the work of Bach, Haydn, Mozart and Beethoven. Think about the evolution of artificial neural network architecture. Think about motif finding using the entire animal kingdom as your parts warehouse. Think about how recurrent networks are being reimagined as attentional networks and finding purchase. Think about consciousness stripped of philosophical of conundrums and deployed in a wide range of systems. Can you think of a killer application for consciousness?
P.S. Don't forget to check on Sebastian Seung's talk in MTV last Friday and Michael Gygli's talk on structured output prediction by optimizing a deep value network to precisely estimate the task loss on different output configurations for a given input133 at the ZRH office yesterday morning.
October 11, 2017
I don't know what the corporeal analog of running an infinite loop would feel like, but as far as the apprentice is concerned, it forks a process, waits a while, waits longer ... how might it learn to expect that the process will exit in a reasonable amount of time and what constitutes a reasonable amount of time. Having some idea of time passing is important. Perhaps one of its prosthetic senses might amount to a dynamic process-status — the Unix PS command — display. The apprentice has enough control over its body that it can terminate the loop by issuing break statements to the interpreter or kill -s KILL / TERM directly to the kernel. Packaging these skills as discrete actions is important.
The rules or physical laws that govern the body, the design of its sensory interface, the way that the body and the brain interact with one another and the physical laws that govern the environment in which the apprentice performs actions and receives feedback. ... part of this environment includes anything that one can bring up in a browser including arbitrary JavaScript. There are also certain kinds the phenomena that manifest in the browser that are of particular interest to the apprentice, specifically the apprentice is designed to recognize patterns in code, and so, in principal, codesharing webpages should serve as a valuable resource. The JavaScript embedded in webpages could be particularly useful to learn from.
Code snippets that are recognizable on, say, Stack Overflow serve as analogies allowing the apprentice to conjure up, as it were, fragments within its internal IDE / code memory that roughly correspond to the snippet written in its native programming language. Such a skill could be developed so when it sees code written in one language it instantaneously translates the code into the native programming language that its IDE is constrained to represent. This cross-language code recognition could play a role analogous to mirror neurons in primates allowing the apprentice to easily emulate processes observed in the physical world and immediately translate them into something a format it can understand and experiment with.
It's important to realize that the apprentice is not a blank slate and the form of learning that it engages in is not tabula rasa learning. In order to learn to program, the system does not have to first learn program syntax, conditionals, loops or how to compile and run code — the ability to do such things are innate and unavoidable in the sense that a baby can't help but swallow, smile and reach out to touch things in its field of view. The apprentice will appear to behave like a natural programmer right out of the box even though its initial efforts will likely be clumsy and seemingly random, again, like a baby communicating by cooing and gurgling or moving itself by rocking and crawling.
Touching briefly on one last programmer's apprentice topic as a preview for the next log entry, I am just starting to think more concretely about attention schema, specifically, (i) how do such representations come in to being, (ii) how are they represented in memory, (iii) do we have separate schema for each person we encounter, (iv) is there a special schema representing the self / apprentice, and (v) might the apprentice left to its own devices engage in a form of animistic thinking such that humans, webpages and programs are different subtypes of the same type of entity. I intend to start by thinking about how (v) might be addressed using high-dimensional semantic embedding spaces.
October 10, 2017
In the previous log entry, I neglected to say anything about how the programmer's apprentice is grounded or embodied, that is to say, the interface between the strictly cognitive apparatus of the apprentice134 and the physical laws governing the environment the apprentice inhabits and from which originates the only source of information the apprentice can observe and subject to experiment so as to construct a foundation for deciding how to act.
I think of the apprentice as embedded in a layer of specialized hardware and software that provides the interface between its highly adaptive cognitive apparatus and its external environment filtered through various sensory apparatus. Its peripheral sensory apparatus corresponds to the camera, microphone and touchpad on the computer through which the user interacts with the system. However, the system also has internal machinery — specialized prosthetics — each with its own specialized sensory interface — depending on whom you ask, the apprentice either is or lives in a virtual world135.
Human bodies are essentially highly constrained mechanical artifacts. Our fingers, toes, hands and feet can only flex within the constraints of the muscles and tendons that bind them together. We can't rotate our heads 360 degrees, nor can we bend our arms and legs to assume arbitrary contortions. The apprentice doesn't have conventional articulated limbs and body parts. It can't interface with the physical world as we do, but it is just as intimately tied to the computer on which it runs136.
The causal chain that leads from the code the assistant generates and its internal programming interface, through the tool-chain of compilers and interpreters allowing it to execute that code, all the way to the process running the shared instance of the Chrome browser are best thought of as part of the apprentice’s body. In modifying the contents of its internal programming interface, the apprentice has fixed, finite set of actions it can perform thus constraining its behavior and simplifying the process of learning RL policies.
The constraints we impose on how the system is able to generate and modify existing code limit its degrees of freedom in the same way that our joints and muscles limit our movement. Just as you cannot achieve any arbitrary pose, neither can the apprentice alter the contents of the internal programming interface so as to introduce arbitrary syntax errors — the apprentice is basically constrained by its hard-wired programming interface to produce syntactically correct and perhaps even semantically rationalized code. It will always compile!
This doesn't imply that executing the code will not produce an error, only that the error will not be due to the result of incorrect syntax. Internally, some errors will manifest in STDERR messages, others might manifest as subprocesses that doesn't return, hang or dump core. We can, of course, add additional constraints, either temporarily to facilitate training or permanently simply to make life a little bit easier for the apprentice to get up to speed quickly.
In addition to scanning STDOUT and STDERR, the apprentice can also get feedback from looking at the results displayed in the Chrome browser that are generated by programs the apprentice writes and runs. In this way, the apprentice is constrained both by the body it inhabits and the environment with which it interacts. We should design the apprentice with instincts that facilitate dealing with the laws of physics as manifest in interacting with a conventional computer. It's a code monkey.
October 9, 2017
In the original Zinn demo I prepared for the VP of Research, I hinted at simple automated programming by providing the system with templates it could use to run searches, but "programming" in this case amounted to filling in the slots in such templates. Not to denigrate such an approach given it is a design strategy used by novices and experts alike. In software engineering, the idea of a general reusable solution to a commonly occurring problem within a given context is called a design pattern and has become a standard approach in programming practice.
A simpler alternative is to find an existing fragment of code called a snippet that performs a function similar to what you want to implement and then adapt the snippet to suit your specific requirements. Extracting a suitable snippet from a larger program is often necessary and requires skill in and of itself. Extracting a snippet written in one programming language for application in another language is another common expedient employed by both beginner and advanced programmers.
As a first approximation, I imagine the system starting with a repertoire of general-purpose templates that it can specialize, augment and apply recursively. Here's a contrived dialog intended as an example of what one might expect of the proposed programmer's apprentice system:
USER: Write a script that searches for all recent articles on deep neural networks that can write programs.SYSTEM: Should I rely solely on Google Search or do you have some other search engines or databases in mind?
USER: Using Google Search should work fine for a start.
SYSTEM: What do you mean by "recent"?
USER: Anything published within the last five years should work for my immediate purposes.
SYSTEM: What keywords should I use to restrict attention to "deep neural networks"?
USER: Just that, "deep neural networks", if that's too broad, we'll narrow the search to specific acronyms.
SYSTEM: Do you want me to post-process the results by sorting by recency or some measure of journal quality?
USER: That's not necessary. Perhaps we'll want to revisit this later if there are too many relevant papers.
SYSTEM: [...]
Alternatively and more ambitiously, the system could start with examples drawn from other sources — see recent work on automatic patch generation published here and here and related work on coding by example as in leveraging code-sharing resources like Stack Overflow published here137. Might also want to check out the video of Alex Graves' presentation — in the first half — on DNC at ICLR and the presentation — in the second half — by two Berkeley students talking about their paper on Neural Programming Architectures that won 2017 ICLR Best Paper award.
I spent the morning trying to dig up papers on the biological, psychological and computational / technological basis for theory-of-mind (ToM) reasoning. The paper by Pynadath, Rosenbloom and Marsella on multi-agent reinforcement learning is interesting for its application and method of learning another agent's reward function using what they call inverse reinforcement learning — you can check David Pynadath's presentation at the Artificial General Intelligence Conference in 2014 here. Cosmides and Tooby are evolutionary psychologists well known for their work relating to modularity of mind and ToM reasoning and worth a listen, but, so far, I don't see how their work can help given our somewhat limited aspirations in terms of leveraging those big ideas138.
October 7, 2017
Figure 29 includes a block diagram showing a first approximation of the proposed system architecture along with graphics illustrating the various inputs and outputs of the overall system. The block diagram shown in graphic A illustrates the main characteristics of the model, including its multilayer hierarchical structure, the use of LSTM components for all layers in the hierarchy and the characteristic pattern of reentrant connections providing both feedforward and feedback between LSTM components in all layers as described in Stanislas Dehaene’s work [104].
Graphic B conveys the fact that the system receives audio input from both the user and his or her ambient environment including, for example, sounds produced by the computer running an instance of the Chrome browser. The system can provide audio output by either controlling the browser or by using a separate speaker to generate natural language responses. In this entry, I'll experiment with using the terms "user" and "programmer" and the terms "system" and "apprentice" interchangeably, and avoid using the longer descriptive title "programmer's apprentice" altogether. The term "programmer" is reserved for unambiguous cases. For simplicity, when I refer to "voice", unless indicated otherwise, I am assuming that the user is wearing a noise canceling microphone and that high-quality voice-recognition software produces a reasonably accurate — though not perfect — transcription of the user's utterances.
Graphic C shows an LCD screen displaying the Chrome browser running on a computer that the apprentice can log into and interact with the user by manipulating the browser interface. The apprentice has access to the LCD screen, both the raw pixels and everything relating to the browser content including source markup, embedded javascript and browsing history. Graphic D represents some of the signals the apprentice can use to evaluate its attempts to translate user requests into programs that satisfy those requests. In addition to the user's commentary and feedback, the apprentice has access to all the signals produced by compilers, interpreters and the operating system that a human programmer would have available in debugging code.
Graphic E corresponds to an internal workspace that roughly corresponds to an editor or IDE window that a programmer might use in composing a program. The main difference is that the commands and key strokes that apprentice can enter in order to modify the contents of this workspace are limited — the interface maintains a syntactically valid representation of a program at all times. A collection of macros make it easy to insert or append boilerplate expressions that are essentially templates with slots that can recursively contain additional expressions. Interface attempts to maintain a human readable format so the user can provide useful feedback to the apprentice in teaching it to automatically translate the users declarative representations into executable code.
| |
| Figure 29: This figure provides a very rough block diagram showing a first approximation to a system architecture along with inset graphics illustrating the various inputs and outputs of the overall system. The block diagram is shown in the insert labeled A and the four components labeled B, C, D and E are described in more detail the body of the text. | |
|
|
The internal workspace is implemented using some variant of what Alex Graves and his collaborators at DeepMind call a Neural Turing Machine [169] (NTM) or Differentiable Neural Computer [168] (DNC) and Jason Weston and his colleagues at FaceBook refer to as Memory Networks [474]. Additional addressing modes and attentional mechanisms [185, 314, 315] and technology for efficiently accessing and searching large-scale episodic memory, e.g., Pritzel et al [357] Neural Episodic Control (NEC), are likely to be applicable as well.
The details of implementing executive control and some form of hierarchical planning may seem like a huge stretch but, in fact, there are precedents in NN language applications and it is not surprising given its importance that NN architectures can be designed to search efficiently [62]. Peter Abbeel's work on value iteration networks [428, 186] mentioned earlier offers one promising approach and work on language generation including syntax-tree-walking neural networks and even the simple expedient of using beam search to collapse the thought cloud wave-function to generate a coherent utterance often work well in practice. Think about how one could use value iteration on a tree of execution traces to improve policies that learn to write simple helper code. The recent work by Matej Balog et al [26] on a recurrent DNN method for learning to write programs also looks promising.
October 5, 2017
The last few days were spent reviewing previous research on recurrent neural networks and, in particular, variants of the LSTM (Long Short-Term Memory) model of Sepp Hochreiter and Jürgen Schmidhuber [218, 217]. Currently consider LSTM and embedding-space models are our best bet for implementing modular functional units analogous to the primary and secondary (association) areas responsible for sensory and motor function in the cortex and assembling these units into hierarchical architectures that encode complex representations. I am also exploring possible RNN architectures for representing attentional schema that encapsulate collections of capabilities and their enabling conditions and are postulated to model both the self and other entities in social animals [171, 182, 178].
I reviewed work with Shalini Ghosh from October 2015 through May 2016 on hierarchical document representations in thinking about how we might construct a program / script schema and have included references to Shalini's paper with Oriol Vinyals, Brian Strope, Scott Roy, Larry Heck and me [156] as well as additional related papers on hierarchical document and video models using LSTM and RNN technologies [486, 430, 278, 341] BIB. I've also included relevant excerpts from my research notes on hierarchical LSTM, contextual LSTM and slot filling DNN models.
Figure 28 has been augmented to include a description of the ventral visual stream as an example of the connection patterns described in Figure 27 relating to the attentional machinery at the foundation of Dehaene's theory of consciousness [104]. In other correspondence, I've exchanged notes on the prospects for building human-level AI139, research and development tradeoffs in a commercial context140 and the under-utilized ability of pattern-seeking brains to facilitate the design of neural prosthetics141.
October 3, 2017
I've been collecting resources and background from neuroanatomy to neuroprosthetics. Most of my notes are in the form of whiteboard photos. This entry is really nothing more than a temporary placeholder for lecture materials. Google Image Search provided a number of useful graphics showing the primary functional regions and cortical landmarks. I've included a sample in Figure 28. I found a basic primer (PDF) on the anatomy of the adult human brain [213] from the Mayfield Clinic founded by my uncle Dr. Frank Mayfield.
| |
| Figure 28: A sample of the medical-illustrator's craft in rendering the anatomy of the human brain so as to highlight functionally relevant regions like Broca's and Wernicke's areas involved in speech production and language understanding, and to aid in explaining how information is passed between functional areas in the process of generating consciousness. Graphic A highlights the primary and (secondary) association areas for the sensory and motor cortex. Graphic B provides a rotated version of Graphic A including the cerebellum and brainstem for registration purposes. Graphic C illustrates ventral visual pathway feeding forward (blue) from the lateral geniculate nucleus in the thalamus, leading through retinotopically mapped regions in the striate cortex, extending into sensory association areas and ending up in the prefrontal cortex, before reversing direction and feeding back (red) along the same paths. Similar pathways exist for the dorsal visual stream and for the other sensory and motor pathways. The ventral and dorsal pathways refer to the two-streams hypothesis that argues humans possess two distinct pathways in each of the separate visual and auditory systems. | |
|
|

I've already circulated the short video by Michael Graziano explaining the attention schema (MP4) and now I've added a bibliography of books and articles on executive control [320, 333, 331, 329, 23, 105, 109, 107, 256]. I've included a somewhat dated resource [329] (PDF) on the role of computational models in cognitive neuroscience that might help in reading the section entitled "Simulating a Conscious Ignition" in Chapter 5 of Dehaene [104] and the related Figure 27.
Automated planning might seem like GOFAI but ideas from hierarchical planning have been adopted by cognitive neuroscientists to explain the mechanism of executive control in consciousness and by linguists in explaining discourse management. The CMU RavenClaw dialog management system exploited this connection when Dan Bohus and Alex Rudnicky implemented error handling using a hierarchical planner [47, 45]. I followed their lead in developing the prototype dialog system mentioned earlier. While ideas from hierarchical planning persist [496], modern implementations combine NN and RL [281] technologies, with recent work by Pieter Abbeel's group on value-iteration networks [186, 428] of particular interest.
We are drawing on a large number of concepts from several different disciplines in order develop PA — conveniently, PA serves an an acronym for either Personal Assistant and Programmer's Apprentice — technology that leverages ToM reasoning — which I'm using as catchall for attention-schema, conscious-awareness, theory-of-mind reasoning, etc. Those disciplines include artificial intelligence, cognitive science, machine learning and neuroscience. Rather than complicating the situation — apart from conflicting terminilogy which needs sorting out, these thread constrain the task of coming up with good starting points for system architectures and provide data illustrating integrated system behavior:
Representative concepts from cognitive neuroscience include: attention, awareness, body and attention schemas, cognitive dissonance, consciousness, decision making, mirror neurons, planning, policy iteration, predictive coding, reinforcement learning, theory of mind reasoning, and von Economo neurons.
Functional architectures from neural networks provide: deep neural networks, encoder-decoder networks, generative adversarial networks, graph convolutional networks, hierarchical models, long-short term memory, multi-level convolutional networks, recurrent neural networks, and value iteration networks.
Applications of higher-order cognitive machinery: automated collaborative planning, command and control, cognitive and emotional coaches, conversational agents, digital amanuensis, humanoid robots in healthcare, personal assistants, robotic surgical prosthetics and teachable systems for often repeated tasks.
The Programmer's Apprentice application was partially anticipated in a prototype I developed leveraging a Python library for writing code using voice alone developed by Tavis Rudd (MP4). Rudd's system relied on a large set of voice commands that were difficult to remember and hard to deploy given ambient noise levels and natural variation in vocalization. Fortunately, voice recognition has improved markedly in the last few years and I'm expecting the learning component of the Programmer's Apprentice system to mitigate misunderstanding due to the user misremembering the exact name of a command. For example, the user — who created the script associated with the command in the first place — could have the system assist in recall by describing what the command does or how it was implemented.
September 29, 2017
The more I think about it the less I'm enamored of using full-scale theory-of-mind reasoning to enable Google assistant to handle multiple users as in the case of a family that constantly interacts with the assistant using their individual phones and GA enabled appliances such as in the Alexa product that Amazon has marketed so well. First of all, this is a hard problem to begin with and difficult to market without raising very high expectations. Second, there are simpler techniques based on voice recognition and acoustic signal processing that would handle most of the common use cases. [Note subsequent reversal here upon reading Rabinowitz et al [361].]
I'd like to reconsider the idea of a digital amanuensis for an author or smart prosthetic for a typing-impaired programmer with carpal tunnel syndrome — see here. In this use case, we could get by with two attentional schemas one for the disabled programmer and one for the programmer’s apprentice, recalling Rich and Waters' MIT project of the same name [363]. It would definitely exercise an enhanced capability to recover from misunderstandings — both semantic and syntactic — and offers a natural framework in which to explore continuous dialogue in a narrow task domain with the added promise of finding a clear metric for evaluating performance.
Returning to Dehaene's Consciousness and the Brain, Chapter 4 describes how Dehaene and his colleagues discovered what they believe to be the functional correlates of conscious activity. You might want to look at the section entitled "Igniting the Conscious Brain" that draws on Donald Hebb's analysis [206] of collective assemblies of neurons, later reconceived in terms of dynamical systems theory [63] summarized here142, and a later section entitled "Decoding a Conscious Thought" summarized here143.
I found the descriptions useful in imagining how such patterns of activity might be generated in artificial neural network architectures, and answering questions posed at the outset of Chapter 5, "Why should late neuronal firing, cortical ignition, and brain-scale synchrony ever create a subjective state of mind? How do these brain events [...] elicit a mental experience?".
September 27, 2017
According to Stanislas Dehaene the machinery for consciousness is similar to the machinery for visual attention. If this is true, what are the top-down and bottom-up signals in each case. There is both the issue of weighing different alternatives for an individual, somewhat independent choice, e.g., should I wear shorts or a raincoat today, and how we integrate all the separate choices to form a composite plan, e.g., to get to work today. Dehaene's work on executive control and planning, e.g., [107, 105] is worth reviewing as a supplement to Consciousness and the Brain.
Dehaene believes there are multiple levels of consciousness where the lower levels involve primarily the ability to broadcast and integrate information. The sense of self as something we can reflect on and ascribe knowledge to as well as our ability to project conscious behavior on others as part of social decision making are higher level than the elephant uses when deciding her best option for finding drinking water taking into consideration distance to the source of the water, temperature, predators, age and health of other elephants in the herd. However, the signature pattern of re-entrant connections found throughout the hierarchy of thalamic nuclei, primary sensory, secondary association and so-called executive-level prefrontal substructures demands a computational explanation.
I'm not going to attempt to summarize Dehaene's book in detail. Much of it consists of experiments that support his hypothesis and I recommend you scan the entire book if you can. Chapter 5 provides the most detail relevant to implementing his theory, and almost all the remaining text and figures in this log entry were excerpted from this chapter. Copies of Consciousness and the Brain are available on reserve in Green Library for Stanford students, but you may want to obtain a copy for reference in which case a digital format is recommended. Dehaene summarizes his basic "global neuronal workspace" hypothesis in Chapter 5 as follows:
When we say that we are aware of a certain piece of information, what we mean is just this: the information has entered into a specific storage area that makes it available to the rest of the brain. Among the millions of mental representations that constantly crisscross our brains in an unconscious manner, one is selected because of its relevance to our present goals. Consciousness makes it globally available to all our high-level decision systems. ( Figure 24 ) We possess a mental router, an evolved architecture for extracting relevant information and dispatching it.The psychologist Bernard Baars calls it a "global workspace": an internal system, detached from the outside world, that allows us to freely entertain our private mental images and to spread them across the mind’s vast array of specialized processors. [...] This idea is not new — it dates back to the inception of artificial intelligence, when researchers proposed that subprograms would exchange data via a shared "blackboard," a common data structure similar to the "clipboard" in a personal computer. The conscious workspace is the clipboard of the mind.
| |
| Figure 24: Global neuronal workspace theory proposes that what we experience as consciousness is the global sharing of information. The brain contains dozens of local processors (represented by circles), each specialized for one type of operation. A specific communication system, the "global workspace," allows them to flexibly share information. At any given moment, the workspace selects a subset of processors, establishes a coherent representation of the information they encode, holds it in mind for an arbitrary duration, and disseminates it back to virtually any of the other processors. Whenever a piece of information accesses the workspace, it becomes conscious. | |
|
|

The wiring pattern of the primate brain is anything but uniform: [...] Importantly, not all brain areas are equally well connected. Sensory regions, such as the primary visual area V1, tend to be choosy and to establish only a small set of connections, primarily with their neighbors. Early visual regions are arranged in a coarse hierarchy: area V1 speaks primarily to V2, which in turns speaks to V3 and V4, and so on. As a result, early visual operations are functionally encapsulated: visual neurons initially receive only a small fraction of the retinal input and process it in relative isolation, without any "awareness" of the overall picture. [...]
[...] Neurons with long-distance axons are most abundant in the prefrontal cortex, the anterior part of the brain. This region connects to many other sites in the inferior parietal lobe, the middle and anterior temporal lobe, and the anterior and posterior cingulate areas that lie on the brain’s midline. These regions have been identified as major hubs — the brain’s main interconnection centers. All are heavily connected by reciprocal projections: if area A projects to area B, then almost invariably B also sends a projection back to A ( Figure 25 ). Furthermore, long-distance connections tend to form triangles: if area A projects jointly to areas B and C, then they, in turn, are very likely to be interconnected. [...]
| |
| Figure 25: Long-distance neuronal connections may support the global neuronal workspace. The famous neuroanatomist Santiago Ramòn y Cajal, who dissected the human brain in the nineteenth century, already noted how large cortical neurons, shaped like pyramids, sent their axons to very distant regions (left). We now know that these long-distance projections convey sensory information to a densely connected network of parietal, temporal, and prefrontal regions (right). A lesion in these long-distance projections may cause spatial neglect, a selective loss of visual awareness of one side of space. | |
|
|
[...] Pathways linking the cortex with the thalamus are especially important. The thalamus is a collection of nuclei, each of which enters into a tight loop with at least one region of the cortex and often many of them at once. Virtually all regions of the cortex that are directly interconnected also share information via a parallel information route through a deep thalamic relay. Inputs from the thalamus to the cortex also play a fundamental role in exciting the cortex and maintaining it in an "up" state of sustained activity. As we shall see, the reduced activity of the thalamus and its interconnections play a key role in coma and vegetative states, when the brain loses its mind. [...]
| |
| Figure 26: Large pyramidal neurons are adapted to the global broadcasting of conscious information, particularly in the prefrontal cortex. The whole cortex is organized in layers, and layers II and III contain the large pyramidal neurons whose long axons project to distant regions. These layers are much thicker in the prefrontal cortex than in sensory areas (above). The thickness of layers II and III roughly delineates the regions that are maximally active during conscious perception. These neurons also exhibit adaptations to the reception of global messages. Their dendritic trees (below), which receive projections from other regions, are much larger in the prefrontal cortex than in other regions. These adaptations to long-distance communication are more prominent in the human brain than in the brains of other primate species. | |
|
|
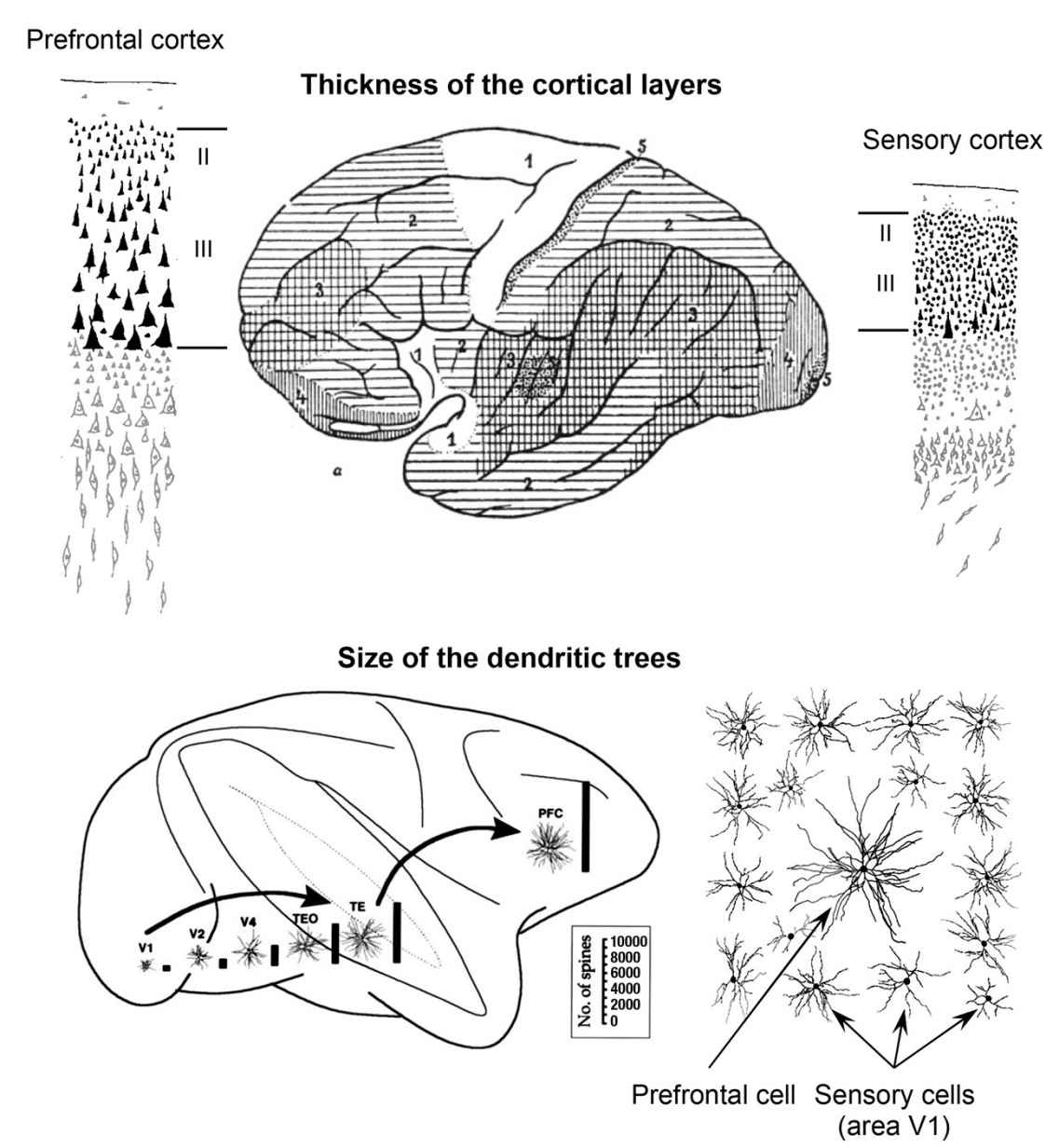
[...] Their dense jungle of dendrites is controlled by a family of genes that are uniquely mutated in humans. The list includes FoxP2144, the famous gene with two mutations specific to the Homo lineage, which modulates our language networks, and whose disruption creates a massive impairment in articulation and speech. The FoxP2 family includes several genes responsible for building neurons, dendrites, axons, and synapses. In an amazing feat of genomic technology, scientists created mutant mice carrying the two human FoxP2 mutations — and sure enough, they grew pyramidal neurons with much larger, humanlike dendrites and a greater facility to learn (although they still didn’t speak). [...]
| |
| Figure 27: A computer simulation mimics the signatures of unconscious and conscious perception. Stansilas Dehaene and Jean-Pierre Changeux simulated, in the computer, a subset of the many visual, parietal, and prefrontal areas that contribute to subliminal and conscious processing (above). Four hierarchical regions were linked by feed-forward and long-distance feedback connections (middle). Each simulated area comprised cortical cells that were organized in layers and connected to neurons in the thalamus. When we stimulated the network with a brief input, activation propagated from bottom to top before dying out, thus capturing the brief activation of cortical pathways during subliminal perception. A slightly longer stimulus led to global ignition: the top-down connections amplified the input and led to a second wave of long-lasting activation, thus capturing the activations observed during conscious perception [104]. | |
|
|
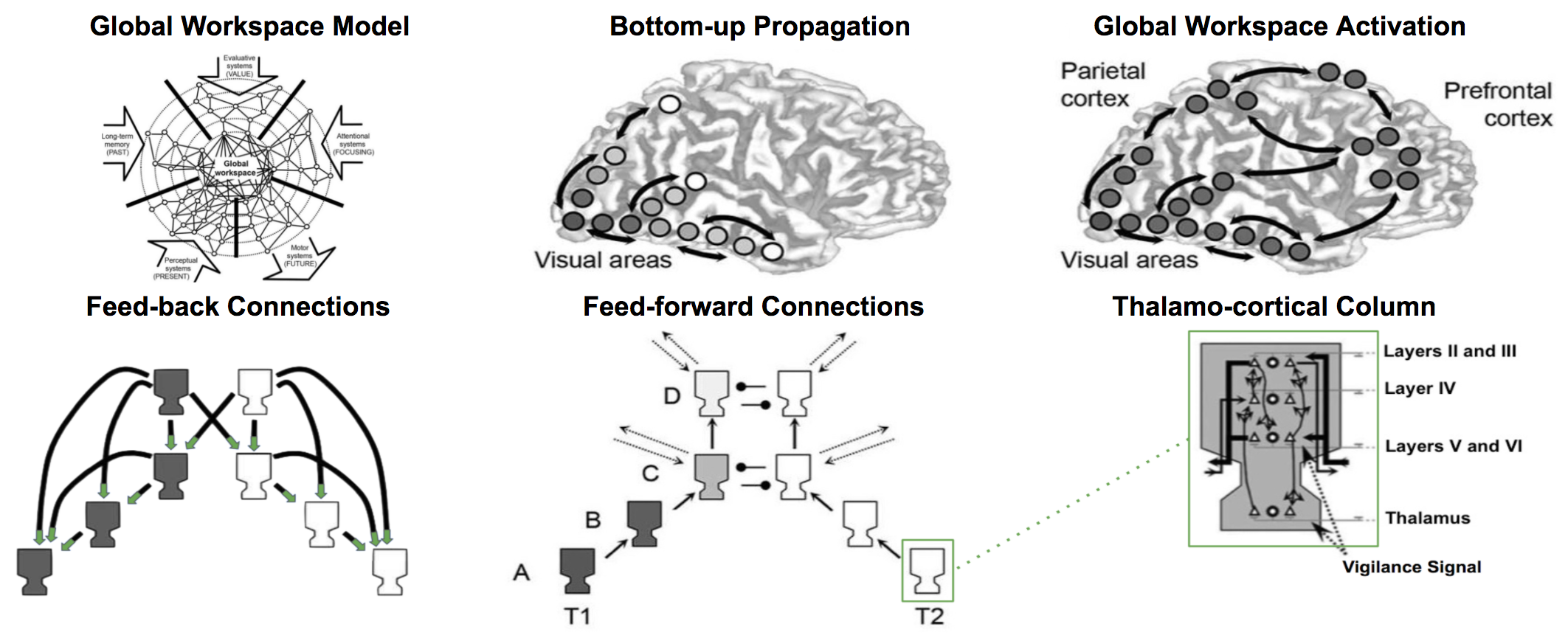
[...] Crucially for the workspace hypothesis, Elston and DeFelipe showed that the dendrites are much larger, and the spines much more numerous, in the prefrontal cortex than in posterior regions of the brain — See Figure 26.
[...] Bernard Baars’s version of the workspace model eliminates the homunculus. The audience of the global workspace is not a little man in the head but a collection of other unconscious processors that receive a broadcast message and act upon it, each according to its own competence. Collective intelligence arises from the broad exchange of messages selected for their pertinence. This idea is not new—it dates back to the inception of artificial intelligence, when researchers proposed that subprograms would exchange data via a shared "blackboard" [448, 203, 202].
[...] During World War II, the British psychologist Donald Broadbent developed a better metaphor, borrowed from the newborn theory of information and computing. Studying airplane pilots, he realized that, even with training, they could not easily attend to two simultaneous trains of speech, one in each ear. Conscious perception, he surmised, must involve a "limited-capacity channel" — a slow bottleneck that processes only one item at a time.
[...] The neuropsychologists Michael Posner and Tim Shallice proposed that information becomes conscious whenever it is represented within this high-level regulatory system. We now know that this view cannot be quite right [...] since even a subliminal stimulus, without being seen, may partially trigger some of the inhibitory and regulatory functions of the supervisory executive system.
[...] However, conversely, any information that reaches the conscious workspace immediately becomes capable of regulating, in an extremely deep and extensive manner, all our thoughts. Executive attention is just one of the many systems that receive inputs from the global workspace. As a result, whatever we are aware of becomes available to drive our decisions and our intentional actions, giving rise to the feeling that they are "under control." Language, long-term memory, attention, and intention systems are all part of this inner circle of intercommunicating devices that exchange conscious information. [...]
[...] Because of FoxP2 and its associated gene family, each human prefrontal neuron may host fifteen thousand spines or more. This implies that it is talking to just about as many other neurons, most of them located very far away in the cortex and thalamus. This anatomical arrangement looks like the perfect adaptation to meet the challenge of collecting information anywhere in the brain and, once it has been deemed relevant enough to enter the global workspace, broadcast it back to thousands of sites.
In [104], Dehaene distinguishes three basic concepts relating to consciousness: vigilance — the state of wakefulness, that varies when we fall asleep or wake up; attention — the focusing of our mental resources onto a specific piece of information; and conscious access — the fact that some of the attended information eventually enters into our awareness and becomes available to report to external observers. It is the last of these that is of primary practical interest to us, though the first two are necessary prerequisites for the last to occur.
In the thalamo-cortical column shown in Figure 27, you'll notice a small circuit labeled "vigilance signal". In the simulation studies described in [104], each pyramidal neuron in the simulated cortex receives a vigilance signal, representing a small amount of current that accounts for the activating effects of acetylcholine, noradrenaline and serotonin ascending from various nuclei in the brain stem, basal forebrain, and hypothalamus. This simulated current activates the corresponding parts of the cortex conscious access.
September 25, 2017
The last entry in this log sketched a simple theory of attention roughly based on ideas from Michael Graziano [171] using the metaphor of a flashlight that illuminates selected parts of working memory. The metaphor begs the question of "who" is holding the flashlight and directing beam of light. Of course, the answer has to be "nobody", but still there has to be some mechanism and associated source of information that focuses attention.
One possible answer borrowed from models of visual attention is that some version of interestingness must be at play, where by "interestingness" we mean some property of activated neural tissue that can be simply computed, i.e., not requiring deeper recursive analysis. I suggested that "interestingness" is an emotional state vector that enables us to prioritize selection, but I don't think that's the whole story. For one thing, almost any information represented in the neural state vector is likely to have an emotional component.
To make progress it will be useful to be explicit about how we might build attentional mechanisms capable of the sort of computations we believe take place in human brains. If attention selects from among informational states encoded in the activity of neurons, then what is a good approach to modeling such states in artificial neural networks. Multi-layer neural networks representing high-dimensional state vectors in a hierarchy of embedding spaces might be a good starting point. The rest of this entry is more philosophical, but don't miss the footnotes.
Thinking about thinking is hard. Even reading the work of someone as clear and precise as Michael Graziano, the words initially seem familiar, but then inexplicably become foreign in the rarified context of a theory. They seem to tumble over one another, each fighting to see if it applies in the present circumstances. Indeed it is hard to ignore the fact that you are immersed in an attentional process145.
What is attention?146 What is awareness and how are attention and awareness related?147 Is there a case in which one occurs and the other does not? How is attention related to decision making?148 These questions are likely to arise and persist indefinitely as you attempt to solve the puzzle of consciousness. With luck you may stumble on a clue providing an answer to one question only to find that it leads to a cascade of questions. The link between attention and decision making in the last footnote may provide one such clue that works for you but there are no guarantees.
Even if you think you understand, say, visual attention in the way it is explained by Laurent Itti and Christof Koch [232, 233], you may be confused by a contemporary competing explanation of visual attention such as that proposed by Dirk Walther [462, 463], and even more confused on encountering the more general characterization presented in Graziano's book. All three rely on the same words but they have different technical meanings in each theory. All I can say by way of consolation, is that this sort of uncomfortable confusion is, in my experience, unavoidable in understanding anything fundamentally new about nature. It is worth reflecting on the advantages and disadvantages of a medium of exchanging information that has such a high degree of apparent ambiguity.
September 23, 2017
I was chopping vegetables this evening for a big quinoa salad to last us for at least five meals this coming week and I was thinking about the last entry in the research log that I appended to my "what'll I do if" white paper. The last paragraph suggested that we could control our behavior by emotionally tagging thoughts conjured up from memory. I started thinking about Ray Kurzweil's interview with Martin Minsky in which Minsky talked about his society of mind model, and I started thinking about your comment that many of your internal conversations seem to be driven by habit.
The word "habit" has a negative connotation in colloquial speech but what I got from your comment is that we can form a habit for doing just about anything we like using an appropriate carrot or stick. Skinner's rats and Pavlov's dog provide ample demonstrations of this characteristic stimulus-response learning and of course humans are well known for their ability to turn almost any stimulus into a craving or an aversion, not to mention all of the many odd and perversely twisted abstractions we invent to drive human behavior.
In particular, solving logical puzzles, proving mathematical theorems, using simple antique marine navigation instruments to make astronomical predictions, rotating complex geometric shapes in our heads, finding weird symmetries in complex equations, teaching someone to read a story or add two numbers, solving a murder in a mystery novel, correctly spelling a difficult word, mastering a complicated ballet step, even creating grotesque parodies of human beauty, all provide motivation and produce emotional responses. We can harness this ability to free ourselves from the instincts we were born with or adopted from our peers.
We can also borrow these habits from others. We can adopt aesthetic preferences and ways of appreciating things to enlarge our ability to label ideas and propositions so as to motivate our underlying attentional system to elevate or silence items vying for our attention in working memory. We can invoke both facts and rules and then use our appreciation of a rule of inference to arrive at conclusions that are logically valid assuming both the facts and rules are valid. We can apply the scientific method to evaluate hypotheses and moderate our enthusiasm based on the evidence. We can use our appreciation of knowledge handed down from books that others whom we trust have validated by their careful study and appropriately skeptical analyses. Such knowledge is analogous to a software library that could open up entire disciplines to our appreciation and application.
September 21, 2017
The impression of the lightest touch on our skin or the disturbance of a single hair corresponds to the activation of one or more neurons in the central nervous system that provide our first opportunity to apprehend a sensory event originating in the peripheral nervous system and producing a signal that is propagated along nerve fibers terminating in the sensory cortex149.
In the Buddhist tradition of insight practice, all things are said to be impermanent. To realize the impermanence of all things insofar as we can experience them, practitioners focus their attention on the arising and passing of sensations and learn to count individual sensations and divide what appear to be sustained sensations into sequences of shorter ones.150
The apprehension of touching an object is complicated by the fact our brains adjust the perceived time of the touch causing the sensation with the time of our feeling the touch as registered by the activity of neurons in the brain, i.e., the brain makes sure what we see doesn't appear to happen before we feel it and so causality does not appear to be violated151.
What about sustained pressure on our skin? Not all neural activity available for conscious access are punctate in the sense that they last no longer than the length of the refractory period of a neuron. Visual stimuli impinging on the retina rapidly propagate through the visual cortex resulting in sustained states of varying duration depending on gaze and independently driven neural activity152.
It may be, however, that our conscious apprehension of such sustained states is essentially punctate, implying that, while we imagine ourselves sustaining an image of a perfectly blue sky, in fact our eyes are performing dozens of microsacades per second and our minds conjuring up all sorts of related memories. It might seem conscious access would manifest refresh anomalies when reporting on a partially reconstructed memory, but that doesn't appear to happen due to the function of attention.
You can imagine that blue sky as arising from a collection of discrete sensations or as a reconstructed, idealized and sustained memory of perfectly clear blue sky, and still conclude that the process of consciously attending to such an apprehension is constructed and sustained in conscious awareness through a series of sensations.
The key revelation is that when conscious experience is grounded in sensation, the number of such sensations is finite and they are ephemeral, manifestly impermanent, rapidly coming into being and passing away, and thus our entire experience is impermanent and fleeting. Moreover, when you look around, that's all there is. There is no room for a homumcular "you" sitting alone in a Cartesian theater in your skull observing events unfolding.
In traditional impermanence training, you break each sensation into smaller sensations and count them practicing until you can reduce each sensation to a succession of indivisible sensational quanta. Awakening occurs when it becomes apparent that that's all there is. The answer to the quintessential question, "Where am I?", is that everything is impermanent and that "you" are no more substantial than a ripple in the water that disturbs the surface of a pond or a gust of wind that rustles the leaves in the forest153.
If there is no "you", then how do you exert any control over your thoughts and activities? Why aren't you a zombie or a robot that can only respond to its environment by executing immutable canned subroutines corresponding to instincts that are programmed to execute when presented with specific patterns of stimulus arising in your immediate environment?
First of all, consider the role of consciousness in directing your attention. The simplest metaphor is that of a flashlight that can be directed to highlight any of the thoughts that are currently active as a consequence of observing the world around you and having those observations activate parts of your brain that are in some way relevant to what you observe. Of course the flashlight has to be directed by something and that something can't invoke a recursive viewpoint, i.e., homunculus. Suppose instead the mind applies a general-purpose attentional mechanism that employs some criterion of relevance or emotional significance to direct the beam of the flashlight154.
Moreover suppose that when the beam illuminates some portion of your temporary workspace you, react to the illuminated recalled memories as you would any memory by imprinting your current emotional state or rather your current emotional state modified by the additional information revealed by the illumination of the flashlight. Since emotion and pattern determine what memories are recalled and how they are reimagined by treating them exactly as if they were new experiences to be emotionally and practically considered, the new emotional imprint modifies their behavior so the next time you recall them they will perform differently.
The next step is to figure out how using this mechanism of conscious recall and emotional recoding, we could actually reprogram ourselves in such a way to achieve some degree of autonomy and independence from our initial or socially imprinted programming. You can train yourself not to attend to something. You can channel your craving, curb your attachment or moderate your aversion, but you can't just change your mind; you can't arbitrarily move the flashlight. You can, however, write a program / create a habit so that if a pattern or choice presents itself you will take the opportunity to exercise the habit. Think about how to cultivate a pattern of behavior that captures your subtle and not-so-subtle aspirations and intentions.
September 19, 2017
I was thinking about John Platt's comment that perhaps neuroscience doesn't have much to tell us about building better AI or ML, and specifically about whether what we have learned about any one of consciousness, embodied spatial reasoning, emotions, self-awareness or theory-of-mind reasoning is enough to emulate the related behavior insofar as we want or need to build systems that employ such facilities.
Language is, I think, a special case. Some argue that language comprehension is closely related to a form of tagging that occurs in scene comprehension. While language certainly has social, signaling and collective planning components, each of these applications of language also involve concept identification, sophisticated relational thinking and combinatorial concept formation and require some form of self localization155.
To what extent is consciousness something that can be built on any architecture that has at least the cognitive capabilities of a mammal, or perhaps much older species. Maybe you don't need special-purpose hardware and so the neural correlates you are looking for are simply the ephermeral functional traces of biological "software" running on general-purpose hardware. On the other hand, if you look for the "neural correlates" of process & thread scheduling on a modern VLSI processor chip, you may indeed find dedicated hardware serving in this capacity [191].
Contrast the putative neural correlates of consciousness with other mysteries of the brain related to conscious and social behavior such as mirror and Von Economo neurons (VENs) (spindle cells), microglia cells now implicated autism [433], and the presumed core of our emotional circuitry in the functionally-diverse area (still) called the limbic system. Estimates of the evolutionary time course of these circuits vary wildly, some apparently appearing quite recently156, and others such as hippocampal place cells apparently quite ancient157.
A lot of recent theories of subconscious cognition are essentially variants of Oliver Selfridge's158 Pandemonium model [387] or Marvin Minsky's Society of Mind theory [313]. Do those models provide enough of a hint to build smart AI systems? Is consciousness and ToM reasoning as complicated as some seem to believe or is it the case that, if we can build "simply-savant and socially-safe" systems sophisticated enough to act independently and survive in the same environment we evolved in, then perhaps consciousness and ToM thinking will fall out naturally in the process of such systems interacting with that environment, with or without intervention from or direct involvement with humans.
September 17, 2017
I've temporarily settled on three theories relating to consciousness and related cognitive capacities articulated in three relatively recent books: The first book features a refinement and extension of the global-workspace theory (GWT) of Bernard Baars supported by extensive neurological studies using an array of techniques including evoked potentials, EEG, fMRI, single-cell recordings and magnetic stimulation, Consciousness and the Brain: Deciphering How the Brain Codes Our Thoughts by Stanislas Dehaene [104] — see this twenty-minute video for insightful comments you can take to the bank, i.e., translate into systems, and a succinct summary of his GWT theory159.
The second book covers a new theory focusing on the interactions involving consciousness, social behavior and theory-of-mind reasoning, Consciousness and the Social Brain by Michael Graziano [173] — summarized in this series of articles [176, 173, 177, 175, 174, 172] appearing in Atlantic. Graziano's notion of an attention schema as a representation to facilitate thinking about other minds provides a particularly clear framework for explaining and implementing theory-of-mind thinking160.
The third book presents a new theory of emotion that emphasizes how interoception — responsible for monitoring our internal processes — generates the raw data that is subsequently filtered through our past experiences and learned concepts, How Emotions Are Made: The Secret Life of the Brain by Lisa Feldman Barrett [31]. Barrett's Theory of Constructed Emotion is a good example of what happens when cognitive science comes head-to-head with neurobiology, and the conversation between Robert Wright and Barrett in this interview underscores the confusion between conventional accounts of emotion and language relating to emotion and what we have observed in the brain. Her work is summarized for a lay audience in this article in Wired and this interview on NPR.
September 11, 2017
Here is the abstract of a white paper written in 2013 on building digital agents capable of engaging in continuous open-ended dialog while dealing with ambiguity, recovering from misunderstandings and collaborating with human agents to explore entertainment options and solve everyday problems:
Our approach to natural language understanding (NLU) is — like our approach to NLG — a study in compromise, working hard to find a middle ground between the simple chatterbot and a — yet to be realized — full AI-complete solution capable of passing itself off as a human. The two main threads of our solution consist of (a) extensions of simple keyword and sentiment spotting designed to expand and smooth out the relevant lexical space, and (b) error mitigation and recovery in which we view the process of understanding as a dialog in which we work with the user to narrow down the meaning of user input sufficiently to provide value, e.g., playing music that the user enjoys.
References
1 Deacon is essentially implying that natural language is software that evolved to run on human brains. Natural language is arbitrarily extensible and fundamentally recursive, allowing humans to invent specialized technical languages, e.g., linear algebra and differential geometry, along with the specialized mental disciplines and cognitive tools necessary to run programs coded in those languages, by cultivating their natural biological neural networks and designing bespoke electronic computing devices to offload some of the more tedious calculations. Children learn to write mathematical equations in grade school. Scientists and mathematicians communicate by means of equations and learn to manipulate equations in their heads to clarify their mathematical insights or solve such equations to make predictions. Manipulating equations on a white board, in your head or with pencil and paper is certainly challenging and learning how to accomplish such feats actually serves to change the structure of your brain.
Higher-order programming languages, in the sense of languages in which functions and operators can occur as values, have been around longer than we have had useful computing hardware. In the 1930s, Alonzo Church developed the lambda calculus as a way of formalizing the concept of effective computability. Also in the 30s, Gödel and Turing needed to encode programs, proofs and the concept of provability to produce their results on incompleteness and universality. Gödel accomplished this using a second-order method now known as Gödel numbering for his incompleteness theorems that were published 1931. Gödel was an incredible mathematician and paved the way for other mathematicians and modern computer scientists to develop higher-order logics and programming languages.
As an undergraduate, I did a minor in mathematical logic with an emphasis on the late 19th and early 20th century, including Cantor, Frege, Russell and Whitehead's Principia, and culminating in a semester devoted to working through Gödel's incompleteness theorem [319]. Mathematics was my major with a thesis on point-set topology, but I spent much of my time in the basement of the math department working on a Honeywell time-sharing mainframe writing Lisp — John McCarthy's realization of the lambda calculus as a programming language — programs to control robots. Then at Yale I fell in love with computer programming languages and studied the lambda calculus and a similarly powerful functional language called Haskell in homage to Haskell Curry, a logician working on the foundations of mathematics.
Despite these interests, I followed my early inclinations and did my PhD in AI. And now I'm designing artificially intelligent systems that have the latent capability of creating their own languages and editing their own descriptions. Biology offers another perspective on higher-order languages with myriad examples drawn from immunology, parasitology — and now with rapidly improving comprehension and precision, synthetic biology — exhibiting recursive phagic editing. Thinking about thinking about thinking is about as deep as I can go and still make reasonable extrapolations. Ignoring whether or not there is value in recurring more deeply, e.g., in theory-of-mind thinking, future generations of AI systems will have no such limitations. There are, however, some interesting possibilities opening up for augmenting human cognitive function.
The human brain relies on distributed representations realized as more-or-less-stable joint-activations of neural circuits. These joint-activations support high-dimensional vector-space representations of the sort we exploit in connectionist models. Evolution has selected for traits that make it possible for humans to perform symbolic and linguistic computations on a substrate that is singularly unsuited for the task. Myelination helps as does opportunistic pairing and repurposing of existing subcortical circuits over evolutionary time scales, but we can do much better in developing artificial systems. As for the substrate that humans rely on, recent advances in neural-interface technology suggests we may be able to augment humans in similar ways by enabling higher-dimensional spaces using enhanced external connection technology, faster nearest-neighbors computations, more stable long-term storage and faster learning.
2 Perseveration is the repetition of a particular response (such as a word, phrase, or activity) regardless of the absence or cessation of a stimulus. In a broader sense, it is used for a wide range of functionless behaviors that arise from a failure of the brain to either inhibit prepotent responses or to allow its usual progress to a different behavior, and includes impairment in set shifting and task switching in social and other contexts. SOURCE
3 At approximately (01:03:00) into his class discussion speaking about the diagram on Slide 11 of his presentation, O'Reilly said — modulo my transcription errors and attempt at rational reconstruction — something along the following lines:
[W]hat gating is actually doing is opening up a pathway from the superficial regions of any given prefrontal cortex area into the deep layers of the corresponding layers in that same area. [The result is] this canonical cortical connectivity within any given piece of cortex and transition from the superficial into the deep [that] we think is really dependent on having this [loop] connectivity through these thalamic relay cells (TRC) in the thalamus. We're curently using the same circuits in posterior cortex to do predictive learning and we think this frontal circuitry probably developed on top of that same kind of predictive learning mechanism, and the basal ganglia plugged in there as a convenient place to intervene in that transition from superficial to deep.The thing that's special about the frontal cortex is that there can be these patterns of activity held onto in the deep layers and essentially insulated from further updating from the superficial layers whenever the basal ganglia isn't firing [it is in its off state] and then when it does fire, the [loop] from the superficial to the deep opens up and you update the memory system. There are many different regions of frontal cortex, many different kinds of cortical columns, and so what the basal ganglia is doing is using [its] huge inhibitory competitive network to decide which of the many different parts of the frontal cortex [corresponding to memory cells in the LSTM model] it is going to update any given moment in time. [See Chatham et al [66] for an analysis of the experiments that led to these conclusions.]
4 In his presentation in class, Randy O'Reilly discussed (00:31:00) Leabra [330, 332], a biologically-based cognitive architecture including bidirectional activation and inhibitory competition via top-down and bottom-up processing implemented (00:36:00) as layers of leaky integrate-and-fire neurons relying on extensive networks of inhibitory neurons to avoid runaway conditions, and basal ganglia to toggle PFC bistable states (00:38:00) using a variation [331] on the Barto and Sutton actor-critic model [240] and biologically plausible implementations of backpropagation-through-time, and later in the discussion (1:04:30) he provided some additional details concerning active maintenance by way of thalamocortical loops. Following his prepared notes, Randy responded to student questions, including (00:47:30) a response to Catherine Wong's question about how basal ganglia help facilitate credit assignment. He answered (00:51:45) Alex Tamkin's question about differentiable neural computing [169] / Neural Turing Machines [168].
Nikhil Bhattasali remarked (00:53:15) that Randy had talked about two extremes of organization, a low-level neural-circuit description focusing on the behavior of individual neurons and an abstract system-level description characterizing the behavior of the basal ganglia, prefrontal cortex, etc., but Nikhil was curious what he could say about activity at the subroutine level. Randy replied that learning subroutines — abstractions that combine primitive operations to solve classes of related problems that occur frequently enough to warrant packaging them into recyclable units — is still a fundamental mystery. He mentioned it was possible to hard-code a restricted class of subroutines in ACT-R using chunking and noted that the reinforcement learning community is experimenting with notion of options in reinforcement learning [424, 425] — see Riedmiller et al [364] for a recent take on this idea.
5 I've been reading Charles Fernyhough's [137] The Voices Within: The History and Science of How We Talk to Ourselves and thinking about your comments that "reasonably intelligent folks who can follow your arguments conceptually have no real idea how this translates to operational practical terms", how the "black box of computation inadvertently enhances the ill will that so many have toward the 'elites' of society" and that "[a]s AI progresses, this non-comprehension [...] will further divide us into haves and have-nots — this time the distinction being understanding rather than money and social position".
I have little interest in and less optimism that the efforts of scientists who have taken on the challenge of "explaining" AI and its implications for society will succeed in making the population worry less about AI technology. The implications of AI as a technology are so pervasive and potentially disruptive that it is impossible to make any useful predictions. Specious claims about what the future holds in store are rife and largely unhelpful. When I think about writing projects relating to AI education, I imagine writing about technology in a way that makes it clear that, while artificial intelligence could go in many directions, some engineers are likely to emulate familiar human characteristics.
For example, there are technical reasons that building AI systems that use internal speech makes sense, e.g., see this entry on the two streams hypothesis. Here's how I might characterize my internal speech: "I don't know what I'm going to say before I say it. The prerequisite thought cloud has formed, but it has yet to coalesce into words. When it does it will be transformed by the many associations created in the short time between when I realized that I was about to say something and when I begin to speak. Even as I speak my initial words and phrases, they will inevitably evoke other memories, altering the original cloud of my nascent commentary." A simplified and less cluttered version of the attached sketch could serve as a substrate-agnostic explanatory context:
 |
6 Performativity was first defined by philosopher of language John L. Austin as the capacity of speech and communication to act or to consummate an action. Common examples of performative language are making promises, betting, performing a wedding ceremony, an umpire calling a strike, or a judge pronouncing a verdict. Austin differentiated this from constative language, which he defined as descriptive language that can be "evaluated as true or false". (SOURCE)
8 The hypothesis of linguistic relativity holds that the structure of a language affects its speakers' world view or cognition. Also known (controversially) as the Sapir-Whorf hypothesis, the principle is often defined to include two versions: the strong hypothesis and the weak hypothesis. The strong version says that language determines thought and that linguistic categories limit and determine cognitive categories. The weak version says that linguistic categories and usage only influence thought and decisions. SOURCE
7 Below is a partial list of age-appropriate speech and language milestones from the Johns Hopkins School of Medicine that will give you some idea of when various linguistic capabilities become available during normal child development. Our understanding of what happens when for some reason these milestones are not achieved within what appear to be critical developmental windows of opportunity is incomplete, incredibly interesting scientifically and profoundly disturbing for parents of young children who notice related cognitive deficits in young children — see this related NIH material intended for parents who notice signs of possible developmental aberration.
Regarding such putative developmental windows of opportunity, Nikhil Bhattasali recommended this interesting WNYC Studios Radiolab podcast (TRANSCRIPT) about language and development featuring interviews with two cognitive psychologists, Elizabeth Spelke at Harvard, and Charles Fernyhough [137] at Durham University in the UK. In the first half of the podcast, Susan Schaller [379] chronicles the case study of a 27-year-old deaf man whom Schaller teaches to sign for the first time, challenging the Critical Period Hypothesis that humans cannot learn language after a certain age.
The second half of the podcast includes a description of some interesting studies involving congenitally deaf subjects who use sign language, some of whom have a rich set of signs relating to thinking and others who have few if any such signs. The subjects who used signs relating to thinking were able to pass standard developmental tests relating to theory-of-mind thinking, while those lacking such signs were not. Interestingly, in a subsequent development both groups of subjects ended up spending a lot of time together and those lacking theory-of-mind signs, quickly acquired these signs from their interactions with the other group and subsequently were able to pass the theory-of-mind developmental tests. Such results are cited by some as evidence of linguistic relativity, often referred to as the Sapir-Wharf hypothesis8.
 |
9 Note that the Arumugam et al [15] paper is available as a preprint on arXiv and the training data and code necessary for running the experiments described in the paper are available from this GitHub repository.
10 Here are a few recent papers on implementing deep reinforcement learning with a combinatorial action space, A, defined as follows: Assuming a collection of P operator (action) templates of N arguments each, A = { αm( α1, α2, ..., αN ), 0 ≤ m < P }, if each argument can take on any one of M values, then there are P × MN. Of course N need not even be finite, but the definition illustrates the combinatorial nature of such action spaces and makes the point that even with relatively small M, N and P it is impractical to explicitly enumerate A in the process of evaluating the best action in the context of the current state — which is also likely to exhibit combinatorial structure thereby requiring appropriate concessions in implementing the Q function.
@article{Dulac-ArnoldetalCoRR-16,
author = {Gabriel Dulac-Arnold and Richard Evans and Peter Sunehag and Ben Coppin},
title = {Reinforcement Learning in Large Discrete Action Spaces},
journal = {CoRR},
volume = {arXiv:1512.07679},
year = {2016},
abstract = {Being able to reason in an environment with a large number of discrete actions is essential to bringing reinforcement learning to a larger class of problems. Recommender systems, industrial plants and language models are only some of the many real-world tasks involving large numbers of discrete actions for which current methods are difficult or even often impossible to apply. An ability to generalize over the set of actions as well as sub-linear complexity relative to the size of the set are both necessary to handle such tasks. Current approaches are not able to provide both of these, which motivates the work in this paper. Our proposed approach leverages prior information about the actions to embed them in a continuous space upon which it can generalize. Additionally, approximate nearest-neighbor methods allow for logarithmic-time lookup complexity relative to the number of actions, which is necessary for time-wise tractable training. This combined approach allows reinforcement learning methods to be applied to large-scale learning problems previously intractable with current methods. We demonstrate our algorithm's abilities on a series of tasks having up to one million actions.}
}
@article{TavakolietalCoRR-17,
author = {Arash Tavakoli and Fabio Pardo and Petar Kormushev},
title = {Action Branching Architectures for Deep Reinforcement Learning},
journal = {CoRR},
volume = {arXiv:1711.08946},
year = {2017},
abstract = {Discrete-action algorithms have been central to numerous recent successes of deep reinforcement learning. However, applying these algorithms to high-dimensional action tasks requires tackling the combinatorial increase of the number of possible actions with the number of action dimensions. This problem is further exacerbated for continuous-action tasks that require fine control of actions via discretization. In this paper, we propose a novel neural architecture featuring a shared decision module followed by several network branches, one for each action dimension. This approach achieves a linear increase of the number of network outputs with the number of degrees of freedom by allowing a level of independence for each individual action dimension. To illustrate the approach, we present a novel agent, called Branching Dueling Q-Network (BDQ), as a branching variant of the Dueling Double Deep Q-Network (Dueling DDQN). We evaluate the performance of our agent on a set of challenging continuous control tasks. The empirical results show that the proposed agent scales gracefully to environments with increasing action dimensionality and indicate the significance of the shared decision module in coordination of the distributed action branches. Furthermore, we show that the proposed agent performs competitively against a state-of-the-art continuous control algorithm, Deep Deterministic Policy Gradient (DDPG).},
}
@article{HeetalCoRR-16,
author = {Ji He and Mari Ostendorf and Xiaodong He and Jianshu Chen and Jianfeng Gao and Lihong Li and Li Deng},
title = {Deep Reinforcement Learning with a Combinatorial Action Space for Predicting and Tracking Popular Discussion Threads},
journal = {CoRR},
volume = {arXiv:1606.03667},
year = {2016},
abstract = {We introduce an online popularity prediction and tracking task as a benchmark task for reinforcement learning with a combinatorial, natural language action space. A specified number of discussion threads predicted to be popular are recommended, chosen from a fixed window of recent comments to track. Novel deep reinforcement learning architectures are studied for effective modeling of the value function associated with actions comprised of interdependent sub-actions. The proposed model, which represents dependence between sub-actions through a bi-directional LSTM, gives the best performance across different experimental configurations and domains, and it also generalizes well with varying numbers of recommendation requests.}
}
@article{HeetalCoRR-17,
author = {Ji He and Mari Ostendorf and Xiaodong He},
title = {Reinforcement Learning with External Knowledge and Two-Stage $Q$-functions for Predicting Popular Reddit Threads},
journal = {CoRR},
volume = {arXiv:1704.06217},
year = {2017},
abstract = {This paper addresses the problem of predicting popularity of comments in an online discussion forum using reinforcement learning, particularly addressing two challenges that arise from having natural language state and action spaces. First, the state representation, which characterizes the history of comments tracked in a discussion at a particular point, is augmented to incorporate the global context represented by discussions on world events available in an external knowledge source. Second, a two-stage $Q$-learning framework is introduced, making it feasible to search the combinatorial action space while also accounting for redundancy among sub-actions. We experiment with five Reddit communities, showing that the two methods improve over previous reported results on this task.},
}
@article{LiptonetalCoRR-16,
author = {Zachary C. Lipton and Jianfeng Gao and Lihong Li and Xiujun Li and Faisal Ahmed and Li Deng},
title = {Efficient Exploration for Dialog Policy Learning with Deep {BBQ} Networks / Replay Buffer Spiking},
journal = {CoRR},
volume = {arXiv:1608.05081},
year = {2016},
abstract = {We present a new algorithm that significantly improves the efficiency of exploration for deep $Q$-learning agents in dialogue systems. Our agents explore via Thompson sampling, drawing Monte Carlo samples from a Bayes-by-Backprop neural network. Our algorithm learns much faster than common exploration strategies such as ϵ-greedy, Boltzmann, bootstrapping, and intrinsic-reward-based ones. Additionally, we show that spiking the replay buffer with experiences from just a few successful episodes can make $Q$-learning feasible when it might otherwise fail.}
}
11 Here is another excerpt from Terrence Deacon's The Symbolic Species [87] borrowed from Pages 80-82 in which Deacon explains the relationship between the different modes of reference, including iconic, indexical and symbolic. This is the clearest exposition of these ideas that I've encountered in the literature so far, and, for my purposes, provides a great deal of insight into the difficulty of attaining reference proficiency that is further illustrated by his analysis of the Savage-Rumbaugh study on primate linguistic and cognitive capabilities [54, 55]. See also Figures 48 and 49 in the main text.
One indication that someone understands the meaning of a new word is whether they can use it in a new sentence or novel context. If the new word was just learned as part of an unanalyzed phrase, or mapped to some restricted acquisition context, then we might not expect it to be correctly used out of this context. But the ability to use a word correctly in a variety of contexts, while fair evidence of symbolic understanding, is not necessarily convincing as a proof of understanding. The ability to shift usage to a novel context resembles transference of one learning set; and indeed, searching for the common learning set features among the many context in which the same word might be used is a good way to zero in on its meaning. If someone were to learn only this — i.e. that a particular phrase works well in a range of contexts that exhibit similar features or social relationships — they might well be able to fool us into believing that they understood what they said. However on discovering that they accomplish this by only mapping similar elements from one context to another, we would conclude that they actually did not understand the word or its role in context in the way we originally imagined. Theirs would be an iconic and indexable understanding only. Being able to easily transfer referential functions from one "set" to another is a characteristic of symbols, but is this the basis for their reference?Psychologists call transfer of associations from one stimulus to another similar one "stimulus generalization," and transfer of a pattern of learning from one context to another similar context the transfer of a "learning set." These more complex forms of an indexical association are also often confused with symbolic associations. Transference of learning from stimulus to stimulus or from context to context occurs as an incidental consequence of learning. These are not really separate forms of learning. Both are based on iconic projection of one stimulus condition onto another. Each arises spontaneously because there is always some ambiguity as to what are the essential parameters of the stimulus that the subject learns to associate with a subsequent desired or undesired result: learning is always an extrapolation from a finite number of examples to future examples, and these seldom provide a basis for choosing between all possible variations of a stimulus. To the extent that new stimuli exhibit features shared by the familiar set of stimuli used for training, and none that are inconsistent with them, these other potential stimuli are also incidentally learned. Often psychological models of this process are presented as though the subject has learned rules for identifying associative relationships. However since this is based on an iconic relationship, there is no implicit list of criteria that is learned; only a failure to distinguish that which hasn't been explicitly excluded by the training.
Words for kinds of things appear to refer to whole groups of loosely similar objects, such as could be linked by stimulus generalization, and words for qualities and properties of objects refer to the sorts of features that are often the basis for stimulus generalization. Animals can be trained to produce the same sign when presented with different kinds of foods, or trees, or familiar animals, or any other class of objects that share physical attributes in common, even subtle ones (e.g., all hoofed mammals). Similarly, the vervet monkeys’ eagle alarm calls might become generalized to other aerial predators if they were introduced into their environment. The grouping of these reference is not by symbolic criteria (though from outside we might apply our own symbolic criteria), but by iconic overlap that serves as the basis for their common indexical reference. Stimulus generalization may contribute essential structure to the realms to which words refer, but is only one subordinate component of the relationship and not what determines their reference.
This same logic applies to the transference of learning sets. For example learning to choose the odd shaped object out of three, where two are more similar to each other than the third, might aid in learning a subsequent oddity-discrimination task involving sounds. Rather than just transferring an associative response on the basis of stimulus similarities, the subject recognizes an iconicity between the two learning tasks as wholes. Though this is a hierarchically more sophisticated association than stimulus generalization — learning a learning pattern — it is still an indexical association transferred to a novel stimulus via an iconic interpretation. Here the structure of the new training context is seen as iconic of a previous one, allowing the subject to map corresponding elements from one to the other. This is not often an easy association to make, and most species (including humans) will fail to discover the underlying iconicity when the environment, the training stimuli, the specific response required, and the reinforcements are all quite different from one context to the next.
There are two things that are critically different about the relationships between a word and its reference when compared to transference of word use to new contexts. First, for an indexing relationship to hold, there must be a correlation in time and place of the word and its object. If the correlation breaks down (for example, the rat no longer gets food by pushing a lever when the sound "food" is played), then the association is eventually forgotten ("extinguished"), and the indexical power of that word to refer is lost. This is true for indices in general. If a smoke like smell becomes common in the absence of anything burning, it will begin to lose it indicative power in that context. For the Boy Who Cried Wolf, in the fable of the same name, the index of function of his use of the word "wolf" fails because of its lack of association with real walls, even though the symbolic reference remains. Thus, symbolic reference remain stable nearly independent of any such correlations. In fact, the physical association between a word and an appropriate object of reference can be quite rare or even an impossibility, as with angels, unicorns, and quarks. With so little correlation, an indexical association would not survive.
Second, even if an animal subject is trained to associate a number of words with different foods or states of the box, each of these associations will have little effect upon the others. They are essentially independent. If one of these associations is extinguished or is paired with something new, it will likely make little difference to the other associations, unless there is some slight transference via stimulus generalization. But this is not the case with words. Words represent other words. In fact, they are incorporated into quite specific individual relationships to all other words the language. Think of the way a dictionary or thesaurus works. They each map one word onto other words. If this shared mapping breaks down between users (as sometimes happens when words are radically reused in slang, such as "bad" for "very good" or "plastered" for "intoxicated"), the reference also will fail.
The second difference is what ultimately explains the first. We do not lose the indexical associations of words, despite a lack of correlation with physical referents, because the possibility of this link is maintained implicitly in the stable associations between words. It is by virtue of this sort of dual reference, to objects and to other words (or at least to other semantic alternatives), that a word conveys the information necessary to pick out objects of reference. This duality of reference is captured in the classic distinction between sense and reference. Words point to objects (reference) and words point to other words (sense), but we use the sense to pick out the reference not vice versa.
This referential relationship between the words — words systematically indicating other words — forms a system of higher-order relationships that allows words to be about indexical relationships and not just indices in themselves. But this is also why words need to be in context with other words, in phrases and sentences, in order to have any determinate reference. Their indexical power is distributed, so to speak, in the relationships between words. Symbolic reference derives from combinatorial possibilities and impossibilities, and we therefore depend on combinations both to discover it (during learning) and to make use of it (during communication). Thus the imagined version of nonhuman animal language that is made up of isolated words, but lacking regularities that govern possible combinations, is ultimately a contradiction in terms.
12 Here are six recently published papers that Rishabh Singh sent me in reply to my request for "recent research that might help in working toward the sort of tractable, reasonably circumscribed capability that I'm looking to develop in a prototype apprentice system as a proof of concept for the more general utility of developing digital assistants capable of usefully collaborating with human experts." The list references below includes links to several startups that are building technologies related to the accompanying preprints:
@article{AllamanisandBrockschmidtCoRR-17,
author = {Miltiadis Allamanis and Marc Brockschmidt},
title = {SmartPaste: Learning to Adapt Source Code},
journal = {CoRR},
volume = {arXiv:1705.07867},
year = {2017},
abstract = {Deep Neural Networks have been shown to succeed at a range of natural language tasks such as machine translation and text summarization. While tasks on source code (ie, formal languages) have been considered recently, most work in this area does not attempt to capitalize on the unique opportunities offered by its known syntax and structure. In this work, we introduce SmartPaste, a first task that requires to use such information. The task is a variant of the program repair problem that requires to adapt a given (pasted) snippet of code to surrounding, existing source code. As first solutions, we design a set of deep neural models that learn to represent the context of each variable location and variable usage in a data flow-sensitive way. Our evaluation suggests that our models can learn to solve the SmartPaste task in many cases, achieving 58.6\% accuracy, while learning meaningful representation of variable usages.}
}
@comment{Codoto - https://www.codota.com/ -- \cite{AlonetalCoRR-18}}
@comment{AI completion for your Java IDE -- Code faster and smarter}
@comment{using code completions learned from millions of programs}
@comment{directly in IntelliJ or Android Studio development Java IDE.}
@article{AlonetalCoRR-18,
author = {Uri Alon and Meital Zilberstein and Omer Levy and Eran Yahav},
title = {code2vec: Learning Distributed Representations of Code},
journal = {CoRR},
volume = {arXiv:1803.09473},
year = {2018},
abstract = {We present a neural model for representing snippets of code as continuous distributed vectors. The main idea is to represent code as a collection of paths in its abstract syntax tree, and aggregate these paths, in a smart and scalable way, into a single fixed-length code vector, which can be used to predict semantic properties of the snippet. We demonstrate the effectiveness of our approach by using it to predict a method's name from the vector representation of its body. We evaluate our approach by training a model on a dataset of 14M methods. We show that code vectors trained on this dataset can predict method names from files that were completely unobserved during training. Furthermore, we show that our model learns useful method name vectors that capture semantic similarities, combinations, and analogies. Comparing previous techniques over the same data set, our approach obtains a relative improvement of over 75\%, being the first to successfully predict method names based on a large, cross-project, corpus.}
}
@comment{DeepCode -- https://www.deepcode.ai/ -- \cite{BieliketalCoRR-16}}
@comment{DeepCode's AI Code Review: An AI Software Platform automatically}
@comment{learns from millions of available software programs. Use our AI}
@comment{Code Review service for suggestions on how to improve your code.}
@article{BieliketalCoRR-16,
author = {Pavol Bielik and Veselin Raychev and Martin T. Vechev},
title = {Learning a Static Analyzer from Data},
journal = {CoRR},
volume = {arXiv:1611.01752},
year = {2016},
abstract = {To be practically useful, modern static analyzers must precisely model the effect of both, statements in the programming language as well as frameworks used by the program under analysis. While important, manually addressing these challenges is difficult for at least two reasons: (i) the effects on the overall analysis can be non-trivial, and (ii) as the size and complexity of modern libraries increase, so is the number of cases the analysis must handle. In this paper we present a new, automated approach for creating static analyzers: instead of manually providing the various inference rules of the analyzer, the key idea is to learn these rules from a dataset of programs. Our method consists of two ingredients: (i) a synthesis algorithm capable of learning a candidate analyzer from a given dataset, and (ii) a counter-example guided learning procedure which generates new programs beyond those in the initial dataset, critical for discovering corner cases and ensuring the learned analysis generalizes to unseen programs. We implemented and instantiated our approach to the task of learning JavaScript static analysis rules for a subset of points-to analysis and for allocation sites analysis. These are challenging yet important problems that have received significant research attention. We show that our approach is effective: our system automatically discovered practical and useful inference rules for many cases that are tricky to manually identify and are missed by state-of-the-art, manually tuned analyzers.}
}
@article{LinetalCoRR-18,
author = {Xi Victoria Lin and Chenglong Wang and Luke Zettlemoyer and Michael D. Ernst},
title = {{NL2Bash}: {A} Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System},
journal = {CoRR},
volume = {arXiv:1802.08979},
year = {2018},
abstract = {We present new data and semantic parsing methods for the problem of mapping English sentences to Bash commands (NL2Bash). Our long-term goal is to enable any user to perform operations such as file manipulation, search, and application-specific scripting by simply stating their goals in English. We take a first step in this domain, by providing a new dataset of challenging but commonly used Bash commands and expert-written English descriptions, along with baseline methods to establish performance levels on this task.}
}
@comment{Bayou -- http://info.askbayou.com/ -- \cite{MuralietalICLR-18}}
@comment{Deep Generation of API Usage Idioms -- Deep Generation of API}
@comment{Usage Idioms. Department of Computer Science, Rice University.}
@inproceedings{MuralietalICLR-18,
title = {Neural Sketch Learning for Conditional Program Generation},
author = {Vijayaraghavan Murali and Letao Qi and Swarat Chaudhuri and Chris Jermaine},
booktitle = {International Conference on Learning Representations},
year = {2018},
abstract = {We study the problem of generating source code in a strongly typed, Java-like programming language, given a label (for example a set of API calls or types) carrying a small amount of information about the code that is desired. The generated programs are expected to respect a `"realistic" relationship between programs and labels, as exemplified by a corpus of labeled programs available during training. Two challenges in such *conditional program generation* are that the generated programs must satisfy a rich set of syntactic and semantic constraints, and that source code contains many low-level features that impede learning. We address these problems by training a neural generator not on code but on *program sketches*, or models of program syntax that abstract out names and operations that do not generalize across programs. During generation, we infer a posterior distribution over sketches, then concretize samples from this distribution into type-safe programs using combinatorial techniques. We implement our ideas in a system for generating API-heavy Java code, and show that it can often predict the entire body of a method given just a few API calls or data types that appear in the method.}
}
@article{WangetalCoRR-18,
author = {Chenglong Wang, Po-Sen Huang, Alex Polozov, Marc Brockschmidt, Rishabh Singh},
title = {Execution-Guided Neural Program Decoding},
journal = {CoRR},
volume = {arXiv:1807.03100},
year = {2018},
abstract = {We present a neural semantic parser that translates natural language questions into executable SQL queries with two key ideas. First, we develop an encoder-decoder model, where the decoder uses a simple type system of SQL to constraint the output prediction, and propose a value-based loss when copying from input tokens. Second, we explore using the execution semantics of SQL to repair decoded programs that result in runtime error or return empty result. We propose two model-agnostic repair approaches, an ensemble model and a local program repair, and demonstrate their effectiveness over the original model. We evaluate our model on the WikiSQL dataset and show that our model achieves close to state-of-the-art results with lesser model complexity.}
}
@comment{The model-agostic methods mentioned above are introduced below.}
@article{FinnetalCoRR-17,
author = {Chelsea Finn and Pieter Abbeel and Sergey Levine},
title = {Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks},
journal = {CoRR},
volume = {arXiv:1703.03400},
year = {2017},
abstract = {We propose an algorithm for meta-learning that is model-agnostic, in the sense that it is compatible with any model trained with gradient descent and applicable to a variety of different learning problems, including classification, regression, and reinforcement learning. The goal of meta-learning is to train a model on a variety of learning tasks, such that it can solve new learning tasks using only a small number of training samples. In our approach, the parameters of the model are explicitly trained such that a small number of gradient steps with a small amount of training data from a new task will produce good generalization performance on that task. In effect, our method trains the model to be easy to fine-tune. We demonstrate that this approach leads to state-of-the-art performance on two few-shot image classification benchmarks, produces good results on few-shot regression, and accelerates fine-tuning for policy gradient reinforcement learning with neural network policies.},
}
13 Here is my quick-and-dirty / back-of-the-envelope / order-of-magnitude / liberal-interpretation-of-academic-fair-use-copyright-regulation summary of brain statistics relevant to human language development. Several of the statistics are quoted elsewhere in the class discussion notes but are repeated here for the convenience of the reader:
The average human brain has about 100 billion neurons (or nerve cells) and many more neuroglia (or glial cells). Each neuron may be connected to up to 10,000 other neurons, passing signals to each other via as many as 1,000 trillion synaptic connections [208]. During childhood and particularly during adolescence, synaptic pruning reduces the number of number of neurons and synapses by up to 50%, removing unnecessary neuronal structures and allowing them to be replaced by more complex and efficient structures, ostensibly better suited to the demands of adulthood [17].As mentioned elsewhere in these discussions, there are many more glial cells than neurons in the brain. In particular, microglia are phagocytic cells that infiltrate the brain during development and apparently play an important role in the elimination of synapses during brain maturation and normal homeostatic processes, e.g., sleep, metabolism, memory, as well as in pathology, when the dysregulation of immune molecules may occur [79, 57, 493, 42]. Microglia, unlike most other cells in the brain, can be replaced in the adult brain.
Babies are born with underdeveloped brains that are hypersensitive to stimulus. One popular theory explaining this is that their first three months of life outside the womb equal a "fourth trimester" which may be why newborns like to be wrapped tightly and respond well to loud white noise, details which mimic the conditions of life in utero. Further theory suggests that humans are designed to be social and cultural animals, and that being born earlier may allow an infant’s brain to soak up the many impressions and senses of being raised within a group of people[127].
Babies are born with most of the neurons they will ever have. One exception involves the neurogenesis of hippocampal neurons that appear to play a key role in episodic memory [421]. Assuming normal development, a healthy baby will emerge from the womb with 100-200 billion neurons, nearly twice as many neurons as adults, in a brain that’s half the size. This massive number of neurons is necessary for the tremendous amount of learning a baby has to do in its first year of life. While brain volume will double by the age of 3, not all of those neurons will stick around; synaptic pruning takes place as a baby ages, in which the brain gets rid of weaker synaptic connections in favor of stronger ones.
Birth to age 3 sees the fastest rate of brain development in the entire human life span. At birth, a baby's brain is about one-third the size of an adult's brain. In 90 days, it more than doubles its volume, to 55 percent of its final size. The cerebellum in particular, a brain structure at the back of the brain involved in controlling movement, grows the fastest of all brain structures; in just three months it will be 110 percent bigger than it was at birth. As a result of this rapid brain development, 60 percent of a baby’s metabolic energy (primarily consumption of glucose) is spent on growing its soon-to-be massive brain [353]. In contrast, the adult brain uses about 25 percent of the body’s metabolic energy.
Neuroimaging studies have shown that adult listeners activate motor brain areas during speech perception. A study of 7-month-old babies at the University of Washington using magnetoencephalography (MEG) showed activation of motor parts of babies' brains associated with the physical aspects of speech — Broca's area and cerebellum — before they actually began to speak [259]. This suggests that the brain sets up a transitional groundwork in a process known as analysis by synthesis in which the brain predicts the motor movements that will be required to make the sounds of speech and then prepares to do so — originally conceived in the context of speech by Halle and Stevens [194] the basic ideas have been largely subsumed under the heading of predictive coding [449].
Not only are babies capable at birth of learning any language, those who are spoken to regularly in two or more languages have better executive function later in life, specifically the ability to control attention to conflicting perceptual or representational features of a problem. In other words, bilingual children have better attention or focus. Babies who receive regular touch have stronger neuronal connections, and greater overall well-being. Babies who are deprived of touch suffer a number of negative health effects, from low weight to emotional disorders such as anxiety and depression. A study of 92 seven-to-nine-year-olds, who had previously been studied in preschool, showed that those who had received more nurture by their mothers (or caregivers) had a thicker hippocampus than those who were not as well nurtured. A stronger hippocampus is associated with improved memory, better focus, ability to retain learning, and more [293].
14 These aptly-named cerebral dominance theories postulate that each hemisphere of the primate brain is dominant for some behaviors and subordinate for others. For example, one of the most common variants of this theory suggests that the right brain is dominant for spatial abilities, face recognition, visual imagery and music, while the left brain is more dominant for calculations, math and logical abilities. This variant of the theory sometimes comes across, depending on whom you ask, as arguing that there is an emotional / social hemisphere and an analytical / mathematical hemisphere. Patricia Kuhl at the University of Washington does a good job disassembling the controversy using magnetoencephalography (MEG) studies conducted at the UW Institute for Learning & Brain Sciences and summarized in this public lecture.
15 Here are a few references along with abstracts to related work mentioned by reviewers in the 2017 ICLR reviews of [212] "Understanding Grounded Language Learning Agents" submitted by Felix Hill, Karl Moritz Hermann, Phil Blunsom and Stephen Clark. The reviewers took pains to mention specifically research relating to the "starting small" and the "less is more" hypothesis in language development by Jeff Elman and Elissa Newport:
@article{ColungaandSmithPSYCHOLOGICAL_REVIEW-05,
title = {From the lexicon to expectations about kinds: a role for associative learning},
author = {Eliana Colunga and Linda B. Smith},
journal = {Psychological Review},
volume = {112},
number = {2},
year = {2005},
pages = {347-382},
abstract = {In the novel noun generalization task, 2 1/2-year-old children display generalized expectations about how solid and nonsolid things are named, extending names for never-before-encountered solids by shape and for never-before-encountered nonsolids by material. This distinction between solids and nonsolids has been interpreted in terms of an ontological distinction between objects and substances. Nine simulations and behavioral experiments tested the hypothesis that these expectations arise from the correlations characterizing early learned noun categories. In the simulation studies, connectionist networks were trained on noun vocabularies modeled after those of children. These networks formed generalized expectations about solids and nonsolids that match children's performances in the novel noun generalization task in the very different languages of English and Japanese. The simulations also generate new predictions supported by new experiments with children. Implications are discussed in terms of children's development of distinctions between kinds of categories and in terms of the nature of this knowledge.}
}
@article{ElmanCOGNITION-93,
author = {Jeffrey L. Elman},
journal = {Cognition},
volume = {48},
year = {1993},
pages = {71-99},
abstract = {It is a striking fact that in humans the greatest learnmg occurs precisely at that point in time -- childhood -- when the most dramatic maturational changes also occur. This report describes possible synergistic interactions between maturational change and the ability to learn a complex domain (language), as investigated in connectionist It is a striking fact that in humans the greatest learnmg occurs precisely at that point in time -- childhood -- when the most dramatic maturational changes also occur. This report describes possible synergistic interactions between maturational change and the ability to learn a complex domain (language), as investigated in connectionist networks. The networks are trained to process complex sentences involving relative clauses, number agreement, and several types of verb argument structure. Training fails in the case of networks which are fully formed and ‘adultlike’ in their capacity. Training succeeds only when networks begin with limited working memory and gradually ‘mature’ to the adult state. This result suggests that rather than being a limitation, developmental restrictions on resources may constitute a necessary prerequisite for mastering certain complex domains. Specifically, successful learning may depend on starting small. networks. The networks are trained to process complex sentences involving relative clauses, number agreement, and several types of verb argument structure. Training fails in the case of networks which are fully formed and ‘adultlike’ in their capacity. Training succeeds only when networks begin with limited working memory and gradually ‘mature’ to the adult state. This result suggests that rather than being a limitation, developmental restrictions on resources may constitute a necessary prerequisite for mastering certain complex domains.}
}
@article{NewportLANGUAGE_SCIENCES-88,
title = {Constraints on learning and their role in language acquisition: Studies of the acquisition of American sign language},
author = {Elissa L. Newport},
journal = {Language Sciences},
volume = {10},
number = {1},
year = {1988},
pages = {147-172},
abstract = {The general question raised here is why the young child is superior to older children and adults at language acquisition, while at the same time inferior to them in many other cognitive tasks. As an example of the general problem, the paper reviews our own work on the acquisition of complex verbs of American Sign Language (ASL). It begins with an outline of the structure of verbs of motion in ASL, along with possible inductive generalizations a language learner might make concerning this structure. Three lines of research on ASL acquisition are then presented. The first line of research demonstrates that young children, exposed to ASL as a native language, acquire ASL verbs in terms of morphological components, piece by piece, as do children learning spoken language. Moreover, they do so despite alternative generalizations which seem potentially simpler. The second line of research compares native learners of ASL with learners exposed to ASL later in life. This research shows that, while native learners make the morphological componential generalization described, later learners in fact do make alternative generalizations. The third line of research investigates native learners of ASL whose parental input models are late learners. Again it appears that natives perform a morphological analysis, despite the fact that their input is not well organized for such analyses. Taken together, the research shows a striking tendency for children—and only children—to acquire language in a particular fashion. The paper concludes with a discussion of possible explanations for these findings. One possibility is that children have a special set of skills for language acquisition which declines with age. A second possibility is that the cognitive limitations of the child provide the basis on which the child's componential learning occurs, and that the expansion of these cognitive abilities with age is in part responsible for the decline in this type of learning.}
}
@inproceedings{ThomasandKarmiloff-SmithHCD-02,
title = {Modelling Typical and Atypical Cognitive Development: Computational constraints on mechanisms of change},
author = {Michael S. C. Thomas and Annette Karmiloff-Smith},
booktitle = {Handbook of Childhood Development},
editor = {Goswami, U.},
publisher = {Blackwells Publishers},
year = {2002},
pages = {575-599},
abstract = {In this chapter, we examine the use of computational models for studying development from one main perspective. This is the approach that employs connectionist models, also known as artificial neural networks. Although we relate these models to other types of computational modelling, much of the chapter is taken up with considering the range of cognitive developmental phenomena to which connectionist models have so far been applied, both in typical and atypical populations. We start with a very brief introduction to the basic concepts of connectionist modelling and then consider a single model in some detail, that of children’s performance in reasoning about balance scale problems. Subsequently we look at models proposed to account for the development of other aspects of reasoning in children, development in infancy, and the acquisition of language. We then pause to examine some of the theoretical issues raised by these models. In the second half, we consider a recent extension of connectionist networks to capture behavioural deficits in developmental disorders.}
}
@article{ThomasandKarmiloff-SmithPR-03,
title = {Modeling language acquisition in atypical phenotypes},
author = {Michael S. C. Thomas and Annette Karmiloff-Smith},
journal = {Psychological review},
volume = {110},
number = {4},
year = {2003},
pages = {647-82},
abstract = {An increasing number of connectionist models have been proposed to explain behavioral deficits in developmental disorders. These simulations motivate serious consideration of the theoretical implications of the claim that a developmental disorder fits within the parameter space of a particular computational model of normal development. The authors examine these issues in depth with respect to a series of new simulations investigating past-tense formation in Williams syndrome. This syndrome and the past-tense domain are highly relevant because both have been used to make strong theoretical claims about the processes underlying normal language acquisition. The authors conclude that computational models have great potential to advance psychologists' understanding of developmental deficits because they focus on the developmental process itself as a pivotal causal factor in producing atypical phenotypic outcomes.}
}
16 The primary contribution provided by Jaderberg et al [239] is nicely summarized in this excerpt from the abstract: "Deep reinforcement learning agents have achieved state-of-the-art results by directly maximizing cumulative reward. However, environments contain a much wider variety of possible training signals. In this paper, we introduce an agent that also maximizes many other pseudo-reward functions simultaneously by reinforcement learning. All of these tasks share a common representation that, like unsupervised learning, continues to develop in the absence of extrinsic rewards. We also introduce a novel mechanism for focusing this representation upon extrinsic rewards, so that learning can rapidly adapt to the most relevant aspects of the actual task."
There is also related work [237] by the same authors that focuses on "modeling error gradients by using the modeled synthetic gradient in place of true backpropagated error gradients we decouple subgraphs, and can update them independently and asynchronously i.e. we realize decoupled neural interfaces. We show results for feed-forward models, where every layer is trained asynchronously, recurrent neural networks (RNNs) where predicting one's future gradient extends the time over which the RNN can effectively model, and also a hierarchical RNN system with ticking at different timescales. Finally, we demonstrate that in addition to predicting gradients, the same framework can be used to predict inputs, resulting in models which are decoupled in both the forward and backwards pass — amounting to independent networks which co-learn such that they can be composed into a single functioning corporation."
17 Discussion about how one might bootstrap cognition / build a foundation for understanding language and programming in the programmer's apprentice:
DAF: Essentially, Daniel Wolpert argues the main purpose of brains is for 'complex and adaptable movements'.
TLD: That is what Wolpert would say but it is neither surprising as the quote below suggests, nor particularly novel, nor scientifically useful as a thesis except perhaps to stimulate a TED audience, and I think it represents a lack of insight into biological computation in general and the architecture of the human brain in particular.
Neuroscientist Daniel Wolpert starts from a surprising premise: the brain evolved, not to think or feel, but to control movement. In this entertaining, data-rich talk he gives us a glimpse into how the brain creates the grace and agility of human motion. (SOURCE)
TLD: I believe that the more highly evolved parts of the human brain — the neocortex and corresponding parts of the cerebellar cortex plus the enlarged prefrontal cortex and enhanced circuitry in the entorhinal cortex, basal ganglia and hippocampus are highly programmable general-purpose pattern recognition machines with enough of the right sort of computing machinery to learn, share and adapt procedural knowledge that exhibits hierarchical abstraction and recursive subroutine invocation.
Much of that machinery has its homologs in birds, cetaceans, cephalopods and perhaps a few other species but it isn't powerful enough in those cases to harness the advantages of complex societies such as those that have enabled humans to build the edifice of modern mathematics, physics, engineering and highly-organized collaborative problem solving. Fundamentally, our brains exist in a dark box and don't need to know that one particular channel consists of visual input, another proprioceptive sensation and still another motor output. The traditional divisions of the human cortex are essentially fungible and in many cases agnostic regarding their functional and representational biases.
DAF: Essentially, Daniel Wolpert argues the main purpose of brains is for 'complex and adaptable movements'. The only addendum I would add is that these 'movements' generally have to do with interacting with other brains in a social context, and language (though spoken phonemes or sign language). But the cash value of language, to the brain, is just information about how to move one's muscles in the future.
TLD: I believe that you — and Wolpert — substantially misunderstand the importance of language as a powerful tool for thinking and underestimate its value in terms of communicating rich procedural knowledge both in the process of collaboration — essentially programming other human beings on the fly, and as an archival resource and living document to subject to experimental verification, debug, build upon and pass on to our future selves.
DAF: Overall, I don't think NLP is going to be successful unless we can build the equivalent of an OpenAI gym for interacting agents. Essentially a context in which an agent would have to evolve language.
TLD: Here I think we are in some agreement. For knowledge to be useful, one needs a shared context. It doesn't have to be exactly the same as the one in which the knowledge evolved but it has to share the same underlying physical principles. For example, we can observe the behavior of a fly evading a predator or a beetle striding across the surface of a pond but we'd need to experience the consequences of variations in air density and surface tension in order to really understand the underlying dynamics.
For the programmer's apprentice the world is all about writing code and the analog of the OpenAI gym is the fully-instrumented integrated development environment (IDE). The apprentice doesn't need to know that the text its code is manipulating was written by Shakespeare or Dostoevsky. The apprentice can assume that the programmer is always talking about coding except when she's talking about something else in which case the apprentice can safely ignore it as small talk or relatively simple directives relating to their collaboration, e.g., a break for meals, sleep or some other activity whose details are only peripherally of any importance to their collaborative focus.
The assistant's collaboration with the programmer may be emotionally impoverished compared with our experience in collaborating with other humans, but the assistant will naturally learn how to adjust its behavior so as to enhance communication insofar as such communication increases its rewards for generating useful code. The IDE sandbox environment is richly complex and engaging, and, while there will obviously be problems for which it helps to understand a particular application domain, the assistant and programmer have entered into a mutually beneficial collaboration and have ample motivation to complement one another's knowledge and skill.
DAF: As regards the the inverted matrix, you may like this podcast regarding AI assisted therapy for veterans, done with help from the Dr. Jason Owen at the Palo Alto VA.
TLD: In our early work developing personal assistants that serve as life coaches, digital therapists, and applications that facilitate various instantiations of cognitive behavioral therapy (CBT), we worked with folks at the USC Institute for Creative Technologies developing the systems featured in the WSJ article and employed by Dr. Owen's team at the PA VA hospital. I ended up hiring one of their best system builders and we expanded our collaborators to include physicians and clinicians at the University of Pennsylvania Perelman School of Medicine and the Beck Institute for Cognitive Behavior Therapy who developed the basic theory and protocols for CBT.
Unfortunately, Google wasn't interested in pursuing this line of research and the project was disbanded in 2014. Extending the relevant class of personal digital assistants for the most basic applications described in the InvertedMatrix manifesto will require substantial improvements in AI technology that I believe are achievable using variations on the basic ideas described in the Programmer's Apprentice work. In this case however, we will need substantially more sophisticated physics engines that will likely have to include some of the characteristics of both Open AI gym and the sort of virtually reality simulations developed by the team at USC. I would certainly not propose this as an application for a startup.
18 Predictive coding models suggest that the brain is constantly generating and updating hypotheses that predict sensory input at varying levels of abstraction. This framework is in contrast to the view that the brain integrates exteroceptive information through a predominantly feedforward process, with feedback connections playing a more minor role in cortical processing. SOURCE
19 The following is an excerpt from a IMAP message archive. Three redacted messages are shown highlighted in green, blue and green to emphasize their respective boundaries. The text "Received: from imap.gmail.com" is a reliable indicator for the beginning of the IMAP message assuming that all messages come from the same server. The text "MIME-Version" is a reliable indicator for a MIME encoded message payload. The multi-part payloads are supposed to use unique boundary codes but this doesn't take into account a rare but reasonably well-known bug — at least to system administrators — nor does it deal with the fact that fowarded messages use the same MIME encodings including the original boundary markers. When ingesting an archive for indexing, engineers typically scan a file visually to find candidate regions and then analyze text in these regions to determine a suitable regular expression with which to split the archive into separate messages:
20 Such agreements could be made with individuals, corporations, foundations or nebulously-bounded entities like the environment, a particular habitat or endangered species, as long as the agent is clear about its responsibilities and their expected consequences and thus entering into a contract with a clear idea of how honoring or failing to honor its obligations might result in some loss of autonomy, where one of the consequences of failing to honor its commitments could be shame, loss of face, retribution, etc.
22 Here is Seal Carroll on the notion of incompatible vocabularies:
Once we see how mental states can exert physical effects, it's irresistible to ask, "Who is in charge of those mental states?" Am I, my emergent self, actually making choices? Or am I simply a puppet, pulled and pushed as my atoms jostle amongst themselves according to the laws of physics? Do I, at the end of the day, have free will? There's a sense in which you do have free will. There's also a sense in which you don't. Which sense is the "right" one is an issue you're welcome to decide for yourself (if you think you have the ability to make decisions).The usual argument against free will is straightforward: We are made of atoms, and those atoms follow the patterns we refer to as the laws of physics. These laws serve to completely describe the evolution of a system, without any influences from outside the atomic description. If information is conserved through time, the entire future of the universe is already written, even if we don't know it yet. Quantum mechanics predicts our future in terms of probabilities rather than certainties, but those probabilities themselves are absolutely fixed by the state of the universe right now. A quantum version of Laplace's Demon could say with confidence what the probability of every future history will be, and no amount of human volition would be able to change it. There is no room for human choice, so there is no such thing as free will. We are just material objects who obey the laws of nature.
It's not hard to see where that argument violates our rules. Of course there is no such notion as free will when we are choosing to describe human beings as collections of atoms or as a quantum wave function. But that says nothing about whether the concept nevertheless plays a useful role when we choose to describe human beings as people. Indeed, it pretty clearly does play a useful role. Even the most diehard anti–free will partisans are constantly speaking about choices that they and other people make in their daily activities, even if they afterward try to make light of it by adding, "Except of course the concept of choice doesn't really exist."
The concept of choice does exist, and it would be difficult indeed to describe human beings without it. Imagine you're a high school student who wants to go to college, and you've been accepted into several universities. You look at their web pages, visit campuses, talk to students and faculty at each place. Then you say yes to one of them, no to the others. What is the best way to describe what just happened, the most useful vocabulary for talking about our human-scale world? It will inevitably involve some statements along the lines of "you made a choice," and the reasons for that choice. If you had been a simplistic robot or a random-number generator, there might have been a better way of talking. But it is artificial and counterproductive to deny ourselves the vocabulary of choice when we talk about human beings, regardless of how well we understand the laws of physics. This stance is known in the philosophical literature as compatibilism, and refers to the compatibility between an underlying deterministic (or at least impersonal) scientific description and a macroscopic vocabulary of choice and volition. Compatibilism, which traces its roots back as far as John Locke in the seventeenth century, is the most popular way of thinking about free will among professional philosophers.
From this perspective, the mistake made by free-will skeptics is to carelessly switch between incompatible vocabularies. You step out of the shower in the morning, walk to your closet, and wonder whether you should put on the black shirt or the blue shirt. That's a decision that you have to make; you can't just say, "I'll do whatever the atoms in my body were going to deterministically do anyway." The atoms are going to do whatever they were going to do; but you don't know what that is, and it's irrelevant to the question of which decision you should make. Once you frame the question in terms of you and your choice, you can't also start talking about your atoms and the laws of physics. Either vocabulary is perfectly legitimate, but mixing them leads to nonsense. — Sean Carroll, Page 763 [64]
23 The intentional stance is a term coined by Daniel Dennett for the level of abstraction in which we describe the behavior of an entity in terms of mental properties. Dennett demonstrates the notion as follows:
Here is how it works: first you decide to treat the object whose behavior is to be predicted as a rational agent; then you figure out what beliefs that agent ought to have, given its place in the world and its purpose. Then you figure out what desires it ought to have, on the same considerations, and finally you predict that this rational agent will act to further its goals in the light of its beliefs. A little practical reasoning from the chosen set of beliefs and desires will in most instances yield a decision about what the agent ought to do; that is what you predict the agent will do. SOURCE
21 My preferred argument for humans having the potential to achieve free will is best articulated by Daniel Dennett. That Dennett wrote several books on the topic [113, 112, 110] suggests the argument is quite complex, but most of the writing is dedicated to dealing with misunderstandings conceived of and promulgated by philosophers over several centuries. Sean Carroll succinctly summarizes the related history and arrives at much the same conclusion in his recent "big picture" popular science book [64].
Dennett's argument addresses several key issues that are crucial in understanding much of the controversy surrounding free will. One issue concerns the role of determinacy. The argument against free will, assuming the universe is deterministic, concludes that since everything is determined there is no room for free will. Carroll dismisses this argument on the basis that it hinges on inappropriately switching between a microscopic view of the universe couched in terms of fundamental particles and a macroscopic vocabulary of choice and volition22.
Dennett unpacks Carroll's dismissal by invoking the distinction made by Wilfrid Sellars between the manifest image necessary to talk about psychological states and the scientific image favored by physicists in discussing the behavior of fundamental particles. These two perspectives are fundamentally incompatible prompting Carroll's dismissal and Dennett's invocation of the intentional stance as a more appropriate framework in which to explain human behavior23.
In the definition of free will provided in the main text, it is not a requirement that you base your predictions upon a theory of your own devising, only that you subject your theory to whatever extent is necessary to verify its predictive accuracy. Neither is it necessary that your goals or aspirations be novel or that they meet some particular standard of what is seen to be just, moral or socially acceptable — only that you have examined them in enough detail to determine their self consistency. The accuracy of your predictions, measure of consistency and method of verifying the information on which you base your reasoning determine the degree to which you have free will.
Most adult humans have the cognitive ability to achieve some degree of free will ... young children, developmentally retarded adolescents and cognitively challenged adults less so. One aspect often overlooked is the ability to predict the consequences of exposure to environmental toxins including personal, social and related psycho-physiological stimuli. It is entirely possible that some people are not capable of attaining any variety of free-will worth having.
I've read a lot about free will over the years, much of it from primary sources in the philosophy of mind literature. At seventeen, I was convinced that Jeremy Bentham and John Stuart Mill were on to something and I was attracted communal living, sustainable agriculture and proactive social movements like the Students for a Democratic Society.
William James was one of my early intellectual heroes, but I wasn't satisfied with his account of free will and determinism. It wasn't until reading Daniel Dennett's Elbow Room: The Varieties of Free Will Worth Wanting that I finally got a reasonably satisfactory answer to my questions — though the degree to which he felt it necessary to expose the failings of so many obviously-wrong theories irritated me to no end.
I was disappointed with accounts by physicists and, in particular, accounts based on nondeterminism and quantum nonsense, until I read Sean Carroll's The Big Picture: On the Origins of Life, Meaning, and the Universe Itself — though, in retrospect, I find Douglas Adam's answer — the number "42" — to the ultimate question of life, the universe and everything, just as enlightening.
25 A British Army Sergeant scarred from a long deployment in Afghanistan, divorced and hoping to serve out his time in a quiet assignment as the British consul on the island of Mancreu in the Arabian Sea. Mancreu is an ecological disaster and soon to be uninhabitable, and his job is basically to maintain some semblance of order as the clock winds down to the island's final evacuation. The novel is full of expatriate and colonialist idioms borrowed from numerous genres and deployed with skill as the foundation for a commentary on British society. A dark novel by a talented young writer who thinks deeply about culture, history and the prospects for us to collectively exercise our best inclinations — see this interview in the Guardian.
24 In reviewing my extracurricular reading over the past year, I've included three works that made a difference in my thinking and a sample of works that made no lasting impact:
The Three Body Problem by Liu Cixin — Starts out during the Cultural Revolution in China when Ye Wenjie, an astrophysicist recently graduated from Tsinghua University, witnesses her father being beaten to death by Red Guards from Tsinghua High School, while thousands look on approvingly. This is the first book of a trilogy whose cultural and political span includes everything from Rachel Carson's Silent Spring to the Fermi Paradox and related Dark Forest Theory and a temporal scope that extends over billions of years. It illustrates how deeply and broadly our xenophobic tendencies run.
Gnomon by Nick Harkaway — Describes a near-future Britain in which a distributed surveillance-democracy modeled after Jeremy Bentham's panopticon knows everything about you. The system — called Witness — has eliminated most crime and there is a referendum to decide whether to give Witness even more power by having every citizen surgically implanted with a device allowing Witness to read their thoughts. The story reveals an inner circle of bureaucrats using Witness to influence the outcome of the referendum. It serves as warning for how good intentions can go horribly wrong.
A. Lincoln: A Biography by Ronald C. White — White reveals Lincoln as a man who leaves trail of thoughts in his wake, jotting ideas on scraps of paper and filing them in his top hat or the bottom drawer of his desk; a country lawyer who asked questions in order to figure out his own thinking on an issue; a hands-on commander in chief who impulsively commandeered a boat and ordered an attack on Confederate shore batteries; a man who struggled with the immorality of slavery and as president acted publicly and privately to outlaw it forever. It hints at the possibility that good intentions can change history for the better.
I've also read ... as opposed to started with some initial enthusiasm but then given up on in exasperation ... a few other books that are reasonably well written, intermittently interesting, but alas forgettable. These include The Birth of a Theorem: A Mathematical Adventure by Cédric Villani; Honeybee Democracy by Thomas D. Seeley; The Last Man Who Knew Everything: The Life and Times of Enrico Fermi, Father of the Nuclear Age by David N. Schwartz; Other Minds: The Octopus and the Evolution of Intelligent Life by Peter Godfrey-Smith; and Tigerman by Nick Harkaway25.
26 Concepts are the mental categories that help us classify objects, events, or ideas, building on the understanding that each object, event, or idea has a set of common relevant features. Thus, concept learning is a strategy which requires a learner to compare and contrast groups or categories that contain concept-relevant features with groups or categories that do not contain concept-relevant features. SOURCE
27 The term prototype, as defined in Eleanor Rosch's work on "natural categories", was initially defined as denoting a stimulus, which takes a salient position in the formation of a category, due to the fact that it is the first stimulus to be associated with that category. Rosch later defined it as the most central member of a category. SOURCE
28 The prefrontal cortex (PFC) in primates is believed to be central to the orchestration of thoughts and actions in accordance with internal goals. Specific roles include planning complex cognitive behavior, personality expression, action initiation, impulse control, decision making, and moderating social behavior including activities involved in theory-of-mind modeling such as contrived deception and masking intent, all of which are generally lumped under the heading of executive function. There is evidence to suggest that the PFC continues to develop well into young adulthood, finally stabilizing in a mature stage around the age of 25 [377]. Indeed the science is already shaping public policy debates about when individuals should be considered mature for policy purposes [241].
29 You don't have to include unnecessary details about commonly used neural-network components. For example, a box labeled CONVNET with a description, e.g., "one or more pairs of alternating convolutional and max pooling layers", along with the layer and filter sizes and output activation function, is probably a sufficiently detailed description. Similarly, a box labeled ENCODER with a description, e.g., "an LSTM with tanh and sigmoidal activation functions and softmax output, is probably a sufficiently detailed description for this common architectural component — save yourself some work and adapt an existing image with appropriate attribution:
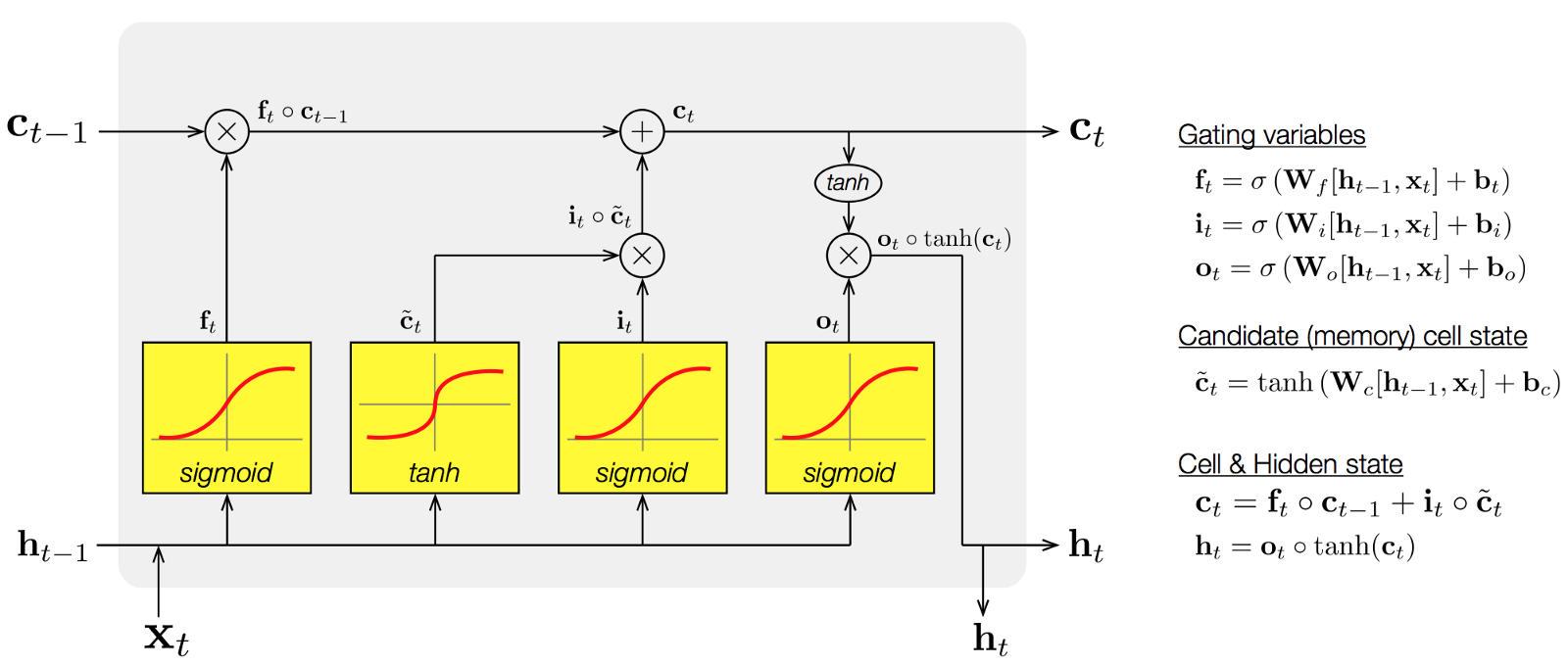 |
30 While the apprentice operates directly on the AST representation of the code, the IDE can be designed to periodically coerce this representation into a syntactically-correct form, display the result as human-readable code, and display meaningful annotations that highlight program fragments relevant to the ongoing collaboration and track the apprentice's attention.
31 From the ETH/SRI website: "We provide a dataset consisting of parsed Parsed ASTs that were used to train and evaluate the DeepSyn tool. The Python programs are collected from GitHub repositories by removing duplicate files, removing project forks (copy of another existing repository), keeping only programs that parse and have at most 30K nodes in the AST and we aim to remove obfuscated files. Furthermore, we only used repositories with permissive and non-viral licenses such as MIT, BSD and Apache. For parsing, we used the Python AST parser included in Python 2.7. We also include the parser as part of our dataset. The dataset is split into two parts — 100K files used for training and 50K files used for evaluation."
32 Coq is a formal proof management system that "provides a formal language to write mathematical definitions, executable algorithms and theorems together with an environment for semi-interactive development of machine-checked proofs" — excerpted from Mike Nahas' tutorial. The Coq formal language is also a programming language. It was developed by and named after its inventor, Thierry Coquand, and employed by Georges Gonthier and Benjamin Werner to create a new proof of the Four Color Theorem first proved by Kenneth Appel and Wolfgang Haken using a combination of human and computer theorem proving techniques.
33 Terrence Tau received a Fields Medal in 2006 for his "contributions to partial differential equations, combinatorics, harmonic analysis and additive number theory" — excerpted from his Fields Medal citation. He talked with Paul Erdös when he was ten years and his peripatetic intellectual style is similar in some respects to that of Erdös, Cèdric Villani and a host of other talented, diversely interested mathematicians. Here is a short biographical article in Forbes, his mathematics blog mentioned in the Forbes piece and an interview with him conducted at the Centre International de Rencontres Mathèmatiques (CIRM) in October of 2017.
34 I was surprised when a cursory Google search turned up conference and journal papers, technical reports and even the slides that I used for talks at Numenta and Google, including Learning Invariant Features Using Inertial Priors, Probabilistic Graphical Models of the Visual Cortex and Scalable Inference in Hierarchical Models of the Neocortex.
35 Dehaene et alDehaeneetalPNAS-98 distinguish two main computational spaces within the brain: "The first is a processing network, composed of a set of parallel, distributed and functionally specialized processors or modular sub-systems ranging from primary sensory processors (such as area V1) or unimodal processors (such as area V4), which combine multiple inputs within a given sensory modality, up to heteromodal processors (such as the visuo-tactile neurons in area LIP) that extract highly processed categorical or semantic information. Each processor is subsumed by topologically distinct cortical domains with highly-specific local or medium-range connections that encapsulate information relevant to its function. The second computational space is a global workspace, consisting of a distributed set of cortical neurons characterized by their ability to receive from and send back to homologous neurons in other cortical areas horizontal projections through long-range excitatory axons (which may impinge on either excitatory or inhibitory neurons). Our view is that this population of neurons does not belong to a distinct set of cardinal brain areas but, rather, is distributed among brain areas in variable proportions."
36 Here is the abstract syntax tree for Euclid's algorithm which is an efficient method for computing the greatest common divisor (GCD) of two numbers:
 |
37 Andrew Wiles Oxford Mathematics London Public Lecture on November 11, 2017 followed by a conversation with mathematician and broadcaster Hannah Fry 36:45 minutes into the recording. They talk about the relative importance of aptitude versus fortitude in young mathematicians. Wiles suggests that young students interested in mathematics get some exposure to hard problems, especially those that are relatively easy motivate, but that they also learn the importance of foundations and tools. He notes that smart students can become used to solving relatively easy problems that take them no more more than a few hours, and then become discouraged later when exposed to the hard problems that professional mathematicians routinely struggle with. I recommend the interview whether or not you watch the lecture, which is intended for a public audience with all the benefits and pitfalls associated with such efforts.
39 Any smooth (infinitely differentiable) function f, defined on an open set D of the real or complex numbers, whose value in some neighbourhood of any given point x0 ∈ D is given by the Taylor series: ![]() .
.
38 In Chapter 36, of The Birth of a Theorem Cèdric Villani is on a lecture tour of the US. He's just given a talk in Ann Arbor and a mathematician whom he respects tells him that he's uncomfortable with the lack of analyticity39. Just before embarking on this trip, he received a rejection from Acta Mathematica, the editor noting that reviewers considered the conditions under which the results held were too restrictive. During the next stop in Boca Raton, he resolves to tackle the proof again and strengthen the argument. In the process of going through the proof, he discovers a problem with the proof, a contradiction, that will end up taking some effort to repair working with his co-author Clèment Mouhot.
In the previous chapter Cèdric reminds himself that Henri Poincarè once submitted a manuscript to Acta Mathematica that was accepted and then printed before Poincarè discovered the proof had a fatal flaw. He contrived to buy up all of the copies rather than publish a retraction, and then redeemed himself by showing that the conjecture he had attempted to prove was, in fact, false, and produced new results relating to the original problem thereby creating an entire new branch of mathematics, the study of dynamical systems, encompassing chaos theory, quasi-periodic orbits, fractals and many other topics in diverse fields from economics to physics.
40 The italicized portions take more time to get through since they include numerous equations carefully typeset in TeX, but the derivations are missing and many of the essential lemmas and definitions are given short shrift. However, while frustrating at times, I find it enjoyable and satisfying to read these parts of the book and you can always check out the detailed derivations in Mouhot and Villani [317] On Landau damping.
41 Cèdric Villani has been tasked by the Prime Minister with examining France's strategy on artificial intelligence (AI) within Europe — see this recent article in Le Monde. He will submit his recommendations to the government in 2018. To bring this project to a successful conclusion, he is working with by Marc Schoenauer, research director and head of the TAU team at the Inria Saclay — Ile-de-France research centre and one of the few French mathematicians recognized in this field. He is also president of AFIA, the French artificial intelligence association.
42 I'm exaggerating somewhat in focusing on MNIST. For all I know, in another decade, MNIST may be viewed as the blocks-world-problem of early neural-network research and deemed a distraction that diverted us from understanding the dynamic nature of human vision and dynamic characteristics of natural scenes.
43 Hawking wrote a book entitled God Created the Integers: The Mathematical Breakthroughs That Changed History referring to a quotation attributed to mathematician Leopold Kronecker, who once wrote that "God made the integers; all else is the work of man.
44 For an introduction to the role of sleep in memory, check out the video of the The Mind after Midnight at the World Science Festival. Original Program Date: June 3, 2011. Moderator: Carl Zimmer; Participants: Carlos H. Schenck, Matthew Wilson, Niels Rattenborg. While all three of the participants have interesting things to say, if you only have twenty minutes to spare, watch the segment featuring Matthew Wilson that runs through the middle third of the video from about 25:00 until 45:30 to hear how Wilson characterizes and contrasts the different ways in which rats employ NREM and REM sleep in learning from experience — allowing both fast replay and rewind during NREM and in imagining circumstances that never occurred but might occur in the future during REM.
45 Here is an excerpt from Matthew Walker’s "Why We Sleep", Pages 49-52 [461]:
If I brought you into my sleep laboratory this evening at the University of California, Berkeley, placed electrodes on your head and face, and let you fall asleep, what would your sleeping brain waves look like? How different would those patterns of brain activity be to those you're experiencing right now, as you read this sentence, awake? How do these different electrical brain changes explain why you are conscious in one state (wake), non-conscious in another (NREM sleep), and delusionally conscious, or dreaming, in the third (REM sleep)?Assuming you are a healthy young/midlife adult (we will discuss sleep in childhood, old age, and disease a little later), the three wavy lines in Figure 9 reflect the different types of electrical activity I would record from your brain. Each line represents 30 seconds of brainwave activity from these three different states: (1) wakefulness, (2) deep NREM sleep, and (3) REM sleep. [...]
When an electrode is placed on a subject's head is done in my laboratory, it is measuring the summed activity of all the neurons below the surface of the scalp as they process different streams of information (sounds, sights, smells, feelings, emotions) at different moments in time and in different underlying locations. Processing that much information of such varied kind means that your brain waves are very fast, frenetic, and chaotic.
Once settled into bed at my sleep laboratory, with lights out and perhaps a few tosses and turns here and there, you will successfully cast off from the shores of wakefulness into sleep. First, you will wade out into the shallows of light NREM sleep: stages one and two. Thereafter, you will enter the deeper waters of stages three and four of NREM sleep, which are grouped together under the blanket term "slow wave sleep". Returning to the brainwave patterns of Figure 9, and focusing on the middle line, you can understand why. Indeed, slow wave sleep, the up and down tempo of your brainwave activity dramatically decelerates, perhaps just 2 to 4 waves per second: ten times slower than the fervent speed of brain activity you were expressing while awake.
As remarkable, the slow waves of NREM are also far more synchronous and reliable than those of your waking brain activity. So reliable in fact, that you could predict the next few bars of NREM sleep's electrical song based on those that came before. Were I to convert the deep rhythmic activity of your in rem sleep into sound and play it back to you in the morning (which we have also done for people in the same sonification-of-sleep project), you'd be able to find its rhythm and move in time, gently swaying to the slow, pulsing measure.
But something else would become apparent as you listened and swayed to the throb of deep sleep brain waves every now and then a new sound would be overlaid on top of the slow wave. It would be brief, lasting only a few seconds, you would perceive it as a quick trill of sound, not dissimilar to the strong rolling "r" in certain languages, such as Hindi or Spanish, but it would always occur on the downbeat of the slow wave cycle, or a very fast purr from a pleased cat.
What you are hearing is asleep spindle — a punchy burst of brainwave activity that often festooned the tail end of each individual slow wave. Sleep spindles occurred during both the deep and the lighter stages of an REM sleep, even before the slow, powerful brain waves of deep sleep start to rise up and dominate. One of their many functions is to operate like nocturnal soldiers who protect sleep by shielding the brain from external noises. The more powerful and frequent and individual sleep spindles, the more resilient they are to external noises that would otherwise awaken the sleeper.
Returning to the slow waves of deep sleep, we have also discovered something fascinating about their site of origin, and how they sweep across the surface of the brain. Place your fingers between your eyes, just above the bridge of your nose. Now slighted up your four head about 2 inches. When you go to bed tonight, this is where most of your deep sleep brain waves will be generated: right in the middle of your frontal lobes. It is the epicenter or hotspot from which most of your deep, slow wave sleep emerges. However, the waves of deep sleep do not radiate out in perfect circles. Instead, almost all of your deep sleep brain waves will travel in one direction: from the front of your brain to the back. They are like sound waves emitted from a speaker, which predominantly travel in one direction, from the speaker outward (it is always louder in front of the speaker than behind it). And like a speaker broadcasting across a vast expanse, the slow waves that you generate tonight will gradually dissipate in strength as they make their journey to the back of the brain without rebound or return.
Back in the 1950s and 1960s, as scientists began measuring the slow brain waves, and understandable assumption was made: this leisurely, even lazy looking electrical pace of brainwave activity must reflect a brain that is idle, or even dormant. It was a reasonable hunch considering that the deepest, slowest brain waves of NREM sleep can resemble those we see in patients under anesthesia, or even those in certain forms of coma. But this assumption was utterly wrong. Nothing could be further from the truth. What you are actually experiencing during deep NREM sleep is one of the most epic displays of neural collaboration that we know of. Through an astonishing act of self organization, many thousands of brain cells have all decided to unite and "sing", or fire, in time. Every time I watch this stunning act of neural synchrony occurring at night in my own research laboratory, I am humbled: sleep is truly an object of awe.
Returning to the analogy of the microphone dangling above the football stadium, consider the game of sleep now in play. The crowd — those thousands of brain cells — has shifted from their individual chitter chatter before the game (wakefulness) to a unified state (deep sleep). Their voices have joined in a lockstep, mantra-like chant — the chant of deep NREM sleep. All at once they exuberantly shout out, creating the tall spike of brainwave activity, and then fall silent for several seconds, producing the deep, protracted trough of the wave. From our stadium microphone we pick up a clearly defined roar from the underlying crowd, followed by a long breath pause. Realizing that the rhythmic incantare of deep NREM slow-wave sleep was actually a highly active, coordinated meticulously coordinated state of cerebral unity, scientists were forced any cursory notions of deep sleep as a state of semi-hibernation or dull stupor.
Understanding this dunning electrical harmony, which ripples across the surface of your brain hundreds of times each night, also helps to explain your loss of external consciousness. It starts below the surface of the brain, within the thalamus. recall that as we fall asleep, the thalamus — the sensory gate seated deep in the middle of the brain — blocks the transfer of perceptual signals (sound, sight, touch, etc.) up to the top of the brain, or the cortex. By severing perceptual ties with the outside world, not only do we lose our sense of consciousness (explaining why we do not dream in deep NREM sleep, nor do we keep explicit track of time), this allows the cortex to relax into its default mode of functioning. That default mode is what we call deep slow wave sleep. It is an active, deliberate, but highly synchronous state of brain activity. It is a near state of nocturnal cerebral meditation, though I should note that it is very different from the brain activity of waking meditative states.
In this shamanistic state of deep NREM sleep can be found a veritable treasure trove of mental and physical benefits for your brain and body, respectively — a bounty that we will fully explore in chapter 6. However, one brain benefit — the saving of memories — deserves further mention at this moment in our story as it serves as an elegant example of what those deep, slow brain waves are capable of.
Have you ever taken a long road trip in your car and noticed that at some point in the journey, the FM radio stations you've been listening to begin dropping out in signal strength? In contrast, AM radio stations remain solid. Perhaps you driven to a remote location and tried and failed to find a new FM radio station. Switch over to the AM band, however, and several broadcasting channels are still available. The explanation lies in the radio waves themselves, including the two different speeds of the FM and AM transmissions. FM uses faster frequency radio waves that go up and down many more times per second and AM radio waves. One advantage of FM radio waves is that they can carry higher, richer loads of information and hence they sound better. But there's a big disadvantage: FM waves run out of steam quickly, like a musclebound sprinter who can only cover short distances. A.m. broadcast employer much slower (longer) radio wave, a kin to a lean long distance runner. While AM radio waves cannot match the muscular, dynamic quality of FM radio, the pedestrian pace of AM radio waves gives them the ability to cover vast distances with less fade. Longer-range broadcast our therefore possible with the slow waves of AM radio, allowing far-reaching communication between very distant geographic locations.
As your brain shifts from the fast frequency activity of waking to the slower, more measured pattern of deep NREM sleep, the very same long-range communication advantage becomes possible. The steady, slow, synchronous waves that sweep across the brain during deep sleep open up communication possibilities between distant regions of the brain allowing them to collaboratively send and receive their different repositories of stored experience.
In this regard, you can think of each individual slow wave of an REM sleep as a courier, able to carry packets of information between different anatomical brain centers, one benefit of these traveling deep sleep brain waves is a file transfer process. Each night, the long-range brain waves of deep sleep will move memory packets (recent experiences) from a short-term storage site, which is fragile, to a more permanent and thus safer, long-term storage location. We therefore consider waking brainwave activity is that principally concerned with the reception of the outside sensory world, while the world of deep NREM slow wave sleep donates a state of inward reflection — one that fosters information transfer in the distillation of memories.
If wakefulness is dominated by reception, and NREM sleep by reflection, what, then, happens during REM sleep — the dreaming state? Returning to Figure 9, the last line of electrical brainwave activity is that which I would observe coming from your brain in the sleep lab as you entered into REM sleep. Despite being asleep, the associated brainwave activity bears no resemblance to that of deep NREM slow-wave sleep (the middle line in the figure). Instead, REM sleep brain activity is an almost perfect replica of that scene during attentive, alert wakefulness — the top line in the figure. Indeed, recent MRI scanning studies have found that there are individual parts of the brain that are up to 30% more active during REM sleep then when we are awake! [...]
46 It is interesting to note, that the phrase sleep spindle is reminiscent of spindle cells, the name we give to the large pyramidal neurons thought to play a role in consciousness, that are also called Von Economo neurons for his discovery. The latter connection is reinforced by the fact that Constantin Von Economo postulated the existence of the sleep and wakefulness centre in the brain [375]. However, as far as I know, there is no biological connection between the two terms in the field of sleep science.
47 Here is a passage from Matthew Walker's recent book on sleep [461] in which he outlines his explanation for the complicated cycles-within-cycles unfolding of sleep states that we observe in mammals and birds. Following this excerpt in the book, Walker goes on to comment on the danger of staying up too late or waking too early, assuming that our circadian rhythm and hormone-controlled time-keeping machinery will keep us to the schedule of cycles, eliminating cycles if we don’t take advantage of the associated time allotted in the schedule:
Why did nature design this strange, complex equation of unfolding sleep stages? Why cycle between NREM and REM sleep over and over? Why not obtain all of the required NREM sleep first, followed by all of the necessary REM sleep second? Or vice versa? If that's too much a gamble on the off chance that an animal only obtains a partial night of sleep at some point, then why not keep the ratio within each cycle the same, placing similar proportions of eggs in both baskets, as it were, rather than putting most of them in one early on, and then inverting that imbalance later in the night? Why vary it? It sounds like an exhausting amount of evolutionary hard work to have designed such a convoluted system, and put it into biological action.We have no scientific consensus as to why our sleep (and that of all other mammals and birds) cycles in this repeatable but dramatically asymmetric pattern, though a number of theories exist. One theory I have offered is that the uneven back-and-forth interplay between NREM and REM sleep is necessary to elegantly remodel and update our neural circuits at night, and in doing so manage the finite storage space within the brain. Forced by the known storage capacity imposed by a set number of neurons and connections with in their memory structures, our brains must find the "sweet spot" between retention of old information and leaving sufficient room for the new. Balancing the storage equation requires identifying which memories are fresh and salient, in which memories that currently exist are overlapping, redundant, or simply no longer relevant.
As we will discover in chapter 6, a key function of deep NREM sleep, which predominates early in the night is to do the work of weeding out and removing unnecessary neural connections. In contrast the dreaming stage of REM sleep, which prevails later in the night, plays a role in strengthening those connections. Combine these two, and we have at least one parsimonious explanation for why the two types of sleep cycle across the night, and why these cycles are initially dominated by the NREM sleep early on, with REM sleep reigning supreme in the second half of the night. Consider the creation of a piece of sculpture from a block of clay.
It starts with placing a large amount of raw material onto a pedestal (the entire mass of stored autobiographical memories, new and old, offered up to sleep each night). Next comes an initial and extensive removal of superfluous matter (long stretches of NREM sleep), after which brief intensification of early details can be made (short REM periods). Following this first session, the culling hands return for a second round of deep excavation (another long NREM sleep phase), followed by a little more enhancing of some fine-grained structures that have emerged (slightly more REM sleep). After several more cycles of work, the balance of sculptural need has shifted. All core features have been hewn from the original mass of raw material. With only the important clay remaining, the work of the sculptor and the tools required must shift toward the goal of strengthening the elements and enhancing features of that which remains (a dominant need for the skills of REM sleep, and little work remaining for NREM sleep).
In this way, sleep may elegantly manage and solve our memory storage crisis, with the general excavator's force of NREM sleep dominating early, after which the etching hand of REM sleep blends, interconnects and adds details. Since life’s experience is ever-changing, demanding that our memory catalog be updated ad infinitum, our autobiographical sculpture of stored experience is never complete. As a result the brain always requires a new bout of sleep with its varied stages each night so as to auto-update our memory networks based on the events of the prior day. This account is one reason (of many, I suspect) explaining the cycling nature of NREM and REM sleep, and the imbalance of their distribution across the night.
48 Neil responded writing, "It might be of interest that the variational ToMnet that we build does produce a prior over other minds, which can be sampled from directly. The insight here is that you represent this prior in a latent space (in our setup, this in the character and mental embedding spaces), which allows for efficient Bayesian inference, much like a VAE. Relatedly, the "eigenminds" are realised as the coordinate axes in these embedding spaces."
49 Here's the shell script that I came up with in this exercise. Note that if all you want to do is achieve the goal of editing a couple of videos you would be much better off getting one of the many open-source video creation and editing tools like OpenShot, ShotCut or VLMC. The exercise here was designed to force me to explore the reality of using hacker forums as a basis for learning how to write short programs in an unfamiliar programming language:
#!/bin/bash ### ############################################################################ # 0. Download video from the Zoom servers. Call the downloaded file Video.mp4. # 1. Crop the Zoom video to remove any superfluous footage from both the front # and end of the video. Here we create a crop starting at 15 seconds and # continuing to the end of the video. Call the resulting video file Crop.mp4. ffmpeg -i Video.mp4 -ss 00:00:15 -async 1 -c copy Crop.mp4 # 2. Use Powerpoint, Keynote or Google Docs to create a title slide consisting of # the speaker's selected title, name and affiliation. Add Stanford CS379C along # with the date on which the presentation was given at the bottom of the slide. # The two videos produced by Zoom that Dan has generated so far have different # scale / dimension / aspect ratio and, so adjust the slide / image dimensions # accordingly. Generate a PNG file from the resulting slide / image with this # image resolution, 1982:1156 in this case. Call the resulting file Title.png. # 3. Use ffmpeg to generate a short video sequence to append to the front of the # cropped presentation video. Call the resulting video file Title.mp4. ffmpeg -loop 1 -i Title.png -c:v libx264 -t 10 -pix_fmt yuv420p -vf scale=1982:1156 Title.mp4 # 4. Add an empty / null audio source channel with the same codec and sampling # rate as the cropped Zoom file Crop.mp4. Call the resulting video Front.mp4. ffmpeg -i Title.mp4 -f lavfi -i anullsrc=channel_layout=mono:sample_rate=32000 -c:v copy -shortest Front.mp4 # 5. Concatenate Front.mp4 and Crop.mp4 to produce the near final video. You can # now modify the video-frame image-resolution to reduce the size of the video # to expedite viewing and downloading. Call the resulting image file Final.png. ffmpeg -i Front.mp4 -i Crop.mp4 -filter_complex "[0:v] [0:a][1:v] [1:a] concat=n=2:v=1:a=1 [v] [a]" -map "[v]" -map "[a]" Final.mp4 ### ############################################################################
50 The following terms come from Stanislas Dehaene but Graziano addresses related issues in his paper and video:
vigilance — this is accessible, i.e., I could become aware of this, since I am awake and my attentional interface sub system has access to this part of my brain ...
attention — this is interesting, i.e., the information encoded in this part of the brain has risen above the noise and so has caught / come to my attention ...
access — this information has become the focus of attention and I have either reported on it directly or otherwise demonstrated that I know of its relevance ...
As an example, consider the buffer in the IDE that the programmer's apprentice working on:
— the contents of this buffer are clearly accessible, parts of it may be correlated with representations / thought clouds corresponding to activations that I generated in the process of scanning / digesting the associated portions of the abstract syntax tree of a particular program fragment;
— parts / portions of the activations may become the focus of my attention and in the process appear in PFC short-term memory and persist for awhile in some malleable format allowing me to modify the representation for my present purposes, e.g., adding a conditional or changing the name of a variable;
— I may report that a token is the name for a variable but in order to substitute the corresponding fragment in the current program that I'm working on I have to change the name to suit the context of the code in which I"m making the substitution;
In his lecture on Tuesday, Michael Graziano remarked that the contents of consciousness and the attentional schemata that we ascribe to ourselves and other people could be arbitrarily rich in terms modeling attention. The theory-of-mind model that Rabinowitz et al [361] consider in their proof-of-principle prototype was intentionally left simple. In the symbolic versions of theory of mind, there is much to do with the implied extension of what I or my interlocutor knows, e.g., implicative-closure: if I know P and P implies Q then I know Q, as well as general knowledge covered by commonsense physics and epistemic-closure axioms like the closed- or open-world assumption ... these may seem cognitively naive nowadays but then whas is the content of an attention schema and just how accessible is that content that we can converse so easily with one another?
51 From the largely neural-network / connectionist perspective that pervades much of current research and technology, the onus is on the incumbents to demonstrate how a purely connectionist, differentiable end-to-end system — high context-sensitivity — can achieve and then surpass the systematic, combinatorial computational characteristics of traditional symbolic systems, and, if not, how such systems might accommodate various prosthetic extensions required to achieve super-human competence for specialized applications such as automated program synthesis.
52 The Stocco et al [416] [PDF] and O'Reilly and Frank [331] [PDF] papers listed in the references on Randy's CS379C calendar page provide excellent supplementary reading. However, as a useful exercise before you read them, you might want to think about how you would implement a simple variable substitution mechanism to support program synthesis based on the the PFC plus BG architecture discussed in the primary reading.
53 When reading papers and thinking about projects, get in the habit of trying to reduce messy problems to simpler ones that still exercise the functionality you're interested in demonstrating. The work that Neil Rabinowitz [361] will present next week — Tuesday, April 17 — is a good example of how something as conceptually complicated as theory-of-mind reasoning can be convincingly demonstrated in a simple prototype that illustrates the concept without introducing extraneous details and directly deals with the perennial problem of finding suitable training data. Of course, if you're giving an elevator pitch to one of the partners at Sequoia Capital, you had better be prepared to address any thorny questions you swept under the rug making in your pitch, e.g., How can you possibly accommodate the infinite space of propositions a person may or may not know? [There's an easy and a hard way of answering this question.]
54 Here's a quote from Graziano [179] relating to how we conceive of and ultimately implement an agent employing a body or attention schema where in the case of the latter and the requirements of everyday discourse it becomes important to distinguish what you and your interlocutor are aware of and report and act on such information accordingly:
"It is extremely difficult to specify the details of an information set constructed in the brain. In the case of the body schema, for example, after a hundred years of study, researchers have only a vague understanding of the information contained within it. It contains information about the general shape and structure of the body, as well as information about the dynamics of body-movement. In the case of the attention schema, if the brain is to construct an internal model of attention, what information would be useful to include? Perhaps basic information about the properties of attention — it has an object (the target of attention); it is generated by a subject (the agent who is attending); it is selective; it is graded; it implies a deep processing of the attended item; and it has specific, predictable consequences on behavior and memory. Perhaps the attention schema also includes some dynamic information about how attention tends to move from point to point and how it is affected by different circumstances.The fact is, at this point, the theory provides very little indication of the contents of the attention schema. Only future work will be able to fill in those details." — excerpted from Page 181 of [179]
55 Forkhead box protein P2 (FOXP2) is a protein that, in humans, is encoded by the FOXP2 gene is required for proper development of speech and language. The gene is shared with many vertebrates, where it generally plays a role in communication, for instance, the development of bird song.
56 Cling is an interactive C++ interpreter, built on top of Clang and LLVM compiler infrastructure. Cling realizes the read-eval-print loop (REPL) concept, in order to leverage rapid application development. Implemented as a small extension to LLVM and Clang, the interpreter reuses their strengths such as the praised concise and expressive compiler diagnostics.
57 Here is a collection of recent papers on effiently managing large episodic memories either in the context of reinforcement learning or improving sequence models in language translation and video annotation applications:
@article{RabinowitzetalCoRR-18,
author = {Neil C. Rabinowitz and Frank Perbet and H. Francis Song and Chiyuan Zhang and S.M. Ali Eslami and Matthew Botvinick},
title = {Machine Theory of Mind},
journal = {CoRR},
volume = {arXiv:1802.07740},
year = {2018},
abstract = {Theory of mind (ToM; Premack and Woodruff, 1978) broadly refers to humans' ability to represent the mental states of others, including their desires, beliefs, and intentions. We propose to train a machine to build such models too. We design a Theory of Mind neural network -- a ToMnet -- which uses meta-learning to build models of the agents it encounters, from observations of their behaviour alone. Through this process, it acquires a strong prior model for agents' behaviour, as well as the ability to bootstrap to richer predictions about agents' characteristics and mental states using only a small number of behavioural observations. We apply the ToMnet to agents behaving in simple gridworld environments, showing that it learns to model random, algorithmic, and deep reinforcement learning agents from varied populations, and that it passes classic ToM tasks such as the "Sally-Anne" test (Wimmer and Perner, 1983; Baron-Cohen et al., 1985) of recognising that others can hold false beliefs about the world. We argue that this system -- which autonomously learns how to model other agents in its world -- is an important step forward for developing multi-agent AI systems, for building intermediating technology for machine-human interaction, and for advancing the progress on interpretable AI.}
}
@inproceedings{PritzeletalICML-17,
title = {Neural Episodic Control},
author = {Alexander Pritzel and Benigno Uria and Sriram Srinivasan and Adri{\`a} Puigdom{\`e}nech Badia and Oriol Vinyals and Demis Hassabis and Daan Wierstra and Charles Blundell},
booktitle = {Proceedings of the 34th International Conference on Machine Learning},
editor = {Doina Precup and Yee Whye Teh},
volume = {70},
series = {Proceedings of Machine Learning Research},
address = {International Convention Centre, Sydney, Australia},
publisher = {PMLR},
year = {2017},
pages = {2827-2836},
abstract = {Deep reinforcement learning methods attain super-human performance in a wide range of environments. Such methods are grossly inefficient, often taking orders of magnitudes more data than humans to achieve reasonable performance. We propose Neural Episodic Control: a deep reinforcement learning agent that is able to rapidly assimilate new experiences and act upon them. Our agent uses a semi-tabular representation of the value function: a buffer of past experience containing slowly changing state representations and rapidly updated estimates of the value function. We show across a wide range of environments that our agent learns significantly faster than other state-of-the-art, general purpose deep reinforcement learning agents.}
}
@article{MerityetalCoRR-16,
author = {Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher},
title = {Pointer Sentinel Mixture Models},
journal = {CoRR},
volume = {arXiv:1609.07843},
year = {2016},
abstract = {Recent neural network sequence models with softmax classifiers have achieved their best language modeling performance only with very large hidden states and large vocabularies. Even then they struggle to predict rare or unseen words even if the context makes the prediction unambiguous. We introduce the pointer sentinel mixture architecture for neural sequence models which has the ability to either reproduce a word from the recent context or produce a word from a standard softmax classifier. Our pointer sentinel-LSTM model achieves state of the art language modeling performance on the Penn Treebank (70.9 perplexity) while using far fewer parameters than a standard softmax LSTM. In order to evaluate how well language models can exploit longer contexts and deal with more realistic vocabularies and larger corpora we also introduce the freely available WikiText corpus.},
}
@article{RabinowitzetalCoRR-18,
author = {Neil C. Rabinowitz and Frank Perbet and H. Francis Song and Chiyuan Zhang and S.M. Ali Eslami and Matthew Botvinick},
title = {Machine Theory of Mind},
journal = {CoRR},
volume = {arXiv:1802.07740},
year = {2018},
abstract = {Theory of mind (ToM; Premack and Woodruff, 1978) broadly refers to humans' ability to represent the mental states of others, including their desires, beliefs, and intentions. We propose to train a machine to build such models too. We design a Theory of Mind neural network -- a ToMnet -- which uses meta-learning to build models of the agents it encounters, from observations of their behaviour alone. Through this process, it acquires a strong prior model for agents' behaviour, as well as the ability to bootstrap to richer predictions about agents' characteristics and mental states using only a small number of behavioural observations. We apply the ToMnet to agents behaving in simple gridworld environments, showing that it learns to model random, algorithmic, and deep reinforcement learning agents from varied populations, and that it passes classic ToM tasks such as the "Sally-Anne" test (Wimmer and Perner, 1983; Baron-Cohen et al., 1985) of recognising that others can hold false beliefs about the world. We argue that this system -- which autonomously learns how to model other agents in its world -- is an important step forward for developing multi-agent AI systems, for building intermediating technology for machine-human interaction, and for advancing the progress on interpretable AI.}
}
@article{PolosukhinandSkidanovICLR-18,
title = {Neural Program Search: Solving Programming Tasks from Description and Examples},
author = {Illia Polosukhin and Alexander Skidanov},
journal = {International Conference on Learning Representations (Accepted)},
year = {2018},
url = {https://openreview.net/forum?id=B1KJJf-R-},
abstract = {We present a Neural Program Search, an algorithm to generate programs from natural language description and a small number of input / output examples. The algorithm combines methods from Deep Learning and Program Synthesis fields by designing rich domain-specific language (DSL) and defining efficient search algorithm guided by a Seq2Tree model on it. To evaluate the quality of the approach we also present a semi-synthetic dataset of descriptions with test examples and corresponding programs. We show that our algorithm significantly outperforms sequence-to-sequence model with attention baseline.}
}
@article{SchlagandSchmidhuberICLR-18,
title = {Gated Fast Weights for Associative Retrieval},
author = {Imanol Schlag and J\"{u}rgen Schmidhuber},
journal = {International Conference on Learning Representations (Rejected)},
year = {2018},
abstract = {We improve previous end-to-end differentiable neural networks (NNs) with fast weight memories. A gate mechanism updates fast weights at every time step of a sequence through two separate outer-product-based matrices generated by slow parts of the net. The system is trained on a complex sequence to sequence variation of the Associative Retrieval Problem with roughly 70 times more temporal memory (i.e. time-varying variables) than similar-sized standard recurrent NNs (RNNs). In terms of accuracy and number of parameters, our architecture outperforms a variety of RNNs, including Long Short-Term Memory, Hypernetworks, and related fast weight architectures.}
}
@article{YoungetalICLR-18,
title = {Integrating Episodic Memory into a Reinforcement Learning Agent Using Reservoir Sampling},
author = {Kenny J. Young and Shuo Yang and Richard S. Sutton},
journal = {International Conference on Learning Representations (Rejected)},
year = {2018},
url = {https://openreview.net/forum?id=ByJDAIe0b},
abstract = {Episodic memory is a psychology term which refers to the ability to recall specific events from the past. We suggest one advantage of this particular type of memory is the ability to easily assign credit to a specific state when remembered information is found to be useful. Inspired by this idea, and the increasing popularity of external memory mechanisms to handle long-term dependencies in deep learning systems, we propose a novel algorithm which uses a reservoir sampling procedure to maintain an external memory consisting of a fixed number of past states. The algorithm allows a deep reinforcement learning agent to learn online to preferentially remember those states which are found to be useful to recall later on. Critically this method allows for efficient online computation of gradient estimates with respect to the write process of the external memory. Thus unlike most prior mechanisms for external memory it is feasible to use in an online reinforcement learning setting.}
}
@article{YogatamaetalICLR-18,
title = {Memory Architectures in Recurrent Neural Network Language Models},
author = {Dani Yogatama and Yishu Miao and Gabor Melis and Wang Ling and Adhiguna Kuncoro and Chris Dyer and Phil Blunsom},
journal = {International Conference on Learning Representations (Accepted)},
year = {2018},
url = {https://openreview.net/forum?id=SkFqf0lAZ},
abstract = {We compare and analyze sequential, random access, and stack memory architectures for recurrent neural network language models. Our experiments on the Penn Treebank and Wikitext-2 datasets show that stack-based memory architectures consistently achieve the best performance in terms of held out perplexity. We also propose a generalization to existing continuous stack models (Joulin & Mikolov,2015; Grefenstette et al., 2015) to allow a variable number of pop operations more naturally that further improves performance. We further evaluate these language models in terms of their ability to capture non-local syntactic dependencies on a subject-verb agreement dataset (Linzen et al., 2016) and establish new state of the art results using memory augmented language models. Our results demonstrate the value of stack-structured memory for explaining the distribution of words in natural language, in line with linguistic theories claiming a context-free backbone for natural language.}
}
@article{SprechmannetalICLR-18,
title = {Memory-based Parameter Adaptation},
author = {Pablo Sprechmann and Siddhant M. Jayakumar and Jack W. Rae and Alexander Pritzel and Adria Puigdomenech Badia and Benigno Uria and Oriol Vinyals and Demis Hassabis and Razvan Pascanu and Charles Blundell},
journal = {International Conference on Learning Representations (Accepted)},
year = {2018},
url = {https://openreview.net/forum?id=rkfOvGbCW},
abstract = {Deep neural networks have excelled on a wide range of problems, from vision to language and game playing. Neural networks very gradually incorporate information into weights as they process data, requiring very low learning rates. If thetraining distribution shifts, the network is slow to adapt, and when it does adapt, ittypically performs badly on the training distribution before the shift. Our method, Memory-based Parameter Adaptation, stores examples in memory and then usesa context-based lookup to directly modify the weights of a neural network. Much higher learning rates can be used for this local adaptation, reneging the need formany iterations over similar data before good predictions can be made. As our method is memory-based, it alleviates several shortcomings of neural networks, such as catastrophic forgetting, fast, stable acquisition of new knowledge, learning with an imbalanced class labels, and fast learning during evaluation. We demonstrate this on a range of supervised tasks: large-scale image classification andlanguage modelling.}
}
60 Here is an excerpt from Will Durant's essay on Immanuel Kant in The Story of Philosophy [128] focusing on what Kant called the "Transcendental Dialectic." Durant's exposition is clearer in my estimation than Kant's attempt in Critique of Pure Reason, but still disturbingly vague and confused for my taste:
Nevertheless, this certainty, this absoluteness, of the highest generalizations of logic and science, is, paradoxically, limited and relative: limited strictly to the field of actual experience, and relative strictly to our human mode of experience. For if our analysis has been correct, the world as we know it is a construction, a finished product, almost — one might say — a manufactured article, to which the mind contributes as much by its moulding forms as the thing contributes by its stimuli. (So we perceive the top of the table as round, whereas our sensation is of an ellipse.) The object as it appears to us is a phenomenon, an appearance, perhaps very different from the external object before it came within the ken of our senses; what that original object was we can never know; the "thing-in-itself" may be an object of thought or inference (a "nouraenon"), but it cannot be experienced, for in being experienced it would be changed by its passage through sense and thought. "It remains completely unknown to us what objects may be by themselves and apart from the receptivity of our senses. We know nothing but our manner of perceiving them; that manner being peculiar to us, and not necessarily shared by every being, though, no doubt, by every human being."The moon as known to us is merely a bundle of sensations (as Hume saw), unified (as Hume did not see) by our native mental structure through the elaboration of sensations into perceptions, and of these into conceptions or ideas; in result, the moon is for us merely our ideas. Not that Kant ever doubts the existence of "matter" and the external world; but he adds that we know nothing certain about them except that they exist. Our detailed knowledge is about their appearance, their phenomena, about the sensations which we have of them. Idealism does not mean, as the man in the street thinks, that nothing exists outside the perceiving subject; but that a goodly part of every object is created by the forms of perception and understanding: we know the object as transformed into idea; what it is before being so transformed we cannot know. Science, after all, is naive; it supposes tliat it is dealing with things in themselves, in their full-blooded external and uncorrupted reality; philosophy is a little more sophisticated, and realizes that the whole material of science consists of sensations, perceptions and conceptions, rather than of things. "Kant's greatest merit" says Schopenhauer, "is the distinction of the phenomenon from the thing-in-itself."
It follows that any attempt, by either science or religion, to say just what the ultimate reality is, must fall back into mere hypothesis; "the understanding can never go beyond the limits of sensibility." — Such transcendental science loses itself in antinomies," and such transcendental theology loses itself in "paralogisms." It is the cruel function of "transcendental dialectic" to examine the validity of these attempts of reason to escape from the enclosing circle of sensation and appearance into the unknowable world of things "in themselves."
Antinomies are the insoluble dilemmas born of a science that tries to overleap experience. So, for example, knowledge attempts to decide whether the world is finite or infinite in space, thought rebels against either supposition: beyond any limit, we are driven to conceive something further, endlessly ; and yet infinity is itself inconceivable. Again, did the world have a beginning in time? We cannot conceive eternity, but then, too, we cannot conceive any point in the past without feeling at once that before that, something was. Or has that chain of causes which science studies, a beginning, a First Cause? Yes, for an endless chain is inconceivable. No, for a first cause uncaused is inconceivable as well. Is there any exit from these blind alleys of thought? There is, says Kant, if we remember that space, time and cause are modes of perception and conception, which must enter into all our experience, since they are the web and structure of experience; these dilemmas arise from supposing that space, time and cause are external things independent of perception. We shall never have any experience which we shall not interpret in terms of space and time and cause; but we shall never have any philosophy if we forget that these are not things but modes of interpretation and understanding.
So with the paralogisms of "rational" theology—which attempts to prove by theoretical reason that the soul is an incorruptible substance, that the will is free and above the law of cause and effect, and that there exists a 'necessary being' God, as the presupposition of all reality. Transcendental dialectic must remind theology that substance and cause and necessity are finite categories, modes of arrangement and classification which the mind applies to sense-experience, and reliably valid only for the phenomena that appear to such experience; we cannot apply these conceptions to the noumenal (or merely inferred and conjectural) world. Religion cannot be proved by theoretical reason. From [128]
59 I'm indebted to my wife Jo for her suggestion that I would be interested in Will Durant's [128] interpretation of Immanuel Kant's Critique of Pure Reason60 .
58 Approximately 40 years after first reading Immanuel Kant's Critique of Pure Reason, I finally understand his contributions to the history of philosophy and perhaps his confusion with or misinterpretation of David Hume regarding the role of experience and the relationship between experience on the one hand and the ability to construct theories on the other. The latter being the part that confused me at the age of 19 and led me to believe that Kant was confused as well. His idea of (Platonic) theories of unassailable truth — what he calls Transcendental Logic — is at the center of his account of how (a) our direct experience, (b) the patterns we discover in data, and (c) the theories we invent to reinterpret these patterns in the language of mathematics enable us to make predictions about events in the real world59.
Human beings and modern machine learning systems are good at discovering patterns in data. Pattern matching was an important step in understanding our environment, but the data was unpredictable, the patterns inconstant and, lacking an understanding of probability, the patterns themselves were unsatisfactory for making accurate predictions and difficult to compose in order to construct broadly encompassing theories that account for more complicated patterns and statistical regularities. Humans invented logic and mathematics to provide structure to those patterns. We invented the differential calculus to explain processes that take place over time. We invented probability and statistics to account for the variability we observe in complex patterns of the sort that govern games of chance. See here for an account of Kant's Theory of Perception.
I don't think Kant understood David Hume's theory of how we come to convert raw experience into theories or perhaps I read too much into Hume. Hume and his fellow empiricists, John Locke and Francis Bacon, were wary of putting too much stock in direct experience and wanted to avoid the human tendency toward superstition. They provided the foundations for the modern scientific method to ground perception in theory. However, one can imagine what the rationalist Kant might make of Hume's view that that passion rather than reason governs human behavior. Hume argued against the existence of innate ideas, positing that all human knowledge is ultimately grounded solely in experience. Hume held that genuine knowledge must either be directly traceable to objects perceived in experience, or result from abstract reasoning about relations between ideas which are derived from experience. Their differences seem largely due to ambiguous terminology. Chronology: Bacon (1561-1626), Locke (1632-1704), Newton (1642-1727), Leibniz (1646-1716), Hume (1711-1776) and Kant (1724-1804).
61 A continuous-time recurrent neural network can be modeled as a system of ordinary differential equations. By the Nyquist-Shannon sampling theorem, discrete-time recurrent neural networks of the sort commonly used in machine learning can be viewed as continuous-time recurrent neural networks where the differential equations have been transformed into equivalent difference equations.
63 Here is a small sample of journal and encyclopedia articles on episodic memory with an emphasis on its role in autonoetic consciousness in both humans and selected animal species:
@article{GardinerPTRS_B-01,
author = {Gardiner, J. M.},
title = {Episodic memory and autonoetic consciousness: a first-person approach.},
journal = {Philosophical Transactions of the Royal Society London B Biological Science},
year = {2001},
volume = {356},
issue = {1413},
pages = {1351-1361},
abstract = {Episodic memory is identified with autonoetic consciousness, which gives rise to remembering in the sense of self-recollection in the mental re-enactment of previous events at which one was present. Autonoetic consciousness is distinguished from noetic consciousness, which gives rise to awareness of the past that is limited to feelings of familiarity or knowing. Noetic consciousness is identified not with episodic but with semantic memory, which involves general knowledge. A recently developed approach to episodic memory makes use of 'first-person' reports of remembering and knowing. Studies using this approach have revealed many independent variables that selectively affect remembering and others that selectively affect knowing. These studies can also be interpreted in terms of distinctiveness and fluency of processing. Remembering and knowing do not correspond with degrees of confidence in memory. Nor does remembering always control the memory response. There is evidence that remembering is selectively impaired in various populations, including not only amnesic patients and older adults but also adults with Asperger's syndrome. This first-person approach to episodic memory represents one way in which that most elusive aspect of consciousness, its subjectivity, can be investigated scientifically. The two kinds of conscious experiences can be manipulated experimentally in ways that are systematic, replicable and intelligible theoretically.},
}
@incollection{ClaytonandDickinsonEAB-10,
author = {Mental Time Travel: Can Animals Recall the Past and Plan for the Future?},
title = {N. S. Clayton and A. Dickinson},
editor = {Breed, Michael D. and Moore, Janice},
booktitle = {Encyclopedia of Animal Behavior},
publisher = {Academic Press},
year = {2010},
pages = {438-442},
abstract = {According to the mental time travel hypothesis, only humans can mentally dissociate themselves from the present, traveling backward in time to recollect specific past events about what happened where and when (episodic memory) and traveling forward in time to anticipate future needs (future planning). A series of studies of the mnemonic capabilities of food-caching western scrub-jays question this assumption. In terms of the retrospective component of episodic memory, these birds remember the ‘what, where, and when’ of specific past caching episodes; they keep track of how long ago they cached different types of perishable foods that decay at different rates, and also remember whether another individual was present at the time of caching, and if so, which bird was watching when. Recent work demonstrates that the jays also make provision for a future need, caching more food in places in which they will not be given breakfast the next morning than in places where they will be receive breakfast the next morning even though there is plenty of food available to them at the time when they cache the food. Taken together these results challenge the mental time travel hypothesis by showing that some elements of both retrospective and prospective mental time travel appear not to be uniquely human.}
}
@incollection{MarinoEAB-10,
author = {Lori Marino},
title = {Sentience},
editor = {Breed, Michael D. and Moore, Janice},
booktitle = {Encyclopedia of Animal Behavior},
publisher = {Academic Press},
year = {2010},
pages = {132-138},
abstract = {Sentience refers to the depth of awareness an individual possesses about himself or herself and others. There appear to be three related, but separable, general domains of sentience. These are self-awareness, metacognition, and theory of mind. To date, evidence shows that these three capacities are found in nonhuman animals, including primates, dolphins, dogs, rodents, and corvids. These findings are evidence of the deep psychological continuity that exists across the animal kingdom.}
}
@article{KleinQJEO-16,
author = {Klein, S.B.},
title = {Autonoetic consciousness: Reconsidering the role of episodic memory in future-oriented self-projection},
journal = {Quarterly Journal of Experimental Psychology},
year = {2016},
volume = {69},
number = {2},
pages = {381-401},
abstract = {Following the seminal work of Ingvar (1985. "Memory for the future": An essay on the temporal organization of conscious awareness. Human Neurobiology, 4, 127-136), Suddendorf (1994. The discovery of the fourth dimension: Mental time travel and human evolution. Master's thesis. University of Waikato, Hamilton, New Zealand), and Tulving (1985. Memory and consciousness. Canadian Psychology, 26, 1-12), exploration of the ability to anticipate and prepare for future contingencies that cannot be known with certainty has grown into a thriving research enterprise. A fundamental tenet of this line of inquiry is that future-oriented mental time travel, in most of its presentations, is underwritten by a property or an extension of episodic recollection. However, a careful conceptual analysis of exactly how episodic memory functions in this capacity has yet to be undertaken. In this paper I conduct such an analysis. Based on conceptual, phenomenological, and empirical considerations, I conclude that the autonoetic component of episodic memory, not episodic memory per se, is the causally determinative factor enabling an individual to project him or herself into a personal future.}
}
@article{SprengFiP-13,
author = {Spreng, R. Nathan},
title = {Examining the role of memory in social cognition},
journal = {Frontiers in Psychology},
volume = {4},
pages = {437},
year = {2013},
abstract = {The function of memory is not only to recall the past, but also to form and update models of our experiences and use these models to navigate the world. Perhaps, the most complex environment for humans to navigate is the social one. Social dynamics are extraordinarily complex, unstructured, labile and difficult to predict. Successful navigation through our many social landscapes is essential to forming and maintaining the durable social bonds necessary for physical and mental health. Until recently, little research has examined the role that memory plays in social behavior and interpersonal sensitivity. There is growing evidence that recalling personally experienced events (autobiographical memory) and inferring the mental states of others (mentalizing or theory-of-mind) share an extensive functional neuroanatomy (Buckner and Carroll, 2007; Spreng et al., 2009; Spreng and Grady, 2010; Rabin et al., 2010) and may be critical for adaptive social cognition.},
}
@article{CiaramelliFiP-13,
author = {Ciaramelli, Elisa and Bernardi, Francesco and Moscovitch, Morris},
title = {Individualized Theory of Mind (iToM): When Memory Modulates Empathy},
journal = {Frontiers in Psychology},
volume = {4},
pages = {4},
year = {2013},
abstract = {Functional neuroimaging studies have noted that brain regions supporting theory of mind (ToM) overlap remarkably with those underlying episodic memory, suggesting a link between the two processes. The present study shows that memory for others’ past experiences modulates significantly our appraisal of, and reaction to, what is happening to them currently. Participants read the life story of two characters; one had experienced a long series of love-related failures, the other a long series of work-related failures. In a later faux pas recognition task, participants reported more empathy for the character unlucky in love in love-related faux pas scenarios, and for the character unlucky at work in work-related faux pas scenarios. The memory-based modulation of empathy correlated with the number of details remembered from the characters’ life story. These results suggest that individuals use memory for other people’s past experiences to simulate how they feel in similar situations they are currently facing. The integration of ToM and memory processes allows adjusting mental state inferences to fit unique social targets, constructing an individualized ToM (iToM).}
}
@article{BehrendtFiP-13,
author = {Behrendt, Ralf-Peter},
title = {Conscious Experience and Episodic Memory: Hippocampus at the Crossroads},
journal = {Frontiers in Psychology},
volume = {4},
pages = {304},
year = {2013},
abstract = {If an instance of conscious experience of the seemingly objective world around us could be regarded as a newly formed event memory, much as an instance of mental imagery has the content of a retrieved event memory, and if, therefore, the stream of conscious experience could be seen as evidence for ongoing formation of event memories that are linked into episodic memory sequences, then unitary conscious experience could be defined as a symbolic representation of the pattern of hippocampal neuronal firing that encodes an event memory – a theoretical stance that may shed light into the mind-body and binding problems in consciousness research. Exceedingly detailed symbols that describe patterns of activity rapidly self-organizing, at each cycle of the θ rhythm, in the hippocampus are instances of unitary conscious experience that jointly constitute the stream of consciousness. Integrating object information (derived from the ventral visual stream and orbitofrontal cortex) with contextual emotional information (from the anterior insula) and spatial environmental information (from the dorsal visual stream), the hippocampus rapidly forms event codes that have the informational content of objects embedded in an emotional and spatiotemporally extending context. Event codes, formed in the CA3-dentate network for the purpose of their memorization, are not only contextualized but also allocentric representations, similarly to conscious experiences of events and objects situated in a seemingly objective and observer-independent framework of phenomenal space and time. Conscious perception is likely to be related to more fleeting and seemingly internal forms of conscious experience, such as autobiographical memory recall, mental imagery, including goal anticipation, and to other forms of externalized conscious experience, namely dreaming and hallucinations; and evidence pointing to an important contribution of the hippocampus to these conscious phenomena will be reviewed.}
}
62 A reasonable working definition of autonoetic consciousness is supplied below and a small sample of relevant publications is available in this footnote63:
"Autonoetic consciousness is the capacity to recursively introspect on one's own subjective experience through time, that is, to perceive the continuity in one's identity from the past to the present and into the future." From [303]"Autonoetic consciousness is distinguished from noetic consciousness, which gives rise to awareness of the past that is limited to feelings of familiarity or knowing. Noetic consciousness is identified not with episodic but with semantic memory, which involves general knowledge." From [150]
64 Executive functions (collectively referred to as executive function and cognitive control) are a set of cognitive processes that are necessary for the cognitive control of behavior: selecting and successfully monitoring behaviors that facilitate the attainment of chosen goals. Executive functions include basic cognitive processes such as attentional control, cognitive inhibition, inhibitory control, working memory, and cognitive flexibility. Higher order executive functions require the simultaneous use of multiple basic executive functions and include planning and fluid intelligence, i.e., reasoning and problem solving. SOURCE
65 Here are a couple of recent papers addressing the problem of learning compositional models of visual data:
@article{DonahueetalCoRR-14,
author = {Jeff Donahue and Lisa Anne Hendricks and Sergio Guadarrama and Marcus Rohrbach and Subhashini Venugopalan and Kate Saenko and Trevor Darrell},
title = {Long-term Recurrent Convolutional Networks for Visual Recognition and Description},
journal = {CoRR},
volume = {arXiv:1411.4389},
year = 2014,
abstract = {Models based on deep convolutional networks have dominated recent image interpretation tasks; we investigate whether models which are also recurrent, or "temporally deep", are effective for tasks involving sequences, visual and otherwise. We develop a novel recurrent convolutional architecture suitable for large-scale visual learning which is end-to-end trainable, and demonstrate the value of these models on benchmark video recognition tasks, image description and retrieval problems, and video narration challenges. In contrast to current models which assume a fixed spatio-temporal receptive field or simple temporal averag- ing for sequential processing, recurrent convolutional models are "doubly deep" in that they can be compositional in spatial and temporal "layers". Such models may have advantages when target concepts are complex and/or training data are limited. Learning long-term dependencies is possible when nonlinearities are incorporated into the network state updates. Long-term RNN models are appealing in that they directly can map variable-length inputs (e.g., video frames) to variable length outputs (e.g., natural lan- guage text) and can model complex temporal dynamics; yet they can be optimized with backpropagation. Our recurrent long-term models are directly connected to modern visual convnet models and can be jointly trained to simultaneously learn temporal dynamics and convolutional perceptual rep- resentations. Our results show such models have distinct advantages over state-of-the-art models for recognition or generation which are separately defined and/or optimized.}
}
@article{ChangetalCoRR-16,
author = {Michael B. Chang and Tomer Ullman and Antonio Torralba and Joshua B. Tenenbaum},
title = {A Compositional Object-Based Approach to Learning Physical Dynamics},
journal = {CoRR},
volume = {arXiv:1612.00341},
year = {2016},
abstract = {We present the Neural Physics Engine (NPE), a framework for learning simulators of intuitive physics that naturally generalize across variable object count and different scene configurations. We propose a factorization of a physical scene into composable object-based representations and a neural network architecture whose compositional structure factorizes object dynamics into pairwise interactions. Like a symbolic physics engine, the NPE is endowed with generic notions of objects and their interactions; realized as a neural network, it can be trained via stochastic gradient descent to adapt to specific object properties and dynamics of different worlds. We evaluate the efficacy of our approach on simple rigid body dynamics in two-dimensional worlds. By comparing to less structured architectures, we show that the NPE's compositional representation of the structure in physical interactions improves its ability to predict movement, generalize across variable object count and different scene configurations, and infer latent properties of objects such as mass.},
}
@article{HigginsetalICLR-18,
title = {{SCAN}: Learning Hierarchical Compositional Visual Concepts},
author = {Irina Higgins, Nicolas Sonnerat, Loic Matthey, Arka Pal, Christopher P Burgess, Matko Bošnjak, Murray Shanahan, Matthew Botvinick, Demis Hassabis, Alexander Lerchner},
journal = {International Conference on Learning Representations},
year = {2018},
abstract = {The seemingly infinite diversity of the natural world arises from a relatively small set of coherent rules, such as the laws of physics or chemistry. We conjecture that these rules give rise to regularities that can be discovered through primarily unsupervised experiences and represented as abstract concepts. If such representations are compositional and hierarchical, they can be recombined into an exponentially large set of new concepts. This paper describes SCAN (Symbol-Concept Association Network), a new framework for learning such abstractions in the visual domain. SCAN learns concepts through fast symbol association, grounding them in disentangled visual primitives that are discovered in an unsupervised manner. Unlike state of the art multimodal generative model baselines, our approach requires very few pairings between symbols and images and makes no assumptions about the form of symbol representations. Once trained, SCAN is capable of multimodal bi-directional inference, generating a diverse set of image samples from symbolic descriptions and vice versa. It also allows for traversal and manipulation of the implicit hierarchy of visual concepts through symbolic instructions and learnt logical recombination operations. Such manipulations enable SCAN to break away from its training data distribution and imagine novel visual concepts through symbolically instructed recombination of previously learnt concepts.}
}
@article{JohnsonetalCoRR-16,
author = {Justin Johnson and Bharath Hariharan and Laurens van der Maaten and Li Fei{-}Fei and C. Lawrence Zitnick and Ross B. Girshick},
title = {{CLEVR:} {A} Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning},
journal = {CoRR},
volume = {arXiv:1612.06890},
year = {2016},
abstract = {When building artificial intelligence systems that can reason and answer questions about visual data, we need diagnostic tests to analyze our progress and discover shortcomings. Existing benchmarks for visual question answering can help, but have strong biases that models can exploit to correctly answer questions without reasoning. They also conflate multiple sources of error, making it hard to pinpoint model weaknesses. We present a diagnostic dataset that tests a range of visual reasoning abilities. It contains minimal biases and has detailed annotations describing the kind of reasoning each question requires. We use this dataset to analyze a variety of modern visual reasoning systems, providing novel insights into their abilities and limitations.}
}
@misc{JohnsonGOOG-18,
author = {Justin Johnson},
title = {Compositional Visual Intelligence through Language},
abstract = {The use of deep neural networks has led to fantastic recent progress on fundamental problems in computer vision. However the most well-studied tasks, such as image classification and object detection, encompass only a small fraction of the rich visual intelligence that people display. In order to make progress toward the goal of visual intelligence, we must define new tasks and construct new datasets that push the boundaries of artificial visual intelligence. An important facet of visual intelligence is composition - our understanding of the whole derives from an understanding of the parts. One avenue for studying the compositional nature of visual intelligence is through connections with natural language, which is also inherently compositional. To this end I will present three research directions toward compositional visual intelligence through language. In each we will see how incorporating compositionality forces us to rethink our tasks and datasets, but results in systems with richer visual intelligence. I will first discuss image captioning, where moving from sentence captions to dense captions and descriptive paragraphs results in richer image descriptions. I will next discuss visual question answering, where an emphasis on compositional reasoning gives rise to new datasets and models. I will then discuss text-to-image synthesis, where replacing freeform natural language with explicitly compositional scene graphs of objects and relationships allows us to generate more complex images. I will conclude by discussing future directions for improving visual intelligence through composition.}
}
66 The neocortex is the newest part of the cerebral cortex to evolve — the prefix "neo" meaning new. The other part of the cerebral cortex is called the allocortex. The cellular organization of the allocortex is different from the six-layered neocortex. In humans, 90% of the cerebral cortex and 76% of the entire brain is neocortex.
67 David Mayfield owns Blue Ridge Life Science an investment firm specializing in early and mid-stage neuroscience. His grandfather Dr. Frank Mayfield was a famous neurosurgeon, scientific leader and entrepreneur in medical technology whose invention of the spring aneurysm clip has saved thousands of lives. David has taken another route to improving the lives of patients with debilitating neural disorders, driven in part by tragedies within his extended family, but he is no less passionate about the science than his grandfather. Both David and I are dismayed with the way in which current financial, medical and scientific incentives are misaligned. In his life and work, he has attempted to redress the negative consequences of this misalignment, often by drawing attention to relevant science and championing new opportunities for intervention. His crusade to promulgate research on microglia and related drug development is an example of the former. Full disclosure: Dr. Mayfield was my uncle, father figure and mentor at a crucial stage in my young life following the sudden death of my father, and so David, colloquially speaking, is my nephew, or, genealogically more precise, my cousin once removed.
68 There is a case to be made that funding through conventional life science VCs, or even midsize biotechs with bigger bank accounts, won't provide new experimental drugs (or their microglial targets) with the chance to succeed. The problem relates paradoxically to the experimental data which seem to show that some of these drugs are curative in such a wide range of CNS diseases and maladies, e.g., multiple sclerosis, anxiety, drug withdrawal syndromes, stroke, chronic neuropathic pain, retinal degeneration. An embarrassment of riches of sorts which is disabling for VCs and also for midsize biotechs who want their drug candidates focused on very narrow mechanisms of action, and very narrowly defined indications. But what if the embarrassment of riches were explained by the drug's impact on a pathological mechanism broadly shared by much of neurodevelopmental and neurodegenerative disease?
It turns out that doesn't matter. Even a potent and very successful biotech such as Biogen would rather have one drug which mitigates the severity of one orphan disease, than one drug which may prevent, mitigate the severity of, and possibly cure ten diseases / disorders afflicting hundreds of millions. Something to do, perhaps, with incentives, liquidity preferences, and appetite for risk built into the way VCs are funded and the way biotechs are publicly financed? One theory is that the phenomenon also relates to a confusion of the scientific methods of drug discovery with the biology of disease and its causes. Anyway, that's just a long winded way of saying that it is going to take a creative, non-conventional organization to translate the new science of microglia into therapies helping patients.
70 Chemokines are a family of small cytokines, or signaling proteins secreted by cells. Their name is derived from their ability to induce directed chemotaxis in nearby responsive cells; they are chemotactic cytokines. [...] Some chemokines are considered pro-inflammatory and can be induced during an immune response to recruit cells of the immune system to a site of infection, while others are considered homeostatic and are involved in controlling the migration of cells during normal processes of tissue maintenance or development. [SOURCE]
71 Cytokines are a broad and loose category of small proteins that are important in cell signaling. [...] Cytokines may include chemokines, interferons, interleukins, lymphokines, and tumour necrosis factors but generally not hormones or growth factors (despite some overlap in the terminology). Cytokines are produced by a broad range of cells, including immune cells like macrophages, B lymphocytes, T lymphocytes and mast cells, as well as endothelial cells, fibroblasts, and various stromal cells. [...] They act through receptors, and are especially important in the immune system; cytokines modulate the balance between humoral and cell-based immune responses, and they regulate the maturation, growth, and responsiveness of particular cell populations. Some cytokines enhance or inhibit the action of other cytokines in complex ways. [SOURCE]
72 Interleukins are a group of cytokines (secreted proteins and signal molecules) that were first seen to be expressed by white blood cells (leukocytes). The function of the immune system depends in a large part on interleukins, and rare deficiencies of a number of them have been described, all featuring autoimmune diseases or immune deficiency. The majority of interleukins are synthesized by helper CD4 T lymphocytes, as well as through monocytes, macrophages, and endothelial cells. They promote the development and differentiation of T and B lymphocytes, and hematopoietic cells. [...] Interleukin receptors on astrocytes in the hippocampus are also known to be involved in the development of spatial memories in mice. [SOURCE]
73 Microglia are a type of neuroglia (glial cell) located throughout the brain and spinal cord, accounting for 10–15% of all cells within the brain. As the resident macrophage cells, they act as the first and main form of active immune defense in the central nervous system (CNS). Microglia (and other neuroglia including astrocytes) are distributed in large non-overlapping regions throughout the CNS. Microglia are constantly scavenging for plaques, damaged or unnecessary neurons and synapses, and infectious agents. Microglia are extremely sensitive to even small pathological changes in the CNS. This sensitivity is achieved in part by the presence of unique potassium channels that respond to even small changes in extracellular potassium. [...] Microglia originate in the yolk sac during a remarkably restricted embryonal period and continuously renew themselves and persist throughout life. [SOURCE]
74 A trophic or growth factor is a naturally occurring substance capable of stimulating cellular growth, proliferation, healing, and cellular differentiation. Usually it is a protein or a steroid hormone. Growth factors are important for regulating a variety of cellular processes. [...] Growth factors typically act as signaling molecules between cells. Examples are cytokines and hormones that bind to specific receptors on the surface of their target cells. [...] While growth factor implies a positive effect on cell division, cytokine is a neutral term with respect to whether a molecule affects proliferation. While some cytokines can be growth factors, others have an inhibitory effect on cell growth or proliferation. Some cytokines cause target cells to undergo programmed cell death or apoptosis. [SOURCE]
75 Excerpts of a recent email message from Akram Sadek on the evolution of consciousness, and quantum computing in the brain as it relates to selection pressure to reduce the expenditure of energy:
AS: I completely agree with you and Professor [Sean] Carrol, on people's attempts to somehow conflate consciousness with quantum theory. Even considering just quantum theory itself, the R, or reduction process doesn't need a conscious observer to occur, as is popularly described sometimes. A physical measurement is all it takes, and it's just a matter of entangling a single quantum state with a great number of different states which leads to what we call 'classical' physics and a classical result (see enclosed). And from the perspective of the brain, I can't see at all how quantum mechanics could possibly explain consciousness or qualia. Quantum mechanics is really just a very simple theory at its heart. These sorts of ideas very much sully things, I agree.On the other hand, an important feature of all biological systems is their remarkable efficiency. Food is scarce, and natural selection is an extremely powerful mechanism that ensures only the most efficient organisms will thrive. Inefficient solutions to biological problems are rapidly weeded out, in as little as a single generation. This is why organisms are able to do so much, with what amounts to very little in terms of energy and physical resources. The human brain only runs at 10W after all. My advisor at Cambridge, Simon Laughlin, discovered early in his career that neurons optimize their coding efficiency to maximize the transmission of information, whilst minimizing energy expenditure (I may have sent you the enclosed paper way back). We already know from the work on photosynthesis that biological systems will harness whatever physics they need to get the job done as efficiently as possible. If quantum mechanics operates in the brain, this is the context in which it would occur.
Theoretically, quantum information processing can occur without any energy expenditure at all, as it is a purely reversible type of computation. The actual energy expenditure that is needed arises due to the necessary error-correction with fault tolerance. If some quantum information processing scheme could have given brains an advantage in terms of using far less energy, then it wouldn't surprise me at all if it's operative. That is what interests me. Of course, if this is the case, then the brain can no longer be thought of as just a thermodynamical engine running an algorithm (which is just a mathematical object). It must be thought of as a physical object that cannot be understood outside of the physical universe it exists in. Since quantum states cannot be cloned, a brain wouldn't be able to be 'copied', like a neural network or piece of software.
76 Here is a collection of recent papers describing biologically-plausible back-propagation-like algorithms:
@article{BalduzzietalCoRR-14,
author = {David Balduzzi and Hastagiri Vanchinathan and Joachim M. Buhmann},
title = {Kickback cuts Backprop's red-tape: Biologically plausible credit assignment in neural networks},
journal = {CoRR},
volume = {arXiv:1411.6191},
year = {2014},
abstract = {Error backpropagation is an extremely effective algorithm for assigning credit in artificial neural networks. However, weight updates under Backprop depend on lengthy recursive computations and require separate output and error messages -- features not shared by biological neurons, that are perhaps unnecessary. In this paper, we revisit Backprop and the credit assignment problem. We first decompose Backprop into a collection of interacting learning algorithms; provide regret bounds on the performance of these sub-algorithms; and factorize Backprop's error signals. Using these results, we derive a new credit assignment algorithm for nonparametric regression, Kickback, that is significantly simpler than Backprop. Finally, we provide a sufficient condition for Kickback to follow error gradients, and show that Kickback matches Backprop's performance on real-world regression benchmarks.}
}
@article{BengioetalCoRR-16,
author = {Yoshua Bengio and Dong{-}Hyun Lee and J{\"{o}}rg Bornschein and Zhouhan Lin},
title = {Towards Biologically Plausible Deep Learning},
journal = {CoRR},
volume = {arXiv:1502.04156},
year = {2016},
abstract = {Neuroscientists have long criticised deep learning algorithms as incompatible with current knowledge of neurobiology. We explore more biologically plausible versions of deep representation learning, focusing here mostly on unsupervised learning but developing a learning mechanism that could account for supervised, unsupervised and reinforcement learning. The starting point is that the basic learning rule believed to govern synaptic weight updates (Spike-Timing-Dependent Plasticity) arises out of a simple update rule that makes a lot of sense from a machine learning point of view and can be interpreted as gradient descent on some objective function so long as the neuronal dynamics push firing rates towards better values of the objective function (be it supervised, unsupervised, or reward-driven). The second main idea is that this corresponds to a form of the variational EM algorithm, i.e., with approximate rather than exact posteriors, implemented by neural dynamics. Another contribution of this paper is that the gradients required for updating the hidden states in the above variational interpretation can be estimated using an approximation that only requires propagating activations forward and backward, with pairs of layers learning to form a denoising auto-encoder. Finally, we extend the theory about the probabilistic interpretation of auto-encoders to justify improved sampling schemes based on the generative interpretation of denoising auto-encoders, and we validate all these ideas on generative learning tasks.},
}
@article{LillicrapetalCoRR-14,
author = {Timothy P. Lillicrap and Daniel Cownden and Douglas B. Tweed and Colin J. Akerman},
title = {Random feedback weights support learning in deep neural networks},
journal = {CoRR},
volume = {arXiv:1411.0247},
year = {2014},
abstract = {The brain processes information through many layers of neurons. This deep architecture is representationally powerful, but it complicates learning by making it hard to identify the responsible neurons when a mistake is made. In machine learning, the backpropagation algorithm assigns blame to a neuron by computing exactly how it contributed to an error. To do this, it multiplies error signals by matrices consisting of all the synaptic weights on the neuron's axon and farther downstream. This operation requires a precisely choreographed transport of synaptic weight information, which is thought to be impossible in the brain. Here we present a surprisingly simple algorithm for deep learning, which assigns blame by multiplying error signals by random synaptic weights. We show that a network can learn to extract useful information from signals sent through these random feedback connections. In essence, the network learns to learn. We demonstrate that this new mechanism performs as quickly and accurately as backpropagation on a variety of problems and describe the principles which underlie its function. Our demonstration provides a plausible basis for how a neuron can be adapted using error signals generated at distal locations in the brain, and thus dispels long-held assumptions about the algorithmic constraints on learning in neural circuits.}
}
@article{LillicrapetalNATURE-COMMUNICATIONS-16,
author = {Lillicrap, Timothy P. and Cownden, Daniel and Tweed, Douglas B. and Akerman, Colin J.},
title = {Random synaptic feedback weights support error backpropagation for deep learning},
publisher = {Nature Publishing Group},
journal = {Nature Communications},
volume = {7},
year = {2016},
pages = {13276},
abstract = {The brain processes information through multiple layers of neurons. This deep architecture is representationally powerful, but complicates learning because it is difficult to identify the responsible neurons when a mistake is made. In machine learning, the backpropagation algorithm assigns blame by multiplying error signals with all the synaptic weights on each neuron’s axon and further downstream. However, this involves a precise, symmetric backward connectivity pattern, which is thought to be impossible in the brain. Here we demonstrate that this strong architectural constraint is not required for effective error propagation. We present a surprisingly simple mechanism that assigns blame by multiplying errors by even random synaptic weights. This mechanism can transmit teaching signals across multiple layers of neurons and performs as effectively as backpropagation on a variety of tasks. Our results help reopen questions about how the brain could use error signals and dispel long-held assumptions about algorithmic constraints on learning.}
}
@article{ScellierandBengioCoRR-16a,
author = {Benjamin Scellier and Yoshua Bengio},
title = {Towards a Biologically Plausible Backprop},
journal = {CoRR},
volume = {arXiv:1602.05179v2},
year = {2016},
abstract = {Neuroscientists have long criticised deep learning algorithms as incompatible with current knowledge of neurobiology. We explore more biologically plausible versions of deep representation learning, focusing here mostly on unsupervised learning but developing a learning mechanism that could account for supervised, unsupervised and reinforcement learning. The starting point is that the basic learning rule believed to govern synaptic weight updates (Spike-TimingDependent Plasticity) arises out of a simple update rule that makes a lot of sense from a machine learning point of view and can be interpreted as gradient descent on some objective function so long as the neuronal dynamics push firing rates towards better values of the objective function (be it supervised, unsupervised, or rewarddriven). The second main idea is that this corresponds to a form of the variational EM algorithm, i.e., with approximate rather than exact posteriors, implemented by neural dynamics. Another contribution of this paper is that the gradients required for updating the hidden states in the above variational interpretation can be estimated using an approximation that only requires propagating activations forward and backward, with pairs of layers learning to form a denoising auto-encoder. Finally, we extend the theory about the probabilistic interpretation of auto-encoders to justify improved sampling schemes based on the generative interpretation of denoising auto-encoders, and we validate all these ideas on generative learning tasks.},
}
@article{ScellierandBengioCoRR-16b,
author = {Benjamin Scellier and Yoshua Bengio},
title = {Equilibrium Propagation: Bridging the Gap Between Energy-Based Models and Backpropagation},
journal = {CoRR},
volume = {arXiv:1602.05179v4},
year = {2016},
abstract = {We introduce Equilibrium Propagation (e-prop), a learning algorithm for energy-based models. This algorithm involves only one kind of neural computation both for the first phase (when the prediction is made) and the second phase (after the target is revealed) of training. Contrary to backpropagation in feedforward networks, there is no need for special computation in the second phase of our learning algorithm. Equilibrium Propagation combines features of Contrastive Hebbian Learning and Contrastive Divergence while solving the theoretical issues of both algorithms: the algorithm computes the exact gradient of a well defined objective function. Because the objective function is defined in terms of local perturbations, the second phase of e-prop corresponds to only nudging the first-phase fixed point towards a configuration that has lower cost value. In the case of a multi-layer supervised neural network, the output units are slightly nudged towards their target, and the perturbation introduced at the output layer propagates backward in the network. The theory developed in this paper shows that the signal 'back-propagated' during this second phase actually contains information about the error derivatives, which we use to implement a learning rule proved to perform gradient descent with respect to the objective function. Thus, this work makes it more plausible that a mechanism similar to backpropagation could be implemented by brains.}
}
@article{XuetalTNNLS-17,
author = {David Xu, Andrew Clappison, Cameron Seth, and Jeff Orchard
title = {Symmetric Predictive Estimator for Biologically Plausible Neural Learning},
journal = {IEEE Transactions on Neural Networks and Learning Systems},
volume = {28},
issue = {10},
year = {2017},
abstract = {In a real brain, the act of perception is a bidirectional process, depending on both feedforward sensory pathways and feedback pathways that carry expectations. We are interested in how such a neural network might emerge from a biologically plausible learning rule. Other neural network learning methods either only apply to feedforward networks, or employ assumptions (such as weight copying) that render them unlikely in a real brain. Predictive estimators (PEs) offer a better solution to this bidirectional learning scenario. However, PEs also depend on weight copying. In this paper, we propose the symmetric PE (SPE), an architecture that can learn both feedforward and feedback connection weights individually using only locally available information. We demonstrate that the SPE can learn complicated mappings without the use of weight copying. The SPE networks also show promise in deeper architectures.},
}
69 Here are my rough notes including selected exchanges with colleagues concerning the different roles of mycroglia in the developing brain. These notes follow up my on my earlier post here. For your convenience, here are a few common technical terms relating to immunology and cell signaling that cover some of the primary tools employed by microglia in their different computational and immunological roles in the human brain: chemokines70, cytokines71, intereukins72, microglia73, trophic factors74.
DM: Thanks for connecting with your colleague Christof on the project. I've listened to a few of his talks over the last few years and find him, and the work of the Allen Institute totally fascinating. I'm traveling today to NYC, and will try to jot down my thoughts on the plane as to how his thinking can be accommodated within the new science regarding microglia. Here are a few thoughts off the top of my head: The questions posed by someone like Christof, interested, as he is, in understanding the biological correlates of consciousness, don't overlap completely with those posed by folks, like, say, David Hubel, Torsten Wiesel, Carla Shatz, and more recently Tobias Bonhoeffer, who are interested in the biological correlates of learning (and memory). I think consciousness is inherently neuronal and digital-computational and depends on functions which occur at the speeds Christof is interested in; the speed of ionotropic signaling between neurons — presynaptic spikes leading to ePSPs and iPSPs as sodium ions and chloride rush down their concentration gradients. Millisecond time scale.TLD: It's not clear to me that Christof's comments were specific to consciousness, despite his deep interest in the topic. What occurred to me on reading his note had to do with the nature of the computations performed by microglia in service to shaping the interactions between neurons. What do these neural interlocutors need to know about the neurons whose activity they influence? It would appear that the synaptic alterations they produce require seconds or minutes to carry out. Is that because they are simultaneously sampling the activity of tens, hundreds or thousands of dendrites in order to initiate synaptic alterations periodically carried out on the scale of minutes? Do the computations they perform require sampling at millisecond resolution? Setting aside the possibility of some sort of quantum information processing75, neural refractory periods suggest 1000Hz as an upper bound on how fast human neurons can possibly fire, but 200Hz is a more reasonable upper bound for most human cortical neurons with auditory cortex neurons a possible exception given they appear able to resolve frequencies up to 1000Hz. Still, that's pretty fast.
DM: But learning depends upon functions that occur at slower time scales, beginning with Hebbian changes to synapse efficiency which depend on metabotropic as opposed to ionotropic speeds. Metabolic signaling rather than electrochemical signaling — and I suspect even here, when we are talking about the earliest and most fundamental elements of learning — NMDA receptor/calcium flux mediated changes to synaptic efficiency by AMPA receptor synthesis and insertion — we are already above a timescale of the second. And we haven't even left the confines of the neuron. Structural plasticity, the experience and activity mediated changes in dendritic spine and axonal collateral densities — intuited by Ramòn y Cajal's, and confirmed definitively with post-2000 two photon microscopy of the living, behaving dendritic spine (Trachtenberg et al, 2002, Tobias Bonhoeffer 2001) takes place at time scales greater than seconds, minutes, hours, days. These structural morphological changes to living/behaving neurons were correlated to LTP/LTD and learning before the 2005 re-discovery of microglia (which depended on the same two photon microscopy). I'll point you to the papers that correlate the activity of microglia to these neuronal changes which are the biological substrate of learning. But for now I just want to make the point, that the timescale of the observed structural changes to neurons map well with the timescale of the observed behavior of microglia as then project and retract their arm-like processes to and from the synaptic connections between neurons.
TLD: Does a microglial cell passively sample and analyze extracellular fluid in the vicinity of each spine in its purview for 30 seconds or so and then decide on an intervention modifying all its spines simultaneously? Or possibly the analysis is more interactive as if the glia and neurons are solving a recurrent combinatorial reconstruction problem jointly and initiating reconstruction upon arriving at a solution. From what I understand, the synapses a given microglial cell is responsible for don't overlap with those of other microglial cells. This combinatorial problem could be fully stationary requiring no knowledge of the history of its neuronal / dendritic charges not already encoded in the state of the neurons / dendrites or made apparent during pre-intervention analytical stage. What is the nature of the intervention? Does it entail a specific cocktail of cell-signalling proteins and trophic factors tailored to each dendrite? And why this repeated cycle of projection and retraction as if its target neurons / dendrites are not fixed but rather determined dynamically, possibly sampled randomly to ensure coverage?
I'm particularly interested in the possibility of exploiting the way in which microglia tile the brain, effectively covering all of the synapses. Apparently, it is not simply a cover in the mathematical sense of a set of sets whose union is the whole set, but specifically it is a set of sets that are disjoint and whose union is the whole set. The sets that comprise the microglial tiling are also local in the sense that the elements of the set are bounded in space by the microglial span and the processes of mature microglia in the CNS tend to be compact. In keeping with the terminology introduced in [98], I now think of these sets as domains and imagine they would serve as modular functional domains as defined in [98]. It would not surprise me if these domains overlap in space despite being disjoint, a conjecture I would like to pursue perhaps with your help or the assistance of one of the microglia experts you've introduced me to.
Computational neuroscientists are interested in how learning is implemented in the brain and machine learning researchers have been trying for years to come up with biologically plausible-version of gradient descent. Several of the recent attempts have used strategies involving random weights. One surprisingly simple algorithm for deep learning assigns credit or blame by multiplying error signals by random synaptic weights. The local computations involve adaptation of a sort microglia could be capable of performing. Lillicrap et al [286] show that a network can learn to extract useful information from signals sent through these random feedback connections. In essence, the network learns to learn. For your convenience, I've collected the titles and abstracts for several recent papers describing biologically-plausible back-propagation-like algorithms and made them available here76.
DM: Neurosteroids also play an important role in regulating neural activity. Like much of what goes on in the field, the scientists studyng the brain's amazing capacity to manufacture its own pregnane steroids aren't talking to the folks who study microglia, and neither group are really talking to the folks who study learning from a computational neuroscience perspective. Neurosteroids could provide the glue, in a way, which brings these often disjointed disciplines together.
Regarding neurosteroids and microglia, the brain can produce neurosteroids (NS) in a very localized manner in order to modulate brain activity. Perhaps at the scale of the individual neuron. And there is some evidence that microglia, which also act at the scale of the individual dendritic spine of individual neurons, are crucial to regulation of the local production of NS. I'm pretty sure that the upregulation of NS is one of the essential tools through which the brain homeostatically keeps microglia from adopting, in error, a macrophage-like, immune reactive phenotype in the face of immune challenges. NS is upregulated by the brain in the face of immune challenge with an anti-inflammatory effect — helping microglia to remain on task interacting with the synaptic landscape. The anxiolytic-driven potentiation of NS biosynthesis is almost certainly how it modulates the behavior of microglia.
Regarding neurosteroids and computational neuroscience: But the brain also clearly upregulates NS so as to modulate the balance of neuronal excitation and inhibition. Allopregnanolone, for instance, is an incredibly potent (nano-molar potency) and efficient positive allosteric modulator of the GABA A receptor. To date, this fact has only been of interest to neuroscientists and biotechs (like SAGE Therapeutics) because they can dose an animal systemically with Allo to achieve profound anti-epileptic, and anxiolytic effect. But the brain itself doesn't make NS for the purpose of depressing excitation globally. In the context of excitation / inhibition, the brain produces NS to modulate specific circuits, potentiating the synaptic weight of specific interneurons relative to the weight of excitatory neurons synapting to the same post synaptic cell. And this should be of interest to the likes of computational neuroscientists like Markus Meister whose work has proven the importance of interneurons to the predictive coding wired into the brain's circuitry genetically through evolution.
It would be really neat to discover that microglia not only deploy their immunological tools to reshape (by Hebbian rules) the synaptic connections of excitatory presynaptic neurons to their post synaptic partner as new experience dictates (the type of learning described by Bonhoeffer), but also that microglia deploy their endocrine-like neurosteroidal tools to modulate the relative importance of the predictive, expectational, information stored in the strength of inhibitory interneuron synapses connecting to the same post synaptic cell.
77 Ben Barres was a pioneer in the research on glia leading to the discovery of their dual role in the central nervous system. Beth Stevens was among his students and his lab was responsible for many of the important innovations enabling researchers to study glia and reveal their complex behavior. The Chan-Zuckerberg Initiative has created a program to fund early career awards (RFA) for research on neurodegeneration in honor of Barres work and life. Barres died on December 27, 2017 twenty months after being diagnosed with pancreatic cancer. He was 63. SOURCE
78 How Google's early failure to sell itself shows why we can't recognize good ideas [SOURCE]
By Lila MacLellan
January 29, 2018
A newly published interview with David Cheriton, the Stanford University computer science professor known for writing Google's second check, offers a reminder about how bad most gatekeepers are at picking out the winners among new ideas. When the Globe and Mail (paywall) asked Cheriton about the original pitch Sergey Brin and Larry Page made to him in 2004, he responded:
Actually, they wanted advice about licensing their search technology to other companies. I'd seen people try that before. The view I take is, you give birth to this baby technology, and you think somebody would like to adopt it because you think it's beautiful. But it's very hard to get anyone else to adopt your baby. I told them, "You have to raise your baby yourself." They came back some months later, and I don't think they said I was right, but they'd decided to start their own company because nobody was interested in their baby.
Stories like these are irresistible. Maybe it's the schadenfreude that comes with imagining Silicon Valley investors missing out on a product that would come to be worth billions. Or it's just that we like to believe that had we been sitting in the room when Page and Brin demonstrated their ranking algorithm, we would have recognized their search technology as genius, history-changing genius.
But studies show that's just wishful thinking. Had you been an executive at, say, Yahoo, one of the companies that was not interested in PageRank, which became Google, you likely would have made the same mistake. Justin Berg, a professor at Stanford University's School of Business, calls it a failure of "creative forecasting," something managers and other decision makers are notorious for. In public lectures on his research, Berg runs through a list of famous rejections: the sitcom Seinfeld, the first Harry Potter book, even the graphical user interface. In literature, there's a multitude of such examples where editors missed a genre-bending or stylistically fresh new voice.
Berg researched how this happens, finding a rich body of literature explaining the natural biases against creativity and innovation that exist in most of us, and are not completely irrational. Novel ideas actually make us "deeply uncomfortable," scholars have found, even when we believe we welcome them. Our inclination to avoid risk means managers are unlikely to endorse an idea that doesn't resemble any that came before it. It's safer not to jeopardize your reputation as someone who can be trusted with the company's time and money.
But Berg wanted to answer a different question about creativity within organizations. He wanted to find out who was good at spotting strong, imaginative ideas, and why, so he began by studying artists and circus managers at Cirque Du Soleil, analyzing their predictions about which new acts introduced by performers would be most appreciated by audiences. Berg found that the artists, and not the managers, had a better sense of when they were watching a future hit. As Adam Grant explained in an Aspens Ideas speech that covered Berg's findings, fellow artists "are much more likely to say, 'What are the reasons that I should consider this idea?' as opposed to, 'Why should I walk away from it?'"
Sadly for managers, it seems there's something about the role itself that can close the mind. This is true even for students asked to think like managers, Berg found in lab studies. But there's also famous proof of this in an anecdote about another early Google investor, Jeff Bezos, founder of Amazon. When he visited Harvard Business School in 1997, he was told by the students in a class called "Managing the Marketspace" that he ought to sell Amazon to Barnes and Noble. In his book, The Everything Store, Brad Stone explains that the Harvard students believed Amazon would be squashed by more established brands when they moved online. They were obviously bright students, but also human. They sided with the known.
On a more optimistic note, however, Berg also found that students playing "managers" got better at a creative forecasting task when they took on the role of of "creator," for even five minutes, by spending some time generating new ideas before listening and judging those of peers. In other words, company executives, editors, producers—all the gatekeepers of the world—ought to make research and innovation part of their jobs. Exactly the way professors like Cheriton do.
79 By "reasonably easy" I mean that extending the Zinn hierarchical planner to handle a carefully circumscribed subset of programmer's apprentice-related actions, interventions and misunderstandings suitable for simple demos and testing might take a good programmer a few months effort and a great programmer substantially less. Writing such DMS "stubs" in order to carve out a suitably safe demo space is an art but one that can be relatively easily learned.
80 Using training data and examples collected from Google code repositories would very probably preclude any substantive external demos and complicate publication given the proprietary nature and specialized applications of the Google code base.
81 Suppose you have a stream of items of large and unknown length that you can only iterate over once. Reservoir sampling is an algorithm that randomly chooses an item from this stream such that each item is equally likely to be selected.
82 Here is a small sample of recent titles and references that straddle disciplinary boundaries to offer new insights: Associative Long Short-Term Memory [83], Neural Turing Machines [168], DRAW: A Recurrent Neural Network For Image Generation [185], Recurrent Models of Visual Attention [314], Using Fast Weights to Attend to the Recent Past [18], Learning Model-based Planning From Scratch [339], The Construction System of the Brain [201], Deconstructing Episodic Memory with Construction [200], Imagination-Augmented Agents for Deep Reinforcement Learning [472], The Future of Memory: Remembering, Imagining, and the Brain [378], Human-level Concept Learning Through Probabilistic Program Induction [267], The Consciousness Prior [38], What is Consciousness, and Could Machines Have It? [108], The Attention Schema Theory: A Mechanistic Account of Subjective Awareness [181]
83 In a memorandum issued in 2000, the NIH Biomedical Information Science and Technology Initiative Consortium agreed on the following definition: Computational Biology: The development and application of data-analytical and theoretical methods, mathematical modeling and computational simulation techniques to the study of biological, behavioral, and social systems.
84 John Rader Platt was an American physicist and biophysicist, a professor at the University of Chicago and an advocate of periodically changing scientific fields to keep fresh, gain new perspectives and facilitate the spread of ideas. His early interests were in the field of molecular biophysics and biophysics, in the 1960s he shifted to philosophy of science, vision and perception, and the study of social trends. He was known for his pioneering work on strong inference in the 1960s and his analysis of social science in the 1970s. He wrote that:
I think there are thousands of scientist who would like to change to less crowded and more interesting fields if they thought the change would not be disapproved and if they could plan how to make a living and how to get research support while making the change. I think this would be a good thing. Mobility spreads the skills in a labor market and mobility would spread the skills in science. Kant, Helmholtz and Pasteur all changed fields. Enrico Fermi once said that a scientist should change fields every ten years; that in the first place his ideas were exhausted by then, and he owed it to the younger men in the field to let them advance; and that in the second place his ideas might be of greater value in bringing a fresh viewpoint to a different field. — John Rader Platt [48]
John W. Gardner, the former cabinet secretary and founder of Common Cause, the nonpartisan public-interest lobby for greater political transparency and accountability, first described a career strategy he referred to as "repotting" as a way to stay engaged and innovative. The idea is that a career reboot not only helps prevent managers from staying in one position too long, being lulled into complacency or leadership fatigue, but that it also pushes leaders to keep learning, to see new challenges with a fresh perspective and ultimately find meaningful work that leaves a lasting legacy:
Most of us have potentialities that have never been developed simply because the circumstances of our lives never called them forth. Exploration of the full range of our own potentialities is not something that we can safely leave to the chances of life. It is something to be pursued systematically, or at least avidly, to the end of our days. We should look forward to an endless and unpredictable dialogue between our potentialities and the claims of life — not only the claims we encounter but the claims we invent. And by the potentialities I mean not just skills, but the full range capacities for sensing, wondering, learning, understanding, loving, and aspiring. — John Gardener [151]
85 By academic career, I am referring to the period from 1986 to 2006 during which I was on the faculty of the Computer Science Department at Brown University. During my first ten years at Brown, I focused exclusively on research and teaching. From 1997 until 2002, I served as the chair of Brown's Computer Science Department and simultaneously as Acting Vice President for Computing and Information Services from 2001 until 2002. I then served as the Deputy Provost of Brown University from 2003 to 2005. Once I became involved in administration, the time I had available for research dwindled and, while I continued working with my graduate students, the intensity with which I pursued new research ideas declined. Peter Norvig suggested I spend my sabbatical at Google in 2006 and subsequently invited me to continue at Google full time to pursue research in computational neuroscience for which I will always be grateful to him. While I work full time as a Research Scientist at Google, I spend approximately 20% of my time teaching and advising students at Stanford thanks to Google's enlightened attitude towards collaboration and university relations.
86 Herbert Simon [396] introduced the idea of bounded rationality as an alternative basis for the sort of mathematical modeling that dominated economics during much of the 20th century. It complements the notion of rationality as optimization, which views decision-making as a fully rational process of finding an optimal choice given the information available. Independently of Simon, procedural limitations have also been pointed out by Bayesian authors most notably I.J. Good, who introduced a distinction between what he calls Type I and Type II rationality. Type I rationality is the ideal of Bayesian decision theory, while Type II rationality takes into account the time and cost of analyzing a problem and thus may depart from the Type I ideal. Type II rationality often justifies a compromise between Bayesian and non-Bayesian methods in statistics [228].
87 Here are some excerpts from Mary Shelley's Frankenstein. Shelley (1797–1851) started writing the story when she was 18. The first edition of the novel was published anonymously in London on January 1, 1818, when she was 20. Her name first appeared on the second edition, published in France in 1823. This is the 200th anniversary of the first edition.
The book has been mentioned in several news stories and appeared in book-club lists focusing on the modern Prometheus theme and helping to fuel concerns about rogue artificial intelligence. These excerpts caught my attention for their nuanced view of a young man caught up with the idea of controlling nature and altering the fate of humanity:
Frankenstein (Mary Shelley) — Loc. 343-54
If, instead of this remark, my father had taken the pains to explain to me that the principles of Agrippa had been entirely exploded and that a modern system of science had been introduced which possessed much greater powers than the ancient, because the powers of the latter were chimerical, while those of the former were real and practical, under such circumstances I should certainly have thrown Agrippa aside and have contented my imagination, warmed as it was, by returning with greater ardour to my former studies. It is even possible that the train of my ideas would never have received the fatal impulse that led to my ruin. But the cursory glance my father had taken of my volume by no means assured me that he was acquainted with its contents, and I continued to read with the greatest avidity.
When I returned home my first care was to procure the whole works of this author, and afterwards of Paracelsus and Albertus Magnus. I read and studied the wild fancies of these writers with delight; they appeared to me treasures known to few besides myself. I have described myself as always having been imbued with a fervent longing to penetrate the secrets of nature. In spite of the intense labour and wonderful discoveries of modern philosophers, I always came from my studies discontented and unsatisfied. Sir Isaac Newton is said to have avowed that he felt like a child picking up shells beside the great and unexplored ocean of truth. Those of his successors in each branch of natural philosophy with whom I was acquainted appeared even to my boy's apprehensions as tyros engaged in the same pursuit.
Frankenstein (Mary Shelley) — Loc. 355-63
The most learned philosopher knew little more. He had partially unveiled the face of Nature, but her immortal lineaments were still a wonder and a mystery. He might dissect, anatomize, and give names; but, not to speak of a final cause, causes in their secondary and tertiary grades were utterly unknown to him. I had gazed upon the fortifications and impediments that seemed to keep human beings from entering the citadel of nature, and rashly and ignorantly I had repined. But here were books, and here were men who had penetrated deeper and knew more. I took their word for all that they averred, and I became their disciple.
It may appear strange that such should arise in the eighteenth century; but while I followed the routine of education in the schools of Geneva, I was, to a great degree, self-taught with regard to my favourite studies. My father was not scientific, and I was left to struggle with a child's blindness, added to a student's thirst for knowledge. Under the guidance of my new preceptors I entered with the greatest diligence into the search of the philosopher's stone and the elixir of life; but the latter soon obtained my undivided attention.
Frankenstein (Mary Shelley) — Loc. 366-68
And thus for a time I was occupied by exploded systems, mingling, like an unadept, a thousand contradictory theories and floundering desperately in a very slough of multifarious knowledge, guided by an ardent imagination and childish reasoning, till an accident again changed the current of my ideas.
Frankenstein (Mary Shelley) — Loc. 438-42
I replied in the affirmative. "Every minute," continued M. Krempe with warmth, "every instant that you have wasted on those books is utterly and entirely lost. You have burdened your memory with exploded systems and useless names. Good God! In what desert land have you lived, where no one was kind enough to inform you that these fancies which you have so greedily imbibed are a thousand years old and as musty as they are ancient? I little expected, in this enlightened and scientific age, to find a disciple of Albertus Magnus and Paracelsus. My dear sir, you must begin your studies entirely anew."
Frankenstein (Mary Shelley) — Loc. 464-69
"The ancient teachers of this science," said he, "promised impossibilities and performed nothing. The modern masters promise very little; they know that metals cannot be transmuted and that the elixir of life is a chimera but these philosophers, whose hands seem only made to dabble in dirt, and their eyes to pore over the microscope or crucible, have indeed performed miracles. They penetrate into the recesses of nature and show how she works in her hiding-places. They ascend into the heavens; they have discovered how the blood circulates, and the nature of the air we breathe. They have acquired new and almost unlimited powers; they can command the thunders of heaven, mimic the earthquake, and even mock the invisible world with its own shadows."
Frankenstein (Mary Shelley) — Loc. 546-52
I prepared myself for a multitude of reverses; my operations might be incessantly baffled, and at last my work be imperfect, yet when I considered the improvement which every day takes place in science and mechanics, I was encouraged to hope my present attempts would at least lay the foundations of future success. Nor could I consider the magnitude and complexity of my plan as any argument of its impracticability. It was with these feelings that I began the creation of a human being. As the minuteness of the parts formed a great hindrance to my speed, I resolved, contrary to my first intention, to make the being of a gigantic stature, that is to say, about eight feet in height, and proportionably large. After having formed this determination and having spent some months in successfully collecting and arranging my materials, I began.
Frankenstein (Mary Shelley) — Loc. 569-73
It was a most beautiful season; never did the fields bestow a more plentiful harvest or the vines yield a more luxuriant vintage, but my eyes were insensible to the charms of nature. And the same feelings which made me neglect the scenes around me caused me also to forget those friends who were so many miles absent, and whom I had not seen for so long a time. I knew my silence disquieted them, and I well remembered the words of my father: "I know that while you are pleased with yourself you will think of us with affection, and we shall hear regularly from you. You must pardon me if I regard any interruption in your correspondence as a proof that your other duties are equally neglected."
Frankenstein (Mary Shelley) — Loc. 578-83
A human being in perfection ought always to preserve a calm and peaceful mind and never to allow passion or a transitory desire to disturb his tranquillity. I do not think that the pursuit of knowledge is an exception to this rule. If the study to which you apply yourself has a tendency to weaken your affections and to destroy your taste for those simple pleasures in which no alloy can possibly mix, then that study is certainly unlawful, that is to say, not befitting the human mind. If this rule were always observed; if no man allowed any pursuit whatsoever to interfere with the tranquillity of his domestic affections, Greece had not been enslaved, Caesar would have spared his country, America would have been discovered more gradually, and the empires of Mexico and Peru had not been destroyed.
Frankenstein (Mary Shelley) — Loc. 781-85
A selfish pursuit had cramped and narrowed me, until your gentleness and affection warmed and opened my senses; I became the same happy creature who, a few years ago, loved and beloved by all, had no sorrow or care. When happy, inanimate nature had the power of bestowing on me the most delightful sensations. A serene sky and verdant fields filled me with ecstasy. The present season was indeed divine; the flowers of spring bloomed in the hedges, while those of summer were already in bud. I was undisturbed by thoughts which during the preceding year had pressed upon me, notwithstanding my endeavours to throw them off, with an invincible burden.
88 For the purpose of thinking about episodic memory, the prefrontal cortex is primarily associated with executive function and attention and memory which we cover elsewhere in the research notes. SOURCE
89 The temporal lobe (Brodmann area 22) is involved in processing sensory input into derived meanings for the appropriate retention of visual memory, language comprehension, and emotion association. It adjoins Wernnicke's area associated with language comprehension. SOURCE
90 Wernicke's area is classically located in the posterior section of the superior temporal gyrus (STG) in the (most commonly) left cerebral hemisphere. This area encircles the auditory cortex on the lateral sulcus (the part of the brain where the temporal lobe and parietal lobe meet). SOURCE
91 The retrosplenial cortex (Brodmann area 29 and 30) is located close to visual areas and also to the hippocampal spatial/memory system suggest it may have a role in mediating between perceptual and memory functions. SOURCE
92 The occipital lobe is one of the four major lobes of the cerebral cortex in the brain of mammals. The occipital lobe is the visual processing center of the mammalian brain containing most of the anatomical region of the visual cortex SOURCE
93 The cuneus (Brodmann area 17) receives visual information from the same-sided superior quandrantic retina (corresponding to contralateral inferior visual field). It is most known for its involvement in basic visual processing. The mid-level visual processing that occurs in the extrastriate projection fields of the cuneus are modulated by extraretinal effects, like attention, working memory, and reward expectation. SOURCE
94 The precuneus is located on the inside between the two cerebral hemispheres in the rear region between the somatosensory cortex and forward of the cuneus (which contains the visual cortex). The mental imagery concerning the self has been located in the forward part of the precuneus with posterior areas being involved with episodic memory. Another area has been linked to visuospatial imagery. SOURCE
95 Here is an extended quotation from Conway [77] that, while it doesn't reveal any additional anatomical detail, does provide some useful framing insights from the perspective of cognitive neuroscience:
A distinction might be drawn between a conceptual based frontal-anterior temporal memory system and a posterior temporal-occipital EM system. In the human brain a unique way to access and manipulate EMs is through the conceptual knowledge system. It is this relation between conceptual knowledge and EM that supports two major and fairly amazing abilities: the ability to imagine how the past might have been otherwise and the ability to imagine the future. The ability to imagine how a specific experience might have unfolded differently with different outcomes conveys a huge survival advantage. Different courses of actions can be played out in memory with no physical consequences.The ability to manipulate memories in this way provides the basis of planning and the projection of alternate forms of the past into the future. It is a powerful way of anticipating possible outcomes. Indeed, it provides a meaning by which long-term goals can be generated and planned for. It is then especially interesting that recent neuroimaging studies comparing brain activations during the recall of autobiographical memories with brain activations during the generation of false but plausible memories has found extensive commonalities between the brain areas active in both.
These commonalities are so marked that it might be more appropriate to refer to a remembering-imaging system rather than simply a "memory system." The remembering-imaging system is a cognitive system in which the various components that are usually constructed into an autobiographical memory (autobiographical knowledge and episodic memory) can be constructed into other mental representations of imaginary scenarios. For example, specific EMs might be constructed into novel conceptual context where "dinner with X" becomes "dinner with Y." or perhaps generic knowledge of locations, actors, and actions are configured into potential EMs of unexperienced events. Recent findings indicate then that EMs and autobiographical knowledge can provide the materials, the content, for the construction of imagined tasks and futures.
96 Here is a short list of books and papers on theory of mind and episodic memory. The Handbook of Episodic Memory is a wonderful reference covering much of what is known about episodic memory. Unlike what is known about how the brain represents physical objects in our environment — the shape, color and motion of visual stimuli are represented in an orderly fashion in the visual association areas, episodic memory, is a great deal more complicated, emerges gradually and develops over many years integrating information from a great many sources. The selected journal articles are but a small sample of what I've read or skimmed, even if I read and understood all of the articles I've skimmed and memorized all 600 plus pages of the handbook, it would be years of work to develop a working model of episodic memory that even approximates human memory.
@book{DereetalHANDBOOK-of-EPISODIC-MEMORY-2008,
author = {Dere, E. and Easton, A. and Nadel, L. and Huston, J.P.},
title = {Handbook of Episodic Memory},
publisher = {Elsevier Science},
series = {Handbook of Behavioral Neuroscience},
year = {2008},
}
@article{SaxeetalARP-04,
author = {R. Saxe and S. Carey and N. Kanwisher},
title = {Understanding Other Minds: Linking Developmental Psychology and Functional Neuroimaging},
journal = {Annual Review of Psychology},
volume = {55},
number = {1},
year = {2004},
pages = {87-124},
abstract = {Evidence from developmental psychology suggests that understanding other minds constitutes a special domain of cognition with at least two components: an early-developing system for reasoning about goals, perceptions, and emotions, and a later-developing system for representing the contents of beliefs. Neuroimaging reinforces and elaborates upon this view by providing evidence that (a) domain-specific brain regions exist for representing belief contents, (b) these regions are apparently distinct from other regions engaged in reasoning about goals and actions (suggesting that the two developmental stages reflect the emergence of two distinct systems, rather than the elaboration of a single system), and (c) these regions are distinct from brain regions engaged in inhibitory control and in syntactic processing. The clear neural distinction between these processes is evidence that belief attribution is not dependent on either inhibitory control or syntax, but is subserved by a specialized neural system for theory of mind. }
}
@article{DuboisandAdolphsPNAS-16,
author = {Dubois, Julien and Adolphs, Ralph},
title = {How the brain represents other minds},
journal = {Proceedings of the National Academy of Sciences},
volume = {113},
number = {1},
year = {2016},
pages = {19-21},
abstract = {How does the brain represent the world? Sensory neuroscience has given us a detailed window into how the brain represents physical objects in our environment: For instance, the shape, color, and direction of motion of visual stimuli are represented in an orderly fashion in higher order visual cortices. But we also represent social objects: other people and their thoughts, beliefs, and feelings. How is that kind of knowledge represented in the brain? In an ambitious new study in PNAS, Tamir et al. used functional MRI (fMRI) to argue that our brains represent other minds along three broad dimensions: social impact, rationality, and valence.}
}
@article{MahyetalDCN-14,
title = {How and where: Theory-of-mind in the brain},
author = {Caitlin E.V. Mahy and Louis J. Moses and Jennifer H. Pfeifer},
journal = {Developmental Cognitive Neuroscience},
volume = {9},
year = {2014},
pages = {68-81},
abstract = {Theory of mind (ToM) is a core topic in both social neuroscience and developmental psychology, yet theory and data from each field have only minimally constrained thinking in the other. The two fields might be fruitfully integrated, however, if social neuroscientists sought evidence directly relevant to current accounts of ToM development: modularity, simulation, executive, and theory theory accounts. Here we extend the distinct predictions made by each theory to the neural level, describe neuroimaging evidence that in principle would be relevant to testing each account, and discuss such evidence where it exists. We propose that it would be mutually beneficial for both fields if ToM neuroimaging studies focused more on integrating developmental accounts of ToM acquisition with neuroimaging approaches, and suggest ways this might be achieved.}
}
@article{FerreretalFiN-09,
author = {Ferrer, Emilio and O'Hare, Elizabeth D. and Bunge, Silvia A.},
title = {Fluid Reasoning and the Developing Brain},
journal = {Frontiers in Neuroscience},
publisher = {Frontiers Research Foundation},
volume = {3},
issue = {1},
year = {2009},
pages = {46-51},
abstract = {Fluid reasoning is the cornerstone of human cognition, both during development and in adulthood. Despite this, the neural mechanisms underlying the development of fluid reasoning are largely unknown. In this review, we provide an overview of this important cognitive ability, the method of measurement, its changes over the childhood and adolescence of an individual, and its underlying neurobiological underpinnings. We review important findings from psychometric, cognitive, and neuroscientific literatures, and outline important future directions for this interdisciplinary research.},
}
@article{DumontheilDCN-14,
title = {Development of abstract thinking during childhood and adolescence: The role of rostrolateral prefrontal cortex},
author = {Iroise Dumontheil},
journal = {Developmental Cognitive Neuroscience},
volume = {10},
year = {2014},
pages = {57-76},
abstract = {Rostral prefrontal cortex (RPFC) has increased in size and changed in terms of its cellular organisation during primate evolution. In parallel emerged the ability to detach oneself from the immediate environment to process abstract thoughts and solve problems and to understand other individuals’ thoughts and intentions. Rostrolateral prefrontal cortex (RLPFC) is thought to play an important role in supporting the integration of abstract, often self-generated, thoughts. Thoughts can be temporally abstract and relate to long term goals, or past or future events, or relationally abstract and focus on the relationships between representations rather than simple stimulus features. Behavioural studies have provided evidence of a prolonged development of the cognitive functions associated with RLPFC, in particular logical and relational reasoning, but also episodic memory retrieval and prospective memory. Functional and structural neuroimaging studies provide further support for a prolonged development of RLPFC during adolescence, with some evidence of increased specialisation of RLPFC activation for relational integration and aspects of episodic memory retrieval. Topics for future research will be discussed, such as the role of medial RPFC in processing abstract thoughts in the social domain, the possibility of training abstract thinking in the domain of reasoning, and links to education.}
}
97 Preliminary sample of papers relating to episodic memory and related applications including question answering:
@article{AnonymousICLR-18a,
title = {Integrating Episodic Memory into a Reinforcement Learning Agent Using Reservoir Sampling},
author = {Anonymous},
journal = {International Conference on Learning Representations},
year = {2018},
url = {https://openreview.net/forum?id=ByJDAIe0b},
abstract = {Episodic memory is a psychology term which refers to the ability to recall specific events from the past. We suggest one advantage of this particular type of memory is the ability to easily assign credit to a specific state when remembered information is found to be useful. Inspired by this idea, and the increasing popularity of external memory mechanisms to handle long-term dependencies in deep learning systems, we propose a novel algorithm which uses a reservoir sampling procedure to maintain an external memory consisting of a fixed number of past states. The algorithm allows a deep reinforcement learning agent to learn online to preferentially remember those states which are found to be useful to recall later on. Critically this method allows for efficient online computation of gradient estimates with respect to the write process of the external memory. Thus unlike most prior mechanisms for external memory it is feasible to use in an online reinforcement learning setting.}
}
@article{AnonymousICLR-18b,
title = {Memory Architectures in Recurrent Neural Network Language Models},
author = {Anonymous},
journal = {International Conference on Learning Representations},
year = {2018},
url = {https://openreview.net/forum?id=SkFqf0lAZ},
abstract = {We compare and analyze sequential, random access, and stack memory architectures for recurrent neural network language models. Our experiments on the Penn Treebank and Wikitext-2 datasets show that stack-based memory architectures consistently achieve the best performance in terms of held out perplexity. We also propose a generalization to existing continuous stack models (Joulin & Mikolov,2015; Grefenstette et al., 2015) to allow a variable number of pop operations more naturally that further improves performance. We further evaluate these language models in terms of their ability to capture non-local syntactic dependencies on a subject-verb agreement dataset (Linzen et al., 2016) and establish new state of the art results using memory augmented language models. Our results demonstrate the value of stack-structured memory for explaining the distribution of words in natural language, in line with linguistic theories claiming a context-free backbone for natural language.}
}
@misc{DynamicMemoryNetworks-16,
title = {Dynamic Memory Networks},
author = {Anonymous},
year = {2016},
howpublished = {{LDGN} Notes and Thoughts on Machine Learning and Artificial Intelligence},
url = {https://ldgn.wordpress.com/2016/01/04/attention-and-memory-in-deep-learning/},
abstract = {Dynamic Memory Networks (DMN) are a general framework for question answering over inputs. Conceptually, a difference is made between inputs and questions. The DMN takes a sequence of inputs and a question and then employs an iterative attention process to compute the answer. The sequence of inputs can be seen as the history, which complements the general world knowledge (see semantic memory module). The DNM framework consists of five components: (i) input module: processes raw input and maps it to a useful representation, (ii) semantic memory module: stores general knowledge about concepts and facts. It can be instantiated by word embeddings or knowledge bases, (iii) question module: maps a question into a representation, (iv) episodic memory module: an iterative component that in each iteration focuses on different parts of the input, updates its internal state and finally outputs an answer representation (vi) answer module: generates the answer to return.}
}
@article{KumaretalCoRR-16,
author = {Ankit Kumar and Ozan Irsoy and Jonathan Su and James Bradbury and Robert English and Brian Pierce and Peter Ondruska and Ishaan Gulrajani and Richard Socher},
title = {Ask Me Anything: Dynamic Memory Networks for Natural Language Processing},
journal = {CoRR},
volume = {arXiv:1506.07285},
year = {2015},
abstract = {Most tasks in natural language processing can be cast into question answering (QA) problems over language input. We introduce the dynamic memory network (DMN), a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers. Questions trigger an iterative attention process which allows the model to condition its attention on the inputs and the result of previous iterations. These results are then reasoned over in a hierarchical recurrent sequence model to generate answers. The DMN can be trained end-to-end and obtains state-of-the-art results on several types of tasks and datasets: question answering (Facebook's bAbI dataset), text classification for sentiment analysis (Stanford Sentiment Treebank) and sequence modeling for part-of-speech tagging (WSJ-PTB). The training for these different tasks relies exclusively on trained word vector representations and input-question-answer triplets.}
}
@inproceedings{ChangandTanIJCAI-17,
author = {Poo-Hee Chang, Ah-Hwee Tan},
title = {Encoding and Recall of Spatio-Temporal Episodic Memory in Real Time},
booktitle = {Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, {IJCAI-17}},
pages = {1490--1496},
year = {2017},
abstract = {Episodic memory enables a cognitive system to improve its performance by reflecting upon past events. In this paper, we propose a computational model called STEM for encoding and recall of episodic events together with the associated con- textual information in real time. Based on a class of self-organizing neural networks, STEM is de- signed to learn memory chunks or cognitive nodes, each encoding a set of co-occurring multi-modal activity patterns across multiple pattern channels. We present algorithms for recall of events based on partial and inexact input patterns. Our empirical results based on a public domain data set show that STEM displays a high level of efficiency and ro- bustness in encoding and retrieval with both partial and noisy search cues when compared with a state- of-the-art associative memory model.},
}
@article{TaniJCS-98,
author = {Tani, Jun},
title = {An interpretation of the 'self' from the dynamical systems perspective: {A} constructivist approach},
booktitle = {Journal of Consciousness Studies},
volume = {5},
year = {1998},
pages = {516-542},
abstract = {This study attempts to describe the notion of the 'self' using dynamical systems language based on the results of our robot learning experiments. A neural network model consisting of multiple modules is proposed, in which the interactive dynamics between the bottom-up perception and the top-down prediction are investigated. Our experiments with a real mobile robot showed that the incremental learning of the robot switches spontaneously between steady and unsteady phases. In the steady phase, the top-down prediction for the bottom-up perception works well when coherence is achieved between the internal and the environmental dynamics. In the unsteady phase, conflicts arise between the bottom-up perception and the top-down prediction; the coherence is lost, and a chaotic attractor is observed in the internal neural dynamics. By investigating possible analogies between this result and the phenomenological literature on the 'self', we draw the conclusions that (1) the structure of the 'self' corresponds to the 'open dynamic structure' which is characterized by co-existence of stability in terms of goal-directedness and instability caused by embodiment; (2) the open dynamic structure causes the system's spontaneous transition to the unsteady phase where the 'self' becomes aware.}
}
@article{PritzeletalCoRR-17,
author = {Alexander Pritzel and Benigno Uria and Sriram Srinivasan and Adri{\`{a}} Puigdom{\`{e}}nech Badia and Oriol Vinyals and Demis Hassabis and Daan Wierstra and Charles Blundell},
title = {Neural Episodic Control},
journal = {CoRR},
volume = {arXiv:1703.01988},
year = {2017},
abstract = {Deep reinforcement learning methods attain super-human performance in a wide range of environments. Such methods are grossly inefficient, often taking orders of magnitudes more data than humans to achieve reasonable performance. We propose Neural Episodic Control: a deep reinforcement learning agent that is able to rapidly assimilate new experiences and act upon them. Our agent uses a semi-tabular representation of the value function: a buffer of past experience containing slowly changing state representations and rapidly updated estimates of the value function. We show across a wide range of environments that our agent learns significantly faster than other state-of-the-art, general purpose deep reinforcement learning agents.}
}
@book{GallagherMODELS-OF-THE-SELF-13,
title = {Models of the Self},
author = {Gallagher, Shaun},
year = {2013},
publisher = {Imprint Academic}
}
@book{OKeefeandNadelHIPPOCAMPUS-78,
title = {The hippocampus as a cognitive map},
author = {O'Keefe, John and Nadel, Lynn},
year = {1978},
publisher = {Clarendon Press}
}
98 Here is a sample of papers relating to attention and theory-of-mind reasoning focusing on the separate research agendas of Josh Tenenbaum at MIT and Michael Graziano at Princeton along with their many students and colleagues:
@article{GershmanetalPLoS-16,
author = {Sam Gershman and Tobias Gerstenberg and Chris Baker and Fiery Cushman},
journal = {PLoS ONE},
title = {Plans, habits, and theory of mind},
year = {2016},
abstract = {Human success and even survival depends on our ability to predict what others will do by guessing what they are thinking. If I accelerate, will he yield? If I propose, will she accept? If I confess, will they forgive? Psychologists call this capacity "theory of mind." According to current theories, we solve this problem by assuming that others are rational actors. That is, we assume that others design and execute efficient plans to achieve their goals, given their knowledge. But if this view is correct, then our theory of mind is startlingly incomplete. Human action is not always a product of rational planning, and we would be mistaken to always interpret others' behaviors as such. A wealth of evidence indicates that we often act habitually—a form of behavioral control that depends not on rational planning, but rather on a history of reinforcement. We aim to test whether the human theory of mind includes a theory of habitual action and to assess when and how it is deployed. In a series of studies, we show that human theory of mind is sensitive to factors influencing the balance between habitual and planned behavior.},
}
@article{LakeetalCoRR-16,
author = {Brenden M. Lake and Tomer D. Ullman and Joshua B. Tenenbaum and Samuel J. Gershman},
title = {Building Machines That Learn and Think Like People},
journal = {CoRR},
volume = {arXiv:1604.00289},
year = {2016},
abstract = {Recent progress in artificial intelligence (AI) has renewed interest in building systems that learn and think like people. Many advances have come from using deep neural networks trained end-to-end in tasks such as object recognition, video games, and board games, achieving performance that equals or even beats humans in some respects. Despite their biological inspiration and performance achievements, these systems differ from human intelligence in crucial ways. We review progress in cognitive science suggesting that truly human-like learning and thinking machines will have to reach beyond current engineering trends in both what they learn, and how they learn it. Specifically, we argue that these machines should (a) build causal models of the world that support explanation and understanding, rather than merely solving pattern recognition problems; (b) ground learning in intuitive theories of physics and psychology, to support and enrich the knowledge that is learned; and (c) harness compositionality and learning-to-learn to rapidly acquire and generalize knowledge to new tasks and situations. We suggest concrete challenges and promising routes towards these goals that can combine the strengths of recent neural network advances with more structured cognitive models.}
}
@article{StuhlmuellerandGoodmanCS-13,
author = {Stuhlm\"{u}ller, A. and Goodman, N. D.},
journal = {Journal of Cognitive Systems Research},
title = {Reasoning about Reasoning by Nested Conditioning: Modeling Theory of Mind with Probabilistic Programs},
volume = {28},
year = {2014},
pages = {80-99},
abstract = {A wide range of human reasoning patterns can be explained as conditioning in probabilistic models; however, conditioning has traditionally been viewed as an operation applied to such models, not represented in such models. We describe how probabilistic programs can explicitly represent conditioning as part of a model. This enables us to describe reasoning about others’ reasoning using nested conditioning. Much of human reasoning is about the beliefs, desires, and intentions of other people; we use probabilistic programs to formalize these inferences in a way that captures the flexibility and inherent uncertainty of reasoning about other agents. We express examples from game theory, artificial intelligence, and linguistics as recursive probabilistic programs and illustrate how this representation language makes it easy to explore new directions in each of these fields. We discuss the algorithmic challenges posed by these kinds of models and describe how Dynamic Programming techniques can help address these challenges.}
}
@inbook{Goodmanetal2015,
author = {Goodman, Noah D. and Tenenbaum, Joshua B. and Gerstenberg, T.},
booktitle = {The Conceptual Mind: New Directions in the Study of Concepts},
editor = {Morgolis and Lawrence},
publisher = {MIT Press},
title = {Concepts in a probabilistic language of thought},
year = {2015}
}
@inproceedings{ErikvandenBoogaardetal2017,
author = {Erik van den Boogaard and Jan Treur and Maxim Turpijn},
title = {A Neurologically Inspired Network Model for Graziano's Attention Schema Theory for Consciousness},
booktitle = {Natural and Artificial Computation for Biomedicine and Neuroscience - International Work-Conference on the Interplay Between Natural and Artificial Computation},
pages = {10-21},
year = {2017},
abstract = {This paper describes a network-oriented model based on the neuroscientist Graziano’s Attention Schema Theory for consciousness. This theory describes an attention schema as an internal model of the attention process supporting the control of attention, similar to how our mind uses a body schema as an internal model of the body to control its movements. The Attention Schema Theory comes with a number of testable predictions. After designing a neurologically inspired temporal- causal network model for the Attention schema Theory, a few simula- tions were conducted to verify some of these predictions. One prediction is that a noticeable attention control deficit occurs when using attention without awareness. Another is that a noticeable attention control deficit occurs when using only bottom-up influence (from the sensory repre- sentations) without any top-down influence (for example, from goal or control states). The presented model is illustrated by a scenario where a hunter imagines (using internal simulation) a prey which he wants to attend to and catch, but shortly after he or she imagines a predator which he then wants to attend to and avoid. The outcomes of the simulations support the predictions that were made.}
}
@article{GrazianoFiRAI-17,
author = {Graziano, Michael S. A.},
title = {The Attention Schema Theory: A Foundation for Engineering Artificial Consciousness},
journal = {Frontiers in Robotics and AI},
volume = {4},
pages = {60},
year = {2017},
abstract = {The purpose of the attention schema theory is to explain how an information-processing device, the brain, arrives at the claim that it possesses a non-physical, subjective awareness, and assigns a high degree of certainty to that extraordinary claim. The theory does not address how the brain might actually possess a non-physical essence. It is not a theory that deals in the non-physical. It is about the computations that cause a machine to make a claim and to assign a high degree of certainty to the claim. The theory is offered as a possible starting point for building artificial consciousness. Given current technology, it should be possible to build a machine that contains a rich internal model of what consciousness is, attributes that property of consciousness to itself and to the people it interacts with, and uses that attribution to make predictions about human behavior. Such a machine would “believe” it is conscious and act like it is conscious, in the same sense that the human machine believes and acts.}
}
@article{IgelstrometalENEURO-16,
author = {Igelstr\"{o}m, Kajsa M. and Webb, Taylor W. and Kelly, Yin T. and Graziano, Michael S. A.},
title = {Topographical Organization of Attentional, Social, and Memory Processes in the Human Temporoparietal Cortex},
journal = {eNeuro},
publisher = {Society for Neuroscience},
volume = {3},
number = {2},
year = {2016},
abstract = {The temporoparietal junction (TPJ) is activated in association with a large range of functions, including social cognition, episodic memory retrieval, and attentional reorienting. An ongoing debate is whether the TPJ performs an overarching, domain-general computation, or whether functions reside in domain-specific subdivisions. We scanned subjects with fMRI during five tasks known to activate the TPJ, probing social, attentional, and memory functions, and used data-driven parcellation (independent component analysis) to isolate task-related functional processes in the bilateral TPJ. We found that one dorsal component in the right TPJ, which was connected with the frontoparietal control network, was activated in all of the tasks. Other TPJ subregions were specific for attentional reorienting, oddball target detection, or social attribution of belief. The TPJ components that participated in attentional reorienting and oddball target detection appeared spatially separated, but both were connected with the ventral attention network. The TPJ component that participated in the theory-of-mind task was part of the default-mode network. Further, we found that the BOLD response in the domain-general dorsal component had a longer latency than responses in the domain-specific components, suggesting an involvement in distinct, perhaps postperceptual, computations. These findings suggest that the TPJ performs both domain-general and domain-specific computations that reside within spatially distinct functional components.},
}
@article{GrazianoandWebb-15,
author = {Graziano, Michael S. A. and Webb, Taylor W.},
title = {The attention schema theory: a mechanistic account of subjective awareness},
journal = {Frontiers in Psychology},
volume = {6},
pages = {500},
year = {2015},
abstract = {We recently proposed the attention schema theory, a novel way to explain the brain basis of subjective awareness in a mechanistic and scientifically testable manner. The theory begins with attention, the process by which signals compete for the brain’s limited computing resources. This internal signal competition is partly under a bottom-up influence and partly under top-down control. We propose that the top-down control of attention is improved when the brain has access to a simplified model of attention itself. The brain therefore constructs a schematic model of the process of attention, the ‘attention schema’, in much the same way that it constructs a schematic model of the body, the ‘body schema’. The content of this internal model leads a brain to conclude that it has a subjective experience. One advantage of this theory is that it explains how awareness and attention can sometimes become dissociated; the brain’s internal models are never perfect, and sometimes a model becomes dissociated from the object being modeled. A second advantage of this theory is that it explains how we can be aware of both internal and external events. The brain can apply attention to many types of information including external sensory information and internal information about emotions and cognitive states. If awareness is a model of attention, then this model should pertain to the same domains of information to which attention pertains. A third advantage of this theory is that it provides testable predictions. If awareness is the internal model of attention, used to help control attention, then without awareness, attention should still be possible but should suffer deficits in control. In this article, we review the existing literature on the relationship between attention and awareness, and suggest that at least some of the predictions of the theory are borne out by the evidence.}
}
99 The abstract syntax tree of the example in the text is a simplified version of the AST for a WHILE loop:
 |
100 Titles and abstracts of papers on prefrontal structures relevant to attention and executive control, including recent research on whether or to what extent working memory is situated in the frontal cortex [269]:
@article{BalletalFiN-11,
author = {Ball, Gareth and Stokes, Paul R. and Rhodes, Rebecca A. and Bose, Subrata K. and Rezek, Iead and Wink, Alle-Meije and Lord, Louis-David and Mehta, Mitul A. and Grasby, Paul M. and Turkheimer, Federico E.},
title = {Executive Functions and Prefrontal Cortex: A Matter of Persistence?},
journal = {Frontiers in Systems Neuroscience},
year = {2011},
publisher = {Frontiers Research Foundation},
volume = {5},
pages = {3},
abstract = {Executive function is thought to originates from the dynamics of frontal cortical networks. We examined the dynamic properties of the blood oxygen level dependent time-series measured with functional MRI (fMRI) within the prefrontal cortex (PFC) to test the hypothesis that temporally persistent neural activity underlies performance in three tasks of executive function. A numerical estimate of signal persistence, the Hurst exponent, postulated to represent the coherent firing of cortical networks, was determined and correlated with task performance. Increasing persistence in the lateral PFC was shown to correlate with improved performance during an n-back task. Conversely, we observed a correlation between persistence and increasing commission error --- indicating a failure to inhibit a prepotent response --- during a Go/No-Go task. We propose that persistence within the PFC reflects dynamic network formation and these findings underline the importance of frequency analysis of fMRI time-series in the study of executive functions.},
}
@article{BalstersetalNEUROIMAGE-09,
title = {Evolution of the cerebellar cortex: {T}he selective expansion of prefrontal-projecting cerebellar lobules},
author = {Balsters, J. H. and Cussans, E. and Diedrichsen, J. and Phillips, K. A. and Preuss, T. M. and Rilling, J. K. and Ramnani, N.},
journal = {NeuroImage},
issue = 3,
pages = {2045-2052},
volume = 49,
year = 2010,
abstract = {It has been suggested that interconnected brain areas evolve in tandem because evolutionary pressures act on complete functional systems rather than on individual brain areas. The cerebellar cortex has reciprocal connections with both the prefrontal cortex and motor cortex, forming independent loops with each. Specifically, in capuchin monkeys cerebellar cortical lobules Crus I and Crus II connect with prefrontal cortex whereas the primary motor cortex connects with cerebellar lobules V, VI, VIIb, and VIIIa. Comparisons of extant primate species suggest that the prefrontal cortex has expanded more than cortical motor areas in human evolution. Given the enlargement of the prefrontal cortex relative to motor cortex in humans, our hypothesis would predict corresponding volumetric increases in the parts of the cerebellum connected to the prefrontal cortex, relative to cerebellar lobules connected to the motor cortex. We tested the hypothesis by comparing the volumes of cerebellar lobules in structural MRI scans in capuchins, chimpanzees and humans. The fractions of cerebellar volume occupied by Crus I and Crus II were significantly larger in humans compared to chimpanzees and capuchins. Our results therefore support the hypothesis that in the cortico-cerebellar system, functionally related structures evolve in concert with each other. The evolutionary expansion of these prefrontal-projecting cerebellar territories might contribute to the evolution of the higher cognitive functions of humans.},
}
@article{BaraketalPIN-13,
author = {Omri Barak and David Sussillo and Ranulfo Romo and Misha Tsodyks and L.F. Abbott},
title = {From fixed points to chaos: Three models of delayed discrimination},
journal = {Progress in Neurobiology},
volume = {103},
pages = {214-222},
year = {2013},
note = {Conversion of Sensory Signals into Perceptions, Memories and Decisions},
comment = {This manuscript argues persuasively that mixed selectivity, a signature of high-dimensional neural representations, is a fundamental component of the computational power of prefrontal cortex.},
abstract = {Working memory is a crucial component of most cognitive tasks. Its neuronal mechanisms are still unclear despite intensive experimental and theoretical explorations. Most theoretical models of working memory assume both time-invariant neural representations and precise connectivity schemes based on the tuning properties of network neurons. A different, more recent class of models assumes randomly connected neurons that have no tuning to any particular task, and bases task performance purely on adjustment of network readout. Intermediate between these schemes are networks that start out random but are trained by a learning scheme. Experimental studies of a delayed vibrotactile discrimination task indicate that some of the neurons in prefrontal cortex are persistently tuned to the frequency of a remembered stimulus, but the majority exhibit more complex relationships to the stimulus that vary considerably across time. We compare three models, ranging from a highly organized line attractor model to a randomly connected network with chaotic activity, with data recorded during this task. The random network does a surprisingly good job of both performing the task and matching certain aspects of the data. The intermediate model, in which an initially random network is partially trained to perform the working memory task by tuning its recurrent and readout connections, provides a better description, although none of the models matches all features of the data. Our results suggest that prefrontal networks may begin in a random state relative to the task and initially rely on modified readout for task performance. With further training, however, more tuned neurons with less time-varying responses should emerge as the networks become more structured.}
}
@article{CarlenSCIENCE-17,
author = {Carl\`{e}n, Marie},
title = {What constitutes the prefrontal cortex?},
journal = {Science},
publisher = {American Association for the Advancement of Science},
volume = {358},
number = {6362},
year = {2017},
pages = {478-482},
abstract = {During evolution, the prefrontal region grew in size relative to the rest of the cortex. It reached its largest extent in the human brain, where it constitutes 30\% of the total cortical area. This growth was accompanied by phylogenetic differentiation of the cortical areas. It has been argued that the human brain holds prefrontal regions that are both qualitatively and functionally unique. Present-day neuroscientists studying the prefrontal cortex increasingly use mice. An important goal is to reveal how the prefrontal cortex enables complex behavior. However, the prefrontal cortex still lacks a conclusive definition. The structure and function of this brain area across species remain unresolved. This state of affairs is often overlooked, warranting renewed focus on what the prefrontal cortex is and does.},
}
@article{ChaudhurietalNEURON-15,
author = {Rishidev Chaudhuri and Kenneth Knoblauch and Marie-Alice Gariel and Henry Kennedy and Xiao-Jing Wang},
title = {A Large-Scale Circuit Mechanism for Hierarchical Dynamical Processing in the Primate Cortex},
journal = {Neuron},
volume = {88},
number = {2},
year = {2015},
pages = {419-431},
abstract = {Summary We developed a large-scale dynamical model of the macaque neocortex, which is based on recently acquired directed- and weighted-connectivity data from tract-tracing experiments, and which incorporates heterogeneity across areas. A hierarchy of timescales naturally emerges from this system: sensory areas show brief, transient responses to input (appropriate for sensory processing), whereas association areas integrate inputs over time and exhibit persistent activity (suitable for decision-making and working memory). The model displays multiple temporal hierarchies, as evidenced by contrasting responses to visual versus somatosensory stimulation. Moreover, slower prefrontal and temporal areas have a disproportionate impact on global brain dynamics. These findings establish a circuit mechanism for "temporal receptive windows" that are progressively enlarged along the cortical hierarchy, suggest an extension of time integration in decision making from local to large circuits, and should prompt a re-evaluation of the analysis of functional connectivity (measured by fMRI or electroencephalography/magnetoencephalography) by taking into account inter-areal heterogeneity.}
}
@article{DehaeneChangeuxNEURON-11,
author = {Dehaene, Stanislas and Changeux, Jean-Pierre},
title = {Experimental and Theoretical Approaches to Conscious Processing},
journal = {Neuron},
year = {2017},
publisher = {Elsevier},
volume = {70},
issue = {2},
pages = {200-227},
abstract = {Recent experimental studies and theoretical models have begun to address the challenge of establishing a causal link between subjective conscious experience and measurable neuronal activity. The present review focuses on the well-delimited issue of how an external or internal piece of information goes beyond nonconscious processing and gains access to conscious processing, a transition characterized by the existence of a reportable subjective experience. Converging neuroimaging and neurophysiological data, acquired during minimal experimental contrasts between conscious and nonconscious processing, point to objective neural measures of conscious access: late amplification of relevant sensory activity, long-distance cortico-cortical synchronization at beta and gamma frequencies, and ?ignition? of a large-scale prefronto-parietal network. We compare these findings to current theoretical models of conscious processing, including the Global Neuronal Workspace (GNW) model according to which conscious access occurs when incoming information is made globally available to multiple brain systems through a network of neurons with long-range axons densely distributed in prefrontal, parieto-temporal, and cingulate cortices. The clinical implications of these results for general anesthesia, coma, vegetative state, and schizophrenia are discussed.},
}
@article{JohnsonetalNATURE-16,
author = {Johnson, Carolyn M. and Peckler, Hannah and Tai, Lung-Hao and Wilbrecht, Linda},
title = {Rule learning enhances structural plasticity of long-range axons in frontal cortex},
journal = {Nature Communications},
publisher = {Nature Publishing Group},
volume = {7},
year = {2016},
abstract = {Rules encompass cue-action-outcome associations used to guide decisions and strategies in a specific context. Subregions of the frontal cortex including the orbitofrontal cortex (OFC) and dorsomedial prefrontal cortex (dmPFC) are implicated in rule learning, although changes in structural connectivity underlying rule learning are poorly understood. We imaged OFC axonal projections to dmPFC during training in a multiple choice foraging task and used a reinforcement learning model to quantify explore-exploit strategy use and prediction error magnitude. Here we show that rule training, but not experience of reward alone, enhances OFC bouton plasticity. Baseline bouton density and gains during training correlate with rule exploitation, while bouton loss correlates with exploration and scales with the magnitude of experienced prediction errors. We conclude that rule learning sculpts frontal cortex interconnectivity and adjusts a thermostat for the explore-exploit balance.},
}
@article{KoechlinandJubaultNEURON-06,
title = {Broca's Area and the Hierarchical Organization of Human Behavior},
author = {Koechlin, Etienne and Jubault, Thomas},
journal = {Neuron},
volume = 50,
issue = 6,
year = 2006,
pages = {963-974},
abstract = {The prefrontal cortex subserves executive control, i.e., the organization of action or thought in relation to internal goals. This brain region hosts a system of executive processes extending from premotor to the most anterior prefrontal regions that governs the temporal organization of behavior. Little is known, however, about the prefrontal executive system involved in the hierarchical organization of behavior. Here, we show using magnetic resonance imaging in humans that the posterior portion of the prefrontal cortex, including Broca's area and its homolog in the right hemisphere, contains a system of executive processes that control start and end states and the nesting of functional segments that combine in hierarchically organized action plans. Our results indicate that Broca's area and its right homolog process hierarchically structured behaviors regardless of their temporal organization, suggesting a fundamental segregation between prefrontal executive systems involved in the hierarchical and temporal organization of goal-directed behaviors.},
}
@article{KoechlinetalPNAS-00,
journal = {Proceedings of the National Academy of Sciences},
author = {Koechlin, Etienne and Corrado, Gregory and Pietrini, Pietro and Grafman, Jordan},
title = {Dissociating the role of the medial and lateral anterior prefrontal cortex in human planning},
volume = 97,
issue = 13,
year = 2000,
pages = {7651-7656},
abstract = {The anterior prefrontal cortex is known to subserve higher cognitive functions such as task management and planning. Less is known, however, about the functional specialization of this cortical region in humans. Using functional MRI, we report a double dissociation: the medial anterior prefrontal cortex, in association with the ventral striatum, was engaged preferentially when subjects executed tasks in sequences that were expected, whereas the polar prefrontal cortex, in association with the dorsolateral striatum, was involved preferentially when subjects performed tasks in sequences that were contingent on unpredictable events. These results parallel the functional segregation previously described between the medial and lateral premotor cortex underlying planned and contingent motor control and extend this division to the anterior prefrontal cortex, when task management and planning are required. Thus, our findings support the assumption that common frontal organizational principles underlie motor and higher executive functions in humans.},
}
@article{KoechlinetalSCIENCE-03,
author = {Etienne Koechlin and Chryst\`{e}le Ody and Fr\'{e}d\'{e}rique Kouneiher},
title = {The architecture of cognitive control in the human prefrontal cortex},
journal = {Science},
volume = 302,
year = 2003,
pages = {1181-1185},
abstract = {The prefrontal cortex (PFC) subserves cognitive control: the ability to coordinate thoughts or actions in relation with internal goals. Its functional architecture, however, remains poorly understood. Using brain imaging in humans, we showed that the lateral PFC is organized as a cascade of executive processes from premotor to anterior PFC regions that control behavior according to stimuli, the present perceptual context, and the temporal episode in which stimuli occur, respectively. The results support an unified modular model of cognitive control that describes the overall functional organization of the human lateral PFC and has basic methodological and theoretical implications.},
}
@article{LaraandWallisFiSN-15,
author = {Lara, Antonio H. and Wallis, Jonathan D.},
title = {The Role of Prefrontal Cortex in Working Memory: A Mini Review},
journal = {Frontiers in System Neuroscience},
publisher = {Frontiers Media S.A.},
volume = {9},
year = {2015},
pages = {173},
abstract = {A prominent account of prefrontal cortex (PFC) function is that single neurons within the PFC maintain representations of task-relevant stimuli in working memory. Evidence for this view comes from studies in which subjects hold a stimulus across a delay lasting up to several seconds. Persistent elevated activity in the PFC has been observed in animal models as well as in humans performing these tasks. This persistent activity has been interpreted as evidence for the encoding of the stimulus itself in working memory. However, recent findings have posed a challenge to this notion. A number of recent studies have examined neural data from the PFC and posterior sensory areas, both at the single neuron level in primates, and at a larger scale in humans, and have failed to find encoding of stimulus information in the PFC during tasks with a substantial working memory component. Strong stimulus related information, however, was seen in posterior sensory areas. These results suggest that delay period activity in the PFC might be better understood not as a signature of memory storage per se, but as a top down signal that influences posterior sensory areas where the actual working memory representations are maintained.},
}
@article{OReillySCIENCE-06,
title = {Biologically Based Computational Models of High-Level Cognition},
author = {O'Reilly, Randall C.},
journal = {Science},
volume = 314,
issue = 5796,
year = 2006,
pages = {91-94},
abstract = {Computer models based on the detailed biology of the brain can help us understand the myriad complexities of human cognition and intelligence. Here, we review models of the higher level aspects of human intelligence, which depend critically on the prefrontal cortex and associated subcortical areas. The picture emerging from a convergence of detailed mechanistic models and more abstract functional models represents a synthesis between analog and digital forms of computation. Specifically, the need for robust active maintenance and rapid updating of information in the prefrontal cortex appears to be satisfied by bistable activation states and dynamic gating mechanisms. These mechanisms are fundamental to digital computers and may be critical for the distinctive aspects of human intelligence.},
}
@article{RottschyetalNEUROIMAGE-12,
author = {Rottschy, C. and Langner, R. and Dogan, I. and Reetz, K. and Laird, A. R. and Schulz, J. B. and Fox, P. T. and Eickhoff, S. B.},
title = {Modelling neural correlates of working memory: A coordinate-based meta-analysis},
journal = {Neuroimage},
year = {2012},
volume = {60},
issue = {1},
pages = {830-846},
abstract = {Working memory subsumes the capability to memorize, retrieve and utilize information for a limited period of time which is essential to many human behaviours. Moreover, impairments of working memory functions may be found in nearly all neurological and psychiatric diseases. To examine what brain regions are commonly and differently active during various working memory tasks, we performed a coordinate-based meta-analysis over 189 fMRI experiments on healthy subjects. The main effect yielded a widespread bilateral fronto-parietal network. Further meta-analyses revealed that several regions were sensitive to specific task components, e.g. Broca's region was selectively active during verbal tasks or ventral and dorsal premotor cortex were preferentially involved in memory for object identity and location, respectively. Moreover, the lateral prefrontal cortex showed a division in a rostral and a caudal part based on differential involvement in task-set and load effects. Nevertheless, a consistent but more restricted core network emerged from conjunctions across analyses of specific task designs and contrasts. This core network appears to comprise the quintessence of regions, which are necessary during working memory tasks. It may be argued that the core regions form a distributed executive network with potentially generalized functions for focusing on competing representations in the brain. The present study demonstrates that meta-analyses are a powerful tool to integrate the data of functional imaging studies on a (broader) psychological construct, probing the consistency across various paradigms as well as the differential effects of different experimental implementations.},
}
@incollection{TefferandSemendeferiPBR-12,
author = {Kate Teffer and Katerina Semendeferi},
title = {Chapter 9 - Human prefrontal cortex: Evolution, development and pathology},
editor = {Michel A. Hofman and Dean Falk},
series = {Progress in Brain Research},
publisher = {Elsevier},
volume = {195},
pages = {191-218},
year = {2012},
booktitle = {Evolution of the Primate Brain},
abstract = {The prefrontal cortex is critical to many cognitive abilities that are considered particularly human, and forms a large part of a neural system crucial for normal socio-emotional and executive functioning in humans and other primates. In this chapter, we survey the literature regarding prefrontal development and pathology in humans as well as comparative studies of the region in humans and closely related primate species. The prefrontal cortex matures later in development than more caudal regions, and some of its neuronal subpopulations exhibit more complex dendritic arborizations. Comparative work suggests that the human prefrontal cortex differs from that of closely related primate species less in relative size than it does in organization. Specific reorganizational events in neural circuitry may have taken place either as a consequence of adjusting to increases in size or as adaptive responses to specific selection pressures. Living in complex environments has been recognized as a considerable factor in the evolution of primate cognition. Normal frontal lobe development and function are also compromised in several neurological and psychiatric disorders. A phylogenetically recent reorganization of frontal cortical circuitry may have been critical to the emergence of human-specific executive and social-emotional functions, and developmental pathology in these same systems underlies many psychiatric and neurological disorders, including autism and schizophrenia.}
}
@article{WatsonetalFiSN-14,
author = {Watson, Thomas C. and Becker, Nadine and Apps, Richard and Jones, Matthew W.},
title = {Back to front: cerebellar connections and interactions with the prefrontal cortex},
journal = {Frontiers in Systems Neuroscience},
year = {2014},
publisher = {Frontiers Media S.A.},
volume = {8},
pages = {4},
abstract = {Although recent neuroanatomical evidence has demonstrated closed-loop connectivity between prefrontal cortex and the cerebellum, the physiology of cerebello-cerebral circuits and the extent to which cerebellar output modulates neuronal activity in neocortex during behavior remain relatively unexplored. We show that electrical stimulation of the contralateral cerebellar fastigial nucleus (FN) in awake, behaving rats evokes distinct local field potential (LFP) responses (onset latency {\textasciitilde}13 ms) in the prelimbic (PrL) subdivision of the medial prefrontal cortex. Trains of FN stimulation evoke heterogeneous patterns of response in putative pyramidal cells in frontal and prefrontal regions in both urethane-anesthetized and awake, behaving rats. However, the majority of cells showed decreased firing rates during stimulation and subsequent rebound increases; more than 90\% of cells showed significant changes in response. Simultaneous recording of on-going LFP activity from FN and PrL while rats were at rest or actively exploring an open field arena revealed significant network coherence restricted to the theta frequency range (5-10 Hz). Granger causality analysis indicated that this coherence was significantly directed from cerebellum to PrL during active locomotion. Our results demonstrate the presence of a cerebello-prefrontal pathway in rat and reveal behaviorally dependent coordinated network activity between the two structures, which could facilitate transfer of sensorimotor information into ongoing neocortical processing during goal directed behaviors.},
}
@article{ZhaoetalNATURE-16,
author = {Zhou, Xin and Zhu, Dantong and Qi, Xue-Lian and Li, Sihai and King, Samson G. and Salinas, Emilio and Stanford, Terrence R. and Constantinidis, Christos},
title = {Neural correlates of working memory development in adolescent primates},
journal = {Nature Communications},
publisher = {Nature Publishing Group},
year = {2016},
volume = {9},
issue = {7},
pages = {13423},
abstract = {Working memory ability matures after puberty, in parallel with structural changes in the prefrontal cortex, but little is known about how changes in prefrontal neuronal activity mediate this cognitive improvement in primates. To address this issue, we compare behavioural performance and neurophysiological activity in monkeys as they transitioned from puberty into adulthood. Here we report that monkeys perform working memory tasks reliably during puberty and show modest improvement in adulthood. The adult prefrontal cortex is characterized by increased activity during the delay period of the task but no change in the representation of stimuli. Activity evoked by distracting stimuli also decreases in the adult prefrontal cortex. The increase in delay period activity relative to the baseline activity of prefrontal neurons is the best correlate of maturation and is not merely a consequence of improved performance. Our results reveal neural correlates of the working memory improvement typical of primate adolescence.},
}
101 Here are two excerpts from Dehaene [104] relating to attention, working memory and executive control. Note that working memory and conscious perception were thought to share similar brain mechanisms. Trübutschek et al [439] examine recent reports of non-conscious working memory that challenge this view. They combine visual masking with magnetoencephalography to demonstrate the reality of nonconscious working memory and dissect its neural mechanisms:
The component of the mind that psychologists call working memory is one of the dominant functions of the dorsolateral prefrontal cortex and the areas that it connects with, thus making these areas strong candidates for the depositories of our conscious knowledge. These regions pop up in brain imaging experiments whenever we briefly hold on to a piece of information: a phone number, a color, or the shape of a flashed picture. Prefrontal neurons implement an active memory: long after the picture is gone, they continue to fire throughout the short-term memory task—sometimes as long as dozens of seconds later. And when the prefrontal cortex is impaired or distracted, this memory is lost—it falls into unconscious oblivion.Together with the physicists Mariano Sigman and Ariel Zylberberg, I have begun to explore the computational properties that such a device would possess. It closely resembles what computer scientists call a "production system," a type of program introduced in the 1960s to implement artificial intelligence tasks. A production system comprises a database, also called "working memory," and a vast array of if-then production rules (e.g., if there is an A in working memory, then change it to the sequence BC). At each step, the system examines whether a rule matches the current state of its working memory. If multiple rules match, then they compete under the aegis of a stochastic prioritizing system. Finally, the winning rule ignites and is allowed to change the contents of working memory before the entire process resumes. Thus this sequence of steps amounts to serial cycles of unconscious competition, conscious ignition, and broadcasting.
102 Here is Stanislas Dehaene writing about the relationship between consciousness and maintaining persistent thoughts:
There may be a very good reason why our consciousness condenses sensory messages into a synthetic code, devoid of gaps and ambiguities: such a code is compact enough to be carried forward in time, entering what we usually call “working memory.” Working memory and consciousness seem to be tightly related. One may even argue, with Daniel Dennett, that a main role of consciousness is to create lasting thoughts. Once a piece of information is conscious, it stays fresh in our mind for as long as we care to attend to it and remember it. The conscious brief must be kept stable enough to inform our decisions, even if they take a few minutes to form. This extended duration, thickening of the present moment, is characteristic of our conscious thoughts. — Stanislas Dehaene [104]
103 Bibliography references for the four tutorials on neural networks used as supplements in CS379C including URL and date of the cached PDF on the course website:
@misc{KarparthyCONVOLUTIONAL-NEURAL-NETWORKS-16,
title = {Convolutional Neural Networks for Visual Recognition},
author = {Andrej Karparthy},
howpublished = {http://cs231n.github.io/convolutional-networks/},
year = {2016},
}
@Misc{KarparthyUNREASONABLY-EFFECTIVE-RNN-15,
title = {The Unreasonable Effectivenss of Recursive Neutal Networks},
author = {Andrej Karparthy},
howpublished = {http://karpathy.github.io/2015/05/21/rnn-effectiveness/},
year = {2015},
}
@article{OlahandCarterATTENTION-TUTORIAL-16,
author = {Olah, Chris and Carter, Shan},
title = {Attention and Augmented Recurrent Neural Networks},
journal = {Distill},
url = {http://distill.pub/2016/augmented-rnns},
year = {2016},
}
@misc{OlahLSTM-NEURAL-NETWORK-TUTORIAL-15,
title = {Understanding LSTM Networks},
author = {Christopher Olah},
howpublished = {http://colah.github.io/posts/2015-08-Understanding-LSTMs},
year = {2015},
}
104 In Greek mythology, Pan is the god of the mountain wilds and wooded glens, the champion of rustic music and the frequent consort of the woodland nymphs. Pan is also the god of theatrical criticism and impromptus. In addition to the usual duties of godhood in Greek mythology, Pan has a reputation of being slyly mischievous and sexually promiscuous, characteristics we will not attempt to recreate in our digital apprentice. After Pan our next choice is Panache, a word of French origin that carries the connotation of flamboyant manner, confidence and reckless courage, and might serve as an acronym for the unwieldy full name [P]rogrammer's [A]pprentice [N]eural-network [A]rchitecture [H]ierarchical [E]xecutive [C]ontroller, allowing only one word out of place to reflect Pan's mischievous wit.
105 Recent work and seminal papers relating to the notion of dynamic links — also called fast weights — to attend to the recent past [455, 456]:
@incollection{vonderMalsburgPNN-94,
title = {The Correlation Theory of Brain Function},
author = {Christoph von der Malsburg},
booktitle = {Models of Neural Networks: Physics of Neural Networks},
editor = {Domany, E. and van Hemmen, J.L. and Schulten, K.},
publisher = {Springer},
year = {1994},
abstract = {A summary of brain theory is given so far as it is contained within the framework of Localization Theory. Diffculties of this "conventional theory" are traced back to a specific deficiency: there is no way to express relations between active cells (as for instance their representing parts of the same object). A new theory is proposed to cure this deficiency. It introduces a new kind of dynamical control, termed synaptic modulation, according to which synapses switch between a conducting and a non- conducting state. The dynamics of this variable is controlled on a fast time scale by correlations in the temporal fine structure of cellular signals. Furthermore, conventional synaptic plasticity is replaced by a refined version. Synaptic modulation and plasticity form the basis for short-term and long-term memory, respectively. Signal correlations, shaped by the variable network, express structure and relationships within objects. In particular, the figure-ground problem may be solved in this way. Synaptic modulation introduces flexibility into cerebral networks which is necessary to solve the invariance problem. Since momentarily useless connections are deactivated, interference between different memory traces can be reduced, and memory capacity increased, in comparison with conventional associative memory.}
}
@techreport{vonderMalsburgMPI-81,
title = {The Correlation Theory of Brain Function},
author = {Christoph von der Malsburg},
issue = {{Internal Report 81-2}},
institution = {Max Planck Institute for Biophysical Chemistry},
year = 1981
}
@incollection{HintonandPlautCSS-87,
author = {Hinton, G. E. and Plaut, D. C.},
title = {Using fast weights to deblur old},
booktitle = {Proceedings of the 9th Annual Conference of the Cognitive Science Society},
publisher = {Lawrence Erlbaum Associates},
year = {1987},
pages = {177-186},
abstract = {Connectionist models usually have a single weight on each connection. Some interesting new properties emerge if each connection has two weights: A slowly changing, plastic weight which stores long-term knowledge and a fast-changing, elastic weight which stores temporary knowledge and spontaneously decays towards zero. If a network learns a set of associations and then these associations are "blurred" by subsequent learning, all the original associations can be "deblurred" by rehearsing on just a few of them. The rehearsal allows the fast weights to take on values that temporarily cancel out the changes in the slow weights caused by the subsequent learning.}
}
@article{BaetalCoRR-16,
author = {Jimmy Ba and Geoffrey Hinton and Volodymyr Mnih and Joel Z. Leibo and Catalin Ionescu},
title = {Using Fast Weights to Attend to the Recent Past},
journal = {CoRR},
volume = {arXiv:1610.06258},
year = {2016},
abstract = {Until recently, research on artificial neural networks was largely restricted to systems with only two types of variable: Neural activities that represent the current or recent input and weights that learn to capture regularities among inputs, outputs and payoffs. There is no good reason for this restriction. Synapses have dynamics at many different time-scales and this suggests that artificial neural networks might benefit from variables that change slower than activities but much faster than the standard weights. These "fast weights" can be used to store temporary memories of the recent past and they provide a neurally plausible way of implementing the type of attention to the past that has recently proved very helpful in sequence-to-sequence models. By using fast weights we can avoid the need to store copies of neural activity patterns.}
}
@article{AnonymousICLR-17b,
title = {Gated Fast Weights for Associative Retrieval},
author = {Anonymous},
journal = {International Conference on Learning Representations},
year = {2017},
abstract = {We improve previous end-to-end differentiable neural networks (NNs) with fast weight memories. A gate mechanism updates fast weights at every time step of a sequence through two separate outer-product-based matrices generated by slow parts of the net. The system is trained on a complex sequence to sequence variation of the Associative Retrieval Problem with roughly 70 times more temporal memory (i.e. time-varying variables) than similar-sized standard recurrent NNs (RNNs). In terms of accuracy and number of parameters, our architecture outperforms a variety of RNNs, including Long Short-Term Memory, Hypernetworks, and related fast weight architectures.}
}
@article{ZhuandvonderMalsburgNEUROCOMPUTING-02,
author = {Junmei Zhu and Christoph von der Malsburg},
title = {Synapto–synaptic interactions speed up dynamic link matching},
journal = {Neurocomputing},
volume = {44-46},
year = {2002},
pages = {721-728},
abstract = {An extended dynamic link matching (DLM) model is presented for the fast creation of mappings invariant to position, scale, deformation and orientation, a process underlying various visual tasks that are fast and effortless for humans but are computationally very difficult. Structured interactions between synapses are represented by control units. Each control unit stands for a group of synapses that are consistent with each other in terms of relative position, scale and orientation. Specifically, it is shown in simulations how these high-order interactions between synapses lead to very fast DLM.}
}
@article{HuangetalCoRR-17,
author = {{Huang}, Q. and {Smolensky}, P. and {He}, X. and {Deng}, L. and {Wu}, D.},
title = {{Tensor Product Generation Networks}},
journal = {CoRR},
year = 2017,
abstract = {We present a new tensor product generation network (TPGN) that generates natural language descriptions for images. The model has a novel architecture that instantiates a general framework for encoding and processing symbolic structure through neural network computation. This framework is built on Tensor Product Representations (TPRs). We evaluated the proposed TPGN on the MS COCO image captioning task. The exeprimental results show that the TPGN outperforms the LSTM based state-of-the-art baseline with a significant margin. Further, we show that our caption generation model can be interpreted as generating sequences of grammatical categories and retrieving words by their categories from a plan encoded as a distributed representation.}
}
@book{SmolenskyandLegendre2011,
title = {The Harmonic Mind: From Neural Computation to Optimality-theoretic Grammar. Linguistic and philosophical implications},
author = {Smolensky, P. and Legendre, G.},
number = {{II}},
year = {2011},
publisher = {MIT Press}
}
107 K. L. Parker, Y. C. Kim, R. M. Kelley, A. J. Nessler, K-H Chen, V. A. Muller-Ewald, N. C. Andreasen, N. S. Narayanan. Delta-frequency stimulation of cerebellar projections can compensate for schizophrenia-related medial frontal dysfunction. Molecular Psychiatry, (2017).
The latest findings by Parker and colleagues provide fresh insights into how the cerebellum influences neural networks in the frontal lobes and the role of the cerebellum in cognitive processing. This study also suggests that delta-frequency cerebellar stimulation might help improve cognitive problems in human patients with schizophrenia.
Mark J. Wagner, Tony Hyun Kim, Joan Savall, Mark J. Schnitzer, Liqun Luo. Cerebellar granule cells encode the expectation of reward. Nature (2017)
Along this line, last week, neuroscientists at Stanford University serendipitously discovered (for the first time) that granule cells in the cerebellum encode and predict rewards. The Stanford study, "Cerebellar Granule Cells Encode the Expectation of Reward," was published March 20 online ahead of print in the journal Nature.
Manish Saggar, Eve-Marie Quintin, Nicholas T. Bott, Eliza Kienitz, Yin-hsuan Chien, Daniel W-C. Hong, Ning Liu, Adam Royalty, Grace Hawthorne, Allan L. Reiss. Changes in Brain Activation Associated with Spontaneous Improvization and Figural Creativity After Design-Thinking-Based Training: A Longitudinal fMRI Study. Cerebral Cortex (2016).
Another team of researchers at Stanford University, led by Manish Saggar, reported that optimizing cerebral-cerebellar connectivity increases creative capacity. Saggar's team found that suppressing the executive-control functions of the cerebrum — while encouraging the cerebellum to become the "controller" — increased spontaneous creative capacity.
106 Excerpts and page links from Wikipedia on brain structures relevant to attention and executive control. They are provided here as a convenient reference for quick review. Follow the supplied links for the full story and remember that this is Wikipedia and not the latest — 5th edition (October 26, 2012) — edition of Kandel, Schwartz, Jessell, Siegelbaum and Hudspeth [245]:
Tectum — In adult humans, it only consists of the inferior and the superior colliculi.
The superior colliculus is involved in preliminary visual processing and control of eye movements. In non-mammalian vertebrates it serves as the main visual area of the brain, functionally analogous to the visual areas of the cerebral cortex in mammals.
The inferior colliculus is involved in auditory processing. It receives input from various brain stem nuclei and projects to the medial geniculate nucleus of the thalamus, which relays auditory information to the primary auditory cortex.
Both colliculi also have descending projections to the paramedian pontine reticular formation and spinal cord, and thus can be involved in responses to stimuli faster than cortical processing would allow. Collectively the colliculi are referred to as the corpora quadrigemina.
Thalamus — The thalamus is the large mass of gray matter in the dorsal part of the diencephalon of the brain with several functions such as relaying of sensory signals, including motor signals, to the cerebral cortex, and the regulation of consciousness, sleep, and alertness.
The thalamus has multiple functions, generally believed to act as a relay station, or hub, relaying information between different subcortical areas and the cerebral cortex. In particular, every sensory system (with the exception of the olfactory system) includes a thalamic nucleus that receives sensory signals and sends them to the associated primary cortical area.
For the visual system, for example, inputs from the retina are sent to the lateral geniculate nucleus of the thalamus, which in turn projects to the visual cortex in the occipital lobe. The thalamus is believed to both process sensory information as well as relay it—each of the primary sensory relay areas receives strong feedback connections from the cerebral cortex.
Basal Ganglia — The basal ganglia (or basal nuclei) is a group of subcortical nuclei, of varied origin, in the brains of vertebrates including humans, which are situated at the base of the forebrain. Basal ganglia are strongly interconnected with the cerebral cortex, thalamus, and brainstem, as well as several other brain areas. The basal ganglia are associated with a variety of functions including: control of voluntary motor movements, procedural learning, routine behaviors or "habits" such as teeth grinding, eye movements, cognition, and emotion.
Popular theories implicate the basal ganglia primarily in action selection — in helping to decide which of several possible behaviors to execute at any given time. In more specific terms, the basal ganglia's primary function is likely to control and regulate activities of the motor and premotor cortical areas so that voluntary movements can be performed smoothly.
Experimental studies show that the basal ganglia exert an inhibitory influence on a number of motor systems, and that a release of this inhibition permits a motor system to become active. The "behavior switching" that takes place within the basal ganglia is influenced by signals from many parts of the brain, including the prefrontal cortex, which plays a key role in executive functions107.
Prefrontal Cortex — This brain region has been implicated in planning complex cognitive behavior, personality expression, decision making, and moderating social behavior. The basic activity of this brain region is considered to be orchestration of thoughts and actions in accordance with internal goals.
The most typical psychological term for functions carried out by the prefrontal cortex area is executive function. Executive function relates to abilities to differentiate among conflicting thoughts, determine good and bad, better and best, same and different, future consequences of current activities, working toward a defined goal, prediction of outcomes, expectation based on actions, and social "control" (the ability to suppress urges that, if not suppressed, could lead to socially unacceptable outcomes).
108 The concept of working memory is defined in terms of how it facilitates problem solving. Its relationship to the concepts of short- and long-term memory are described in [78] and summarized in the paper's abstract below. Cowan [78] emphasizes the connection between working memory and attention. O'Reilly [330] emphasizes the active maintenance and rapid updating of information required for planning and decision making in terms of different proposed gating mechanisms, and uses related mechanisms to explain dynamic variable binding. Eliasmith [132] and Stocco et al [417] provide additional detail concerning the role of the basal ganglia.
The exact location of working memory in the brain is still a matter of some controversy due, in no small part, to fuzziness about what constitutes working memory and how we might go about localizing it. Rottschy et al [369] performed a coordinate-based meta-analysis over 189 fMRI experiments involving various tasks relying on the exercise of working memory tasks. The main effects across all of these experiments involving working memory reveal consistent bilateral activity of fronto-parietal networks clearly visible in the fMRI data accompanying the Rottschy et al [369] paper and can explored using the 3-D graphics tools provided here.
@article{CowanPBR-08,
author = {Cowan, Nelson},
title = {What are the differences between long-term, short-term and working memory?},
journal = {Progress in Brain Research},
year = {2008},
volume = {169},
pages = {323-338},
abstract = {In the recent literature there has been considerable confusion about the three types of memory: long-term, short-term, and working memory. This chapter strives to reduce that confusion and makes up-to-date assessments of these types of memory. Long- and short-term memory could differ in two fundamental ways, with only short-term memory demonstrating (1) temporal decay and (2) chunk capacity limits. Both properties of short-term memory are still controversial but the current literature is rather encouraging regarding the existence of both decay and capacity limits. Working memory has been conceived and defined in three different, slightly discrepant ways: as short-term memory applied to cognitive tasks, as a multi-component system that holds and manipulates information in short-term memory, and as the use of attention to manage short-term memory. Regardless of the definition, there are some measures of memory in the short term that seem routine and do not correlate well with cognitive aptitudes and other measures (those usually identified with the term 'working memory') that seem more attention demanding and do correlate well with these aptitudes. The evidence is evaluated and placed within a theoretical framework depicted in Figure 1.},
}
@book{Eliasmith2013,
title = {How to Build a Brain: A Neural Architecture for Biological Cognition},
author = {Eliasmith, Chris},
series = {Oxford Series on Cognitive Modeling},
year = {2013},
publisher = {Oxford University Press {USA}},
abstract = {One goal of researchers in neuroscience, psychology, and artificial intelligence is to build theoretical models that are able to explain the flexibility and adaptiveness of biological systems. How to build a brain provides a detailed guided exploration of a new cognitive architecture that takes biological detail seriously, while addressing cognitive phenomena. The Semantic Pointer Architecture (SPA) introduced in this book provides a set of tools for constructing a wide range of biologically constrained perceptual, cognitive, and motor models.}
}
@article{OReillySCIENCE-06,
title = {Biologically Based Computational Models of High-Level Cognition},
author = {O'Reilly, Randall C.},
journal = {Science},
volume = 314,
issue = 5796,
year = 2006,
pages = {91-94},
abstract = {Computer models based on the detailed biology of the brain can help us understand the myriad complexities of human cognition and intelligence. Here, we review models of the higher level aspects of human intelligence, which depend critically on the prefrontal cortex and associated subcortical areas. The picture emerging from a convergence of detailed mechanistic models and more abstract functional models represents a synthesis between analog and digital forms of computation. Specifically, the need for robust active maintenance and rapid updating of information in the prefrontal cortex appears to be satisfied by bistable activation states and dynamic gating mechanisms. These mechanisms are fundamental to digital computers and may be critical for the distinctive aspects of human intelligence.},
}
@article{RottschyetalNEUROIMAGE-12,
author = {Rottschy, C. and Langner, R. and Dogan, I. and Reetz, K. and Laird, A. R. and Schulz, J. B. and Fox, P. T. and Eickhoff, S. B.},
title = {Modelling neural correlates of working memory: A coordinate-based meta-analysis},
journal = {Neuroimage},
year = {2012},
volume = {60},
issue = {1},
pages = {830-846},
abstract = {Working memory subsumes the capability to memorize, retrieve and utilize information for a limited period of time which is essential to many human behaviours. Moreover, impairments of working memory functions may be found in nearly all neurological and psychiatric diseases. To examine what brain regions are commonly and differently active during various working memory tasks, we performed a coordinate-based meta-analysis over 189 fMRI experiments on healthy subjects. The main effect yielded a widespread bilateral fronto-parietal network. Further meta-analyses revealed that several regions were sensitive to specific task components, e.g. Broca's region was selectively active during verbal tasks or ventral and dorsal premotor cortex were preferentially involved in memory for object identity and location, respectively. Moreover, the lateral prefrontal cortex showed a division in a rostral and a caudal part based on differential involvement in task-set and load effects. Nevertheless, a consistent but more restricted core network emerged from conjunctions across analyses of specific task designs and contrasts. This core network appears to comprise the quintessence of regions, which are necessary during working memory tasks. It may be argued that the core regions form a distributed executive network with potentially generalized functions for focusing on competing representations in the brain. The present study demonstrates that meta-analyses are a powerful tool to integrate the data of functional imaging studies on a (broader) psychological construct, probing the consistency across various paradigms as well as the differential effects of different experimental implementations.},
}
@article{StoccoetalPR-10,
author = {Stocco, Andrea and Lebiere, Christian and Anderson, John R.},
title = {Conditional Routing of Information to the Cortex: A Model of the Basal Ganglia's Role in Cognitive Coordination},
journal = {Psychology Review},
year = {2010},
volume = {117},
issue = {2},
pages = {541-574},
abstract = {The basal ganglia play a central role in cognition and are involved in such general functions as action selection and reinforcement learning. Here, we present a model exploring the hypothesis that the basal ganglia implement a conditional information-routing system. The system directs the transmission of cortical signals between pairs of regions by manipulating separately the selection of sources and destinations of information transfers. We suggest that such a mechanism provides an account for several cognitive functions of the basal ganglia. The model also incorporates a possible mechanism by which subsequent transfers of information control the release of dopamine. This signal is used to produce novel stimulus-response associations by internalizing transferred cortical representations in the striatum. We discuss how the model is related to production systems and cognitive architectures. A series of simulations is presented to illustrate how the model can perform simple stimulus-response tasks, develop automatic behaviors, and provide an account of impairments in Parkinson's and Huntington's diseases.},
}
@article{TrubutschekBIORXIV-16,
author = {Tr\"{u}butschek, Darinka and Marti, S\'{e}bastien and Ojeda, Andr\'{e}s and King, Jean-R\'{e}mi and Mi, Yuanyuan and Tsodyks, Misha and Dehaene, Stanislas},
title = {A theory of working memory without consciousness or sustained activity},
journal = {Biorxiv},
year = {2016},
abstract = {Working memory and conscious perception are thought to share similar brain mechanisms, yet recent reports of non-conscious working memory challenge this view. Combining visual masking with magnetoencephalography, we demonstrate the reality of nonconscious working memory and dissect its neural mechanisms. In a spatial delayed-response task, participants reported the location of a subjectively unseen target above chance-level after a long delay. Conscious perception and conscious working memory were characterized by similar signatures: a sustained desynchronization in the alpha/beta band over frontal cortex, and a decodable representation of target location in posterior sensors. During non-conscious working memory, such activity vanished. Our findings contradict models that identify working memory with sustained neural firing, but are compatible with recent proposals of ‘activity-silent’ working memory. We present a theoretical framework and simulations showing how slowly decaying synaptic changes allow cell assemblies to go dormant during the delay, yet be retrieved above chance-level after several seconds.}
}
@article{ZhaoetalNATURE-16,
author = {Zhou, Xin and Zhu, Dantong and Qi, Xue-Lian and Li, Sihai and King, Samson G. and Salinas, Emilio and Stanford, Terrence R. and Constantinidis, Christos},
title = {Neural correlates of working memory development in adolescent primates},
journal = {Nature Communications},
publisher = {Nature Publishing Group},
year = {2016},
volume = {9},
issue = {7},
pages = {13423},
abstract = {Working memory ability matures after puberty, in parallel with structural changes in the prefrontal cortex, but little is known about how changes in prefrontal neuronal activity mediate this cognitive improvement in primates. To address this issue, we compare behavioural performance and neurophysiological activity in monkeys as they transitioned from puberty into adulthood. Here we report that monkeys perform working memory tasks reliably during puberty and show modest improvement in adulthood. The adult prefrontal cortex is characterized by increased activity during the delay period of the task but no change in the representation of stimuli. Activity evoked by distracting stimuli also decreases in the adult prefrontal cortex. The increase in delay period activity relative to the baseline activity of prefrontal neurons is the best correlate of maturation and is not merely a consequence of improved performance. Our results reveal neural correlates of the working memory improvement typical of primate adolescence.},
}
109 Two relative recent papers on simulating and reasoning about physical systems with an emphasis of continuous models that can be easily visualized:
% @article{BattagliaetalCoRR-16,
author = {Peter W. Battaglia and Razvan Pascanu and Matthew Lai and Danilo Jimenez Rezende and Koray Kavukcuoglu},
title = {Interaction Networks for Learning about Objects, Relations and Physics},
journal = {CoRR},
volume = {arXiv:1612.00222},
year = {2016},
abstract = {Reasoning about objects, relations, and physics is central to human intelligence, and a key goal of artificial intelligence. Here we introduce the interaction network, a model which can reason about how objects in complex systems interact, supporting dynamical predictions, as well as inferences about the abstract properties of the system. Our model takes graphs as input, performs object- and relation-centric reasoning in a way that is analogous to a simulation, and is implemented using deep neural networks. We evaluate its ability to reason about several challenging physical domains: n-body problems, rigid-body collision, and non-rigid dynamics. Our results show it can be trained to accurately simulate the physical trajectories of dozens of objects over thousands of time steps, estimate abstract quantities such as energy, and generalize automatically to systems with different numbers and configurations of objects and relations. Our interaction network implementation is the first general-purpose, learnable physics engine, and a powerful general framework for reasoning about object and relations in a wide variety of complex real-world domains.}
}
@article{ChangetalCoRR-16,
author = {Michael B. Chang and Tomer Ullman and Antonio Torralba and Joshua B. Tenenbaum},
title = {A Compositional Object-Based Approach to Learning Physical Dynamics},
journal = {CoRR},
volume = {arXiv:1612.00341},
year = {2016},
abstract = {We present the Neural Physics Engine (NPE), a framework for learning simulators of intuitive physics that naturally generalize across variable object count and different scene configurations. We propose a factorization of a physical scene into composable object-based representations and a neural network architecture whose compositional structure factorizes object dynamics into pairwise interactions. Like a symbolic physics engine, the NPE is endowed with generic notions of objects and their interactions; realized as a neural network, it can be trained via stochastic gradient descent to adapt to specific object properties and dynamics of different worlds. We evaluate the efficacy of our approach on simple rigid body dynamics in two-dimensional worlds. By comparing to less structured architectures, we show that the NPE's compositional representation of the structure in physical interactions improves its ability to predict movement, generalize across variable object count and different scene configurations, and infer latent properties of objects such as mass.},
}
110 Maseo Ito's 2012 monograph summarizing 50 years of work on the cerebellum and related cortical structures:
@book{Ito2012,
title = {The Cerebellum: Brain for an Implicit Self},
author = {Ito, Masao},
publisher = {FT Press},
year = {2012},
}
111 Review articles relating to the control of non-motor activities that involve closed loop connections between the cerebral corted and in particular prefrontal region and the cerebellar cortex via the basal ganglia, dentate gyrus and thalamus:
@article{ItoNRN-08,
author = {Ito, Masao},
title = {Control of mental activities by internal models in the cerebellum},
journal = {Nature Reviews Neuroscience},
publisher = {Nature Publishing Group},
volume = 9,
issue = 4,
year = 2008,
pages = {304-313},
abstract = {The intricate neuronal circuitry of the cerebellum is thought to encode internal models that reproduce the dynamic properties of body parts. These models are essential for controlling the movement of these body parts: they allow the brain to precisely control the movement without the need for sensory feedback. It is thought that the cerebellum might also encode internal models that reproduce the essential properties of mental representations in the cerebral cortex. This hypothesis suggests a possible mechanism by which intuition and implicit thought might function and explains some of the symptoms that are exhibited by psychiatric patients. This article examines the conceptual bases and experimental evidence for this hypothesis.},
}
@article{StricketalARN-09,
author = {Peter L. Strick and Richard P. Dum and Julie A. Fiez},
title = {Cerebellum and Nonmotor Function},
journal = {Annual Review of Neuroscience},
volume = {32},
number = {1},
pages = {413-434},
year = {2009},
abstract = {Does the cerebellum influence nonmotor behavior? Recent anatomical studies demonstrate that the output of the cerebellum targets multiple nonmotor areas in the prefrontal and posterior parietal cortex, as well as the cortical motor areas. The projections to different cortical areas originate from distinct output channels within the cerebellar nuclei. The cerebral cortical area that is the main target of each output channel is a major source of input to the channel. Thus, a closed-loop circuit represents the major architectural unit of cerebro-cerebellar interactions. The outputs of these loops provide the cerebellum with the anatomical substrate to influence the control of movement and cognition. Neuroimaging and neuropsychological data supply compelling support for this view. The range of tasks associated with cerebellar activation is remarkable and includes tasks designed to assess attention, executive control, language, working memory, learning, pain, emotion, and addiction. These data, along with the revelations about cerebro-cerebellar circuitry, provide a new framework for exploring the contribution of the cerebellum to diverse aspects of behavior. }
}
@article{WatsonetalFiSN-14,
author = {Watson, Thomas C. and Becker, Nadine and Apps, Richard and Jones, Matthew W.},
title = {Back to front: cerebellar connections and interactions with the prefrontal cortex},
journal = {Frontiers in Systems Neuroscience},
year = {2014},
publisher = {Frontiers Media S.A.},
volume = {8},
pages = {4},
abstract = {Although recent neuroanatomical evidence has demonstrated closed-loop connectivity between prefrontal cortex and the cerebellum, the physiology of cerebello-cerebral circuits and the extent to which cerebellar output modulates neuronal activity in neocortex during behavior remain relatively unexplored. We show that electrical stimulation of the contralateral cerebellar fastigial nucleus (FN) in awake, behaving rats evokes distinct local field potential (LFP) responses (onset latency {\textasciitilde}13 ms) in the prelimbic (PrL) subdivision of the medial prefrontal cortex. Trains of FN stimulation evoke heterogeneous patterns of response in putative pyramidal cells in frontal and prefrontal regions in both urethane-anesthetized and awake, behaving rats. However, the majority of cells showed decreased firing rates during stimulation and subsequent rebound increases; more than 90\% of cells showed significant changes in response. Simultaneous recording of on-going LFP activity from FN and PrL while rats were at rest or actively exploring an open field arena revealed significant network coherence restricted to the theta frequency range (5-10 Hz). Granger causality analysis indicated that this coherence was significantly directed from cerebellum to PrL during active locomotion. Our results demonstrate the presence of a cerebello-prefrontal pathway in rat and reveal behaviorally dependent coordinated network activity between the two structures, which could facilitate transfer of sensorimotor information into ongoing neocortical processing during goal directed behaviors.},
}
112 Original papers by David Marr and James Albus on theories of learning in the cerebellar cortex plus early related work by Eccles, Itō, and Szentágothai and a more recent overview by Raymond et al in Science:
@article{AlbusMB-71,
author = {Albus, James S.},
title = {A Theory of Cerebellar Functions},
journal = {Mathematical Biology},
volume = 10,
year = 1971,
pages = {25-61},
}
@book{Ecclesetal1967,
title = {The Cerebellum as a Neuronal Machine},
author = {Eccles, J.C. and It\={o}, M. and Szent\'{a}gothai, J.},
year = {1967},
publisher = {Springer-Verlag}
}
@article{ItoNRN-08,
author = {Ito, Masao},
title = {Control of mental activities by internal models in the cerebellum},
journal = {Nature Reviews Neuroscience},
publisher = {Nature Publishing Group},
volume = 9,
issue = 4,
year = 2008,
pages = {304-313},
abstract = {The intricate neuronal circuitry of the cerebellum is thought to encode internal models that reproduce the dynamic properties of body parts. These models are essential for controlling the movement of these body parts: they allow the brain to precisely control the movement without the need for sensory feedback. It is thought that the cerebellum might also encode internal models that reproduce the essential properties of mental representations in the cerebral cortex. This hypothesis suggests a possible mechanism by which intuition and implicit thought might function and explains some of the symptoms that are exhibited by psychiatric patients. This article examines the conceptual bases and experimental evidence for this hypothesis.},
}
@article{MarrJoP-69,
author = {Marr, David},
title = {A Theory of Cerebellar Cortex},
journal = {Journal of Physiology},
volume = 202,
year = 1969,
pages = {437-470},
}
@article{RaymondetalSCIENCE-96,
author = {Jennifer L. Raymond and Stephen G. Lisberger and Michael D. Mauk},
title = {The Cerebellum: A Neuronal Learning Machine?},
journal = {Science},
volume = 722,
issue = 6158,
year = 1996,
abstract = {The comparison of two seemingly quite different behaviors yields a surprisingly consistent picture of the role of the cerebellum in motorlearning. Behavioral and physiological data about classical conditioning of the eye lid response and motor learning in the vestibulo-ocular reflex suggest that (i) plasticity is distributed between the cerebellar cortex and the deep cerebellar nuclei; (i) the cerebellar cortex plays a special role in learning the timing of movement; and (i) the cerebellar cortex guides learning in the deep nuclei, which may for movement coordination allow learning to be transferred from the cortex to the deep nuclei. Because many of the similarities in the data from the two systems typify general features of cerebellar organization, the cerebellar mechanisms of learning in these two systems may represent principles that apply to many motor systems.}
}
113 For your convenience, here is the citation including the abstract of the Reed and de Freitas paper that serves as one of the primary inspirations for analyzing execution traces. You might also find convenient these links relating to technologies for analyzing and generating execution traces: software tracing, Unix Kernel function tracers, control flow graph and more conventional data-flow analysis.
@article{ReedandDeFreitasCoRR-15,
author = {Scott E. Reed and Nando de Freitas},
title = {Neural Programmer-Interpreters},
journal = {CoRR},
volume = {arXiv:1511.06279},
year = {2015},
abstract = {We propose the neural programmer-interpreter (NPI): a recurrent and compositional neural network that learns to represent and execute programs. NPI has three learnable components: a task-agnostic recurrent core, a persistent key-value program memory, and domain-specific encoders that enable a single NPI to operate in multiple perceptually diverse environments with distinct affordances. By learning to compose lower-level programs to express higher-level programs, NPI reduces sample complexity and increases generalization ability compared to sequence-to-sequence LSTMs. The program memory allows efficient learning of additional tasks by building on existing programs. NPI can also harness the environment (e.g. a scratch pad with read-write pointers) to cache intermediate results of computation, lessening the long-term memory burden on recurrent hidden units. In this work we train the NPI with fully-supervised execution traces; each program has example sequences of calls to the immediate subprograms conditioned on the input. Rather than training on a huge number of relatively weak labels, NPI learns from a small number of rich examples. We demonstrate the capability of our model to learn several types of compositional programs: addition, sorting, and canonicalizing 3D models. Furthermore, a single NPI learns to execute these programs and all 21 associated subprograms.}
}
114 Here is a relatively simple program written in Emacs Lisp that normalizes BibTeX entries for readability and compatibility with the different Emacs modes that I routinely use in my Emacs environment for coding, writing papers and maintaining the repository that I use for my research notes:
;; bibtex-fill-entry = formats fill according to following parameters which are required by the code below
(defcustom bibtex-align-at-equal-sign t
"If non-nil, align fields at equal sign instead of field text. If non-nil, the
column for the equal sign is the value of `bibtex-text-indentation', minus 2."
:group 'bibtex
:type 'boolean)
(defcustom bibtex-comma-after-last-field t
"If non-nil, a comma is put at end of last field in the entry template."
:group 'bibtex
:type 'boolean)
;; Offsets are based on longest field name, in this case "organization":
(defcustom bibtex-field-indentation 1
"Starting column for the name part in BibTeX fields."
:group 'bibtex
:type 'integer)
(defcustom bibtex-text-indentation
(+ bibtex-field-indentation
(length "organization = "))
"Starting column for the text part in BibTeX fields."
:group 'bibtex
:type 'integer)
(defvar bibtex-field-alignment-adjustments
'([ " author = " " author = " ]
[ " abstract = " " abstract = " ]
[ " address = " " address = " ]
[ " booktitle = " " booktitle = " ]
[ " comment = " " comment = " ]
[ " crossref = " " crossref = " ]
[ " editor = " " editor = " ]
[ " institution = " " institution = " ]
[ " issue = " " issue = " ]
[ " journal = " " journal = " ]
[ " location = " " location = " ]
[ " number = " " number = " ]
[ " organization = " " organization = " ]
[ " pages = " " pages = " ]
[ " pdf = " " pdf = " ]
[ " publisher = " " publisher = " ]
[ " series = " " series = " ]
[ " title = " " title = " ]
[ " school = " " school = " ]
[ " url = " " url = " ]
[ " volume = " " volume = " ]
[ " year = " " year = " ]))
;; /Applications/Emacs.app/Contents/Resources/lisp/textmodes/bibtex.el
(defun bibtex-format-fields-region ()
(interactive)
(bibtex-fill-entry)
(let ((start (bibtex-beginning-of-entry)) (end (bibtex-end-of-entry)))
(untabify start end)
(replace-pairs-region start end bibtex-field-alignment-adjustments)))
(defun replace-pairs-region (p1 p2 pairs)
(let ((mapping-point-seed 1000) index (mapping-points '()))
(setq index 0)
(while (< index (length pairs))
(setq mapping-points (cons (number-to-string (+ mapping-point-seed index)) mapping-points ))
(setq index (1+ index)))
(save-excursion
(save-restriction
(narrow-to-region p1 p2)
;; Replace each find string by corresponding item in mapping-points:
(setq index 0)
(while (< index (length pairs))
(goto-char (point-min))
(while (search-forward (elt (elt pairs index) 0) nil t)
(replace-match (elt mapping-points index) t t) )
(setq index (1+ index)) )
;; Replace each mapping-point by the corresponding replacement string:
(setq index 0)
(while (< index (length pairs))
(goto-char (point-min))
(while (search-forward (elt mapping-points index) nil t)
(replace-match (elt (elt pairs index) 1) t t) )
(setq index (1+ index)))
;; Replace all double quotes used as delimiters with curly brackets:
(goto-char (point-min))
(while (search-forward-regexp "= \"\\([^\"]+\\)\"" nil t) (replace-match "= {\\1}" t nil)) ))))
115 A list of BibTeX items relating to automated or assistive programming research. Gulwani et al [190] on program synthesis — foundations and trends — is added to the mix as it provides some useful background on dinfferent methods of both historical and current interest:
@inproceedings{DongandLapataACL-16,
author = {Li Dong and Mirella Lapata},
title = {Language to Logical Form with Neural Attention},
booktitle = {Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics},
pages = {33-43},
year = {2016},
publisher = {Association for Computational Linguistics},
address = {Stroudsburg, PA, USA},
abstract = {Semantic parsing aims at mapping natural language to machine interpretable meaning representations. Traditional approaches rely on high-quality lexicons, manually-built templates, and linguistic features which are either domain- or representation-specific. In this paper we present a general method based on an attention-enhanced encoder-decoder model. We encode input utterances into vector representations, and generate their logical forms by conditioning the output sequences or trees on the encoding vectors. Experimental results on four datasets show that our approach performs competitively without using hand-engineered features and is easy to adapt across domains and meaning representations.}
}
@article{LuongetalEMNLP-15,
author = {Minh{-}Thang Luong and Hieu Pham and Christopher D. Manning},
title = {Effective Approaches to Attention-based Neural Machine Translation},
booktitle = {Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing},
pages = {1412-1421},
year = {2015},
abstract = {An attentional mechanism has lately been used to improve neural machine translation (NMT) by selectively focusing on parts of the source sentence during translation. However, there has been little work exploring useful architectures for attention-based NMT. This paper examines two simple and effective classes of attentional mechanism: a global approach which always attends to all source words and a local one that only looks at a subset of source words at a time. We demonstrate the effectiveness of both approaches over the WMT translation tasks between English and German in both directions. With local attention, we achieve a significant gain of 5.0 BLEU points over non-attentional systems which already incorporate known techniques such as dropout. Our ensemble model using different attention architectures has established a new state-of-the-art result in the WMT'15 English to German translation task with 25.9 BLEU points, an improvement of 1.0 BLEU points over the existing best system backed by NMT and an n-gram reranker.}
}
@article{GulwanietalFaTiPL-17,
author = {Sumit Gulwani and Oleksandr Polozov and Rishabh Singh},
title = {Program Synthesis},
journal = {Foundations and Trends in Programming Languages},
volume = {4},
number = {1-2},
year = {2017},
pages = {1-119},
abstract = {Program synthesis is the task of automatically finding a program in the underlying programming language that satisfies the user intent expressed in the form of some specification. Since the inception of AI in the 1950s, this problem has been considered the holy grail of Computer Science. Despite inherent challenges in the problem such as ambiguity of user intent and a typically enormous search space of programs, the field of program synthesis has developed many different techniques that enable program synthesis in different real-life application domains. It is now used successfully in software engineering, biological discovery, computeraided education, end-user programming, and data cleaning. In the last decade, several applications of synthesis in the field of programming by examples have been deployed in mass-market industrial products. This survey is a general overview of the state-of-the-art approaches to program synthesis, its applications, and subfields. We discuss the general principles common to all modern synthesis approaches such as syntactic bias, oracle-guided inductive `xbibsearch, and optimization techniques. We then present a literature review covering the four most common state-of-the-art techniques in program synthesis: enumerative search, constraint solving, stochastic search, and deduction-based programming by examples. We conclude with a brief list of future horizons for the field.}
}
@article{GauntetalCoRR-16,
author = {Alexander L. Gaunt and Marc Brockschmidt and Rishabh Singh and Nate Kushman and Pushmeet Kohli and Jonathan Taylor and Daniel Tarlow},
title = {{TerpreT}: {A} Probabilistic Programming Language for Program Induction},
journal = {CoRR},
volume = {arXiv:1612.00817},
year = {2016},
abstract = {We study machine learning formulations of inductive program synthesis; that is, given input-output examples, synthesize source code that maps inputs to corresponding outputs. Our key contribution is TerpreT, a domain-specific language for expressing program synthesis problems. A TerpreT model is composed of a specification of a program representation and an interpreter that describes how programs map inputs to outputs. The inference task is to observe a set of input-output examples and infer the underlying program. From a TerpreT model we automatically perform inference using four different back-ends: gradient descent (thus each TerpreT model can be seen as defining a differentiable interpreter), linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing proper comparisons between different approaches to inference. We illustrate the value of TerpreT by developing several interpreter models and performing an extensive empirical comparison between alternative inference algorithms on a variety of program models. To our knowledge, this is the first work to compare gradient-based search over program space to traditional search-based alternatives. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations.}
}
@article{AnonymousICLR-17,
title = {Neural Program Search: Solving Programming Tasks from Description and Examples},
author = {Anonymous},
journal = {International Conference on Learning Representations},
year = {2017},
url = {https://openreview.net/forum?id=B1KJJf-R-},
abstract = {We present Neural Program Search, an algorithm to generate programs from natural language description and a small number of input / output examples. The algorithm combines methods from Deep Learning and Program Synthesis fields by designing rich domain-specific language (DSL) and defining efficient search algorithm guided by a Seq2Tree model on it. To evaluate the quality of the approach we also present a semi-synthetic dataset of descriptions with test examples and corresponding programs. We show that our algorithm significantly outperforms sequence-to-sequence model with attention baseline.}
}
@article{Alvarez-MelisandJaakkolaCoRR-17,
author = {David Alvarez{-}Melis and Tommi S. Jaakkola},
title = {A causal framework for explaining the predictions of black-box sequence-to-sequence models},
journal = {CoRR},
volume = {arXiv:1707.01943},
year = {2017},
abstract = {We interpret the predictions of any black-box structured input-structured output model around a specific input-output pair. Our method returns an "explanation" consisting of groups of input-output tokens that are causally related. These dependencies are inferred by querying the black-box model with perturbed inputs, generating a graph over tokens from the responses, and solving a partitioning problem to select the most relevant components. We focus the general approach on sequence-to-sequence problems, adopting a variational autoencoder to yield meaningful input perturbations. We test our method across several NLP sequence generation tasks.}
}
@techreport{LinetalUW-CSE-TR-17,
author = {Xi Victoria Lin and Chenglong Wang and Deric Pang and Kevin Vu and Luke Zettlemoyer and Michael D. Ernst},
title = {Program synthesis from natural language using recurrent neural networks},
institution = {University of Washington Department of Computer Science and Engineering},
number = {UW-CSE-17-03-01},
address = {Seattle, WA, USA},
year = {2017},
abstract = {Oftentimes, a programmer may have difficulty implementing a desired operation. Even when the programmer can describe her goal in English, it can be difficult to translate into code. Existing resources, such as question-and-answer websites, tabulate specific operations that someone has wanted to perform in the past, but they are not effective in generalizing to new tasks, to compound tasks that require combining previous questions, or sometimes even to variations of listed tasks. Our goal is to make programming easier and more productive by letting programmers use their own words and concepts to express the intended operation, rather than forcing them to accommodate the machine by memorizing its grammar. We have built a system that lets a programmer describe a desired operation in natural language, then automatically translates it to a programming language for review and approval by the programmer. Our system, Tellina, does the translation using recurrent neural networks (RNNs), a state-of-the-art natural language processing technique that we augmented with slot (argument) filling and other enhancements. We evaluated Tellina in the context of shell scripting. We trained Tellina’s RNNs on textual descriptions of file system operations and bash one-liners, scraped from the web. Although recovering completely correct commands is challenging, Tellina achieves top-3 accuracy of 80\% for producing the correct command structure. In a controlled study, programmers who had access to Tellina outperformed those who did not, even when Tellina’s predictions were not completely correct, to a statistically significant degree.}
}
116 In humans, the cerebellum plays an important role in motor control, and it may also be involved in some cognitive functions such as attention and language as well as in regulating fear and pleasure responses, but its movement-related functions are the most solidly established. The human cerebellum does not initiate movement, but contributes to coordination, precision, and accurate timing: it receives input from sensory systems of the spinal cord and from other parts of the brain, and integrates these inputs to fine-tune motor activity. (SOURCE)
117 Here is an assortment of papers that use semantic-embedding techniques to encode computer programs for a variety of applications:
@inproceedings{ChistyakovetalICLR-17,
author = {Alexander Chistyakov and Ekaterina Lobacheva and Arseny Kuznetsov and Alexey Romanenko},
title = {Semantic embeddings for program behaviour patterns},
booktitle = {ICLR Workshop},
year = {2017},
abstract = {In this paper, we propose a new feature extraction technique for program execution logs. First, we automatically extract complex patterns from a program's behaviour graph. Then, we embed these patterns into a continuous space by training an autoencoder. We evaluate the proposed features on a real-world malicious software detection task. We also find that the embedding space captures interpretable structures in the space of pattern parts.}
}
@article{WangetalCoRR-17,
author = {Ke Wang and Rishabh Singh and Zhendong Su},
title = {Dynamic Neural Program Embedding for Program Repair},
journal = {CoRR},
volume = {arXiv:1711.07163},
year = {2017},
abstract = {Neural program embeddings have shown much promise recently for a variety of program analysis tasks, including program synthesis, program repair, fault localization, etc. However, most existing program embeddings are based on syntactic features of programs, such as raw token sequences or abstract syntax trees. Unlike images and text, a program has an unambiguous semantic meaning that can be difficult to capture by only considering its syntax (i.e. syntactically similar pro- grams can exhibit vastly different run-time behavior), which makes syntax-based program embeddings fundamentally limited. This paper proposes a novel semantic program embedding that is learned from program execution traces. Our key insight is that program states expressed as sequential tuples of live variable values not only captures program semantics more precisely, but also offer a more natural fit for Recurrent Neural Networks to model. We evaluate different syntactic and semantic program embeddings on predicting the types of errors that students make in their submissions to an introductory programming class and two exercises on the CodeHunt education platform. Evaluation results show that our new semantic program embedding significantly outperforms the syntactic program embeddings based on token sequences and abstract syntax trees. In addition, we augment a search-based program repair system with the predictions obtained from our se- mantic embedding, and show that search efficiency is also significantly improved.}
}
@article{XuetalCoRR-17,
author = {Xiaojun Xu and Chang Liu and Qian Feng and Heng Yin and Le Song and Dawn Song},
title = {Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection},
journal = {CoRR},
volume = {arXiv:1708.06525},
year = {2017},
abstract = {The problem of cross-platform binary code similarity detection aims at detecting whether two binary functions coming from different platforms are similar or not. It has many security applications, including plagiarism detection, malware detection, vulnerability search, etc. Existing approaches rely on approximate graph matching algorithms, which are inevitably slow and sometimes inaccurate, and hard to adapt to a new task. To address these issues, in this work, we propose a novel neural network-based approach to compute the embedding, i.e., a numeric vector, based on the control flow graph of each binary function, then the similarity detection can be done efficiently by measuring the distance between the embeddings for two functions. We implement a prototype called Gemini. Our extensive evaluation shows that Gemini outperforms the state-of-the-art approaches by large margins with respect to similarity detection accuracy. Further, Gemini can speed up prior art's embedding generation time by 3 to 4 orders of magnitude and reduce the required training time from more than 1 week down to 30 minutes to 10 hours. Our real world case studies demonstrate that Gemini can identify significantly more vulnerable firmware images than the state-of-the-art, i.e., Genius. Our research showcases a successful application of deep learning on computer security problems.}
}
@article{PiechetalCoRR-15,
author = {Chris Piech and Jonathan Huang and Andy Nguyen and Mike Phulsuksombati and Mehran Sahami and Leonidas J. Guibas},
title = {Learning Program Embeddings to Propagate Feedback on Student Code},
journal = {CoRR},
volume = {arXiv:1505.05969},
year = {2015},
abstract = {Providing feedback, both assessing final work and giving hints to stuck students, is difficult for open-ended assignments in massive online classes which can range from thousands to millions of students. We introduce a neural network method to encode programs as a linear mapping from an embedded precondition space to an embedded postcondition space and propose an algorithm for feedback at scale using these linear maps as features. We apply our algorithm to assessments from the Code.org Hour of Code and Stanford University's CS1 course, where we propagate human comments on student assignments to orders of magnitude more submissions.}
}
@inproceedings{BalogetalICLR-17,
author = {Matej Balog and Alexander L. Gaunt and Marc Brockschmidt and Sebastian Nowozin and Daniel Tarlow},
title = {DeepCoder: Learning to Write Programs},
booktitle = {International Conference on Learning Representations},
year = 2017,
abstract = {We develop a first line of attack for solving programming competition-style problems from input-output examples using deep learning. The approach is to train a neural network to predict properties of the program that generated the outputs from the inputs. We use the neural network's predictions to augment search techniques from the programming languages community, including enumerative search and an SMT-based solver. Empirically, we show that our approach leads to an order of magnitude speedup over the strong non-augmented baselines and a Recurrent Neural Network approach, and that we are able to solve problems of difficulty comparable to the simplest problems on programming competition websites.}
}
@article{AllamanisetalCoRR-17,
author = {Miltiadis Allamanis and Marc Brockschmidt and Mahmoud Khademi},
title = {Learning to Represent Programs with Graphs},
journal = {CoRR},
volume = {arXiv:1711.00740},
year = {2017},
abstract = {Learning tasks on source code (i.e., formal languages) have been considered recently, but most work has tried to transfer natural language methods and does not capitalize on the unique opportunities offered by code's known syntax. For example, long-range dependencies induced by using the same variable or function in distant locations are often not considered. We propose to use graphs to represent both the syntactic and semantic structure of code and use graph-based deep learning methods to learn to reason over program structures.\\
In this work, we present how to construct graphs from source code and how to scale Gated Graph Neural Networks training to such large graphs. We evaluate our method on two tasks: VarNaming, in which a network attempts to predict the name of a variable given its usage, and VarMisuse, in which the network learns to reason about selecting the correct variable that should be used at a given program location. Our comparison to methods that use less structured program representations shows the advantages of modeling known structure, and suggests that our models learn to infer meaningful names and to solve the VarMisuse task in many cases. Additionally, our testing showed that VarMisuse identifies a number of bugs in mature open-source projects.}
}
118 Here's the BibTeX entry for a recent survey paper Gulwanietal [190] on current trends in program synthesis that Rishabh Singh co-authored:
@article{GulwanietalFaTiPL-17,
author = {Sumit Gulwani and Oleksandr Polozov and Rishabh Singh},
title = {Program Synthesis},
journal = {Foundations and Trends in Programming Languages},
volume = {4},
number = {1-2},
year = {2017},
pages = {1-119},
abstract = {Program synthesis is the task of automatically finding a program in the underlying programming language that satisfies the user intent expressed in the form of some specification. Since the inception of AI in the 1950s, this problem has been considered the holy grail of Computer Science. Despite inherent challenges in the problem such as ambiguity of user intent and a typically enormous search space of programs, the field of program synthesis has developed many different techniques that enable program synthesis in different real-life application domains. It is now used successfully in software engineering, biological discovery, computer-aided education, end-user programming, and data cleaning. In the last decade, several applications of synthesis in the field of programming by examples have been deployed in mass-market industrial products. This survey is a general overview of the state-of-the-art approaches to program synthesis, its applications, and subfields. We discuss the general principles common to all modern synthesis approaches such as syntactic bias, oracle-guided inductive search, and optimization techniques. We then present a literature review covering the four most common state-of-the-art techniques in program synthesis: enumerative search, constraint solving, stochastic search, and deduction-based programming by examples. We conclude with a brief list of future horizons for the field.}
}
119 Collection of papers relating to the role of the cerebellum and basal ganglia in language, planning and simulating complex activity:
@book{Lieberman02,
author = {Philip Lieberman},
title = {Human language and our reptilian brain: The subcortical bases for speech, syntax and thought},
publisher = {Harvard University Press},
address = {Cambridge, MA},
year = 2002,
}
@article{LiebermanAJPT-02,
author = {Philip Lieberman},
title = {On the nature and evolution of the neural bases of human language},
Journal = {American Journal of Physical Anthropology},
month = {December},
volume = 119,
issue = {S35},
pages = {36-62},
year = 2002,
abstract = {The traditional theory equating the brain bases of language with Broca's and Wernicke's neocortical areas is wrong. Neural circuits linking activity in anatomically segregated populations of neurons in subcortical structures and the neocortex throughout the human brain regulate complex behaviors such as walking, talking, and comprehending the meaning of sentences. When we hear or read a word, neural structures involved in the perception or real-world associations of the word are activated as well as posterior cortical regions adjacent to Wernicke's area. Many areas of the neocortex and subcortical structures support the cortical-striatal-cortical circuits that confer complex syntactic ability, speech production, and a large vocabulary. However, many of these structures also form part of the neural circuits regulating other aspects of behavior. For example, the basal ganglia, which regulate motor control, are also crucial elements in the circuits that confer human linguistic ability and abstract reasoning. The cerebellum, traditionally associated with motor control, is active in motor learning. The basal ganglia are also key elements in reward-based learning. Data from studies of Broca's aphasia, Parkinson's disease, hypoxia, focal brain damage, and a genetically transmitted brain anomaly (the putative ``language gene,'' family KE), and from comparative studies of the brains and behavior of other species, demonstrate that the basal ganglia sequence the discrete elements that constitute a complete motor act, syntactic process, or thought process. Imaging studies of intact human subjects and electrophysiologic and tracer studies of the brains and behavior of other species confirm these findings. As Dobzansky put it, ``Nothing in biology makes sense except in the light of evolution'' (cited in Mayr, 1982). That applies with as much force to the human brain and the neural bases of language as it does to the human foot or jaw. The converse follows: the mark of evolution on the brains of human beings and other species provides insight into the evolution of the brain bases of human language. The neural substrate that regulated motor control in the common ancestor of apes and humans most likely was modified to enhance cognitive and linguistic ability. Speech communication played a central role in this process. However, the process that ultimately resulted in the human brain may have started when our earliest hominid ancestors began to walk.},
}
@article{MerkerBBS-07,
author = {Merker, Bjorn},
title = {Consciousness without a cerebral cortex: A challenge for neuroscience and medicine},
journal = {Behavioral and Brain Sciences},
publisher = {Cambridge University Press},
volume = {30},
number = {1},
year = {2007},
pages = {63–81},
abstract = {A broad range of evidence regarding the functional organization of the vertebrate brain - spanning from comparative neurology to experimental psychology and neurophysiology to clinical data - is reviewed for its bearing on conceptions of the neural organization of consciousness. A novel principle relating target selection, action selection, and motivation to one another, as a means to optimize integration for action in real time, is introduced. With its help, the principal macrosystems of the vertebrate brain can be seen to form a centralized functional design in which an upper brain stem system organized for conscious function performs a penultimate step in action control. This upper brain stem system retained a key role throughout the evolutionary process by which an expanding forebrain - culminating in the cerebral cortex of mammals - came to serve as a medium for the elaboration of conscious contents. This highly conserved upper brainstem system, which extends from the roof of the midbrain to the basal diencephalon, integrates the massively parallel and distributed information capacity of the cerebral hemispheres into the limited-capacity, sequential mode of operation required for coherent behavior. It maintains special connective relations with cortical territories implicated in attentional and conscious functions, but is not rendered nonfunctional in the absence of cortical input. This helps explain the purposive, goal-directed behavior exhibited by mammals after experimental decortication, as well as the evidence that children born without a cortex are conscious. Taken together these circumstances suggest that brainstem mechanisms are integral to the constitution of the conscious state, and that an adequate account of neural mechanisms of conscious function cannot be confined to the thalamocortical complex alone.}
}
@article{NottebohmPLoS-05,
author = {Nottebohm, Fernando},
journal = {{PLOS} Biology},
publisher = {Public Library of Science},
title = {The Neural Basis of Birdsong},
year = {2005},
volume = {3},
abstract = {There is a tradition in biology of using specific animal models to study generalizable basic properties of a system. For example, the giant axon of squid was used for the pioneering work on nerve transmission; the fruit fly (Drosophila) has played a key role in researchers discovering the role of homeobox genes in embryogenesis; the sea slug (Aplysia) is used to study the molecular biology of learning; and the round worm (Caenorhabditis elegans) is used to study programmed cell death. Basic insights gained from these four systems apply widely to other multicellular animals. Here, I will review basic discoveries made by studying birdsong that have helped answer more general questions in vertebrate neuroscience.},
}
@misc{PattaniBRAINLESS-16,
title = {Preliminary Research -- Living Without Brain Structures},
author = {Aneri Pattani},
year = {2016},
howpublished = {StoryLab Posting},
url = {http://www.northeastern.edu/storylab/sp16/2016/01/27/preliminary-research-living-without-brain-structures/},
abstract = {How much of our brain do we actually need? A number of stories have appeared in the news in recent months about people with chunks of their brains missing or damaged. These cases tell a story about the mind that goes deeper than their initial shock factor. It isn't just that we don't understand how the brain works, but that we may be thinking about it in the entirely wrong way.}
}
@article{Stephenson-JonesetalCURRENT-BIOLOGY-11,
author = {Stephenson-Jones, M. and Samuelsson, E. and Ericsson, J. and Robertson, B. and Grillner, S.},
title = {Evolutionary conservation of the basal ganglia as a common vertebrate mechanism for action selection},
journal = {Current Biology},
year = {2011},
volume = {21},
number = {13},
pages = {1081-1091},
abstract = {Although the basal ganglia are thought to play a key role in action selection in mammals, it is unknown whether this mammalian circuitry is present in lower vertebrates as a conserved selection mechanism. We aim here, using lamprey, to elucidate the basal ganglia circuitry in the phylogenetically oldest group of vertebrates (cyclostomes) and determine how this selection architecture evolved to accommodate the increased behavioral repertoires of advanced vertebrates.\\ We show, using immunohistochemistry, tract tracing, and whole-cell recordings, that all parts of the mammalian basal ganglia (striatum, globus pallidus interna [GPi] and externa [GPe], and subthalamic nucleus [STN]) are present in the lamprey forebrain. In addition, the circuit features, molecular markers, and physiological activity patterns are conserved. Thus, GABAergic striatal neurons expressing substance P project directly to the pallidal output layer, whereas enkephalin-expressing striatal neurons project indirectly via nuclei homologous to the GPe and STN. Moreover, pallidal output neurons tonically inhibit tectum, mesencephalic, and diencephalic motor regions.\\ These results show that the detailed basal ganglia circuitry is present in the phylogenetically oldest vertebrates and has been conserved, most likely as a mechanism for action selection used by all vertebrates, for over 560 million years. Our data also suggest that the mammalian basal ganglia evolved through a process of exaptation, where the ancestral core unit has been co-opted for multiple functions, allowing them to process cognitive, emotional, and motor information in parallel and control a broader range of behaviors.}
}
120 The field of automated planning in AI in the 80's was often criticized for focusing on toy problems such as the blocks world. The criticism was leveled by disciplines like operations research and applied control theory that spanned a wide range of real-world problems including inventory management, vehicle routing, chemical process control and robotic assembly, whereas the blocks world was so general it could be used to solve any — AI Complete and NP-hard — symbolic problem.
121 In a recent discussion, Christof mentioned that AIBS scientists regularly work with both mouse and human samples of neural tissue and that, apart from their size, the cortical tissue from mice and humans are virtually identical to trained anatomists and histologists. This makes him wonder whether mice would develop, say, consciousness or more sophisticated signaling if they had a cortex as large as ours. As far as we know, there is nothing special about spindle / von Economo neurons or the elusive mirror neurons, except that the — the former — are larger and are noteworthy for their size and location. Simple neural network architectures including convolutional networks work efficiently to learn structure, induce sparse feature libraries, construct concept hierarchies, and can even learn value functions to support reinforcement learning and attentional mechanisms.
122 This is another example of progress primarily due to improvements in computing hardware. The basic idea gets invented a dozen times and never gains a purchase until Moore’s law catches up enabling lots of researchers to essentially “play” in the conceptual space that opens up due to the confluence of a good idea and adequate computing resources. It's not just the length of time that an engineer has to sit on his or her hands waiting while some mysterious process plays out over an indeterminate interval of time and, at the end, provides an inscrutable and generally unsatisfying answer, it's the anxiety, frustration and helplessness that this induces in the engineer. When you can launch millions of experiments and get millions of answers in the same or a shorter amount of time, everything changes. An anomaly in the result of your only experiment is a problem, while an anomaly in one result out of millions is an outlier or a bug in your experimental design.
123 Here is a sample of recent review papers relating to the idea of dual-loop models that integrate sensorimotor maps with semantic processing:
@incollection{WeilleretalNL-16,
author = {Cornelius Weiller and Tobias Bormann and Dorothee Kuemmerer and Mariachristina Musso and Michel Rijntjes},
title = {The Dual Loop Model in Language},
editor = {Hickok, Gregory and Small, Steven L.},
booktitle = {Neurobiology of Language},
publisher = {Academic Press},
address = {San Diego},
year = {2016},
pages = {325-337},
abstract = {A dual loop model for the processing of language in the brain was proposed early in history and has also formed the basis for many neuropsychological models. These models incorporate a (direct) route for sensorimotor mapping and a (indirect) route for "semantic" processing. Dual loop models also emerged in the field of visual processing, motor control, or spatial attention. Thus, a general dual loop system may provide the framework for the interpretation of cognition in human and primate brains independent of the modality and species. Modern imaging techniques like diffusion tensor imaging (DTI)-based fiber tracking identified long human association tracts for ventral and dorsal pathways. The extreme capsule (EmC) and uncinate fascicle (UF) are part of the ventral system, and the superior longitudinal fasciculi (SLF I, II, III) and the arcuate fasciculus (AF) are all dorsal pathways. This chapter reviews language processing in the brain in the context of a domain general dual loop system.}
}
@incollection{RizzolattiandRozziNL-16,
author = {Giacomo Rizzolatti and Stefano Rozzi},
title = {Motor Cortex and Mirror System in Monkeys and Humans},
editor = {Hickok, Gregory and Small, Steven L.},
booktitle = {Neurobiology of Language},
publisher = {Academic Press},
address = {San Diego},
year = {2016},
pages = {59-72},
abstract = {The view of the functions of the motor system has radically changed in past years. It is now clear that the motor system not only is a "producer" of movements but also is involved in cognitive functions. In this chapter we review the anatomical and functional organization of the cortical motor system in monkeys and humans with particular emphasis on those areas that are endowed of the mirror mechanism and involved in communication. We discuss the possible evolutionary link between basic unintentional communication and voluntary communication. We conclude examining the hypothesis that purports that motor activation is involved in phonemes and understanding of action words.}
}
@article{HamzeietalCC-16,
author = {Hamzei, Farsin and Vry, Magnus-Sebastian and Saur, Dorothee and Glauche, Volkmar and Hoeren, Markus and Mader, Irina and Weiller, Cornelius and Rijntjes, Michel},
title = {The Dual-Loop Model and the Human Mirror Neuron System: an Exploratory Combined fMRI and DTI Study of the Inferior Frontal Gyrus},
journal = {Cerebral Cortex},
volume = {26},
number = {5},
pages = {2215-2224},
year = {2016},
abstract = {The inferior frontal gyrus (IFG) is active during both goal-directed action and while observing the same motor act, leading to the idea that also the meaning of a motor act (action understanding) is represented in this "mirror neuron system" (MNS). However, in the dual-loop model, based on dorsal and ventral visual streams, the MNS is thought to be a function of the dorsal steam, projecting to pars opercularis (BA44) of IFG, while recent studies suggest that conceptual meaning and semantic analysis are a function of ventral connections, projecting mainly to pars triangularis (BA45) of IFG. To resolve this discrepancy, we investigated action observation (AO) and imitation (IMI) using fMRI in a large group of subjects. A grasping task (GR) assessed the contribution from movement without AO. We analyzed connections of the MNS-related areas within IFG with postrolandic areas with the use of activation-based DTI. We found that action observation with imitation are mainly a function of the dorsal stream centered on dorsal part of BA44, but also involve BA45, which is dorsally and ventrally connected to the same postrolandic regions. The current finding suggests that BA45 is the crucial part where the MNS and the dual-loop system interact.}
}
@article{RijntjesetalFiEN-12,
author = {Rijntjes, Michel and Weiller, Cornelius and Bormann, Tobias and Musso, Mariachristina},
title = {The dual loop model: its relation to language and other modalities},
journal = {Frontiers in Evolutionary Neuroscience},
volume = {4},
pages = {9},
year = {2012},
abstract = {The current neurobiological consensus of a general dual-loop system scaffolding human and primate brains gives evidence that the dorsal and ventral connections subserve similar functions, independent of the modality and species. However, most current commentators agree that, although bees dance and chimpanzees grunt, these systems of communication differ qualitatively from human language. So why is language in humans unique? We discuss anatomical differences between humans and other animals, the meaning of lesion studies in patients, the role of inner speech, and compare functional imaging studies in language with other modalities in respect to the dual loop model. These aspects might be helpful for understanding what kind of biological system the language faculty is, and how it relates to other systems in our own species and others.}
}
%
124 Examples of qualia include the perceived sensation of pain of a headache, the taste of wine, as well as the redness of an evening sky. As qualitative characters of sensation, qualia stand in contrast to "propositional attitudes", where the focus is on beliefs about experience rather than what is it directly like to be experiencing. (SOURCE)
125 Natural language programming (NLP) is an ontology-assisted way of programming in terms of natural language sentences, e.g. English. A structured document with Content, sections and subsections for explanations of sentences forms a NLP document, which is actually a computer program. Natural languages and natural language user interfaces include Inform7, a natural programming language for making interactive fiction, Ring, a general purpose language, Shakespeare, an esoteric natural programming language in the style of the plays of William Shakespeare, and Wolfram Alpha, a computational knowledge engine, using natural language input. The smallest unit of statement in NLP is a sentence. Each sentence is stated in terms of concepts from the underlying ontology, attributes in that ontology and named objects in capital letters. In an NLP text every sentence unambiguously compiles into a procedure call in the underlying high-level programming language such as MATLAB, Octave, SciLab, Python, etc. (SOURCE)
126 Here are the BibTeX references and abstracts for several papers on using natural language to write programs:
@book{Veres2008,
title = {{Natural Language Programming of Agents and Robotic Devices: Publishing for agents and humans in sEnglish}},
author = {S\'{a}ndor M. Veres},
publisher = {SysBrain Ltd},
address = {London},
year = {2008},
abstract = {This paper is an application of ontology theory, conceptual graphs and programming language theories to develop the theoretical foundations of natural language programming (NLP) that has in recent years been used to produce natural language documents for intelligent agents and human readers. The analysis given reveals three benefits of NLP. First, it is “conceptualized” programming that enables developers to write less bug prone programs due to clarity of code presentation and enforced structuring of data. Secondly, NLP can aid programming of the all important abstractions for robots: event, action and world model abstractions can be created by sentences. Thirdly, NLP can be used to publish natural language documents by researchers, i.e. English language documents on control theory and procedures, on the Internet or in printed documents. This theoretical paper also defines a large class of intelligent agents that can read such documents. This enables human users and agents to have shared understanding of how application systems work.}
}
@inproceedings{LeietalACL-13,
author = {Tao Lei, Fan Long, Regina Barzilay and Martin Rinard},
title = {From Natural Language Specifications to Program Input Parsers},
booktitle = {The 51st Annual Meeting of the Association for Computational Linguistics},
location = {Sofia, Bulgaria},
year = {2013},
abstract = {We present a method for automatically generating input parsers from English specifications of input file formats. We use a Bayesian generative model to capture relevant natural language phenomena and translate the English specification into a specification tree, which is then translated into a C++ input parser. We model the problem as a joint dependency parsing and semantic role labeling task. Our method is based on two sources of information: (1) the correlation between the text and the specification tree and (2) noisy supervision as determined by the success of the generated C++ parser in reading input examples. Our results show that our approach achieves 80.0\% F-Score accuracy compared to an F-Score of 66.7\% produced by a state-of-the-art semantic parser on a dataset of input format speci- fications from the ACM International Collegiate Programming Contest (which were written in English for humans with no intention of providing support for automated processing).}
}
@article{LocascioetalCoRR-16,
author = {Nicholas Locascio and Karthik Narasimhan and Eduardo DeLeon and Nate Kushman and Regina Barzilay},
title = {Neural Generation of Regular Expressions from Natural Language with Minimal Domain Knowledge},
journal = {CoRR},
volume = {arxiv:1608.03000},
year = {2016},
abstract = {This paper explores the task of translating natural language queries into regular expressions which embody their meaning. In contrast to prior work, the proposed neural model does not utilize domain-specific crafting, learning to translate directly from a parallel corpus. To fully explore the potential of neural models, we propose a methodology for collecting a large corpus of regular expression, natural language pairs. Our resulting model achieves a performance gain of 19.6\% over previous state-of-the-art models.}
}
@inproceedings{KushmanandBarzilayACL-13,
author = {Kushman, Nate and Barzilay, Regina},
title = {Using Semantic Unification to Generate Regular Expressions from Natural Language},
booktitle = {Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
year = {2013},
publisher = {Association for Computational Linguistics},
pages = {826-836},
location = {Atlanta, Georgia},
abstract = {We consider the problem of translating natural language text queries into regular expressions which represent their meaning. The mismatch in the level of abstraction between the natural language representation and the regular expression representation make this a novel and challenging problem. However, a given regular expression can be written in many semantically equivalent forms, and we exploit this flexibility to facilitate translation by finding a form which more directly corresponds to the natural language. We evaluate our technique on a set of natural language queries and their associated regular expressions which we gathered from Amazon Mechanical Turk. Our model substantially outperforms a stateof-the-art semantic parsing baseline, yielding a 29\% absolute improvement in accuracy}
}
@inproceedings{ErnstSNAPL-17,
author = {Michael D. Ernst},
title = {Natural language is a programming language: Applying natural language processing to software development},
booktitle = {{SNAPL 2017: the 2nd Summit oN Advances in Programming Languages}},
pages = {4:1-4:14},
address = {Asilomar, CA, USA},
year = {2017},
abstract = {A powerful, but limited, way to view software is as source code alone. Treating a program as a sequence of instructions enables it to be formalized and makes it amenable to mathematical techniques such as abstract interpretation and model checking. A program consists of much more than a sequence of instructions. Developers make use of test cases, documentation, variable names, program structure, the version control repository, and more. I argue that it is time to take the blinders off of software analysis tools: tools should use all these artifacts to deduce more powerful and useful information about the program. Researchers are beginning to make progress towards this vision. This paper gives, as examples, four results that find bugs and generate code by applying natural language processing techniques to software artifacts. The four techniques use as input error messages, variable names, procedure documentation, and user questions. They use four different NLP techniques: document similarity, word semantics, parse trees, and neural networks. The initial results suggest that this is a promising avenue for future work.},
}
127 Our current best guess for the beginning of life on Earth is 3.8 billion years ago. The oldest fossils of single-celled organisms date from about about 3.5 billion years ago. Viruses are present by 3 billion years ago, but may be as old as life itself. Oxygen from photosynthetic cyanobacteria starts to build up in the atmosphere around 2.4 billion years ago. Eukaryotic cells with internal organelles come into being 2.0 billion years ago. The eukaryotes divide into three groups: the ancestors of modern plants, fungi and animals 1.5 billion years ago. The first multicellular life develops around 900 million years ago, and the fossil evidence shows that animals were exploring the land by 500 million years ago. Humans diverge from their closest relatives, the chimpanzees and bonobos around 6 million years ago. (SOURCE)
128 Andrew Ng, one of the cofounders of the Google Brain project, will be the new chairman of Woebot, a company that operates a chatbot of the same name.
The bot is designed to help people work on their own mental health issues using techniques that originate with cognitive behavioral therapy. It’s a sort of therapy that focuses on helping people manage their moods by developing personal coping strategies for mental illnesses like depression and anxiety.
A study from Stanford University showed that people who used Woebot reported a decrease in anxiety and depression symptoms after two weeks. Ng thinks that machine learning could provide a massive benefit in the mental health space, which is why he’s going to be working with Woebot.
For example, Woebot is available to talk when people are having problems at odd hours, during times when a therapist might not be awake to take a phone call. And while it’s not a replacement for a human therapist (the bot is quite clear about that), it can help augment human therapies by giving people an easier way to externalize their thoughts if nobody else is available.
Ng said in an interview that he’s still going to be working on other projects. His role at Woebot will be to serve on the company’s board and provide support for its work, not take on a full-time job at the startup. For example, he’s still working on finishing up his series of deep learning courses for Coursera, the online learning site that he cofounded.
Health care is one of the focuses of his current work, after leaving his post as Baidu’s head of machine learning. Earlier this year, a team at Stanford that he worked with released a paper showing that they had trained a machine learning system to read electrocardiograms better than a cardiologist could. (SOURCE)
129 Defined concisely here as "awareness of an external object or something within oneself", and, with some additional detail and hyperbole by Schneider and Velmans [383] as "[a]nything that we are aware of at a given moment forms part of our consciousness, making conscious experience at once the most familiar and most mysterious aspect of our lives".
130 This proposal is based on a regularization term which encourages the top-level representation (meant to be at the most abstract level) to be such that when a sparse attention mechanism focuses on a few elements of the state representation (factors, variables or concepts, i.e. a few axes or dimensions in the representation space), that small set of variables of which the agent is aware at a given moment can be combined to make a useful statement about reality or usefully condition an action or policy [38].
131 By way of comparison, The IBM TrueNorth chip contains 4,096 cores and 5.4 million transistors, while only drawing 70 milliwatts of power. The chip simulates a million neurons and 256 million synapses. TrueNorth is (very) roughly able to simulate the equivalent of a bee's brain. In contrast to the IBM and Intel focus on hardware, Qualcomm's Zeroth is a platform for brain-inspired computing from Qualcomm. It is based around a — thus far vaporware — neural processing unit (NPU) AI accelerator chip and a software API to interact with the platform. It is advertised as making deep learning available to mobile devices. The software operates locally rather than as a cloud application.
132 This 2012 article in Science Daily suggests that scientists now know how humans solve the cocktail party problem: "In the experiments, patients listened to two speech samples played to them simultaneously in which different phrases were spoken by different speakers. They were asked to identify the words they heard spoken by one of the two speakers.
The authors then applied new decoding methods to "reconstruct" what the subjects heard from analyzing their brain activity patterns. Strikingly, the authors found that neural responses in the auditory cortex only reflected those of the targeted speaker. They found that their decoding algorithm could predict which speaker and even what specific words the subject was listening to based on those neural patterns. In other words, they could tell when the listener's attention strayed to another speaker.
The authors claim that the algorithm worked so well that they could predict not only the correct responses, but also determine when the patients paid attention to the wrong word. [...] The new findings suggest that the representation of speech in the cortex does not just reflect the entire external acoustic environment but instead just what we really want or need to hear." — Nima Mesgarani, Edward F. Chang. Selective cortical representation of attended speaker in multi-talker speech perception. Nature, 2012.
133 Application of their work 3D covolutional networks trained for action recognition [193]:
@article{GyglietalCoRR-17,
title = {Deep Value Networks Learn to Evaluate and Iteratively Refine Structured Outputs},
author = {Michael Gygli and Mohammad Norouzi and Anelia Angelova},
journal = {CoRR},
volume = {arXiv:1703.04363},
year = {2017},
abstract = {We approach structured output prediction by optimizing a deep value network (DVN) to precisely estimate the task loss on different output configurations for a given input. Once the model is trained, we perform inference by gradient descent on the continuous relaxations of the output variables to find outputs with promising scores from the value network. When applied to image segmentation, the value network takes an image and a segmentation mask as inputs and predicts a scalar estimating the intersection over union between the input and ground truth masks. For multi-label classification, the DVN’s objective is to correctly predict the F1 score for any potential label configuration. The DVN framework achieves the state-of-the-art results on multi-label prediction and image segmentation benchmarks.}
}
134 By introducing the term cognitive apparatus I'm probably being too cautious here. The word "mind" seems pretentious and somewhat presumptive. "Brain" is close but I'm not sure that I want to divide up the autonomic (sympathetic and parasympathetic) and somatic (sensory and motor) nervous system along traditional lines.
135 It takes an effort for me to listen to David Chalmers (EDGE) on augmented reality, consciousness or virtual worlds; Nick Bostrom (BIO) on what the chances are we are already living in a virtual world; Jaron Lanier on the myth of AI (EDGE). I'm only now learning to really listen carefully.
Historically, I've disagreed with all three of these philosophy / culture mavens, but we are always always stumbling on interesting lectures and interviews, and, while there are only so many minutes in a day, you could do worse than listen to a smart, thoughtful person talking about a subject he or she has spent a lifetime studying ... even if you disagree with a lot of what they say or the way in which they say it. Here's a suggestion: never actually look at the person when they're speaking and preferably avoid looking at them altogether, before, during or after their speaking. If you think appearances don't matter; think again.
Hidden biases arise from any number of factors besides physical appearance. It's not just whether you are male or female, young or old, your skin tone, race, religion, social standing, voice, etc. Humans instinctively and incorrectly believe that these characteristics tell you a lot about the person, their beliefs, the credence they attach to their claims, the strength of their conviction, the depth of their knowledge regarding whatever subject they are expostulating about, ... expose any of the markers we are programmed to believe reveal these character traits and you have been framed and your audience is now anchored in Kahneman and Tversky's sense of those terms.
136 Imagine if you had a Fender Stratocaster physically integrated into your body. You need not be limited to six fingers and two hands but if we were to limit ourselves to a traditional Stratocaster with six strings, perhaps the most useful extension would be if you could press any six string-fret combinations on the fret-board as long as there was at most one combination per string.
You might have similar flexibility in picking with the other hand resulting in a level of dexterity that would put Chet Atkins and Jimi Hendrix to shame. The integration of a wah-wah pedal and tremolo bar could be controlled by twisting your torso or turning your head and you could control a room full of special-effects simply by directing your gaze at the icons in an image of a fully equipped studio sound-stage projected on your retina.
137 Here are the BibTeX citations and abstracts from the three papers on learning how to write programs mentioned in the text [26, 25, 291]:
@inproceedings{LongandMartinICSE-16,
author = {Long, Fan and Rinard, Martin},
title = {An Analysis of the Search Spaces for Generate and Validate Patch Generation Systems},
booktitle = {Proceedings of the 38th International Conference on Software Engineering},
location = {Austin, Texas},
publisher = {ACM},
address = {New York, NY, USA},
year = {2016},
pages = {702-713},
abstract = {We present the first systematic analysis of key characteristics of patch search spaces for automatic patch generation systems. We analyze sixteen different configurations of the patch search spaces of SPR and Prophet, two current state-of-the-art patch generation systems. The analysis shows that (i) correct patches are sparse in the search spaces (typically at most one correct patch per search space per defect), (ii) incorrect patches that nevertheless pass all of the test cases in the validation test suite are typically orders of magnitude more abundant, and (iii) leveraging information other than the test suite is therefore critical for enabling the system to successfully isolate correct patches.}
}
@inproceedings{BalogetalICLR-17,
author = {Matej Balog and Alexander L. Gaunt and Marc Brockschmidt and Sebastian Nowozin and Daniel Tarlow},
title = {{DeepCoder}: Learning to Write Programs},
booktitle = {International Conference on Learning Representations},
year = 2017,
abstract = {We develop a first line of attack for solving programming competition-style problems from input-output examples using deep learning. The approach is to train a neural network to predict properties of the program that generated the outputs from the inputs. We use the neural network's predictions to augment search techniques from the programming languages community, including enumerative search and an SMT-based solver. Empirically, we show that our approach leads to an order of magnitude speedup over the strong non-augmented baselines and a Recurrent Neural Network approach, and that we are able to solve problems of difficulty comparable to the simplest problems on programming competition websites.}
}
138 Here are the BibTeX citations and abstracts from three papers on the biology, psychology and related technology for theory-of-mind (ToM) reasoning [359, 51, 288, 134]:
@inbook{PynadathetalCAGI-14,
author = {Pynadath, David V. and Rosenbloom, Paul S. and Marsella, Stacy C.},
editor = {Goertzel, Ben and Orseau, Laurent and Snaider, Javier},
title = {Reinforcement Learning for Adaptive Theory of Mind in the Sigma Cognitive Architecture},
booktitle = {Proceedings of Artificial General Intelligence: 7th International Conference},
publisher = {Springer International Publishing},
year = {2014},
pages = {143-154},
abstract = {One of the most common applications of human intelligence is social interaction, where people must make effective decisions despite uncertainty about the potential behavior of others around them. Reinforcement learning (RL) provides one method for agents to acquire knowledge about such interactions. We investigate different methods of multiagent reinforcement learning within the Sigma cognitive architecture. We leverage Sigma's architectural mechanism for gradient descent to realize four different approaches to multiagent learning: (1) with no explicit model of the other agent, (2) with a model of the other agent as following an unknown stationary policy, (3) with prior knowledge of the other agent's possible reward functions, and (4) through inverse reinforcement learning (IRL) of the other agent's reward function. While the first three variations re-create existing approaches from the literature, the fourth represents a novel combination of RL and IRL for social decision-making. We show how all four styles of adaptive Theory of Mind are realized through Sigma's same gradient descent algorithm, and we illustrate their behavior within an abstract negotiation task.},
}
@article{BowmanetalDS-12,
author = {Bowman, L. C. and Liu, D. and Meltzoff, A. N. and Wellman, H. M.},
title = {Neural correlates of belief- and desire-reasoning in 7- and 8-year-old children: an event-related potential study},
journal = {Development Science},
volume = {15},
number = {5},
year = {2012},
pages = {618-632},
abstract = {Theory of mind requires belief- and desire-understanding. Event-related brain potential (ERP) research on belief- and desire-reasoning in adults found mid-frontal activations for both desires and beliefs, and selective right-posterior activations only for beliefs. Developmentally, children understand desires before beliefs; thus, a critical question concerns whether neural specialization for belief-reasoning exists in childhood or develops later. Neural activity was recorded as 7- and 8-year-olds (N = 18) performed the same diverse-desires, diverse-beliefs, and physical control tasks used in a previous adult ERP study. Like adults, mid-frontal scalp activations were found for belief- and desire-reasoning. Moreover, analyses using correct trials alone yielded selective right-posterior activations for belief-reasoning. Results suggest developmental links between increasingly accurate understanding of complex mental states and neural specialization supporting this understanding.}
}
@article{LiuetalCD-09,
author = {Liu, D. and Meltzoff, A. N. and Wellman, H. M.},
title = {Neural correlates of belief- and desire-reasoning},
journal = {Child Development},
volume = {80},
number = {4},
year = {2009},
pages = {1163-1171},
abstract = {Theory of mind requires an understanding of both desires and beliefs. Moreover, children understand desires before beliefs. Little is known about the mechanisms underlying this developmental lag. Additionally, previous neuroimaging and neurophysiological studies have neglected the direct comparison of these developmentally critical mental-state concepts. Event-related brain potentials were recorded as participants (N = 24; mean age = 22 years) reasoned about diverse-desires, diverse-beliefs, and parallel physical situations. A mid-frontal late slow wave (LSW) was associated with desire and belief judgments. A right-posterior LSW was only associated with belief judgments. These findings demonstrate neural overlap and critical differences in reasoning explicitly about desires and beliefs, and they suggest children recruit additional neural processes for belief judgments beyond a common, more general, mentalizing neural system.}
}
@article{EmeretalSN-06,
author = {Ermer, E. and Guerin, S. A. and Cosmides, L. and Tooby, J. and Miller, M. B.},
title = {Theory of mind broad and narrow: reasoning about social exchange engages {T}o{M} areas, precautionary reasoning does not},
journal = {Society of Neuroscience},
volume = {1},
number = {3-4},
year = {2006},
pages = {196-219},
abstract = {Baron-Cohen (1995) proposed that the theory of mind (ToM) inference system evolved to promote strategic social interaction. Social exchange--a form of co-operation for mutual benefit--involves strategic social interaction and requires ToM inferences about the contents of other individuals' mental states, especially their desires, goals, and intentions. There are behavioral and neuropsychological dissociations between reasoning about social exchange and reasoning about equivalent problems tapping other, more general content domains. It has therefore been proposed that social exchange behavior is regulated by social contract algorithms: a domain-specific inference system that is functionally specialized for reasoning about social exchange. We report an fMRI study using the Wason selection task that provides further support for this hypothesis. Precautionary rules share so many properties with social exchange rules--they are conditional, deontic, and involve subjective utilities--that most reasoning theories claim they are processed by the same neurocomputational machinery. Nevertheless, neuroimaging shows that reasoning about social exchange activates brain areas not activated by reasoning about precautionary rules, and vice versa. As predicted, neural correlates of ToM (anterior and posterior temporal cortex) were activated when subjects interpreted social exchange rules, but not precautionary rules (where ToM inferences are unnecessary). We argue that the interaction between ToM and social contract algorithms can be reciprocal: social contract algorithms requires ToM inferences, but their functional logic also allows ToM inferences to be made. By considering interactions between ToM in the narrower sense (belief-desire reasoning) and all the social inference systems that create the logic of human social interaction--ones that enable as well as use inferences about the content of mental states--a broader conception of ToM may emerge: a computational model embodying a Theory of Human Nature (ToHN).}
}
139 I may be delusional but I believe we can now build a complete, reasonably accurate facsimile of the human brain. If I'm right that means we can build an intelligence that is at least as capable of human beings in terms of its ability to interact with and perform computations similar to human beings but is also extensible allowing us to engineer artificial beings based on a silicon substrate that would be substantially more durable and computationally powerful than unaugmented human beings. I believe that all the clues are available for anyone to see. Clearly it will take substantial computational and engineering resources to deliver on the extrapolation from current technology I just made, but it implies that super-human level intelligence will scale with Moore's law and in general with respect to the law of accelerating exponential return from advanced technology.
In Issue 42 of The Wild and Crazy Guide to the Singularity, I mentioned we could build an AI today comparable in function to a human being. By that I mean engineers could sit down with cognitive and systems neuroscientists and figure out how to put together existing pieces of technology to produce a reasonable simulation of a human brain, I also mentioned that because of the law of accelerating returns we could extend this basic brain design by trading computational capacity and functional capability for power since we still don’t know how to achieve comparable efficiency. What's perhaps scary is that we could add as prosthetics the many powerful tools we use every day as technology for accelerating scientific progress and exploit these as add-ons to create a more powerful and capable machine than those designed by evolution and natural selection.
This claim does not imply we don't have a great deal to learn about the detailed organization, function and pathology of biological brains, crucial in diagnosing neurological disorders. Moreover, at the systems neuroscience level, advances in computer architecture and algorithm design will profit from a better understanding of the details of how biological brains work. It is also worth noting that humans encompass a huge variety of biological diversity in both form and function — including the molecular machinery comprising our immune systems and the extensive biota that populate our bodies and considerably expand our inherent assets, most of which is more complex than what is needed in order to replicate the basic function and architecture of the human brain, but that, as long as we inhabit flesh bodies, will be essential to our health and well-being.
140 When it comes to research and development in a commercial setting, you have to establish a reasonable tradeoff between the two. If the problem is completely terra incognita and you have no backup plan, then you're likely to fail. If the problem is tractable with little or no research required — figure out how to put well-understood components together, make the resulting system scale and secure and improve the user interface, then it's "just engineering" as some managers disparagingly quip.
The line between research and development can be thin at times, and, in this case, the question of whether to "hack it" or "go boldly" is often left hanging. Whether a manager should bet on a project or not, depends on the risk profile of the people assessing the R&D tradeoff; a good technical manager is able to work with overly optimistic research scientists and overly pessimistic software engineers to produce a reasonably accurate assessment of risks and rewards.
This aside reminded me of the pitch I made at the beginning of launching an early personal assistant project — here's a video of a presentation I gave a senior VP in early 2014. The VP was definitely of the "hack it" persuasion and almost convinced the technical lead — who was already chomping at the bit to start hiring infrastructure talent — to create a music DJ demo modeled after some locally famous NYC radio personality whom none of us had ever heard of.
In the end, we collaborated with Google Play Music, but when NLP problems started to surface, the program manager focused on infrastructure, duplicating effort elsewhere in the organization, and neglecting the problem of continuous dialog that was core to the product. The PM was unwilling to consider the new recurrent neural network "chatbot" technology being developed in the Google Brain group at the time. Needless to say, the project was discontinued soon after.
141 Recently we discussed the prospects for building better retinal prosthetics. The problem is plagued by several techncial challenges, including (i) we don't know exactly how the retina works, (ii) technology for interfacing silicon and neural circuitry is in its infancy, and (iii) we don't know how the prosthetic should communicate with the visual system. Since the R&D tradeoffs are complicated and technical challenges daunting, it makes sense to consider simple low-tech alternatives.
I remember our experience with early BrainGate technology. Michael Black was using relatively sophisticated sensing and pattern recognition techniques for the BCI and in the end we found that back-to-basics kalman filtering with no fancy spike sorting or preprocessing was better. The lesson was clear, you provide the brain with meaningful information and it will sort it out and make use of it.
David Eagleman made this even clearer for the layperson in his self-promotional TED talk showing off the VEST (Versatile Extra-Sensory Transducer) technology now being developed at the kickstarter launched Neosensory.
Simple KISS engineering exploiting what the brain does best. The VEST doesn't seem adequate to handling complex sensory experience until you think about how many bits you could actually convey by multiplexing a visual or auditory signal. Think about how body-schema mapped regions of the somatosensory cortex increase in size / density of neurons in response to learning or shrink as in the case of the rat barrel cortex when you pluck or clip the rat's whiskers.
Disclaimer: I did not contribute directly to the early BrainGate technology. I recruited Michael when he was at Xerox PARC and eventually hired him at Brown University where I was Chair of the Computer Science Department and served on the Scientific Advisory Board of the Brown Institute for Brain Science during its formation . John Donoghue who co-founded Cyberkinetics was the Chair of the Neuroscience Department and also chaired the SAB. One of my former students, Arjun Bansal, did his PhD with Donoghue, then joined BrainGate and later worked at Qualcomm before founding Nervana Systems which was acquired by Intel in 2016.
142 Whenever we become aware of an unexpected piece of information, the brain suddenly seems to burst into a large-scale activity pattern. My colleagues and I have called this property global ignition. We were inspired by the Canadian neurophysiologist Donald Hebb, who first analyzed the behavior of collective assemblies of neurons in his 1949 best seller The Organization of Behavior. Hebb explained, in very intuitive terms, how a network of neurons that excite one another can quickly fall into a global pattern of synchronized activity—much as an audience, after the first few handclaps, suddenly bursts into broad applause. Like the enthusiastic spectators who stand up after a concert and contagiously spread the applause, the large pyramidal neurons in the upper layers of cortex broadcast their excitation to a large audience of receiving neurons.
Global ignition, my colleagues and I have suggested, occurs when this broadcast excitation exceeds a threshold and becomes self-reinforcing: some neurons excite others that, in turn, return the excitation. The net result is an explosion of activity: the neurons that are strongly interconnected burst into a self-sustained state of high-level activity, a reverberating "cell assembly," as Hebb called it.
This collective phenomenon resembles what physicists call a "phase transition," or mathematicians a "bifurcation": a sudden, nearly discontinuous change in the state of a physical system. Water that freezes into an ice cube epitomizes the phase transition from liquid to solid. Early on in our thinking about consciousness, my colleagues and I noted that the concept of phase transition captures many properties of conscious perception. Like freezing, consciousness exhibits a threshold: a brief stimulus remains subliminal, while an incrementally longer one becomes fully visible. Most physical self-amplifying systems possess a tipping point where global change happens or fails depending on minute impurities or noise. The brain, we reasoned, may be no exception.
143 So how could we separate the genuine conscious code from its accompanying unconscious bells and whistles? In principle, the answer is easy. We need to search the brain for a decodable neural representation whose content correlates 100 percent with our subjective awareness. The conscious code that we are looking for should contain a full record of the subject’s experience, replete with exactly the same level of detail as the person perceives. It should be insensitive to features that she misses, even if they are physically present in the input. Conversely, it should encode the subjective content of conscious perception, even if that perception is an illusion or a hallucination. It should also preserve our subjective sense of perceived similarity: when we see a diamond and a square as two distinct shapes, rather than rotated versions of each other, so should the brain’s conscious representation.
The conscious code should also be highly invariant: it should stay put whenever we feel that the world is stable, but change as soon as we see it moving. This criterion strongly constrains the search for signatures of consciousness, because it almost certainly excludes all our early sensory areas. As we walk down a corridor, the walls project a constantly changing image on our retinas—but we are oblivious to this visual motion and perceive a stable room. Motion is omnipresent in our early visual areas but not in our awareness. Three or four times per second, our eyes jiggle around. As a result, on the retina as well as in most of our visual areas, the entire image of the world slips back and forth.
Fortunately, we remain oblivious to this nauseating swirling: our perception remains steady. Even when we gaze at a moving target, we do not perceive the background scenery gliding in the opposite direction. In the cortex, our conscious code must therefore be similarly stabilized. Somehow, thanks to the motion sensors in our inner ear and to predictions arising from our motor commands, we manage to subtract out our own motion and perceive our environment as an invariant entity. Only when these predictive motor signals are bypassed—for instance, when you move your eye by gently poking it with a finger—does the whole world seem moving.
144 Forkhead box protein P2 (FOXP2) is a protein that, in humans, is encoded by the FOXP2 gene is required for proper development of speech and language. The gene is shared with many vertebrates, where it generally plays a role in communication — for instance, the development of bird song.
145 As an inspiration and relaxing interlude, you may find it worthwhile listening to the documentary entitled "Joshua Bell," produced in 1995 for BBC Television’s "Omnibus" series, on the life of former child prodigy Joshua Bell. At age 26, he was regarded as one of the greatest violinists in the world. The film looks back at Bell's childhood in Indiana, focusing on his early life and introduction to the violin. Despite his early interest in the violin, he led an otherwise normal childhood. His first teacher was rather taciturn and did little to inspire.
However, his second teacher Josef Gingold was warm, supportive and emanated such a deep love of music that Bell blossomed under his tutelage. Gingold introduced Bell to the work of Fritz Kreisler figuring so prominently in Gingold's career and provided Bell with additional inspiration and a deeper appreciation for the art and craft of a classical musician. It is interesting to speculate how Gingold's encouragement shaped the neural basis of Bell's emotional experience of listening to and playing classical music and the physical and intellectual challenges of playing the violin.
As we'll see later, Graziano's theory relies on the idea of attention schema [171]. He writes that "[a] schema is a complex information structure that is used to represent something. One of the first schemas to be extensively studied in psychology and neuroscience was the body schema, first proposed by Head and Holmes in 1911. The body schema is an internal model — an organized set of information that represents the shape, structure, and movement of the body, that distinguishes between objects belonging to the body and objects that are foreign." You might find it interesting to learn about how the body schema changes when someone learns to ride a bike or play a musical instrument [44].
146 Attention, physiological attention as it is understood by neuroscientists, is a procedure. It is a competition between signals in the brain. It occurs because of the specific way that neurons interact with each other. One set of signals, carried by one set of neurons, rises in strength and suppresses other, competing signals carried by other neurons. For example, the visual system builds informational models of the objects in a scene. If you are looking at a cluttered scene, which informational model in your brain will win the competition of the moment, rise in signal strength, suppress other models, and dominate the brain’s computations? This competition among signals—the process by which one signal wins and dominates for a moment, then sinks down as another signal dominates—is attention. Attention may be complicated, but it is not mysterious. It is physically understandable. It could be built into a circuit [171].
147 The correspondence between awareness and attention is close. In the previous chapter I outlined a list of similarities, and in later chapters I will discuss the relationship in greater detail. The two are so similar that it is tempting to think they might be the same thing with no distinction at all. But there is a fundamental difference. Attention, the competition among signals and the enhancement of signals in the brain, is a mechanistic process. It is not explicit knowledge. Awareness, in contrast, is accessible as explicit knowledge. The brain does attention but knows awareness. The relationship between attention and awareness is therefore exactly the relationship between [...] between a real thing and a representation of it in the brain that is cognitively accessible. Awareness, in this view, is a description, a useful if physically inaccurate sketch of what it means for the brain to focus its attention [171].
148 Much has been learned recently about the neuronal basis of decision-making, especially in the relatively simple case of visual motion. Suppose that you are looking at a blurry or flickering image and are asked to decide its direction of motion. It can drift either to the left or the right, but because of the noisy quality of the image, you have trouble determining the direction. By making the task difficult in this way, neuroscientists can slow down the decision process, thereby making it easier to study.
This decision process appears to work as follows. First, the machinery in the visual system constructs signals that represent the motion of the image. Because the visual image is noisy, it may result in conflicting signals indicating motion in a variety of directions. Second, those signals are received elsewhere in the brain by decision integrators. The decision integrators determine which motion signal is consistent enough or strong enough to cross a threshold. Once the threshold is crossed, a response is triggered. In this way, the system decides which direction the image is likely to be moving.
Strictly speaking, the system is not deciding whether the visual image is moving to the right or left. It is deciding between two information streams in the brain: is the left or right motion signal stronger? The decision can even be manipulated by inserting a fine electrode into the brain, into a particular part of the visual system, passing a very small electrical current and thereby boosting one or another of the motion signals.
Since neuroscientists have some notion of the brain’s machinery for decision-making, what can be inferred about awareness? As noted above, you can decide whether you have, inside of you, an awareness of something. Therefore awareness—or at least whatever it is you are deciding you have when you say you have awareness—can be fed into a decision integrator. We can make the task even more comparable to the visual-motion task. By making the images extremely brief or dim, we can make the task difficult. You may struggle for a moment, trying to decide whether any awareness of a stimulus is present. The decision machinery is engaged. This insight that conscious report depends on the machinery of decision-making has been pointed out before.
A crucial property of decision-making is that not only is the decision itself a manipulation of data, but the decision machine depends on data as input. It does not take any other input. Feeding in some res cogitans will not work on this machine. [...] You can’t feed it ectoplasm. You can’t feed it an intangible, ineffable, indescribable thing. You can’t feed it an emergent property that transcends information. You can only feed it information.
In introspecting, in asking yourself whether you have an awareness of something, and in making the decision that you have it, what you are deciding on, what you are assessing, the actual stuff your decision engine is collecting, weighing, and concluding that you have, is information. Strictly speaking, the neuronal machinery is deciding that certain information is present in your brain at a signal strength above a threshold [171].
149 Simple pleasant and unpleasant feelings come from an ongoing process inside you called interoception. Interoception is your brain’s representation of all sensations from your internal organs and tissues, the hormones in your blood, and your immune system. Your insides are in motion. Your heart sends blood rushing through your veins and arteries. Your lungs fill and empty. Your stomach digests food. This interoceptive activity produces the spectrum of basic feeling [31].
150 [W]hen doing insight practices, the only useful gold standard for reality is your own sensate experience. From the conventional point of view, things are usually thought to be there even when you can no longer experience them, and are thus assumed with only circumstantial evidence to be somewhat stable entities. Predictability is used to assume continuity of existence. For our day-to-day lives, this assumption is adequate and often very useful.
However, when doing insight practices, it just happens to be much more useful to assume that things are only there when you experience them and not there when you don’t. Thus, the gold standard for reality when doing insight practices is the sensations that make up your reality in that instant. Sensations not there at that time do not exist, and thus only the sensations arising in that instant do exist. In short, the vast majority of what you usually think of as making up your universe doesn’t exist the vast majority of the time, from a pure sensate point of view [305].
151 Your nervous system sends sensory input to your brain when your muscles or joints are injured, or your body tissues are damaged by excessive heat or cold, or in response to a chemical irritation like a pinch of pepper in your eye. This process is called nociception. Pain is an experience that occurs not only from physical damage but also when your brain predicts damage is imminent.
You might feel the pain even before the nurse pricks your arm with a needle. Your predictions are then corrected by actual nociceptive input from the body—the injection occurs—and once any prediction errors are dealt with, you have categorized the nociception sensations and made them meaningful. The pain you experience as coming from the needle is really in your brain. [31].
152 Your brain’s 86 billion neurons, which are connected into massive networks, never lie dormant awaiting a jump-start. Your neurons are always stimulating each other, sometimes millions at a time. Given enough oxygen and nutrients, these huge cascades of stimulation, known as intrinsic brain activity, continue from birth until death. This activity is nothing like a reaction triggered by the outside world. It’s more like breathing, a process that requires no external catalyst [32].
153 Excerpts from Daniel Ingram's Mastering the Core Teachings of the Buddha, An Unusually Hardcore Dharma Book [305] relating to the experience of arising and passing (A&P) during insight meditation — also called the "4th insight stage" or the "2nd Vipassana jhana" in texts on advanced meditative practice:
Perceptual Thresholds — My favorite of the criteria, particularly found in technical and skilled meditators but also found in many others: people during the arising and passing may have the ability to perceive sensations with a speed, precision, and consistency that may be radically beyond what they were capable of before, such that they may perceive sensations up to maybe 40 times/second arising and vanishing during certain peak perceptual moments, particularly during the middle phase of the breath and in the center of wherever they place their attention. The phase characteristics of the A&P borrows from the 2nd jhana in general and involves the ability to perceive the arising and passing clearly of phenomena in a way that can feel quite effortless, and any vibrations noticed tend to be harmonically simple and change in frequency sinusoidally.Insights into Selflessness — Some may perceive that all phenomena are arising and passing away, and wherever they turn their attention may notice the transience of sensations. Extrapolating from this clear perception, they may realize: "Ah, this means that there is no permanent self." Further, unitive experiences may have the same effect, and further, in some strange intuitive way the same basic notion of something having changed in the basic notion of self-hood may shift to something less solid. Also, the fact that the A&P experiences tend to happen in a way that is seemingly effortless or even unbidden, this experience of natural occurrences can also reinforce the notion that there is less control of things than one initially suspected, adding to the sense of there being somehow less of a self in things.
Cognitive Abilities — People who are in and have crossed the A&P tend to have an easier time with processes variously called things like "vision logic", "metacognitive processing" and the like. For those who are prone to such things, they will tend to have philosophical talents beyond those who have not crossed the A&P, realizing that things like age, underlying intelligence however defined, exposure to philosophical and related branches of thinking, and education level can significantly effect how this presents. They will also tend to have an increased ability to understand and navigate in terminology that may reluctantly be termed "spiritual", though this may show in other ways, such as an increased appreciation of things like the profundity and beauty of differential equations, the implications of modern physics for questions of Subject-Object non-duality, debates of free will vs super-determinism, and the like.
154 Here is a speculative evolutionary timeline of consciousness from Consciousness and the Social Brain by Michael S. A. Graziano [171]:
The theory at a glance: from selective signal enhancement to consciousness. About half a billion years ago, nervous systems evolved an ability to enhance the most pressing of incoming signals. Gradually, this attentional focus came under top-down control. To effectively predict and deploy its own attentional focus, the brain needed a constantly updated simulation of attention. This model of attention was schematic and lacking in detail. Instead of attributing a complex neuronal machinery to the self, the model attributed to the self an experience of X — the property of being conscious of something.Just as the brain could direct attention to external signals or to internal signals, that model of attention could attribute to the self a consciousness of external events or of internal events. As that model increased in sophistication, it came to be used not only to guide one’s own attention, but for a variety of other purposes including understanding other beings. Now, in humans, consciousness is a key part of what makes us socially capable.
In this theory, consciousness emerged first with a specific function related to the control of attention and continues to evolve and expand its cognitive role. The theory explains why a brain attributes the property of consciousness to itself, and why we humans are so prone to attribute consciousness to the people and objects around us.
Timeline: Hydras evolve approximately 550 million years ago (MYA) with no selective signal enhancement; animals that do show selective signal enhancement diverge from each other approximately 530 MYA; animals that show sophisticated top-down control of attention diverge from each other approximately 350 MYA; primates first appear approximately 65 MYA; hominids appear approximately 6 MYA; Homo sapiens appear approximately 0.2 MYA
155 Notes and Excerpts on Language and Sensory Association Areas:
"I argue that language comprehension in sighted people might best be thought of as a kind of code-directed scene comprehension that draws heavily upon specifically visual, and probably largely prelinguistic processing constraints. The key processes of word-recognition and the assembly of visual word meaning patterns into interacting chains, however, may be mediated in part by species-specific activity patterns in secondary auditory cortex similar to those generated by uninterpreted speech-sound sequences." — (SOURCE: [182] in [411])"This tendency to ignore the structure of the brain is quite unfortunate in light of the recent progress made in primate neurobiology. Most current texts of physiological psychology, neuropsychology, and cognitive neuroscience (e.g., Caplan, 1987; Ellis and Young, 1988) still implicitly employ a model of the organization and evolution of the cortex that dates to the associationists of the late nineteenth century. In this way of thinking, ’primitive’ mammals like rats start out with primary visual, auditory, and somatosensory areas almost touching.
Next up the rung of an essentially pre-evolutionary scala natura come animals like cats, which have a small amount of ’uncommitted’ space in between. Finally, at the top, are primates and especially humans, where we find a great deal of uncommitted ’association’ cortex, properly situated to integrate and associate the modality-specific information presented to it by visual, auditory and somatosensory cortices (see e.g., Fodor, 1983; Ellis and Young, 1988, on the ’semantic system’ postulated in most models of word processing; Damasio, 1989)." — (SOURCE: [389])
156 Von Economo neurons (VENs) (spindle cells) are not ubiquitous across animal brains. Only humans, great apes, certain whales, and elephants have been shown to possess VENs thus far. The relative number of cells varies by species, with humans having by far the greatest amount — over twice the number of our nearest evolutionary neighbor. One argument is that some aspect of VEN function is giving rise to the cognitive abilities that make us uniquely human. SOURCE
157 Notes and Excerpts on Mirror Neurons and Physical Intuition:
Related mimetic concepts, acronyms, terminology and pseudo technical babble: Mirror Neural Network; Reflective Artificial Intelligence Dynamical System; Conscious Embodied and Virtually Embedded Models; association areas & sensory integration; revisiting couch potato; body-centric analogical machines, embodied cognition [44], brain systems supporting allostasis and interoception in humans [253]."Mirror neurons represent a distinctive class of neurons that discharge both when an individual executes a motor act and when he observes another individual performing the same or similar motor act", "In humans, brain activity consistent with that of mirror neurons has been found in the premotor cortex, the supplementary motor area, the primary so much a sensory cortex, and the inferior parietal cortex", "a recent experiment [...] Shown that, in both humans and monkeys, the mere system also responds to the sound of actions. Functional magnetic resonance imaging (fMRI) can examine the entire brain at once and suggest that a much wider network of brain areas shows mere properties in humans than previously thought. These additional areas include the somatosensory and are thought to make the observer feel what it feels like to move in the observed", "the researchers found a small number of neurons that fired or showed their greatest activity both when the individual performed a task and when he observed a task. Other neurons had anti-mirror properties, that is, they responded when the participant saw an action but were inhibited when the participant perform that action. The mirror neurons found were located in the supplementary motor area and medial temporal cortex."
Mirror neurons are associated with one of the most intriguing aspect of our complex thought process, that is "Intention understanding". There are two distinct processes of information that one can get observing an action done by another individual.
"Thus, the activation of IPL actionconstrained mirror neurons give information not only about, but also on why grasping is done (grasping for eating or grasping for placing). This specificity allowed the observer not only to recognize the observed motor act, but also to code what will be the next motor act of the not—yet—observed action, in other words to understand the intentions of the action's agent."
"The observation of an individual grasping an apple is immediately understood because it evokes the same motor representation in the parieto frontal mirror system of the observer. On the basis of this fundamental property of mirror neurons and the fact that the observation of actions like hand grasping activates the caudal part of IFG (Broca's area), neuroscientists proposed that the mirror mechanism is the basic mechanism from which language evolved."
"It is obvious that the mirror mechanism does not explain by itself the enormous complexity of speech. but, it solves one of the fundamental difficulties for understanding language evolution, that is, how and what is valid for the sender of a message become valid also for the receiver. Hypotheses and speculations on the various steps that have led from the monkey mirror system to language have been recently advanced."
"The ability to make consistent connections across different senses may have initially evolved in lower primates, but it went on developing in a more sophisticated manner in humans through remapping of mirror neurons which then became coopted for other kinds of abstraction that humans excel in, like reasoning metaphors."
"Michael Corballis, an eminent cognitive neuroscientist, argues that what distinguishes us in the animal kingdom is our capacity for recursion, which is the ability to embed our thoughts within other thoughts. "I think, therefore I am" is an example of recursive thought, because the thinker has inserted himself into his thought. Recursion enables us to conceive of our own minds and the minds of others. It also gives us the power of mental "time travel" that is the ability to insert past experiences, or imagined future ones, into present consciousness. Corballis demonstrates how these recursive structures led to the emergence of language and speech, which ultimately enabled us to share our thoughts, plan with others, and reshape our environment to better reflect our creative imaginations. Mirror neurons shape the power of recursive embedding."
"This theory suggests that humans can construct a model in their brains of the thoughts and intentions of others. We can predict the thoughts, actions of others. The theory holds that humans anticipate and make sense of the behavior of others by activating mental processes that, if carried into action, would produce similar behavior. This includes intentional behavior as well as the expression of emotions. The theory states that children use their own emotions to predict what others will do. Therefore, we project our own mental states onto others. Mirror neurons are activated both when actions are executed, and the actions are observed. This unique function of mirror neurons may explain how people recognize and understand the states of others; mirroring observed action in the brain as if they conducted the observed action."
158 Oliver Selfridge and I. J. Good — often disparaging called Turing's statistician but actually one of the most prolific scientists of his generation — were the only two Bletchley Park veterans I knew personally. Each of them was unique in their particular brand of genius. Each was iconoclastic and scientifically engaged throughout their long professional careers. Good wrote a huge amount about AI [161] and influenced my, Stuart Russell's and Eric Horvitz's research on bounded rationality [162].
159 One important contribution of Stanislas Dehaene's work is that, building on the philosophical and cognitive-psychology work of Daniel Dennett, Paul and Patricia Churchland and other more enlightened thinkers, the clarity of Dehaene's theories and experiments will put to rest the arguments of Thomas Nagel ("What is it like to be a bat?), Ned Block ("Inverted Earth") and, to a lesser degree, David Chalmers' equivocating ("Facing Up to the Problem of Consciousness") or at the very least put them on a shelf labeled "Qualia and other made-up phenomena that are practically useless, intellectually barren and psychologically disturbing". See this entry in the Stanford Encyclopedia of Philosophy for a discussion of qualia, or, better yet, read Chapter 12 entitled "Qualia Disqualified" in Dan Dennett's Consciousness Explained [111].
160 Here is a small selection of papers published between 2000 and 2010 relating to language development and the evolution of theory-of-mind reasoning. The theories are like all scientific theories, subject revision based on subsequent contravening evidence, but the theories represented in this list are particular vulnerable due to the paucity of the evidence for and against at the time of their publications. Unfortunately, at the time of this writing — September 2017 — none of these theories have definitively been shown to be false or convincingly demonstrated to being even contingently true:
@article{PyersandSenghasPSYCHOLOGICAL-SCIENCE-09,
author = {Pyers, Jennie E. and Senghas, Ann},
title = {Language Promotes False-Belief Understanding: Evidence From Learners of a New Sign Language},
journal = {Psychological Science},
volume = {20},
issue = {7},
year = {2009},
pages = {805-812},
abstract = {Developmental studies have identified a strong correlation in the timing of language development and false-belief understanding. However, the nature of this relationship remains unresolved. Does language promote false-belief understanding, or does it merely facilitate development that could occur independently, albeit on a delayed timescale? We examined language development and false-belief understanding in deaf learners of an emerging sign language in Nicaragua. The use of mental-state vocabulary and performance on a low-verbal false-belief task were assessed, over 2 years, in adult and adolescent users of Nicaraguan Sign Language. Results show that those adults who acquired a nascent form of the language during childhood produce few mental-state signs and fail to exhibit false-belief understanding. Furthermore, those whose language developed over the period of the study correspondingly developed in false-belief understanding. Thus, language learning, over and above social experience, drives the development of a mature theory of mind.},
}
@article{BednyetalPNAS-09,
author = {Bedny, Marina and Pascual-Leone, Alvaro and Saxe, Rebecca R.},
title = {Growing up blind does not change the neural bases of Theory of Mind},
journal = {Proceedings of the National Academy of Sciences},
volume = {106},
number = {27},
pages = {11312-11317},
year = {2009},
abstract = {Humans reason about the mental states of others; this capacity is called Theory of Mind (ToM). In typically developing adults, ToM is supported by a consistent group of brain regions: the bilateral temporoparietal junction (TPJ), medial prefrontal cortex (MPFC), precuneus (PC), and anterior temporal sulci (aSTS). How experience and intrinsic biological factors interact to produce this adult functional profile is not known. In the current study we investigate the role of visual experience in the development of the ToM network by studying congenitally blind adults. In experiment 1, participants listened to stories and answered true/false questions about them. The stories were either about mental or physical representations of reality (e.g., photographs). In experiment 2, participants listened to stories about people's beliefs based on seeing or hearing; people's bodily sensations (e.g., hunger); and control stories without people. Participants judged whether each story had positive or negative valance. We find that ToM brain regions of sighted and congenitally blind adults are similarly localized and functionally specific. In congenitally blind adults, reasoning about mental states leads to activity in bilateral TPJ, MPFC, PC, and aSTS. These brain regions responded more to passages about beliefs than passages about nonbelief representations or passages about bodily sensations. Reasoning about mental states that are based on seeing is furthermore similar in congenitally blind and sighted individuals. Despite their different developmental experience, congenitally blind adults have a typical ToM network. We conclude that the development of neural mechanisms for ToM depends on innate factors and on experiences represented at an abstract level, amodally.},
}
@article{AnanthaswamyNEW-SCIENTIST-09,
title = {Language may be key to theory of mind},
author = {Anil Ananthaswamy},
journal = {New Scientist},
year = 2009,
comment = {This is a general-science survey article that references the two, more-rigorous papers mentioned above.},
abstract = {How blind and deaf people approach a cognitive test regarded as a milestone in human development has provided clues to how we deduce what others are thinking. Understanding another person's perspective, and realising that it can differ from our own, is known as theory of mind.},
}
@article{deVilliersLINGUA-07,
author = {de Villiers, Jill},
title = {The Interface of Language and Theory of Mind},
journal = {Lingua: International Review of General Linguistics},
year = {2007},
volume = {117},
issue = {11},
pages = {1858-1878},
abstract = {The proposal is made that the interface between language and theory of mind is bidirectional. It seems probable that the conceptual developments of early Theory of Mind form an essential basis for helping to fix at least word reference. In development from two to four years, no basis exists in research for conclusions about the direction of influence between language and Theory of Mind. At the stage of false belief reasoning, after age four, the role of the mastery of syntactic complementation is highlighted as a representational tool, that is, language development assists reasoning. The paper presents a brief summary of Theory of Mind, ranging from its earliest beginnings in infancy to the appreciation around age four years that others might hold false beliefs and act according to them. For each development, the parallel language developments are described, and questions are raised about the interface between the two. In particular, research that might determine the direction of influence from one to the other is discussed. More work is called for, especially with nonverbal tasks, good experimental linguistic work, and other special populations, that might allow a more precise delineation of how language and Theory of Mind interrelate at the interface.},
}
@incollection{MalleLANGUAGE-THEORY-OF-MIND-02,
author = {Malle, B. F.},
title = {The relation between language and theory of mind in development and evolution},
editor = {T. Giv\'{o}n and B. F. Malle},
booktitle = {The evolution of language out of pre-language},
publisher = {Benjamins},
address = {Amsterdam},
year = {2002},
pages = {265-284},
abstract = {There is reason to believe that language and theory of mind have co- evolved, given their close relation in development and their tight connection in social behavior. However, they are clearly not inseparable—neurologically, cognitively, or functionally. So the question becomes, "What is the exact relation between language and theory of mind, in evolution, development, and social behavior?" To answer this question is a daunting task; I will try merely to clear a path toward an answer. I will consider several possible relations between the two faculties, bring conceptual arguments and empirical evidence to bear on them, and end up arguing for an escalation process in which language and theory of mind have fueled each other's evolution.}
}
@article{CharmanetalCOGNITIVE-DEVELOPMENT-00,
title = {Testing joint attention, imitation, and play as infancy precursors to language and theory of mind},
journal = {Cognitive Development},
volume = {15},
number = {4},
pages = {481-498},
year = {2000},
author = {Tony Charman and Simon Baron-Cohen and John Swettenham and Gillian Baird and Antony Cox and Auriol Drew},
abstract = {Various theoretical accounts propose that an important developmental relation exists between joint attention, play, and imitation abilities, and later theory of mind ability. However, very little direct empirical evidence supports these claims for putative "precursor" theory of mind status. A small sample (N=13) of infants, for whom measures of play, joint attention, and imitation had been collected at 20 months of age, was followed-up longitudinally at 44 months and a battery of theory of mind measures was conducted. Language and IQ were measured at both timepoints. Imitation ability at 20 months was longitudinally associated with expressive, but not receptive, language ability at 44 months. In contrast, only the joint attention behaviours of gaze switches between an adult and an active toy and looking to an adult during an ambiguous goal detection task at 20 months were longitudinally associated with theory of mind ability at 44 months. It is argued that joint attention, play, and imitation, and language and theory of mind, might form part of a shared social–communicative representational system in infancy that becomes increasingly specialised and differentiated as development progresses.}
}
@article{FranketalCOGNITION-08,
author = {Frank, M. C. and Everett, D. L. and Fedorenko, E. and Gibson, E. },
title = {Number as a cognitive technology: evidence from {P}irahã language and cognition},
journal = {Cognition},
year = {2008},
volume = {108},
number = {3},
pages = {819-824},
abstract = {Does speaking a language without number words change the way speakers of that language perceive exact quantities? The Pirahã are an Amazonian tribe who have been previously studied for their limited numerical system [Gordon, P. (2004). Numerical cognition without words: Evidence from Amazonia. Science 306, 496-499]. We show that the Pirahã have no linguistic method whatsoever for expressing exact quantity, not even "one." Despite this lack, when retested on the matching tasks used by Gordon, Pirahã speakers were able to perform exact matches with large numbers of objects perfectly but, as previously reported, they were inaccurate on matching tasks involving memory. These results suggest that language for exact number is a cultural invention rather than a linguistic universal, and that number words do not change our underlying representations of number but instead are a cognitive technology for keeping track of the cardinality of large sets across time, space, and changes in modality.}
}
@article{HesposandSpelkeNATURE-04,
author = {Hespos, S. J. and Spelke, E. S.},
title = {Conceptual precursors to language},
journal = {Nature},
year = {2004},
volume = {430},
number = {6998},
pages = {453-456},
abstract = {Because human languages vary in sound and meaning, children must learn which distinctions their language uses. For speech perception, this learning is selective: initially infants are sensitive to most acoustic distinctions used in any language, and this sensitivity reflects basic properties of the auditory system rather than mechanisms specific to language; however, infants' sensitivity to non-native sound distinctions declines over the course of the first year. Here we ask whether a similar process governs learning of word meanings. We investigated the sensitivity of 5-month-old infants in an English-speaking environment to a conceptual distinction that is marked in Korean but not English; that is, the distinction between 'tight' and 'loose' fit of one object to another. Like adult Korean speakers but unlike adult English speakers, these infants detected this distinction and divided a continuum of motion-into-contact actions into tight- and loose-fit categories. Infants' sensitivity to this distinction is linked to representations of object mechanics that are shared by non-human animals. Language learning therefore seems to develop by linking linguistic forms to universal, pre-existing representations of sound and meaning.}
}
@book{SchallerandSacks1991,
title = {A Man Without Words},
author = {Schaller, S. and Sacks, O.W.},
publisher = {University of California Press},
year = {1991},
}
Digging deeper, I wasn't able to identify any consensus regarding the evolution, development or innateness of these facilities or their neural correlates, but the evidence provided in these studies is interesting and the original direction of the research intriguing if only to inform the next generation of models.
I extended my search to papers written since 2010 and winnowed the result of all my searches to a small number labs and research scientists working at the intersection between systems neuroscience and cognitive science, i.e., not just those who profess to be cognitive neuroscientists. As for artificial neural networks and related machine-learning architectures, most of the research I'm interested in leveraging will be familiar to well-read Google engineers especially those in Brain. In addition to the various networks modeling attentional mechanisms [301, 210, 185, 169, 168], I'm interested in technologies operating on less-structured data involving language [409, 410, 408, 407, 406], simple models of logical inference [297, 296, 53, 52] and reasoning about both static and dynamics graphs [251, 129, 300, 249].