Schedule: Algorithms, Geometry and Learning
Abstracts, references and notes will be uploaded as they become available.
The schedule has been finalized. Also available in Google Calendar.
The reading group is held every Tuesday 3:00pm - 5:00pm in Gates 463.
Spring Quarter 2016
Tuesday 10/11: Paris Syminelakis on Local Dimensionality Reduction: beyond the Johnson-Lindenstrauss bound
The JL lemma gives us a way to approximately preserve the euclidean distance between 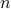 points in
points in 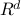 by projecting them in a random subspace of dimension
by projecting them in a random subspace of dimension 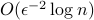 . It has been shown LN’16 that the dimension of this map is optimal. In this talk, we will explore what can be done in the case where we seek to approximate distances only between close pairs of points, that is, construct maps with ‘‘small local distortion‘‘ and of dimension that depends only on the ‘‘locality‘‘ and crucially not on the total number of points. We will present techniques for general metric spaces as well as specifically for the euclidean space. In particular, we will discuss three Distributional lemmas that provide the basis of constructing such maps, based on: Biased Random Sampling (Bourgain/Matousek), Probabilistic Partitions (Bartal et al.), Randomized Nash Device (Bartal, Recht, Schulman). The talk will be self contained and only assumes knowledge of basic probability.
. It has been shown LN’16 that the dimension of this map is optimal. In this talk, we will explore what can be done in the case where we seek to approximate distances only between close pairs of points, that is, construct maps with ‘‘small local distortion‘‘ and of dimension that depends only on the ‘‘locality‘‘ and crucially not on the total number of points. We will present techniques for general metric spaces as well as specifically for the euclidean space. In particular, we will discuss three Distributional lemmas that provide the basis of constructing such maps, based on: Biased Random Sampling (Bourgain/Matousek), Probabilistic Partitions (Bartal et al.), Randomized Nash Device (Bartal, Recht, Schulman). The talk will be self contained and only assumes knowledge of basic probability.
Notes by Paris Syminelakis.
Local Embeddings of Metric Spaces by I. Abraham, Y. Bartal, O. Neiman, in Algorithmica’15.
Dimensionality Reduction: beyond the Johnson-Lindenstrauss bound by Y. Bartal, B. Recht, L. Schulman, in SODA’11.
Tuesday 10/18: Roy Frostig on What functions do neural networks express at initialization?
We would all some day like to understand what functions neural nets effectively capture as a consequence of (a) their architecture and (b) the training procedure. This paper takes a first step by studying the point of random initialization (where full gradient-based training typically begins). A random-weight network yields, via its final hidden layer, an embedding. We show that this embedding is a randomized approximation of a particular kernel that depends on the network structure, so that learning linear classifiers over this embedding is approximately learning in the kernel space.
Tuesday 10/25: Yuchen Zhang on Provable algorithms for learning neural networks.
Neural networks have been widely used in machine learning and artificial intelligence, but the theoretical understanding of neural network learning has lagged its practical successes. In this talk, we study several provable algorithms for learning multi-layer and fully connected neural networks for binary classification.
We make two critical assumptions on the class of neural networks to be learned. First, we assume that the L1-norm of the incoming weights of any neuron is bounded by a constant. Second, we assume that there is an oracle neural network which separates all positive and negative examples by a constant margin. Under these assumptions, we present an efficient algorithm which learns a neural network with arbitrarily small generalization error 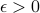 . The algorithm's sample complexity and time complexity have polynomial dependence on the input dimension and on
. The algorithm's sample complexity and time complexity have polynomial dependence on the input dimension and on 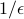 . We also present a kernel-based improper learning algorithm which achieves the same learnability result, but not relying on the separability assumption. Experiments on synthetic and real datasets demonstrate that the proposed algorithms are not only understandable in theory, but also useful in practice.
. We also present a kernel-based improper learning algorithm which achieves the same learnability result, but not relying on the separability assumption. Experiments on synthetic and real datasets demonstrate that the proposed algorithms are not only understandable in theory, but also useful in practice.
L1-regularized Neural Networks are Improperly Learnable in Polynomial Time Y. Zhang et al., ICML 2016.
Learning Halfspaces and Neural Networks with Random Initialization by Y. Zhang et al.
Tuesday 11/1: Josh Wang on Provable Bounds for learning some deep representations
Continuing from last week, we again examine provable algorithms for learning neural networks. This time, we will consider the task of learning a random neural network. By analyzing the structure of random graphs, it turns out that we can give good guarantees about the number of samples and the computation time that we need for this task. Along the way, we will also show that each layer of our random neural network is a denoising autoencoder with high probability.
Notes by Josh Wang.
Tuesday 11/8: Junzi Zhang on Deep Learning without Poor Local optima
This week, instead of talking about algorithms for neural networks, we examine the behavior of critical points in general deep learning problems. We first discuss a recent result by Kenji Kawaguchi NIPS'16 concerning deep linear networks, which states that every critical point must either be a global minimum or a saddle point. Proof techniques will be summarized with brief comments. We then introduce the counterpart results in deep nonlinear networks, comparing the works by Kawaguchi and Choromanska et al respectively. We will see that although Kawaguchi weakens the assumptions taken by Choromanska et al., he only proves a very restricted partial generalization by reduction to linear cases, which is too optimistic in some sense. Removing all unrealistic assumptions in nonlinear cases and obtaining more expressive critical point structures remains an open problem.
Notes by Junzi Jhang.
Deep Learning without Poor Local optima by Kenji Kawaguchi.
The landscape of the loss surfaces of multilayer networks by Chromanska et al.
Neural Networks and Principal Component Analysis: Learning from Examples Without Local Minima by P. Baldo and K. Hornik.
Tuesday 11/15: Michael Kim on Optimal Sample Complexity of PAC Learning
In this talk, we will cover the recent optimal PAC Learning algorithm by Hanneke. Specifically, we will show that in order to PAC learn a concept f from any concept class C with VC dimension d, 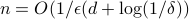 samples suffice to learn a concept that, w.p.
samples suffice to learn a concept that, w.p. 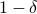 has error rate
has error rate 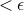 . This upper bound matches a long-standing lower bound. The approach is conceptually simple: train many classifiers on portions of the data and take the majority vote of these classifiers. The main contribution is a novel combinatorial technique for reusing training data while maintaining sufficient independence between training sets, which may be of independent interest. The talk will be self-contained – all are welcome!
. This upper bound matches a long-standing lower bound. The approach is conceptually simple: train many classifiers on portions of the data and take the majority vote of these classifiers. The main contribution is a novel combinatorial technique for reusing training data while maintaining sufficient independence between training sets, which may be of independent interest. The talk will be self-contained – all are welcome!
Notes by Michael Kim.
A general lower bound on the number of examples needed for learning, A. Ehrenfreucht et al., 1989.
Tuesday 11/29: Steve Mussman on Agnositcally Learning Decision Trees
This paper provides a query algorithm for agnostically learning decision trees with respect to the uniform distribution on inputs. Given black-box access to an arbitrary binary function f on the n-dimensional hypercube, the algorithm finds a function that agrees with f on almost as many inputs as the best size-t decision tree, in polynomial time. This is the first polynomial-time algorithm for learning decision trees in a harsh noise model. The core of the learning algorithm is a procedure to implicitly solve a convex optimization problem over the L1 ball in 2^n dimensions using an approximate gradient projection method. The problem and basic concepts will be presented, the main result will be stated, and the proof will be shown. The talk will be self-contained and I hope to present it in a way so that everyone can get something out of it.
Notes by Steve Mussman.