One common need in clinic is to estimate the probability of various clinical outcomes for the patient, to help counsel the patient about options. This is especially important when we are considering a treatment that is probably not going to work very well or is especially risky. How can a patient weigh the risks and benefits when their likelihood is unknown? The current way doctors approach this is not great. For common situations we will often be able to give a good estimate off the top of our head, based on past trials or retrospective studies. I suspect that even in this situation many doctors' estimates told to patients are not that accurate, but at least it is feasible to succeed in this.
But for uncommon situations, like a rare cancer diagnosis, or the combination of two moderately common diseases that interact with each other, there are usually few clinical trials and we will not have numbers memorized. Common references like UpToDate will often not contain the information either. So to get an estimate the doctor would have to do extra work, by diving into abstracts and papers, or polling colleagues. This is nonideal for many reasons: it won't be possible to give the patient an answer right away, the doctor may not be motivated to do this or may be too busy, and the data that they use may be inaccurate or may not apply that well to this patient. Take the hypothetical example question: "My patient received concurrent chemoradiation for HPV negative squamous cell carcinoma of the base of tongue two years ago and now has recurrence in the primary site and bilateral nodes. If he has salvage surgery, what are the chances of cure and long-term survival? He is a nonsmoker and is otherwise healthy." This is not an especially obscure topic. UpToDate has an article on treatment of locally recurrent head and neck cancer that has a section on salvage surgery. But the first reference is from 2000 and doesn't examine smoking and HPV status even though these are likely to significantly affect the outcome. Another reference had only 15 oropharynx patients who got salvage surgery. It would be very hard to quickly get good answers to the questions. Due to these difficulties, the outcome estimates that doctors give to their patients probably are often not very accurate. I have had several situations where another doctor quoted a patient a cancer recurrence risk that was more than 50% off from my estimate. I am not saying the other doctor was even wrong -- just that the fact that two cancer specalists had such different estimates is a sign that there is a problem.
And, this comes up all the time! Uncommon situations aren't uncommon when you add them all together.
AI to the rescue?
I think AI will have a huge positive impact on this issue. In the near future the doctor may be able to type the question into the computer, and the computer will quickly return a detailed report that the doctor and patient can use right away.
I can see two main approaches that could help accomplish this: using published papers/literature, or using individual patients' electronic medical record (EMR) data. I think that in the short term the first approach will work better, but in the long term it will be eclipsed by the second.
The literature summarization approach
The literature-based approach is clearly easier to do, and is already getting useful. A great example of this is Elicit. You type in a research question and it looks through millions of paper abstracts, finds the most relevant ones, and tries to extract an answer to your question from each. In addition to a table of the papers, it makes a nice 1-paragraph summary of its findings:

This is very cool and it's already an improvement on the status quo, if you take the time to read through the papers it finds to make sure it's not hallucinating its conclusions. But there are major issues that limit the potential of the approach:
- Publication bias / file drawer problem
Studies showing null results, or results that do not align with scientific consensus, tend to be published less. Here is a convincing paper on the topic: TESS study.
- P-hacking, coding errors
Researchers sometimes subconsciously or consciously change their research methods and analyses to get significant p values (to get the paper accepted), and/or find the results they are hoping to find. This is not necessarily nefarious. This pattern has been demonstrated in multiple fields including medicine, but maybe most famously in psychology. See: A peculiar prevalence of p values just below .05. Thinking about our specific topic which is outcomes of certain treatments, it is not hard to imagine that papers from radiation oncologists will tend to find good results from radiation, surgeons will tend to find good results from surgery, etc.
And retrospective studies often have statistical analysis done by doctors or medical students who are not experts in statistics. Sometimes there are errors in the coding or analysis that flip the conclusions of the study; many of these have probably never been caught. One example in a different field.
- Inadequate studies
For uncommon clinical situations, these studies tend to be from a single institution due to difficulties with data sharing and academic credit (there can only be one first author). This limits the sample size. Also, each study will report different patient characteristics, outcomes, and subgroup analyses.
- Recent developments
Certain areas change quickly. For instance, the rise of anti-PD-1 immunotherapy in the last decade. For an older/frail patient with localized cutaneous squamous cell carcinoma who has a complete response to neoadjuvant immunotherapy, should we even do local treatment with surgery or radiation? Very few papers on this that I am aware of, because it takes years to follow the patients for outcomes, start a study, analyze the data, and get it published.
- Ultra-rare situation
So your patient has an early stage lung cancer, COPD, and a rare nontuberculous mycobacterial infection of the lungs. You want to know the risk of respiratory compromise if you give radiation treatment for the lung cancer. There is just not going to be enough in the literature to answer this (though you never know -- I found a surprisingly good paper on lung cancer and NTM when researching this article!).
The individual patient data approach
There is a different approach that solves most of these problems. If we go to the source and extract specific patients' outcomes from the electronic medical record, we can avoid p-hacking and publication bias. And if we pool data from many centers, maybe we can get enough patients together that we can estimate outcomes for even rare situations. Until recently this would have been a pipe dream. One could select patients using diagnosis and procedure codes entered by doctors in routine care, but these are notoriously unreliable. And many clinical concepts cannot be reduced to diagnosis codes anyway (cancer stage, performance status, medication adherence, social support, etc.).
But now with large language models we can automatically extract patient cohorts and outcomes from the doctors' notes in the medical record with good accuracy [1, 2], and LLMs are only going to get better at this. So the LLM could take the user's question, break it down into specific tasks (extracting patient cohort, treatments, and outcomes), and end up with a custom dataset of patients and outcomes that the LLM could then analyze to answer the question.
It is also starting to become plausible that this could be done on many medical centers' data at once, to increase sample size. Organizations like OHDSI are making it easier to transform medical records into a common data model and quickly run a query on multiple centers' clinical data, without the data ever leaving the center's computers.
I don't think this clinical question answering approach is going to be deployed in the next 1-2 years, because significant infrastructure would be needed and LLMs have to get more bulletproof since there would not be manual vetting of the LLM's work. But it could happen in the next 5 years.
There are already some people and companies working in this direction, like Atropos Health. They have a commercial offering that uses individual patient data to answer questions:
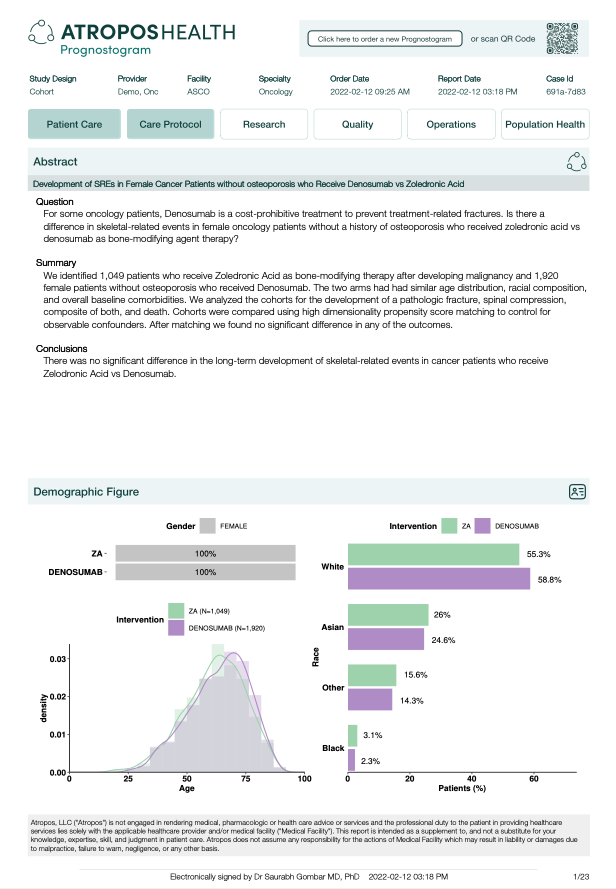
I believe that their current offering relies on structured diagnosis/procedure codes, but I am sure they are thinking about how to transition to using clinical notes.
The individual patient data approach is not a panacea. Our clinical question often involves asking which treatment will work better for our patient, and non-randomized data are not very good at answering that question since certain kinds of patients tend to get certain treatments. If patients who get radiation tend to be sicker than surgery patients, and the medical record does not fully capture this (for instance due to a doctor not recording all of a patient's symptoms), radiation will look like it leads to shorter survival. My colleagues and I (and many others) have been doing some research to try to overcome this issue but it is a work in progress. Randomized controlled trials are still incredibly valuable and are the gold standard for comparing effectiveness of different treatments.
Another major issue is incomplete outcome data. Some outcomes that require specialized cognitive or cardiovascular testing are not captured in routine medical record data. And patients are lost to follow-up and get care from different centers, leading to incomplete data on treatment and outcomes. For example, it has been demonstrated that medical record data tends to over-estimate survival time due to informative censoring (sicker patients tend to be lost to follow-up and their deaths are not captured) [1, 2]. Depending on the outcome of interest this effect may be more or less important.
Final thoughts
It is possible that the the two strategies will converge over time. It will get easier to publish chart review papers since LLMs can help find the patients and extract the outcomes (just as described in the prior section). Sharing the raw data along with the publication is getting more popular (though it should be much more common than it is -- journal editors, please help push this forward!). MedRxiv and other sites now make it easy to post preprints, these are getting more accepted, and people are waking up to the absurdities in the journal publishing system. So literature summarization tools like Elicit will have more and better papers and data to work with.
While I am convinced these sorts of tools will be incredibly useful for doctors, other health care providers, and patients, there is a lot of work left to do. There are potential issues of errors/hallucinations from the LLM, bias against certain groups which currently have poor health outcomes, automation bias (users overly trusting the answers), and probably other things that I am not aware of or that are yet to be discovered. But I think these will be surmounted or mitigated, and I hope to be using these tools in my practice in the near future.