Algorithm
Optimization:
Given a graph 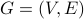 , with vertex set
, with vertex set ![V=[n]](eqs/8750270273880543756-130.png) ,
and an integer
,
and an integer 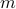 , we attempt to solve the following non-convex problem:
, we attempt to solve the following non-convex problem:
![begin{array}{ll} {rm maximize} & sum_{(i,j)in E} sigma_icdotsigma_j-frac{gamma}{2}big|Mbig|_2^2 {rm subj. to} & |sigma_{i}|_2 = 1; forall iin [n], end{array}](eqs/1354162627471729238-130.png)
where 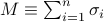 , and
, and 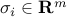 .
.
We use block-coordiate ascent, where at each step we maximize over the vector 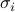 .
Namely at each step, we draw
.
Namely at each step, we draw ![iin [n]](eqs/2396769512758373086-130.png) uniformly at random and update to
uniformly at random and update to
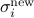 given by
given by
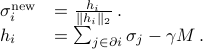
where  denotes the set of neighbors of
denotes the set of neighbors of  in
in 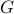 .
.
Projection:
Once an (approximate, local) maximizer is obtained, we construct an embedding of vertices as follows.
Compute the empirical covariance
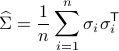
Compute its eigenvalues end eigenvectors
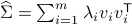 ,
with
,
with  . Note that, by construction
. Note that, by construction  .
Let
.
Let 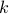 be the smallest index such that
be the smallest index such that 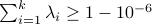 .
.
Return, for each vertex
, the projections on the leading eigenvectors
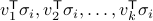 .
Notice that these coordinates are ordered by ‘importance.’
.
Notice that these coordinates are ordered by ‘importance.’
We observe empirically that is often smaller than . The dimension of the embedding can be further
reduced by only using the first  dimensions (for some
dimensions (for some 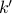 chosen by the user).
chosen by the user).
How to choose the input parameters:
The user must specify three parameters:
The number of components
. The algorithm is pretty insensitive to this choice, and we found that 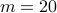 works in most cases (in the sense that the optimization converges to a global maximum).
Indeed, this choice appears to be conservative and often
works in most cases (in the sense that the optimization converges to a global maximum).
Indeed, this choice appears to be conservative and often 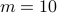 or smaller works as well.
For very large instances (above
or smaller works as well.
For very large instances (above 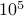 vertices), it might be useful to use larger values, e.g.
vertices), it might be useful to use larger values, e.g.  .
.
The regularization parameter
 . The default choice
. The default choice 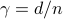 , with
, with 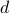 the average degree,
seems appropriate in most cases.
the average degree,
seems appropriate in most cases.
The number of iterations. Each iteration corresponds to
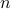 block updates. We obtained satisfactory results with
block updates. We obtained satisfactory results with 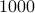 iterations or less.
iterations or less.