Principal components regression
- Supervised setting with response \(Y\) and design \(X\): model
\[
Y | X \sim N(X\beta, \sigma^2 I)
\equiv N(Z\alpha, \sigma^2 I), \qquad (Y_i, X_i) \overset{IID}{\sim} F
\]
where \(\alpha = \Gamma^T\beta\) and \(\text{Var}_F(X) = \Gamma \Lambda \Gamma^T\) and \(Z=X\Gamma\).
For sample version take \(\Gamma=V\) in SVD of \(R_cX\) so \(Z=\hat{Z}\)
We might hypothesize the \(\alpha[(k+1):p] = 0\), i.e. only the first \(k\) principal components of \(X\) contribute to regression…
Estimation is easy
\[
\widehat{\alpha}_i = \frac{\widehat{Z}[,i]^T Y}{n\widehat{\Lambda}[i]}
\sim N\left(\alpha_i, \frac{1}{n \Lambda[i]}\right)
\]
Noisy version
\[
Y_{n \times p} = \mu_{n \times p} + \sigma \cdot \epsilon_{n \times p}, \qquad \epsilon \sim N(0, I \otimes I)
\]
We observe entries of \(Y\) only on \(\Omega \subset \{(i,j):1 \leq i \leq n, 1 \leq j \leq p\}\).
Goal is to estimate \(\mu\).
Natural problem to try to solve:
\[
\text{minimize}_{\mu} \frac{1}{2} \|P_{\Omega}(Y - \mu)\|^2_F
\]
- Needs some regularization… low-rank?
Nuclear norm
Noiseless case
- When \(\sigma=0\) important work on the Netflix prize considered the problem
\[
\text{minimize}_{\mu: P_{\Omega}\mu=P_{\Omega}Y} \|\mu\|_*
\]
- Nuclear norm: if \(\mu=UDV^T\):
\[
\|\mu\|_* = \sum_{i} d_i
\]
\[
\text{minimize}_{\mu} \frac{1}{2} \|P_{\Omega}(Y-\mu)\|^2_F + \lambda \|\mu\|_*
\]
- Authors note that the data and estimate are “sparse + low-rank”
\[
P_{\Omega}(Y-\mu) = P_{\Omega}Y + P_{\Omega}^{\perp}\mu - \mu
\]
Algorithm involves repeated calls of nuclear norm proximal map (this soft-thresholds the singular values…)
When solution is low-rank the proximal map can be computed very quickly (faster than a full SVD) due to “sparse + low-rank” structure
PCA as an autoencoder
- Recall that the rank \(k\) PCA solution can be recast (with some particular choices) as
\[
\text{minimize}_{A \in \mathbb{R}^{p \times k}, B \in \mathbb{R}^{p \times k}}
\frac{1}{2} \|X - XAB^T\|^2_F
\]
The map \(\mathbb{R}^p \ni x \mapsto Ax \in \mathbb{R}^k\) is a “low-dimensional projection” say \(P_A\).
The map \(\mathbb{R}^k \ni u \mapsto B^Tu \in \mathbb{R}^p\) is an embedding, say \(E_B\).
- We could rewrite this objective as
\[
\text{minimize}_{A \in \mathbb{R}^{p \times k}, B \in \mathbb{R}^{p \times k}}
\frac{1}{2} \sum_{i=1}^n \|X_i - E_B(P_A(X_i))\|^2_2
\]
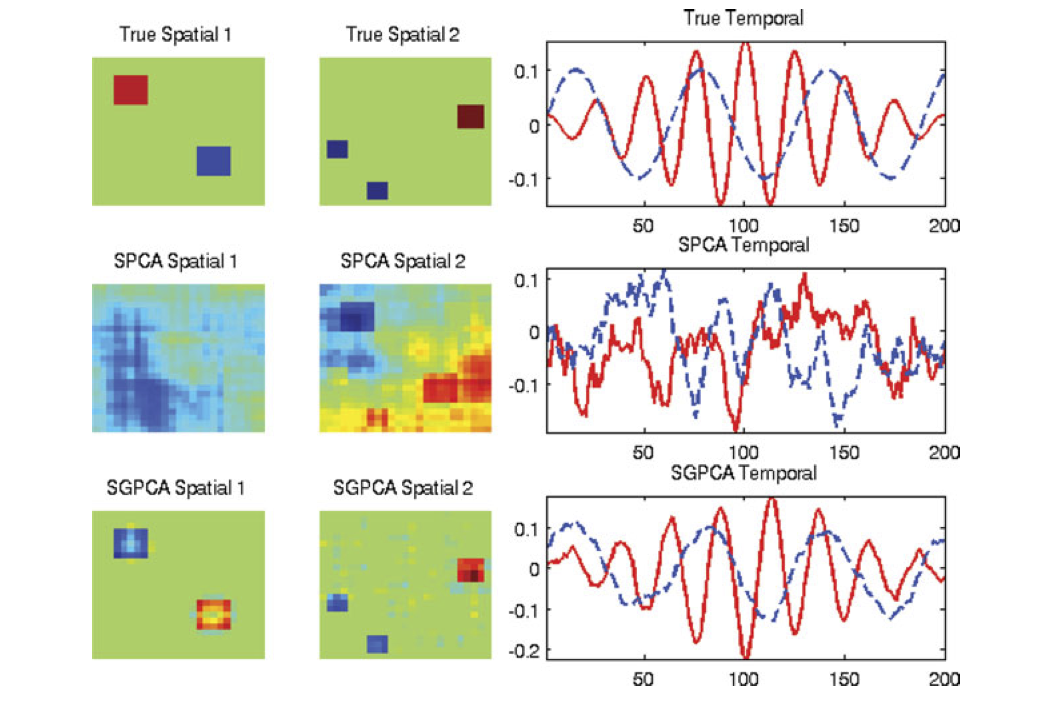
Structured PCA
We may want to interpret loading vectors: “what features are important for determining major modes of variation in the data?”
Why not try to make them sparse?
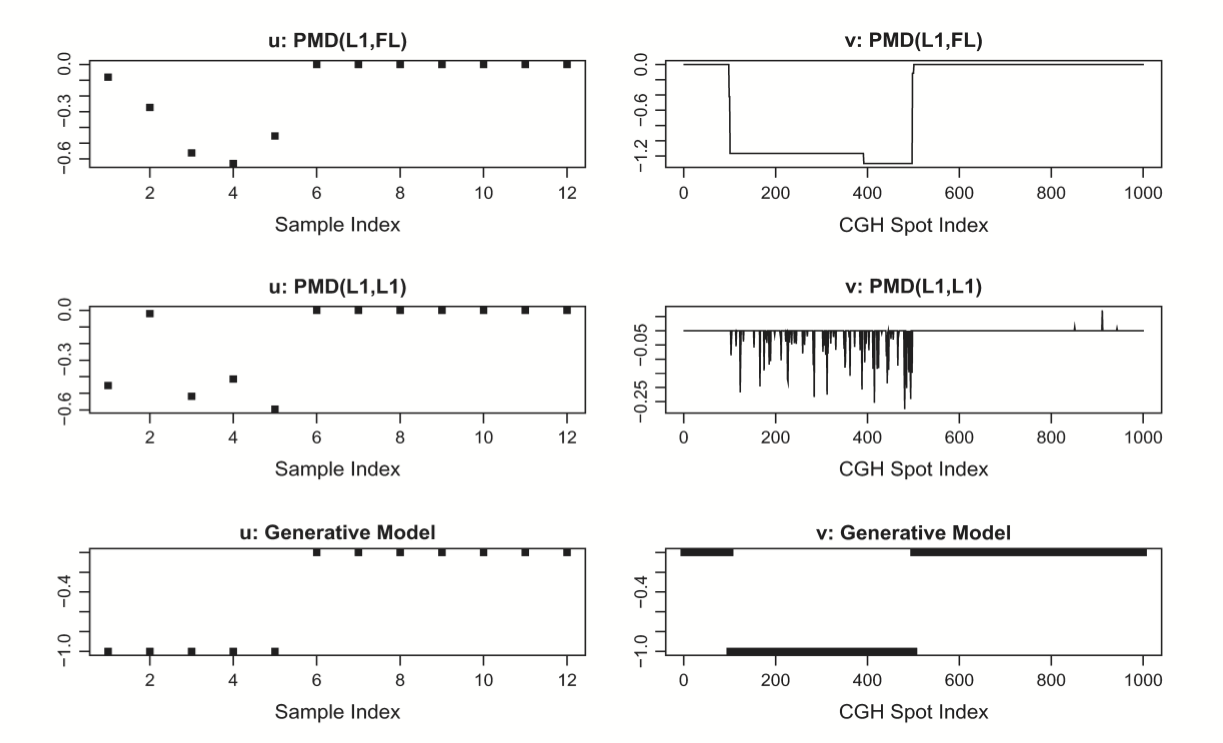
Rank-1 PCA has left and right singular vectors \(u, v\) that satisfy
\[
\text{maximize}_{u,v:\|u\|_2=1,\|v\|_2=1} u^TXv
\]
- Leading singular value is achieved value \(\hat{u}^TX\hat{v}\).
- Suppose we want sparsity in \(v\), the PMD proposes
\[
\text{maximize}_{u,v:\|u\|_2 \leq 1,\|v\|_2 \leq 1, \|v\|_1 \leq c} u^TXv
\]
- Problem (phrased as minimization) is bi-convex in \((u,v)\) which induces a natural ascent algorithm: starting at \((u^{(t)}, v^{(t)})\)
\[
\begin{aligned}
u^{(t+1)} &= \text{argmax}_{u: \|u\|_2 \leq 1} u^TXv^{(t)} \\
v^{(t+1)} &= \text{argmax}_{v: \|v\|_2 \leq 1, \|v\|_1 \leq c} (u^{(t+1)})^TXv \\
\end{aligned}
\]
Missing data
- PMD can be fit with missing entries: as in matrix completion, replace \(u^TXv\) with
\[
\text{Tr}(P_{\omega}(X) P_{\omega}(vu^T))
\]
\[
\begin{aligned}
u^{(t+1)} &= \text{argmax}_{u: \|u\|_2 \leq 1} \text{Tr}(P_{\omega}(X) P_{\omega}(v^{(t)}u^T)) \\
v^{(t+1)} &= \text{argmax}_{v: \|v\|_2 \leq 1, \|v\|_1 \leq c} \text{Tr}(P_{\omega}(X) P_{\omega}(vu^{(t+1)}^T)) \\
\end{aligned}
\]
Choice of tuning parameter
Split \(X\) into 10 matrices removing elements at random, resulting in matrices similar to matrix completion
Run CV: fit PMD on the union of 9 out of 10, predict on missing 10th…
Similar to a scheme proposed for tuning PCA Bi-CV
Fused LASSO
- They use the fused LASSO:
\[
{\cal P}(\beta) = \lambda_1 \|\beta\|_1 + \lambda_2 \sum_{j=1}^{p-1} |\beta_{j+1} - \beta_j|
\]
- Solutions generically will be sparse and piecewise constant.
\[
\text{minimize}_{A \in \mathbb{R}^{n \times k}, B \in \mathbb{R}^{p \times k}: A \geq 0, B \geq 0} \frac{1}{2} \|X-AB^T\|^2_F
\]
Natural model for NNMF?
\[
X_{ij} \sim \text{Poisson}(\lambda_{ij})
\]
\[
\lambda_{ij} = \lambda_0 \pi^R_i \pi^C_j
\]
- Corresponds to sampling a Poisson number of individuals from a population with \(R\) independent of \(C\).
- Suppose there is a mixture of \(k\) independence models
\[
\lambda_{ij} = \lambda_0 \left(\sum_{l=1}^k \pi^L_l \pi^R_{i|l} \pi^C_{j|l} \right)
\]
- Such \(\lambda\) matrix has an NNMF of rank \(k\), though likelihood would not be Frobenius norm…
- We looked at PCA solely with Frobenius norm, i.e. the rank \(k\) PCA is equivalent to
\[
\text{minimize}_{A \in \mathbb{R}^{n \times k}, B \in \mathbb{R}^{p \times k}} \frac{1}{2} \|X-AB^T\|^2_F
\]
What if there were structure across rows, i.e. \(X[,i] \sim N(0, \Sigma_R)\)?
Reasonable to whiten first and consider
\[
\text{minimize}_{A \in \mathbb{R}^{n \times k}, B \in \mathbb{R}^{p \times k}} \frac{1}{2} \|\Sigma_R^{-1/2}(X-AB^T)\|^2_F
\]
- Could have structure in the columns as well, why not whiten there as well?
\[
\text{minimize}_{A \in \mathbb{R}^{n \times k}, B \in \mathbb{R}^{p \times k}} \frac{1}{2} \|\Sigma_R^{-1/2}(X-AB^T)\Sigma_C^{-1/2}\|^2_F
\]
- Replaces Frobenius norm with a norm
\[
X \mapsto \text{Tr}(\Sigma_C^{-1}X^T\Sigma_R^{-1}X)^{1/2}
\]
- Frobenius is the special case \(\Sigma_C, \Sigma_R = I_p, I_n\).